An Approach to Knowledge Base Completion by a Committee-Based Knowledge Graph Embedding


Abstract
:1. Introduction
2. Related Work
3. Knowledge Base Completion
4. Committee-Based Knowledge Base Completion
5. Measuring Plausibility by Embedding Committee
6. Experiments
6.1. Experimental Settings
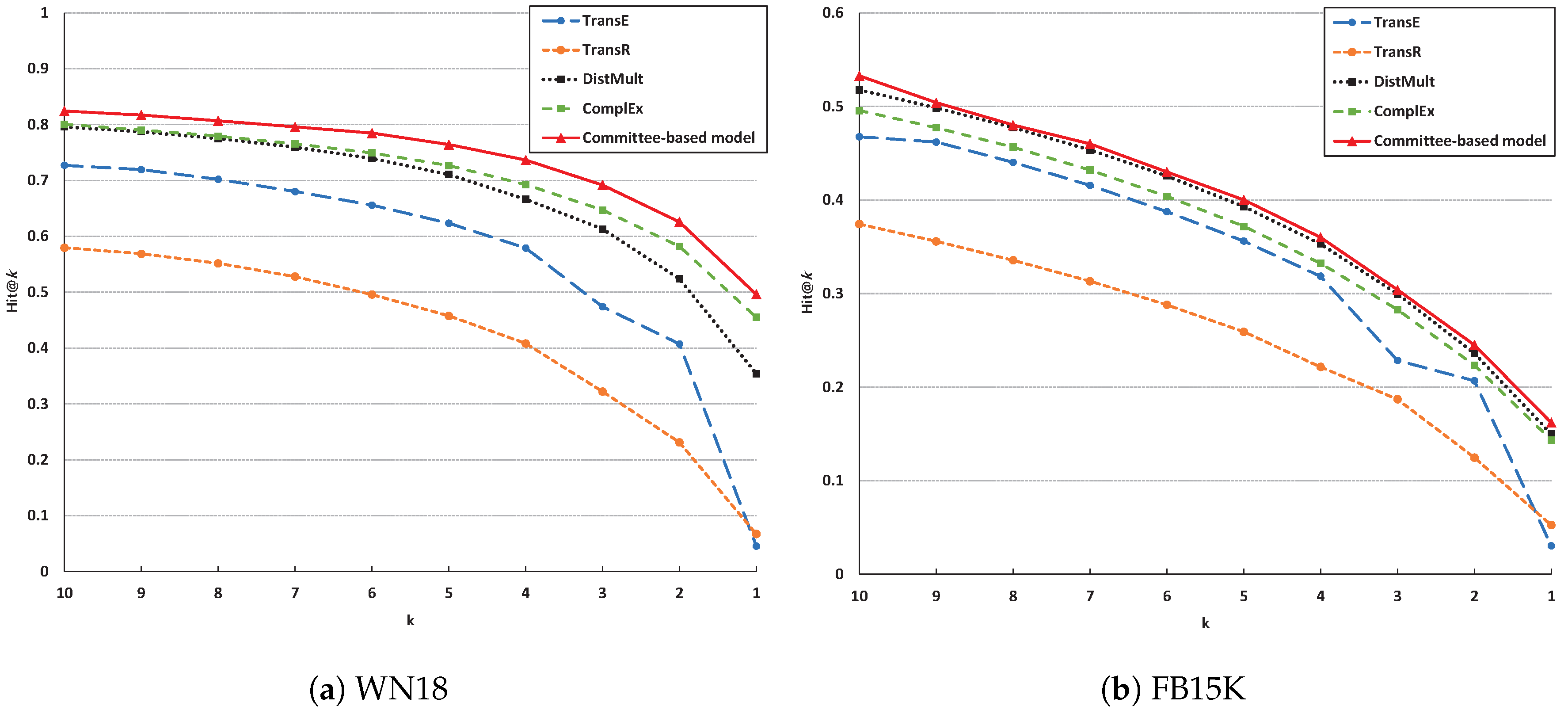
6.2. Experimental Results
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. DBpedia—A Large-scale, Multilingual Knowledge Base Extracted from Wikipedia. Semant. Web J. 2015, 6, 167–195. [Google Scholar]
- Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.R., Jr.; Mitchell, T.M. Toward an architecture for never-ending language learning. In Proceedings of the 24th AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010; pp. 1306–1313. [Google Scholar]
- West, R.; Gabrilovich, E.; Murphy, K.; Sun, S.; Gupta, R.; Lin, D. Knowledge Base Completion via Search-Based Question Answering. In Proceedings of the 23th International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 515–526. [Google Scholar]
- Bordes, A.; Glorot, X.; Weston, J.; Bengio, Y. A semantic matching energy function for learning with multi-relational data. Mach. Learn. 2014, 94, 233–259. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 2787–2795. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A three-way model for collective learning on multi-relational data. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 809–816. [Google Scholar]
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A. Reasoning with Neural Tensor Networks for Knowledge Base Completion. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 926–934. [Google Scholar]
- Xiao, H.; Huang, M.; Zhu, X. From one point to a manifold: Knowledge graph embedding for precise link prediction. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 1315–1321. [Google Scholar]
- Kadlec, R.; Bajgar, O.; Kleindienst, J. Knowledge Base Completion: Baselines Strike Back. In Proceedings of the 2nd Workshop on Representation Learning for NLP, Vancouver, BC, Canada, 3 August 2017; pp. 69–74. [Google Scholar]
- Wang, Q.; Wang, B.; Guo, L. Knowledge Base Completion Using Embeddings and Rules. In Proceedings of the 24th International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 1859–1865. [Google Scholar]
- Choi, S.J.; Song, H.J.; Yoon, H.G.; Park, S.B.; Park, S.Y. A Re-ranking Model for Accurate Knowledge Base Completion with Knowledge Base Schema and Web Statistic. In Proceedings of the IEEE Congress on Evolutionary Computation, San Sebastián, Spain, 6–11 July 2016; pp. 4958–4964. [Google Scholar]
- Fan, M.; Zhou, Q.; Zheng, T.F.; Grishman, R. Distributed representation learning for knowledge graphs with entity descriptions. Pattern Recognit. Lett. 2017, 93, 31–37. [Google Scholar]
- He, S.; Liu, K.; Ji, G.; Zhao, J. Learning to Representation Knowledge Graphs with Gaussian Embedding. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 623–632. [Google Scholar]
- Jia, Y.; Wang, Y.; Jin, X.; Lin, H.; Cheng, X. Knowledge Graph Embedding: A Locally and Temporally Adaptive Translation-Based Approach. ACM Trans. Web 2017, 12, 1–33. [Google Scholar]
- Xie, R.; Liu, Z.; Sun, M. Representation Learning of Knowledge Graphs with Hierarchical Types. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2955–2971. [Google Scholar]
- Nickel, M.; Murphy, K.; Tresp, V.; Gabrilovich, E. A review of relational machine learning for knowledge graphs. Proc. IEEE 2016, 104, 11–33. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar]
- Fan, M.; Zhou, Q.; Chang, E.; Zheng, T.F. Transition-based knowledge graph embedding with relational mapping properties. In Proceedings of the 28th Pacific Asia Conference on Language, Information and Computing, Phuket, Thailand, 12–14 December 2014; pp. 328–337. [Google Scholar]
- Feng, J.; Huang, M.; Wang, M.; Zhou, M.; Hao, Y.; Zhu, X. Knowledge Graph Embedding by Flexible Translation. In Proceedings of the 15th International Conference on Principles of Knowledge Representation and Reasoning, Cape Town, South Africa, 25–29 April 2016; pp. 557–560. [Google Scholar]
- Ji, G.; Liu, K.; He, S.; Zhao, J. Knowledge graph completion with adaptive sparse transfer matrix. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 985–991. [Google Scholar]
- Zhu, J.Z.; Jia, Y.T.; Xu, J.; Qiao, J.Z.; Cheng, X.Q. Modeling the Correlations of Relations for Knowledge Graph Embedding. J. Comput. Sci. Technol. 2018, 33, 323–334. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the 28th AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014; pp. 1112–1119. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- García-Durán, A.; Bordes, A.; Usunier, N.; Grandvalet, Y. Combining two and three-way embedding models for link prediction in knowledge bases. J. Artif. Intell. Res. 2016, 55, 715–742. [Google Scholar]
- Jenatton, R.; Roux, N.L.; Bordes, A.; Obozinski, G.R. A latent factor model for highly multi-relational data. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 3167–3175. [Google Scholar]
- Liu, H.; Wu, Y.; Yang, Y. Analogical inference for multi-relational embeddings. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2018; pp. 2168–2178. [Google Scholar]
- Yang, B.; Yih, W.t.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Nickel, M.; Rosasco, L.; Poggio, T. Holographic Embeddings of Knowledge Graphs. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1955–1961. [Google Scholar]
- Plate, T.A. Holographic Reduced Representations. IEEE Trans. Neural Netw. 1995, 6, 623–641. [Google Scholar]
- Trouillon, T.; Dance, C.R.; Gaussier, É.; Welbl, J.; Riedel, S.; Bouchard, G. Knowledge graph completion via complex tensor factorization. J. Mach. Learn. Res. 2017, 18, 4735–4772. [Google Scholar]
- Krompaß, D.; Tresp, V. Ensemble Solutions for Link-Prediction in Knowledge Graphs. In Proceedings of the 2nd Workshop on Linked Data for Knowledge Discovery, Porto, Portugal, 7–11th September 2015; pp. 1–10. [Google Scholar]
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 601–610. [Google Scholar]
- Bordes, A.; Weston, J.; Collobert, R.; Bengio, Y. Learning Structured Embeddings of Knowledge Bases. In Proceedings of the 25th AAAI Conference on Artificial Intelligence, Francisco, CA, USA, 7–11 August 2011; pp. 301–306. [Google Scholar]
- García-Durán, A.; Niepert, M. KBLRN: End-to-End Learning of Knowledge Base Representations with Latent, Relational, and Numerical Features. In Proceedings of the 34th Conference on Uncertainty in Artificial Intelligence, Monterey, CA, USA, 6–10 August 2018. [Google Scholar]
- Mikolov, T.; Yih, W.; Zweig, G. Linguistic Regularities in Continuous Space Word Representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 746–751. [Google Scholar]
- Fellbaum, C. WordNet: An Electronic Lexical Database; Bradford Books: Cambridge, MA, USA, 1998. [Google Scholar]
- Kinga, D.; Adam, J.B. A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
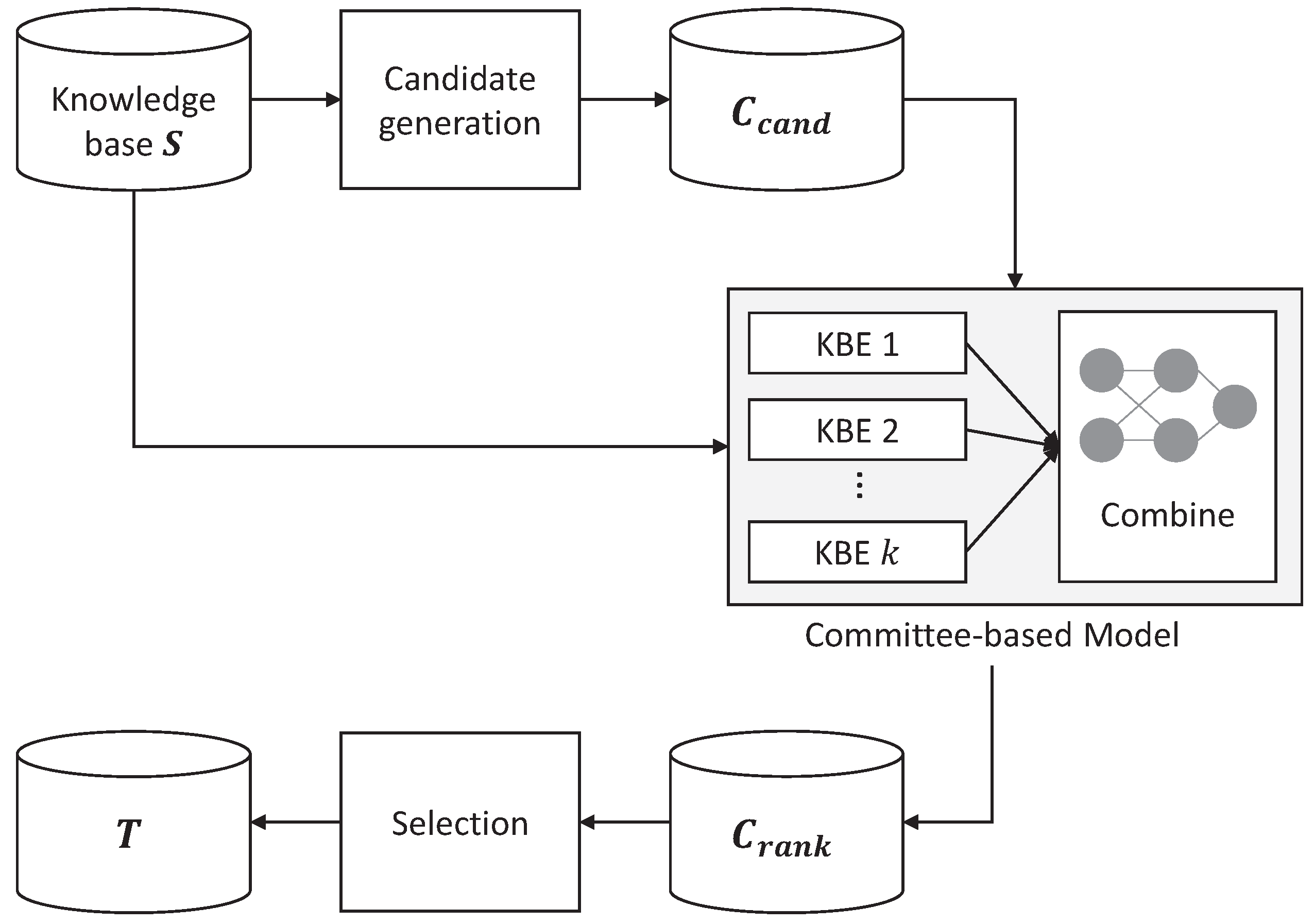

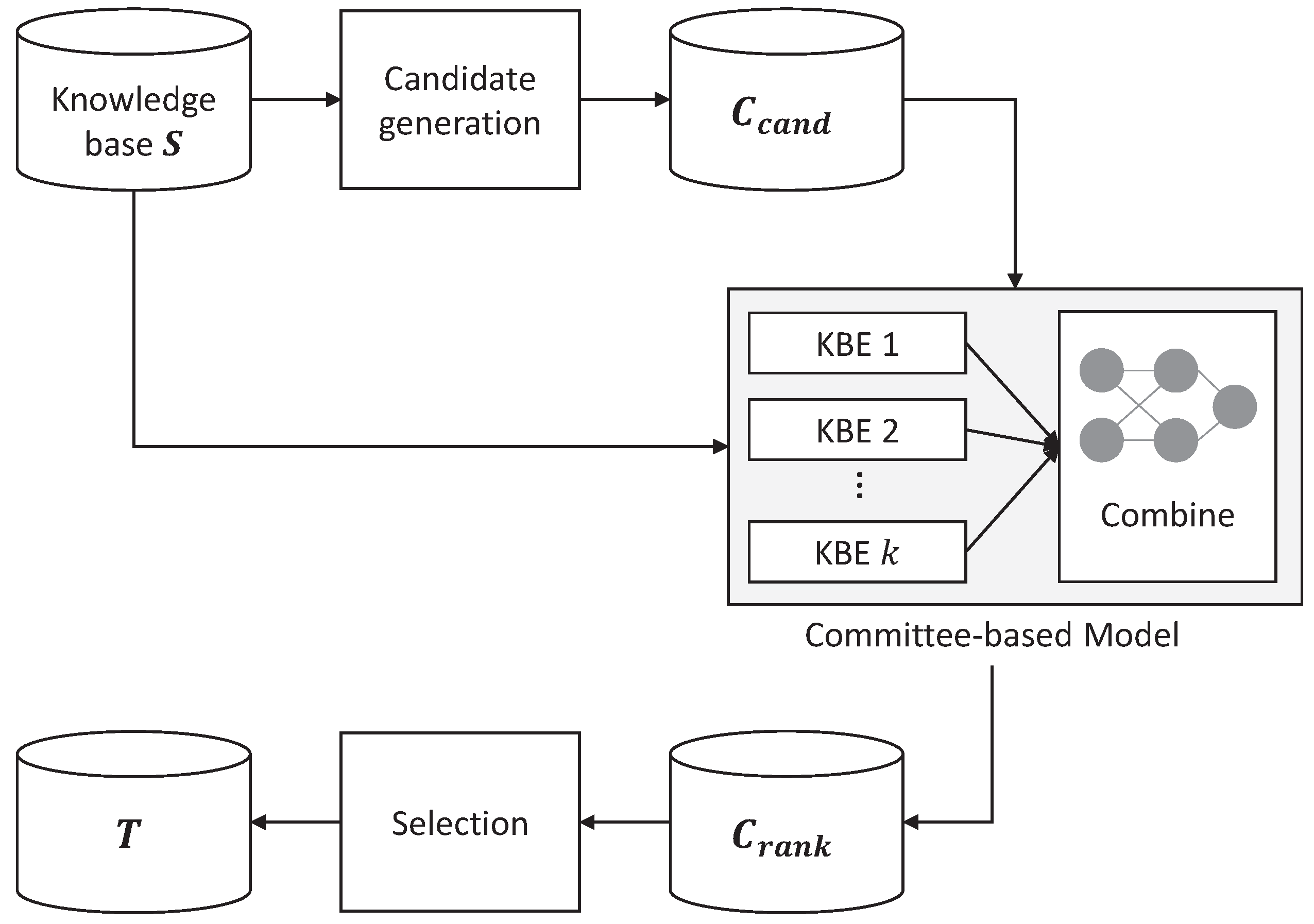{kind=link}
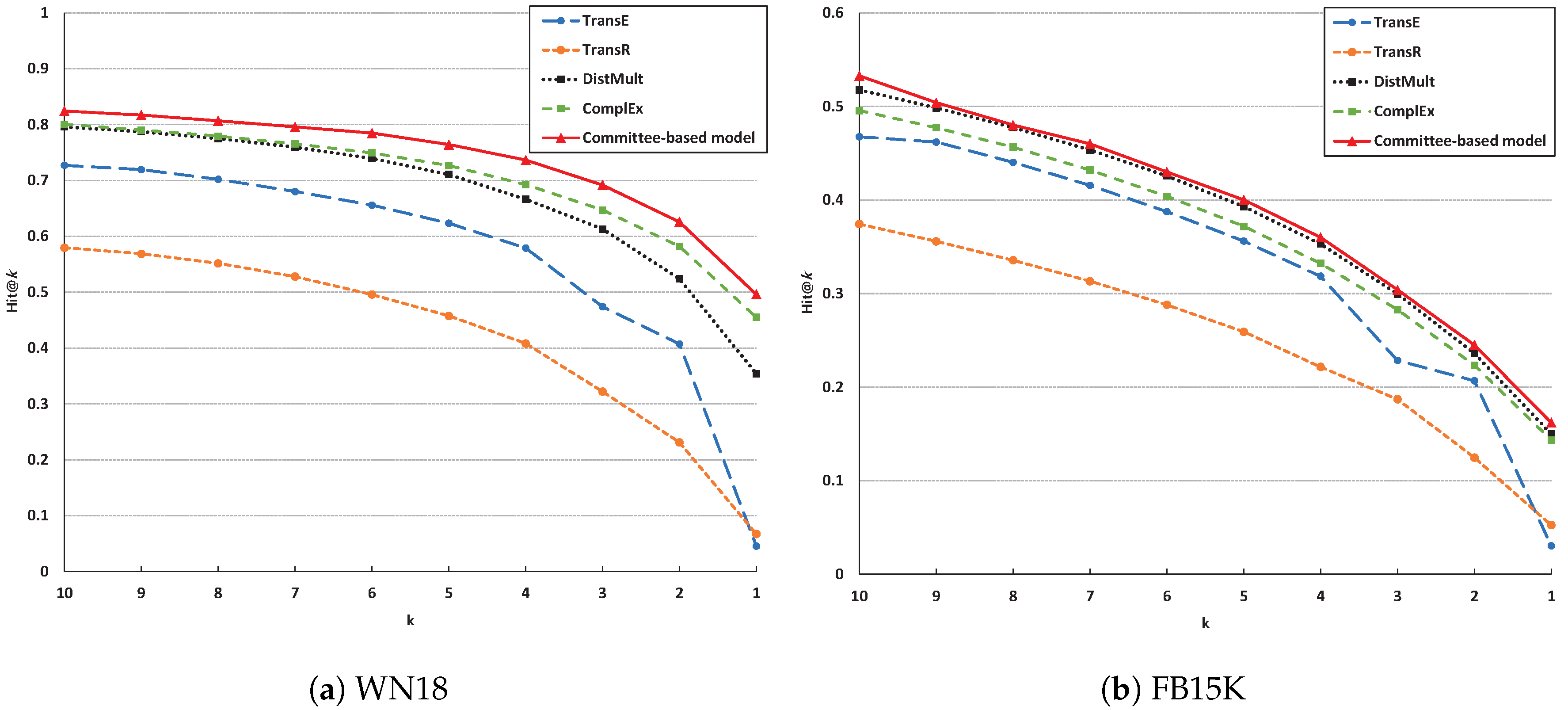{kind=link}
| Entity Embedding | Relation Embedding | Plausibility Function | |
|---|---|---|---|
| TransE | |||
| TransH | |||
| TransR | |||
| TransD | |||
| RESCAL | |||
| DistMult | |||
| HolE | |||
| ComplEx |
| Rank | TransE | TransR | DistMult | ComplEx |
|---|---|---|---|---|
| 1 | dairy product | leave | cheddar cheese | solid food |
| 2 | solid food | convertor | chalcidfly | dairy product |
| 3 | lover | solid food | tear down | degrade |
| 4 | free-reed instrument | internal secretion | immovableness | financial aid |
| 5 | fish | dairy product | fire | mixture |
| 6 | travel | wrong | solid food | tug |
| 7 | meat | foodstuff | pelargonium peltatum | copper-base alloy |
| 8 | preserves | baked goods | tyrant flycatcher | swamp plant |
| 9 | foodstuff | hair | dairy product | terabit |
| 10 | pull together | disposition | feather palm | previous question |
| TransE | TransR | DistMult | ComplEx | |
|---|---|---|---|---|
| TransE | - | 0.5904 | 0.4940 | 0.4946 |
| TransR | 0.5904 | - | 0.4916 | 0.4926 |
| DistMulti | 0.4940 | 0.4916 | - | 0.5317 |
| ComplEx | 0.4946 | 0.4926 | 0.5317 | - |
| Data Set | FB15K | WN18 |
|---|---|---|
| # of Entities | 14,951 | 40,943 |
| # of Relations | 1345 | 18 |
| # of Training Triples | 483,142 | 141,441 |
| # of Validation Triples | 50,000 | 5000 |
| # of Test Triples | 59,071 | 5000 |
| # of Total Triples | 592,213 | 151,441 |
| TransE | TransR | DistMult | ComplEx | Committee-Based Model | ||
|---|---|---|---|---|---|---|
| Hits@10 | Head | 0.721 | 0.575 | 0.787 | 0.794 | 0.813 |
| Tail | 0.733 | 0.584 | 0.805 | 0.807 | 0.835 | |
| Average | 0.727 | 0.579 | 0.796 | 0.800 | 0.824 | |
| Hits@3 | Head | 0.474 | 0.330 | 0.600 | 0.630 | 0.673 |
| Tail | 0.474 | 0.314 | 0.626 | 0.664 | 0.709 | |
| Average | 0.474 | 0.322 | 0.613 | 0.647 | 0.691 | |
| Hits@1 | Head | 0.057 | 0.080 | 0.340 | 0.441 | 0.477 |
| Tail | 0.034 | 0.054 | 0.368 | 0.469 | 0.514 | |
| Average | 0.045 | 0.067 | 0.354 | 0.455 | 0.495 | |
| TransE | TransR | DistMult | ComplEx | Committee-Based Model | ||
|---|---|---|---|---|---|---|
| Hits@10 | Head | 0.434 | 0.344 | 0.483 | 0.465 | 0.501 |
| Tail | 0.501 | 0.410 | 0.551 | 0.526 | 0.564 | |
| Average | 0.467 | 0.377 | 0.517 | 0.495 | 0.532 | |
| Hits@3 | Head | 0.213 | 0.167 | 0.272 | 0.260 | 0.281 |
| Tail | 0.244 | 0.207 | 0.327 | 0.305 | 0.330 | |
| Average | 0.228 | 0.187 | 0.299 | 0.282 | 0.305 | |
| Hits@1 | Head | 0.054 | 0.059 | 0.129 | 0.128 | 0.145 |
| Tail | 0.007 | 0.046 | 0.170 | 0.160 | 0.180 | |
| Average | 0.030 | 0.052 | 0.149 | 0.144 | 0.162 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, S.J.; Song, H.-J.; Park, S.-B. An Approach to Knowledge Base Completion by a Committee-Based Knowledge Graph Embedding. Appl. Sci. 2020, 10, 2651. https://doi.org/10.3390/app10082651
Choi SJ, Song H-J, Park S-B. An Approach to Knowledge Base Completion by a Committee-Based Knowledge Graph Embedding. Applied Sciences. 2020; 10(8):2651. https://doi.org/10.3390/app10082651
Chicago/Turabian StyleChoi, Su Jeong, Hyun-Je Song, and Seong-Bae Park. 2020. "An Approach to Knowledge Base Completion by a Committee-Based Knowledge Graph Embedding" Applied Sciences 10, no. 8: 2651. https://doi.org/10.3390/app10082651
APA StyleChoi, S. J., Song, H.-J., & Park, S.-B. (2020). An Approach to Knowledge Base Completion by a Committee-Based Knowledge Graph Embedding. Applied Sciences, 10(8), 2651. https://doi.org/10.3390/app10082651