Voice Conversion Using a Perceptual Criterion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
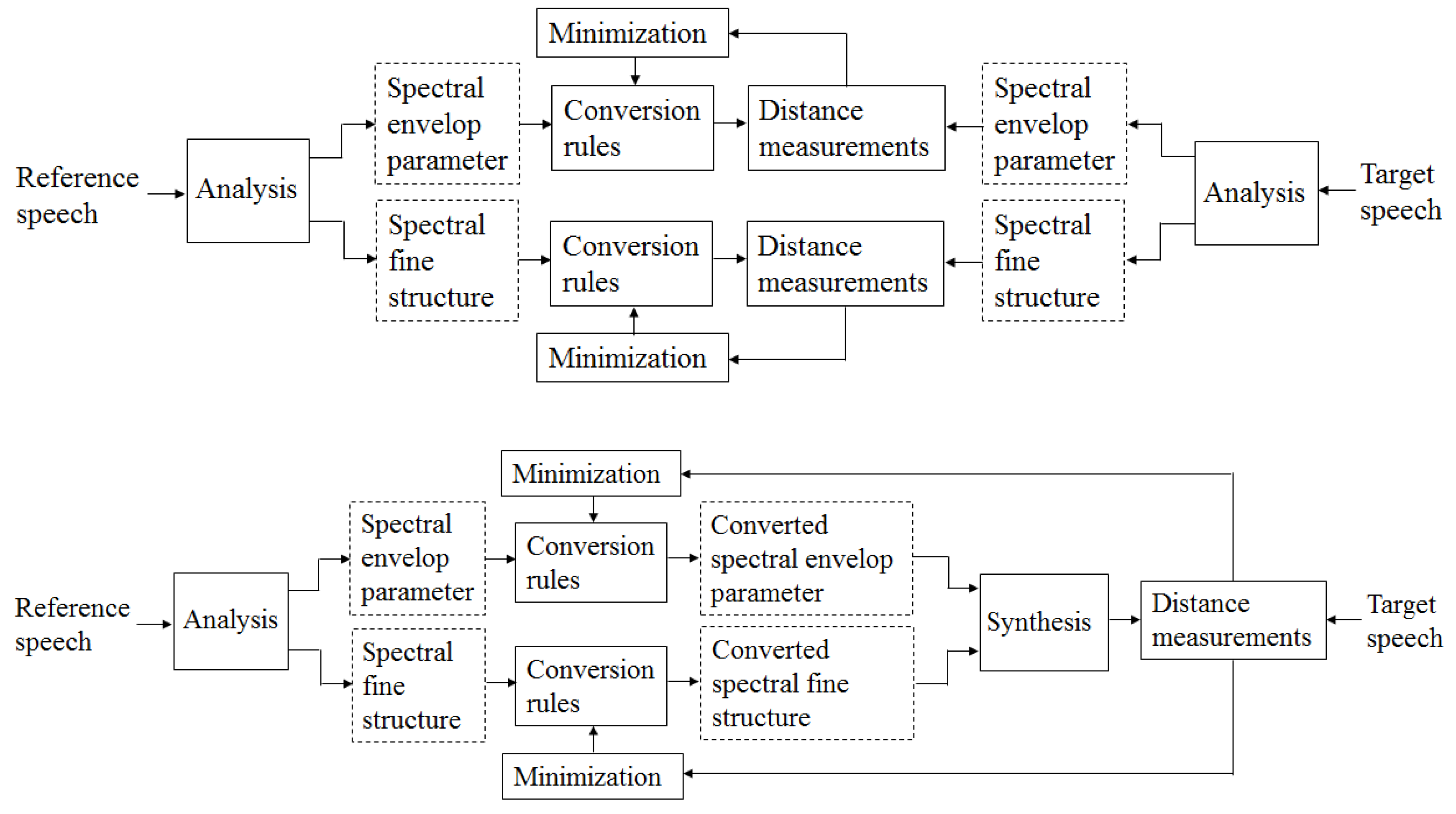
2. The Structure of the Proposed VC Method
3. Perceptual Distance
- (1)
- Perceptual domain transformation: The target and converted loudness spectra and , which are perceptually closer to the actual human listening are obtained as follows,where Q is the number of Bark bands, is a Bark transformation matrix that converts the power spectra , into the Bark spectra , , respectively. is the mapping function that converts each band of the Bark spectrum to a sone loudness scale as follows,where is a loudness scaling factor, is the absolute hearing threshold for the q-th Bark band and is set to 0.23 [25]
- (2)
- Disturbances computation: A relative small difference between the target and converted loudness spectra can be negligible [25,30,41]. Accordingly, a center-clipping operator over the absolute difference between the loudness spectra was applied to compute the symmetrical disturbance vector as follows,where is a clipping factor and , , and are applied element-wise, while is a zero-filled vector of length Q. The asymmetrical disturbance vector is obtained as , where ⊙ denotes an element-wise multiplication and is a vector of asymmetry ratios with components computed from the Bark spectra,For the speech enhancement task, the constants and were set to 50 and 1.2, respectively [25]. In this study, the experiments were carried out to optimally determine the two constants, and . The experimental results showed that the same values adopted in [25] also yielded the minimum . The symmetrical and asymmetrical disturbance terms in (8) are given by the weighted sum of each disturbance vector,where the components of the weight vector are proportional to the width of the Bard bands, as explained in [30].
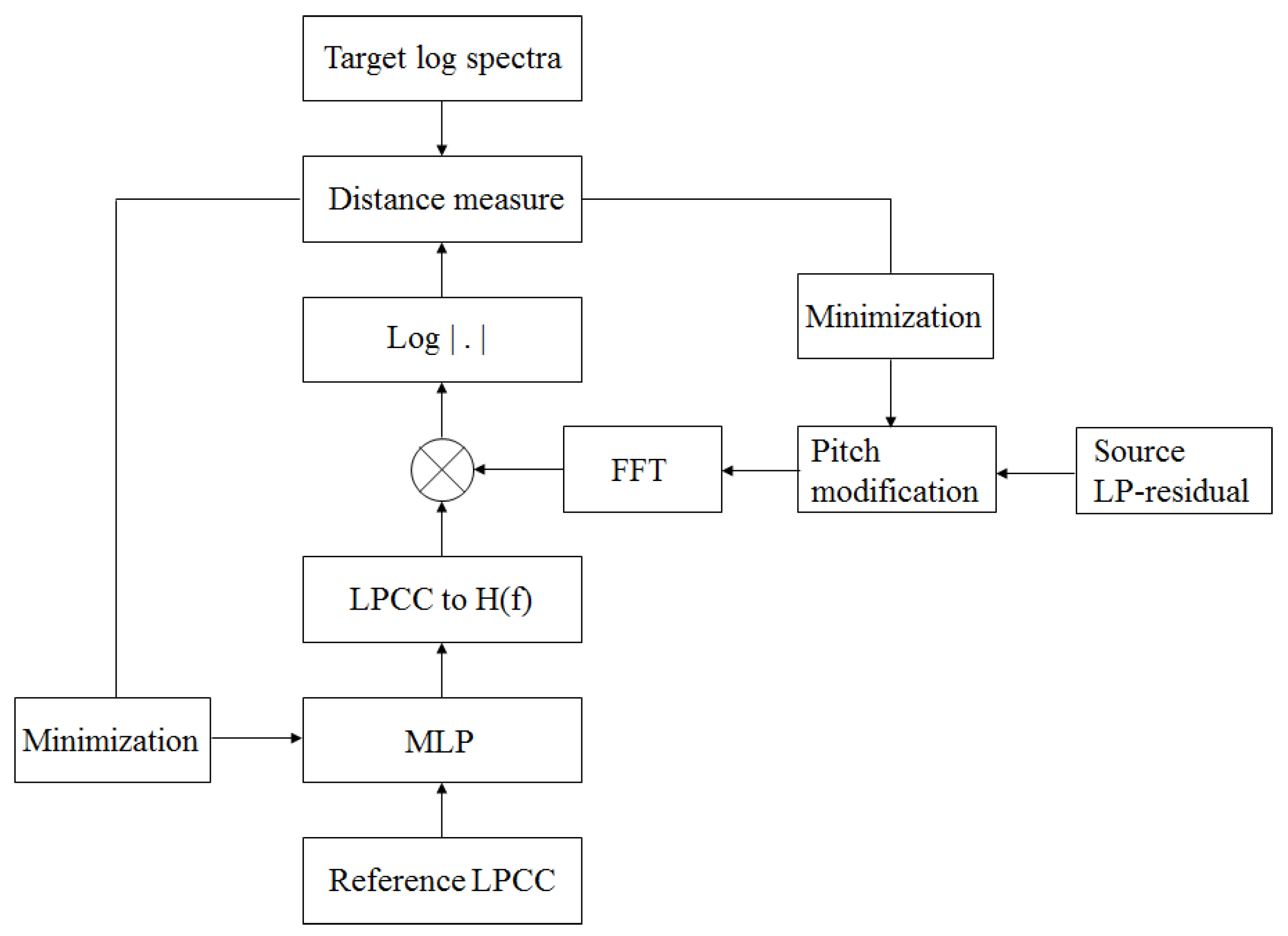
4. Estimation of the Conversion Parameters
5. Experiments and Results
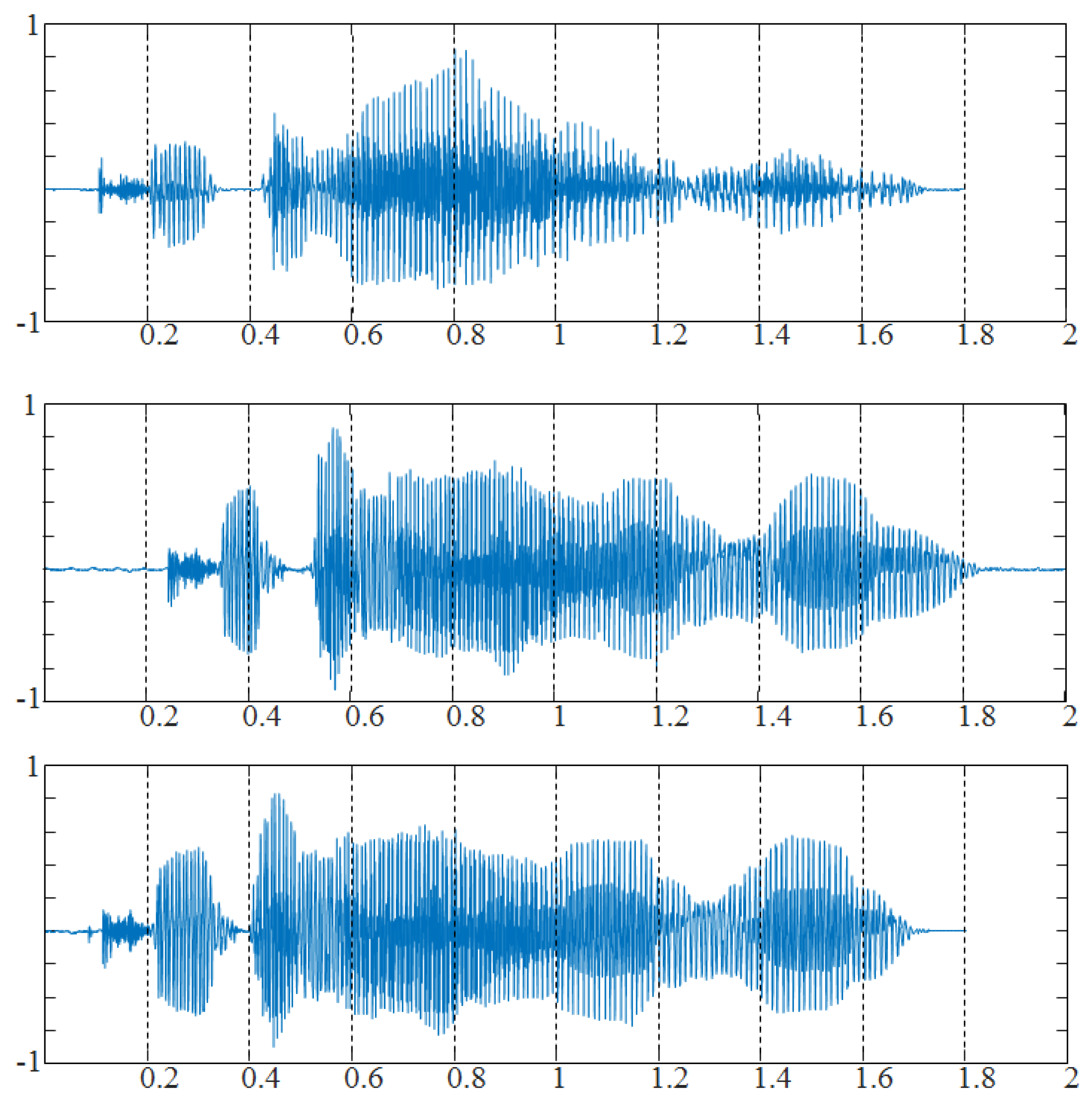
5.1. Experiment Setup
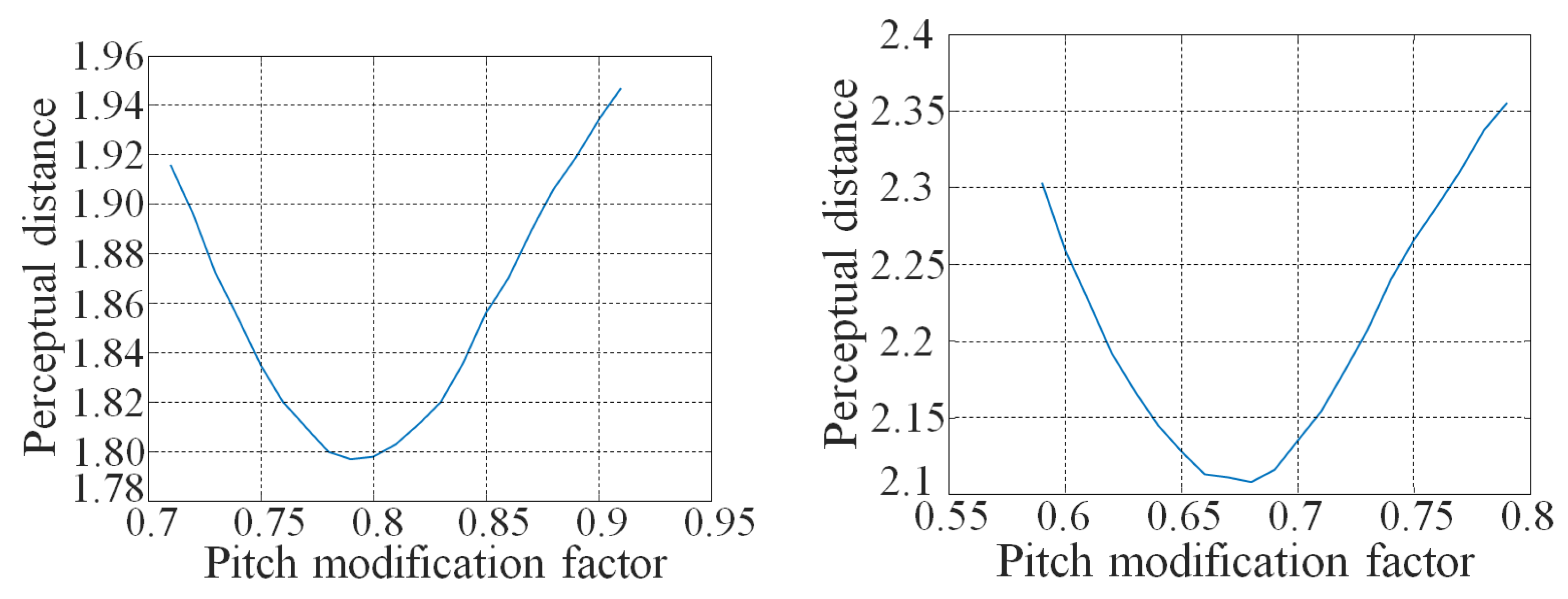
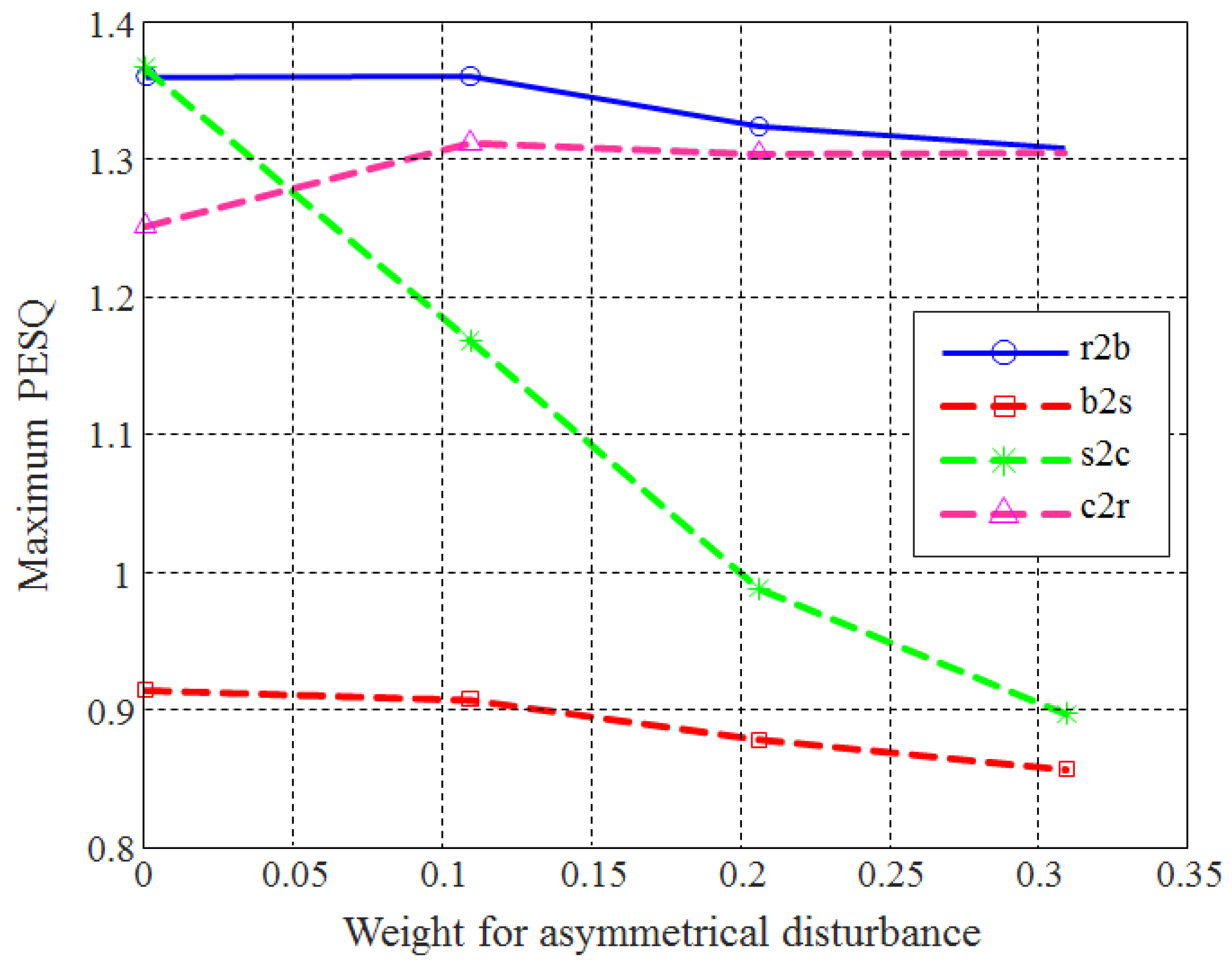
5.2. Determination of the Weights for Each Disturbance
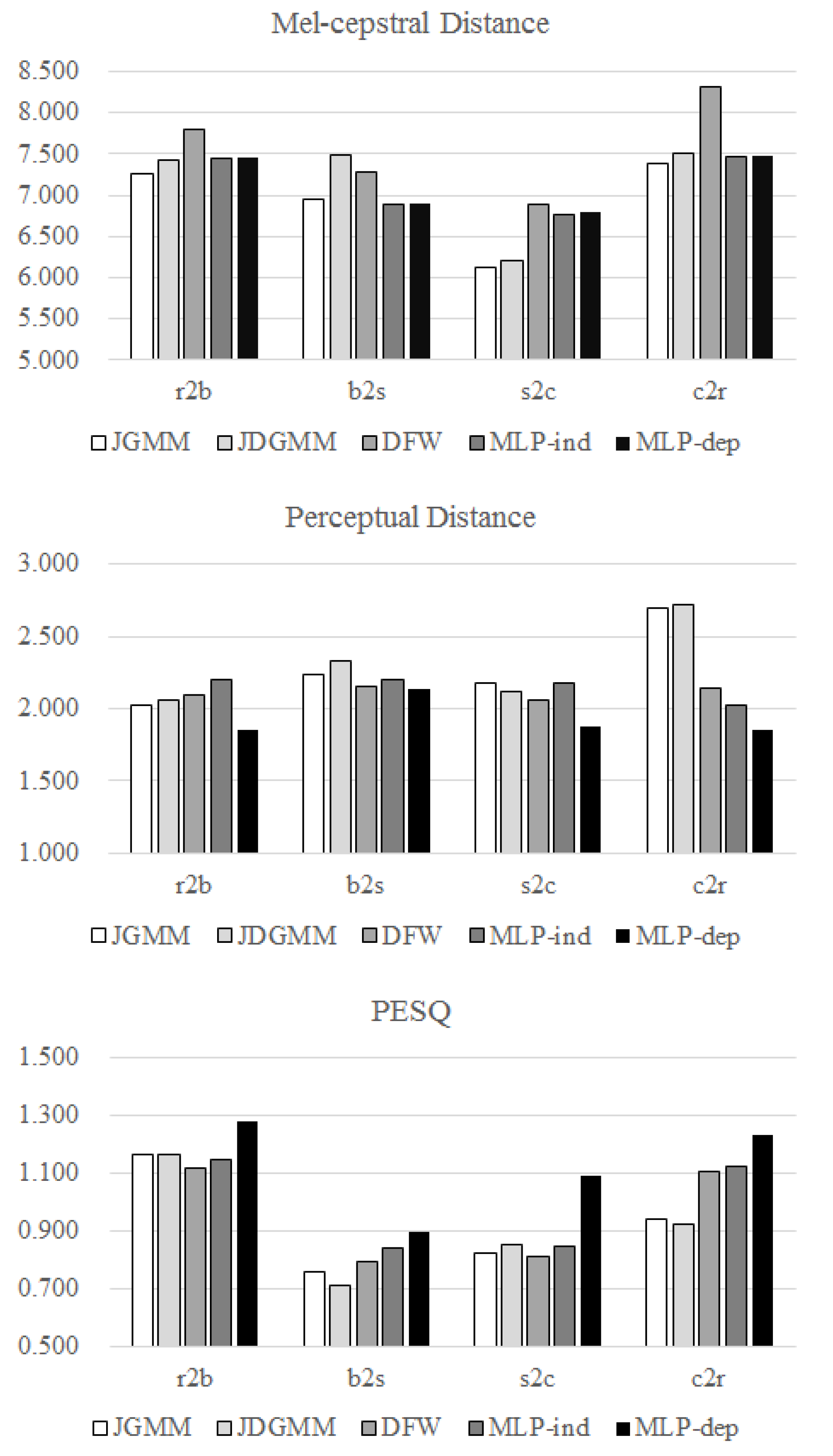
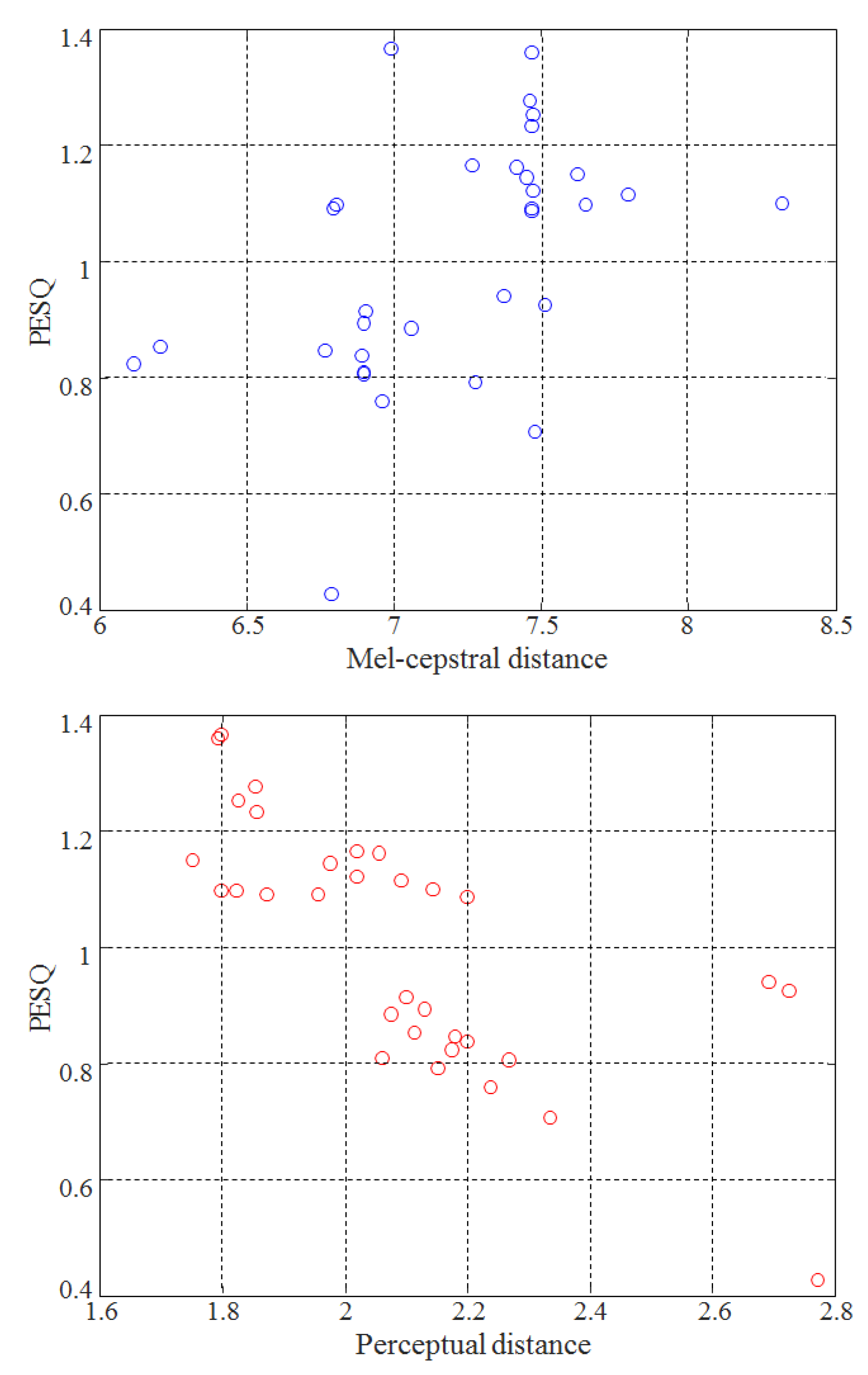
5.3. Objective Evaluation
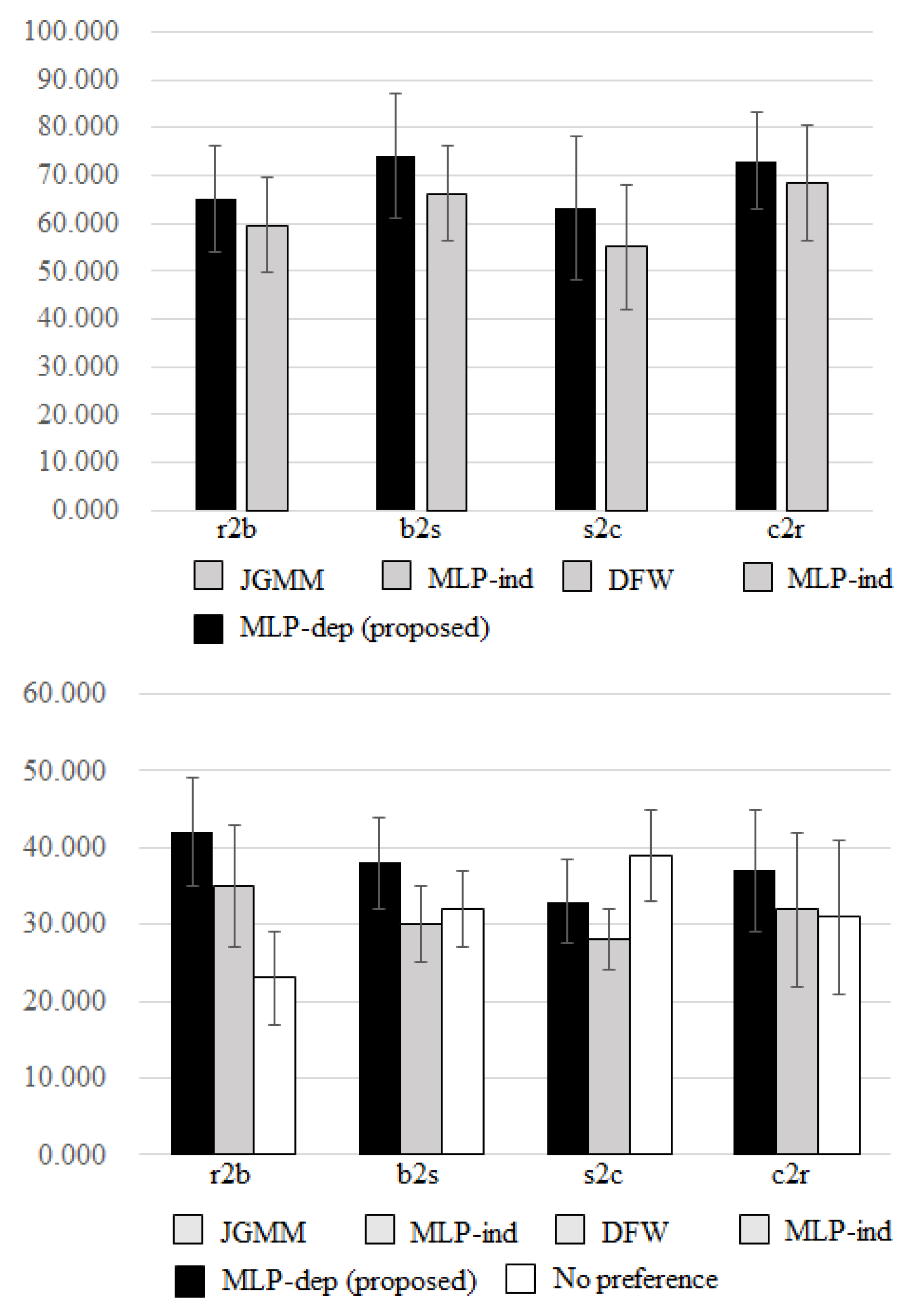
5.4. Subjective Evaluation
6. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| VC | Voice Conversion |
| DNN | Deep Neural Networks |
| MLP | Multi-Layer Perceptron |
| MSE | Mean Squared Error |
| PESQ | Perceptual Evaluation of Speech Quality |
| MCC | Mel Cepstral Coefficients |
| MFCC | Mel-Frequency Cepstral Coefficients |
| LPC | Linear Prediction Coefficients |
| LSP | Line Spectrum Pair |
| MOS | Most Opinion Score |
| DTW | Dynamic Time Warping |
| SOLA | Synchronized OverLap and Add |
| LPCC | Linear Predictive Ceptral Coefficients |
| TD-PSOLA | Time Domain Pitch synchronous OverLap and Add |
| DFT | Discrete Fourier Transform |
| PD | Perceptual Distance |
| MCD | Mel-Cepstral Distance |
| RBM | Restricted Boltzmann Machines |
References
- Mohammadi, S.H.; Kain, A. An overview of voice conversion systems. Speech Commun. 2017, 88, 65–82. [Google Scholar] [CrossRef]
- Wu, C.-H.; Hsia, C.-C.; Liu, T.-H.; Wang, J.-F. Voice conversion using duration-embedded bi-HMMs for expressive speech synthesis. IEEE Trans. Audio Speech Lang. Process. 2006, 4, 1109–1116. [Google Scholar]
- Huang, Y.-C.; Wu, C.-H.; Chao, Y.-T. Personalized spectral and prosody conversion using frame-based codeword distribution and adaptive CRF. IEEE Trans. Audio Speech Lang. Process. 2013, 1, 51–62. [Google Scholar] [CrossRef]
- Cox, S.J.; Bridle, J.S. Unsupervised speaker adaptation by probabilistic spectrum fitting. In Proceedings of the International Conference on Acoustic, Speech Signal Processing, Glasgow, UK, 23–26 May 1989; pp. 294–297. [Google Scholar]
- Bi, N.; Qi, Y. Application of speech conversion to alaryngeal speech enhancement. IEEE Trans. Audio Speech Lang. Process. 1997, 2, 97–105. [Google Scholar]
- Moulines, E.; Charpentier, F. Pitch synchronous waveform processing techniques for text-to-speech synthesis using diphones. Speech Commun. 1990, 9, 453–467. [Google Scholar] [CrossRef]
- McDougall, K. Assessing perceived voice similarity using Multidimensional Scaling for the construction of voice parades. Int. J. Speech Lang. Law 2013, 20, 163–172. [Google Scholar] [CrossRef]
- Wu, Z.; Kinnunen, T.; Chng, E.S.; Li, H. Mixture of factor analyzers using priors from non-parallel speech for voice conversion. IEEE Signal Process. Lett. 2012, 12, 914–917. [Google Scholar] [CrossRef]
- Nakashika, T.; Takiguchi, T.; Ariki, Y. Voice conversion using RNN pre-trained by recurrent temporal restricted Boltzmann machine. IEEE Trans. Audio Speech Lang. Process. 2015, 3, 580–587. [Google Scholar] [CrossRef]
- Abe, M.; Nakamura, S.; Shikano, K.; Kuwabara, H. Voice conversion through vector quantization. In Proceedings of the International Conference on Acoustic, Speech Signal Processing, New York, NY, USA, 11–14 April 1988; pp. 565–568. [Google Scholar]
- Valbret, H.; Moulines, E.; Tubach, J.P. Tubach, Voice transformation using PSOLA technique. Speech Commun. 1992, 11, 175–187. [Google Scholar] [CrossRef]
- Lee, K.S. Statistical approach for voice personality transformation. IEEE Trans. Audio Speech Lang. Process. 2007, 2, 641–651. [Google Scholar] [CrossRef]
- Lee, K.S.; Youn, D.H.; Cha, I.W. A New voice personality transformation based on both linear and nonlinear prediction analysis. In Proceedings of the 4th International Conference on Spoken Language Processing, Philadelphia, PA, USA, 3–6 October 1996; pp. 1401–1404. [Google Scholar]
- Erro, D.; Moreno, A.; Bonafonte, A. Voice conversion based on weighted frequency warping. IEEE Trans. Audio Speech Lang. Process. 2010, 5, 922–931. [Google Scholar] [CrossRef]
- Ye, H.; Young, S. Quality-enhanced voice morphing using maximum likelihood transformations. IEEE Trans. Audio Speech Lang. Process. 2006, 4, 1301–1312. [Google Scholar] [CrossRef]
- Mouchtaris, A.; der Spiegel, J.V.; Mueller, P. Nonparallel training for voice conversion based on a parameter adaptation approach. IEEE Trans. Audio Speech Lang. Process. 2006, 3, 952–963. [Google Scholar] [CrossRef]
- Raitio, T.; Lu, H.; Kane, J.; Suni, A.; Vainio, M.; King, S.; Alku, P. Voice source modelling using deep neural networks for statistical parametric speech synthesis. In Proceedings of the European Signal Processing Conference, Lisbon, Portugal, 1–5 September 2014; pp. 2290–2294. [Google Scholar]
- Rabiner, L.R.; Schaffer, R.W. The mechanism of speech production. In Digital Processing of Speech Signals; Prentice Hall Inc.: Englewood Cliffs, NJ, USA, 1978; pp. 39–41. [Google Scholar]
- Chatterjee, S.; Kleijn, W.B. Auditory Model-Based Design and Optimization of Feature Vectors for Automatic Speech Recognition. IEEE Trans. Audio Speech Lang. Process. 2011, 6, 1813–1825. [Google Scholar]
- Kain, A.; Macon, M.W. Spectral voice conversion for text-to-speech synthesis. In Proceedings of the International Conference on Acoustic, Speech Signal Processing, Seattle, WA, USA, 12–15 May 1998; pp. 285–288. [Google Scholar]
- Toda, T.; Black, A.W.; Tokuda, K. Voice conversion based on maximum likelihood estimation of spectral parameter trajectory. IEEE Trans. Audio Speech Lang. Process. 2007, 8, 2222–2235. [Google Scholar] [CrossRef]
- Godoy, E.; Rosec, O.; Chonavel, T. Voice conversion sugin dynamic frequency warping with amplitude scaling, for parallel or nonparallel corpora. IEEE Trans. Audio Speech Lang. Process. 2012, 4, 1313–1323. [Google Scholar] [CrossRef]
- Tian, X.; Lee, S.W.; Wu, Z.; Chng, E.S.; Li, H. An exemplar-based approach to frequency warping for voice conversion. IEEE Trans. Audio Speech Lang. Process. 2017, 10, 1863–1876. [Google Scholar] [CrossRef]
- Arslan, L.M.; Talkin, D. Speaker transformation using sentence HMM based alignments and detailed prosody modification. In Proceedings of the International Conference on Acoustic, Speech Signal Processing, Seattle, WA, USA, 12–15 May 1998; pp. 289–292. [Google Scholar]
- Martin, J.M.; Gomez, A.M.; Gonzalez, J.A.; Peinado, A.M. A deep learning loss function based on the perceptual evaluation of the speech quality. IEEE Signal Process. 2018, 11, 1680–1684. [Google Scholar] [CrossRef]
- Moritz, N.; Anemüller, J.; Kollmeier, B. An Auditory Inspired Amplitude Modulation Filter Bank for Robust Feature Extraction in Automatic Speech Recognition. IEEE Trans. Audio Speech Lang. Process. 2015, 11, 1926–1937. [Google Scholar] [CrossRef]
- Cernak, M.; Asaei, A.; Hyafil, A. Cognitive Speech Coding: Examining the Impact of Cognitive Speech Processing on Speech Compression. IEEE Signal Process. Mag. 2018, 3, 97–109. [Google Scholar] [CrossRef]
- Tachibana, K.; Toda, T.; Shiga, Y.; Kawai, H. An Investigation of Noise Shaping with Perceptual Weighting for Wavenet-Based Speech Generation. In Proceedings of the International Conference on Acoustic, Speech Signal Processing, Calgary, AB, Canada, 15–20 April 2018; pp. 5664–5668. [Google Scholar]
- Gupta, C.; Li, H.; Wang, Y. Perceptual evalution of singing quality. In Proceedings of the APSIPA Annual Summit and Conference, Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 577–586. [Google Scholar]
- ITU-T, Rec. P. 862. Perceptual Evaluation of Speech Quality (PESQ): An Objective Method for End-to-End Speech Quality Assessment of Narrow Band Telephone Networks and Speech Codecs; International Telecommunication Union-Telecommunication Standardisation Sector: Geneva, Switzerland, 2001. [Google Scholar]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 19, 11–26. [Google Scholar] [CrossRef]
- Wen, Z.; Li, K.; Tao, J.; Lee, C.H. Deep neural network based voice conversion with a large synthesized parallel corpus. In Proceedings of the IEEE 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, Jeju, Korea, 13–15 December 2016; pp. 1–5. [Google Scholar]
- Chen, L.H.; Ling, Z.H.; Song, Y.; Dai, L.R. Joint spectral distribution modeling using restricted boltzmann machines for voice conversion. In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013; pp. 3052–3056. [Google Scholar]
- Tobing, P.L.; Wu, Y.C.; Hayashi, T.; Kobayashi, K.; Toda, T. Voice conversion with cyclic recurrent neural network and fine-tuned WaveNet vocoder. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 6815–6819. [Google Scholar]
- Ding, S.; Zhao, G.; Liberatore, C.; Gutierrez-Osuna, R. Learning Structured Sparse Representations for Voice Conversion. IEEE Trans. Audio Speech Lang. Process. 2020, 28, 343–354. [Google Scholar] [CrossRef]
- Zhang, J.-X.; Ling, Z.-H.; Lui, L.-J.; Jiang, Y.; Dai, L.-R. Sequence-to-sequence acoustic modeling for voice conversion. IEEE Trans. Audio Speech Lang. Process. 2019, 27, 631–643. [Google Scholar] [CrossRef]
- Zhang, J.-X.; Ling, Z.-H.; Dai, L.-R. Non-Parallel Sequence-to-Sequence Voice Conversion with Disentangled Linguistic and Speaker Representations. IEEE Trans. Audio Speech Lang. Process. 2020, 28, 540–552. [Google Scholar] [CrossRef]
- Oord, A.V.D.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A generative model for raw audio. In Proceedings of the 9th ISCA Speech Synthesis Workshop, Sunnyvale, CA, USA, 13–15 September 2016; p. 125. [Google Scholar]
- White, G.M.; Neely, R.B. Speech recognition experiments with linear prediction, bandpass filtering, and dynamic programming. IEEE Trans. Acoust. Speech Signal Process. 1976, 2, 183–188. [Google Scholar] [CrossRef]
- Roucos, S.; Wilgus, A.M. High quality time-scale modification for speech. In Proceedings of the International Conference on Acoustic, Speech Signal Processing, Tampa, FL, USA, 26–29 March 1985; pp. 493–496. [Google Scholar]
- Zwicker, E.; Fastl, H. Critical bands and excitation. In Psychoacoustics; Springer: Heidelberg, Germany, 1990; pp. 149–174. [Google Scholar]
- Kominek, J.; Black, A.W. The CMU ARCTIC speech databases. In Proceedings of the 5th ISCA ITRW on Speech Synthesis, Pittsburgh, PA, USA, 14–16 June 2004; pp. 223–224. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R. Reducing the dimensionality of data with neural networks. Science 2006, 5786, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Deng, L.; Seltzer, M.L.; Yu, D. Binary coding of speech spectrogram using a deep auto-encoder. In Proceedings of the 11th Annual Conference of the International Speech Communication Association, Makuhari, Japan, 26–30 September 2010; pp. 1692–1695. [Google Scholar]
- Hinton, G.E. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002, 8, 1711–1800. [Google Scholar] [CrossRef]








© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.-S. Voice Conversion Using a Perceptual Criterion. Appl. Sci. 2020, 10, 2884. https://doi.org/10.3390/app10082884
Lee K-S. Voice Conversion Using a Perceptual Criterion. Applied Sciences. 2020; 10(8):2884. https://doi.org/10.3390/app10082884
Chicago/Turabian StyleLee, Ki-Seung. 2020. "Voice Conversion Using a Perceptual Criterion" Applied Sciences 10, no. 8: 2884. https://doi.org/10.3390/app10082884
APA StyleLee, K.-S. (2020). Voice Conversion Using a Perceptual Criterion. Applied Sciences, 10(8), 2884. https://doi.org/10.3390/app10082884