1. Introduction
Highway inventory plays a critical role in highway maintenance and asset management. State departments of transportation (DOTs) and local transportation agencies always need up-to-date inventory data to establish the condition of road networks, prioritize reconstruction and repair work, and evaluate highway assets [
1]. Traffic signs, as important highway inventory, play an imperative role in road safety and efficiency by giving instructions or providing information to drivers or autonomous vehicles.
Based on the sensing platform, existing highway inventory methods can be classified into two categories: ground-based and air- or space-based methods [
1]. Ground-based methods include field inventory, photo/video log, integrated global positioning system (GPS)/global information system (GIS) mapping, terrestrial light detection and ranging (LiDAR), and mobile LiDAR. Air-based methods include aerial/satellite photography and airborne LiDAR. Each method has its advantages and limitations. Recent studies show that the total cost of aerial mapping is much lower than other methods considering the time and personnel needed for large-area inventories (e.g., a whole state highway inventory). As unmanned aerial vehicles (UAVs) become more easily accessible and inexpensive, it is likely that the aerial mapping methods for road inventory will become even less expensive and more efficient in the future.
Here, we introduce several air-based traffic sign detection methods for different types of data captured by different types of sensors. Two common categories of these methods utilize images and light detection and ranging (LiDAR) data. Here, we briefly review several representative approaches that use camera images and LiDAR data.
Several image-based methods have been introduced in recent years to detect and recognize traffic signs. For instance, Soheilian et al. [
2] introduce a multi-view constrained 3D reconstruction algorithm, which incorporates color information of traffic signs in imagery data and provides an optimum 3D silhouette for traffic sign detection. Adam and Ioannidis [
3] propose to train a support vector machine (SVM) classifier using histogram of oriented gradient (HOG) to detect traffic signs. Khalid et al. [
4] extract traffic sign candidates by enhancing the red and blue channel of RGB images based on the assumption that most of the signs are available in these two colors. They further train a SVM-k-nearest neighbor classifier to extract traffic signs among the candidates. Despite the favorable performance of these image-based algorithms, visual features of traffic signs such as color, shape, and appearance are often sensitive to illumination conditions, angles of view, etc.
Recently, researchers have proposed various methods utilizing LiDAR technology for traffic sign detection. However, the number of published work in this aspect is relatively small. Most of these methods use mobile light detection and ranging scanning (MLS) data since they usually have better quality and density than airborne LiDAR. As one of the pioneer works, Pu et al. [
5] initially classify the data points to three major categories such as ground surface, objects located on the ground, and objects off the ground. They further incorporate geometrical features including size, shape, and orientation to extract traffic signs from on-ground points. Yokoyama et al. [
6] propose to utilize principal component analysis (PCA) to distinguish pole like objects from planar ones in MLS data. In addition, they classify pole like objects into three classes, namely, utility poles, lamp posts, and street signs. Yu and Li [
7] eliminate ground points using a voxel-based upward growing method. They then cluster and segment off-ground points into individual objects via Euclidean distance clustering and voxel-based normalized cut segmentation. Riveiro et al. [
8] propose to find an optimized intensity threshold in order to segment points corresponding to traffic sign panels. They further perform a contour recognition for each sign using a linear regression model based on a raster image. Lehtomaki et al. [
9] utilize prior information to eliminate ground and building points. They then segment the remaining data to different categories based on local descriptor histogram (LDH), spin images, and geometrical features. Javanmardi et al. [
10] detect high elevated objects located on top or border of the road in MLS point cloud and cluster these high elevated objects to traffic sign and light pole classes. They further introduce a modified seeded region growing algorithm to remove noisy points and incorporate shape information to filter out false objects from both classes. These aforementioned methods use the 3-dimensional information or reflectiveness of traffic signs to detect various objects. However, their detection efficiency and effectiveness on airborne LiDAR data is degraded due to its low quality resulted from a large number of outliers and different angles of view.
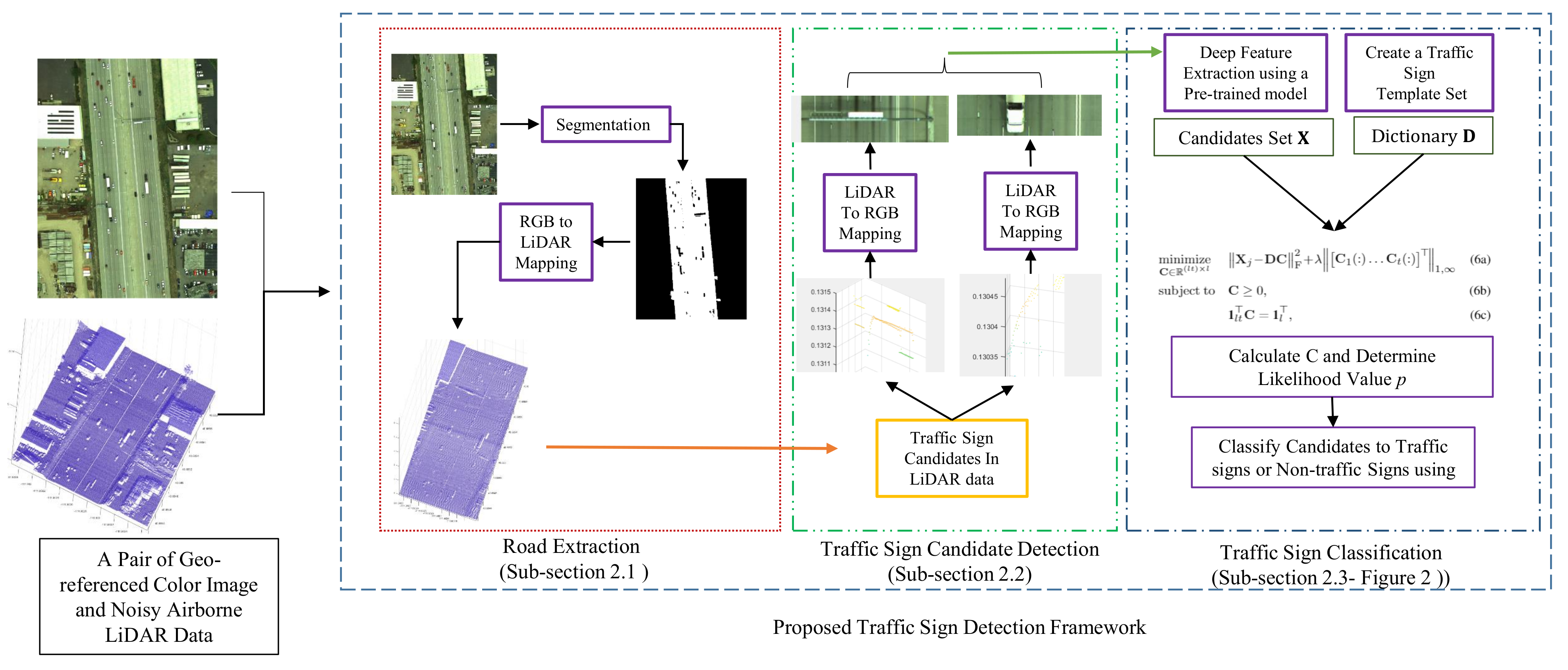
To achieve the maximum level of accuracy and completeness, we propose to develop a data fusion approach that utilizes both aerial LiDAR and aerial imagery data to address the limitations of both image-based and LiDAR-based methods. Unlike other methods [
9,
10], which detect traffic signs using high resolution MLS data, the proposed method detects traffic sign candidates in airborne LiDAR data, which tend to be more noisy than MLS data and easier and faster to collect. It also represents traffic sign candidates in a convex optimization model in color imagery data to classify candidates as traffic or non-traffic signs at a higher accuracy. Specifically, we first segment the airborne color images to road and non-road segments by integrating various local features in an inequality constraint quadratic optimization model. Next, we find the corresponding road regions in LiDAR data and use the height information to extract high elevated objects above the road. We then use Euclidean distance-based clustering to segment extracted objects into traffic sign candidate regions. Finally, we find the corresponding traffic sign candidate regions in color images and extract their convolutional neural network (CNN) features in a new convex optimization framework to classify them as traffic signs or non-traffic signs. The main contributions of the paper are as follows:
Incorporating various local features extracted from color imagery data in an inequality constraint quadratic optimization model and numerically solving the model using the accelerated proximal gradient (APG) method.
Adopting Euclidean distance-based clustering to classify high elevated objects in LiDAR data to several object candidates.
Developing a convex optimization model in color imagery data to classify object candidates as traffic or non-traffic signs.
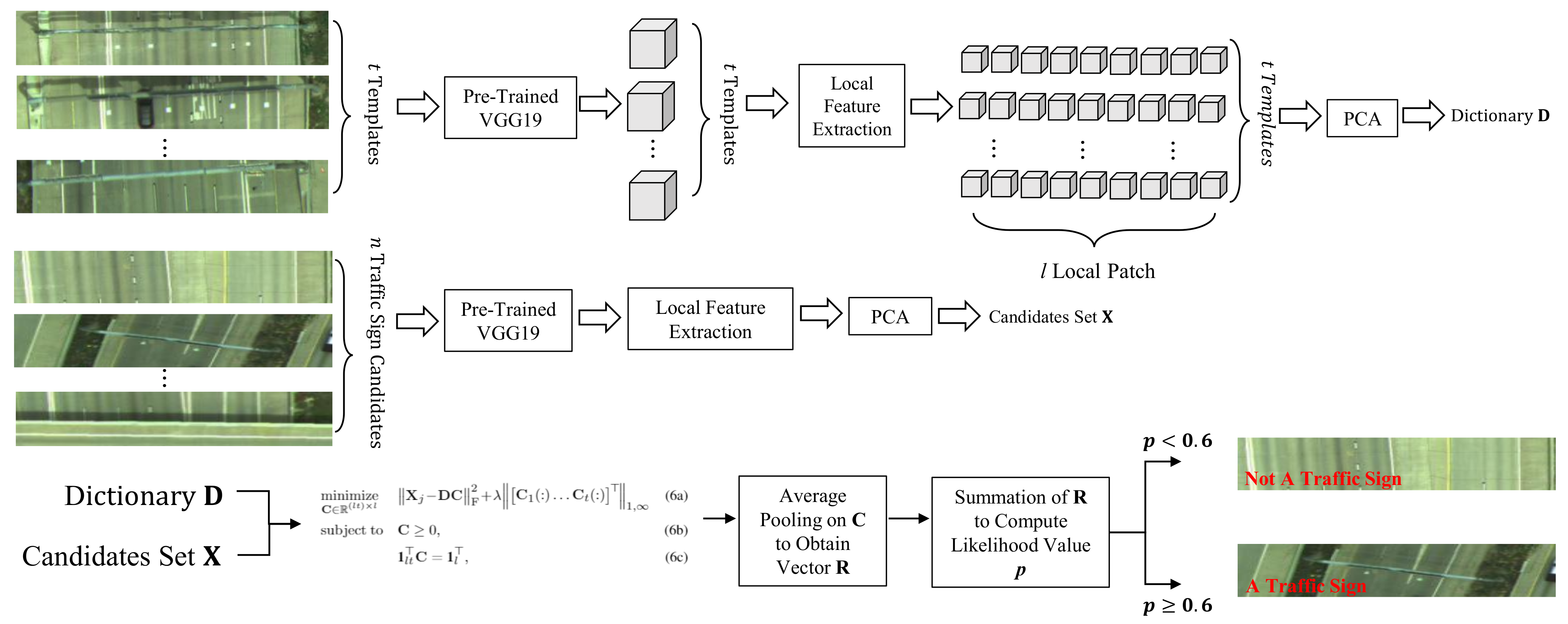
Seamlessly combining the CNN features of local patches of each object candidate with a group-sparsity regularization term to encourage the classifier to sparsely select appropriate local patches of the same subset of templates.
Designing a fast and parallel numerical algorithm by deriving the augmented Lagrangian of the optimization model into two close-form problems: the quadratic problem and the Euclidean norm projection onto probability simplex constraints problem.
The remainder of this paper is organized as follows:
Section 2 describes the three main components of the proposed method in detail. These three components are road extraction, traffic sign candidate detection, and traffic sign classification.
Section 3 presents experimental results and demonstrates the effectiveness of the proposed method to utilize information captured from geo-referenced color images and noisy airborne LiDAR data provided by Utah State University (USU) for Utah DOT (UDOT) along I-15 highway.
Section 4 draws the conclusions.
3. Experimental Results
We evaluated the performance of the proposed local deep-features-based traffic sign detection method by conducting various experiments on 20 sections of multiple pairs of airborne color images and noisy LiDAR data collected from I-15 highway located in Utah, United States (e.g., I-15 North mileposts 284 to 307 and I-15 South mileposts 241 to 260). Airborne LiDAR data were collected by the Remote Sensing Service Laboratory (RSSL) at Utah State University (USU). The USU airborne LiDAR system was mounted in a single engine Cessna TP206 aircraft. The system consisted of a LiDAR scanner, inertial measurement unit (IMU), and flight navigation unit. This LiDAR instrument was composed of a Riegl Q560 transceiver and Novatel SPAN LN-200 GPS/IMU positioning and orientations system. Depending on the flight height, the LiDAR scanner could collect data at a pulse rate of 250,000 shots/s. The beam divergence was less than 0.5 mrad, which allows the LiDAR scanner to have a footprint of about 0.5 m at flight height of 1000 m above ground level (agl). Each section of the roads of interests was divided into multiple subsections, with each covered by a single flight line. The data were acquired at an average flight height of approximately 500 m agl or lower. The LiDAR scan rate was about 125 Hz, the pulse rate was 200,000 shots/s, and the average flight speed was about 180 km/h. In these settings, the point density of the LiDAR data could be up to 6.2 points/m
[
1].
The UDOT provided the locations of traffic signs for each dataset. We used these locations to find the corresponding regions in the color images and cropped them as ground-truth for traffic signs. The quantitative evaluation of the proposed method was based on the traffic sign locations provided by the UDOT. If the detection result and the ground truth overlap, we considered it as true positive. It should be also noted that the data in the collected 20 sections contained different traffic flows since it was collected along the I-15 highway for 40 miles. It would be nice to collect data under multiple conditions including different traffic flows, different days and times, and different weather conditions to thoroughly test the performance of the proposed method. However, collecting data under these circumstances takes time and effort.
In
Section 3.1, we provide road extraction results on 20 sections of the road on color images. In
Section 3.2, we provide traffic sign candidate extraction and classification results on the same 20 sections of the road. Due to the lack of space, we qualitatively show eight representative sections of the road and present the quantitative results of all 20 sections for evaluation. In
Section 3.3, we compare the performance of the proposed traffic sign detection method with several state-of-the-art methods.
3.1. Road Extraction Results
To evaluate the performance of the proposed road extraction method, we conducted extensive experiments on 20 sections of the road. Each section section(i) (
) contained different kinds of objects such as road, buildings, vegetation, parking lots, etc.
Figure 3 demonstrates
section(1) of a geo-referenced color image of the dataset that contains objects such as road, vehicles, building, and vegetation commonly seen on a highway.
We generated six feature matrices from over-segmented regions [
27] of the input image on six sets of complementary layers [
11], which represented the input image from different perspectives. The six sets of layers included color layers of CIE-LAB and
color spaces, gradient layers of Gaussian and Laplacian of Gaussian, soft segmentation layers [
28] of first three principal components, a texture layer [
29], a combined color and soft segmentation layer, and a combined color, gradient, soft segmentation, and texture layer. We then extracted local spectral histogram (LSH) for image pixels from each of the six layers. A feature vector by averaging features of all pixels within a region represented characteristic features of the region. The feature vectors for each over-segmented region were combined to construct the corresponding feature matrix. For the last step of road and non-road extraction, we extracted the aforementioned local features for
pixels in road regions and construct the road dictionary. Similarly, we built the non-road dictionary by extracting the local features for
pixels in non-road regions. For all experiments, we set
in (
3a) as 10 to control the smoothness of the result.
We qualitatively demonstrated road extraction results on four sections of the road (i.e.,
section(1),
section(2),
section(3), and
section(4)) in
Figure 4 and another four sections of the road (i.e.,
section(5),
section(6),
section(7), and
section(8)) in
Figure 5. The
section(1) and
section(2) in
Figure 4 demonstratde the conditions with low traffic flows while
section(7) and
section(8) in
Figure 5 demonstrated the conditions with high traffic flows. The
section(6) and
section(8) in
Figure 5 had road bypass with vegetation in between. The
section(1),
section(3), and
section(4) in
Figure 4 had buildings along the road and
section(2) had the highest vegetation along the road among all the demonstrated sections. The road extraction results for all sections shown in
Figure 4 and
Figure 5 clearly demonstrated the robustness of the proposed method in extracting road regions under multiple conditions including different traffic flows, different road-side buildings, various road shapes, and various road-side objects (i.e., vegetation, building, and parking lot).
To demonstrate the effectiveness of the last learning step of the road extraction method, we further compared road extraction results with the results without involving learning on 20 sections of airborne color images.
Figure 6 compares road extraction results before employing the last learning step and after employing the last learning step for four selected sections, namely,
section(1),
section(3),
section(5), and
section(7). The results before learning (BL) clearly showed that buildings, parking lots, and vegetation regions were part of road extraction results since they were similar to the road. The results after learning (AL) showed that with the help of the learning step, the proposed road extraction method effectively identified the road region and removed buildings, parking lots, and vegetation regions that were similar to the road region. These comparison results showed the effectiveness of using the optimization with equality constraints to remove objects that were similar to the road from the extraction results (i.e., to better classify a pixel as road or non-road).
3.2. Traffic Sign Candidate Detection
and Classification Results
To evaluate the performance of the proposed traffic sign candidate detection and classification method, we conducted extensive experiments on the same 20 sections of the road.
Figure 7 presents extracted road regions in both color images and their associated LiDAR data for four selected regions, which were cropped from the sections of the road for better illustration purpose. In each row, we demonstrate the color image of one of four cropped sections of the road and its corresponding road extraction results alongside with its associated geo-referenced LiDAR data and its corresponding road extraction results. It should be mentioned that these four sections contained various objects including the road, buildings, parking lots, vegetation, traffic signs, billboards, and bridges to illustrate the effectiveness of traffic sign detection results.
Figure 7 clearly shows that road regions extracted from color images were correctly mapped to the corresponding road regions in the LiDAR data by employing the image to global coordinate projection. Since it is much easier to extract road regions in a color image using complementary features, we utilized road extraction results in color image to quickly find road regions in LiDAR data.
Utilizing a histogram to obtain height statistics, we could quickly remove high elevated objects above the road to find traffic sign candidates in the LiDAR data.
Figure 8 demonstrates traffic sign candidates that were extracted from road regions presented in
Figure 7, where each row shows extracted traffic sign candidates for each section of the road. These candidates were fed into the sparse classifier optimization model to be classified to a traffic sign class or a non-traffic sign class by empirically setting the parameter
p to be 0.6 as shown in
Figure 2. We labeled the classification result of each traffic sign candidate at the bottom left of each airborne color image with “TS” indicating a traffic sign and “NTS” indicating a non-traffic sign.
To quantitatively evaluate the proposed traffic sign detection method, we provided its true positives, false negatives, and true negatives on all the 20 sections of the dataset containing 17 traffic signs in total. The proposed method extracted 24 traffic sign candidates by removing high elevated objects above the road in the LiDAR data. The deep-features-based sparse classifier correctly classified 14 out of 24 candidates as traffic signs (true positives), incorrectly classified three out of 24 candidates as non-traffic signs (false negatives), and correctly classified seven out of 24 candidates as non-traffic signs (true negatives). In other words, the proposed method was able to successfully extract 14 out of 17 traffic signs and achieved the detection accuracy of 82.35%. We further provided four evaluation measures including recall (detection rate), precision,
-measure, and quality in
Table 1. These measures were computed as follows:
It shows that the proposed method achieved an average precision of 82.35%, a recall of 100%, a -measure of 90.32%, and a quality of 82.35%. This performance is attributed to the use of the optimization with equality constraints to more accurately classify a pixel as road or non-road, the use of deep features to more accurately representing the visual data of candidates, and the use of the sparse classifier optimization model to more accurately classify each candidate as traffic sign or non-traffic sign.
3.3. Comparison with Other Methods
Extracting road and detecting traffic signs along the road in one source of the input (i.e., LiDAR data or color images) is not straightforward. For instance, it is challenging to segment 3D LiDAR data and extract road from the segments mainly due to high level of noise. It is also challenging to detect traffic signs due to their low density in the airborne LiDAR data. We implemented the method proposed in [
30] to segment the road in LiDAR data and the method proposed in [
31] to identify traffic signs along the road in LiDAR data. To this end, we extracted 3D hand-crafted features [
30], namely, normal vectors and principal curvatures, to segment road in our airborne LiDAR data. We obtained inaccurate segmentation results, which contained many of the parking lot areas along the road, due to similar normal vectors and curvatures for parking lots and road. We further extracted 3D deep features [
31] to segment and classify traffic signs in our airborne LiDAR data. We obtained inaccurate segmentation and classification results since 3D deep features capture a lot of noise in the data. On the other hand, traffic signs appeared with low density in our airborne LiDAR data. As a result, they did not form any recognizable shape and were difficult to be detected as any solid objects. Our experimental results on the airborne LiDAR data showed that seven non-traffic signs were detected as traffic signs. These seven non-traffic signs could be easily filtered out if we fused the complementary information from both color images and LiDAR data.
Similarly, detecting traffic signs in airborne color images is also challenging since the height and shape information of traffic signs is missing in the 2D data. We cannot compare the performance of other methods of detecting traffic signs in color images with ours since they do not process airborne color images, where traffic signs do not exhibit any rectangular shapes.
To the best of our knowledge, there is no research working on registered airborne geo-referenced color images and airborne LiDAR data to detect traffic signs. Therefore, we cannot compare the proposed method with state-of-the-art methods in this regard. In addition, comparing the performance of the proposed method with the performance of previous studies on the same dataset is challenging due to the differences in datasets and the variation of the defined tasks. For instance, one method working well on a high density MLS point cloud collected from a city area may not obtain a good performance on airborne LiDAR data collected from highway and vice versa. This is mainly due to different scan angles of objects, point cloud density, and noise level. Instead, we compared the performance of the proposed method with several traffic sign detection methods that worked with either LiDAR data or color images to demonstrate the effectiveness of the proposed fusion technique. We chose four methods [
5,
9,
10,
32], to compare their performance of detecting traffic signs in the LiDAR data with ours. However, this comparison was difficult due to the difference of datasets in terms of the quality, density, and distribution of the point clouds, areas (city vs. highway) where the data were collected from, and the data source (mobile LiDAR vs. airborne LiDAR). In [
32], the authors report a recall rate of 65% and a precision rate of 58% for 60 traffic signs. A recall of 60.81% and a precision of 95.74% are reported in [
5]. Lehtomäki et al. [
9] report a recall of 65.96% and a precision of 93.94%. Javanmardi et al. [
10] report a performance of 94.48% and 84.04% in terms of recall and precision, respectively. Our proposed fusion method achieved 100% recall and 82.35% precision. Specifically, it correctly detected 14 out of 17 traffic signs. The proposed method outperformeed [
32] in term of precision rate and achieved the highest recall rate among the compared methods.
4. Conclusions
In this paper, we utilize information captured from airborne geo-referenced color images and noisy airborne LiDAR data to fuse the complementary information and accurately detect traffic signs. Our designed method includes three major steps: (1) road extraction, (2) traffic sign candidate detection, and (3) traffic sign classification. Six joint local features are seamlessly incorporated in the aggregation optimization model to accurately identify the road region in color images. Histogram of height information is utilized along the road region in the LiDAR data mapped by the image to global coordinate projection to detect traffic sign candidates. Local deep features are also incorporated in the sparse representation-based optimization model to accurately identify traffic sign candidates in color images mapped by the global to image coordinate projection. Both qualitative and quantitative results show the effectiveness of the proposed method to detect traffic signs. Some of the important findings are summarized as follows:
Using the complementary information from color images and airborne LiDAR data improves the accuracy of traffic sign detection.
Extracting road regions is an essential initial step, which significantly reduces the search space for traffic signs to improve the detection efficiency.
Representing local deep features in a sparse representation-based local-embedded optimization model helps to capture the local structure of traffic signs for more accurate classification.
With the advent of unmanned aerial vehicle (UAV) technology, high-resolution aerial images and LiDAR data will be much more affordable and easily accessible for transportation agencies in the future. Although the current data set was collected with a fixed-wing plane, the methodology developed for the current data set will be readily transferable to any UAV-based data collection platform.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}