Resolving Dilemmas Arising during Design and Implementation of Digital Repository of Heterogenic Scientific Resources


Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
3.1. Domain-Specific Vocabulary
- accessibility—a feature of designed products, devices, services and environments related to their adaptation to the needs of users with diverse abilities, and manifested either directly or through the use of assistive technologies;
- collective data records view –a view in which more than one data record is rendered, which may involve showing a specific portion of representative contents of data records, with the use of filters and pagination;
- data record—a set of metadata, data, and licenses forming a single overall object stored in the repository;
- data record rendering—presenting the contents of the data record on a computer screen;
- data record validation—the process of assessing the accuracy of data records according to non-measurable criteria (compliance with expectations);
- data record verification—the process of evaluating the correctness of data records according to measurable criteria (compliance with schema);
- depositing—the process of delivering data records to a repository (through the available interfaces) and saving those records in the repository, which may be accompanied by verification and validation of these data records;
- metadata—a structured set of named attributes with associated values used to describe data;
- publishing—the process of making data records available on websites and through APIs or GUI;
- search—the process of formulating and submitting queries to the repository and generating responses.
3.2. Requirements Analysis
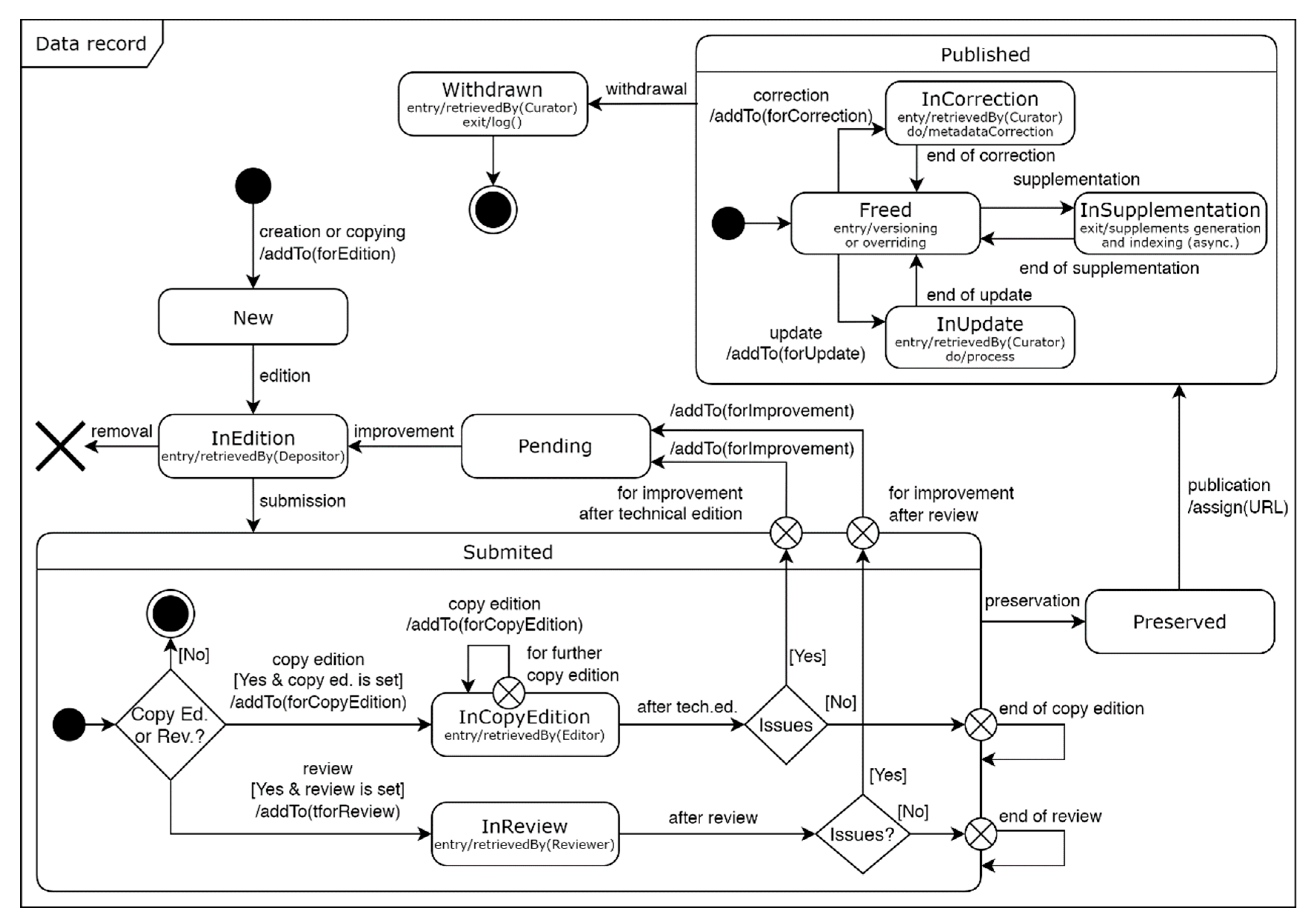
- Depositing—upon deposit, quality control of data records should be concerned. Thus, the platform should support the editing and review of data records by different users. Moreover, depositing should be possible through GUI and API, in the context of the depositor or his representative. Large data records that cannot be loaded into the repository with the HTTP protocol should also be supported.
- Publishing—published data records should appear on a website in collective and individual views, in both human and machine-readable form. The rendering should be consistent for all supported types of data records while ensuring their high availability. The data centre should activate batch processing of data (including, among others, standardization, annotation, generation of voice transcription, indexing for search purposes, linking, and determination of keywords). Records’ use should be monitored, and their correction and curation should be possible.
- Searching and browsing—published data records should be searchable in various ways (simple, advanced, faceted, by browsing, and with filtering). This requirement involves indexing their attributes and supporting the full-text search. The parameterization of search queries should be supported by utilizing dictionaries. Dictionary management (creating, adding, deleting, modifying terms) and accessing them (e.g., finding related terms in advanced search) should be possible through GUI and API.
- Securing—three pillars of security must be provided by the infrastructure: authentication, authorization, and monitoring. Moreover, the functions offered should correspond to the adopted security policies and formal procedures (including audits, issues handling, etc.).
- Maintaining—the system should ensure secure preservation of deposited resources and their long-term maintenance. The former function includes checking for consistency and physical integrity, backing up, storing several copies in different locations, etc. The latter involves checking for up-to-date links and migrations triggered by introducing new data types or upgrades of system hardware and software.
- Audio/video handling—uploading large video or audio should be supported, together with the assignment of unique IDs and publicly accessible links (so audio/video players can use that).
- Transcripts/subtitles handling—uploading multiple transcription text files, subtitles and associate them with the corresponding video should be possible.
- Streaming—video streaming and rendering with subtitling in the player on zasobynauki.com is expected.
- Video processing—adapting the stream’s quality to the quality of the connection (or choosing the quality from offered options in the player) is required.
- Video type supporting—the solution must assure support for HLS (and/or MPEG-DASH).
3.3. Information Model
- metadata—a set of mandatory (e.g., name, description, author, keywords) and optional elements (e.g., links to related resources). Some of these elements are of a simple type (can be represented by literals), while others are references to existing objects using URIs. Such URIs should make it possible to create links to reference registers (internal or external).
- data—an optional part, which might be represented by one or many files.
- license —information about license defined at a record level.
- Data: Catalogue; Chemical analysis; Dataset, database; Dendrological collection; Flow (NetFlow) from a firewall device; Herbarium sheet; Histological preparation—human; Histopathological preparation—animal; Source code; Threat log;
- Documents: Article, chapter; Book; Journal; Legislation; Legislation collection; Map; Map collection, atlas; Synopsis; Thesis;
- Materials: Archival material; Educational material; Manuscript; Note; Other documents;
- Multimedia: 3D, foto360; Artistic, architectural work; Audio; Photo; Presentation; Video;
- Portfolio: Expert; Research equipment; Research laboratory; Research offer.
4. Results
4.1. Infrastructure
- virtual servers—a virtual servers farm managed by VMware virtualizer;
- ∘
- ffmpeg—web service deployed on one of the virtual servers, used mainly for video transcoding, build on the base of ffmpeg tool;
- ∘
- image server—web service deployed on one of the virtual servers, used for user-friendly multimedia presentation, build on iipsrv (IIPImage—High Resolution Streaming Image Server);
- disk array—a system built from multiple disk drives and a cache memory offering storage capacity for numerous hosts;
- tape library—a high-capacity storage system, also called a tape robot, preserving data on many tape cartridges;
- Lustre file system—an efficient file system, optimized for access (write, read) to temporary data generated during calculations on the cluster, with a dedicated communication network—Infiniband;
- BEM cluster—a supercomputer, with 22 thousand computing cores and a total output of 860 TFLOPS. The cluster has 720 24-core computing nodes (Intel Xeon E5-2670 v3 2.3 GHz, Haswell) and 192 28-core computing nodes (Intel Xeon E5-2697 v3 2.6 GHz, Haswell). It has 74.6 TB of RAM (64, 128, or 512 GB per node). The exchange of data files between BEM and its clients takes place through the enabled disk shares.
- OZONE—an on-premises platform for multimedia processing (deployed in the existing infrastructure);
- Limecraft—a cloud-based platform for multimedia processing (deployed in the external infrastructure).
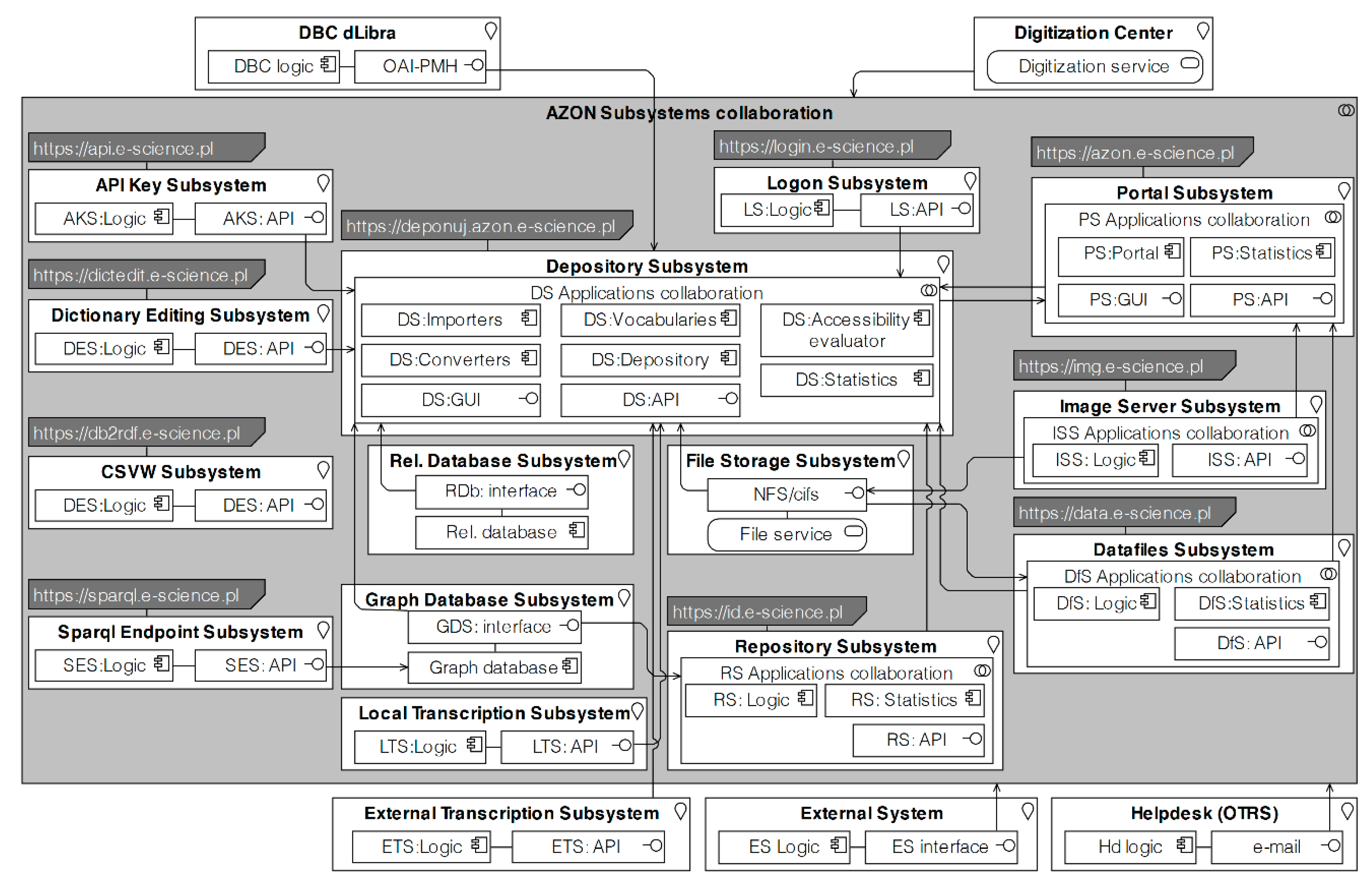
4.2. Logical Architecture
- Depository subsystem (digital repository engine),
- Portal subsystem (digital repository front-end),
- Database subsystem, Graph Database Subsystem, File Storage Subsystem (parts of the AZON platform used for data storage implementation: relational database, graphs database, file system)
- Local Transcription Subsystem (part of the AZON platform responsible for multimedia processing),
- Image Server Subsystem, Datafiles Subsystem (web services accountable for content delivering to Portal Subsystem or to be downloaded by the users)
- Repository Subsystem, Sparql Endpoint Subsystem (web services used to publish metadata in a semantic form and according to LOD principles)
- Logon Subsystem, API Key Subsystem (web services responsible for handling user credentials and assure system security). Logging into the AZON platform and accessing its services works with the SAML mechanism, realized through CAS. The CAS server retrieves authentication data from indicated LDAP and Active Directory servers. For depositors from external universities or institutions with no authentication source (LDAP, AC), registration in the platform is obligatory. The Logon Subsystem is responsible for handling such tasks. However, access for reading is open for everyone with some exceptions enforced by security rules. To reach API offered by AZON components, the users must apply individually for access tokens through API Key Subsystem. This subsystem incorporates API Umbrella (https://apiumbrella.io) working in the background.
- Dictionary Editing Subsystem (web services used to view and modify dictionaries used in Depository Subsystem or manage custom dictionaries).
- CSVW Subsystem (web service enabling conversion of tabular data in CSV format to RDF format using the CSVW standard (https://www.w3.org/TR/tabular-data-model/)).
- External Transcription Subsystem (service responsible for multimedia processing, like OZONE system used for transcription).
- DBC dLibra (element used to integrate AZON depository with Lower Silesian Digital Library system).
- Helpdesk (OTRS) (element responsible for handling users’ help requests and comments).
- External System (any external system that uses AZON API).
- Digitization Center (services running within institutions involved in the project, aimed at resources digitization).
4.3. Business Processes
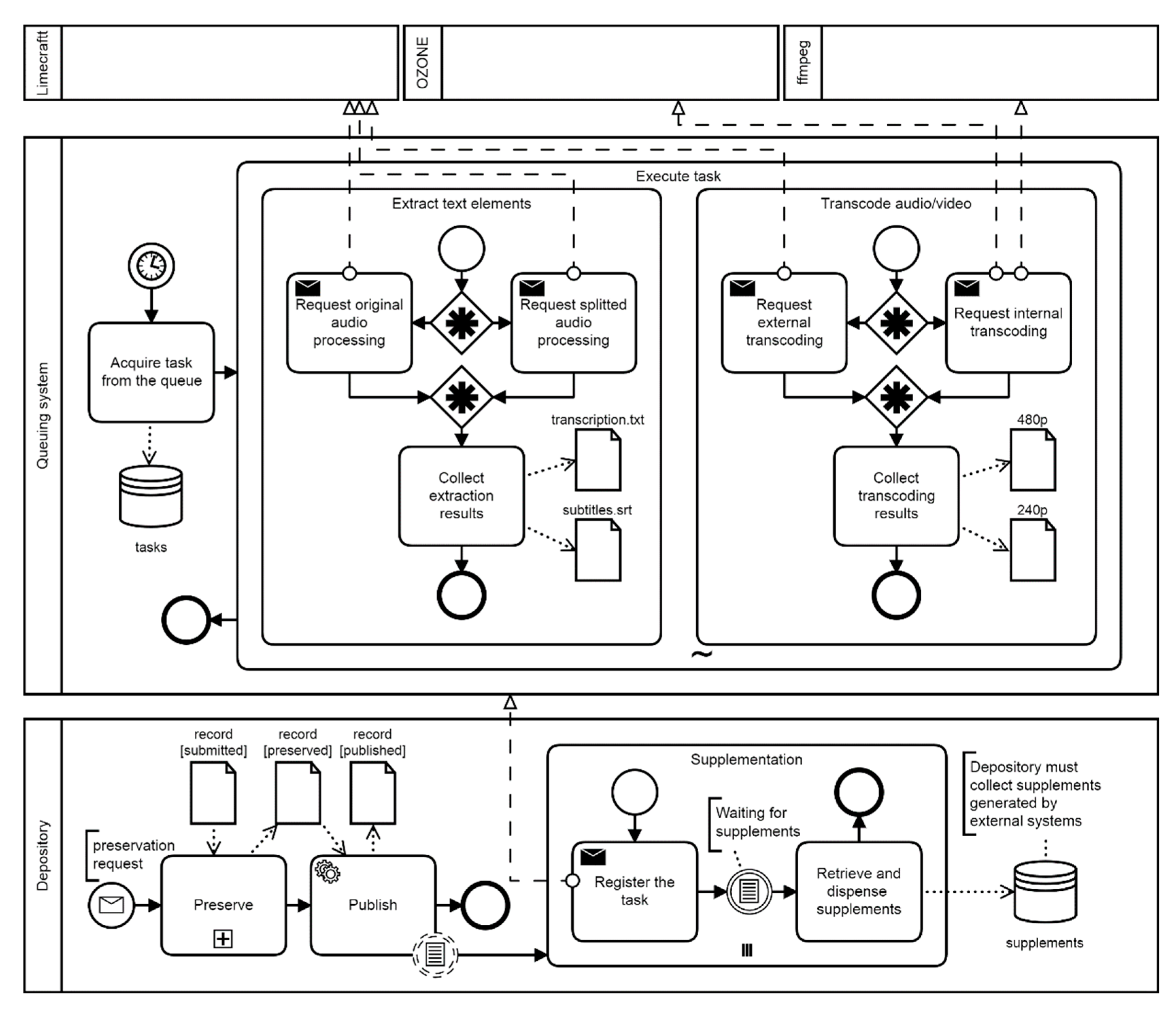
- simple, by sending original audio to the Limecraft cloud for processing, and downloading processing results. The processing flow starts with a POST request parameterized with file name and size. In the response, Limecraft returns URL API for file upload. After receiving the information about the upload end (send through API), Limecraft starts the transcript generation process and makes their results (transcript, subtitles) available in selected formats.
- complex, by splitting audio from the original audio/video input and then sending that audio to the Limecraft cloud to process and download the results. This scenario brings benefits in terms of reducing the amount of data stored in Limecraft cloud (this reduces costs) and accelerating data transfer to/from the cloud (this reduces total processing time).
- by using external, on-premise service, which means uploading the data to OZONE platform configured for automatic storage and streaming of video, audio, subtitles as required (handled video resolutions: 240p/360p/480p/720p/1080p);
- by using internal, developed service, which means uploading data to a dedicated server, starting the processing through adequately configured and used ffmpeg tool, obtaining results of required resolution and storing and streaming video, audio, subtitles as required (handled video resolutions: 480p/720p/1080p);
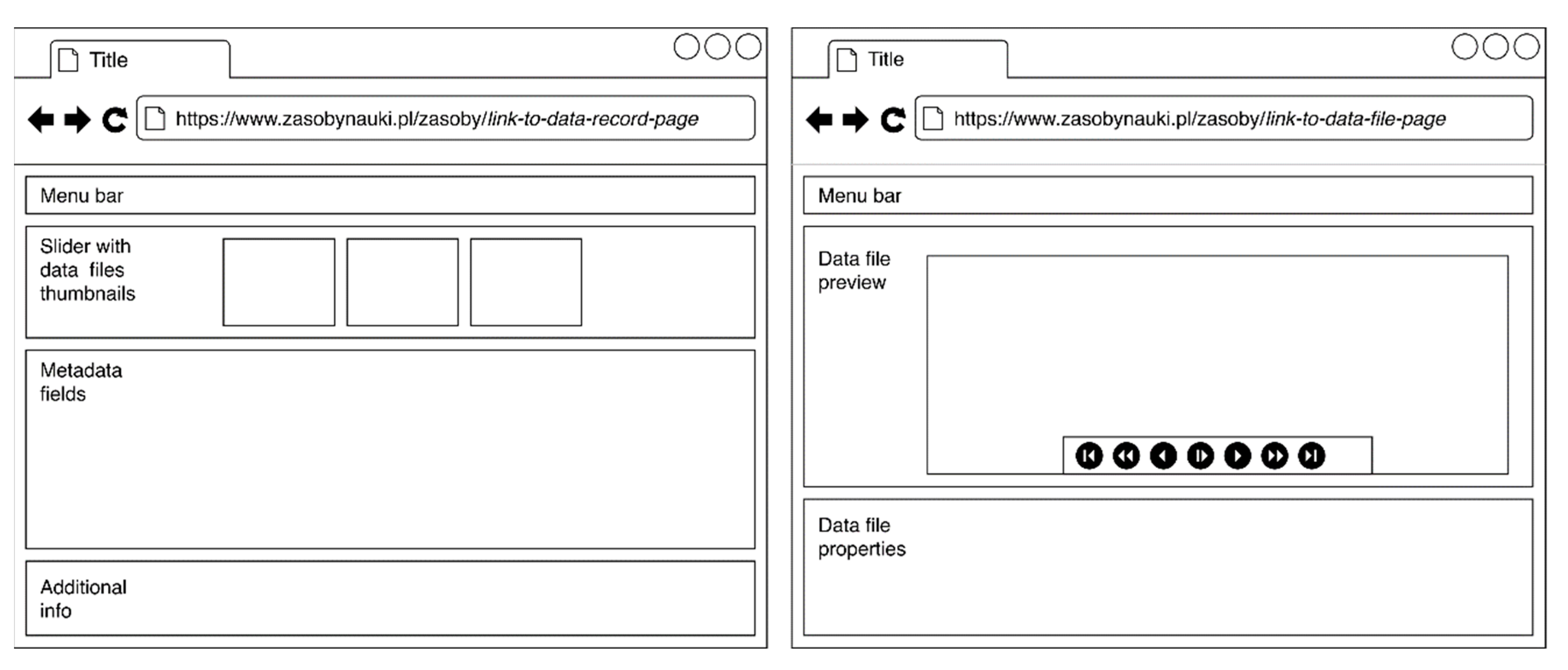
4.4. Online Presentation
- OZONE platform provides video (in HLS or MPEG-DASH format);
- AZON streaming service (HLS format) provides video when such video is not present in the OZONE platform or OZONE service is unavailable (because of failure or other reasons);
- if the streaming service cannot deliver video, the original data files are fed from the file system via the data.e-science.pl website (in MP4, MOV, or another format). For example, this may happen if the request for a video is issued before the supplementation phase.
4.5. AZON in Numbers
- Data (total: 19,381): Catalogue (0); Chemical analysis (763); Dataset, database (13,582); Dendrological collection (356); Flow (NetFlow) from a firewall device (886); Herbarium sheet (1018); Histological preparation—human (1277); Histopathological preparation—animal; Source code (65); Threat log (1224);
- Documents (total: 14,619): Article, chapter (2682); Book (1933); Journal (9475); Legislation (1); Legislation collection (0); Map (1); Map collection, atlas (0); Synopsis (154); Thesis;
- Materials: Archival material (0); Educational material (408); Manuscript (0); Note (1); Other document (965);
- Multimedia (total 8327): 3D, foto360 (1953); Artistic, architectural work (245); Audio (418); Photo (1956); Presentation (107); Video (3648);
- Portfolio (577): Expert (176); Research equipment (241); Research laboratory (45); Research offer (115);
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Flesca, S.; Greco, S.; Masciari, E.; Saccà, D. (Eds.) A Comprehensive Guide through the Italian Database Research Over the Last 25 Years; Studies in Big Data; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; Volume 31, Studies in Big Data. [Google Scholar]
- Baran, R.; Dziech, A.; Zeja, A. A capable multimedia content discovery platform based on visual content analysis and intelligent data enrichment. Multimed. Tools Appl. 2018, 77, 14077–14091. [Google Scholar] [CrossRef]
- Moscato, V.; Picariello, A. Multimedia Data Modeling and Management. In A Comprehensive Guide through the Italian Database Research over the Last 25 Years, 1st ed.; Flesca, S., Greco, S., Masciari, E., Sacc, D., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; Volume 31, Chapter 16; pp. 269–284. [Google Scholar]
- Bankier, J.G.; Gleason, K. Institutional Repository Software Comparison. Programme and Meeting Document CI/KSD/2014/PI/H/; UNESCO: Paris, France, 2014. [Google Scholar]
- Antonacci, M.; Brigandì, A.; Caballer, M.; Cetinicć, E.; Davidovic, D.; Donvito, G.; Moltó, G.; Salomoni, D.; Forti, A.; Betev, L.; et al. Digital repository as a service: Automatic deployment of an Invenio-based repository using TOSCA orchestration and Apache Mesos. EPJ Web Conf. 2019, 214, 1–8. [Google Scholar] [CrossRef]
- Verdugo, P.; Astudillo-Rodriguez, C.; Verdugo, J.; Lima, J.F.; Cedillo, S. Documentation and Scientific Archiving: Digital Repository. Advances in Creativity, Innovation, Entrepreneurship and Communication of Design; Markopoulos, E., Goonetilleke, R.S., Ho, A.G., Luximon, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 296–302. [Google Scholar]
- Lynch, C.A. Institutional Repositories: Essential Infrastructure for Scholarship in the Digital Age. Portal Libraries Acad. 2003, 3, 327–336. [Google Scholar] [CrossRef]
- Joint, N. Current research information systems, open access repositories and libraries: ANTAEUS. Libr. Rev. 2008, 57, 570–575. [Google Scholar] [CrossRef]
- Brush, D.A.; Jiras, J. Developing an institutional repository using Digital Commons. Digital Libr. Perspect. 2019, 35, 31–40. [Google Scholar] [CrossRef]
- Schöpfel, J.; Azeroual, O. 2-Current research information systems and institutional repositories: From data ingestion to convergence and merger. In Future Directions in Digital Information; Baker, D., Ellis, L., Eds.; Chandos Digital Information Review; Chandos Publishing: Kidlington, UK, 2021; pp. 19–37. [Google Scholar]
- Castiglione, A.; Colace, F.; Moscato, V.; Palmieri, F. CHIS: A big data infrastructure to manage digital cultural items. Future Gener. Comput. Syst. 2018, 86, 1134–1145. [Google Scholar] [CrossRef]
- Carvajal, D.A.L.; Morita, M.M.; Bilmes, G.M. Virtual museums. Captured reality and 3D modeling. J. Cult. Herit. 2020, 45, 234–239. [Google Scholar] [CrossRef]
- Fanini, B.; Pescarin, S.; Palombini, A. A cloud-based architecture for processing and dissemination of 3D landscapes online. Digit. Appl. Archaeol. Cult. Herit. 2019, 14. [Google Scholar] [CrossRef]
- Heftberger, A. Chapter 4-Exploring the Moving Image: The Role of Audiovisual Archives as Partners for Digital Humanities and Cultural Heritage Institutions. In Digital Humanities, Libraries, and Partnerships; Kear, R., Joranson, K., Eds.; Chandos Publishing: Kidlington, UK, 2018; pp. 45–57. [Google Scholar]
- Nishanbaev, I. A web repository for geo-located 3D digital cultural heritage models. Digit. Appl. Archaeol. Cult. Herit. 2020, 16, e00139. [Google Scholar] [CrossRef]
- Xie, I.; Matusiak, K. Discover Digital Libraries: Theory and Practice, 1st ed.; Elsevier Science Publishers B. V.: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Space Data and Information Transfer Systems–Open Archival Information System (OAIS)–Reference Model; Standard ISO 14721:2012; International Organization for Standardization: Geneva, Switzerland, 2012.
- Space Data and Information Transfer Systems–Producer-Archive Interface–Methodology Abstract standard; Standard ISO 20652:2006; International Organization for Standardization: Geneva, Switzerland, 2006.
- Space Data and Information Transfer Systems–Audit and Certification of Trustworthy Digital Repositories; Standard ISO 16363:2012; International Organization for Standardization: Geneva, Switzerland, 2012.
- Sharma, S.; Gupta, P.; Nagpal, C.K. A Novel Architecture to Crawl Images Using OAI-PMH. Sensors and Image Processing; Urooj, S., Virmani, J., Eds.; Springer: Singapore, 2018; pp. 37–48. [Google Scholar]
- Martin-Rodilla, P.; Gonzalez-Perez, C. Metainformation scenarios in Digital Humanities: Characterisation and conceptual modelling strategies. Inf. Syst. 2019, 84, 29–48. [Google Scholar] [CrossRef]
- Xie, K.; Di Tosto, G.; Chen, S.B.; Vongkulluksn, V.W. A systematic review of design and technology components of educational digital resources. Comput. Educ. 2018, 127, 90–106. [Google Scholar] [CrossRef]
- Jadoon, R.N.; Zhou, W.; Haq, F.U.; Shafi, J.; Khan, I.A.; Jadoon, W. A Reliable Scheme for Synchronising Multimedia Data Streams under Multicasting Environment. Appl. Sci. 2020, 8, 556. [Google Scholar] [CrossRef]
- Tanseer, I.; Kanwal, N.; Asghar, M.N.; Iqbal, A.; Tanseer, F.; Fleury, M. Real-Time, Content-Based Communication Load Reduction in the Internet of Multimedia Things. Appl. Sci. 2020, 10, 1152. [Google Scholar] [CrossRef]
- Adão, T.; Pádua, L.; Fonseca, M.; Agrellos, L.; Sousa, J.J.; Magalhães, L.; Peres, E. A rapid prototyping tool to produce 360° video-based immersive experiences enhanced with virtual/multimedia elements. Procedia Comput. Sci. 2018, 138, 441–453. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project Name and Its Homepage | Supported Metadata Standards | Software Type and Search Features |
|---|---|---|
| Fedora Commons, https://duraspace.org/fedora/ | MODS, Dublin Core, QDC out of the box, arbitrary metadata sets | platform only, with API, with native Linked Data support |
| Islandora, https://islandora.ca | MODS, Dublin Core, PREMIS, MARCXML | repository, built on Fedora Commons, uses Apache Solr |
| Samvera (previously Hydra), https://samvera.org | MODS, DC, DC11, EDM, FOAF, custom metadata set | bespoke solution, build on Fedora Commons, uses Apache Solr |
| DSpace, http://duraspace.org/dspace/ | Dublin Core, arbitrary metadata sets (but flat) | repository, uses Apache Solr |
| Archivematica, https://www.archivematica.org/en/ | METS, PREMIS, Dublin Core, Library of Congress BagIt | repository, based on ISO-OAIS functional model, uses Elastic Search |
| AtoM, https://www.accesstomemory.org/en/ | EAD, Dublin Core XML, MODS XML, EAC, SKOS | repository, uses Elastic Search |
| Invenio, https://invenio-software.org | MARC | repository, uses Elastic Search |
| VIVO, https://duraspace.org/vivo/ | VIVO ontology, arbitrary metadata sets (custom ontologies) | repository, uses Apache Solr |
| RODA, https://www.roda-community.org | EAD, DC, METS, PREMIS, and others (e.g., NISO Z39.87 for digital still images) | repository, uses Apache Solr |
| EPrints, https://www.eprints.org | custom metadata set | repository, uses custom indexer |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kubik, T.; Kwiecień, A. Resolving Dilemmas Arising during Design and Implementation of Digital Repository of Heterogenic Scientific Resources. Appl. Sci. 2021, 11, 215. https://doi.org/10.3390/app11010215
Kubik T, Kwiecień A. Resolving Dilemmas Arising during Design and Implementation of Digital Repository of Heterogenic Scientific Resources. Applied Sciences. 2021; 11(1):215. https://doi.org/10.3390/app11010215
Chicago/Turabian StyleKubik, Tomasz, and Agnieszka Kwiecień. 2021. "Resolving Dilemmas Arising during Design and Implementation of Digital Repository of Heterogenic Scientific Resources" Applied Sciences 11, no. 1: 215. https://doi.org/10.3390/app11010215
APA StyleKubik, T., & Kwiecień, A. (2021). Resolving Dilemmas Arising during Design and Implementation of Digital Repository of Heterogenic Scientific Resources. Applied Sciences, 11(1), 215. https://doi.org/10.3390/app11010215