1. Introduction
Load forecasting has always been a challenging task that triggers the interest of both academia and the industrial sector. Since the 1960s, auto-regressive (AR) models have been widely used for designing and implementing predictive load forecasting models. These were based on the assumption that the system/substation load at any given time can be satisfactorily described as a linear combination of past load values and other values of a set of exogenous variables. Therefore, they were either plain AR models or AR models with exogenous variables (ARX) and/ or AR models with moving average components (ARMA and ARMAX). Such models and variants thereof were used extensively for electric load forecasting [
1,
2].
The linearity assumption was relaxed with the development of machine learning-based models such as neural networks [
3,
4] and kernel-based methods (e.g., support vector machines [
5]). Neural networks are nowadays the most widely used machine learning tool for nonlinear regression in electrical load forecasting. At the same time, support vector regression is gaining popularity in this area [
6].
In this paper we focus on the state-of-the-art Artificial Neural Network (ANN) deep learning algorithms, namely the Convolution Neural Nets (CNNs) in order to perform load prediction. Currently the most successful and popular algorithm in literature for addressing this issue is the use of Long Short Term Memory (LSTM) [
7] method, which belongs to the Recurrent Neural Network (RNN) architectural type and exploits the short and long term relationships that exist in a data series in order to build a predictive model. LSTM algorithms are considered to be the most suitable choice for electric load forecasting compared to other neural network architectures. CNNs, on the other hand, are considered to be the preferred choice for image processing related tasks, like image recognition, due to their ability to take advantage of the inherent stationarity usually observed in the pixel data, thus resulting in more accurate models. Nevertheless, it will be shown that CNN-based models can also provide efficient solutions for the electric load forecasting problem and under certain conditions, such as applying proper data preprocessing and analysis, they could even outperform the LSTM-based models.
Despite the black box nature of ANN solutions, there is considerable freedom for differentiating model selection choices and parameter tuning, such as the number of epochs, batch size or hidden dimensions and filters (i.e., the number of output filters in the convolution) for the CNN-based models. The proposed approach offers a comprehensive methodology for model selection and parameter tuning resulting in significantly lower forecasting errors compared to the LSTM model. Furthermore, the data transformation which was performed after extensive statistical analysis allows optimal input selection for our models. The most common input in such cases is the previous state (t-1) of the forecasted variable. This leads to higher accuracy for uni-step forecasting applications, but at the same time it lowers the performance of the multi-step ones by introducing several defects. In our case, the input value is derived directly from the results of statistical analysis. It is important to mention that this paper does not focus on the CNN algorithm itself, but rather on the proper statistical analysis (pre-processing) which facilitates the data transformation based on data features (i.e., stationarity) and achieve best possible performance of the algorithm. The methodology and the different techniques employed will be thoroughly described in
Section 2.
According to the time horizon used for prediction, load forecasting can be classified into very short-term load forecasting (VSTLF), short-term load forecasting (STLF), medium-term load forecasting (MTLF), and long-term load forecasting (LTLF). The forecasting horizon varies from 5 min, to one day, to two weeks or to three or more years; depending on the planning or operational function it supports [
8].
Across literature a wide range of methodologies and models have been proposed to improve the accuracy of load forecasting, yet most of them are based upon aggregated power consumption data at the system (top) level with little to no information regarding power consumption profiles at the customer class level. This approach was acceptable till now, since the operational focus until recently had been on the bulk transmission system and the wholesale energy markets. Since the interest now is shifted towards the distribution system and the efficient integration of Distributed Energy Resources (DERs) connected close to the edge of the grid, this approach is not sufficient anymore. Hence, distribution substation load forecasting becomes a necessity for the Distribution System Operators (DSOs). Forecasting on distribution feeder has not been widely examined across literature. Low Voltage (LV) distribution feeders are more volatile compared to the high voltage (HV) ones, since they consist of low aggregations of consumers [
9]. One approach is to adopt the forecasting techniques and models that are currently employed at higher voltage levels. The main forecasting research in these areas has been presented in [
10,
11], that apply both ARIMAX and ANN methods to a single LV transformer (consisting of 128 customers) for forecasting the total energy and peak demand. In their method they take into account historical weather data and they achieve MAPEs of 6–12%. In [
12] a three-stage methodology, which consists of pre-processing, forecasting, and post-processing, was applied to forecast loads of three datasets ranging from distribution level to transmission level. A semi-parametric additive model was proposed in [
13] to forecast the load of Australian National Electricity Market. The same technique was also applied to forecast more than 2200 substation loads of the French distribution network in [
14]. Another load forecasting study on seven substations from the French network was performed in [
15], where a conventional time series forecasting methodology was utilized. In [
16], the authors proposed a neural network model to forecast the load of two French distribution substations, which outperformed a time series model. It is focused on developing a methodology for neural network design in order to obtain a model that has the best achievable predictive ability given the available data. Variable selection and model selection was applied to electrical load forecasts to ensure an optimal generalization capacity of the neural network model.
Exponential smoothing model and its variations, such as double and triple seasonal exponential smoothing ones, have also showcased good results [
17] but are less popular in real-life applications due to their inability to accommodate exogenous variables. Another popular approach, denoted as hybrid, is to combine different models as in [
1] where Principal Component Analysis (PCA) and Multiple Linear Regression (MLR) are combined for daily load predictions.
For LV networks accurate load forecasting can be employed to support a number of operations, including demand side response [
18], storage control [
19,
20] and energy management systems [
21,
22]. Load forecasting for low scale consumers, such as residential loads, is valuable for home energy management systems (HEMS) [
23] while house level load forecasting can play a significant role in the future Local Energy Markets (LEM) which will facilitate the energy transactions among participants [
24]. Load forecasting has been implemented for either the HV or system level and typically consists of the aggregated demand of hundreds of thousands or millions of consumers. Such demand is much less volatile than the LV demand, and hence, is easier to predict. Load forecasting at this level is very mature research-wise and there is a great volume of literature describing and testing a number of methods and algorithms, including ANNs, Support Vector Machine (SVM), ARIMA, exponential smoothing, fuzzy systems, and linear regression. Recent methods upon load forecasting can be found in [
25].
However, the loads of a house, a factory, and a feeder are more volatile than HV level loads. Therefore, developing a highly accurate forecast at lower consumption levels is nontrivial. Although the majority of the load forecasting literature has been dedicated to forecasting at the top (high voltage) level, the information from medium/low voltage levels offers a promising field of research. The highly volatile nature of house load time series makes it particularly difficult to achieve very accurate predictions. In [
26] the authors showed that the ‘‘double peak’’ error for spiky data sets means that it is difficult to measure the accuracy of household-level point forecasts objectively introducing traditional pointwise errors. Similar methods have been applied at the household level as at the HV level, including ANNs [
27,
28] ARIMAs, wavelets [
29], Kalman filters [
30] and Holt-Winters exponential smoothing [
31]. The prediction errors of these methods are much higher compared to those reported at the HV level, with MAPEs ranging from 7% up to 85% in some cases.
Regardless the voltage level and the load scale, load forecasting problems share certain common factors that may affect the prediction accuracy of energy consumption. These are the energy markets, the variables affected by the weather and the hierarchical topology of the grid. In competitive energy retail markets, the electricity consumption is largely driven by the number of customers. Since the number of customers is uncertain, the load profile is consequently characterized by high stochasticity. In [
32] the authors propose a two-stage long-term retail load forecasting method to take customer reduction into consideration. The first stage forecasts each customer’s load using multiple linear regression with a variable selection method. The second stage forecasts customer attrition using survival analysis. Then, the final forecast results from the product of the two forecasts. Another issue regarding the energy market is the demand response programs which pose another challenge in load forecasting, since some consumers are willing to alter their consumption patterns according to price signals, while others are not. In [
33] the authors detect the price-driven customers by applying a non-parametric test so that they can be forecasted separately. Across literature, many papers have shown strong correlations between weather effects and demand. A weather variable investigated in literature is humidity [
34], where the authors discovered that the temperature-humidity index (THI) may not be optimal for load forecasting models. Instead, more accurate load forecasts than the THI-based models were performed when the authors separated relative humidity, temperature and their higher order terms and interactions in the model, with the corresponding parameters being estimated by the training data. In [
35] the load of a root node of any sub-tree was forecasted first. The child nodes were then treated separately based on their similarities. The forecast of a “regular” node was proportional to that of the parent node, while the “irregular” nodes were forecasted individually using neural networks. In [
36] the authors exploit the hierarchical structure of electricity grid for load forecasting. Two case studies were investigated, one based on New York City and its substations, and the other one based on Pennsylvania-New Jersey-Maryland (PJM) and its substations. The authors demonstrated the effectiveness of aggregation in improving the higher level load forecast accuracy.
The availability of data from Advanced Metering Infrastructure (AMI) systems enables the use of novel approaches to the way load forecasting is performed, ranging from the distribution level to even the residential scale. In existing literature, researchers have focused on: (1) longitudinal and (2) cross-sectional grouping methods trying to handle efficiently load data. Longitudinal grouping refers to identifying time periods with similar load patterns, which are derived from statistical analysis based on historical data. On the other hand, cross-sectional grouping refers to the aggregation of customers with similar consumption characteristics. In [
37] the authors examined six methods which are usually employed in large-scale energy systems to predict a load similar to that of a single transformer. The models that were investigated were ANNs, AR, ARMA, autoregressive integrated moving average, fuzzy logic, and wavelet NNs for day-ahead and week-ahead electric load forecasting in two scenarios with different number of houses. In [
38] a clustering based on AMI data is performed among customers to identify groups with similar load patterns prior to performing load forecasting, in favor of forecasting accuracy. In [
39], the authors implemented a neural network (NN)-based method for the construction of prediction intervals (PIs) to quantify potential uncertainties associated with forecasts. A newly introduced method, called lower upper bound estimation (LUBE), is applied and extended to develop PIs using NN models. In [
40] a new hybrid model is proposed. This model is a combination of the manifold learning Principal Components (PC) technique and the traditional multiple regression (PC-regression), for short and medium-term forecasting of daily, aggregated, day-ahead, electricity system-wide load in the Greek Electricity Market for the period 2004–2014. PC-regression is compared with a number of classical statistical approaches as well as with the more sophisticated artificial intelligence models, ANN and SVM. The authors have concluded that the forecasts of the developed hybrid model outperforms the ones generated by the other models, with the SARIMAX model being the next best performing approach, giving comparable result.
The advantages that smart meters bring to load forecasting are two-fold. Firstly, smart meters offer the opportunity to distribution companies and electricity retailers to better understand and forecast the load of small scale consumers. Secondly, the high granularity and volume of load data provided by smart meters may improve the forecast accuracy of the models on the grounds that the training dataset will be more representative and will capture the highly volatile demand patterns that describe the load behavior of households or buildings. Therefore, the traditional techniques and methods developed for load forecasting at an aggregate level may not be well suited. Many different approaches are currently examined, all attempting to leverage the large volume of data derived from the numerous operating smart meters so as to improve the forecasting accuracy. In [
41] seven existing techniques, including linear regression, ANN, SVM and their variants were examined. The case study was conducted on two datasets, one comprising of two commercial buildings and the other of three residential homes. The study demonstrated that these techniques could produce forecasts with high accuracy for the two commercial loads, but did not perform well for the residential ones. In [
29] a self-recurrent wavelet neural network (SRWNN) was proposed to forecast the load for a building within a microgrid. The proposed SRWNN was shown to be more accurate than its ancestor wavelet neural network (WNN) for both building level and higher level load cases. Deep learning techniques for the household and building-level load forecasting are also employed across literature. In [
42] a pooling-based deep RNN was proposed to learn spatial information shared between interconnected customers and to address the over-fitting problems. The proposed method outperformed ARIMA, SVR, and classical deep RNN on the Irish CER residential dataset. In [
43] a spatio-temporal forecasting approach was proposed to leverage the sparsity which is a valuable element in small scale load forecasting. The proposed method combined ideas from compressive sensing and data decomposition to exploit the low-dimensional structures governing the interactions among the nearby houses. The dataset upon which the method was examined was the Pecan Street dataset.
Additional categorization among the different load forecasting methods in the literature can be summarized as follows: (1) Physics principles-based models and (2) Statistical/Machine learning-based models. In [
44] ANNs were used to perform load forecasting in buildings. Finally, in [
45] a short-term residential load forecasting based on resident behavior learning was examined. RNNs, such as LSTM, seem as a reasonable selection for time series applications since they are developed explicitly to handle sequential data. In [
46] a custom Deep Learning model that combines multiple layers of CNNs for feature extraction is presented, where both LSTM layers (prediction) and parallel dense layers (transforming exogenous variables) are proposed. Finally in [
47] a novel method to forecast the electricity loads of single residential households is proposed based on CNNs (combined with a data-augmentation technique), which can artificially enlarge the training data in order to face the lack of sufficient data.
This work focuses on a statistical learning-based approach by examining and leveraging the special statistical features of each given dataset [
48] and thereafter transforming the dataset into a form according to the statistical analysis performed for that purpose. Our framework is based on the employment of a CNN architecture. CNNs are among the most popular techniques for deep learning, mainly for image processing tasks [
49], where they leverage the spatial locality of pixels. There have been recently presented remarkable efforts of using CNN models for electrical load forecasting [
50]. CNNs choice is based on the fact that in load time series, two neighboring points do not exhibit significant deviation. Therefore, load time series are characterized by temporal locality which can be exploited by CNNs. In this paper, we demonstrate that LSTMs for load forecasting under certain conditions can be outperformed; this finding is supported by experimental evidence. To prove our point, we furthermore compare our CNN model with three other machine learning techniques, namely LSTM, ANN and Multilayer Perceptron (MLP). The main contributions of the paper can be summarized in the following:
We introduce a method for properly tuning the model’s parameters by taking into account the time series statistical properties and especially its auto correlation.
We offer a valid alternative to the load forecasting problem in the case of low scale energy deployments where it is derived that our CNN based approach is more efficient than other methods.
We identify the conditions under which the CNN outperforms the other widely used forecasting solutions such as high temporal relationship between time series observations, lack of historical data and low scale load consumption.
We offer a solution to times series forecasting in cases where there is shortage of training data, since in our experiments the historical data available for training were limited.
The rest of the paper is organized as follows: In
Section 2 the proposed methodology is analyzed in detail, in
Section 3 the results of our investigation is given and in
Section 4 we present the discussion and the conclusions of our work and suggest possible future research extensions.
2. Proposed Methodology
2.1. Convolutional Neural Networks (CNN)
CNN is a class of deep neural networks, most commonly applied to analyzing visual imagery. They are also known as shift invariant or space invariant artificial neural networks (SIANN), based on their shared-weights architecture and translation invariance characteristics [
51,
52]. CNNs are regularized versions of multi-layer perceptron but they take a different approach towards regularization, since they take advantage of the hierarchical form in data and assemble more complex patterns using smaller and simpler patterns. Therefore, on the scale of connectivity and complexity, CNNs are functioning on the lower extreme. CNNs use relatively little pre-processing compared to other image classification algorithms. This means that the network trains the filters that in traditional algorithms were hand-engineered. This independence from prior knowledge and human effort in feature design is a major advantage.
As presented in
Figure 1, a CNN consists of an input and an output layer, as well as multiple hidden layers. These layers perform operations that alter data with the intent of extracting features specific to the data. Three of the most common layers are: convolution, activation or ReLU, and pooling. The hidden layers of a CNN typically consist of a series of convolutional layers that convolve through multiplication or other dot product each of which activates certain image features.
The input layer reads an input image into the CNN. It consists of various low-level image-processing functions to pre-process the input image as an appropriate data type for the minimal CNN. Practically, the size of the input image is preferably on the order of power of 2 so that to ensure computation efficiency for a CNN. However, input images with uneven row-column dimensions can also be used. The convolution layer extracts pixel-wise visual features from an input image [
54,
55,
56]. The trainable convolution kernels in this layer adjust their (kernel) weights automatically through back-propagation to learn the input image features [
56,
57]. Image features learned by the convolution layer allow the successive algorithmic layers to process the extracted image features for other computational operations. The convolution layer is the dot product of the input image
I and the kernel used,
K. The result is a convolved feature map,
which is derived by the Equation (
1).
Here ⊗ denotes a two-dimensional discrete convolution operator. Equation (
1) shows that the convolution kernel
K spatially slides over the input image
I to compute the element-wise multiplication and sum to produce an output, a convolved feature map
. Convolution provides weights sharing, sparse interaction (and local connectivity), and equivariant representation for unsupervised feature learning. More in depth technical details on these convolution properties can be found in [
54,
55,
57,
58,
59,
60]. The activation function is commonly a Rectified Linear Unit (
) layer.
allows for faster and more effective training by mapping negative values to zero and maintaining positive values. This is sometimes referred to as activation, because only the activated features are carried forward to the next layer. The objective of the
layers is to introduce a point-wise nonlinearity to a CNN, which allows it to learn through a nonlinear input function.
has also proven to be an effective solution to resolve vanishing gradient problems when training a CNN using the backpropagation algorithm [
55,
56]. The mathematical structure of the ReLU function is a piecewise nonlinear operator with a max output indicative function [
54,
58]. The output of a
is a rectified feature map,
that can be obtained by Equation (
2).
Equation (
2) produces zero for negative inputs and linearly conveys the input for positive inputs. The activation layer is followed by pooling layers which simplify the output by performing nonlinear down-sampling, thus reducing the number of parameters that the network needs to learn, controlling the overfitting by progressively reducing the spatial size of the network and reducing the computational burden in the network. Those layers are referred to as hidden layers because their inputs and outputs are masked by the activation function and final convolution. The final convolution, in turn, often involves backpropagation in order to more accurately weight the end product.
Though the layers are colloquially referred to as convolutions, this is only by convention. Mathematically or technically, it is a sliding dot product or cross-correlation. This is significant for the indices in the matrix, in the sense that it affects how the weight is determined at a specific index point.
This special design of CNNs renders them capable to successfully capture the spatial and temporal dependencies in an image through the application of the relevant afore-described filters. The architecture shows a better fitting to the image dataset due to the reduction in the number of parameters involved and reusability of weights. In other words, the network can be trained to understand the sophistication of the image better. In this context, a CNN-based methodology is analyzed to evaluate its performance for forecasting applications with short period datasets with the motivation behind the CNN-based approach being its wide usage for image recognition applications. More specifically, the CNN models exploit the spatial locality of the pixel data in order to recognize an image. Similarly, in load time series, time locality, expressed by data stationarity and autocorrelation, forms the main motivation for utilizing CNN-based models in load forecasting applications. In our approach we transform the time series data into image-like data, taking advantage of the autocorrelation excibited by time series. Therefore, the first step is to perform statistical analysis and test the data for stationarity. If the data are not stationary then a second step of stationarity analysis is conducted by deploying a Unit Root Test, in order to capture more complex forms of stationarity, which is the case in most datasets.
2.2. Load Time Series Formulation and Statistical Analysis
The time-varying nature of both residential and community electrical load datasets is modeled by deploying smaller auto-regressive data models. An autoregressive model depicts that the output variable depends linearly on its own previous values and on a stochastic term, therefore the model is in the form of a stochastic difference equation. Specifically, an autoregressive model of order
p is defined as in Equation (
3):
Here are the parameters of the model, c is a constant, and is the error, where and .
The stationarity of the load time series is explored by deploying the unit root test [
61]. A linear stochastic process has a unit root, if 1 is a root of the process’ characteristic equation. Such a process is non-stationary but does not always have a trend. If the other roots of the characteristic equation lie inside the unit circle—that is, have a modulus (absolute value) less than one—then the first difference of the process will be stationary; otherwise, the process will need to be differentiated multiple times to become stationary. Due to this characteristic, unit root processes are also called difference stationary. Unit root processes may sometimes be confused with trend-stationary processes; while they share many properties, they are different in many aspects. It is possible for a time series to be non-stationary, yet to have no unit root and be trend-stationary. In both unit root and trend-stationary processes, their mean average may be increasing or decreasing over time; however, in the presence of a shock, trend-stationary processes are mean-reverting. The previous discrete-time stochastic process can be rewritten as an autoregressive process of order
p:
and
The time series is a serially uncorrelated, zero-mean stochastic process with constant variance
. If
is a root of the characteristic Equation (
6) then the stochastic process has a unit root.
The stochastic process has a unit root or, alternatively, is 1st order integrated. If
with a root of multiplicity
r, then the stochastic process is
integrated, denoted
. There are various tests to check the existence of a unit root. In this paper we use the Augmented Dickey Fuller (ADF) [
62] test which is widely used in statistics and econometrics. This analysis tests the null hypothesis that a unit root is present in a time series sample. If the unit root is not present then we cannot determine whether the time series is stationary. The ADF test is suitable for a large and more complicated set of time series models. The ADF index (
) is a negative number; the more negative it is, the stronger the rejection of the hypothesis of non-stationarity for the observed level of significance is. As can be seen from
Table 1, for all datasets the null hypothesis for non-stationarity has been rejected at the 0.01 significance level. Therefore it is quite likely that the electric load measured in all these cases displays the characteristic of trend or differential stationarity. The testing process of the ADF test is similar to the Dickey Fuller test but it is applied to the following model Equation (
7).
2.3. Stationarity Analysis
The CNN structure is based on image as an input and for this reason the first step of our methodology is to transform the time series-sequential data into an appropriate, image-like form in order to be processed by the CNN. Image data can be more efficiently processed by CNNs because of their ability to handle the local stationarity of the respective pixels. Image data, namely pixels are characterized as highly stationary and this is the feature that our investigation will leverage. By detecting such behavior in our data we will accordingly transform our time series into “image” like structures. Electrical load data, as mentioned before, appear to have time stationarity.
In order to determine the stationarity of each dataset we calculate their sample means (Mean in
Table 1) and standard deviations (STD in
Table 1). In a stationary process the unconditional joint probability distribution (and consequently its mean and standard deviations) does not change when shifted in time, so we split each dataset into two sets of equal size and we check how close their corresponding mean and standard deviations values are.
Table 1 contains the results of this analysis.
As it can be seen, only the office dataset display a clearly stationary behavior, while the Trento and Household data need further investigation. For these two datasets the second step of the stationary analysis, the Unit Root ADF test is performed. Those results are presented in
Table 2.
Apparently, the results of the ADF test indicate that both datasets can be assumed to be stationary, based on their corresponding p-values. Therefore the CNN model can now be further exploited.
2.4. Time Interval Selection
After examining stationarity, the next step would be to partition the dataset and transform it into an image-like matrix. For this step a deep statistical analysis is necessary, in order to determine the autocorrelation coefficients of the given datasets by applying the Auto-Correlation Function (ACF) test. The majority of multi-step forecasting strategies introduce errors, which are directly dependent on the forecasting horizon; the longer the forecasting horizon, the higher the errors. Consequently, reduced precision is inevitable as the horizon grows. To alleviate the absence of data stationarity, a novel technique is proposed that leads to a performance closer to uni-step forecasting methods. Specifically, we introduce a technique that manages to shorten the forecasting horizon so as to mimic a uni-step forecasting method. This is achieved by choosing the inputs of our model in an alternative way, which is explained below.
Despite that the method of determining the inputs of NN for STLF still remains an open question. The most common technique is to use as input the immediately preceded value. So, if we want to predict n we will have as input the value. This achieves great results in uni-step forecasting but for multi-step it introduces some errors, since the forecasted errors are accumulated and the final predicted value will not be accurate. In our case, the inputs are determined based on the experience or an-priori knowledge about the behavior of the system. A rather intuitive guess in load forecasting is that there must be instants in the past homologous to the current period, either during the same period on the previous day (24 h ago) or during the same period on the previous week, or previous two weeks, and so on.
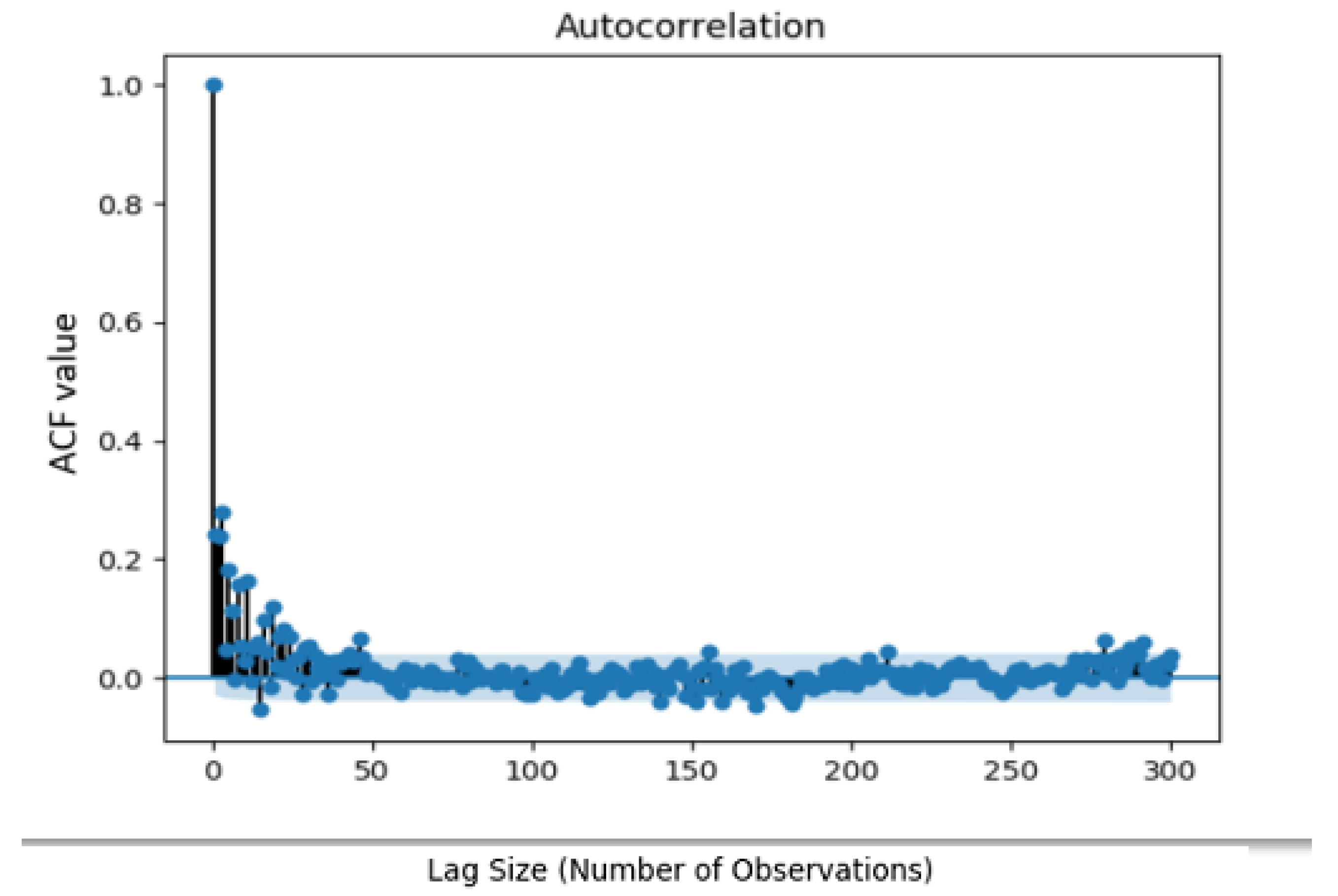
In this paper, the inputs for the neural networks are determined after examining the ACF; the assumption regarding homologous instants is analyzed in the second part of our proposed methodology. Based on this analysis it was derived that the most recent 24-h data exhibit the highest correlation with the forecasts and as such they form the basic input of the proposed methodology. In this way, the day ahead forecast problem is transformed into a uni-step problem. The first part of the analysis deals with the development of the auto-correlation plot of observations starting at time t and for two days duration.
Figure 2,
Figure 3 and
Figure 4 present the correlation analysis and auto-correlation plots for Trento, household and office datasets. The vertical axis shows the ACF value, which ranges from −1 to 1. The horizontal axis of the plot shows the size of the lag between the elements of the time series. For instance, the autocorrelation with lag 4 is the correlation between the time series elements and the corresponding elements observed four periods earlier.
As it can be seen, the highest correlation values are derived at the same time the previous or next day (every 24 h), which confirms the assumption of stationarity of
Table 1. According to these results, the highest correlated value, always for after one day, is the:
The first step of data transformation is then performed, since these results determine the one of the two dimension of our matrix, namely the columns. The following step is linked with the examination of the datasets in terms of these columns; more precisely we are trying to define a B (batch size) (highest correlated value) matrix. Additionally, it is evident that the highest correlated value, determined above will be the input for out model.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}