
Semantic Structure from Motion for Railroad Bridges Using Deep Learning



Abstract
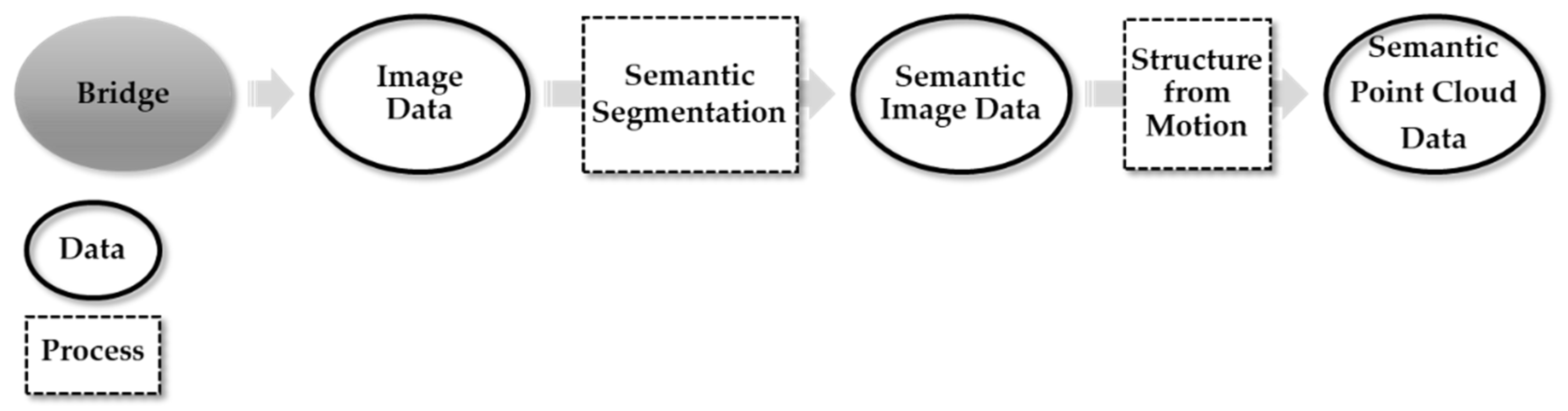
1. Introduction
2. Background
2.1. Semantic Segmentation Using Deep Learning
2.2. SfM
3. System Development
3.1. Bridge Component Classification Using Semantic Segmentation
3.2. Construction of 3D PCD Using SfM
4. Validation Test
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Yoon, H.; Elanwar, H.; Choi, H.; Golparvar-Fard, M.; Spencer Jr, B.F. Target-free approach for vision-based structural system identification using consumer-grade cameras. Struct. Control Health Monitor. 2016, 23, 1405–1416. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Narazaki, Y.; Hoskere, V.; Hoang, T.A.; Fujino, Y.; Sakurai, A.; Spencer, B.F., Jr. Vision-based automated bridge component recognition with high-level scene consistency. Comput. Aided Civ. Infrastruct. Eng. 2020, 35, 465–482. [Google Scholar] [CrossRef]
- Lee, J.H.; Park, J.J.; Yoon, H. Automatic bridge design parameter extraction for scan-to-BIM. Appl. Sci. 2020, 10, 7346. [Google Scholar] [CrossRef]
- Park, G.; Hong, K.-N.; Yoon, H. Vision-based structural FE model updating using genetic algorithm. Appl. Sci. 2021, 11, 1622. [Google Scholar] [CrossRef]
- Park, T.S.; Park, H.S. The current status and facilitation strategy of BIM for civil infrastructure projects. J. Korean Soc. Civ. Eng. 2018, 38, 133–140. [Google Scholar]
- Kim, S.-W. Overseas BIM cases and effective use method of BIM. Railw. J. 2018, 21, 129–135. [Google Scholar]
- Ilter, D.; Ergen, E. BIM for building refurbishment and maintenance: Current status and research directions. Struct. Surv. 2015, 33, 228–256. [Google Scholar] [CrossRef]
- Bosché, F.; Ahmed, M.; Turkan, Y.; Haas, C.T.; Haas, R. The value of integrating scan-to-BIM and scan-vs-BIM techniques for construction monitoring using laser scanning and BIM: The case of cylindrical MEP components. Autom. Constr. 2015, 49, 201–213. [Google Scholar] [CrossRef]
- Wang, Q.; Guo, J.; Kim, M.-K. An application oriented scan-to-BIM framework. Remote Sens. 2019, 11, 365. [Google Scholar] [CrossRef]
- Bao, S.Y.; Savarese, S. Semantic Structure from Motion. In Proceedings of the CVPR 2011, IEEE, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2025–2032. [Google Scholar]
- Abbondati, F.; Biancardo, S.A.; Palazzo, S.; Capaldo, F.S.; Viscione, N. I-BIM for existing airport infrastructures. Transp. Res. Proc. 2020, 45, 596–603. [Google Scholar] [CrossRef]
- Biancardo, S.A.; Viscione, N.; Oreto, C.; Veropalumbo, R.; Abbondati, F. BIM Approach for Modeling Airports Terminal Expansion. Infrastructures 2020, 5, 41. [Google Scholar] [CrossRef]
- Abbondati, F.; Biancardo, S.A.; Sicignano, G.; De Oliveira, S.G.; Tibaut, A.; Dell’Acqua, G. BIM Parametric Modelling of a Railway Underpass. Ingegneria Ferroviaria 2020, 6, 443–459. [Google Scholar]
- Abbondati, F.; Oreto, C.; Viscione, N.; Biancardo, S.A. Rural Road Reverse Engineering Using BIM: An Italian Case Study. In Proceeding of the International Conference on Environmental Engineering, Vilnius, Lithuania, 1–2 August 2020; Volume 11, pp. 1–7. [Google Scholar]
- Ullman, S. The interpretation of structure from motion. Proc. R. Soc. Lond. Ser. B Biol. Sci. 1979, 203, 405–426. [Google Scholar]
- Jiang, R.; Jáuregui, D.V.; White, K.R. Close-range photogrammetry applications in bridge measurement: Literature review. Measurement 2008, 41, 823–834. [Google Scholar] [CrossRef]
- Kwiatkowski, J.; Anigacz, W.; Beben, D. Comparison of Non-Destructive Techniques for Technological Bridge Deflection Testing. Materials 2020, 13, 1908. [Google Scholar] [CrossRef]
- Gawronek, P.; Makuch, M.; Mitka, B.; Gargula, T. Measurements of the Vertical Displacements of a Railway Bridge Using TLS Technology in the Context of the Upgrade of the Polish Railway Transport. Sensors 2019, 19, 4275. [Google Scholar] [CrossRef]
- Kwiatkowski, J.; Anigacz, W.; Beben, D. A Case Study on the Noncontact Inventory of the Oldest European Cast-iron Bridge Using Terrestrial Laser Scanning and Photogrammetric Techniques. Remote Sens. 2020, 12, 2745. [Google Scholar] [CrossRef]
- Porras-Amores, C.; Mazarrón, F.R.; Cañas, I.; Villoria Sáez, P. Terrestrial Laser Scanning Digitalization in Underground Constructions. J. Cult. Herit. 2019, 38, 213–220. [Google Scholar] [CrossRef]
- Kim, H.; Yoon, J.; Sim, S.-H. Automated Bridge Component Recognition from Point Clouds Using Deep Learning. Struct. Control Health Monit. 2020, 27, e2591. [Google Scholar] [CrossRef]
- Liang, X. Image-based Post-Disaster Inspection of Reinforced Concrete Bridge Systems Using Deep Learning with Bayesian Optimization. Comput. Aided Civ. Infrastruct. Eng. 2019, 34, 415–430. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Adv. Ineural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder–Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Sin, H.J.; Yang, J.S.; Song, T.S.; Kwak, N.J. Network analysis according to modified architecture of residual block of ResNet. Korean Inst. Inf. Commun. Eng. 2019, 10, 292–294. [Google Scholar]
- Moghaddam, B.; Lee, J.; Pfister, H.; Machiraju, R. Model-Based 3D Face Capture with Shape-from-Silhouettes. In Proceedings of the 2003 IEEE International SOI Conference. (Cat. No. 03CH37443), Nice, France, 17 October 2003; pp. 20–27. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Amberg, B.; Blake, A.; Fitzgibbon, A.; Romdhani, S.; Vetter, T. Reconstructing High Quality Face-Surfaces Using Model Based Stereo. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded Up Robust Features. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maximum speed | 94 km/h |
| Maximum flight time | Approximately 27 min |
| Maximum service ceiling above sea level | 2500 m |
| Maximum tilt angle | 35° |
| Hovering accuracy (P mode) | Vertical: 0.1 m/Horizontal: 0.3 m |
| Weight | 3440 g |
| Lens | DJI MFT 15 mm/1.7 ASPH |
| Image sensor | CMOS, 4/3 |
| Focal length | 15 mm |
| Image resolution | 5280 × 3956 |
| Field of view | 72° |
| Weight | 461 g |
| Batch size | 5 |
| Epoch number | 500 |
| Optimizer | Adam optimizer |
| Initial learn rate | 0.001 |
| Learn rate drop period | 10 |
| Learn rate drop factor | 0.3 |
| Predicted Class | |||
|---|---|---|---|
| True | False | ||
| Actual class | True | True positive (TP) | False negative (FN) |
| False | False positive (FP) | True negative (TN) | |
| Class | |||
|---|---|---|---|
| Girder | Pier | Average | |
| Accuracy (%) | 85.00 | 76.73 | 80.87 |
| IoU (%) | 80.22 | 53.09 | 66.66 |
| BF-score (%) | 62.49 | 50.17 | 56.33 |
| Class | |||
|---|---|---|---|
| Girder | Pier | Average | |
| Precision (%) | 78.64 | 69.81 | 74.23 |
| IoU (%) | 75.05 | 56.74 | 65.90 |
| BF-score (%) | 59.29 | 51.88 | 55.59 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, G.; Lee, J.H.; Yoon, H. Semantic Structure from Motion for Railroad Bridges Using Deep Learning. Appl. Sci. 2021, 11, 4332. https://doi.org/10.3390/app11104332
Park G, Lee JH, Yoon H. Semantic Structure from Motion for Railroad Bridges Using Deep Learning. Applied Sciences. 2021; 11(10):4332. https://doi.org/10.3390/app11104332
Chicago/Turabian StylePark, Gun, Jae Hyuk Lee, and Hyungchul Yoon. 2021. "Semantic Structure from Motion for Railroad Bridges Using Deep Learning" Applied Sciences 11, no. 10: 4332. https://doi.org/10.3390/app11104332
APA StylePark, G., Lee, J. H., & Yoon, H. (2021). Semantic Structure from Motion for Railroad Bridges Using Deep Learning. Applied Sciences, 11(10), 4332. https://doi.org/10.3390/app11104332