1. Introduction
The surge of social networks, full of opinions about all possible kinds of objects, has provoked a strong change in decision making. Preferences, prices and other criteria are still very relevant; however, the weight of the opinion of other users is certainly growing [
1,
2,
3]. Some studies show that a large majority of people reads public reviews on the Web before buying any object [
4,
5]. Reviews are very important to know the quality of the products and services offered by a company; for example, a restaurant may advertise that it offers a free WiFi service, but the reviews may warn us that the connection quality is very low.
It is arguably important to integrate the information about the preferences of the user with the public opinions on the products in a decision support system. The management of preferences in ranking systems [
6,
7] and the automated analysis of the sentiments of texts [
8] have been heavily studied in their respective fields. However, there are not many current works aiming at the integration of both aspects to rank the decision alternatives.
A multiple criteria decision aid (MCDA) [
6] deals with different conflicting criteria, establishing scientific bases to elaborate recommendations according to the needs of decision-makers. Artificial intelligence techniques can be used to elicit and construct a knowledge model for each particular decision-maker.
Sentiment analysis (SA) detects whether the polarity of the opinion of a user in a text is positive or negative. It is commonly applied to online reviews in many different domains [
8,
9,
10]. The techniques of analysis developed in this field may be applied to a whole document, to a sentence or even to a particular aspect in a sentence (aspect-based sentiment analysis, ABSA) [
11]. An aspect refers to a particular characteristic of an object (e.g., the quality of the food in a restaurant), which may be evaluated in a part of a sentence (e.g., “Although the dinner was very expensive, the food was delicious”).
In this work we analyse how to integrate the public opinions of users about a certain set of products in a standard multi-criteria decision support system. To make this integration it is necessary to identify the aspects appearing in the reviews; to obtain the polarity associated with each aspect in each review; to integrate this information as new criteria to be considered in the MCDM process; and finally, to rank the alternatives considering the user preferences, the knowledge about the values of the alternatives in different criteria and the information about the opinions of the users on the Web.
SentiRank is a system that integrates the opinions of the users on a set of products as a new set of criteria to be taken into account in ELECTRE, the well-known MCDM ranking methodology. This paper focuses especially on the aspect-based sentiment analysis task, which involves two main sub-tasks: aspect detection (detect the aspects of an object mentioned in a sentence) and aspect polarity (identify if the opinion about that aspect of the object is positive or negative).
To summarise, the main contributions of this work are the following:
We propose a new sentiment analysis system to obtain the polarity associated with each aspect mentioned in every sentence of a review. First, the relevant aspects of a sentence are detected; after that, a Support Vector Machine (SVM) is employed to calculate the polarity of the opinion of the user for each aspect. The experiments show that this new system has a performance comparable to the one of the current state-of-the-art systems.
We integrate the sentiment information about the aspects as new (social) criteria to be considered, alongside the standard criteria of the domain. Then, we apply ELECTRE-III to rank the alternatives.
We show how the rankings change when social criteria are considered in a use case with restaurant data.
The rest of the article is structured as follows.
Section 2 overviews the state-of-the-art in the fields of SA (specially ABSA) and MCDA.
Section 3 describes the development of the aspect-based sentiment analysis system, the architecture of our ranking system and its implementation details.
Section 4 presents and discusses the experimental results.
Section 5 summarises the article and points out some ideas for future work.
3. Methodology
Figure 2 shows the architecture of SentiRank, the system that has been designed and developed to rank objects using ELECTRE-III, taking into account the preferences of the user on certain domain attributes and the global opinions of users on the Web about the decision alternatives. It is composed by three main modules. The first one is the customers’ reviews unit, which transforms the reviews about alternatives into a matrix of real numbers which we call the social performance table. The second one is the domain analysis unit. It takes as an input the description of the alternatives and the goals of the decision-maker and it converts them to another matrix of real numbers called domain performance table. As soon as we get the output of the two units, we merge them to get the final performance table. Finally, we feed the performance table to the last unit, i.e., the ranking unit, to have the alternatives ranked.
3.1. Customers’ Reviews Unit
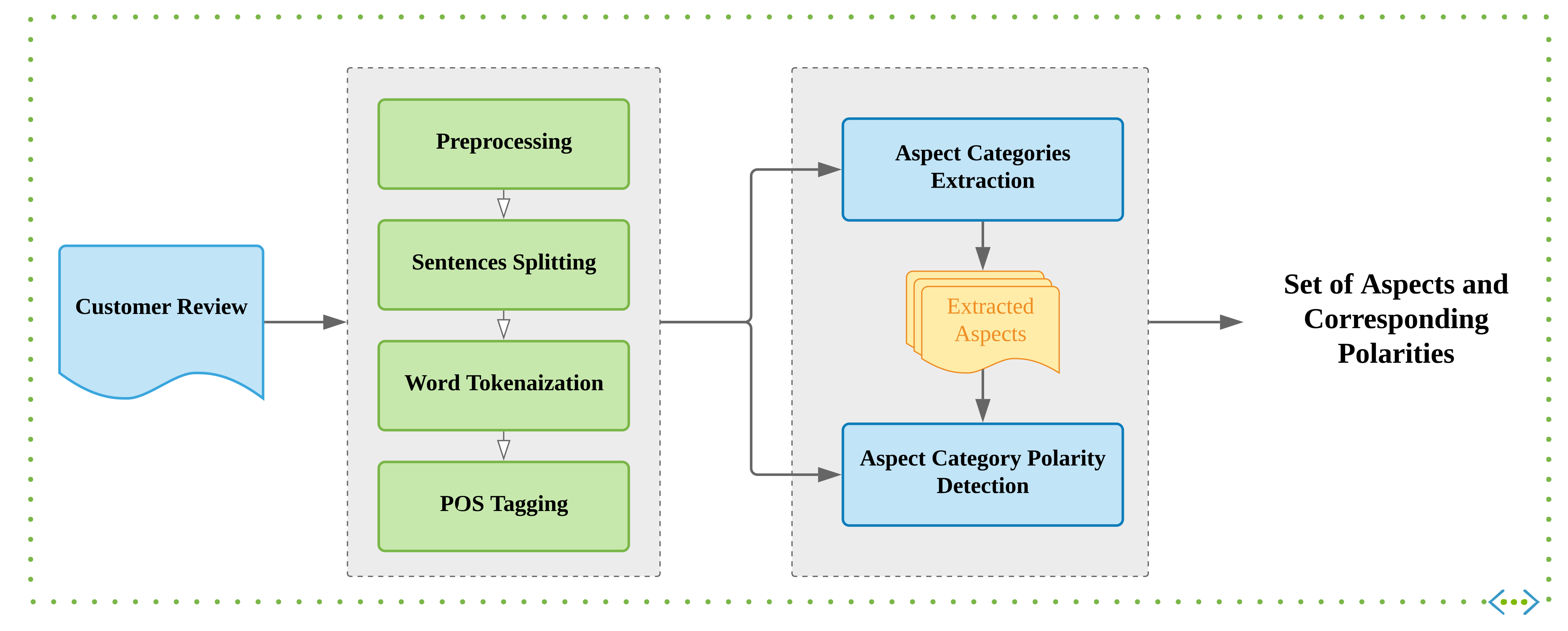
This module receives a set of reviews about a given set of objects. It analyses the aspects mentioned in each review, it determines their polarity, and then it builds the social performance matrix. In this structure each row represents a particular object, and each column corresponds to the one of the detected aspects. As shown in
Figure 3, the first step is to preprocess the text. After that, sentences are separated and tokenised. Then, the aspects mentioned in each sentence are found and their polarity is calculated. All these steps are explained in the following subsections.
3.2. Text Preprocessing
Text preprocessing is an essential step for most text analytics problems, especially for sentiment analysis. It is especially important when the text to be analysed comes from reviews on social media, which tend to be written in an informal way. The following text normalisation steps are applied in SentiRank:
Text is moved to lowercase.
HTML tags are removed.
The URLs are replaced by the <URL> symbol.
The user mentions are replaced by the <USER> symbol.
The emails are replaced by the <EMAIL> symbol.
The dates are replaced by the <DATE> symbol.
The times are replaced by the <TIME> symbol.
The numbers are replaced by the <NUMBER> symbol.
The money is replaced by the <MONEY> symbol.
The text was split into sentences, tokenised and tagged with the Part-Of-Speech (POS), using Stanford’s tokeniser and POS-tagger.
3.3. Extraction of Aspect Categories
A sentence may contain references to several aspects. Thus, finding these aspects may be conceptualised as a multi-label classification problem [
37]. Let
be the instance set and
the aspect set, with dimensions
n and
m respectively. The supervised multi-label data set
D can be defined as follows:
We use the binary relevance mechanism [
37,
38,
39] to solve the multi-label classification problem. The main idea is to transform this problem into several binary problems (one for each aspect), that can be solved by independently trained binary classifiers. In order to train the binary classifier for each corresponding aspect
,
, we first construct the following binary data set:
In this expression,
is a function that returns 1 if
and 0 otherwise.
Figure 4 illustrates the decomposition process.
After that, we build a SVM binary classifier
from each training set
. When the system is given a new sentence
x, the aspects that are associated with it are detected by these binary classifiers. Hence, the function
can be defined as follows:
3.4. Calculation of the Aspect Polarity
In this step the system has to calculate whether the opinion of the user about each aspect of each sentence is positive, negative, neutral or “conflict.” A multi-class Support Vector Machine is trained for each aspect category. In the next section it will be seen how the set of features of each SVM is enlarged with specific knowledge about the aspect category.
We define the aspect polarity detection function
as follows:
In this expression
is the classification support function, and the function PositionMax returns the position of the input vector with the highest value. We summarise the aspect extraction and polarity detection steps in Algorithm 1.
| Algorithm 1: Aspect extraction and polarity detection algorithm. |
 |
3.5. Transforming the Sentiment Information into Social Criteria
In the previous step the system has detected the aspects mentioned in a review and the polarity of the opinion about each of them. In order to integrate this information into a MCDM system, we consider each of the aspects as a social criterion. Thus, we generate a matrix in which each row represents an alternative, and each column is one of the aspects evaluated in the textual reviews. The value for a specific cell is the polarity index [
9], which is a number from 0 to 100 that indicates the positiveness of the opinion of the users’ reviews about a certain aspect for a given alternative. This index is calculated as follows (P and N are the amounts of positive and negative opinions, respectively):
The range of is , so we transform it to by adding 1 and multiplying the result by 50. Thus, 0 is the lowest satisfaction and 100 represents the highest degree of satisfaction. Algorithm 2 illustrates the transformation steps.
3.6. Domain Analysis Unit
As depicted in
Figure 2, this module employs utility functions to transform the values of the domain attributes into numerical values that represent the user’s degree of satisfaction, taking into account his/her preferences. The transformation to be made depends on the type of attribute that is being considered. We have considered three kinds of attributes: numerical, categorical and linguistic. In the case of numerical attributes, they do not need any transformation, as they are already numbers. Features of this kind sometimes have to be maximised (e.g., the social features that indicate the opinion gathered from the reviews on some aspects of an object) and sometimes they have to be minimised (e.g., the distance of a restaurant to the city centre). The utility functions needed in the other two cases are described in the following subsections.
3.6.1. Categorical
The utility function used for categorical attributes is the following:
In this formula U is the set of values preferred by the user and F is the set of values of the attribute for a particular object. Thus, the utility function computes the percentage of preferred values offered by the object, which the user will desire to maximise.
Example: let us have a categorical criterion (e.g., food types served in a restaurant) and let us assume that the user preferences are
and the values provided by an alternative are
; then, the utility value of this alternative given the preferred values is
.
| Algorithm 2: Creation of the social performance table. |
 |
3.6.2. Linguistic
The utility function that is employed by the system to transform linguistic values into numbers is the following:
In this formula L is the set of linguistic terms used in that attribute, the function returns the position of a particular value in this set, p is the term preferred by the user and x is the term appearing in a certain alternative. The utility function returns a number between 1 and the number of terms; the higher this number, the higher the satisfaction of the user with that alternative.
Example: Let us have the price feature represented as a linguistic variable. Let be the linguistic values. Here, is 2. Assuming that the user prefers and the alternative value is , then the utility value of this alternative given the user preference is .
3.7. Ranking Unit
This module receives the performance table (which integrates the domain attributes and the social attributes derived from the sentiment analysis of the reviews) and ranks the alternatives using ELECTRE-III. In order to use this methodology, it is necessary to know the range of values of each attribute, whether an attribute has to be maximised or minimised to satisfy the user, the weight to be given to each attribute and the ELECTRE thresholds of each criterion (preference, indifference and veto). ELECTRE-III compares each pair of alternatives and creates the outranking relations between them; after that, the exploitation step is done to compute the final ranking of the alternatives.
4. Experiments and Results
A set of restaurants from the city of Tarragona was chosen as a use case to test the system, considering users with different preferences. This section is structured as follows. First, we describe in
Section 4.1 the data and the criteria used in this study.
Section 4.2 explains how we built the sentiment analysis models. We show the features that have been used to extract the aspects and to evaluate the polarity of the users’ opinions of them, and the values of the parameters of the employed classifiers. We also show and discuss the performances of the developed models with a publicly available benchmark on the restaurant domain presented in SemEval-2014 [
40]. In
Section 4.5, we show the performance of SentiRank by varying the preferences of the user and analysing the obtained results.
4.1. Data
Table 1 shows all the criteria that define the peculiarities of each restaurant. The domain criteria include the information of the restaurants provided in the TripAdvisor website. The sentiments of the reviews were analysed with respect to five aspect categories, as described in the ABSA task of SemEval-2014: food, price, service, ambience and anecdotes [
40]. The polarities of the reviews on these categories constitute the values of the social criteria.
The models to detect the aspects and determine the polarity of the user’s opinion of them were built and tested using the training and testing sets provided in the ABSA task of the SemEval-2014 competition [
40]. They had 3041 and 800 sentences in English, respectively. Each sentence was labelled with a set of pairs (aspect, polarity). The number of opinions for each aspect and each polarity is shown in
Table 2. Most of the sentences contain positive opinions, and the aspect that received the most opinions was the quality of the food.
4.2. Sentiment Analysis Model: Training Setup
We describe in this subsection the training setup of the aspect extraction and the aspect polarity detection models. We used LIBLINEAR (
https://www.csie.ntu.edu.tw/~cjlin/liblinear/) to build all the linear classifiers. First, we define all the features used in our system, and then we show the configuration of features for each model. After that, we present the evaluation metrics and the performances of the models, and finally we discuss the results on the Tarragona case study.
4.2.1. Features
The features used in our system are the following:
Word n-grams: appearances of consecutive words.
Character n-grams: appearances of consecutive characters.
Part-Of-Speech tags: appearances of each kind of POS.
Lexicon-Based features: A sentiment lexicon associates to a word a number that represents its degree of positiveness/negativity. For each word w and polarity value in a given lexicon l, we calculate the following features: (1) the total score ; (2) the highest value ; (3) the number of positive words in the sentence; (4) the lowest value ; (5) the number of negative words in the sentence, and (6) the value of the last word in the sentence. The lexicons used in this work are the following:
- –
Yelp Restaurant Sentiment Lexicon (Yelp-Res): this lexicon, which contains almost 40,000 unigrams, was created automatically from restaurant reviews contained in Yelp [
41] (
http://www.yelp.com/dataset_challenge).
- –
NRC Hashtag Sentiment Lexicon (NRC-Hashtag): This lexicon was constructed from a pseudo-labelled corpus of tweets [
41]. It contains almost 40,000 unigrams and 180,000 bigrams.
- –
NRC Yelp Word-Aspect Association (WA-Lexicon): It contains lexicons of words associated with the five aspect categories shown in
Table 2, created from over 180,000 reviews in Yelp. Thus, unlike the other lexicons, this one is centred in the aspect categories. The value that represents the relationship between each word and each category was calculated using the PMI metric [
24].
Word Clusters: The CMU POS-tagger (
http://www.cs.cmu.edu/~ark/TweetNLP/clusters/50mpaths2) employed Brown clustering to divide the English words appearing in over 50 million tweets in 1000 clusters. We used the total occurrences of words from each of the clusters as features.
4.2.2. Configurations
Table 3 shows the features employed to build the aspect detection module. Their values were obtained using 5-fold cross-validation.
As suggested in [
24], a domain adaptation mechanism was used to enlarge the features used to train this module. Given an aspect category
a, two copies were made of each word
x. They are called
x#general and
x#a. The former refers to the general use of the word, whereas the latter represents the usage of the word when referring to a particular aspect. In that way, the classifier may learn that a certain word is positive in general (e.g., “splendid”), and it also may learn that a word is positive in a particular context (e.g., “tasty” is a very good word when referring to the quality of food).
As described in
Section 3.2, first the sentences of the reviews are separated into words and POS-tagged. After that, the system calculates all the features mentioned in the previous section, except the n-grams based on characters: word 3-grams (both general and aspect-based), Part-Of-Speech tags and the cluster and lexicon-based features (with the three lexicons mentioned above).
4.3. Evaluation Metrics
To evaluate the module of aspect detection, the standard precision (
P), recall (
R) and F1 measures were used (
S is the set of aspects calculated by SentiRank, and
G is the set of correct aspects of each sentence).
The correctness of the polarity of the opinion with respect to an aspect is measured by the accuracy (correct polarity labels associated with an aspect by the system divided by the number of correct labels).
4.4. Results
Table 4 shows the performance of the aspect detection module for each category. In general, the model shows a very good
value in all the categories. The model gives the best performance in the food and price categories, whereas the worst value appears in the anecdotes category.
SentiRank was also compared with the top three systems in the ABSA task in SemEval-2014 [
40], as shown in
Table 5 and
Table 6. The best values are shown in bold. The results for SentiRank are quite close to the ones of the top system, NRC-Can-2014 [
24], in both tasks.
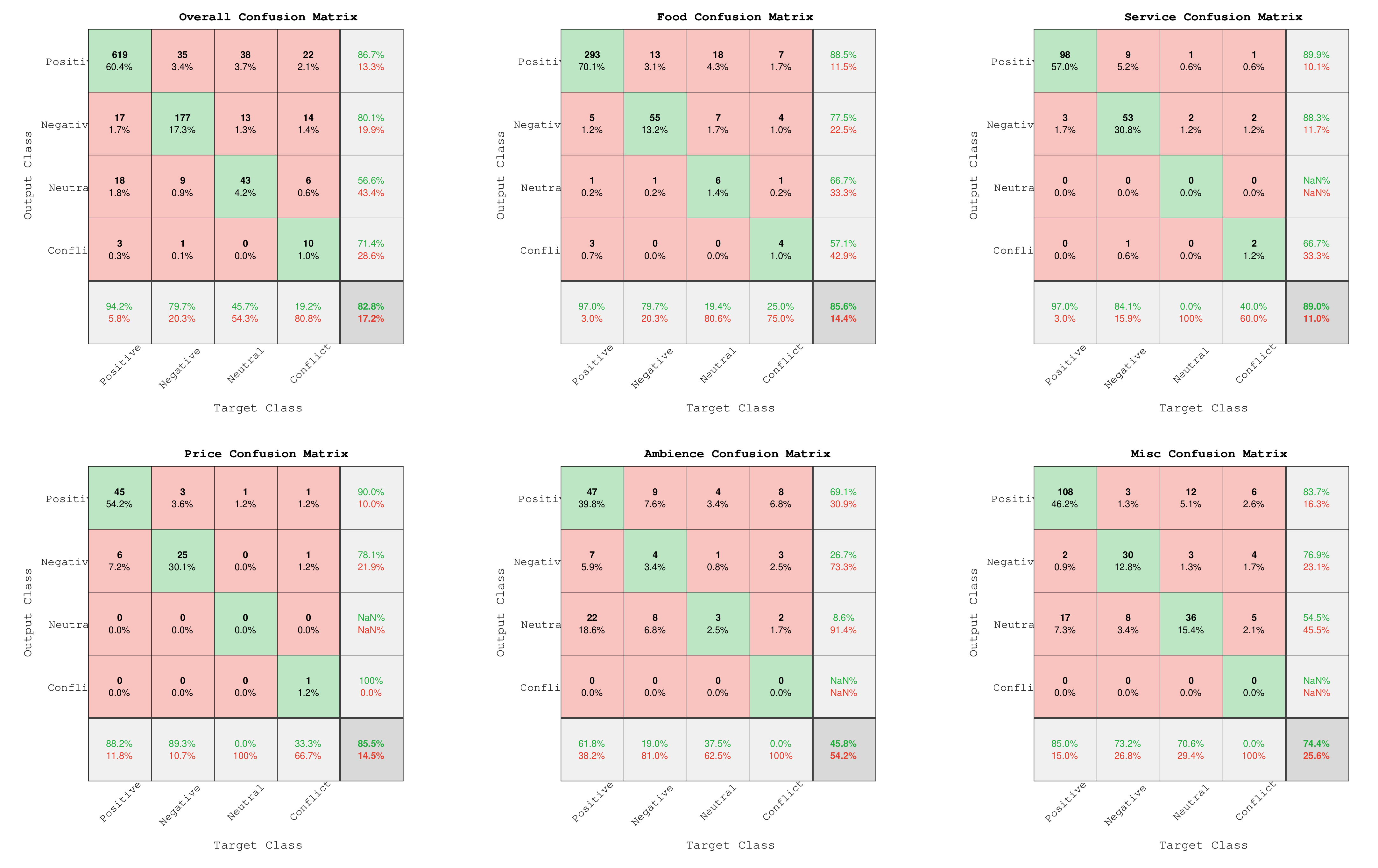
To get more insights into the system’s performance, we analysed the confusion matrices shown in
Figure 5. The figure on the top left is the confusion matrix of the overall score, when we ignore the category and consider only the polarities. The other five figures show the confusion matrices at the category level of analysis. In general the system’s performance is quite good, as 82.8% instances were correctly classified. The best values correspond to the positive and negative classes, whereas the worst ones appear in the conflict and neutral classes, where most samples were misclassified as positive. To understand the performance of the system for each category, we analysed the confusion matrix for each of them. The best performance appeared in the food, service and price categories. The ambience category showed the worst performance, followed by the “Misc” category. Such a finding can be attributed to the low number of training examples for these two categories. As the positive class had the highest number of training samples in all the categories, it showed a remarkable performance in all of them. However, on the other hand, this superiority of the positive examples caused a bias in the classifications and led to a low performance in other categories.
4.5. Case Study
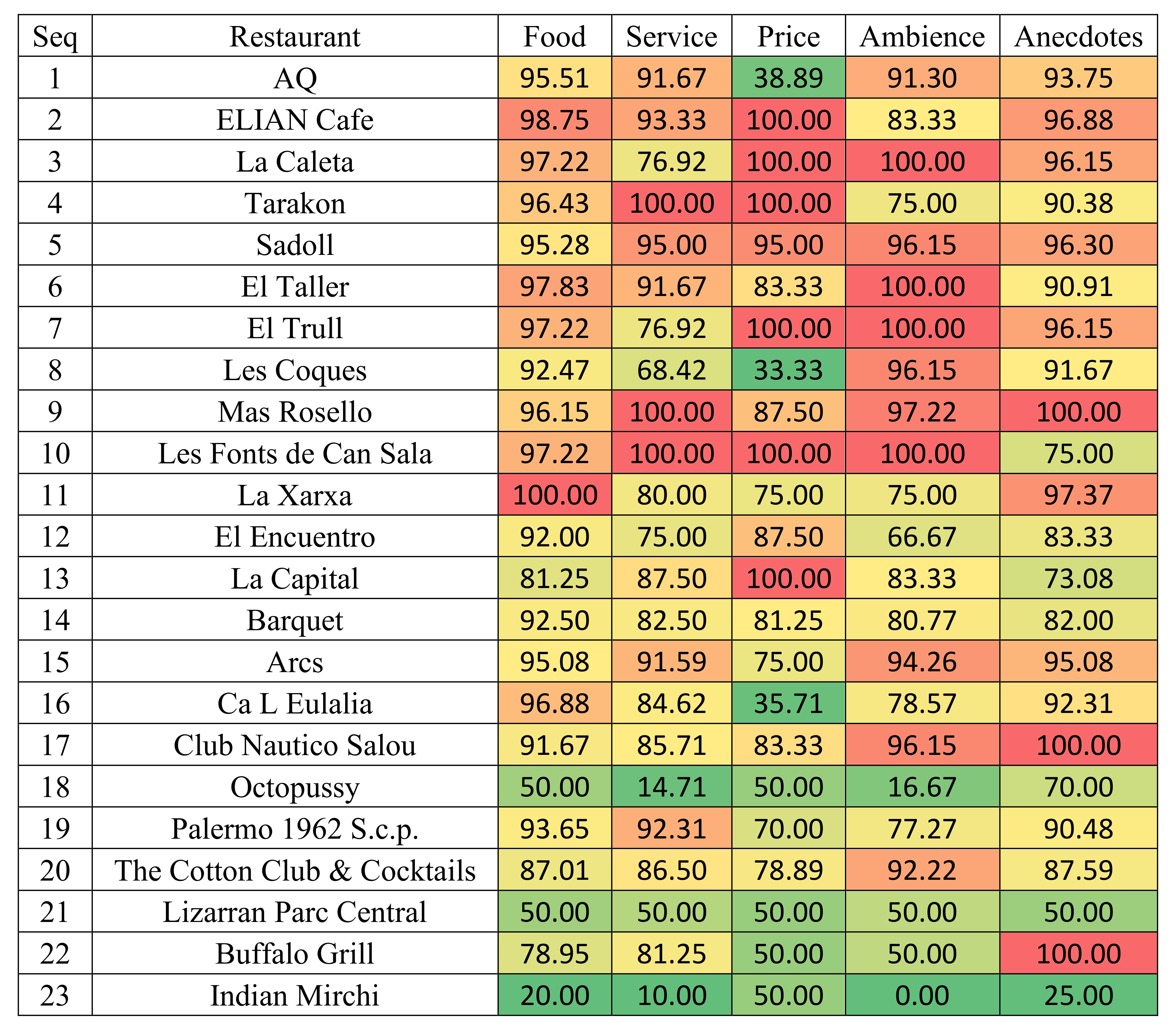
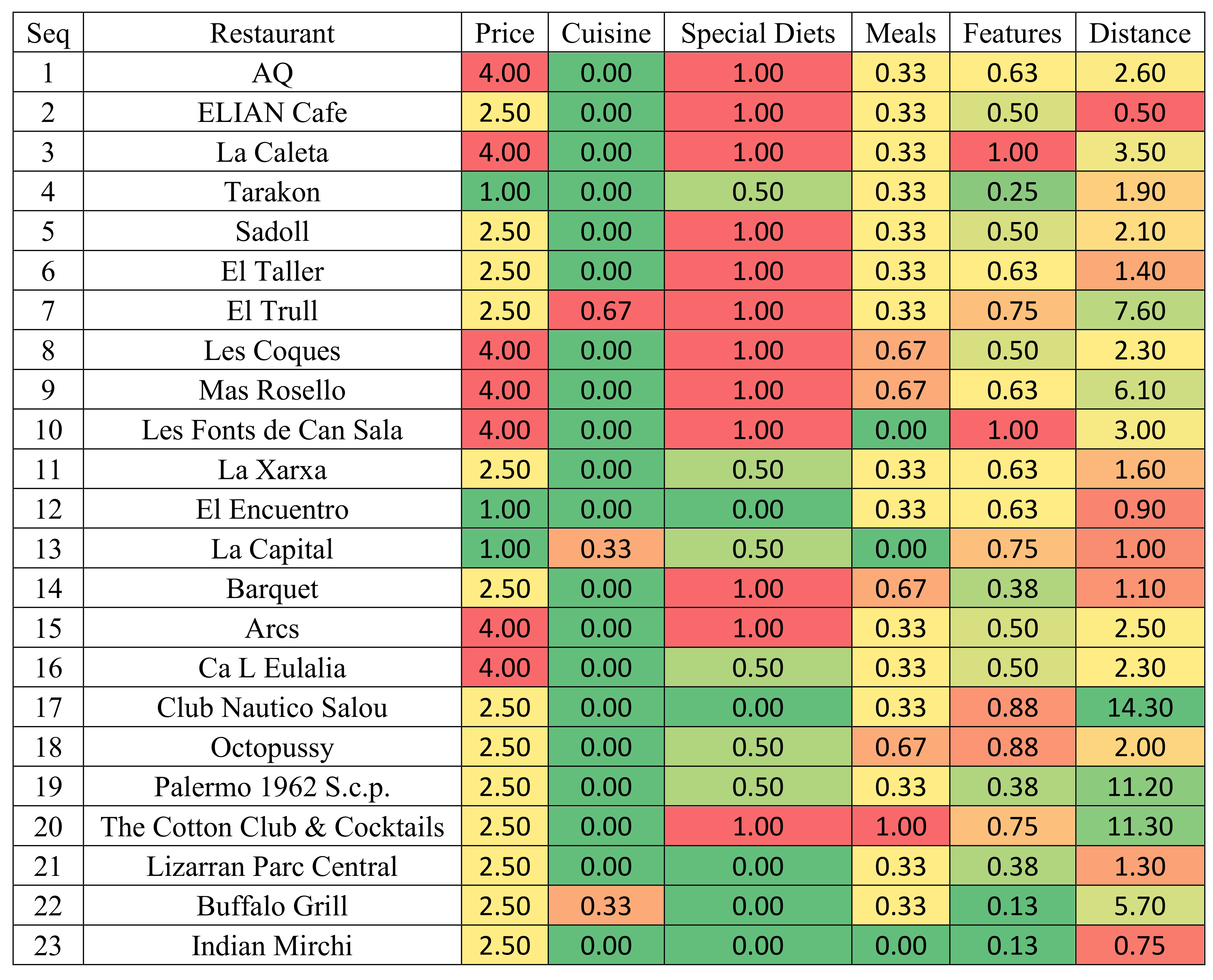
The information available in TripAdvisor about 23 local restaurants was collected. As it may be seen in
Figure 6, there is information about the number of reviews, the distance to the city centre, the range of prices, the types of food and the catering of special culinary requirements. There is also a rating for each domain attribute and a global rating of the restaurant. The ratings for the 23 alternatives are shown in
Table 7. Interested readers may find the remaining details in TripAdvisor.
We analysed the correlation between the TripAdvisor ratings and the results of the ABSA module as follows. First, we calculated the polarity index of each pair (alternative, aspect) given a set of reviews as described in Algorithm 2. Then, the overall polarity index of an alternative was obtained by taking the average of all the aspects. Finally, we converted the polarity index into a rating value from 0 to 5 by dividing the polarity index value by 20. The obtained correlations were 0.93 (food), 0.83 (service), 0.55 (price), 0.73 (ambience) and 0.8 (overall rating). Thus, the correlation between the overall rating provided by our system and the overall rating provided by TripAdvisor is strong. This shows the robustness of our sentiment analysis system and indicates that it is applicable to the restaurant domain. The low correlation in the “price” aspect may be attributed to the fact that people tend to give their opinion towards the quality of the service rather than the price, as we found that the “price” aspect has the lowest number of reviews. The “ambience” aspect shows an acceptable correlation with a value of 0.73; however, it is not quite strong. This can be attributed to the low performance of our system with respect to this aspect as shown in
Table 4.
As the results discussed above show the effectiveness of our sentiment analysis system, now we can use it to combine the preferences of the users with the analysis of the reviews to rank the restaurants. In the next subsection we will show the results of SentiRank considering two different kinds of users, and examining the influence of the addition of the social criteria derived from the sentiment analysis.
4.5.1. Example 1
In this first example we are going to consider a user with the following preferences:
Price: low.
Cuisine: bar, seafood, Spanish.
Special Diets: no gluten, vegetarian.
Meals: brunch, cocktails, lunch.
Features: parking, private dining, high chairs, handicap accessible, free WiFi, credit cards accepted.
Distance: the distance to the city centre must be as small as possible.
The user has some flexibility in the type of food and the general services of the restaurant, but it is not as tolerant with regard to the times in which meals are served and the diet—special requirements. The values of the ELECTRE thresholds that represent this knowledge are shown in
Table 8. All the social criteria are treated in the same way.
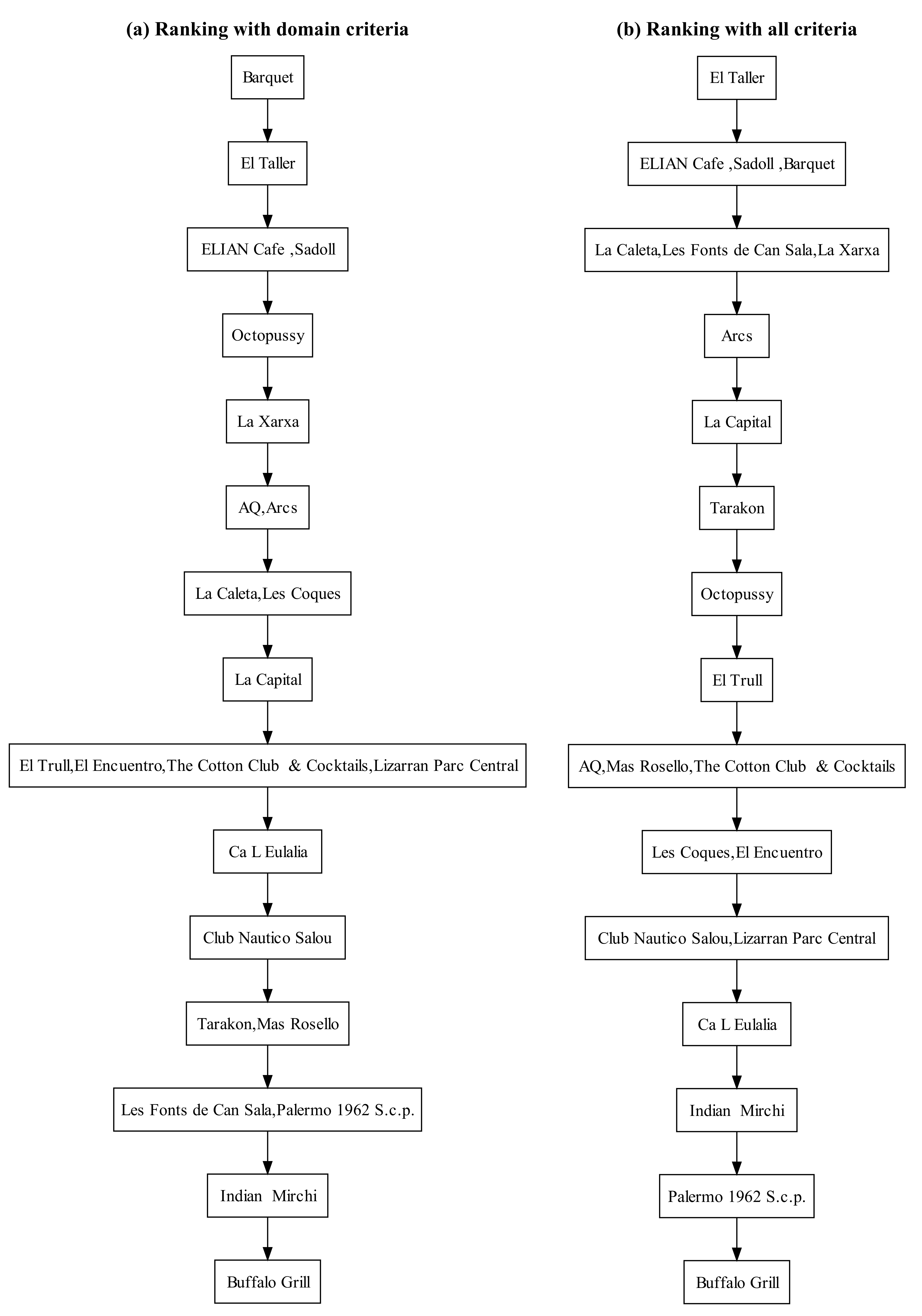
Figure 7 and
Figure 8 show the domain and social performance tables respectively.
Figure 9 shows the ranking results using only the standard criteria of the domain (left) and also taking into account the social criteria (right). As expected, the addition of the social criteria derived from the analysis of the textual reviews produce changes in the ordering of the restaurants.
The difference in the rankings reflects the importance of taking into account the opinions of the users expressed in the reviews. In the case of domain criteria, as it may be seen in
Table 7, most of the criteria have similar values (especially those for which the user has a stronger preference). The attribute in which there is a greater difference between the restaurants is the distance to the city centre.
Several interesting facts may be noted when considering social criteria:
In summary, this example shows the clear influence of the social criteria on the ranking process.
4.5.2. Example 2
In this second example the following user preferences are considered:
Price: very high.
Cuisine: grill, barbecue, bar.
Special Diets: no gluten, vegetarian.
Meals: dinner, drinks, late night.
Features: private dining, serves alcohol, table service, free WiFi, credit cards, outdoor seating, parking, full bar.
Distance: restaurants in the city centre are preferred.
We keep the same weight for all criteria and the same ELECTRE thresholds as in the previous example. The utility values of the domain criteria are shown in
Figure 10 and the ranking results of the two cases (without and with the social-based criteria) are shown in
Figure 11. As we can see, there are clear differences in the two ranking graphs. For example, the alternative “La Caleta” changes from the third to the first position. On the other hand, the alternative “Les Coques” is downgraded from position 1 to position 8 and “AQ” is downgraded from position 2 to position 7. The analysis of the domain performance table for this example, depicted in
Figure 10, shows that the more relevant criteria are price, distance to the city centre and features, in this order.
Changes similar to those reported in the first example may also be noted here. For example, the restaurant “Les Coques”, which was the best in terms of domain criteria, goes down to the middle of the ranking when users’ opinions are considered.
Given all that, we can conclude that the incorporation of the social-based criteria adds more constraints to the ranking process. However, we believe that the integration of the users’ reviews with the decision-maker preferences needs more investigation to improve the results. The next section discusses this point in more detail.
5. Conclusions and Future Work
Decision making is a very hard task, as it often requires the analysis of hundreds of potential alternatives defined on multiple and conflict criteria. Methods based on decision rules, utility functions or outranking methods have been proposed in the multi-criteria decision aid field. All of these methods use only the utility values of the so-called domain criteria. With the rapid growth of the Web, there is a myriad of online platforms on which users can express their opinions on the products or services offered by a company. This paper has presented SentiRank, a ranking system based on the well-known ELECTRE methodology that takes into account not only the standard domain attributes describing the alternatives but also the opinions of the users about them. A novel ABSA module has been incorporated to calculate the polarity of the users’ comments about different aspects and to integrate this information as new “social” criteria. A use case with a set of restaurants has shown the important contribution of these new features in the ranking process. The degree of relevance of this contribution may be modulated with the ELECTRE weights associated with each domain and social criterion. Thus, SentiRank opens up a new line of research on the integration of the polarity of textual reviews on MCDA systems.
Concerning the future work, from a practical perspective we plan to extend the implemented system by adding more domains, such as hotels, laptops and cameras. We also plan to make the system a Web-based application and implement RESTfull APIs to allow developers and users to use the system remotely. We also plan to perform a prof-of-concept (PoC) analysis with surveys on real customers using the system. On the theoretical side, we plan to make the system multi-lingual, so that it is able to analyse reviews in other languages. We are also planning to study the possibility of using deep learning techniques in the aspect detection and aspect polarity assessment modules, as it is already being done in recommender systems [
44].


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}