A Survey on Theories and Applications for Self-Driving Cars Based on Deep Learning Methods



Abstract
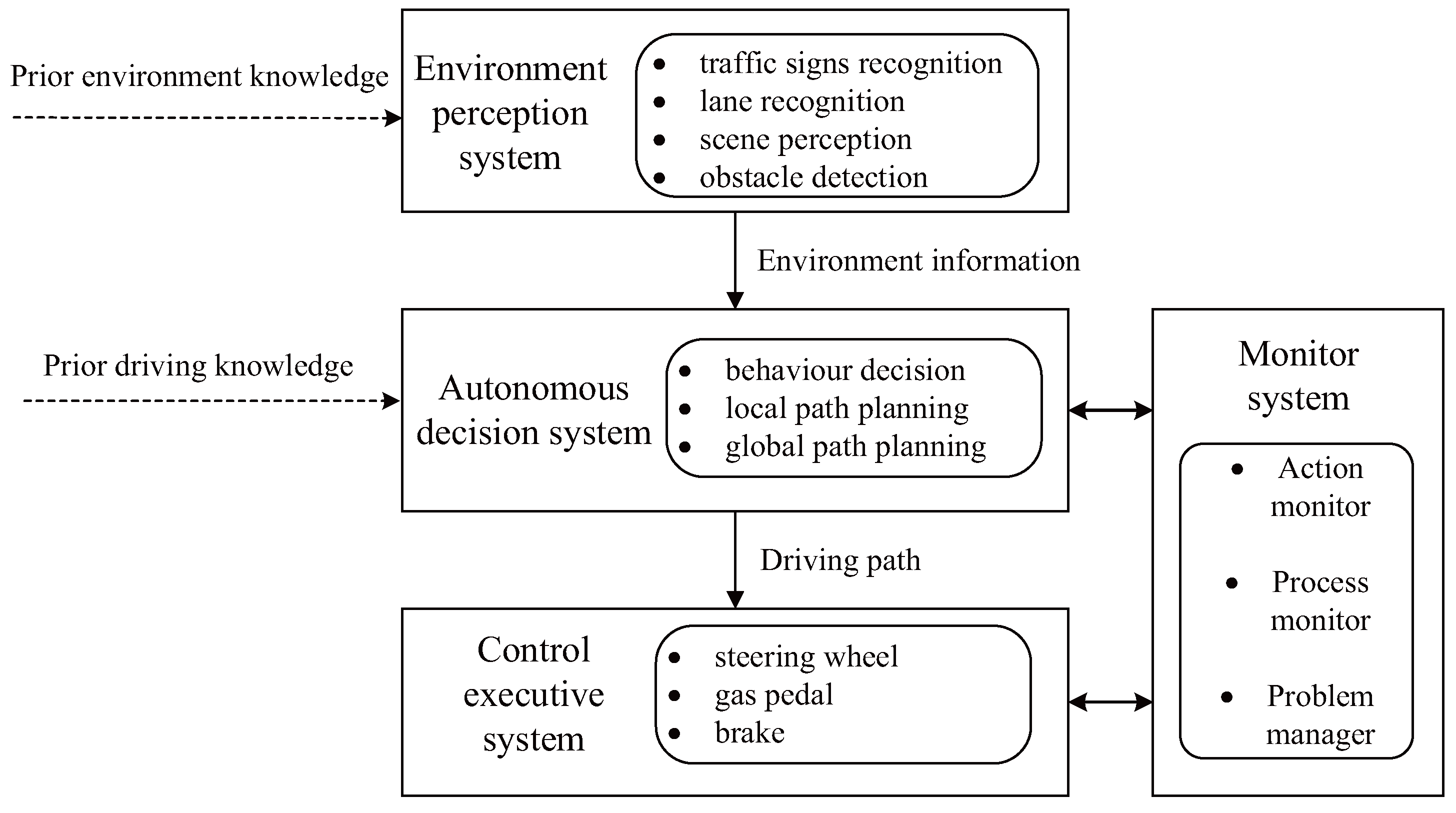
1. Introduction
2. Development of Self-Driving Cars
3. Theoretical Background of Deep Learning Methods Used for Self-Driving Cars
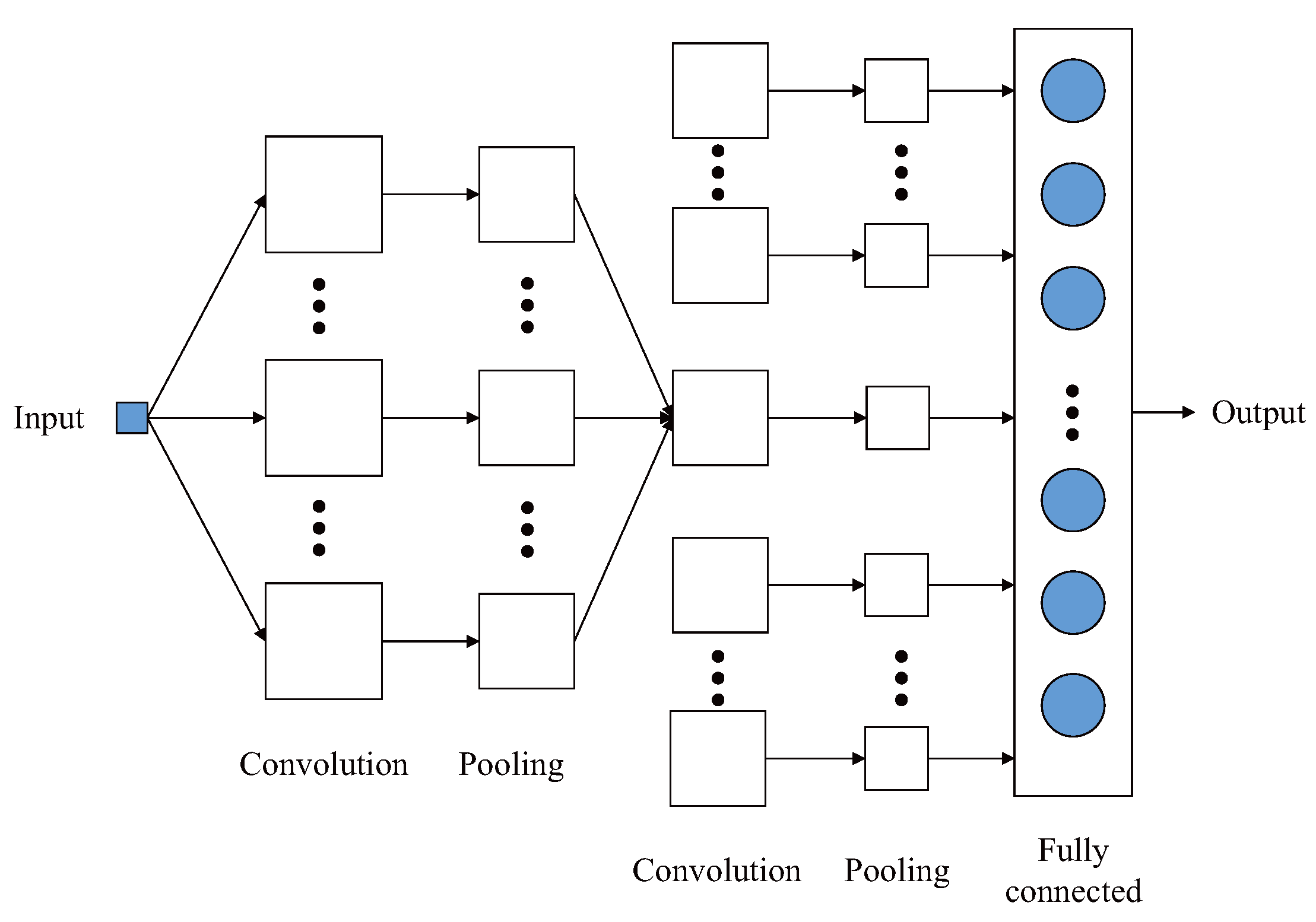
3.1. Convolutional Neural Network
3.2. Recurrent Neural Network
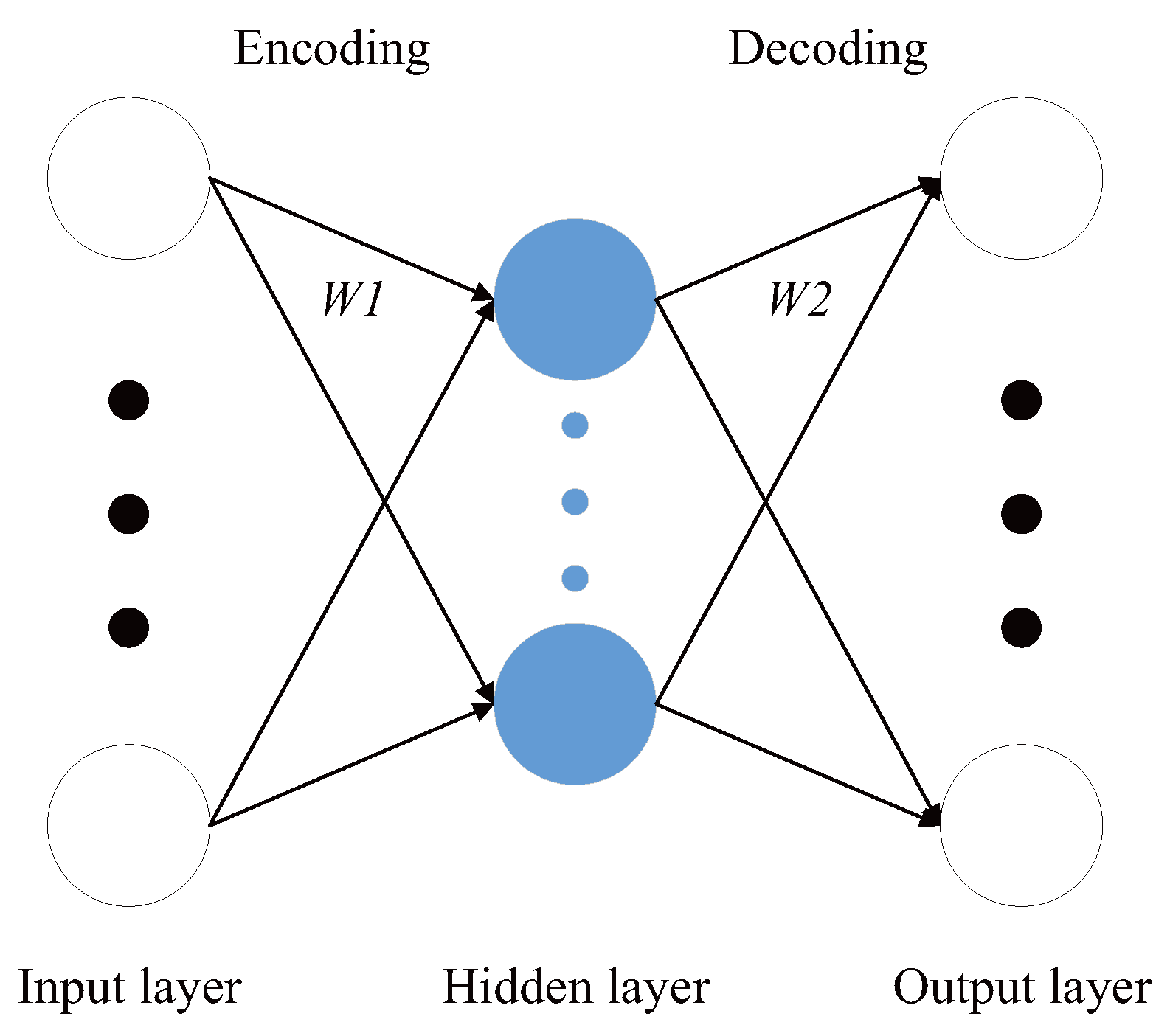
3.3. Auto-Encoder (AE)
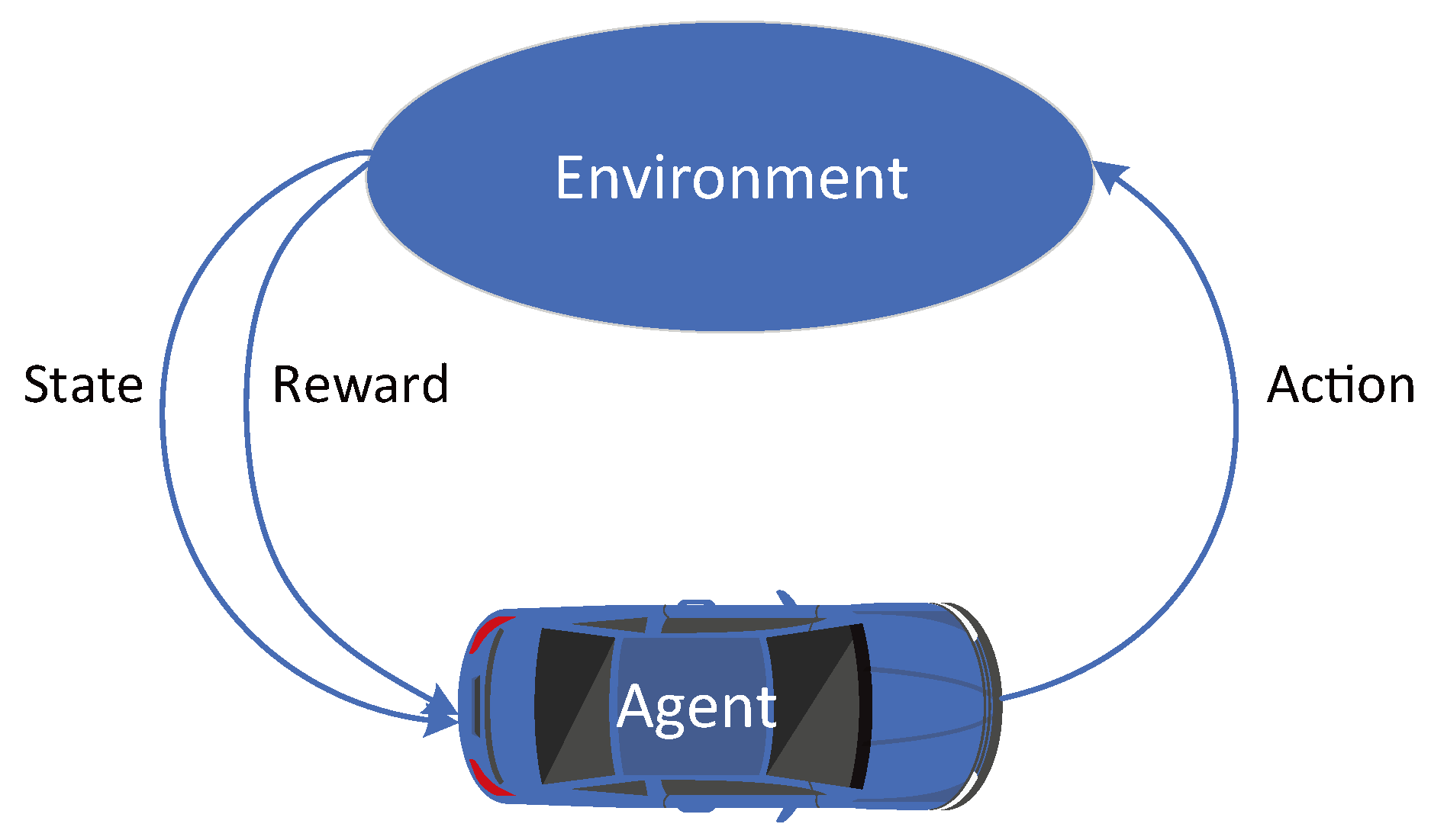
3.4. Deep Reinforcement Learning (DRL)
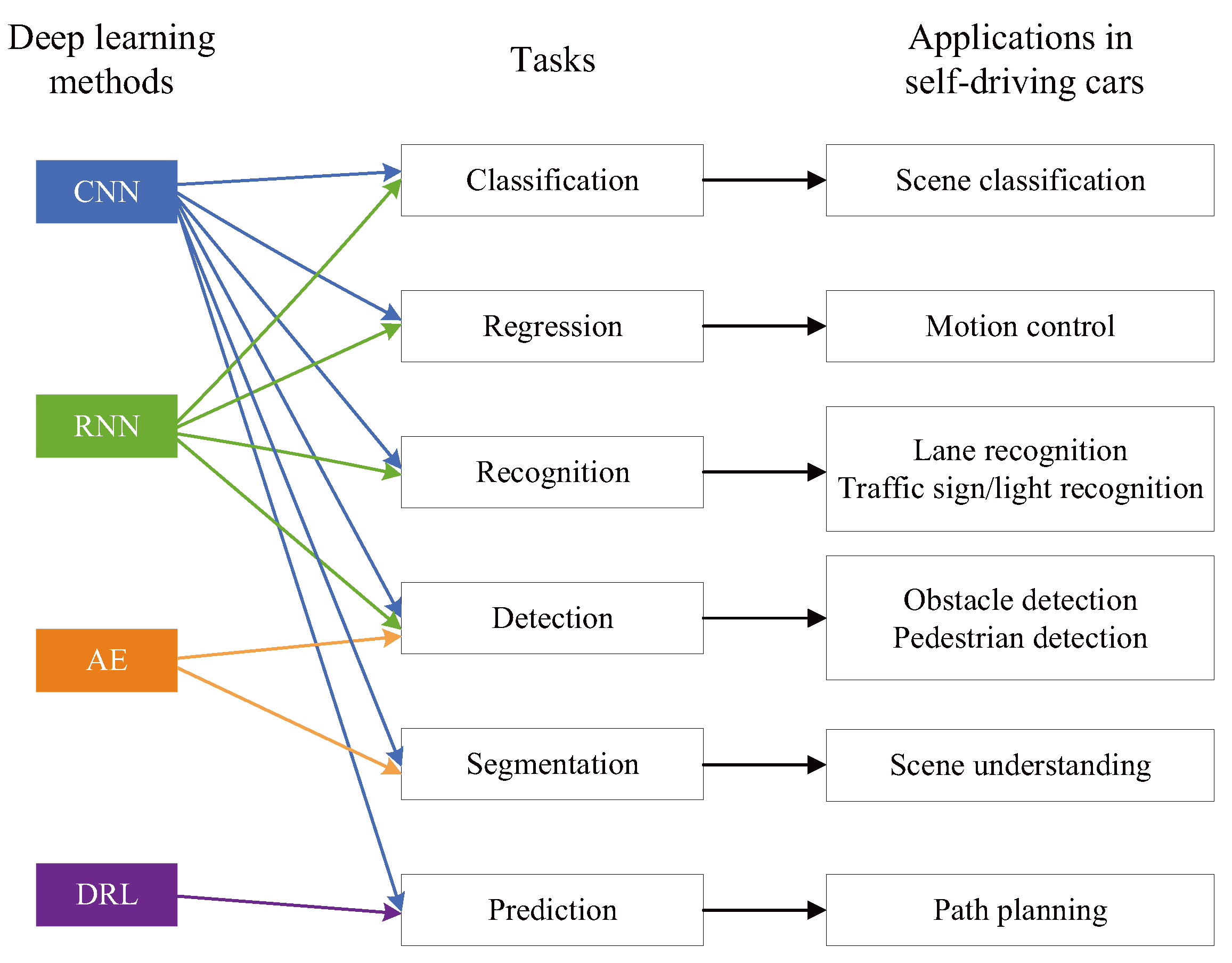
4. Applications Overview of Deep Learning in the Field of Self-Driving Cars
4.1. Obstacle Detection
4.2. Scene Classification and Understanding
4.3. Lane Recognition
4.4. Other Applications
4.4.1. Path Planning
4.4.2. Motion Control
4.4.3. Pedestrian Detection
4.4.4. Traffic Signs and Lights Recognition
5. Future Directions
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Duarte, F. Self-driving cars: A city perspective. Sci. Robot. 2019, 4. [Google Scholar] [CrossRef]
- Shakhatreh, H.; Sawalmeh, A.H.; Al-Fuqaha, A.; Dou, Z.; Almaita, E.; Khalil, I.; Othman, N.S.; Khreishah, A.; Guizani, M. Unmanned aerial vehicles (UAVs): A survey on civil applications and key research challenges. IEEE Access 2019, 7, 48572–48634. [Google Scholar] [CrossRef]
- Clements, L.M.; Kockelman, K.M. Economic effects of automated vehicles. Trans. Res. Rec. 2017, 2606, 106–114. [Google Scholar] [CrossRef]
- Hussain, R.; Zeadally, S. Autonomous cars: research results, issues, and future challenges. IEEE Commun. Surv. Tutor. 2019, 21, 1275–1313. [Google Scholar] [CrossRef]
- Xue, J.R.; Fang, J.W.; Zhang, P. A survey of scene understanding by event reasoning in autonomous driving. Int. J. Autom. Comput. 2018, 15, 249–266. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, K.; Li, J.; Zhu, Y.; Zhang, Y. Various frameworks and libraries of machine learning and deep learning: A survey. Arch. Comput. Methods Eng. 2019. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, N. A survey on deep learning based face recognition. Comput. Vis. Image Underst. 2019, 189, 102805. [Google Scholar] [CrossRef]
- Greenblatt, N.A. Self-driving cars and the law. IEEE Spect. 2016, 53, 46–51. [Google Scholar] [CrossRef]
- Bengio, Y.I.; Goodfellow, J.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Birdsall, M. Google and ITE: The road ahead for self-driving cars. ITE J. (Inst. Transp. Eng.) 2014, 84, 36–39. [Google Scholar]
- Dikmen, M.; Burns, C. Trust in autonomous vehicles: The case of Tesla autopilot and summon. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics, SMC 2017, Banff, AB, Canada, 5–8 October 2017; pp. 1093–1098. [Google Scholar]
- Coelingh, E.; Nilsson, J.; Buffum, J. Driving tests for self-driving cars. IEEE Spectr. 2018, 55, 41–45. [Google Scholar] [CrossRef]
- Park, J.; Nam, C.; Kim, H.j. Exploring the key services and players in the smart car market. Telecommun. Policy 2019, 43, 101819. [Google Scholar] [CrossRef]
- Toschi, A.; Sanic, M.; Leng, J.; Chen, Q.; Wang, C.; Guo, M. Characterizing perception module performance and robustness in production-scale autonomous driving system. In Proceedings of the 16th IFIP WG 10.3 International Conference on Network and Parallel Computing, Hohhot, China, 23–24 August 2019; pp. 235–247. [Google Scholar]
- Li, Y.; Wang, J.; Xing, T.; Liu, T.; Li, C.; Su, K. TAD16K: An enhanced benchmark for autonomous driving. In Proceedings of the 24th IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 2344–2348. [Google Scholar]
- Yue, L.; Abdel-Aty, M.; Wu, Y.; Wang, L. Assessment of the safety benefits of vehicles advanced driver assistance, connectivity and low level automation systems. Accident Anal. Prev. 2018, 117, 55–64. [Google Scholar] [CrossRef] [PubMed]
- Bylykbashi, K.; Qafzezi, E.; Ikeda, M.; Matsuo, K.; Barolli, L. Fuzzy-based driver monitoring system (FDMS): Implementation of two intelligent FDMSs and a testbed for safe driving in VANETs. Future Gener. Comput. Syst. 2020, 105, 665–674. [Google Scholar] [CrossRef]
- Schnelle, S.; Wang, J.; Jagacinski, R.; Su, H.j. A feedforward and feedback integrated lateral and longitudinal driver model for personalized advanced driver assistance systems. Mechatronics 2018, 50, 177–188. [Google Scholar] [CrossRef]
- Paden, B.; Cap, M.; Yong, S.Z.; Yershov, D.; Frazzoli, E. A survey of motion planning and control techniques for self-driving urban vehicles. IEEE Trans. Intell. Veh. 2016, 1, 33–55. [Google Scholar] [CrossRef]
- Mittal, S. A Survey on optimized implementation of deep learning models on the NVIDIA Jetson platform. J. Syst. Arch. 2019, 97, 428–442. [Google Scholar] [CrossRef]
- Jones, L. Driverless when and cars: Where? Eng. Technol. 2017, 12, 36–40. [Google Scholar] [CrossRef]
- Dekhtiar, J.; Durupt, A.; Bricogne, M.; Eynard, B.; Rowson, H.; Kiritsis, D. Deep learning for big data applications in CAD and PLM research review, opportunities and case study. Comput. Ind. 2018, 100, 227–243. [Google Scholar] [CrossRef]
- Ni, J.; Wang, K.; Cao, Q.; Khan, Z.; Fan, X. A memetic algorithm with variable length chromosome for robot path planning under dynamic environments. Int. J. Robot. Autom. 2017, 32, 414–424. [Google Scholar] [CrossRef]
- Ni, J.; Wu, L.; Fan, X.; Yang, S.X. Bioinspired intelligent algorithm and its applications for mobile robot control: A survey. Comput. Intell. Neurosci. 2016, 2016, 3810903. [Google Scholar] [CrossRef]
- McCall, R.; McGee, F.; Mirnig, A.; Meschtscherjakov, A.; Louveton, N.; Engel, T.; Tscheligi, M. A taxonomy of autonomous vehicle handover situations. Transp. Res. Part A Policy Pract. 2019, 124, 507–522. [Google Scholar] [CrossRef]
- Liu, M.; Grana, D. Accelerating geostatistical seismic inversion using TensorFlow: A heterogeneous distributed deep learning framework. Comput. Geosci. 2019, 124, 37–45. [Google Scholar] [CrossRef]
- Zhao, B.; Feng, J.; Wu, X.; Yan, S. A survey on deep learning-based fine-grained object classification and semantic segmentation. Int. J. Autom. Comput. 2017, 14, 119–135. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral-spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Agrawal, P.; Ganapathy, S. Modulation filter learning using deep variational networks for robust speech recognition. IEEE J. Sel. Top. Sign. Process. 2019, 13, 244–253. [Google Scholar] [CrossRef]
- Zhang, Z.; Geiger, J.; Pohjalainen, J.; Mousa, A.E.D.; Jin, W.; Schuller, B. Deep learning for environmentally robust speech recognition: An overview of recent developments. ACM Trans. Intell. Syst. Technol. 2018, 9, 49. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Sun, S.; Luo, C.; Chen, J. A review of natural language processing techniques for opinion mining systems. Inform. Fus. 2017, 36, 10–25. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. In Proceedings of the 1999 the 9th International Conference on ‘Artificial Neural Networks (ICANN99)’, Edinburgh, UK, 7–10 September 1999; Volume 2, pp. 850–855. [Google Scholar]
- Bouwmans, T.; Javed, S.; Sultana, M.; Jung, S.K. Deep neural network concepts for background subtraction: A systematic review and comparative evaluation. Neural Netw. 2019, 117, 8–66. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Li, Y.; Bao, Y.; Yan, W.; Fang, Z.; Lu, H. Contextual deconvolution network for semantic segmentation. Pattern Recognit. 2020, 101, 107152. [Google Scholar] [CrossRef]
- Woo, J.; Kim, N. Collision avoidance for an unmanned surface vehicle using deep reinforcement learning. Ocean Eng. 2020, in press. [Google Scholar] [CrossRef]
- Ding, Y.; Ma, L.; Ma, J.; Suo, M.; Tao, L.; Cheng, Y.; Lu, C. Intelligent fault diagnosis for rotating machinery using deep Q-network based health state classification: A deep reinforcement learning approach. Adv. Eng. Inform. 2019, 42, 100977. [Google Scholar] [CrossRef]
- Ni, J.; Liu, M.; Ren, L.; Yang, S.X. A multiagent Q-learning-based optimal allocation approach for urban water resource management system. IEEE Trans. Autom. Sci. Eng. 2014, 11, 204–214. [Google Scholar] [CrossRef]
- Ni, J.; Li, X.; Hua, M.; Yang, S.X. Bioinspired neural network-based Q-learning approach for robot path planning in unknown environments. Int. J. Robot. Autom. 2016, 31, 464–474. [Google Scholar] [CrossRef]
- Wen, S.; Zhao, Y.; Yuan, X.; Wang, Z.; Zhang, D.; Manfredi, L. Path planning for active SLAM based on deep reinforcement learning under unknown environments. Intell. Serv. Robot. 2020, in press. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Liu, H.; Sun, F.; Zhang, X. Robotic material perception using active multimodal fusion. IEEE Trans. Indust. Electron. 2019, 66, 9878–9886. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, M.; Qiu, P.; Huang, Y.; Li, J. Radar and vision fusion for the real-time obstacle detection and identification. Indust. Robot 2019, 46, 391–395. [Google Scholar] [CrossRef]
- Kriechbaumer, T.; Blackburn, K.; Breckon, T.P.; Hamilton, O.; Casado, M.R. Quantitative evaluation of stereo visual odometry for autonomous vessel localisation in inland waterway sensing applications. Sensors 2015, 15, 31869–31887. [Google Scholar] [CrossRef]
- Mancini, M.; Costante, G.; Valigi, P.; Ciarfuglia, T.A. J-MOD2: Joint monocular obstacle detection and depth estimation. IEEE Robot. Autom. Lett. 2018, 3, 1490–1497. [Google Scholar]
- Chen, H. Monocular vision-based obstacle detection and avoidance for a multicopter. IEEE Access 2019, 7, 167869–167883. [Google Scholar]
- Parmar, Y.; Natarajan, S.; Sobha, G. DeepRange: Deep-learning-based object detection and ranging in autonomous driving. IET Intell. Trans. Syst. 2019, 13, 1256–1264. [Google Scholar]
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar]
- Žbontar, J.; Lecun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Nguyen, T.P.; Jeon, J.W. Wide context learning network for stereo matching. Signal Process. Image Commun. 2019, 78, 263–273. [Google Scholar]
- Zhang, G.; Zhu, D.; Shi, W.; Ye, X.; Li, J.; Zhang, X. Multi-dimensional residual dense attention network for stereo matching. IEEE Access 2019, 7, 51681–51690. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the 16th IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Dairi, A.; Harrou, F.; Sun, Y.; Senouci, M. Obstacle detection for intelligent transportation systems using deep stacked autoencoder and k-nearest neighbor scheme. IEEE Sens. J. 2018, 18, 5122–5132. [Google Scholar]
- Mancini, M.; Costante, G.; Valigi, P.; Ciarfuglia, T.A. Fast robust monocular depth estimation for obstacle detection with fully convolutional networks. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2016, Daejeon, Korea, 9–14 October 2016; Volume 2016-November, pp. 4296–4303. [Google Scholar]
- Jia, B.; Feng, W.; Zhu, M. Obstacle detection in single images with deep neural networks. Signal Image Video Process. 2016, 10, 1033–1040. [Google Scholar]
- Zhong, Y.; Li, H.; Dai, Y. Open-world stereo video matching with deep RNN. In Proceedings of the 15th European Conference on Computer Vision, ECCV 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Jie, Z.; Wang, P.; Ling, Y.; Zhao, B.; Wei, Y.; Feng, J.; Liu, W. Left-right comparative recurrent model for stereo matching. In Proceedings of the 31st Meeting of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chen, L.; Zhan, W.; Tian, W.; He, Y.; Zou, Q. Deep integration: A multi-label architecture for road scene recognition. IEEE Trans. Image Process. 2019, 28, 4883–4898. [Google Scholar]
- Wang, L.; Guo, S.; Huang, W.; Xiong, Y.; Qiao, Y. Knowledge guided disambiguation for large-scale scene classification with multi-resolution CNNs. IEEE Trans. Image Process. 2017, 26, 2055–2068. [Google Scholar] [CrossRef]
- Tang, P.; Wang, H.; Kwong, S. G-MS2F: GoogLeNet based multi-stage feature fusion of deep CNN for scene recognition. Neurocomputing 2017, 225, 188–197. [Google Scholar] [CrossRef]
- Byeon, W.; Breuel, T.M.; Raue, F.; Liwicki, M. Scene labeling with LSTM recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zhang, L.; Li, L.; Pan, X.; Cao, Z.; Chen, Q.; Yang, H. Multi-level ensemble network for scene recognition. Multimed. Tools Appl. 2019, 78, 28209–28230. [Google Scholar] [CrossRef]
- Liu, S.; Tian, G.; Xu, Y. A novel scene classification model combining ResNet based transfer learning and data augmentation with a filter. Neurocomputing 2019, 338, 191–206. [Google Scholar] [CrossRef]
- Cheng, X.; Lu, J.; Feng, J.; Yuan, B.; Zhou, J. Scene recognition with objectness. Pattern Recognit. 2018, 74, 474–487. [Google Scholar] [CrossRef]
- Sun, N.; Li, W.; Liu, J.; Han, G.; Wu, C. Fusing object semantics and deep appearance features for scene recognition. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 1715–1728. [Google Scholar] [CrossRef]
- John, V.; Liu, Z.; Mita, S.; Guo, C.; Kidono, K. Real-time road surface and semantic lane estimation using deep features. Signal Image Video Process. 2018, 12, 1133–1140. [Google Scholar] [CrossRef]
- Xiao, D.; Yang, X.; Li, J.; Islam, M. Attention deep neural network for lane marking detection. Knowl. Based Syst. 2020, 105584. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.; Jang, G.J.; Lee, M. Fast learning method for convolutional neural networks using extreme learning machine and its application to lane detection. Neural Netw. 2017, 87, 109–121. [Google Scholar] [CrossRef]
- Liu, J. Learning full-reference quality-guided discriminative gradient cues for lane detection based on neural networks. J. Vis. Commun. Image Represent. 2019, 65, 102675. [Google Scholar] [CrossRef]
- Li, J.; Mei, X.; Prokhorov, D.; Tao, D. Deep neural network for structural prediction and lane detection in traffic scene. IEEE Trans. Neural Networks Learn. Syst. 2017, 28, 690–703. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Gelernter, J.; Wang, X.; Chen, W.; Gao, J.; Zhang, Y.; Li, X. Lane marking detection via deep convolutional neural network. Neurocomputing 2018, 280, 46–55. [Google Scholar] [CrossRef] [PubMed]
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards end-to-end lane detection: An instance segmentation approach. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium, IV 2018, Changshu, China, 26–30 June 2018. [Google Scholar]
- Yang, W.; Cheng, Y.; Chung, P. Improved lane detection with multilevel features in branch convolutional neural networks. IEEE Access 2019, 7, 173148–173156. [Google Scholar] [CrossRef]
- Zou, Q.; Jiang, H.; Dai, Q.; Yue, Y.; Chen, L.; Wang, Q. Robust lane detection from continuous driving scenes using deep neural networks. IEEE Trans. Veh. Technol. 2020, 69, 41–54. [Google Scholar] [CrossRef]
- Ghafoorian, M.; Nugteren, C.; Baka, N.; Booij, O.; Hofmann, M. EL-GAN: Embedding loss driven generative adversarial networks for lane detection. In Proceedings of the 15th European Conference on Computer Vision, ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 256–272. [Google Scholar]
- Ni, J.; Wu, L.; Shi, P.; Yang, S.X. A dynamic bioinspired neural network based real-time path planning method for autonomous underwater vehicles. Comput. Intell. Neurosci. 2017, 2017, 9269742. [Google Scholar] [CrossRef]
- Ni, J.; Yang, L.; Wu, L.; Fan, X. An improved spinal neural system-based approach for heterogeneous AUVs cooperative hunting. Int. J. Fuzzy Syst. 2018, 20, 672–686. [Google Scholar] [CrossRef]
- Yu, L.; Shao, X.; Wei, Y.; Zhou, K. Intelligent land-vehicle model transfer trajectory planning method based on deep reinforcement learning. Sensors (Switzerland) 2018, 18, 2905. [Google Scholar]
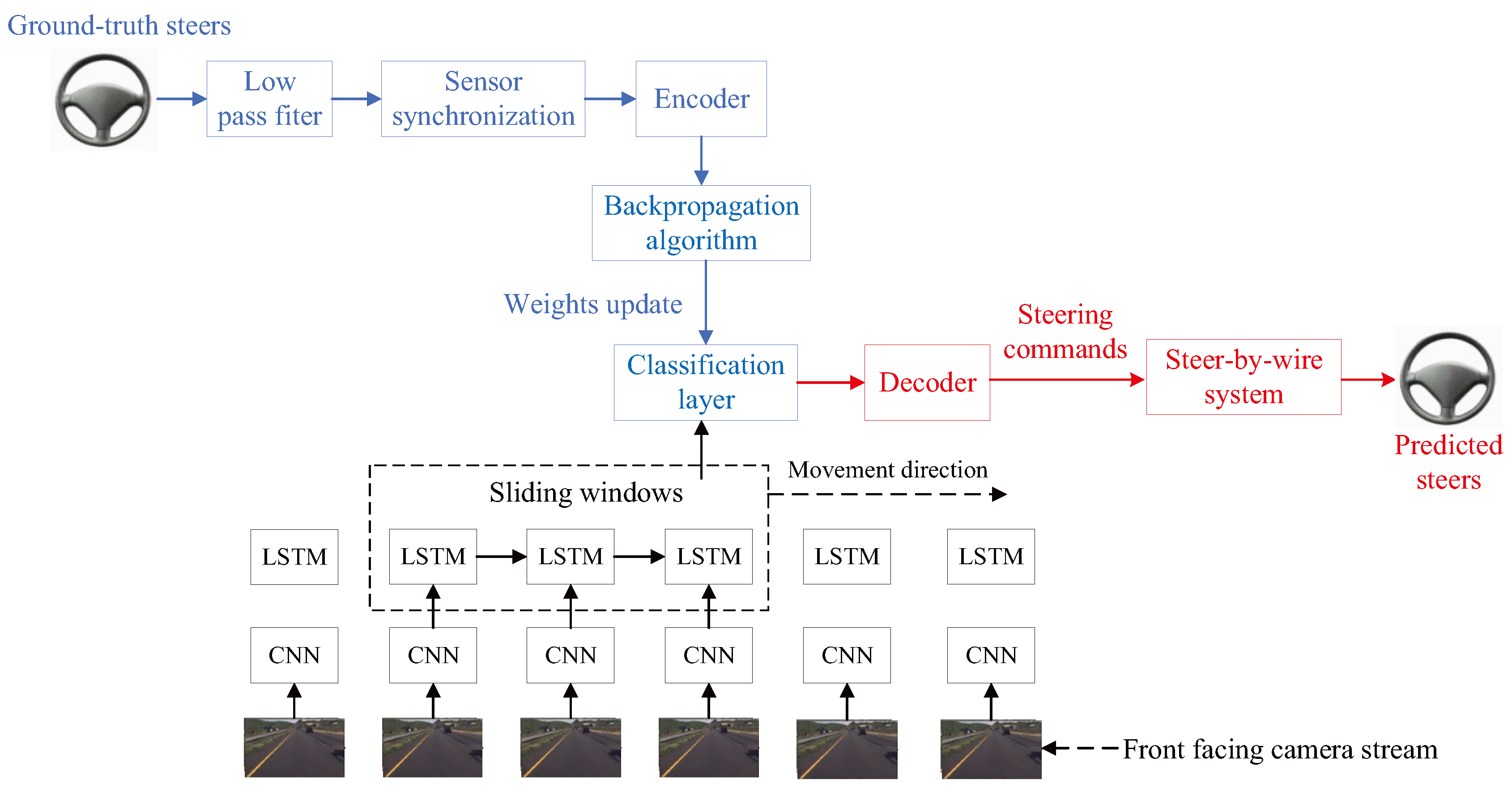
- Eraqi, H.M.; Moustafa, M.N.; Honer, J. End-to-end deep learning for steering autonomous vehicles considering temporal dependencies. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), MLITS Workshop, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Shen, C.; Zhao, X.; Fan, X.; Lian, X.; Zhang, F.; Kreidieh, A.R.; Liu, Z. Multi-receptive field graph convolutional neural networks for pedestrian detection. IET Intell. Trans. Syst. 2019, 13, 1319–1328. [Google Scholar] [CrossRef]
- Xu, H.; Srivastava, G. Automatic recognition algorithm of traffic signs based on convolution neural network. Multimed. Tools Appl. 2020, in press. [Google Scholar] [CrossRef]
- Alghmgham, D.A.; Latif, G.; Alghazo, J.; Alzubaidi, L. Autonomous traffic sign (ATSR) detection and recognition using deep CNN. Procedia Comput. Sci. 2019, 163, 266–274. [Google Scholar] [CrossRef]
- Lee, E.; Kim, D. Accurate traffic light detection using deep neural network with focal regression loss. Image Vis. Comput. 2019, 87, 24–36. [Google Scholar] [CrossRef]
- Kim, H.K.; Yoo, K.Y.; Park, J.H.; Jung, H.Y. Traffic light recognition based on binary semantic segmentation network. Sensors 2019, 19, 1700. [Google Scholar] [CrossRef]
- Testolin, A.; Stoianov, I.; Zorzi, M. Letter perception emerges from unsupervised deep learning and recycling of natural image features. Nat. Hum. Behav. 2017, 1, 657–664. [Google Scholar] [CrossRef]
- Fraga-Lamas, P.; Ramos, L.; Mondejar-Guerra, V.; Fernandez-Carames, T.M. A review on IoT deep learning UAV systems for autonomous obstacle detection and collision avoidance. Remote Sens. 2019, 11, 2144. [Google Scholar] [CrossRef]
- Micucci, A.; Mantecchini, L.; Sangermano, M. Analysis of the relationship between turning signal detection and motorcycle driver’s characteristics on urban roads; A case study. Sensors 2019, 19, 1802. [Google Scholar] [CrossRef]
- Micucci, A.; Sangermano, M. A study on cyclists behaviour and bicycles kinematic. Int. J. Trans. Dev. Integr. 2020, 4, 14–28. [Google Scholar] [CrossRef]
- Khamparia, A.; Singh, K.M. A systematic review on deep learning architectures and applications. Expert Syst. 2019, 36, e12400. [Google Scholar] [CrossRef]
- Carrio, A.; Sampedro, C.; Rodriguez-Ramos, A.; Campoy, P. A review of deep learning methods and applications for unmanned aerial vehicles. J. Sens. 2017, 2017, 3296874. [Google Scholar] [CrossRef]
- Zhang, R.; Li, G.; Li, M.; Wang, L. Fusion of images and point clouds for the semantic segmentation of large-scale 3D scenes based on deep learning. ISPRS J. Photogram. Remote Sens. 2018, 143, 85–96. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, F.; Wu, F.; Zeng, D.; Ji, Y.M.; Jing, X.Y. Multi-view semantic learning network for point cloud based 3D object detection. Neurocomputing 2020, in press. [Google Scholar] [CrossRef]
- Sirohi, D.; Kumar, N.; Rana, P.S. Convolutional neural networks for 5G-enabled intelligent transportation system: A systematic review. Comput. Commun. 2020, 153, 459–498. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Reference | Method | Remarks | Performances |
|---|---|---|---|---|
| Monocular vision | Mancini, et al. (2015) [46] | CNN | The input of the proposed network is an RGB image and the features are extracted by the VGG19 module. Then these features are used to obtain the dense depth maps and obstacles bounding boxes based on CNNs. | Recall of 90.85% on UnrealDataset dataset. |
| Parmar, et al. (2019) [48] | CNN | The range of the object in meters and class labels for each detected object are produced based on the proposed feed-forward CNN. | mAP of 96.92% on KITTI dataset. | |
| Mancini, et al. (2016) [55] | FCN | A fully convolutional network (FCN) is proposed, which is used to obtain depth estimation based on both images and optical flows. | RMSE of 6.863 on KITTI dataset. | |
| Jia, et al. (2016) [56] | CNN and DBN | The local information of a candidate block is generalized by CNN, and the global information of the whole image is generalized by DBN. Then all the features are transferred to the final classifier together for obstacle detection. | Block accuracy of 90.64% on KITTI dataset. | |
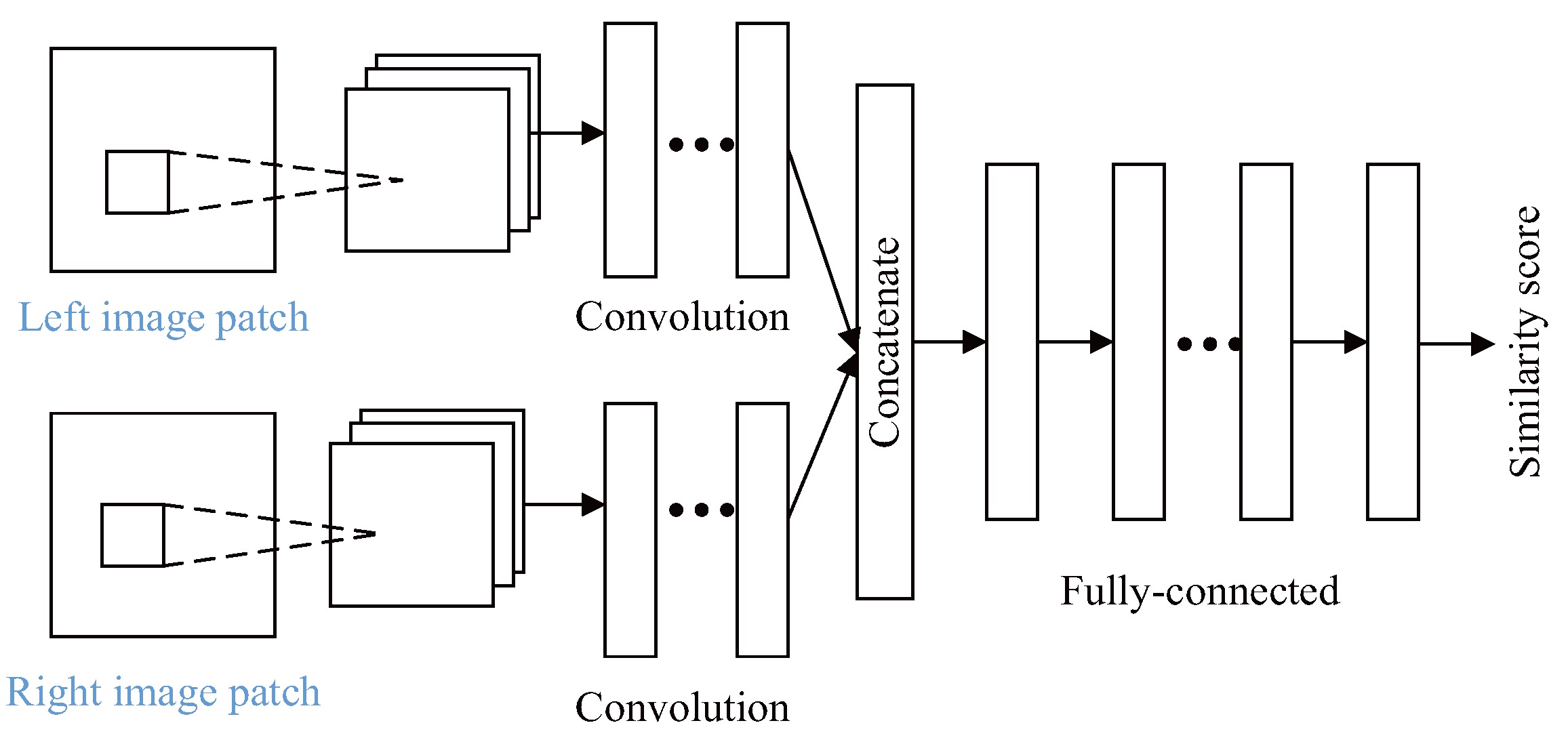
| Binocular vision | bontar, et al. (2016) [50] | 2D-CNN | A CNN architecture is presented for measuring the similarity of image patches, which is used to deal with the problem of stereo matching. | Misclassified pixels error of 2.43% on KITTI dataset. |
| Nguyen, et al. (2019) [51] | 2D-CNN | A wide context learning network is used to extract global context information. Then a stacked encoder-decoder 2D CNNs performs contextual aggregation followed by a regression step to predict the disparity map. | 2PE of 4.35%, 3PE of 2.74% on KITTI dataset. | |
| Zhang, et al. (2019) [52] | 3D-CNN | There are two parts in the proposed network, namely the 2D residual dense attention net and the 3D convolutional attention net. They are used for feature extraction and matching respectively. | 2PE of 3.21%, 3PE of 2.09% on KITTI dataset. | |
| Kendall, et al. (2017) [53] | 3D-CNN | The proposed method learns context in the disparity cost volume using 3-D convolutions and regresses sub-pixel disparity values from the disparity cost volume using a soft Argmin function. | 2PE of 3.46%, 3PE of 2.30% on KITTI dataset. | |
| Dairi, et al. (2018) [54] | SAE | A deep stacked auto-encoders (SAE) model and an unsupervised k-nearest neighbor algorithm are used to detect the obstacles. | AUC of 0.91 on MSVUD and DUSD datasets. | |
| Zhong, et al. (2018) [57] | RNN | The input of the proposed RNN is a continuous stereo video. Then, a depth-map at each frame is predicted directly. There is no pre-training process, and no need of ground-truth disparity maps in the proposed method. | RMSE of 4.451 on KITTI dataset. | |
| Jie, et al. (2018) [58] | RNN | A left-right comparative recurrent model is proposed to perform left-right consistency checking jointly with disparity estimation. | Error rates of all the pixels of 3.03% on KITTI dataset. |
| Method | ImageNet-1k | Places205 | Places365 | Places401 |
|---|---|---|---|---|
| (Top1/Top5) | (Top1/Top5) | (Top1/Top5) | (Top1/Top5) | |
| Two-Resolution CNN | 21.8%/6.0% | 36.4%/10.4% | 42.8%/13.2% | 47.4%/16.3% |
| Structure | Reference | Method | Remarks | Performances |
|---|---|---|---|---|
| GoogLeNet | Chen et al. (2019) [59] | CNN | A multi-label neural network is proposed for road scene recognition, where single and multiple class classification modes are incorporated into a multi-level cost function for training with imbalanced categories. | mAP of 83.1% on their own dataset. |
| GoogLeNet | Tang et al. (2017) [61] | CNN | GoogLeNet is partitioned into three parts, which are used to extract the features. Then these features are fused for the final recognition based on the product rule. | Accuracy of 92.90% on Scenel5 dataset. |
| ResNet | Zhang et al. (2019) [63] | CNN | The separate predictions are carried out based on the features obtained from multiple levels of the network. Then the final prediction is made by the ensemble learning within the network. | Top5 accuracy of 98.7% on UMC dataset. |
| ResNet | Liu, et al. (2019) [64] | CNN | A transfer learning model based on the ResNet is proposed, where the multi-layer feature fusion is utilized. The interlayer discriminating features are fused for classification by Softmax regression. | Accuracy of 94.05% on MIT67 dataset. |
| VGGNet | Cheng, et al. (2018) [65] | CNN | The correlations of object configurations among different scenes are exploited through the co-occurrence pattern of all objects across scenes, and then the representative and discriminative objects in the scene can be chosen. | Accuracy of 94.37% on Scene15 dataset. |
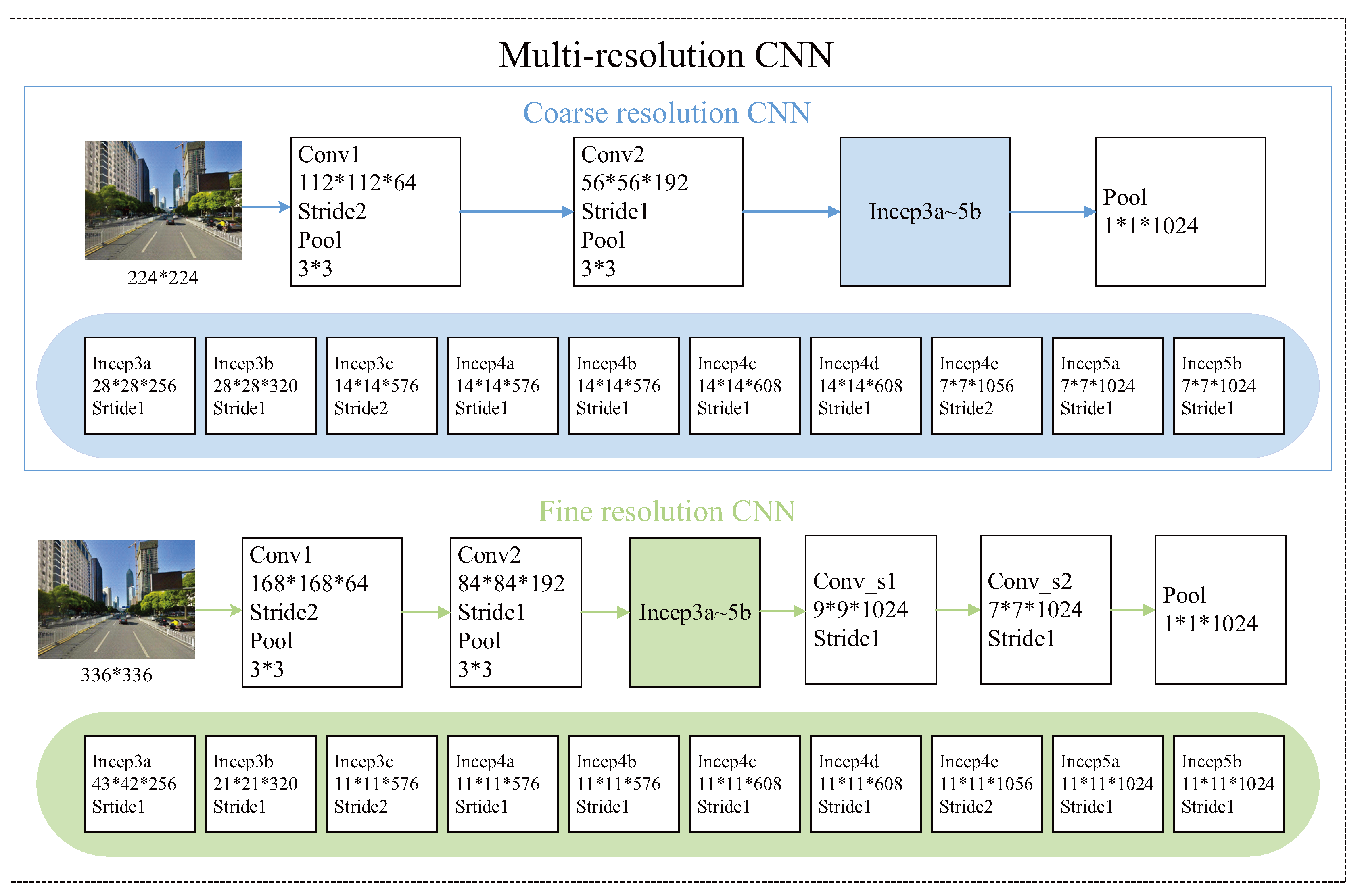
| Bn-Inception | Wang, et al. (2017) [60] | CNN | The proposed multi-resolution CNN architecture is composed of coarse resolution CNNs and fine resolution CNNs, which can capture visual content and structure at multiple levels. | Top5 error of 13.2% on Place365 dataset. |
| 2D-LSTM | Byeon et al. (2015) [62] | RNN | In this approach, segmentation, classification, and context integration are all carried out by 2D LSTM RNNs, and the texture and spatial model parameters can be learned within a single model. | Pixel accuracy of 78.56% on Stanford Background dataset. |
| DenseNet | Fu et al. (2020) [36] | CAE | A contextual deconvolution network is proposed by embedding two types of contextual modules. The channel and the spatial contextual module utilize global and local features respectively. | Mean IoU of 80.5% on Cityscapes dataset. |
| CNN and RNN | Sun et al. (2019) [66] | Hybrid network | Deep features are extracted from the information of object semantics, global appearance, and contextual appearance. Then these features are fused for scene recognition based on a comprehensive representation. | Accuracy of 89.51% on MIT67 dataset. |
| Category | Reference | Method | Remarks | Performances |
|---|---|---|---|---|
| One-stage method | John et al. (2018) [67] | CNN | The road scene features are extracted by the fine-tuned Deconvnet filters. Then scene features are used to estimate the road lanes based on a extra trees-based classification and regression framework. | Accuracy of 98.42% on TTI dataset. |
| Kim et al. (2017) [69] | CNN | The proposed framework combined CNN and a stacked extreme learning machine architecture, which can reduce computation time dramatically. | Accuracy of 98.7% on Caltech-cordova1 dataset. | |
| Li et al. (2017) [71] | CNN and RNN | The proposed framework processes an input image as a sequence of the region of interests (ROIs), and applies two steps of feature extraction on each ROI by CNNs and RNNs. | AUC of 0.99 on Caltect dataset. | |
| Tian et al. (2018) [72] | Fast-RCNN | Multiple strategies, such as fast multi-level combination, context cues, and a new anchor generating method are employed for lane markings detection. | Precision of 83.5% on their own dataset. | |
| Two-stage method | Neven et al. (2018) [73] | CNN | The output of the proposed lane detection network is a lane instance map, which is based on the label of each lane pixel with a lane ID. Then the lane pixels are transformed using the transformation matrix, to finally get the lane. | Accuracy of 96.4% on TuSimple dataset. |
| Yang et al. (2019) [74] | CNN | Multiple level features are extracted based on the VGG16 encoder. Then these features are utilized for the semantic segmentation of the lanes, which can predict the high quality lane maps. | Accuracy of 93.8% on TuSimple dataset. | |
| Zou et al. (2020) [75] | CNN and RNN | In the proposed method, information of each frame is abstracted by a CNN block. Then CNN features of continuous frames are input into the RNN block for feature learning and lane prediction. | Accuracy of 97.3% on TuSimple dataset. | |
| Ghafoorian et al. (2019) [76] | GAN | In the proposed Generative adversarial networks (GANs), the source data, a prediction map and a ground truth label are input into the discriminator together for lane marking segmentation. | Accuracy of 96.39% on TuSimple dataset. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, J.; Chen, Y.; Chen, Y.; Zhu, J.; Ali, D.; Cao, W. A Survey on Theories and Applications for Self-Driving Cars Based on Deep Learning Methods. Appl. Sci. 2020, 10, 2749. https://doi.org/10.3390/app10082749
Ni J, Chen Y, Chen Y, Zhu J, Ali D, Cao W. A Survey on Theories and Applications for Self-Driving Cars Based on Deep Learning Methods. Applied Sciences. 2020; 10(8):2749. https://doi.org/10.3390/app10082749
Chicago/Turabian StyleNi, Jianjun, Yinan Chen, Yan Chen, Jinxiu Zhu, Deena Ali, and Weidong Cao. 2020. "A Survey on Theories and Applications for Self-Driving Cars Based on Deep Learning Methods" Applied Sciences 10, no. 8: 2749. https://doi.org/10.3390/app10082749
APA StyleNi, J., Chen, Y., Chen, Y., Zhu, J., Ali, D., & Cao, W. (2020). A Survey on Theories and Applications for Self-Driving Cars Based on Deep Learning Methods. Applied Sciences, 10(8), 2749. https://doi.org/10.3390/app10082749