1. Introduction
Object tracking has been widely used in the field of computer vision [
1], such as in automatic driving, precision guidance, and video surveillance. The pursuit of certain precision, speed, and robustness in these applications has important engineering significance. Most object tracking algorithms estimate the location and scale of the object in the subsequent frames based on the given object bounding box in the first frame. This mimics human visual attention and eye movements by rapidly finding important objects in a video sequence. However, in practice, there are significant challenges, such as motion blur, occlusion, and background clutter [
2,
3] which still hinder the efficiency and accuracy of a tracker.
Most general trackers learn necessary information from the given first frame to model a tracking target and estimate the position in the subsequent frames via the initially learned information. Complicated background clutter is a crucial issue for robust object tracking. Most tracking algorithms rely on model updates in each frame to sufficiently learn about the target’s appearance, which is prone to drift in the case of a noisy update. Thereby, strategies of target description and model update are both paramount to an outstanding tracker.
Owing to extensive studies in recent years, a number of algorithms mostly satisfy the requirements of object tracking. However, there is still room for improvement in terms of accuracy and robustness. In this paper, an object tracking algorithm based on sum of template and pixel-wise learners (Staple) [
4], termed robust Staple (rStaple), is proposed. It can simultaneously improve tracking accuracy while maintaining real-time performance based on the foundation in Staple of a combination of correlation filters and a color histogram, which is inherently robust to both color changes and deformations.
Specifically, we combine histogram of oriented gradient of Felzenszwalb’s variant (fHOG) [
5,
6] with the color names (CN) feature [
7,
8] to train the correlation filter. This further reduces the impact of target deformation and the boundary effect [
9], and effectively overcomes the instability of the single histogram of oriented gradient (HOG) feature in Staple. In addition, the proposed method also learns the color histogram score as in Staple, but with the difference that significant enhancements are applied to the score map of color histograms. Therefore, the final tracking result could be located via combining the response map of the correlation filter and color histogram score. Moreover, Staple adopts a scheme to update learned filters each frame for handling the target appearance variations over time. However, such a scheme tends to bring about model drift due to occlusion or being out of view. To address this problem, we adopt a detection mechanism which can effectively detect despite severe temporary occlusion or when the target is missing in the current frame. In this way, the correlation filters terminate the model update. The model restarts updating when the target is re-detected correctly. Therefore, this flexible mechanism can avoid tracking failure due to model corruption in subsequent frames. Finally, the proposed rStaple is tested on the Visual Tracking Benchmark datasets OTB2013 [
10] and OTB2015 [
11], and experimental results demonstrate its effectiveness.
The remaining sections of the paper are organized as follows. Some previous attempts to solve the object tracking problem are presented in
Section 2.
Section 3 describes the basic preliminaries, including the kernelized correlation filter and color histogram. In
Section 4, the procedure of our proposed rStaple tracking approach is described. Moreover, the detailed specification for implementing the algorithm is presented.
Section 5 shows the evaluation results of experiments on the test datasets. Finally, conclusions are presented in
Section 6.
2. Related Work
Existing object tracking algorithms mainly consist of two categories: generative model methods and discriminative model methods [
2,
12,
13]. The generative model method builds a model for the given target area in the initial frame. The target location is estimated via searching for the area which is most similar to the model in the subsequent frames. Typical algorithms of the generative model method are adapative structural local sparse appearance (ASLA) [
14], locality sensitive histograms (LSHT) [
15], locally orderless tracking (LOT) [
16], and scale-adaptive mean-shift (SAMS) [
17]. However, these tracking algorithms usually lack the discriminative capability of distinguishing the target from its background. Consequently, the generative model-based algorithms tend to suffer low tracking accuracy, thus limiting their applications. Most state-of-the-art tracking algorithms adopt the tracking-by-detection method, which is a form of discriminative model. A discriminative model method [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30] treats object tracking as an object detection task in each frame wherein image features are collected to train a classifier. Specifically, the target area and background are regarded as positive samples and negative samples, respectively. The optimal solution in the subsequent frames can be acquired using the trained classifier. In the tracking process, the output in each frame is continuously used as a positive sample and the background as a negative sample for training the classifier online.
Recently, correlation filters [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27] and deep learning-based trackers [
28,
29,
30,
31,
32,
33,
34,
35] have become two active research topics of discriminative model methods with outstanding performance. Owing to the attractive property of extracting deep features, trackers based on deep learning have demonstrated great potential for the object tracking task. Bertinetto et al. proposed a fully-convolution Siamese network (SiamFC) [
29] for object tracking, which extracted deep features of the searching and target areas using the same fully-convolutional network to find the target position. Valmadre et al. proposed an asymmetric Siamese network architecture named CFNet [
30]. They interpreted the correlation filter learner as a differentiable layer in a deep neural network and made full use of the advantages of the correlation filter in object tracking. Choi et al. proposed the Attentional Correlation Filter Network (ACFN) [
31], which introduced an attentional mechanism into a novel tracking framework to increase robustness and computational efficiency. Hyeonseob and Han proposed a multi-domain convolutional neural network (CNN) for visual tracking, which was referred to as a Multi-Domain Network (MDNet) [
32]. It pre-trained a CNN using a large set of data to obtain a generic target representation. Subsequently, the domain-specific layers of the CNN were trained online to learn the specific target representation of the tracking target in a new sequence. Recently, Yuan et al. [
33] proposed an anti-occlusion tracker which extracted features from different layers of a residual neural network (ResNet) to produce response maps and an occlusion detection strategy was introduced to prevent model drift. Lu et al. [
34] exploited a novel deconvolution network to enlarge the low spatial resolution feature maps in a deep convolution network and summarized the feature maps to better represent the target appearance. Generally, deep learning-based algorithms rely on expensive hardware components such as graphics processing units (GPUs). In addition, a large number of datasets are required to pre-train the network. In spite of great performance in terms of accuracy, their running speed is generally slow on central processing unit (CPUs). Moreover, with both the proposal of light networks, such as MobileNet [
36], and the advent of low-cost hardware with GPUs and embedded segments, e.g., NVIDIA Jetson TX2 and Google Coral, deep learning based algorithms can increasingly be applied to smaller devices such as drones, robots, and medical devices.
As a trade-off between accuracy and efficiency, correlation filter-based algorithms have attracted extensive attention in recent years. Bolme et al. proposed a new type of correlation filter for visual tracking, named Minimum Output Sum of Squared Error (MOSSE) [
18]. Since MOSSE only uses a single-channel grayscale feature, its practical performance is not desirable. However, the speed is over 600 frames per second (FPS), prompting researchers to discover the potential value of correlation filters. Henriques et al. developed the circulant structure of tracking-by-detection with kernels (CSK) [
19], which adopted the well-established theory of circulant matrices based on MOSSE. The resulting tracker increases the number of training samples, thus improves the tracking accuracy. Henriques et al. proposed a high-speed tracker which trains a discriminant classifier using Kernelized Correlation Filters (KCF) [
20]. The derived tracker extended the single-channel grayscale feature to the multi-channel histogram of oriented gradient (HOG) [
5] feature and maintained high-speed capability. Aiming at scale adaption, Discriminative Scale Space Tracking (DSST) [
21] learned two separated discriminative correlation filters for translation and scale estimation. Since the circulant matrix is introduced for sampling in the correlation filters, the cosine window is applied to ensure the rationality of samples. Nevertheless, the cosine window would lead to the boundary effect [
9] which weakens the performance of trackers on fast motion targets. To solve that problem, Danelljan et al. added spatial regularization to the discriminative correlation filters (SRDCF) [
23]. Specifically, this penalizes correlation filter coefficients near the boundary and enlarges the searching area to learn more negative samples. One obvious shortcoming is that it destroys the closed form of discriminative correlation filters (DCF); instead, it uses Gauss–Seidel iterative optimization to obtain the optimal solution. As a result, it increases tracking quality at the expense of running speed. Ma et al. [
24] proposed a long-term tracker which learns both the long-term and short-term memory of target appearance. For preventing severe tracking failures, a learned detector is used to recover the target position. Recently, Zhou et al. [
25] applied adaptive context awareness and trained a structural correlation filter for tracking, to make the tracker learn more context information. Shin et al. [
26] proposed a failure detection and re-tracking algorithm based on KCF performed in real-time. Li et al. [
27] trained a large margin correlation filter to maximize the margin between the tracking target and its background. In addition, the correlation filter was trained with multi-level scale supervision to make it sensitive to scale variation.
In this paper, we propose a tracker which follows the state-of-the-art algorithm Staple mentioned above. The proposed tracker uses more comprehensive features to describe the target, as well as an adaptive model update strategy to avoid model drift to make the tracker more robust.
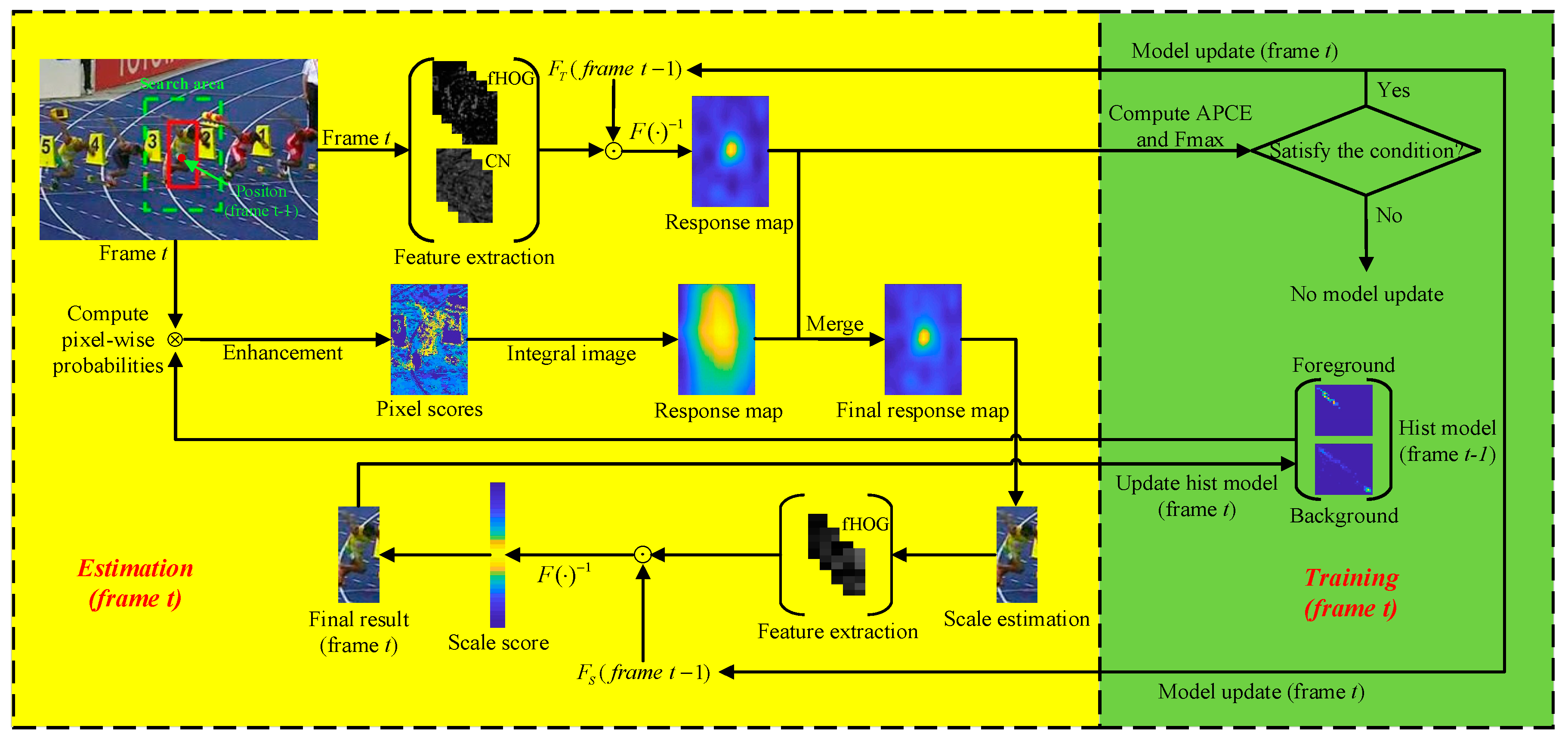
4. Proposed rStaple Tracking Method
In this section, the detailed procedure of the proposed real-time object tracking algorithm termed the robust sum of template and pixel-wise learners (rStaple) is presented. It is based on the Staple [
4], an effective tracker which has been widely used in visual tracking.
To initialize the tracker in the first frame of video sequence, the proposed method primarily extracts fHOG [
6] and CN [
7,
8] from the searching area around the given target position. The combination of these two handcrafted features is used to train a translation filter
. Secondly, the histogram models of the foreground and background are established by current target information. Finally, our tracker trains a 1-D scale filter with fHOG extracted from the initial searching area.
In subsequent frames, firstly, the combination of fHOG and CN of the searching area are extracted to compute a translation filter response map via the translation filter
learned in previous frames. Then, we compute the color histogram pixel score map by the histogram model of previous frames, and apply a significant enhancement to the original pixel score map. The final translation score map is a linear combination of the above translation filter response map and the enhanced color histogram score map. Thus, the target position in this frame can be obtained via the final translation score map. Meanwhile, we use fHOG extracted in the current frame and the scale filter learned in the previous frames for scale estimation. Note that the scale estimation can be obtained directly based on the estimated translation result, which greatly reduces the computational cost. Finally, quantitative indicators average peak-to correlation energy (
APCE) [
44] and
are introduced to detect the state of tracking target for the adaptive model update. If the indicators computed from the translation filter response map satisfy the predetermined condition, the translation filter and scale filter are updated in the current frame.
Figure 1 illustrates the overall procedure of the proposed rStaple. The area in yellow represents the estimation part in frame
and the green area is the training part in frame
. In particular, the training part is performed after estimation.
4.1. Feature Fusion
Researchers have demonstrated that feature extractors usually play the most important role in various object trackers [
1]. Therefore, it is necessary to select appropriate features for target modelling. In this paper, fHOG and CN are combined to get a 42-D feature to meet the goal. The combined feature is used to train a translation filter which can learn more information about the tracking target and background.
HOG is one of the most popular features in computer vision. Specifically, it is mainly used to describe the gradient change information in images, and is robust to translation, illumination variation, and posture changes. An input image is divided into many small
cells when calculating HOG, wherein several adjacent cells are combined into one block. A
region is divided into nine unsigned gradient directions, then each block can be described as a 36-D feature. As an optimization, fHOG [
6] divides a
region into 18 signed gradient directions to obtain a 108-D feature. For reducing the dimensions, the features of four cells in each direction are accumulated to obtain a 27-D feature, while nine unsigned gradient directions of four cells are accumulated to obtain a 4-D feature. Finally, this results in a 31-D feature. In fact, fHOG slightly outperforms HOG via our offline experimental verification. We evaluated the performance of using fHOG instead of HOG on 10 video sequences, under the same experimental conditions. Results show that fHOG operates 22.7% faster than the original HOG with similar accuracy. Therefore, fHOG is adopted in the proposed tracker for both translation estimation and scale estimation.
In some challenging application tasks it is not desirable that trackers simply use fHOG, which lacks robustness to target deformation. Therefore, CN is exploited in the proposed tracking method. CN describes color characteristics of an object and is robust to rotation and deformation. Specifically, it refines the 3-channel RGB features in 11 basic color terms: black, blue, brown, grey, green, orange, pink, purple, red, white, and yellow. In this paper, the mapping given by Weijer et al. [
7] is introduced to compute CN, which is learned from the Google image dataset.
4.2. Histogram Significant Enhancement
In conventional tracking tasks, color information of the target generally differs from that of the background, which is a convenient attribute for locating the target more simply. In other words, the target can be found simply via highlighting it in the image. Thus, we can inspect the pixels in the target area with certain rules to significantly enhance the target.
The color histogram tracking builds the color statistical model of the foreground and background. Firstly, the probabilities that each pixel belongs to the foreground and background are calculated separately to obtain the target probability of each pixel. Then, the target probability in a certain area around the pixel is accumulated as the score of the point. Eventually, the difference in color between target and surrounding background is used for tracking.
We can increase the histogram score of the pixels with a higher target probability to highlight the target area in the image. When the target probability
of a pixel in Equation (14) is greater than a certain threshold
, we deploy a significant enhancement to this pixel as:
where
denotes a magnification of the enhanced pixel score. By enhancing the high-response pixel, the discrimination of the foreground and background in the searching area can be increased thereby improving the tracking performance. We update the color histogram model in each frame to improve the adaptability of our tracker:
where
denotes the learning rate of color histogram,
and
denotes foreground model and background model from frame 1 to
, respectively, and
and
denotes model estimated in frame
.
As shown in
Figure 2, we test our approach in a video sequence in which the target clearly differs from its background. The tracker with histogram enhancement could keep following the target consistently. In contrast, the tracker without histogram enhancement loses the tracking target in the first few frames since the target is small with a fast motion. This proves that color histogram significant enhancement can weaken the boundary effect of correlation filters to some extent.
Finally, we linearly combine the response map of the translation filter
and the color histogram score map
to obtain the final translation score map
expressed as:
The position of the maximum in the score map
r is the estimated target position in the current frame, and we subsequently perform scale estimation to obtain the final tracking result.
4.3. Scale Estimation
As mentioned above, the target position can be estimated by the combination of translation filter response map and color histogram score map. In addition, a scale pyramid is formulated on the estimated target position to train a scale filter
. Given the target size
and scale factor
, a scale pool
containing
scales can be expressed as:
For each scale
in the scale pool
, we crop an image patch of size
at the center of the estimated target position and interpolate to
. fHOG is then extracted and extended into a 1-D vector containing the multi-scale representation of the target. A one-dimensional scale correlation filter can be trained using the features of
scales. The response score of each scale can be calculated by
, which represents the similarity between the target in the scale
and the learned model. Eventually, the best scale
can be solved from the following optimization problem:
Notice that here only fHOG is adopted to train the scale filter. In order to reduce the errors by inaccurate scale estimation, the result of scale estimation is merely used to update the scale filter, instead of updating both scale filter and translation filter.
4.4. Adaptive Model Update
Most existing correlation filter algorithms update their models at each frame using the estimated tracking result to fit the gradual change of the target appearance. The target position in the next frame is detected by the updated model. However, when the target is occluded or out of view, even for a short time, the accumulation of errors may cause the tracking model to drift. As a result, the model is corrupted and even if the tracking target reappears, the object cannot be redetected by the tracker. MOSSE [
18] proposed a peak to sidelobe ratio (PSR) criterion to determine the confidence of the current tracking result. However, this method is not highly effective since a fixed empirical threshold is necessary to guide the selection of updating the model.
In fact, the response map in object tracking can reveal the confidence of tracking to a certain extent. When the peak value is large and fluctuation of the response map is slight, the confidence of the tracking result is considered to be high. If the response map fluctuates intensely and multiple peaks are detected, it indicates that there is background clutter or target occlusion. To solve this problem, two criteria, namely the peak value of the translation filter response map
and average peak-to correlation energy (
APCE) [
44], are adopted to detect the confidence of the tracking result. Specifically,
APCE is defined as:
where
,
, and
denote the maximum, minimum, and the value of the coordinate (
w,
h) in the translation filter response map, respectively.
APCE can effectively indicate the confidence of the response map. If the
APCE of the response map is large, the peak value is sharp and the fluctuation is slight. Otherwise, the fluctuation is intense and the peak is moderate. In this way, the occlusion or missing state can be determined.
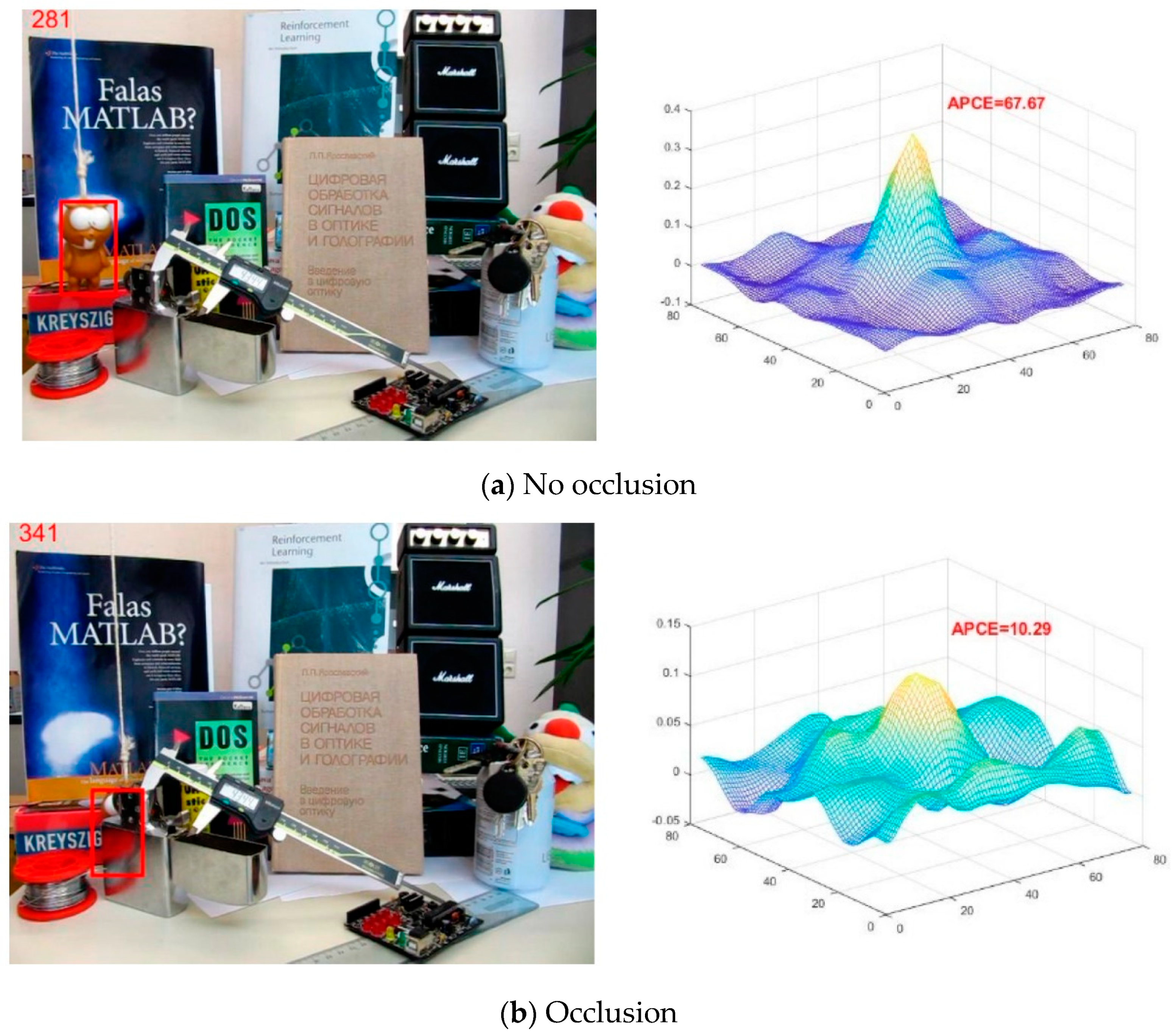
As demonstrated in
Figure 3a, the target is not occluded in the
frame. It can be observed that there is only one sharp peak in the response map and the remaining area is relatively flat, wherein the
APCE is 67.67. In
Figure 3b, the target is severely occluded in the
frame. As a result, there are many local peaks with relatively low values in the response map, among which the highest peak is not obvious and the
APCE is 10.29. To summarize, the
APCE of the response map can effectively reflect the confidence of the tracking result.
Therefore, in order to improve the tracking robustness, those two criteria are introduced to determine whether to update the model. When the
APCE and
of the translation filter response map are both greater than their historical average values with certain ratios
,
, the tracker updates both models of the translation filter
and scale filter
. The filter model corresponds to
in Equation (10), which is used to maximize the response in Equation (12) at the target position. Then the filter model
would be updated as:
where
denotes the learning rate of the translation filter and scale filter,
and
denote the parameters estimated from frame 1 to
, and
and
denote the parameters estimated from frame
alone.
Notice in
Figure 4 that the target is partially occluded from the
frame until detaching from occlusion in
frame. Our strategy adaptively determines to hold the current model since the
APCE and
significantly decrease caused by target occlusion. In this way, the target could be redetected when it appears again. In contrast, if the strategy is not applied, the tracking model would be corrupted during the occlusion and cannot follow the target again when it appears.
4.5. Implementation Details
The proposed rStaple is summarized in Algorithm 1. In this paper, the model of the translation filter is normalized to a fixed size
. The learning rate of translation filter
, the learning rate of scale filter
, and the learning rate of color histogram
are set to 0.01, 0.025 and 0.04, respectively. The learning rate parameters determine how much target information the tracker can learn in the next frame; too high a learning rate will lead to overlearning of the change of target area and a tendency to drift under the situations of occlusion and being out of view. For scale estimation, the scale factor
is set to 1.02 and the number of scales
in the scale pool is 33. The update thresholds
and
of
APCE and
in the adaptive model update are 0.57 and 0.38, respectively. The thresholds affect when to perform the model update; if the thresholds are inappropriate, wrong update timing will lead to tracking failure. The parameter
is set to 0.71 and
in histogram enhancement is 0.82. If
is too high and
is too low, the enhancement will be weak and not beneficial to the performance. Otherwise, the color histogram part will excessively impact the tracker result. We empirically determine these parameters and fix them throughout all the experiments. The parameter of learning rate
is determined by Staple and the parameters in scale estimation refer to DSST [
21]. Furthermore, we preset the update thresholds and parameters in the histogram enhancement with a few random initial values. After, these values were tested in 10 video sequences which are not included in OTB2013 [
10] and OTB2015 [
11] to avoid overfitting. Finally, we further fine-tune the values with good performance to obtain the most suitable choice.
| Algorithm 1 Outline of our proposed tracking algorithm |
| Input: Initial bounding box , , |
| Output: Estimated target bounding box |
| 1: repeat |
| 2: Crop out an image patch z from frame t at the center of and extract its fHOG and CN features; |
| //Translation estimation |
| 3: Compute the response map with and , estimate target position ; |
| //Scale estimation |
| 4: Construct scale pyramid at estimated target position , infer the best scale with ; |
| //Adaptive model update |
| 5: Compute and APCE of ; |
| 6: if and APCE satisfy the condition then |
| 7: Update and ; |
| 8: end if |
| 9: until end of video sequence. |
5. Experimental Results
We implemented rStaple in the MATLAB 2018b environment on a standard PC with i5-8400 and 16 GB RAM. The proposed tracking algorithm was evaluated on video sequences from OTB2013 [
10] and OTB2015 [
11] datasets and compared with 12 state-of-the-art trackers, namely, KCF [
20], DSST [
21], fDSST [
22], Staple [
4], SRDCF [
23], dual linear structured support vector machine (DLSSVM) [
45], compressive tracking (CT) [
46], CSK [
19], long-term correlation tracking (LCT) [
24], SiamFC [
29], CFNet [
30] and ACFN [
31]. Of these, SiamFC, CFNet, and ACFN are deep learning-based algorithms. KCF, DSST, fDSST, Staple, SRDCF, LCT, CT, and CSK are correlation filter -based trackers. To show the results clearly and avoid overly dense result curves, the proposed tracker is compared with nine trackers without deep learning on OTB2013. In addition, the deep learning-based algorithms and several trackers that perform well on OTB2013 are compared with our proposed tracker on OTB2015.
5.1. Evaluation Metrics
The OTB2013 and OTB2015 datasets include 11 common challenges in object tracking: illumination variation (IV), scale variation (SV), occlusion (OCC), deformation (DEF), motion blur (MB), fast motion (FM), in-plane rotation (IPR), out-of-plane rotation (OPR), out-of-view (OV), background clutters (BC), and low resolution (LR). Each video sequence also has one or more attributes. The proposed tracker is evaluated by one-pass evaluation (OPE), which initializes the tracker with the ground truth bounding box in the first frame, and subsequent frames are processed by the tracker. We evaluate the performance of the proposed tracker using the following four widely used metrics in Visual Tracking Benchmark dataset:
Overlap success(OS) rate: the percentage of frames in which the Intersection over Union (IOU) between the estimated target bounding box and the ground truth bounding box is larger than a threshold , i.e., .
Distance precision (DP) rate: the percentage of frames in which the distance between the estimated center location of the target and the ground truth center location is smaller than the threshold.
Average center location error: the average distance between the estimated center location and the ground truth center location in each frame.
Average FPS: the average number of frames processed by the trackers in one second.
5.2. Overall Performance
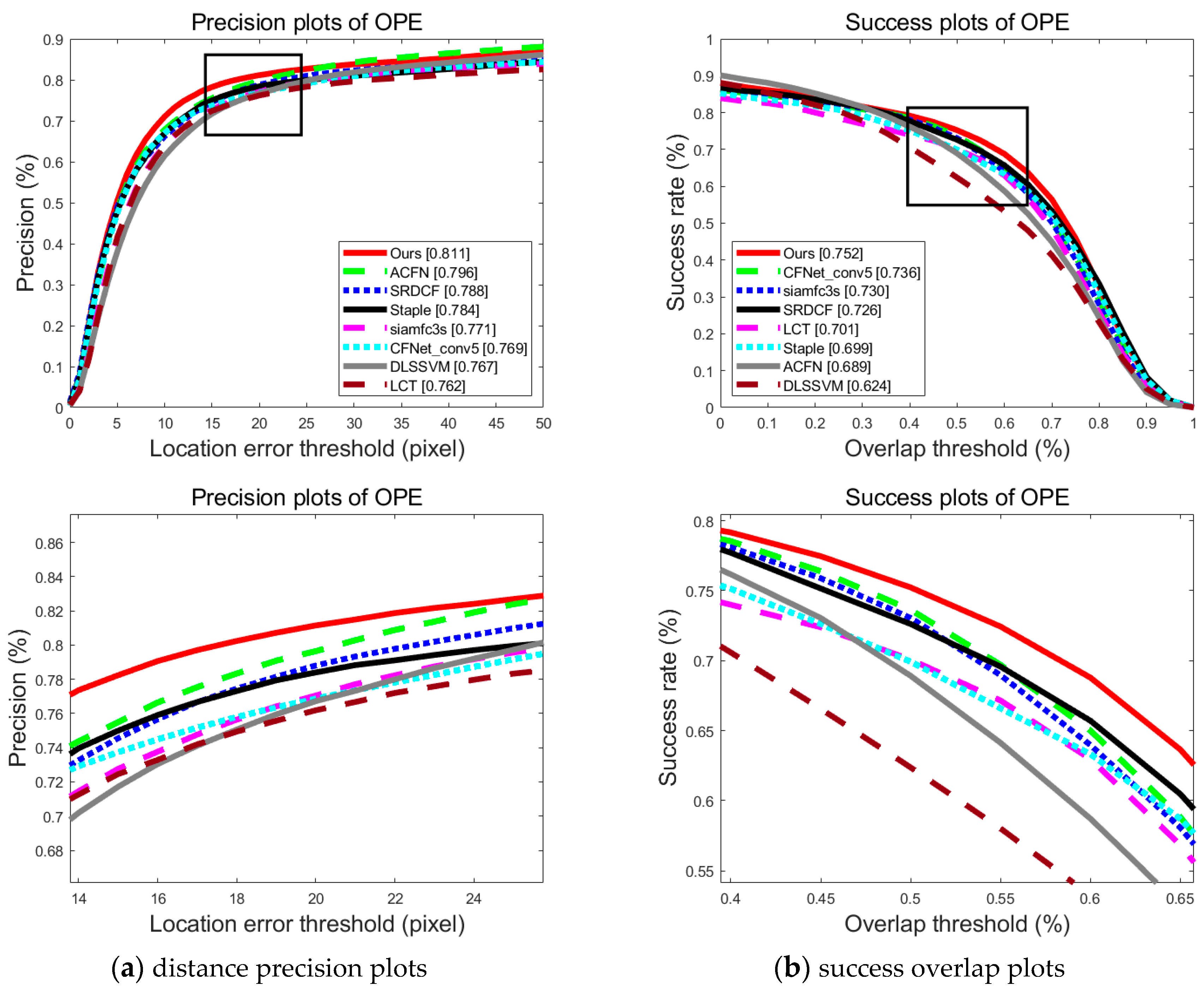
In
Figure 5 and
Figure 6, we depict the precision rate curve and success rate curve of the proposed algorithm and other compared state-of-the-art algorithms using OPE on OTB2013 and OTB2015 datasets.
Figure 5a and
Figure 6a show the smooth curve of the distance precision rate when the location error threshold grows from 0 to 50 pixels.
Figure 5b and
Figure 6b show the curve of the overlap success rate as the overlap threshold increases from 0 to 1. Meanwhile, the data at a predetermined threshold is displayed in the figure. The proposed method exhibits almost the best performance in both evaluation metrics with the increment of the threshold.
Table 1 shows the distance precision rate at a threshold of 20 pixels, overlap success rate at a threshold of 0.5 intersection over union (IOU), and average speed of 10 trackers evaluated on OTB2013. In particular, to accurately evaluate the complexity of these algorithms, the average speed of all trackers was tested on the same hardware environment. The proposed tracker achieves state-of-the-art performance at real-time speed that is superior to many other methods in terms of accuracy. Compared to the baseline Staple, the distance precision rate increases by 6.6%, the overlap success rate increases by 4.9%, and the average center location error increases from 32 to 18.9 pixels according to the results. The overall computational complexity of the proposed algorithm is
. The first part
comes from the correlation filter estimation and
represents the pixels of features which are extracted from the search area. The second part
comes from the color histogram estimation, where
means the search area size. The third part
represents scale estimation, where
is characteristic of the pixels of features in scale pool
. The final
is representative of the part of model update. (Normally,
).
Table 2 shows the distance precision rate and overlap success rate of eight trackers evaluated on OTB2015. Since the speed of deep learning-based algorithms depends largely on the hardware facilities such as the GPU, only the accuracy of these trackers is depicted. The proposed method performs better than these state-of-the-art trackers, including deep learning-based algorithms. Moreover, compared to the baseline, the distance precision rate and overlap success rate of our tracker increase by 3.4% and 7.6%, respectively.
Although the difference in distance precision rate and overlap success rate compared to SRDCF and LCT is not obvious in
Figure 5, the proposed tracker can achieve better performance at a speed of over two times faster than those methods. Practically, it is desirable for a tracker to provide a better balance between trade-off between efficiency and accuracy.
Distance precision and overlap success rate are shown for 11 different attributes in
Table 3,
Table 4,
Table 5 and
Table 6. The cells in the first row of
Table 3,
Table 4,
Table 5 and
Table 6 are abbreviations of attributes in the OTB dataset, and the number of videos that belong to each attribute is in parentheses. The first-ranked tracker is marked in bold and the second-ranked tracker is marked in italics. In
Table 3, our tracker ranks first in seven attributes; except for the motion blur attribute, the remaining three attributes are within 4% of the first-ranked tracker. Compared to the baseline Staple, our performance is improved in all attributes, especially in these five attributes: deformation (11.1%), illumination variation (11.6%), occlusion (10.6%), out of view (12.6%), and scale variation (10.1%). In
Table 4, our tracker ranks first in three attributes and second in five attributes. Compared to Staple, the performance is improved in all attributes, especially in these four attributes: fast motion (9.6%), deformation (7.6%), occlusion (9.1%), and out of view (22.9%). In
Table 5 and
Table 6, our tracker ranks first in eight attributes. Compared to the baseline Staple, our performance is improved in all attributes. According to
Table 3,
Table 4,
Table 5 and
Table 6, the proposed tracker is extremely apt at handling the occlusion, out of view and scale variation situations. Furthermore, the performance of the proposed tracker in low resolution is relatively poor, which is due to using fHOG because fHOG resizes a
pixel area to one pixel for calculating the final feature. Most tracking targets with a low resolution attribute are extremely small, and a host of target information is lost after the resize which leads to tracking failure.
The contribution to performance improvement can be generalized to three aspects. Firstly, we apply significant enhancement to the score map of the color histogram. This improves the attention of the tracker to the target and increases the weight of the color histogram with high confidence, thus weakening the boundary effect. Secondly, the combination of fHOG [
6] and CN [
7,
8] strengthens the discriminating ability of the proposed tracker, which facilitates the translation filter locating the target more accurately. Thirdly, we adaptively update the model of the translation filter and scale filter with criteria
APCE [
44] and
. When the target is occluded or out of view, the filter model update is terminated. Therefore, this strategy effectively avoids model drift.
5.3. Specific Analysis
In order to analyze more intuitively, we display the specific tracking results of tested algorithms in five video sequences from OTB2013 and five video sequences from OTB2015. The challenging attributes of these sequences are shown in
Table 7 and
Table 8.
Figure 7 shows the tracking results of the proposed algorithm and nine compared trackers on five video sequences from OTB2013. In the first sequence
Girl, CT and CSK both lose the target before the
frame. Occlusion occurs between the
frame and
frame. Since the obstruction is similar to the target in color and appearance, Staple, KCF, DSST, and fDSST all drift when the occlusion object leaves. All the tracking bounding boxes follow the occluded object and leave the real target. Our approach successfully avoids model drift when the target is occluded based on the adaptive model update. In the second sequence
Jogging-2, the target has a short-term out of view between the
frame and
frame. Only SRDCF, DLSSVM, and rStaple keep tracking when the target reappears at the
frame; the other trackers all fail to track the target again.
The scene of the third sequence, Matrix, is relatively complicated: the target is small and undergoing fast motion and the background changes drastically. From the frame, CSK, CT, KCF, and DSST fail to track because of the frequent background variance. Staple, LCT and SRDCF lose the target due to fast motion and background clutter. There is also an easily neglected tracking object in the fourth sequence Skiing. The searching area of the correlation filter is related to the size of the estimated bounding box in the current frame, so it is quite difficult to track accurately when the target moves fast and the size of searching area is small. Since DLSSVM abandons correlation filters, only the proposed rStaple and DLSSVM keep tracking till the end. In the last sequence Soccer, DSST fails to track due to fast motion around the frame. Both CSK and LCT lose the target in the frame due to occlusion and severe background clutter. In the frame, the target is completely occluded by the red background and the colors of most areas in the image are very similar, thus, most trackers cannot detect the target precisely. Only rStaple, fDSST, and SRDCF can follow the target when it reappears in the frame.
Figure 8 shows the tracking results of the proposed algorithm and seven compared trackers on five video sequences from OTB2015. In the first video sequence
Bolt2, ACFN, LCT, SRDCF, and DLSSVM lose the tracking target before the
frame due to fast motion and deformation. In the
frame, ACFN follows a similar object near the target. SiamFC loses the target in the
frame since it is surrounded by several similar objects. In the second sequence
DragonBaby, the tracking target is a baby’s head which has a small size and undergoes a fast motion. Many trackers fail to follow the target because of the fast motion. The target in the third sequence,
KiteSurf, is also a man’s head. In the
frame, head rotation of the man leads to most trackers losing the target. In the fourth sequence,
Lemming, target occlusion occurs between the
frame and
frames. SRDCF, DLSSVM, and Staple fail to track the target due to model drift within this period. ACFN miscalculates the target scale in the
frame and fails to recover. In the last sequence,
Panda, LCT and SRDCF lose the target when it turns a corner. In the
frame, Staple and ACFN fail to follow the panda when it passes a tree because of the noisy update of the tracking model.
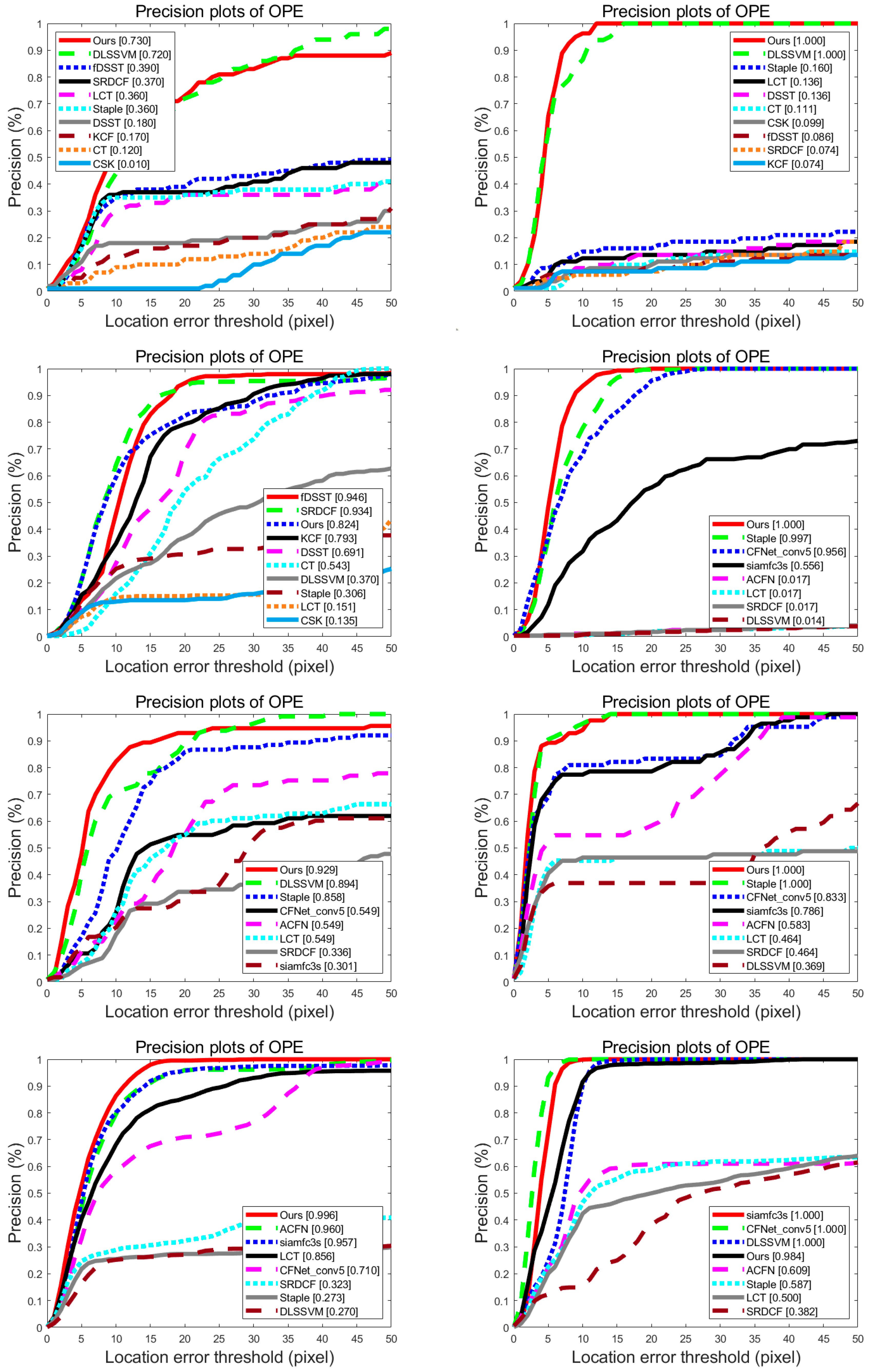
To show the details of the tracking results on ten sequences mentioned above clearly, distance precision rate curves of these sequences are demonstrated in
Figure 9. The order from the first figure to the last is:
Girl,
Jogging-2,
Matrix,
Skiing,
Soccer,
Bolt2,
DragonBaby,
KiteSurf,
Lemming, and
Panda. As shown in
Figure 9, the improvement of the proposed method over the baseline Staple is remarkable. In addition, our method has outstanding performance compared to all of these state-of-the-art trackers.
As illustrated above, the proposed method, rStaple, can handle the challenges of occlusion, fast motion, deformation, and scale variation well in most complex scenes, and achieves state-of-the-art performance.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}