Methods to Apply a 3-Parameter Logistic Model to Wind Turbine Data




Abstract
1. Introduction
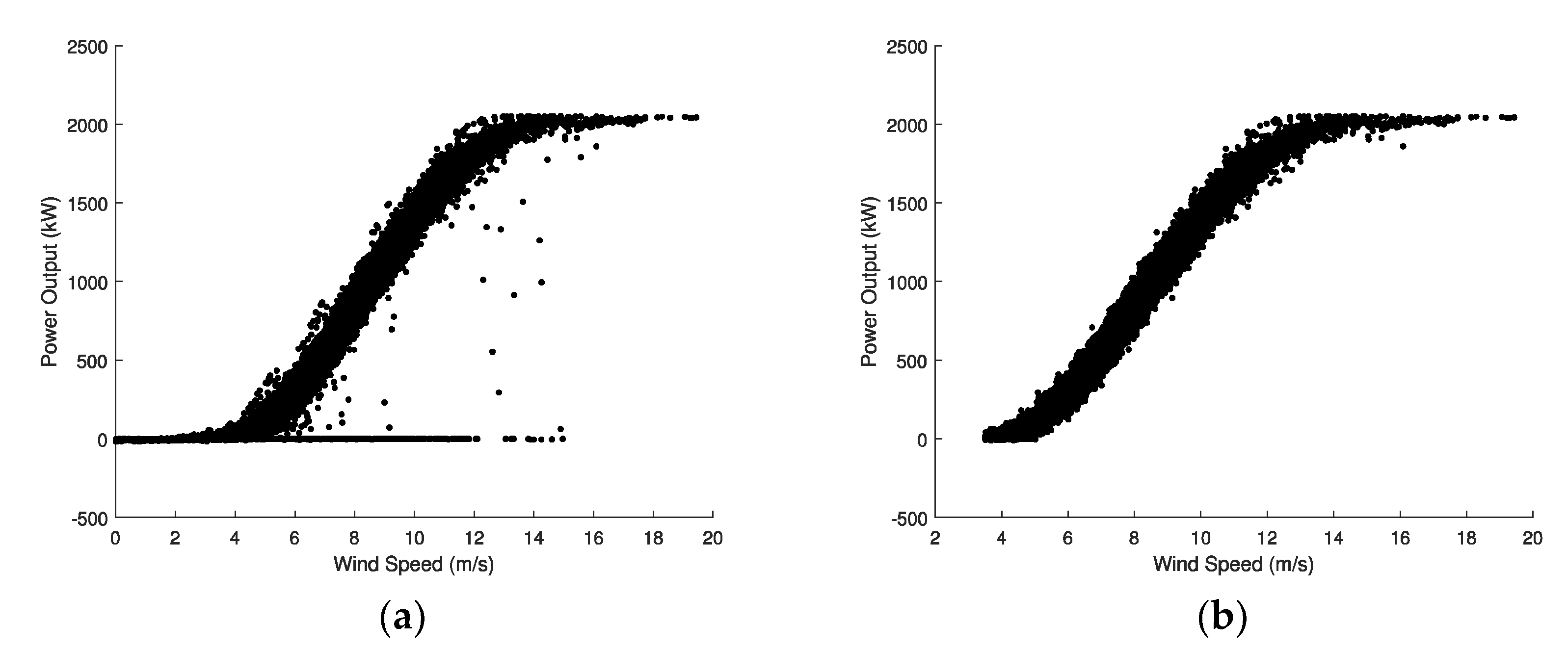
2. Data Filtering
- To discard wind speed values that are lower than the cut-in wind speed.
- To discard wind speed values that are 1.5 m/s above the cut-in wind speed, when they provide an output power lower than a 5% of the rated power.
- To discard wind speed values that are 1 m/s above the rated wind speed, when they provide an output power lower than a 75% of the rated power.
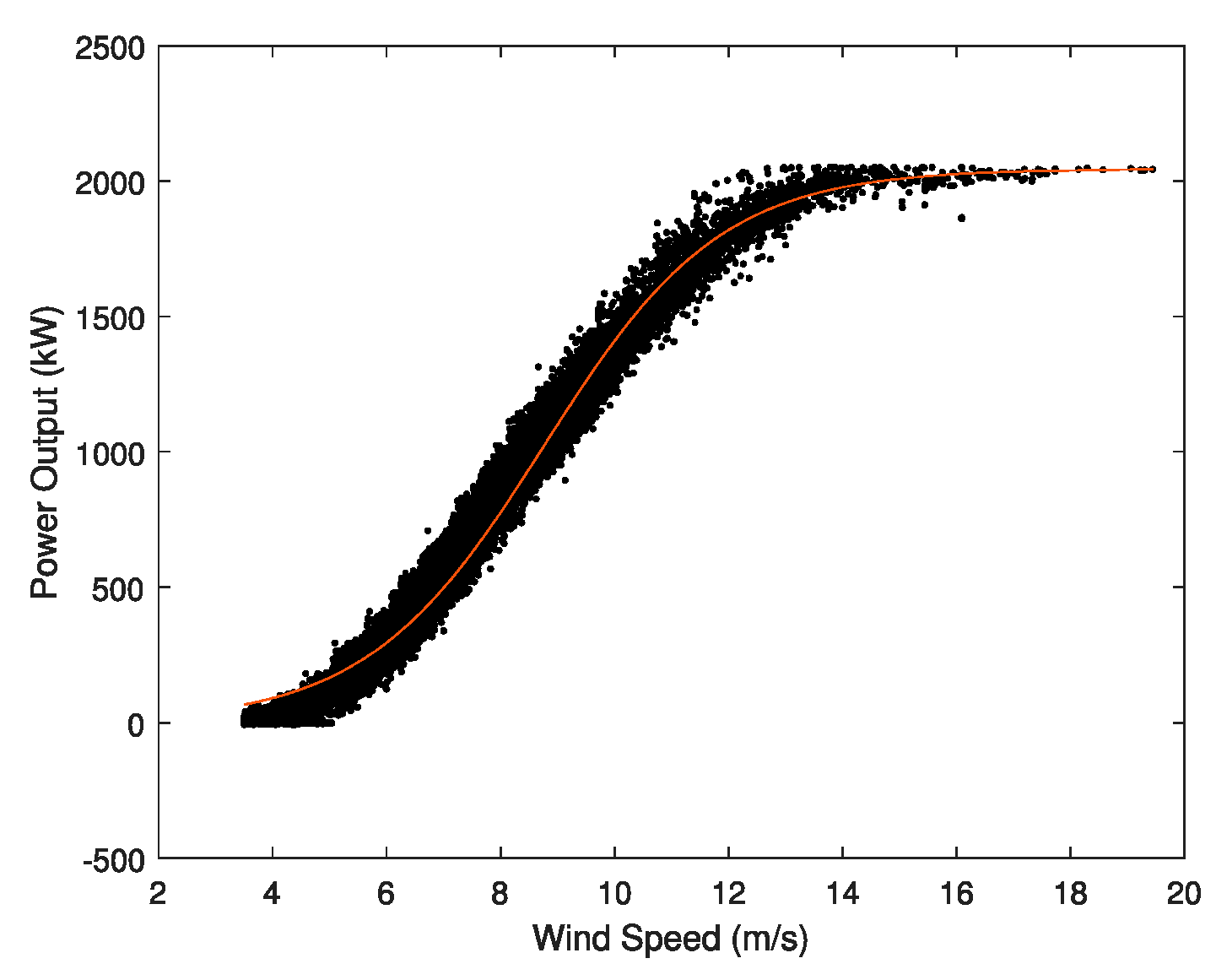
3. Methods Proposed
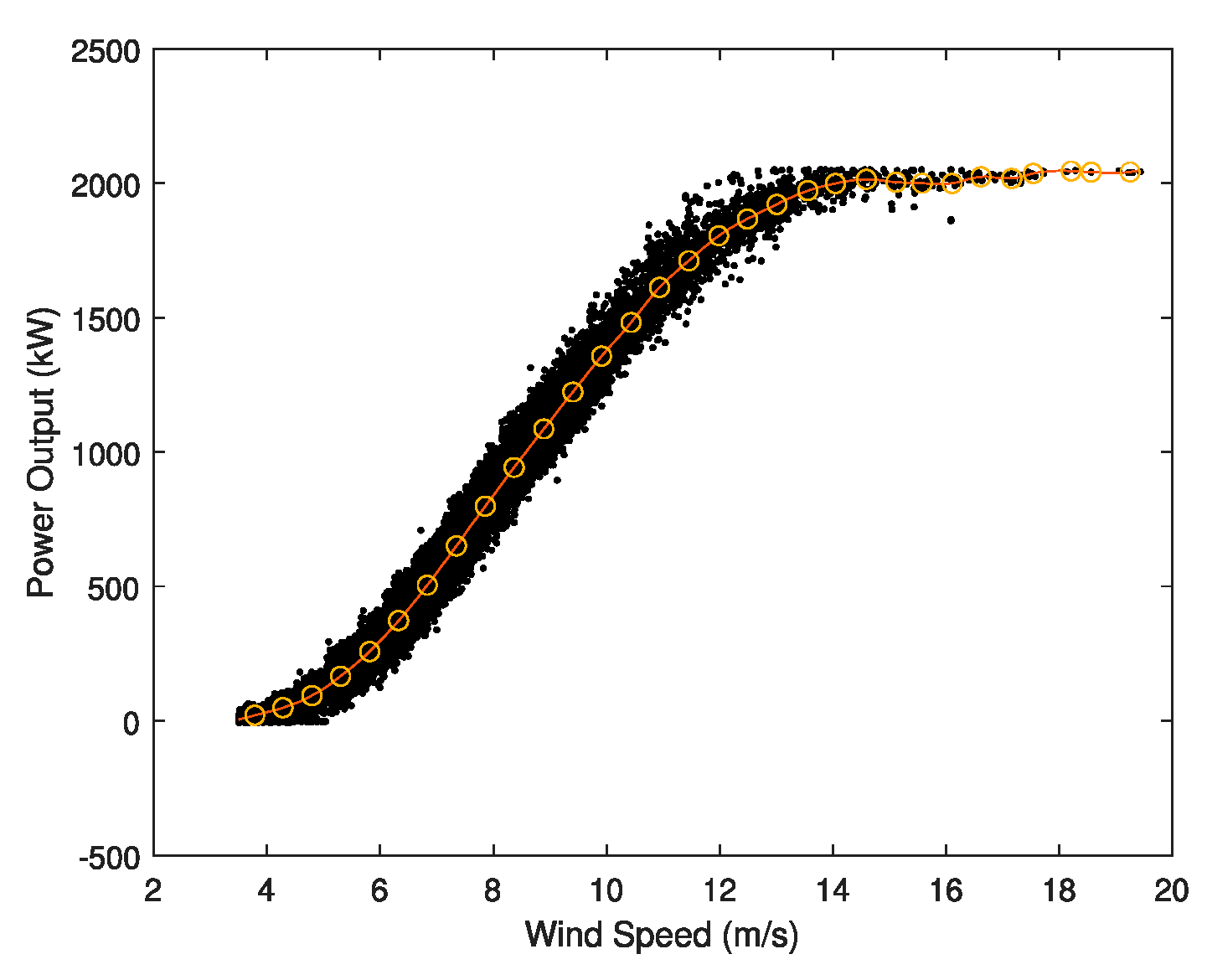
3.1. Spline
- Divide the data into intervals, one every 0.5 m/s. The identification of each interval is an integer or the mean value of two consecutive integers. Notice that the number of data on each interval may be different.
- Obtain the mean power on each interval and assign that value to the identification of the interval on each one, too. The result is a number of pairs of values (wind speed, output power).
- Finally, the spline according to Equation (1) is obtained. Using MATLAB (R2019a, Mathworks Inc.), all the points for the spline are provided.
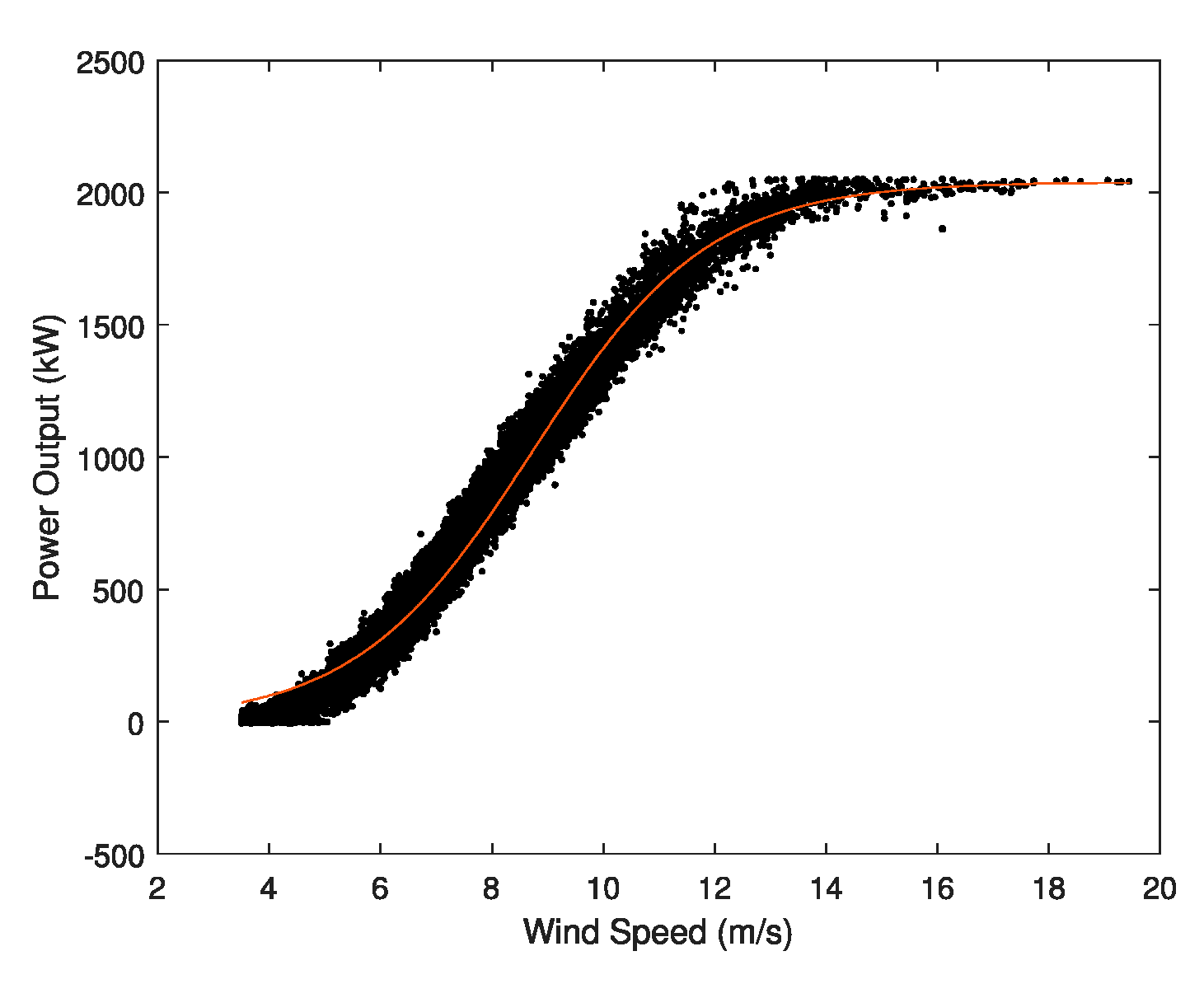
3.2. Clustering
3.3. Cloud Data
3.4. Cluster Simulation
- Divide the data in intervals, one every 0.5 m/s. The identification of each interval is an integer or and the mean value of two consecutive integers. This method is just an alternative when the number of data on each interval is different, as usual.
- Obtain the mean power and the standard deviation for each interval.
- Afterwards, a Normal distribution of the data on each interval is assumed and, with the parameters (µ, σ) obtained, values of power for each interval are simulated. The number of values generated for each interval has to be the same and has to be representative of all the possibilities (i.e. 200) The simulation has to be performed using MATLAB.
- Using the simulated values as data, the process depicted in the method Cloud data is applied.
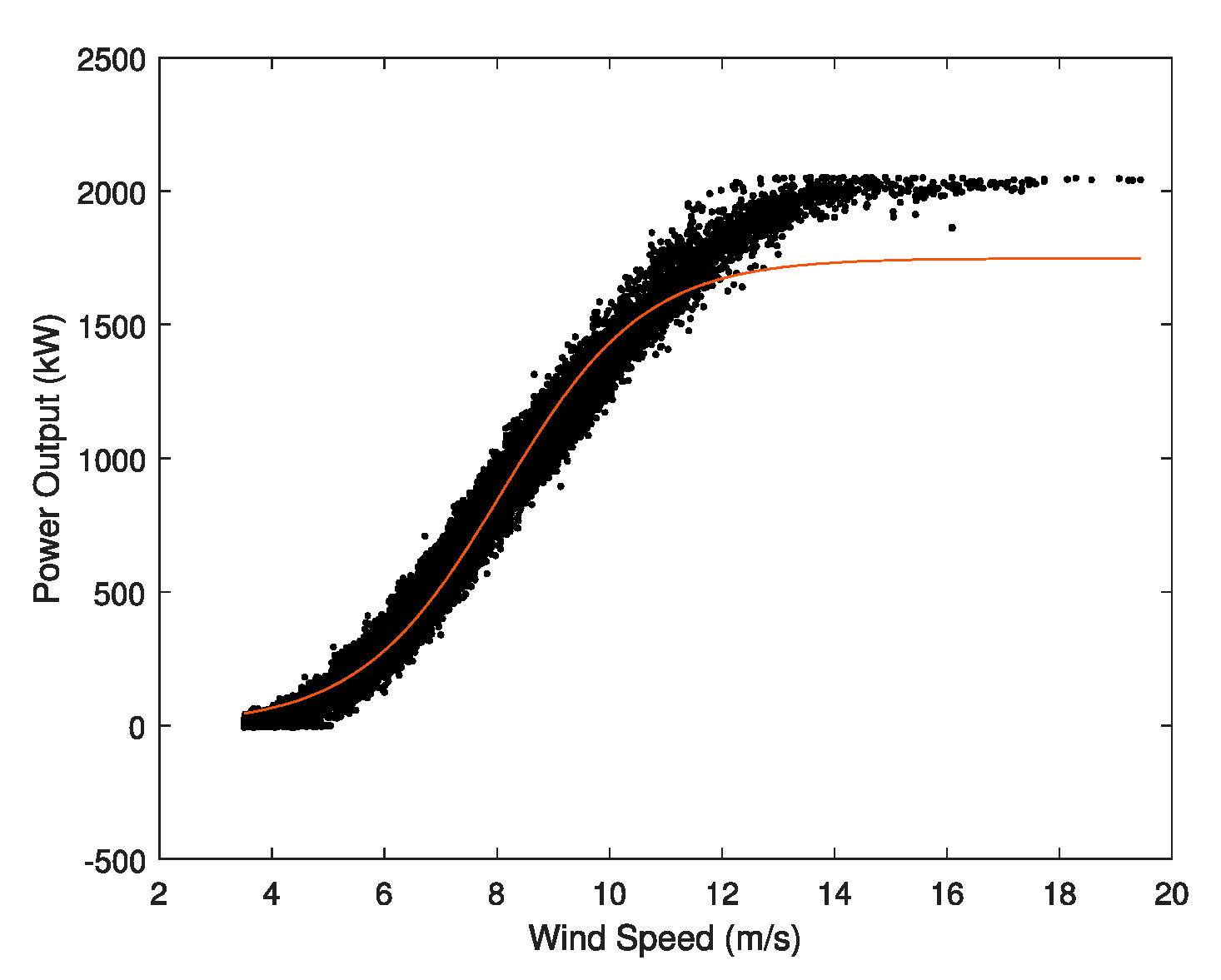
3.5. Maximum Error Cluster
4. Method Assessment
- Cloud Data MAPE: it measures the difference, in absolute value, between the value provided by the model and the output power value (from the filtered data). It is obtained according to Equation (4).
- Mean Values MAPE: it measures the difference, in absolute value, between the value provided by the model and the corresponding mean value of the power. In order to obtain the mean values, intervals of 0.5 m/s were taken. It is obtained according to Equation (5).
5. Case Study
- In the reference case the MV MAPE is always 0 because it is the definition of the reference. However, when obtaining the CD MAPE, the value obtained is close to 2%. The reason is that all the pairs of points do not correspond exactly with the spline models, there is some variability.
- In all cases, the MV MAPE is lower than the CD MAPE because the latter measures the errors of all the pairs of points with respect to the model, so the variability is higher. There is an exception to the previous rule and is in the case of the cloud data because, in that case, all the pairs of points participate with the same weight in the model.
- The errors provided by the Clustering and the Cluster simulation methods are very low in both cases. In fact, in both cases the difference between the CD MAPE and the MV MAPE is lower than the corresponding one of the spline.
- Comparing Clustering and Cluster simulation methods, they provide very similar results in this case.
- In the case of the Max error cluster method, the values of errors are a bit higher in all cases.
- The CD MAPE for the Spline is a bit lower than in the case of the first wind turbine. The reason may be that the variability of the output power of that wind turbine is lower than in the first one which can be due to performance reasons.
- The MV MAPE Cloud data is higher than in the first wind turbine while the CD Cloud data is lower. The reason may be the same as in the first comment, the pairs of points are not very dispersed, therefore, they provide a very good model, when assessing all data.
- It is the wind turbine with the lower errors from a general point of view. The MV MAPE Clustering and the MV MAPE Cluster simulation errors are close to 1%.
- Its behavior and levels of errors are very similar to the ones of the first one.
- The CD MAPE for the spline is over 2% (very high compared with the others).
- The CD MAPE Clustering is also very high (more than 3%).
- The MV MAPE for Clustering and Cluster simulation are very similar to the rest of wind turbines.
- The rest of errors are out of the ranges of the other three wind turbines.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- IEC 61400-12-1:2017. Wind Energy Generation Systems- Part 12-1: Power Performance Measurements of Electricity Producing Wind Turbines; International Electrotechnical Commission: Geneva, Switzerland, 2017.
- Kaiser, K.; Langreder, W.; Hohlen, H.; Højstrup, J. Turbulence Correction for Power Curves; Peinke, J., Schaumann, P., Barth, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Möllerström, E.; Ottermo, F.; Goude, A.; Eriksson, S.; Hylander, J.; Bernhoff, H. Turbulence influence on wind energy extraction for a medium size vertical axis wind turbine. Wind Energy 2016, 19, 1963–1973. [Google Scholar] [CrossRef]
- Davis, N.N.; Pinson, P.; Hahmann, A.N.; Clausen, N.-E.; Žagar, M. Identifying and characterizing the impact of turbine icing on wind farm power generation. Wind Energy 2016, 19, 1503–1518. [Google Scholar] [CrossRef]
- Hoolohan, V.; Tomlin, A.S.; Cockerill, T. Improved near surface wind speed predictions using Gaussian process regression combined with numerical weather predictions and observed meteorological data. Renew. Energy 2018, 126, 1043–1054. [Google Scholar] [CrossRef]
- Paiva, L.T.; Veiga Rodrigues, C.; Palma, J.M.L.M. Determining wind turbine power curves based on operating conditions. Wind Energy 2014, 17, 1563–1575. [Google Scholar] [CrossRef]
- Dai, J.; Tan, Y.; Shen, X. Investigation of energy output in mountain wind farm using multiple-units SCADA data. Appl. Energy 2019, 239, 225–238. [Google Scholar] [CrossRef]
- Han, X.; Liu, D.; Xu, C.; Shen, W.Z. Atmospheric stability and topography effects on wind turbine performance and wake properties in complex terrain. Renew. Energy 2018, 126, 640–651. [Google Scholar] [CrossRef]
- Vahidzadeh, M.; Markfort, C.D. Modified power curves for prediction of power output of wind farms. Energies 2019, 12, 1805. [Google Scholar] [CrossRef]
- Dai, J.; Yang, W.; Cao, J.; Liu, D.; Long, X. Ageing assessment of a wind turbine over time by interpreting wind farm SCADA data. Renew. Energy 2018, 116, 199–208. [Google Scholar] [CrossRef]
- Li, J.; Li, Q.; Zhu, J. Health condition assessment of wind turbine generators based on supervisory control and data acquisition data. IET Renew. Power Gener. 2019, 13, 1343–1350. [Google Scholar] [CrossRef]
- Staffell, I.; Green, R. How does wind farm performance decline with age? Renew. Energy 2014, 66, 775–786. [Google Scholar] [CrossRef]
- Choi, H.S.; Yu, H.; Lee, E.Y.; Loza, B.; Pacheco-Chérrez, J.; Cárdenas, D.; Minchala, L.I.; Probst, O. Comparative fatigue life assessment of wind turbine blades operating with different regulation schemes. Appl. Sci. 2019, 9, 4632. [Google Scholar]
- Sainz, E.; Llombart, A.; Guerrero, J.J. Robust filtering for the characterization of wind turbines: Improving its operation and maintenance. Energy Convers. Manag. 2009, 50, 2136–2147. [Google Scholar] [CrossRef]
- Wang, Y.; Hu, Q.; Li, L.; Foley, A.M.; Srinivasan, D. Approaches to wind power curve modeling: A review and discussion. Renew. Sustain. Energy Rev. 2019, 116, 109422. [Google Scholar] [CrossRef]
- Zhang, F.; Dai, J.; Liu, D.; Li, L.; Long, X. Investigation of the pitch load of large-scale wind turbines using field SCADA data. Energies 2019, 12, 509. [Google Scholar] [CrossRef]
- Lydia, M.; Kumar, S.S.; Selvakumar, A.I.; Prem Kumar, G.E. A comprehensive review on wind turbine power curve modeling techniques. Renew. Sustain. Energy Rev. 2014, 30, 452–460. [Google Scholar] [CrossRef]
- Bandi, M.M. Variability of the wind turbine power curve. Appl. Sci. 2016, 6, 262. [Google Scholar] [CrossRef]
- Khalfallah, M.G.; Koliub, A.M. Suggestions for improving wind turbines power curves. Desalination 2007, 209, 221–229. [Google Scholar] [CrossRef]
- Pallabazzer, R. Evaluation of wind-generator potentiality. Solar Energy 1995, 55, 49–59. [Google Scholar] [CrossRef]
- Salameh, Z.M.; Safari, I. Optimum windmill-site matching. IEEE Trans. Energy Convers. 1992, 7, 669–676. [Google Scholar] [CrossRef]
- Villanueva, D.; Feijóo, A.; Pazos, J.L. Simulation of correlated wind speed data for economic dispatch evaluation. IEEE Trans. Sustain. Energy 2012, 3, 142–149. [Google Scholar] [CrossRef]
- Rodbard, D.; Hutt, D.M. Statistical analysis of radioimmunoassays and immunoradiometric (labeled antibody) assays. In Radioimmunoassay and Related Procedures in Medicine; International Atomic Energy Agency (IAEA): Vienna, Austria, 1974; Volume 1, pp. 165–192. [Google Scholar]
- Gottschalk, P.G.; Dunn, J.R. The five-parameter logistic: A characterization and comparison with the four-parameter logistic. Anal. Biochem. 2005, 343, 54–65. [Google Scholar] [CrossRef] [PubMed]
- Bokde, N.; Feijóo, A.; Villanueva, D. Wind turbine power curves based on the weibull cumulative distribution function. Appl. Sci. 2018, 8, 1757. [Google Scholar] [CrossRef]
- Richards, F.J. A flexible growth function for empirical use. J. Exp. Bot. 1959, 10, 290–301. [Google Scholar] [CrossRef]
- Villanueva, D.; Feijóo, A.E. Reformulation of parameters of the logistic function applied to power curves of wind turbines. Electric Power Syst. Res. 2016, 137, 51–58. [Google Scholar] [CrossRef]
- Villanueva, D.; Feijóo, A. Comparison of logistic functions for modeling wind turbine power curves. Electric Power Syst. Res. 2018, 155, 281–288. [Google Scholar] [CrossRef]
- Goudarzi, A.; Swanson, A.G.; Kazemi, M.; Wang, K. Intelligent wind turbine power curve modelling using the third version of cultural algorithm (CA3). Int. J. Renew. Energy Res. 2017, 7, 1340–1351. [Google Scholar]
- Jafari, S.; Majidi Pishkenari, M.; Sohrabi, S.; Feizarefi, M. Advanced modeling and control of 5 MW wind turbine using global optimization algorithms. Wind Eng. 2019, 43, 488–505. [Google Scholar] [CrossRef]
- Taslimi-Renani, E.; Modiri-Delshad, M.; Elias, M.F.M.; Rahim, N.A. Development of an enhanced parametric model for wind turbine power curve. Appl. Energy 2016, 177, 544–552. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Manufacturer | Model | Rated Power (kW) | Hub Height (m) | Rotor Diameter (m) | Rated Wind Speed (m/s) | Cut-in Wind Speed (m/s) | Cut-out Wind Speed (m/s) |
|---|---|---|---|---|---|---|---|
| Senvion | MM82 | 2050 | 80 | 82 | 14.5 | 3.5 | 25 |
| 2013 | 2014 | 2015 | 2016 | 2017 | |
|---|---|---|---|---|---|
| CD MAPE spline (%) | 1.71 | 1.64 | 2.14 | 1.94 | 2.08 |
| MV MAPE spline (%) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| CD MAPE clustering (%) | 2.62 | 2.60 | 3.27 | 3.17 | 3.23 |
| MV MAPE clustering (%) | 1.16 | 1.40 | 1.29 | 1.38 | 1.81 |
| CD MAPE cloud data (%) | 2.26 | 2.11 | 2.77 | 2.57 | 2.66 |
| MV MAPE cloud data (%) | 6.86 | 6.34 | 5.87 | 7.07 | 6.94 |
| CD MAPE cluster simulation (%) | 2.57 | 2.53 | 3.15 | 3.05 | 3.23 |
| MV MAPE cluster simulation (%) | 1.21 | 1.39 | 1.34 | 1.44 | 2.02 |
| CD MAPE max error cluster (%) | 2.70 | 2.68 | 3.20 | 3.13 | 4.71 |
| MV MAPE max error cluster (%) | 1.76 | 1.62 | 2.24 | 2.52 | 4.63 |
| 2013 | 2014 | 2015 | 2016 | 2017 | |
|---|---|---|---|---|---|
| CD MAPE spline (%) | 1.50 | 1.30 | 1.79 | 1.68 | 1.76 |
| MV MAPE spline (%) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| CD MAPE clustering (%) | 2.61 | 2.49 | 2.99 | 2.95 | 2.81 |
| MV MAPE clustering (%) | 1.25 | 1.36 | 1.52 | 1.35 | 1.46 |
| CD MAPE cloud data (%) | 2.01 | 1.73 | 2.34 | 2.24 | 2.33 |
| MV MAPE cloud data (%) | 8.85 | 8.60 | 6.91 | 7.77 | 6.81 |
| CD MAPE cluster simulation (%) | 2.51 | 2.41 | 2.91 | 2.79 | 2.69 |
| MV MAPE cluster simulation (%) | 1.30 | 1.42 | 1.54 | 1.43 | 1.48 |
| CD MAPE max error cluster (%) | 2.66 | 2.52 | 3.29 | 3.11 | 2.65 |
| MV MAPE max error cluster (%) | 1.60 | 1.59 | 1.53 | 1.55 | 2.05 |
| 2013 | 2014 | 2015 | 2016 | 2017 | |
|---|---|---|---|---|---|
| CD MAPE spline (%) | 1.50 | 1.42 | 1.76 | 1.64 | 1.75 |
| MV MAPE spline (%) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| CD MAPE clustering (%) | 2.42 | 2.42 | 2.80 | 2.82 | 2.78 |
| MV MAPE clustering (%) | 1.11 | 1.26 | 1.27 | 1.18 | 1.18 |
| CD MAPE cloud data (%) | 2.03 | 1.89 | 2.35 | 2.22 | 2.35 |
| MV MAPE cloud data (%) | 6.57 | 5.99 | 5.09 | 6.33 | 6.11 |
| CD MAPE cluster simulation (%) | 2.31 | 2.30 | 2.69 | 2.64 | 2.70 |
| MV MAPE cluster simulation (%) | 1.14 | 1.32 | 1.29 | 1.24 | 1.19 |
| CD MAPE max error cluster (%) | 2.54 | 2.68 | 3.51 | 2.89 | 3.04 |
| MV MAPE max error cluster (%) | 1.41 | 1.28 | 1.46 | 1.64 | 2.19 |
| 2013 | 2014 | 2015 | 2016 | 2017 | |
|---|---|---|---|---|---|
| CD MAPE spline (%) | 2.04 | 1.62 | 2.33 | 2.16 | 2.27 |
| MV MAPE spline (%) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| CD MAPE clustering (%) | 4.69 | 2.85 | 3.62 | 3.49 | 3.50 |
| MV MAPE clustering (%) | 1.60 | 1.51 | 1.52 | 1.40 | 1.27 |
| CD MAPE cloud data (%) | 3.48 | 2.14 | 3.00 | 2.83 | 2.96 |
| MV MAPE cloud data (%) | 11.45 | 6.88 | 6.36 | 7.08 | 7.37 |
| CD MAPE cluster simulation (%) | 4.93 | 2.78 | 3.42 | 3.33 | 3.39 |
| MV MAPE cluster simulation (%) | 1.50 | 1.53 | 1.58 | 1.47 | 1.29 |
| CD MAPE max error cluster (%) | 3.84 | 2.83 | 4.06 | 4.15 | 3.71 |
| MV MAPE max error cluster (%) | 3.97 | 2.04 | 1.86 | 3.30 | 2.96 |
| Optimization Method | Cloud Data MAPE (%) | Mean Values MAPE (%) |
|---|---|---|
| Spline | 1.80 | 0.00 |
| Clustering | 3.01 | 1.36 |
| Cloud data | 2.41 | 7.06 |
| Cluster simulation | 2.92 | 1.41 |
| Maximum error of cluster | 3.19 | 2.16 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villanueva, D.; Sixto, A.; Feijóo, A.; Fernández, A.; Miguez, E. Methods to Apply a 3-Parameter Logistic Model to Wind Turbine Data. Appl. Sci. 2020, 10, 3317. https://doi.org/10.3390/app10093317
Villanueva D, Sixto A, Feijóo A, Fernández A, Miguez E. Methods to Apply a 3-Parameter Logistic Model to Wind Turbine Data. Applied Sciences. 2020; 10(9):3317. https://doi.org/10.3390/app10093317
Chicago/Turabian StyleVillanueva, Daniel, Adrián Sixto, Andrés Feijóo, Antonio Fernández, and Edelmiro Miguez. 2020. "Methods to Apply a 3-Parameter Logistic Model to Wind Turbine Data" Applied Sciences 10, no. 9: 3317. https://doi.org/10.3390/app10093317
APA StyleVillanueva, D., Sixto, A., Feijóo, A., Fernández, A., & Miguez, E. (2020). Methods to Apply a 3-Parameter Logistic Model to Wind Turbine Data. Applied Sciences, 10(9), 3317. https://doi.org/10.3390/app10093317