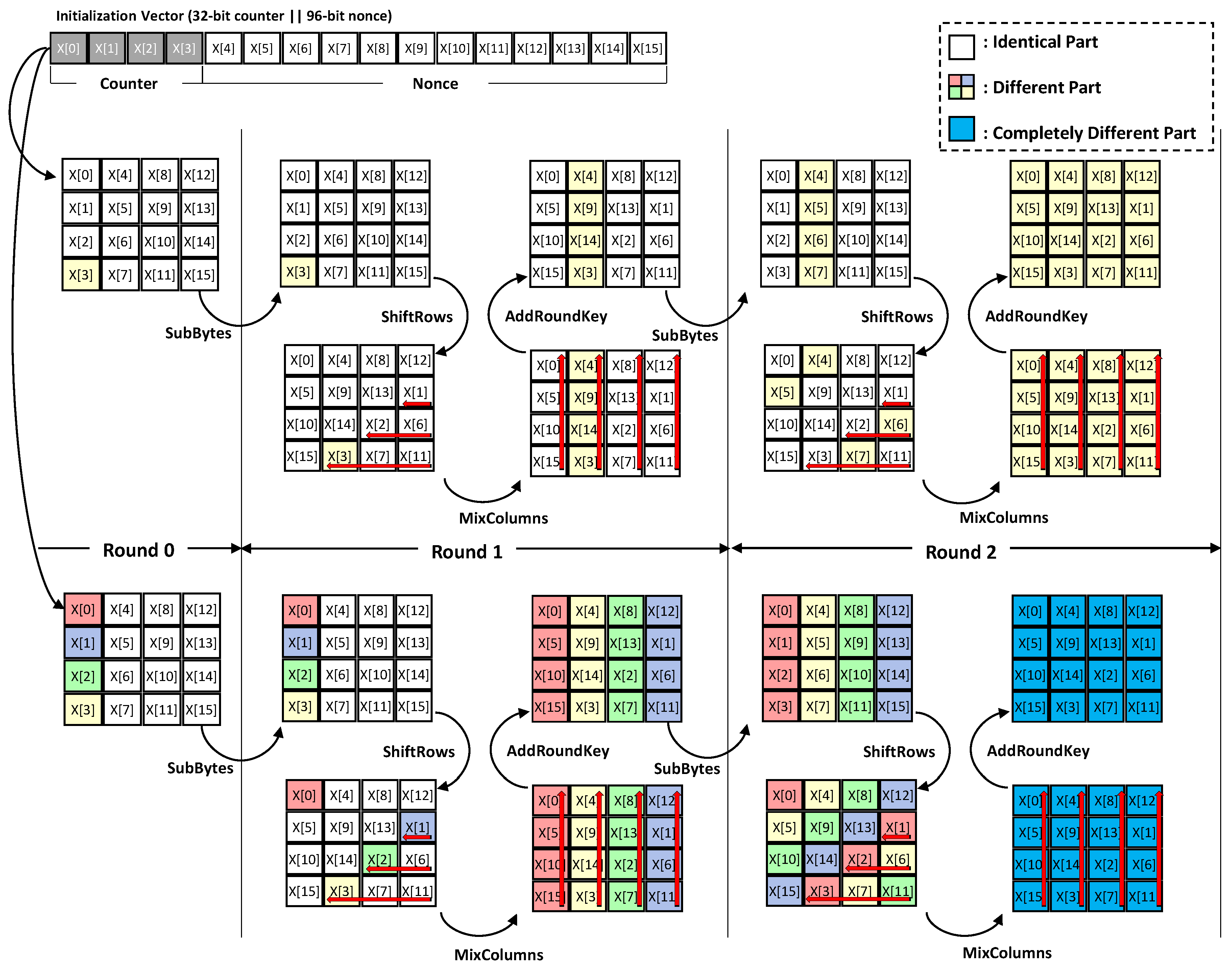
This section describes distinguished features of suggested method by comparing previous works by Seo and Kim [
10]. First, the previous work utilized eight garbage registers to calculate the GHASH function. However, the proposed method only utilizes one garbage register without loss of security against CPA, SPA, and TA. In addition, multiplication computations are optimized to save the register. In total, eight more registers are utilized for Karatsuba algorithm than the previous method. Furthermore, the register optimized version is also investigated Second, the repeated value (
) of GHASH function allows to pre-compute the part of Karatsuba operand. The pre-computed value is generated once and called several times, which reduces the execution timing. Third, the fast reduction by Shay and Kounavis performs faster reduction than the implementation by Seo and Kim [
10,
16]. The method is optimized for the low-end microcontroller.
4.1. Optimized Implementation of PAGE
The Block Comb method by Seo and Kim uses 8 garbage registers for Dummy XOR operation to prevent SPA, TA, and CPA [
10]. Values stored in eight garbage registers are not used during the multiplication. Garbage registers only load meaningless data in order not to be distinguished from the real operation. The attacker cannot distinguish the real operation from the original power trace, which prevents leakage of secret value.
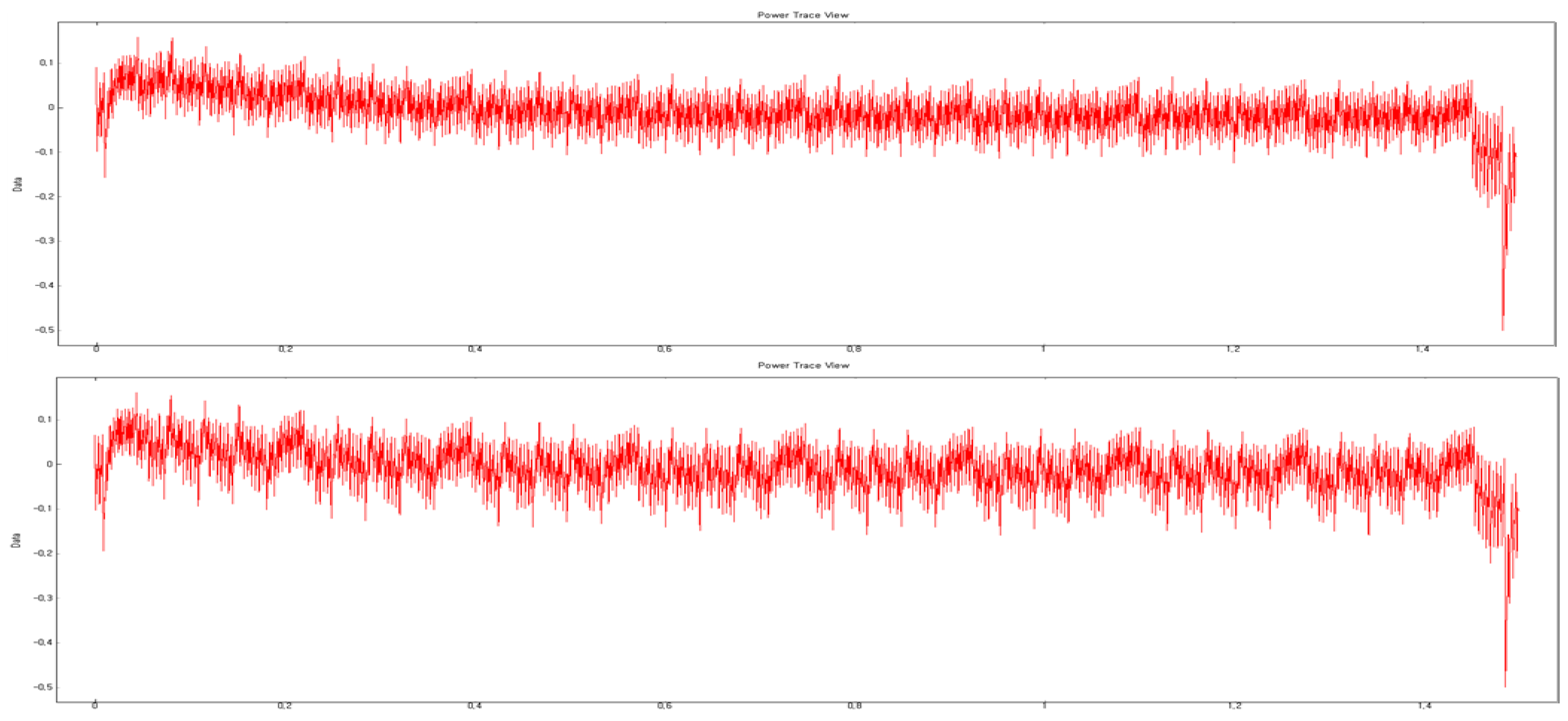
The same effect can be achieved by using only one of eight garbage registers. In
Figure 2, the power trace using eight garbage registers in 32-bit multiplication is shown. Two power traces have regular pattern. In the 11-th line of Algorithm 1, the result of XOR operation using eight garbage registers (
R0∼
R7) can be obtained using only one register (
R24).
| Algorithm 1 Proposed method for 32-bit multiplication. |
- Input:
: 32-bit multiplicand A (), 32-bit multiplier B (), Garbage result (), and real result (). - Output:
: Result C (64-bit) = . … - 1:
- 2:
forl = 7 to 0 do - 3:
for m = 3 to 0 do - 4:
if the l-th bit of ==1 then - 5:
- 6:
for k = 0 to 3 do - 7:
- 8:
end for - 9:
else - 10:
for k = 0 to 3 do - 11:
- 12:
end for - 13:
end if - 14:
end for - 15:
() ← () - 16:
end for …
|
In addition, the performance is improved further by applying Liu et al’s multiplication method to the proposed method. Seo and Kim proposed to shift 40-bit multiplicand (A) for a 64-bit multiplier, rather than shifting 64-bit accumulator. This approach reduces 29 shift instructions per 32-bit multiplication operation. However, the multiplication method suggested by Seo and Kim does not show a big difference in performance compared to the method suggested by Liu et al. According to Seo and Kim, the number of shift instructions can be reduced compare to Liu et al’s method. However, the XOR instruction goes one more operation per bit, which leads to addition of 32 more XOR instructions when calculation 40-bit multiplicand (A). Since five registers are needed to store the 40-bit multiplicand (A), one more register is required compared to the Liu et al’s technique. Liu et al.’s approach is used for multiplication and one register is saved. These spare registers are used in the Karatsuba algorithm to improve the performance. For the optimal number of register utilization, the version without using spare registers is also investigated. Currently, RISC-V introduces new architecture for future microcontrollers. The optimal register utilization can contribute to the optimal architecture design.
4.2. Karatsuba Algorithm for GHASH
Karatsuba algorithm is well known asymptotically fast multiplication method and the proposed implementation also utilizes the Karatsuba algorithm for high performance.
First, the multiplication is performed with lower 32-bit of 64-bit operands () and 64-bit result (L) is obtained. Second, the multiplication is performed with lower 32-bit of 64-bit operands () and 64-bit result (H) is obtained. Third, XOR operation is performed between the upper part and the lower part of the A and B, respectively. Values are multiplied and output the final result (M). The L, H, and M are XORed together and stored in M, again. Lastly, shifted H (), shifted M () and L are XORed and the final 128-bit result (C) is obtained.
Karatsuba algorithm needs a buffer to store intermediate results of each operation. In the Block Comb method proposed by Seo and Kim, the size of intermediate results is over than given size of general purpose registers. For this reason, the part of intermediate result should be stored in STACK. However, accessing to STACK memory (i.e., 2 clock cycles) requires high-overheads than register accesses (i.e., 1 clock cycle). The proposed method uses eight more registers to maintain the intermediate result. For the register optimized version, the intermediate result is stored in STACK memory.
In Algorithm 2, the proposed implementation does not reserve the intermediate result of the Karatsuba calculation, such as
L,
H, and
M, in the
STACK. Instead, only values needed for the following operation are stored using the
to
registers.

When the 128-bit result (C) and the 64-bit intermediate result (M) are divided into 8-bit units, it can be expressed as () and (), respectively. Among them, and store the upper 32-bit multiplication result and the lower 32-bit multiplication result.
The result from to is XORed with the M. The final result of is calculated by . Values affected by XOR, such as and , are stored after each 32-bit multiplication operation. In addition, values used to make can be XORed and stored in advance. Afterward, 64-bit multiplication is performed without loading and storing procedures from the STACK.
In the case of the GHASH function, the associated data and cipher text are XORed and multiplied by the hash key value (). In this process, the B value, which is a multiplier of all 128-bit multiplication operations, is fixed to the value. This repeated value (i.e., ) can be pre-computed and reserved to reduce the number of XOR operations and memory accesses.








{kind=link}
{kind=link}
{kind=link}
{kind=link}