1. Introduction
With the development of information, more and more services need security protection, and identity authentication has gradually become a primary means to protect users’ information. Password-based authentication was created with the advent of mainframes, and has been widely used in mainframe access control since the 1960s. Now, passwords have become one of the most critical means of preventing users from being attacked in the Internet world [
1]. Passwords are not only easy for users to understand and memorize, but also relatively simple for programmers to deploy at low cost, so they have been generally recognized and adopted by academia and industry [
2]. Password authentication will still be a crucial method in the future [
3].
However, on the one hand, users often need to manage dozens or hundreds of password accounts, and the numbers are growing. Additionally, the requirements for setting passwords on various websites are often very different [
4]. On the other hand, users’ energy for dealing with information security affairs is pretty limited, and this will not be greatly improved over time [
5]. This fundamental contradiction leads to potentially vulnerable behaviors, such as using weak passwords with low information entropy, reusing the same password on multiple websites, and recording passwords on paper [
6]. All of these behaviors can bring out vulnerable factors including simple numbers, familiar words, too short length, the inclusion of personal information, and so forth. Consequently, the vulnerable factors make attacking passwords possible [
7].
Password attack technology is mainly used for recovering passwords [
8] and measuring their strength [
9]. In the virtual environment, passwords are often set for files to protect specific data. If users forget or lose their passwords for encrypted files, it is necessary to recover them. In addition, sometimes the security department will need to recover illegal documents [
10], which will also include operating system password recovery, mailbox password recovery, encrypted file password recovery [
11], and so forth. The primary purpose of evaluating password strength is to analyze the ability of a given plaintext password to resist brute force cracking [
12]. In general, some passwords can be cracked with some techniques or tools, so in the field of password strength measurement, the number of times or time spent cracking is taken as the evaluation index.
The password attack method utilizing the password generative model is an offline attack [
13] that does not need to interact with the server. The password can be saved in either plaintext or hash value, and the number of password guessing is usually significant. It is a kind of trawling attacking method [
14], which does not use any personal user information (such as birthday, email, etc.) during the attack. Accompanied by the development of machine learning technology, various password generative models have been proposed [
15,
16,
17]. Attackers first generate a large number of passwords using a generative model, then try to crack the system using the generated passwords one by one. Most of the early password generative models relied on heuristic rules set by experts, such as replacing lowercase letters in passwords with uppercase letters, changing words, and so forth [
18]. These pure rule-based models have poor universality, and their effect is not satisfactory. Recently, models based on machine learning have become mainstream, such as the Markov [
19], PCFG [
20], RNN(LSTM) [
21], and GAN [
22] models. They explicitly or implicitly model the probability of a password with mathematical theory foundation support, and perform better in practice. Compared with the other three models, the Markov model, based on statistical machine learning, has certain advantages in training and inference speed, because it only needs to count and randomly sample instead of performing many neuronal operations [
23]. At the same time, it maintains almost the same level of generated password quality because its assumptions accord with human language habits. The Markov model is still widely used because of its superior comprehensive performance [
24].
Nevertheless, our observation finds that the Markov model suffers from a high repetition rate, and this problem becomes more severe as the number of passwords the model generates increases. It is obvious that a high repetition rate will also lead to an insufficient cover rate [
25]. The enumeration method is different from the random sampling method, which is a deterministic algorithm. It usually has a worse cover rate of high-probability passwords, and always generates the same passwords in the same order when generating them [
26], which makes it easy to attack. To solve the above problems, we introduce a dynamic distribution mechanism into the random sampling method. Then, we add a dynamic distribution mechanism to the Markov model, and eventually build a dynamic Markov model.
The structure of this paper is as follows. In
Section 2, we briefly introduce other password cracking methods, including the brute force cracking and dictionary methods. We introduce the password generative models mainly include the statistical learning models (such as Markov and PCFG model) and the deep learning models (such as RNN and GAN model). In
Section 3, we first analyze the shortcomings of the standard Markov model based on random sampling and OMEN based on enumeration. For the above problems, we introduce the dynamic distribution mechanism and prove its mathematical basis. Finally, we apply the dynamic distribution mechanism to the Markov model and propose a dynamic Markov model. In
Section 4, we carry out the experiment, and compare the performance of several related models from multiple perspectives. In
Section 5, we summarize and analyze the proposed model based on theoretical analysis and experiments. The last section presents our conclusion.
2. Related Work
In order to improve the success rate of password cracking, the patterns of passwords have been studied intensely. Through the analysis of most users’ passwords [
27,
28], it is found that in addition to choosing some words as passwords, users often simply change words to meet the requirements of a website password setting strategy, and about 1 in 10 people choose to use the top 10 passwords. By mining several leaked public data sets, Wang concluded that passwords, like human languages, all satisfy Zipf distribution [
29], that is, the frequency of the password decreases by polynomial, and high-frequency and low-frequency passwords occupy important parts of the whole password set [
30]. The phenomenon that most Chinese passwords contain numbers, and more than a quarter of them are only composed of numbers, was found by [
31]. English passwords prefer English letters, and most passwords are composed of letters and numbers according to an analysis of the character structure of passwords [
32]. The study of the length of passwords indicates that more than 90% of passwords are between 6 and 11 characters, but for websites with high importance, the password length is usually greater than 11 characters [
33]. Additionally, name, name ID, birthday, username, email prefix, ID number, phone number, and even love information may be used [
34].
Generally speaking, password cracking methods consist of brute force [
35] and dictionary [
6] cracking. In the brute force cracking method, with multi-thread, distributed, and GPU assistance [
36], an attacker can test potential passwords through exhaustive algorithms in a relatively simple password space. However, as the maximum password length and character set size increase, the size of the password space will grow exponentially, making it difficult to traverse and search all passwords under limited computing resources [
37]. The dictionary cracking method generates a dictionary consisting of a variety of passwords and guesses using the dictionary. Furthermore, some rules are adopted to promote diversity. John the Ripper [
38] designs word transformation rules that simulate the scene when the user creates a password. Hashcat [
39] modifies, cuts and expands words, and adds some human preferred rules. Analogously, it has inefficient performance when the string space becomes vast. Rather than depending on traverse searching, which ignores the password difference or sets heuristic rules, password generative models try to generate high-quality passwords by machine learning theory.
2.1. Markov Model
Narayanan first introduced the Markov model in the password guessing task [
19]. The password possesses local relevance, which means each character only has a relationship with the previous
n characters. The order of generating passwords from left to right conforms to human habits, and the concise assumption is reasonable in natural language processing. Based on the Markov model, Tansey expanded the number of layer to
n and equipped each layer with different weights, where
n represents the expected length of the password [
40]. Each node in the multi-layer Markov model not only can switch to itself, but also save related information of front characters. Due to the supplemented probability distribution, the model improves the quality of password generation. OMEN [
26], proposed by Durmuth, can generate passwords in descending order of frequency. Then, passwords with high probability appear early, which contributes to increasing the cracking speed. Wang improved the Markov model for targeted attacks [
41]. Specifically, it treats username, email prefix, name, birthday, phone number, and identification number as equal characters. The targeted Markov model makes full use of the user’s personal information and shows excellent performance. The Markov model, as a classic algorithm for natural language processing, also shows good effects with passwords. Additionally, considering the speed perspective, the Markov model surpasses the other password generative models [
42]. In a word, the Markov model is still popular for its overall performance.
2.2. Other Password Generative Models
Other password generative models use distinct principles and can achieve a great cracking effect. The PCFG model [
20] cuts the password according to the type of character (including letter (
l), number (
n), and special symbol (
s)). It counts all generated structures from the training dataset and calculates the probability information during training, eventually uses a queue to generate passwords. Houshmand adopted keyboard rules in FCFG [
43], and could crack extra passwords that obey these rules. Veras conducted deep semantic mining of the letter part, which particularly increased the cracking ability for long passwords [
44]. Li proposed a personal-PCFG model that equally dealt with username, email prefix, and so forth. The reinforced model has better performance especially in target attacks [
45]. With the success of deep learning, neural networks that have more capacity and stronger representation ability have attracted attention. Sutskever generated text using recurrent neural networks, showing that the RNN model has the ability to handle text sequences [
46]. Melicher took passwords as an extension of human language [
21], and first tried to generate passwords in the RNN framework. The RNN generated one character at each time step and used the generated character as the input for the next time step until the terminator appeared or the maximum length was reached. In other studies, RNN [
47] was replaced with LSTM [
48], promoting the effect of capturing the long-range dependence of characters. Teng devised a PG-RNN that increased the number of neurons, and got competitive results on multiple datasets [
34]. The generative adversarial network [
15] is currently the best among the generative models, especially in computer vision. PassGAN was introduced in [
22] to generate passwords. Then, PassGAN was enhanced [
49] to directly learn the probability distribution of the password encoding matrix. After training with the Wasserstein loss function [
50,
51], it just needs to provide the generator with random noise sampled in Gaussian distribution, and then the generator outputs the coding matrix of the password. Nam used the relative GAN to improve the loss function, and the performance of GAN in password guessing was greatly improved by multi-source training [
52]. In addition, the generator was improved in [
53] with recurrent neural networks, which could acquire better generation effect.
Overall, first, compared with the Markov model, the relatively low speed is an apparent disadvantage for the other models [
23]. In the training stage, the PCFG model needs to additionally count structure probability information. For the models based on neural networks, many weight parameters must be trained by the backpropagation algorithm [
54]. In the generation stage, the PCFG model has to generate extra structure. The RNN and GAN models contain large scale multiplication operations and activation functions. These complicated operations inevitably slow down inference speed in contrast with random sampling [
55]. Second, viewed from the perspective of quality, the PCFG model’s straightforward splitting of strings deviates from the actual situation, and models based on neural networks have limit representation ability in passwords [
56]. In addition, considering the problem of generating repeated passwords, models based on neural networks usually do not perform satisfactorily if they are not trained well; in particular, the GAN model frequently experiences mode collapse [
57]. Statistical machine learning models such as the Markov model and PCFG models, also generate large-scale repeated passwords if the random sampling method is used. In summary, the Markov model has an advantage in terms of comprehensive performance, yet a high repetition rate would be one factor prohibiting the model from cracking efficiently.
3. Method
3.1. Standard Markov Model
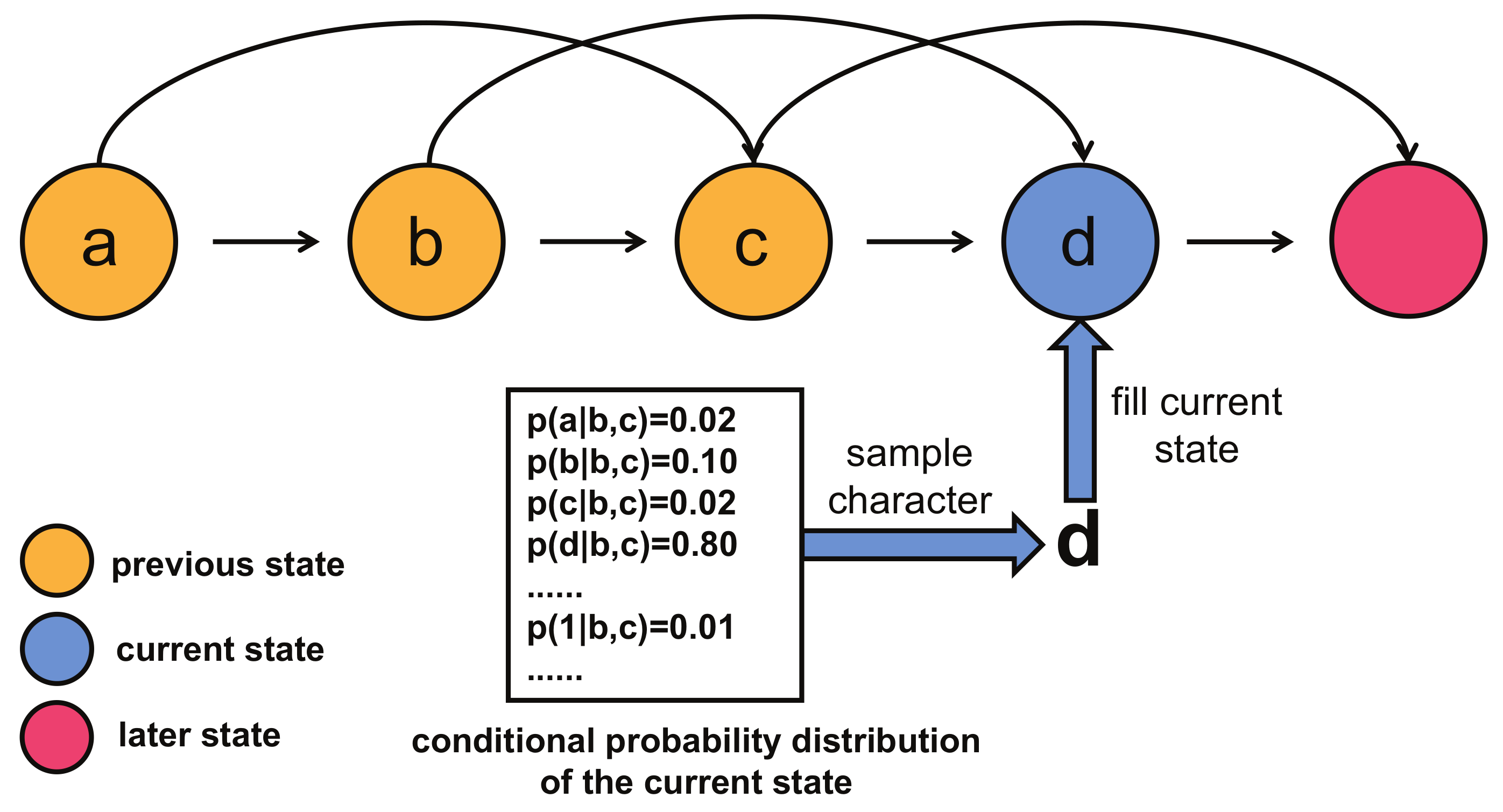
It is impossible to accurately model the probability of a password directly. The Markov model makes a concise hypothesis for the expression of password probability, and then the password can be statistically modeled. In the Markov model, the probability distribution of characters in each state is only related to the characters in the front
n state, where
n is defined as the order of the model, as shown in
Figure 1.
Each character in the password can be combined with the previous
n characters to form an n-gram fragment, which is denoted as
where
is the character in the
ith state, and | is used to isolate the current and previous state characters, so the n-gram fragment represents the dependencies between the current and previous character. For example, a password
containing
m characters can be divided into
m n-gram fragments:
. It should be noted that the first
n n-gram fragments are not
n order gram, which should strictly be 0-gram, 1-gram, n-gram. Here, we call them all n-gram fragments for convenience. Each n-gram fragment
corresponds to a conditional probability
, and these n-gram fragments are independent of each other, so the probability of password
P is the product of
m conditional probability values:
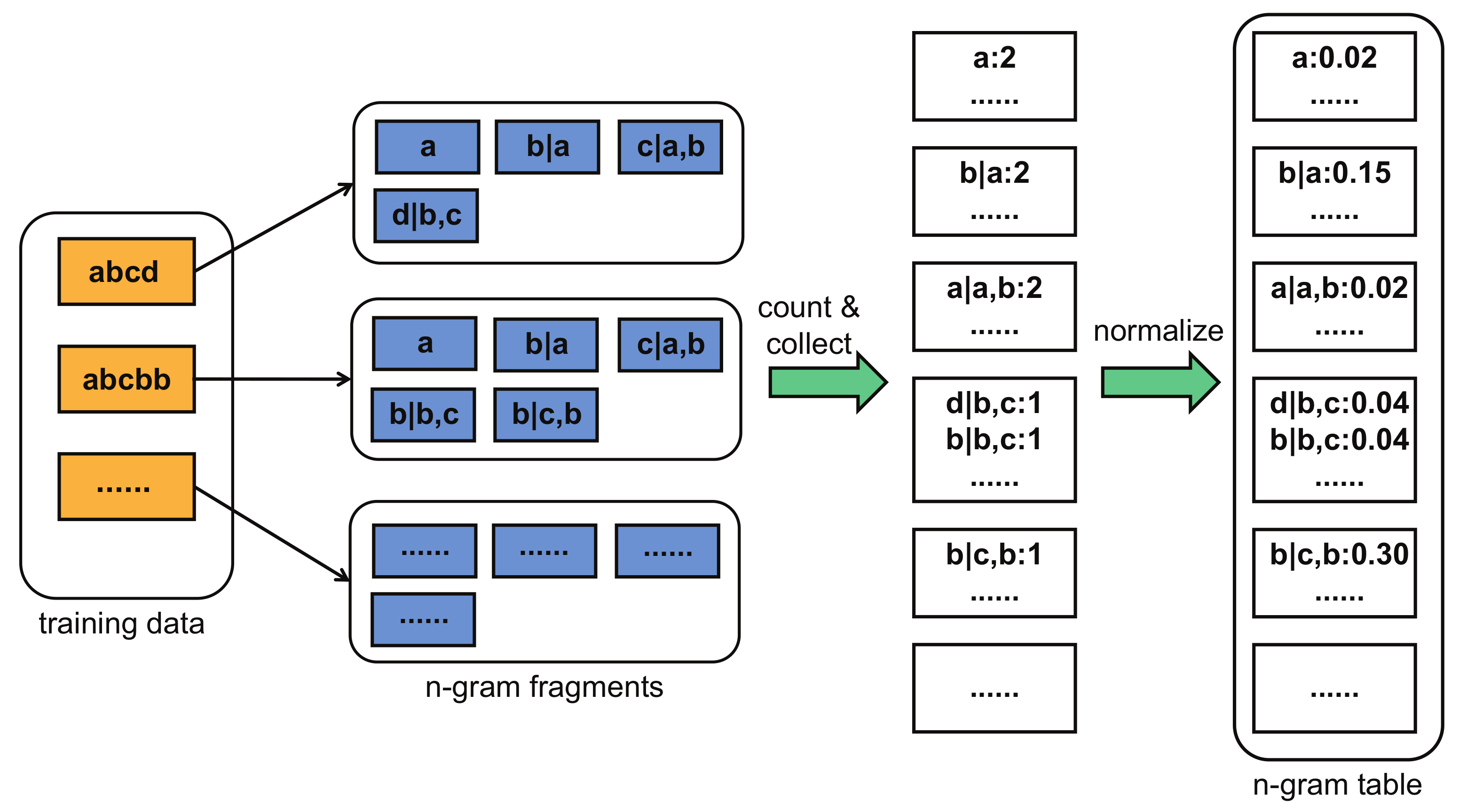
The Markov model should be trained well before generating passwords. In preparation, we have to collect a public password dataset containing quantities of real passwords as a training set. While training the Markov model, we first split each training password into multiple n-gram fragments, count the occurrence frequency of all n-gram fragments, and then collect n-gram fragments that have the same conditional character; eventually we perform the probability normalization operation to obtain the corresponding n-gram conditional probability distribution. The process is depicted in
Figure 2. We define the n-gram table as the set of all n-gram conditional probability distributions. After the training process succeeds, the n-gram table stores the conditional probability distribution of all characters learned by the model, and the explicitly statistical modeling of password probability is completed. When we need to generate a password, we just continuously sample the characters in the n-gram table one by one. We denote this kind of Markov model that uses random sampling as the standard Markov model in the next.
In order to further analyze the password probability distribution, we have to make a clear definition of the support set and original probability distribution of the Markov model. We define the maximum length of the string as , and the character set is . For any string in string space , all satisfy both (1) , and (2) . The Markov model explicitly fixes the probability of each string in string space . For part of the strings , probability can be obtained by querying the n-gram table, while for another part of strings , some n-gram fragments do not exist in the n-gram table, which means their probability is 0. We can form a set of all strings whose probability value is more than 0, and define this set support set . Obviously, support set is a subset of string space . The sum of the probabilities of all strings in is 1, where high probability means the string has a higher probability of being a password, and low probability means the string is not likely to be a password. Only a string with a probability more than 0 can be considered as a password. Any password the model may generate must belong to , so the size of means the cracking potential of the model. The training process not only enables the Markov model to learn support set from string space , but also assigns a corresponding probability to each password in . We call this distribution the original distribution . It is apparent that original distribution is only determined by the training data set.
3.2. Defects in Markov Model
3.2.1. Problems in Standard Markov Model
Cracking passwords using the standard Markov model has the problem of generating large scale repeated passwords. To illustrate this problem, we utilized the RockYou [
58] dataset to train the model. RockYou dataset is a large scale dataset that includes almost 21,000,000 real passwords, therefore it is widely used in password guessing tasks. We made the model generate
passwords, and we observed the result from two aspects: the number of repeated passwords and the repetition rate. The repetition rate expresses the proportion of repeated passwords in the generated passwords. The results (
Table 1) show that there are only
unique passwords, and the other
passwords are all repeated passwords, which means the model wastes about
of computing resources. In addition, we find that there is a positive correlation between the number of generated passwords and the number and proportion of repeated passwords. More unique passwords are accompanied by more waste, which severely limits the cracking efficiency.
Repeated passwords not only constrain efficiency, but also restrict the cover rate. The cover rate indicates the hit ratio of generated passwords to the passwords in the test set. One reason is that repeated passwords take up many appearance opportunities within limit generation time, so the other passwords that are possible to hit have no chance to be generated. Another reason is that the essence of the standard Markov model is equal to random sampling in the original distribution . Due to the randomness of the sampling method, high-probability passwords will appear with high frequency, while low-probability passwords will not show up often or even disappear, and then passwords with low probability in the test set are hard to cover.
3.2.2. Problems in OMEN
Compared with the other Markov model, OMEN, which uses the enumeration method, gets the best cover rate result [
26] but it does not perform best in any probability range. In our experiment, we first divided the RockYou test set into 10 regions according to the probability value (obtained by the Markov model, which is trained on the train dataset). OMEN was also trained in the training dataset and generated
passwords. We find that OMEN performs worse in the high probability range, as shown in
Table 2. For example, in the range
to
, the standard Markov model hits 3000 more passwords.
In addition, OMEN is a deterministic algorithm, while the standard Markov model is a stochastic algorithm. After the model finishes the training process and corresponding parameters are all fixed, OMEN always generates the same passwords with the same order each time, whereas the standard Markov generates different passwords each time. Thus, in some cases, determinacy could be used to prevent passwords from being cracked by OMEN as possible, while this is not possible in the standard Markov model. For instance, we generate T passwords as set using OMEN, and randomly select a password that not in . We also require that must have been modeled, that is, its probability is not zero. At this point, we can guarantee that OMEN will not hit within T generations, because it does not appear in the first T generations. However, it is possible for every password that has been modeled to emerge at any moment if the standard Markov model is applied, hence it has absolute advantages in this particular case.
3.3. Dynamic Distribution Mechanism
For all of the above problems, we propose the dynamic distribution mechanism during the generation process in the Markov model to reduce the repetition rate, so as to improve the cover rate. In establishing the dynamic distribution mechanism, we mainly consider four points, as follows:
First, the dynamic distribution mechanism is apply only in the random sampling method. Second, each time a password is generated, the dynamic distribution mechanism is adopted. It prohibits by reducing its probability value, thereby reducing the possibility of subsequent appearance of . As the probability of the password in the Markov model is the product of multiple conditional probabilities, the passwords’ probability expression has a complex interwoven relationship, then we can consider subtracting by a small constant. Third, since the sum of the probability of all passwords in support set is 1, prohibiting would inevitably lead to a change in probability of other passwords in . Here, we could increase the probability value of all passwords in other than , thus the model would focus more on obtaining other passwords in the next. Finally, it should be pointed out that for strings other than , we think they have little meaning for cracking, and adjusting their probability would require a large amount of computing resources, so the dynamic distribution mechanism only changes the probability of passwords in support set .
There are several advantages to the dynamic distribution mechanism:
- 1.
It can decrease the repetition rate. Once a password is generated, it will be restricted, and the chance of being randomly sampled will be reduced. At the same time, the chance of other passwords being randomly sampled will be increased. The degree of constraint is related to the probability value. Considering the situation that the higher the password’s probability, the larger its contribution to the repetition rate, so this mechanism can decrease the repetition rate accordingly. On the other hand, we find that the dynamic distribution mechanism pushes the probability distribution of passwords toward uniform distribution according to Theorem 1. The closer the probability distribution gets to the uniform distribution , the smaller the repetition rate.
- 2.
It can improve the cover rate. Compared with simple random sampling, the dynamic distribution mechanism can help the model to adjust distribution constantly. This adjustment makes the model avoid useless attempts, but encourages it to try completely new passwords.
- 3.
It can cover high-probability passwords better. In the random sampling method, the appearance frequency of passwords is relevant to their probability. The dynamic distribution mechanism designs a smooth and slow process which ensures that some passwords will keep a high probability value for a long time. At the same time, its effect of reducing repeated passwords expands the search range of high-probability passwords. Therefore, usually, high-probability passwords are almost all sampled if the number of generation operations is large enough. However, enumeration methods (such as OMEN) use local instead of global sorting, so they generate passwords in an approximate but not strict descending probability order. In fact, it is impossible to go through all the passwords and sort them strictly in descending probability order. Hence, usually some high-probability passwords are missed, which is also shown in the experiment in
Table 2.
Theorem 1. For any original distribution , randomly select a password which satisfies , where N is total number of passwords in , then reduce its probability by α, and increase the other passwords probability by , then the new passwords probability distribution will be closer to the uniform distribution .
Proof of Theorem 1. We use KL divergence
to measure the distance between the original and uniform distribution, which is:
In the neighborhood of
:
, we perform a one-order Taylor expansion about
which gets
:
In
, the probability of
is
, while the other passwords probability is
and
. The approximate KL divergence
is:
The approximate difference of two KL divergence
A is defined as:
Therefore,
A can be reduced to:
According to the inequality:
Obviously, if , we have , so . □
3.4. Dynamic Markov Model
We employ the dynamic distribution mechanism in the standard Markov model and propose a dynamic Markov model. Given the way passwords are modeled by Markov chain, we have to make subtle adjustments in practice. There are three deviations compared with the ideal theory in Theorem 1.
When the model generates password , it is impossible to verify whether is more than 1 or not, because N is unknown, therefore the model has to replace the verification method with another simplified method. As multiple n-gram fragments jointly determine the probability of the password, it is very complicated to deal with the probability of the whole password, so the dynamic Markov model executes operations at the n-gram level instead of the password level. So we judge whether the probability value of the n-gram fragment is greater than . Moreover, the experimental results also prove that this simplification can effectively make the distribution of the password more uniform.
In order to reduce the probability of , we can only adjust the conditional probability. If m conditional probability values are all adjusted, the model will consume too much calculation time, affecting the overall password generating speed. Simultaneously, a large number of passwords will be affected, and the probability distribution will change greatly, so it is difficult to guarantee the cover rate. For example, 123456 and 123456789 are both high-probability passwords; 123456 has been generated and 123456789 has not appeared. Adjusting 6 conditional probability values of password 123456 will greatly reduce the probability of 123456789, so randomly getting 123456789 becomes more difficult. Hence, the dynamic Markov model randomly selects one of m conditional probability to adjust each time. This approach of modifying the probability is matched with password modeling mode, and it limits the influence range of modifying as much as possible.
We need to increase the probability of passwords in except for , but it is impossible to traverse all of these passwords. Therefore, we increase the probability of some passwords which have the selected n-gram fragments, while the probability of other unrelated passwords reamins the same. The dynamic Markov model ensures that the changes of the password probability distribution just restrict on the support set and do not propagate into the string space . Although that only modifies a small part of the password, it avoids the time-consuming modification of all passwords every time.
Overall, because the number of passwords in the support set N is unknown and large, and Markov’s modeling strategy for passwords makes them share n-gram fragments, the dynamic Markov model makes the above three modifications on the basis of comprehensive consideration of computational efficiency and practical difficulties. It successfully realizes the application of the dynamic distribution mechanism. It should be noted that there is a balancing effect in the dynamic distribution mechanism itself. For example, changing the probability distribution of the n-gram fragment would result in the over modification of some passwords (such as those that contain ; ; ; etc.), but would have no effect on other passwords (such as those that do not contain these above n-gram fragments). These two simultaneous effects would be partially offset during the multiple processes of random sampling to generate passwords.
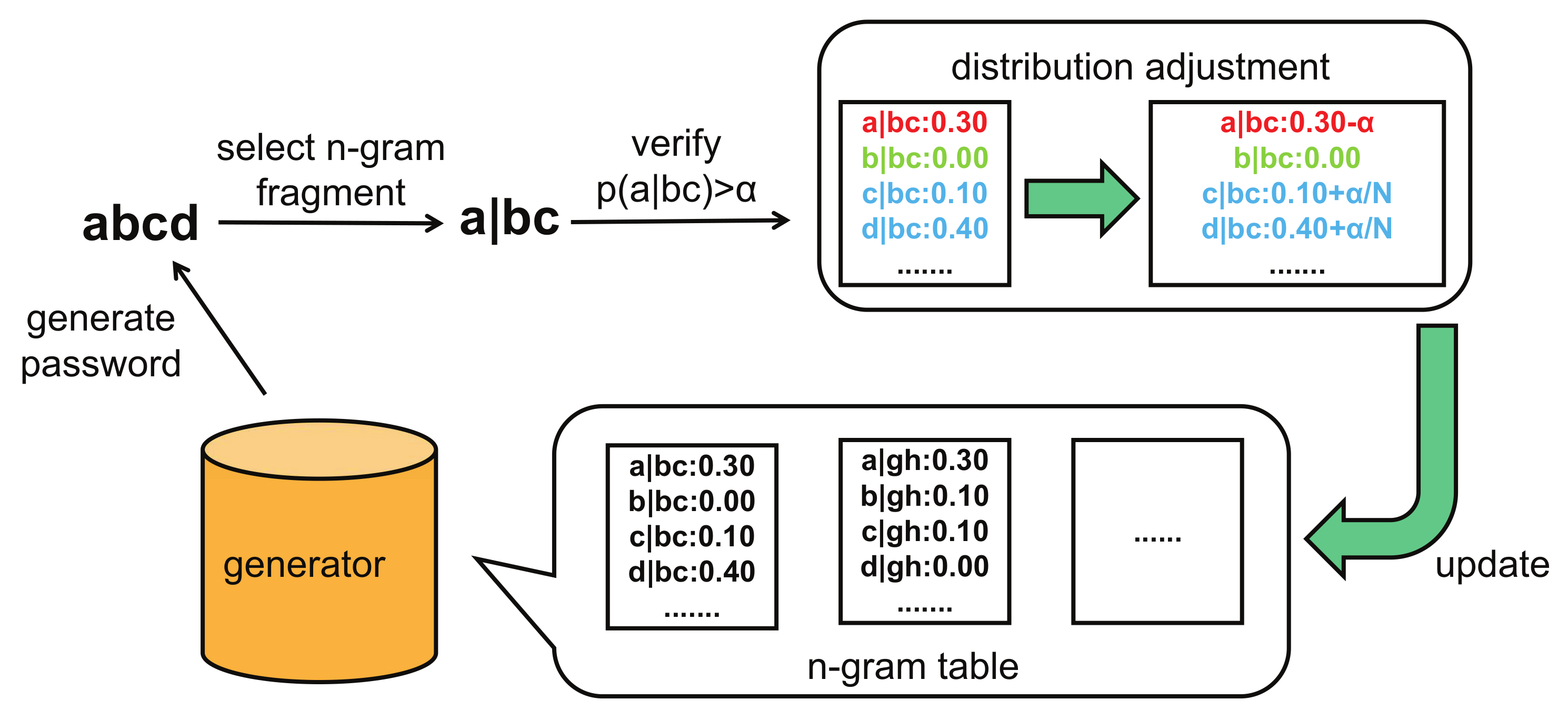
Our dynamic distribution mechanism works as follows in practice: for example, first randomly select n-gram fragment
. For the discrete conditional probability distribution
, reduce the value of
with a fixed value
and adjust it to
, increase the value of
evenly, and keep the value of
always 0, where
represents the character not
and appears in the conditional probability distribution
, and
is the other characters in character set
V except
and
. In summary, when the model adjusts the conditional probability distribution
, it automatically adjusts the probability distribution of other passwords in
. For passwords that contain n-gram fragments
, the probability decreases, and the probability of passwords containing fragments
increases, as shown in
Figure 3. The change degree of the probability depends on the situation of including n-gram fragments. The complete password generating algorithm of dynamic Markov model is shown in Algorithm 1.
| Algorithm 1 dynamic Markov model |
| Require: number of generative passwords: N, max length of password: , n-gram fragment: , other characters except in distribution : , fixed value of reduced probability: . |
| for
|
| initial blank string S |
|
do |
| generate random number |
| generate a character c by randomly sampling in n-gram table using r |
| append c to S |
| until or |
| randomly choose an n-gram fragment (for example, ) in string S |
|
if
|
| adjust to |
| count total number of |
|
for |
| adjust to |
|
end for |
|
end if |
| end for |
4. Experiments
To verify the performance of the dynamic Markov model, we chose to experiment on public dataset. The training of a password generative model requires a large and realistic data set, and the RockYou dataset satisfies both requirements. RockYou.com [
58] stores passwords in plaintext form in the database, and the SQL vulnerability of the site led to a user password leak. Millions of passwords were stolen by intruders and spread on the network for many years; this dataset has been widely applied in academic research related to passwords. The RockYou dataset includes 21,315,685 passwords in total, among which 8,274,727 passwords are unique after deduplication. We randomly shuffled the data set initially, and took the first 80% of the data as the training set and the bottom 20% as the test set. The training set contained 17,052,548 passwords, with 6,909,743 unique passwords. The test set included 4,263,137 passwords, with 2,174,626 unique passwords.
In the experiment, the training set was used to train the password generative model, and both the cover rate and repetition rate were used to evaluate the performance. Assuming that the model generates
N passwords and the number of unique passwords is
n, the repetition rate
is
If the test set has
T passwords and
t unique passwords, then the cover rate
is
Our experimental hardware environment is: Intel(R) Xeon(R) Silver 4116 CPU with 2.10 GHz main frequency, 12 cores and 128 GB memory. The software environment is: the Ubuntu 16.04.6 LTS operating system. The programming language is Python3.6.
4.1. Effect of Parameter
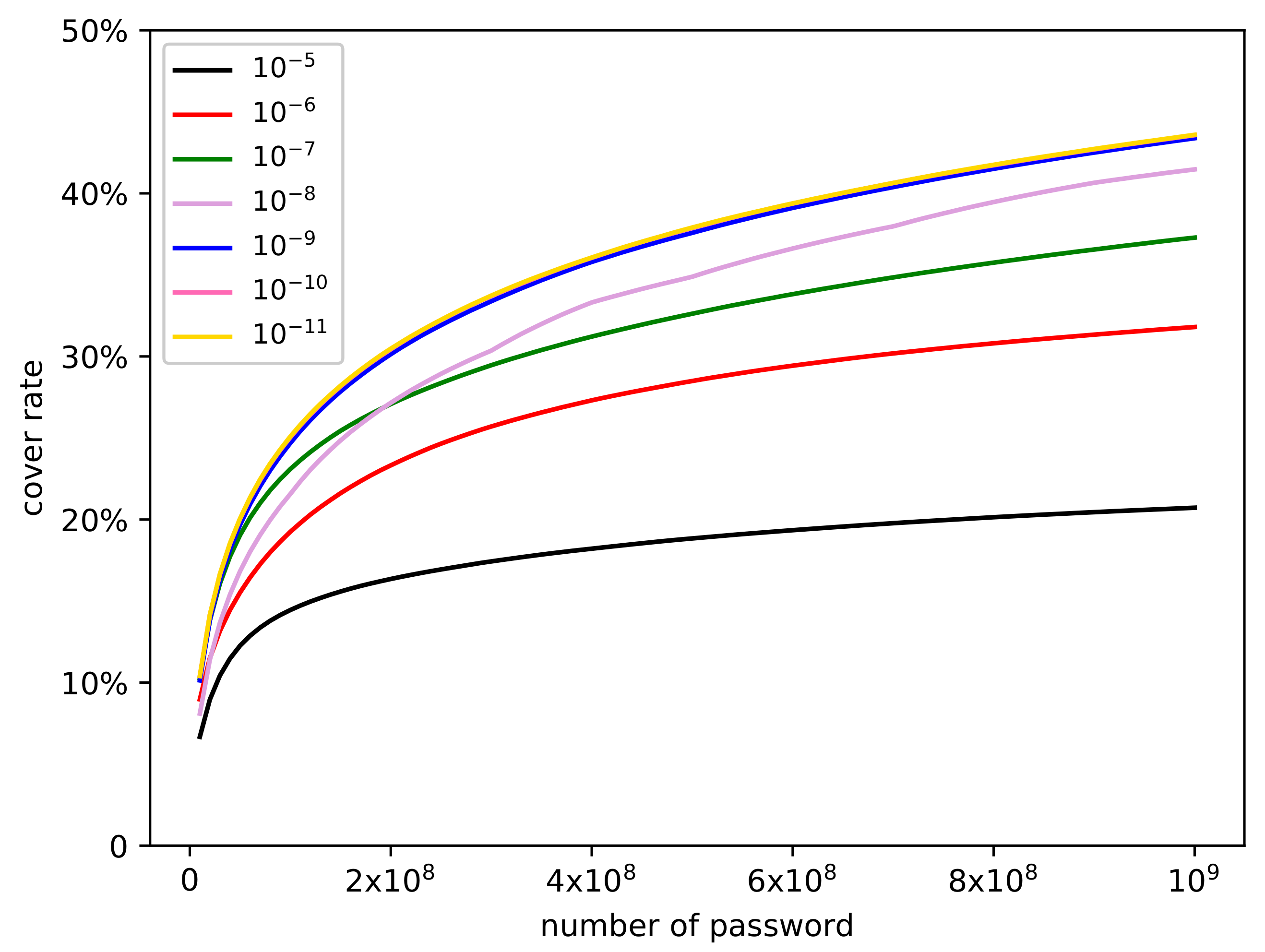
There exists a vital parameter
that has a significant and decisive impact on the performance of the dynamic Markov model. This parameter represents the amplitude of each probability adjustment and directly controls the speed at which the probability distribution of passwords tends to be uniform. If
is too large, most of the n-gram fragments cannot be adjusted, because the probability value is less than
, and the cover rate is greatly reduced (for example, when
is
, the cover rate is less than 20%), making the model useless. On the contrary, if the value of the parameter is small, the effect difference between parameters is not apparent (for example, when
is set as
and
, the cover rate and repetition rate are almost the same), so we conducted experiments on parameter
from
to
, and tried a variety of different values, including
, and
. First, we used the training set to train the dynamic Markov models with different values of
, and we selected the model order
n as 3. Next, we used these 7 password generative models to generate passwords. In order to evaluate the model comprehensively, we generated
passwords and calculate the
and
values in each scale. The experimental results are shown in
Figure 4 and
Figure 5.
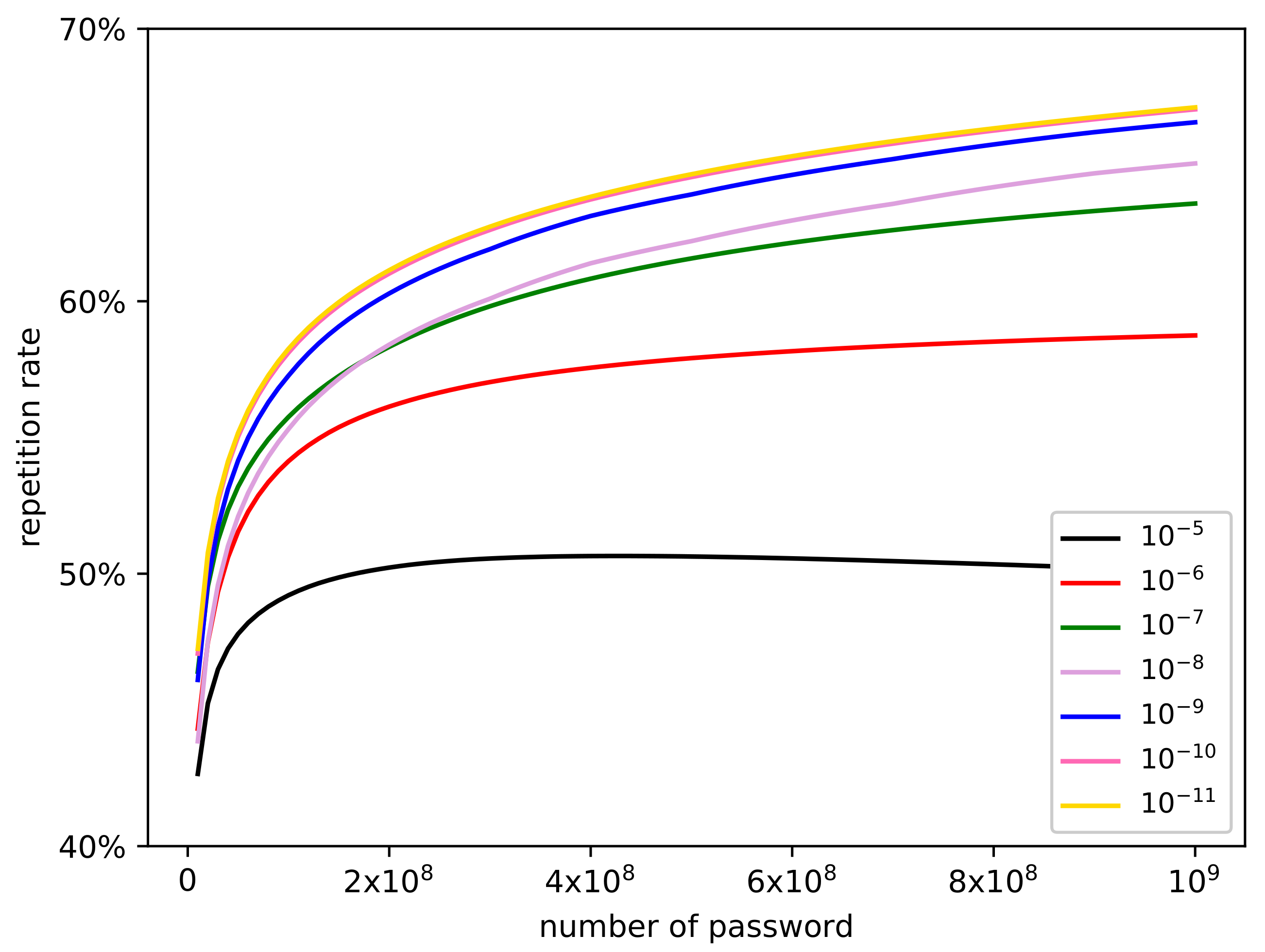
The experimental results prove that the scale of parameter has a remarkable impact on the performance of the model. For the repetition rate, choosing a smaller would get a larger value. When is equal to , is always below 0.5. As the parameter decreases, the gap between adjacent parameters becomes smaller. Both parameters and have essentially the same effect. As for the cover rate, a smaller means a higher cover rate. Analogously, the gap between neighboring parameters also becomes smaller as the parameter decreases. When parameter is selected as , , or , they achieve the same and the best result. The best dynamic Markov model in the RockYou dataset is obtained when parameter is .
For the above results, we infer the core reason is that some high-probability passwords share the same n-gram fragment. After the dynamic Markov model randomly generates a high-probability password, it chooses an n-gram fragment to reduce its probability, which inevitably reduces the probability of those passwords that contain this n-gram fragment so they become low-probability passwords. This mechanism makes it difficult for these passwords to be randomly generated afterward, therefore the cover rate decreases. A larger parameter helps generate more unique passwords. Because the probability of some important n-gram fragments is reduced too much, some low-probability passwords have more chance to be generated, but these passwords usually have the limit potential for cracking. When parameter is selected appropriately, the password probability adjustment variation is relatively low, which can effectively prevent high-probability passwords from being submerged and reduce the repetition rate. This experimental phenomenon also shows us that the adjustment range of the password probability should be limited at a relatively flat level, so it is reasonable to randomly select one n-gram fragment instead of all n-gram fragments to adjust.
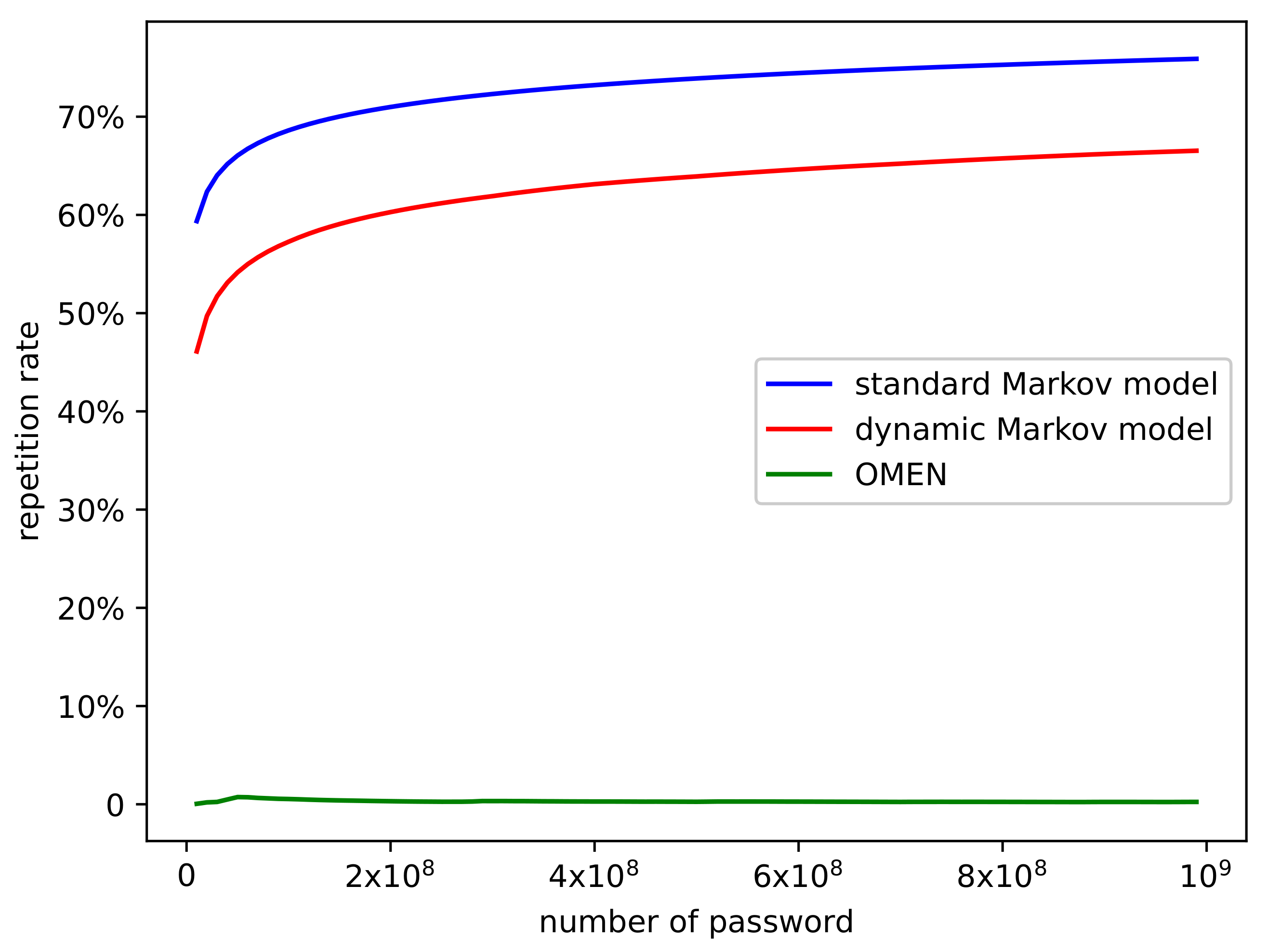
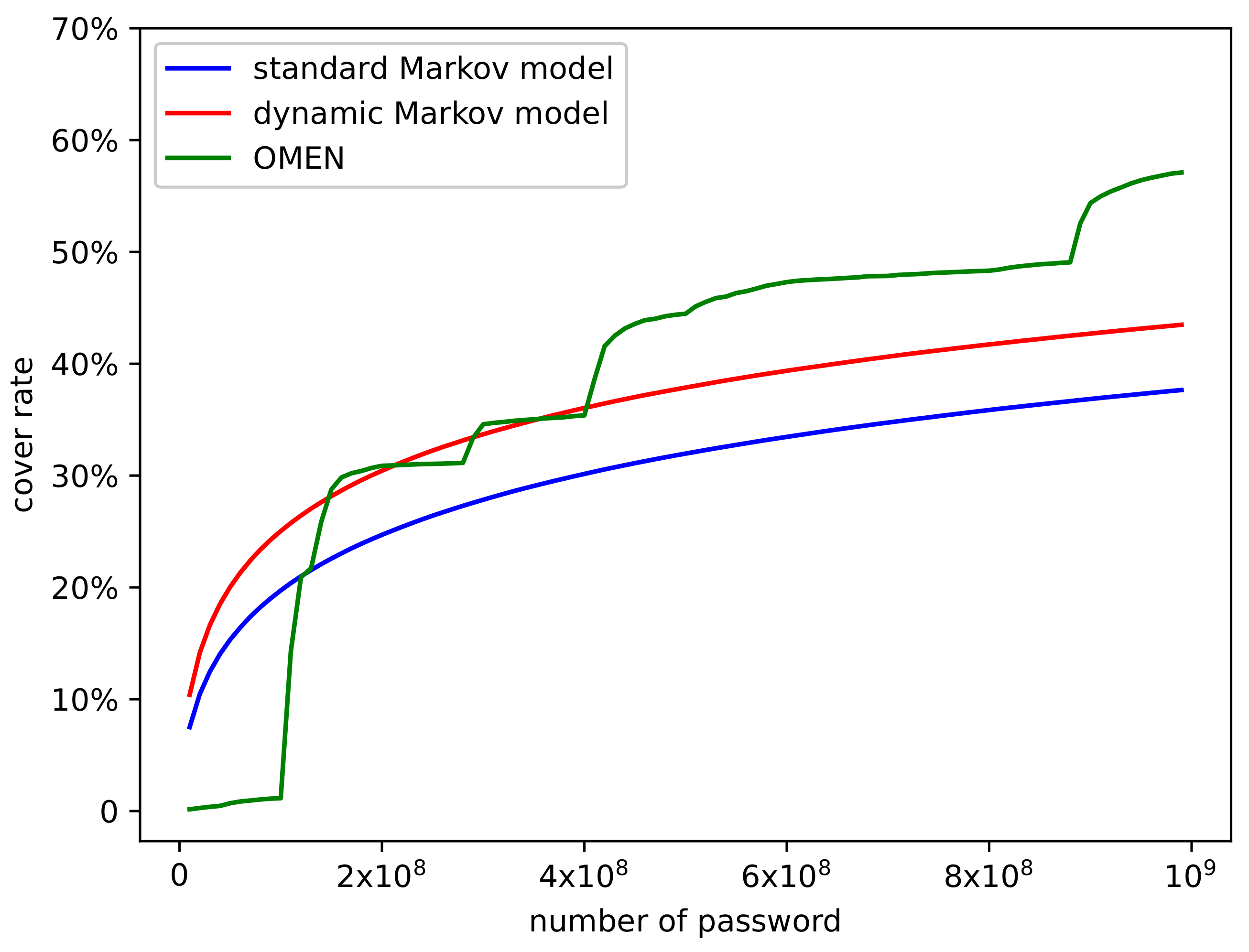
4.2. Comparison of Performance
Then, we compare our model’s performance with the standard Markov model and OMEN. In the RockYou dataset, we selected the best parameter
as
in the dynamic Markov model. We trained these models, generated
passwords, and calculated the
and
values. The experimental results are shown in
Figure 6 and
Figure 7.
The experimental results show that with the help of the dynamic distribution mechanism, the performance of the dynamic Markov model surpasses the standard Markov model in all aspects. The cover rate () increases by 5.84% (from 37.65% to 43.49%) and the repetition rate () decreases 9.38% (from 75.88% to 66.50%). Compared with OMEN, there is 13.61% gap in cover rate, and OMEN generates almost no repeated passwords.
Regarding the comparison results of the two random sampling methods, the dynamic Markov model changes the probability distribution continuously in the process of generating passwords, which finally reduces the probability value of high-probability passwords, thus reducing the repetition rate. At the same time, reducing the repetition rate would make more unique passwords appear, and hence improve the cover rate. Additionally, it is hard for an enumeration method (such as OMEN) to produce repeated passwords, therefore the corresponding is almost 0. The mechanism of generating passwords by approximate probability reduction also ensures that the cover is high enough.
4.3. Cover Number in High Probability Passwords
Next, we compare our model’s performance with the dynamic Markov model and OMEN in the high probability range. We again selected the best parameter
as
in the dynamic Markov model. For the test set, we calculated every password’s probability by the n-gram table and divided them into 11 bins in terms of probability. We finally counted the number of hits, and the cover results are shown in
Table 2.
The experimental results show that the dynamic Markov model and the standard Markov model both perform better than OMEN in the high probability range. In ranges of ∼, ∼, ∼, and ∼, random sampling achieves better cover numbers than OMEN. Especially in range ∼, the dynamic Markov model hits more about 16,000 passwords. In the range ∼, the dynamic Markov model still surpasses OMEN, but the standard Markov model fails. In regions with low probability, OMEN outperforms both the standard Markov model and the dynamic Markov model. In addition, the dynamic Markov model always works better than the standard Markov in any region.
Regarding this experimental phenomenon, we have two explanations. First, in the random sampling method, the appearance of a password is directly related to its probability value. When the number of generations is high enough, passwords with high probability will almost certainly arise, but the enumeration method generates passwords in approximately descending order of probability, which inevitably leads to neglect, so the cover number is not as good for high-probability passwords as in the sampling method. Second, based on the appropriate parameter selection, the degree of adjustment is not large, so the dynamic Markov model can not only hit high-probability passwords very well, but also tries more low-probability passwords.
4.4. Comparison of Method Determinism
Finally, we compare the three models from the perspective of algorithm determinism. After training on the RockYou training set, we ran these three generative models five times, generating
passwords each time, then compared the change of total cover rate with the number of times. The experimental result is shown in
Table 3.
When the dynamic Markov model was run five times, the cover rate increases by 13.39% (from 43.49 to 56.88%), which basically reaches the level of OMEN. The standard Markov model also show an improved cover rate when run more times. As for OMEN, it always generates the same password in the same order, in which there is no randomness, so the cover rate remains unchanged.
OMEN is a deterministic algorithm, so increasing the number of run times has no effect on the cover rate. However, the dynamic Markov model and standard Markov model both are stochastic algorithms, and new passwords are generated each time, so the number running of times improves the cover rate. This result also indicates that the dynamic Markov model and OMEN have the same probabilistic model regarding the passwords, but the difference lies in the order and efficiency of password generation.
5. Discussion
In the task of password guessing, the core is to build a generative model that can generate real passwords. The Markov model based on the statistical method is still widely used due to its good generation effect and high efficiency. The standard Markov model uses the random sampling method to generate passwords, which leads to a high repetition rate, thus affecting the cover rate of generated passwords. The Markov model based on enumeration is a deterministic algorithm. It always generates the same passwords in the same order and can be attacked easily in some specific cases. In addition, the cover rate of high-probability passwords by the enumeration method is not as good as the random sampling algorithm.
To address the above problems, we first design a dynamic distribution mechanism for use in the process of password generation. This mechanism continuously decreases the probability value of high-probability passwords, then the distribution of passwords continues to tend to be uniform distribution strictly, so as to achieve the effect of reducing the repetition rate and improving the cover rate. The dynamic distribution mechanism is designed based on the random sampling method, so it can avoid the shortcomings of the deterministic algorithm and enhance the cover effect of high-probability passwords. In addition, considering practical difficulties and generation efficiency, we fine-tune the dynamic distribution mechanism. We successfully apply it to the Markov model, and propose the dynamic Markov model. These changes mainly include the following: (1) randomly choose an n-gram fragment responded distribution to adjust; (2) just verify whether the probability of the n-gram fragment is greater than ; and (3) the adjustment range of probability distribution is limited to some passwords of the support set.
In the dynamic Markov model, the selection of parameter has a significant impact on the performance. A larger parameter setting may not only significantly reduce the repetition rate, but also reduce the cover rate, and a smaller parameter setting may not be able to exert the effect of the dynamic distribution mechanism. By comparing the results of a series of experiments, we selected the optimal value so that it would take into account both the repetition rate and the cover rate. Compared with the standard Markov model, the dynamic Markov model reduced the repetition rate from 75.88 to 66.50% and increased the cover rate from 37.65 to 43.49%. However, the cover rate still had a gap of 13.61% compared to OMEN. Through the analysis of the cover number of high-probability passwords, we find that the generation algorithm based on random sampling has better results than the method based on enumeration (OMEN), and the dynamic Markov model performed better than the standard Markov model every time. The dynamic Markov model is a random algorithm, and every password is generated randomly, while the deterministic algorithm (OMEN) does not contain any randomness and can be attacked easily. In addition, considering the effects of multiple password generation, the dynamic Markov model could achieve almost the same cover rate as OMEN.
6. Conclusions
In this work, we propose a dynamic distribution mechanism to control the repetition rate of password generation, and apply it to the Markov model based on random sampling. This model can reduce the repetition rate and improve the cover rate. Compared with the enumeration method, the algorithm keeps the advantage of randomness, and further improves the cover of high-probability passwords.
This work inspires us to improve the effectiveness of the password generative model from the perspective of reducing the repetition rate, that is, to optimize the generation efficiency as much as possible by adjusting the password probability distribution close to uniform distribution. This general idea may play a role in other password generative models. In the next research, in order to further improve the cover rate, we will consider other types of dynamic distribution mechanisms, and conduct statistical research on them, and we will also study some methods to speed up the dynamic Markov model.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}