Trends and Features of the Applications of Natural Language Processing Techniques for Clinical Trials Text Analysis



 , ,
, , 
Abstract
1. Introduction
1.1. Introduction to the NLP-Enhanced Clinical Trials Research
1.2. Introduction to Bibliometrics, Science Mapping, and Topic Modeling
1.3. Research Aims
2. Literature Review
3. Materials and Methods
3.1. Data Collection and Preprocessing
3.1.1. Data Collection
3.1.2. Data Pre-Processing
3.2. Performance Bibliometric Analysis
3.3. Scientific Collaboration Networks Analysis
3.4. Science Mapping Analysis
3.5. Structural Topic Modeling Analysis
4. Performance and Collaboration Analyses Results
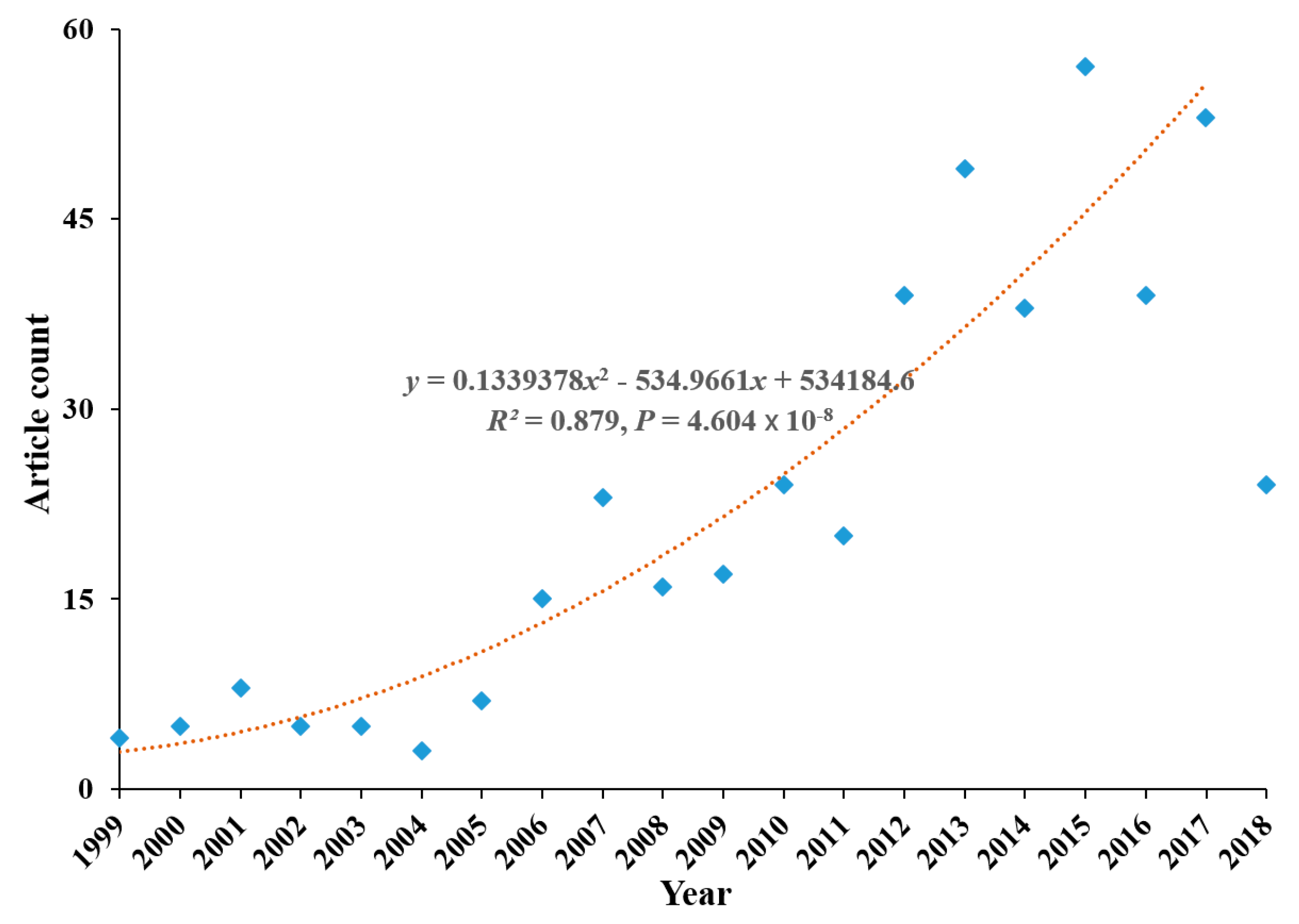
4.1. Analysis of Trend in Articles
4.2. Analysis of Publication Sources
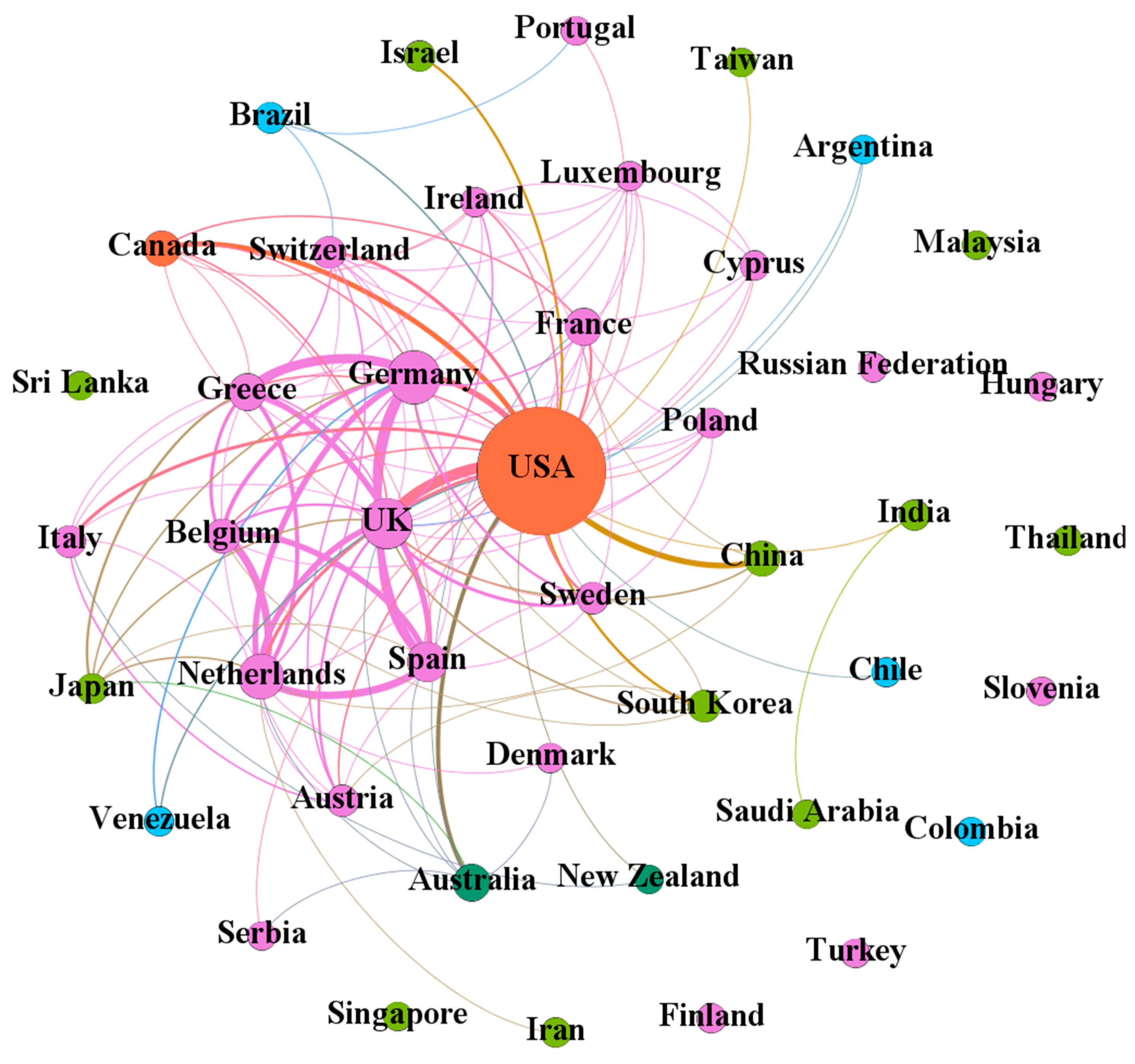
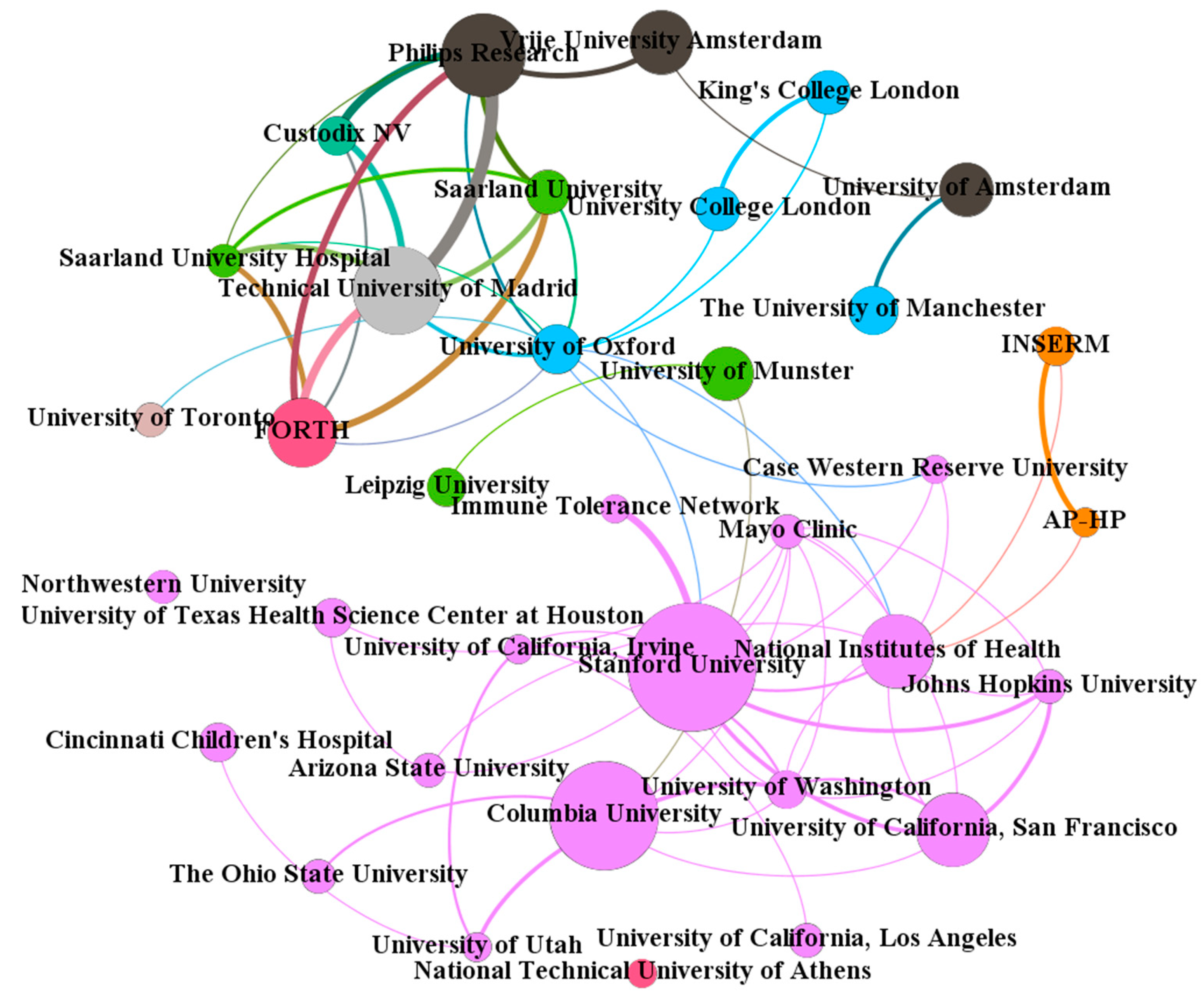
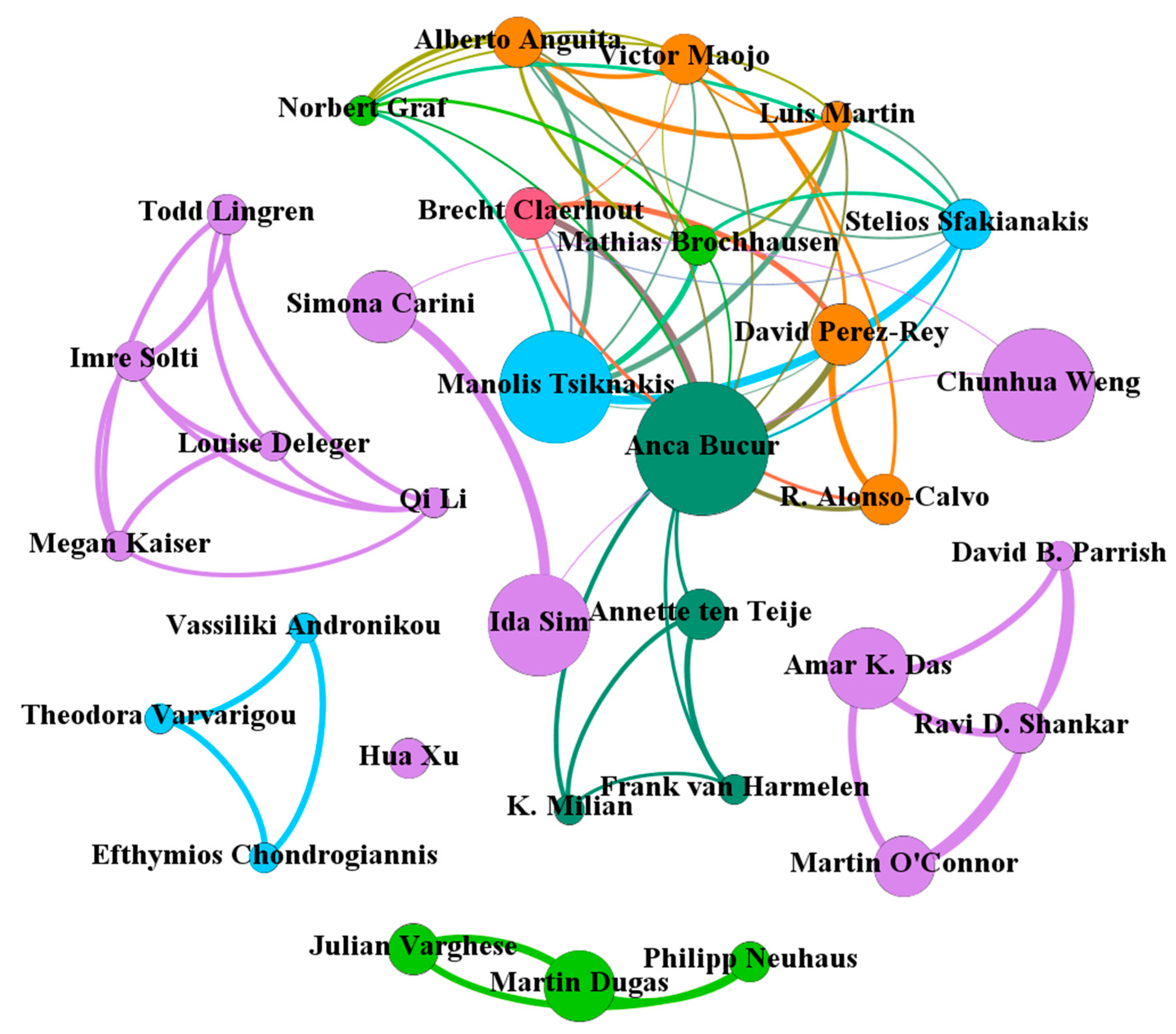
4.3. Analyses of Country/Region, Institution, and Author
4.4. Analysis of Scientific Collaboration
5. Science Mapping Analysis Results
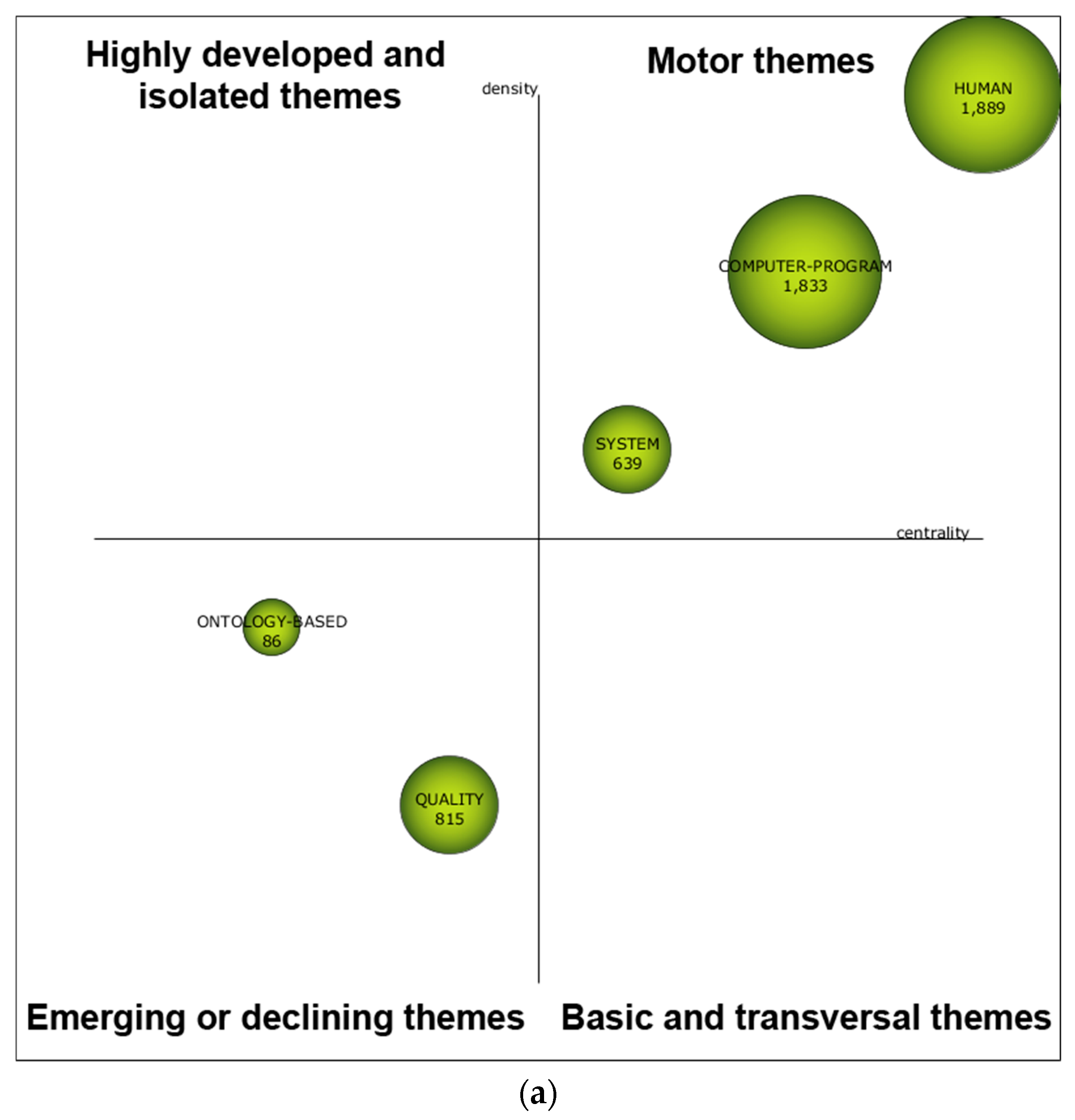
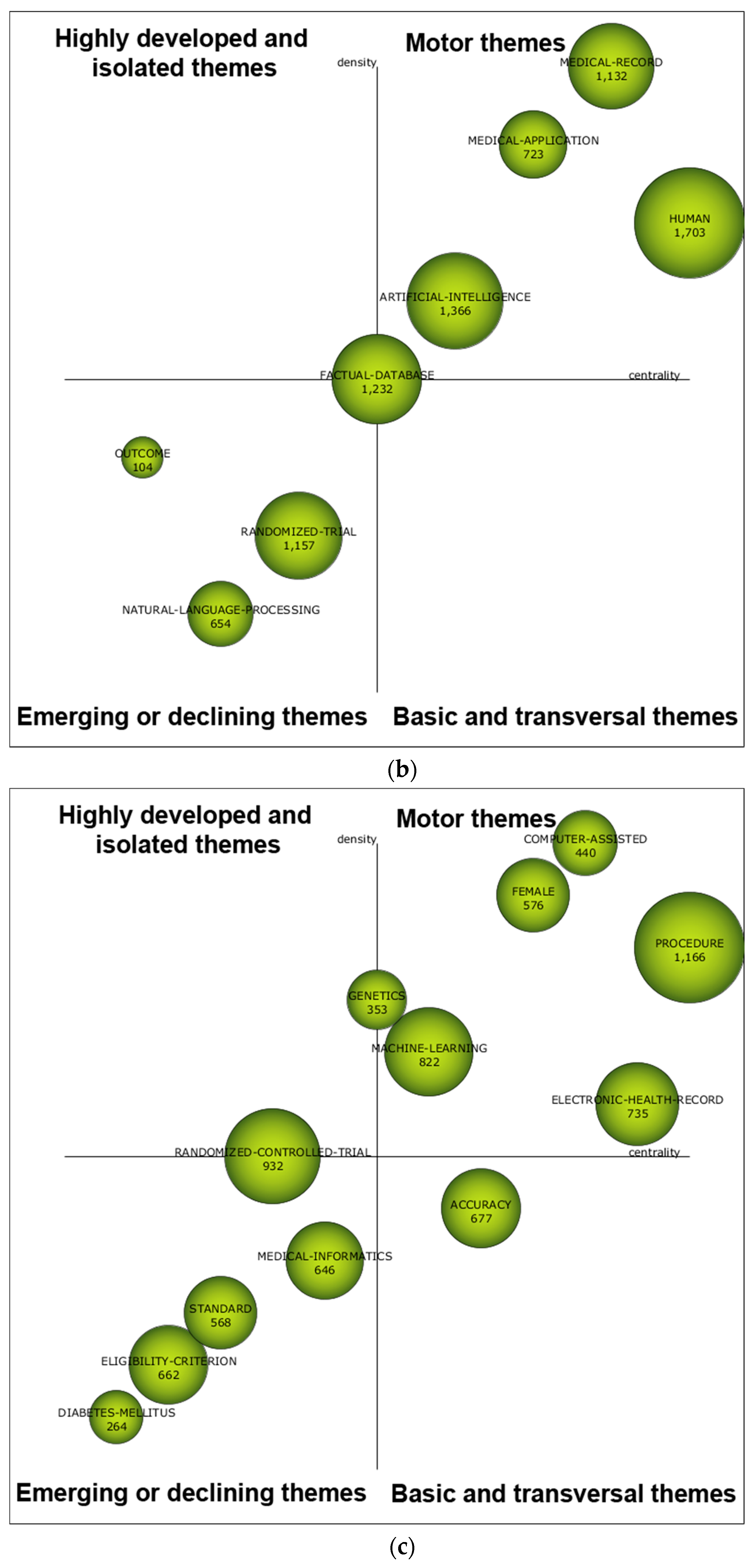
5.1. Analysis of the Content of the Papers Published
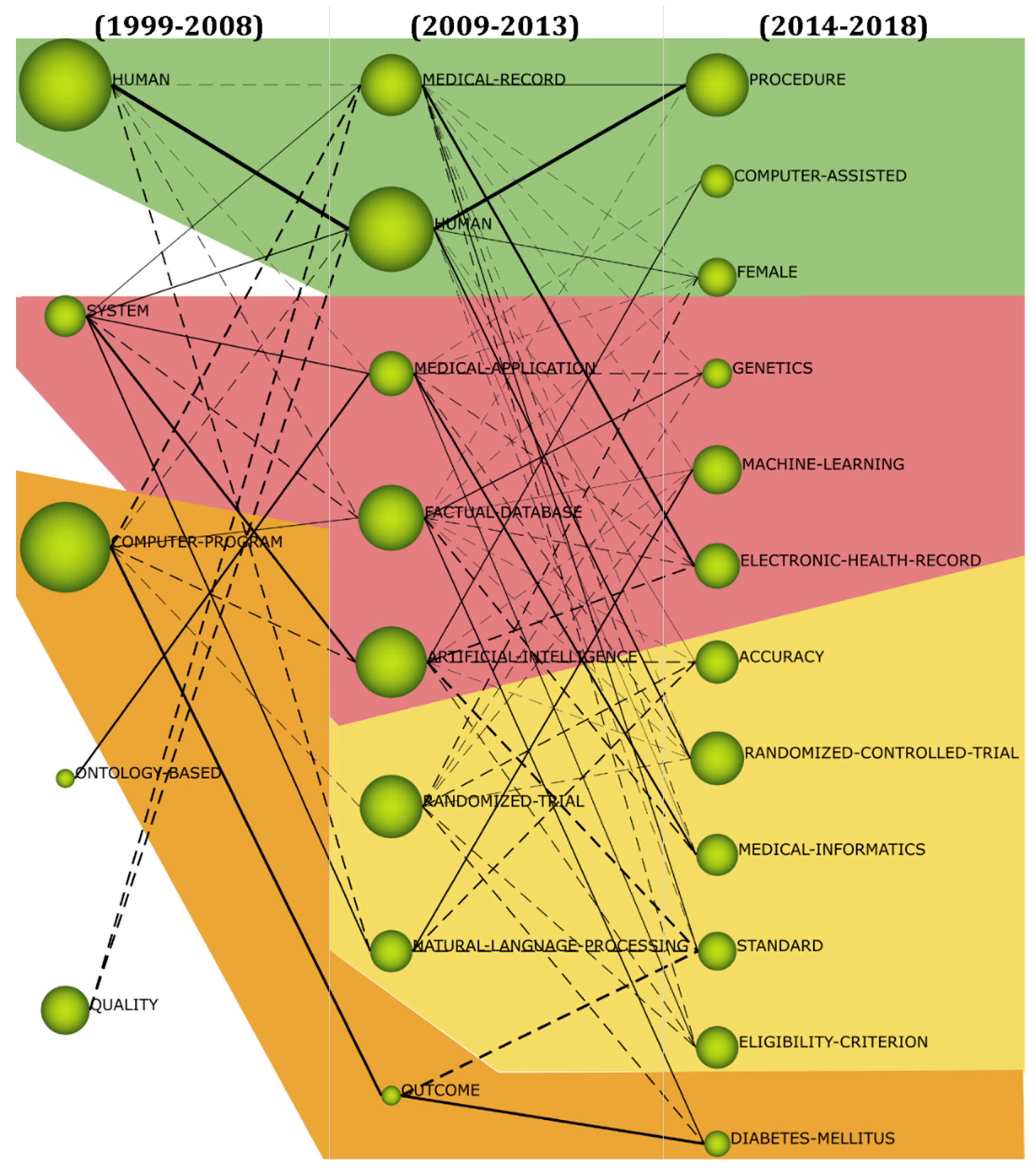
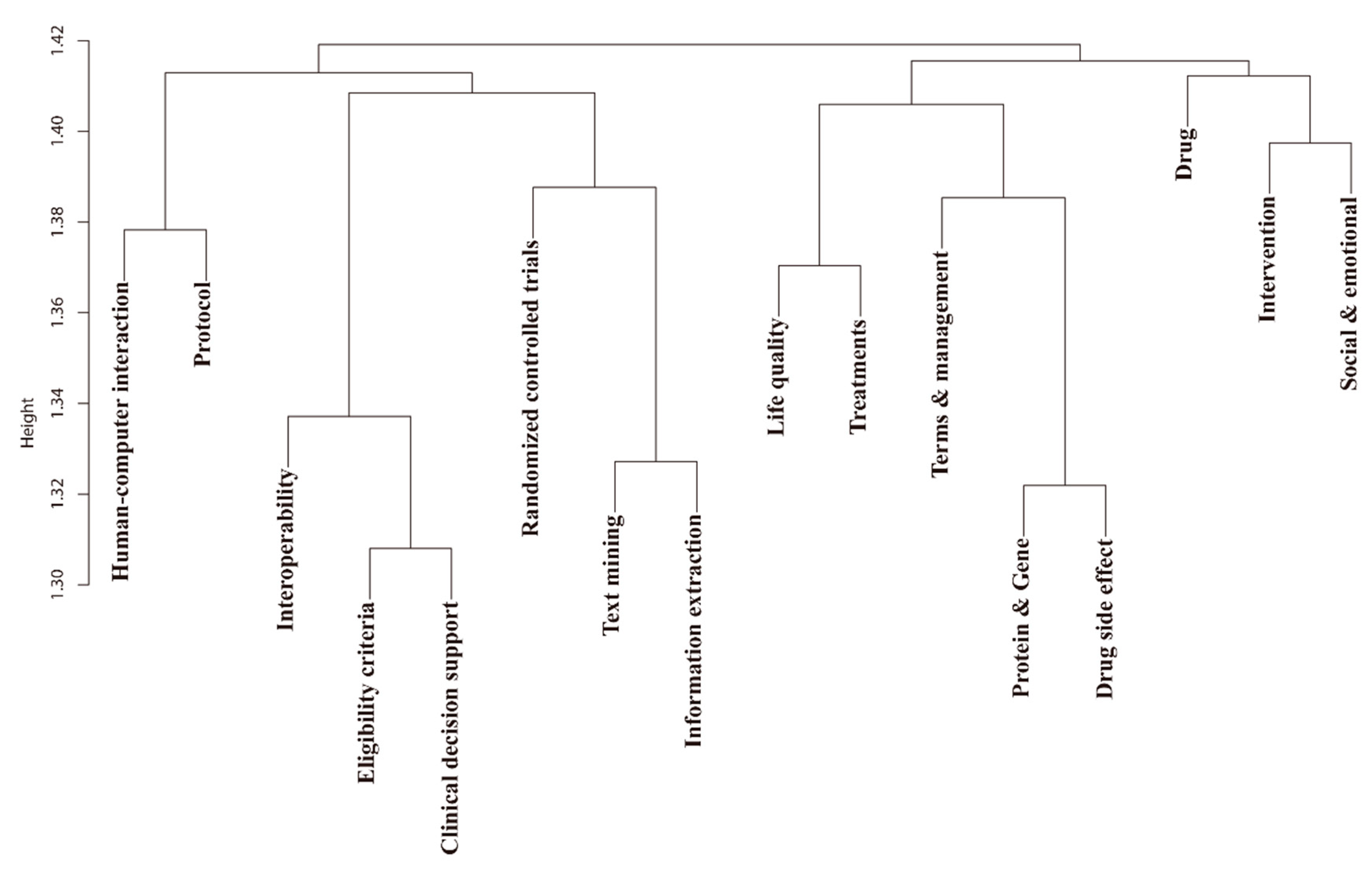
5.2. Conceptual Evolution Map
6. Structural Topic Modeling Analysis Results
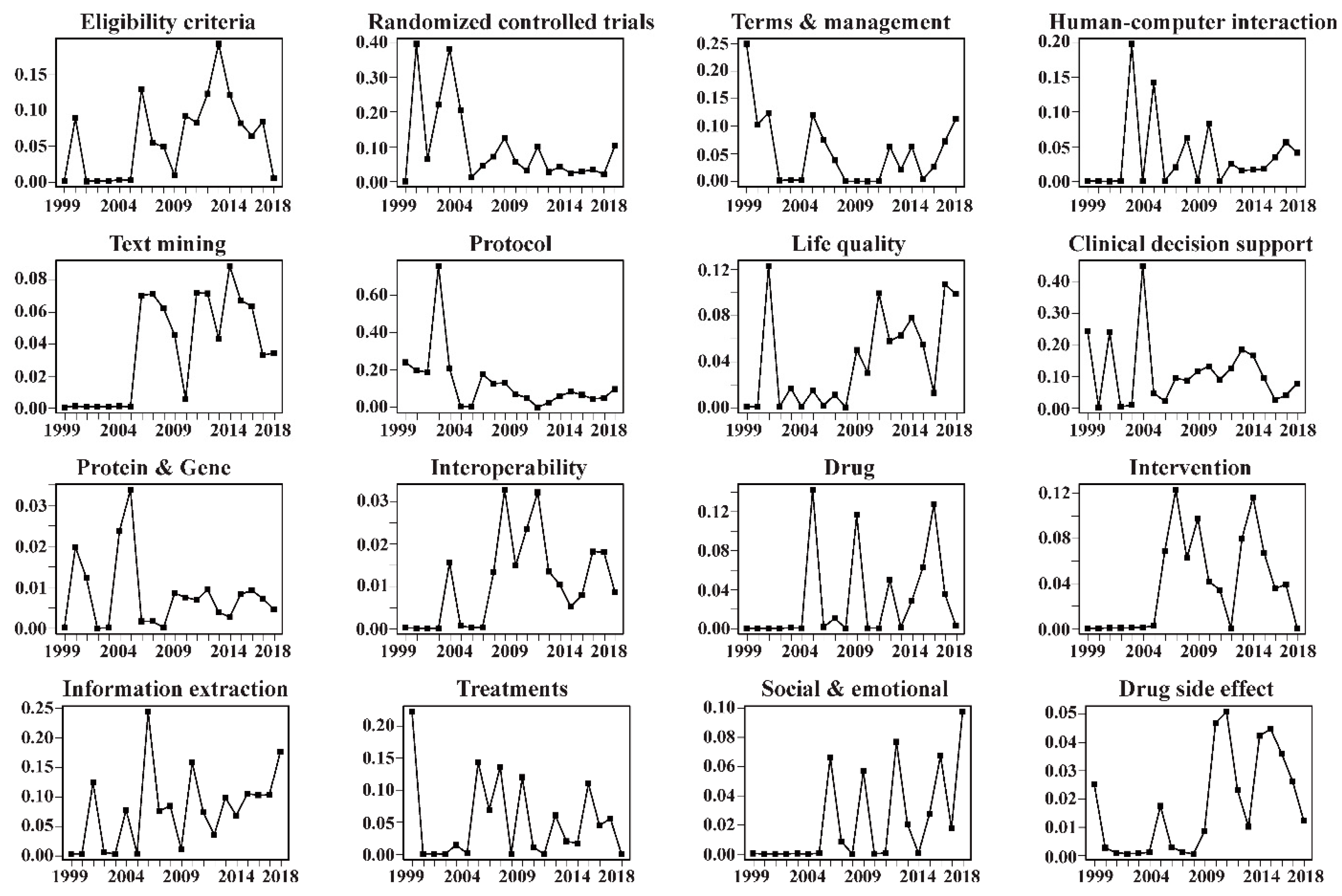
6.1. Topic Identification and Trends
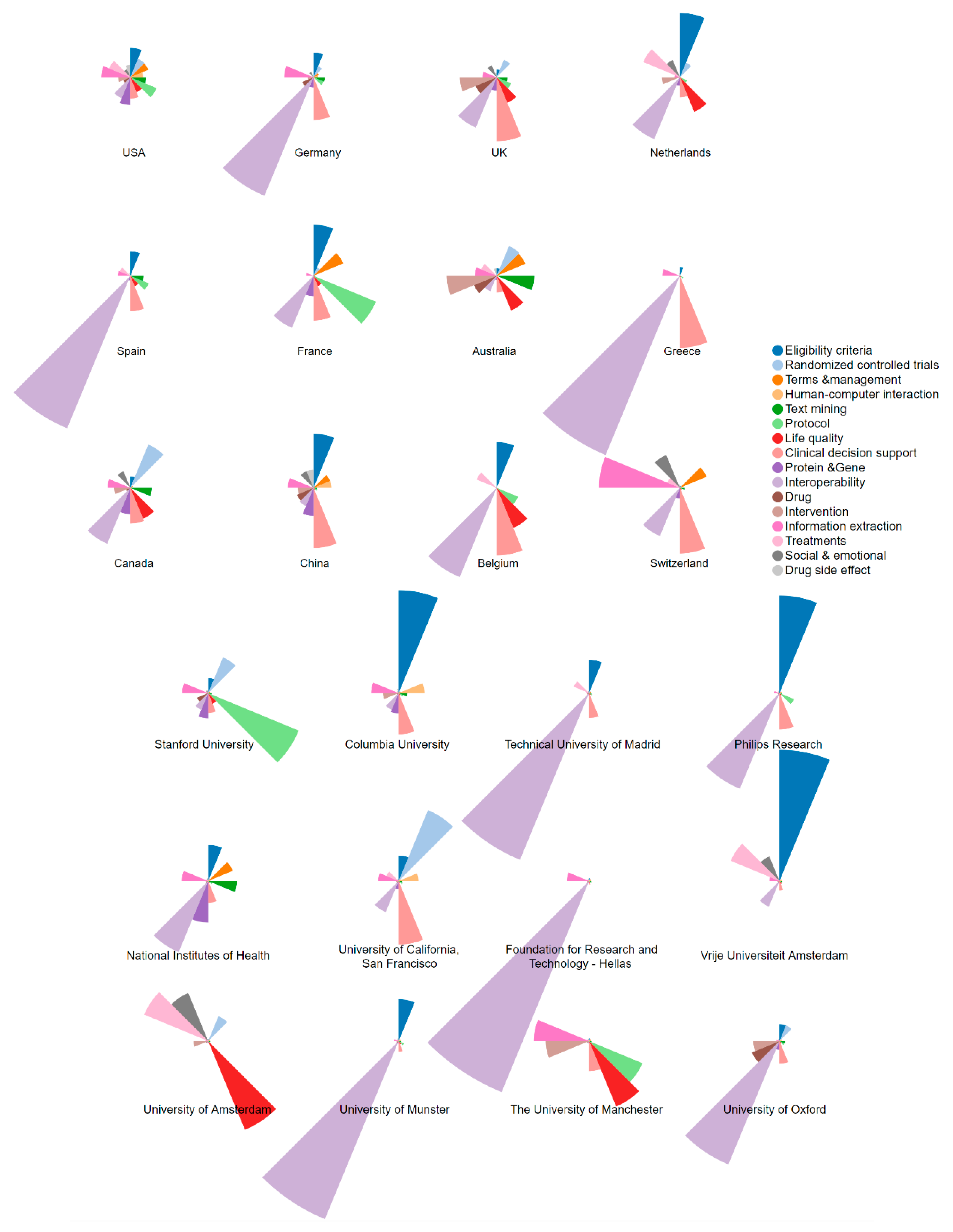
6.2. Topical Distributions Across Prolific Countries/Regions and Institutions
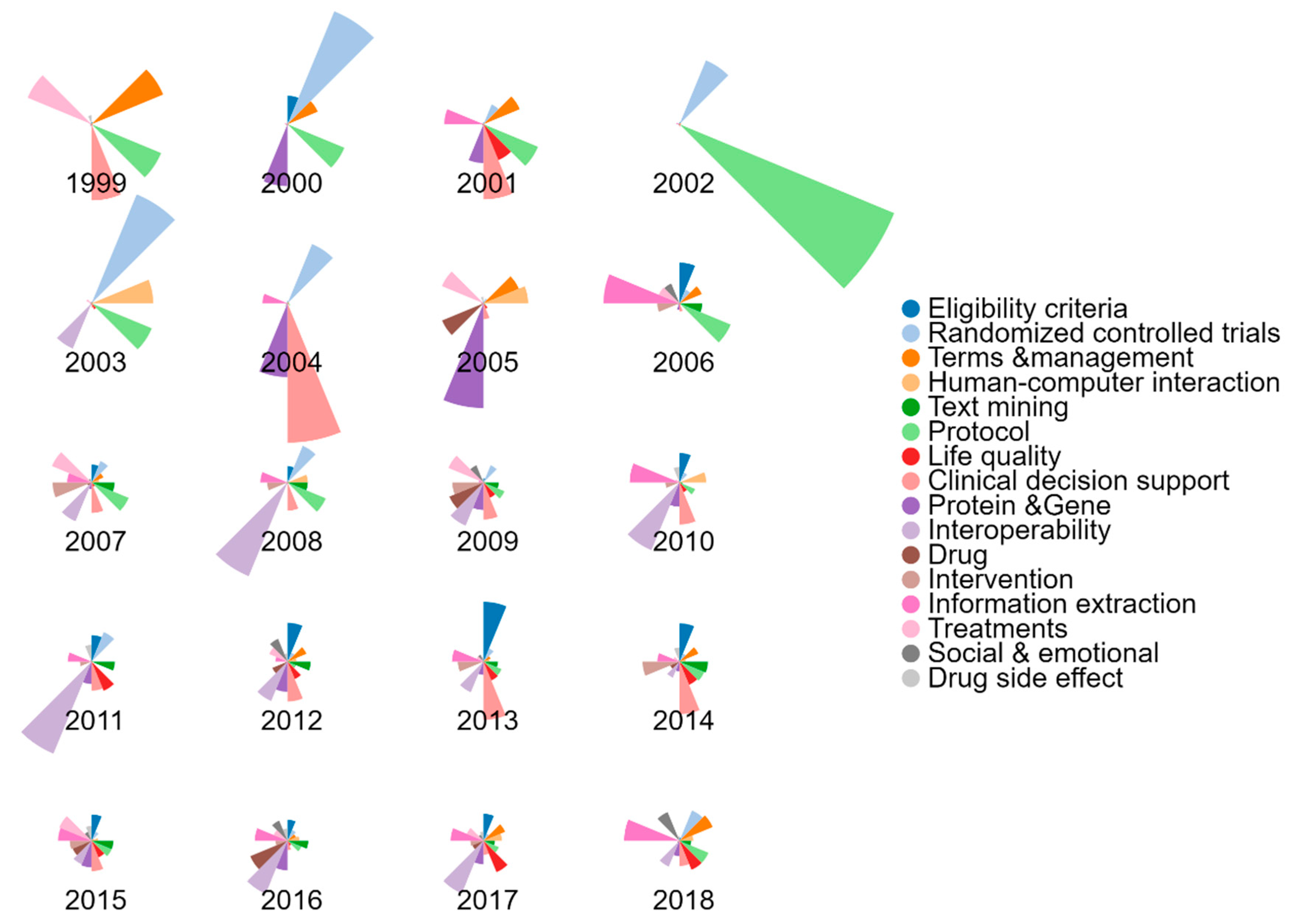
6.3. Topic Proportion Distributions by Year and Topic Clustering
7. Discussions
7.1. Insights From Performance Analysis and Scientific Collaboration Analysis
7.2. Insights From Science Mapping Analysis
7.3. Important Research Topics Identified by STM
7.4. Developing Trends of Research Foci
7.5. Insights Into Potential Inter-Topical Research
7.6. The Latest Trends in NLP-Enhanced Clinical Trials Research
8. Conclusions
8.1. Major Findings
8.2. Suggestions for Future Research on the NLP-Enhanced Clinical Trials
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| "automatic summarization" or "bag of words" or "bayesian n-gram model" or "concept mapping" or "concept normalization" or "conceptual graphs" or "conceptual processing" or "contextual diversity" or "contextual semantics" or "corpus linguistics" or "dirichlet allocation" or "discourse interpretation" or "document ranking" or "information extraction" or "keyword ranked search" or "knowledge bases" or "knowledge graph" or "knowledge maps" or "knowledge reduction" or "knowledge representation" or "language model*" or "latent dirichlet allocation" or "latent semantic analysis" or "lemmatization" or "lexica creation" or "lexical decision" or "lexical knowledge" or "lexical semantics" or "linguistic information" or "linguistic model*" or "linguistic similarity" or "linguistic style match" or "multi-keyword search" or "named entity recognition" or "n-grams" or "part-of-speech" or "parts-of-speech" or "relation extraction" or "semantic analysis" or "semantic interpretation" or "semantic networks" or "semantic orientation" or "semantic processing" or "semantic role labeling" or "semantic roles" or "semantic tag" or "semantic topic analysis" or "semantic vector representation" or "semantical representation" or "semantics" or "semi-supervised learning" or "sentence boundary detection" or "sentence boundary disambiguation " or "sentence breaking" or "sentiment analysis" or "sentiment classification" or "similarity matching" or "smart semantic search" or "spatial similarity" or "string similarity" or "symbolic linguistic computing models" or "syntactic ambiguity resolution" or "syntactic analysis" or "terminology extraction" or "text analysis" or "text analytics" or "text classification" or "text clustering" or "text indexing" or "text simplification" or "text summarization" or "textual analysis" or "texture classification" or "thematic role-assignment" or "thermal-analysis" or "thermogravimetric analysis" or "tokenization" or "topic analysis" or "topic model*" or "word associations" or "word embedding" or "word sense disambiguation" or "word2vec" or "word-emotion associations" or "wordnet" |
| "clinical trial*" or "randomized controlled trial*" or "clinical research trial*" or "clinical research study" or "clinical research studies" or "clinical-trial*" or "randomized controlled-trial*" or "randomized trial*" or "controlled trial*" or "randomized-clinical-trial*" or "randomised trial*" or "randomized-trial*" or "randomization trial*" or "controlled-trial*" or "randomised-trial*" |
| Abbr. | Full names | Abbr. | Full names |
|---|---|---|---|
| ACGT | Advancing Clinico-genomic Trials on Cancer | HRA | Health-risk Assessments |
| ADE | Adverse Drug Events | HTA | Health Technology Assessment |
| ADHD | Attention-deficit/Hyperactivity Disorder | IMR | Iterative Model Reconstruction |
| ADRs | Adverse Drug Reactions | IMS | Intervention-management-system |
| AES | Adverse Events | IR | Iterative Reconstruction |
| AI | Artificial Intelligence | MDM | Medical Data Model |
| AnnSim | Annotation Similarity Measure | NLP | Natural Language Processing |
| APN | Advanced Practice Nurse | NRT | Nicotine Replacement Therapy |
| AskHERMES | A Clinical Question Answering System | OAE | Ontology of Adverse Events |
| BDETs | Bipolar Disorder Efficacy Trials | OAR | Organ-at-risk |
| CDA | Computerized Decision Aid | ODM | Operational Data Model |
| CDISC | Clinical Data Interchange Standards Consortium | PC | Public Consultations |
| CDSS | Clinical Decision-support System | PCROM | Primary Care Research Object Model |
| COIs | Conflicts of Interest | PECODR | Patient-population-problem, Exposure-intervention, Comparison, Outcome, Duration and Results |
| CR | Cardiac Rehabilitation | PGX | Pharmacogenomics |
| CT | Clinical Trials | PWPD | People with Parkinson’s Disease |
| CTPT | Clinical Trial Participant Tracking | QA | Quality Assurance |
| DDI | Drug–drug Interactions | QI | Quality Improvement |
| DRPs | Drug-related Problems | RCTs | Randomized Controlled Trials |
| DTOME | Drug-target Interactome Tool | RD | Reading Disorder |
| EBM | Evidence-Based Medicine | RDCT | Reduced-dose Computed Tomography |
| EC | Eligibility Criteria | RDF | Resource Description Framework |
| ECIG | Electronic Cigarettes | SDCT | Standard-dose Computed Tomography |
| EFV | Efavirenz | SNOMED | The Systematized Nomenclature of Human and Veterinary Medicine |
| EMR | Electronic Medical Records | SR | Structured Reports |
| EOL | End-of-life | SVM | Support Vector Machine |
| FSTs | Frequent Semantic Tags | T2DM | Type 2 Diabetes Mellitus |
| HCI | Human–computer Interaction | TA | Temporal Abstraction |
| HCPs | Health Care Professionals | TBNs | Temporal Bayesian Networks |
| HER | Electronic Health Record | TDM | Therapeutic Drug Monitoring |
| HIV | Human Immunodeficiency Virus | UMLS | Unified Medical Language System |
References
- Roberts, M.E.; Stewart, B.M.; Airoldi, E.M. A model of text for experimentation in the social sciences. J. Am. Stat. Assoc. 2016, 111, 988–1003. [Google Scholar] [CrossRef]
- Roberts, M.E.; Stewart, B.M.; Tingley, D.; Lucas, C.; Leder-Luis, J.; Gadarian, S.K.; Albertson, B.; Rand, D.G. Structural topic models for open-ended survey responses. Am. J. Political Sci. 2014, 58, 1064–1082. [Google Scholar] [CrossRef]
- Jung, H.; Hong, S.; Park, J.; Park, M.; Sun, J.; Lee, S.; Ahn, J.; Ahn, M.; Park, K. MA19. 06 Successful Development of Realtime Automatically Updated Data Warehouse in Health Care (ROOT-S). J. Thorac. Oncol. 2019, 14, S328. [Google Scholar] [CrossRef]
- Jonnalagadda, S.; Cohen, T.; Wu, S.; Gonzalez, G. Enhancing clinical concept extraction with distributional semantics. J. Biomed. Inform. 2012, 45, 129–140. [Google Scholar] [CrossRef] [PubMed]
- Kreimeyer, K.; Foster, M.; Pandey, A.; Arya, N.; Halford, G.; Jones, S.F.; Forshee, R.; Walderhaug, M.; Botsis, T. Natural language processing systems for capturing and standardizing unstructured clinical information: A systematic review. J. Biomed. Inform. 2017, 73, 14–29. [Google Scholar] [CrossRef] [PubMed]
- Heidarysafa, M.; Kowsari, K.; Odukoya, T.; Potter, P.; Barnes, L.E.; Brown, D.E. Women in ISIS Propaganda: A Natural Language Processing Analysis of Topics and Emotions in a Comparison with Mainstream Religious Group. Available online: https://www.researchgate.net/publication/337855242_Women_in_ISIS_Propaganda_A_Natural_Language_Processing_Analysis_of_Topics_and_Emotions_in_a_Comparison_with_Mainstream_Religious_Group (accessed on 1 March 2020).
- Chen, T.; Dredze, M.; Weiner, J.P.; Hernandez, L.; Kimura, J.; Kharrazi, H. Extraction of geriatric syndromes from electronic health record clinical notes: Assessment of statistical natural language processing methods. JMIR. Med. Inform. 2019, 7, e13039. [Google Scholar] [CrossRef] [PubMed]
- Bustos, A.; Pertusa, A. Learning eligibility in cancer clinical trials using deep neural networks. Appl. Sci. 2018, 8, 1206. [Google Scholar] [CrossRef]
- Spyns, P. Natural language processing in medicine: An overview. Methods Inf. Med. 1996, 35, 285–301. [Google Scholar] [CrossRef] [PubMed]
- Friedman, C.; Alderson, P.O.; Austin, J.H.; Cimino, J.J.; Johnson, S.B. A general natural-language text processor for clinical radiology. J. Am. Med. Inform. Assoc. 1994, 1, 161–174. [Google Scholar] [CrossRef] [PubMed]
- Demner-Fushman, D.; Elhadad, N. Aspiring to unintended consequences of natural language processing: A review of recent developments in clinical and consumer-generated text processing. Yearb. Med. Inform. 2016, 25, 224–233. [Google Scholar]
- Zhang, J.; Kowsari, K.; Harrison, J.H.; Lobo, J.M.; Barnes, L.E. Patient2vec: A personalized interpretable deep representation of the longitudinal electronic health record. IEEE Access 2018, 6, 65333–65346. [Google Scholar] [CrossRef]
- Zhang, J.; Gong, J.; Barnes, L. HCNN: Heterogeneous convolutional neural networks for comorbid risk prediction with electronic health records. In Proceedings of the 2017 IEEE/ACM International Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), 2017, Philadelphia, PA, USA, 17–19 July 2017. [Google Scholar]
- Bian, J.; Barnes, L.E.; Chen, G.; Xiong, H. Early detection of diseases using electronic health records data and covariance-regularized linear discriminant analysis. In Proceedings of the 2017 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), 2017, Orlando, FL, USA, 16–19 February 2017. [Google Scholar]
- Löbe, M.; Stäubert, S.; Goldberg, C.; Haffner, I.; Winter, A. Towards Phenotyping of Clinical Trial Eligibility Criteria. Stud. Health Technol. Inform. 2018, 248, 293–299. [Google Scholar] [PubMed]
- Cowie, M.R.; Blomster, J.I.; Curtis, L.H.; Duclaux, S.; Ford, I.; Fritz, F.; Goldman, S.; Janmohamed, S.; Kreuzer, J.; Leenay, M. Electronic health records to facilitate clinical research. Clin. Res. Cardiol. 2017, 106, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Huhdanpaa, H.T.; Tan, W.K.; Rundell, S.D.; Suri, P.; Chokshi, F.H.; Comstock, B.A.; Heagerty, P.J.; James, K.T.; Avins, A.L.; Nedeljkovic, S.S. Using Natural Language Processing of Free-Text Radiology Reports to Identify Type 1 Modic Endplate Changes. J. Digit. Imaging 2018, 31, 84–90. [Google Scholar] [CrossRef] [PubMed]
- Sheikhalishahi, S.; Miotto, R.; Dudley, J.T.; Lavelli, A.; Rinaldi, F.; Osmani, V. Natural language processing of clinical notes on chronic diseases: Systematic review. JMIR Med. Inform. 2019, 7, e12239. [Google Scholar] [CrossRef] [PubMed]
- Dreisbach, C.; Koleck, T.A.; Bourne, P.E.; Bakken, S. A systematic review of natural language processing and text mining of symptoms from electronic patient-authored text data. Int. J. Med. Inform. 2019, 125, 37–46. [Google Scholar] [CrossRef]
- Gonzalez-Hernandez, G.; Sarker, A.; O’Connor, K.; Savova, G. Capturing the patient’s perspective: A review of advances in natural language processing of health-related text. Yearb. Med. Inform. 2017, 26, 214–227. [Google Scholar] [CrossRef]
- Névéol, A.; Zweigenbaum, P. Clinical natural language processing in 2014: Foundational methods supporting efficient healthcare. Yearb. Med. Inform. 2015, 24, 194–198. [Google Scholar] [CrossRef][Green Version]
- Luo, Y.; Thompson, W.K.; Herr, T.M.; Zeng, Z.; Berendsen, M.A.; Jonnalagadda, S.R.; Carson, M.B.; Starren, J. Natural language processing for EHR-based pharmacovigilance: A structured review. Drug Saf. 2017, 40, 1075–1089. [Google Scholar] [CrossRef]
- Koleck, T.A.; Dreisbach, C.; Bourne, P.E.; Bakken, S. Natural language processing of symptoms documented in free-text narratives of electronic health records: A systematic review. J. Am. Med. Inform. Assoc. 2019, 26, 364–379. [Google Scholar] [CrossRef]
- Velupillai, S.; Mowery, D.; South, B.R.; Kvist, M.; Dalianis, H. Recent advances in clinical natural language processing in support of semantic analysis. Yearb. Med. Inform. 2015, 24, 183–193. [Google Scholar]
- Gutiérrez-Salcedo, M.; Martínez, M.Á.; Moral-Munoz, J.; Herrera-Viedma, E.; Cobo, M.J. Some bibliometric procedures for analyzing and evaluating research fields. Appl. Intell. 2018, 48, 1275–1287. [Google Scholar] [CrossRef]
- De la Flor-Martínez, M.; Galindo-Moreno, P.; Sánchez-Fernández, E.; Piattelli, A.; Cobo, M.J.; Herrera-Viedma, E. H-classic: A new method to identify classic articles in Implant Dentistry, Periodontics, and Oral Surgery. Clin. Oral Implant. Res. 2016, 27, 1317–1330. [Google Scholar] [CrossRef] [PubMed]
- De Maio, C.; Fenza, G.; Loia, V.; Parente, M. Biomedical data integration and ontology-driven multi-facets visualization. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–16 July 2015; pp. 1–8. [Google Scholar]
- Houari, N.S.; Taghezout, N. Integrating Agents into a Collaborative Knowledge-based System for Business Rules Consistency Management. Int. J. Interact. Multimed. Artif. Intell. 2016, 4, 61–72. [Google Scholar] [CrossRef][Green Version]
- Settouti, N.; Bechar, M.E.A.; Chikh, M.A. Statistical comparisons of the top 10 algorithms in data mining for classification task. Int. J. Interact. Multimed. Artif. Intell. 2016, 4, 46–51. [Google Scholar]
- Cobo, M.J.; Martínez, M.A.; Gutiérrez-Salcedo, M.; Fujita, H.; Herrera-Viedma, E. 25years at Knowledge-Based Systems: A bibliometric analysis. Knowl. Based Syst. 2015, 80, 3–13. [Google Scholar] [CrossRef]
- Noyons, E.C.; Moed, H.F.; Luwel, M. Combining mapping and citation analysis for evaluative bibliometric purposes: A bibliometric study. J. Am. Soc. Inf. Sci. 1999, 50, 115–131. [Google Scholar] [CrossRef]
- Moed, H.F.; Glänzel, W.; Schmoch, U. Handbook of quantitative science and technology research. In the Use of Publication and Patent Statistics in Studies of S&T Systems; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Cobo, M.J.; Chiclana, F.; Collop, A.; de Ona, J.; Herrera-Viedma, E. A bibliometric analysis of the intelligent transportation systems research based on science mapping. IEEE Trans. Intell. Transp. Syst. 2013, 15, 901–908. [Google Scholar] [CrossRef]
- Grajzl, P.; Murrell, P. Toward understanding 17th century English culture: A structural topic model of Francis Bacon’s ideas. J. Comp. Econ. 2019, 47, 111–135. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Lester, C.A.; Wang, M.; Vydiswaran, V.V. Describing the patient experience from Yelp reviews of community pharmacies. J. Am. Pharm. Assoc. 2019, 59, 349–355. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Zou, D.; Cheng, G.; Xie, H. Detecting latent topics and trends in educational technologies over four decades using structural topic modeling: A retrospective of all volumes of computer & education. Comput. Educ. 2020. [Google Scholar] [CrossRef]
- Chen, X.; Zou, D.; Xie, H. Fifty years of British Journal of Educational Technology: A topic modeling based bibliometric perspective. Br. J. Educ. Technol. 2020. [Google Scholar] [CrossRef]
- Chen, X.; Yu, G.; Cheng, G.; Hao, T. Research topics, author profiles, and collaboration networks in the top-ranked journal on educational technology over the past 40 years: A bibliometric analysis. J. Comput. Educ. 2019, 6, 563–585. [Google Scholar] [CrossRef]
- Chen, X.; Lun, Y.; Yan, J.; Hao, T.; Weng, H. Discovering thematic change and evolution of utilizing social media for healthcare research. BMC Med. Inform. Decis. Mak. 2019, 19, 50. [Google Scholar] [CrossRef] [PubMed]
- Hao, T.; Chen, X.; Li, G.; Yan, J. A bibliometric analysis of text mining in medical research. Soft Comput. 2018, 22, 7875–7892. [Google Scholar] [CrossRef]
- Chen, X.; Liu, Z.; Wei, L.; Yan, J.; Hao, T.; Ding, R. A comparative quantitative study of utilizing artificial intelligence on electronic health records in the USA and China during 2008–2017. BMC Med. Inform. Decis. Mak. 2018, 18, 117. [Google Scholar] [CrossRef]
- Chen, X.; Wang, S.; Tang, Y.; Hao, T. A bibliometric analysis of event detection in social media. Online Inf. Rev. 2019, 43, 29–52. [Google Scholar] [CrossRef]
- Xie, H.; Chu, H.-C.; Hwang, G.-J.; Wang, C.-C. Trends and development in technology-enhanced adaptive/personalized learning: A systematic review of journal publications from 2007 to 2017. Comput. Educ. 2019, 140, 103599. [Google Scholar] [CrossRef]
- Song, Y.; Chen, X.; Hao, T.; Liu, Z.; Lan, Z. Exploring two decades of research on classroom dialogue by using bibliometric analysis. Comput. Educ. 2019, 137, 12–31. [Google Scholar] [CrossRef]
- Chen, X.; Xie, H.; Wang, F.L.; Liu, Z.; Xu, J.; Hao, T. A bibliometric analysis of natural language processing in medical research. BMC Med. Inform. Decis. Mak. 2018, 18, 14. [Google Scholar] [CrossRef] [PubMed]
- Arici, F.; Yildirim, P.; Caliklar, Ş.; Yilmaz, R.M. Research trends in the use of augmented reality in science education: Content and bibliometric mapping analysis. Comput. Educ. 2019, 142, 103647. [Google Scholar] [CrossRef]
- Cancino, C.A.; Amirbagheri, K.; Merigó, J.M.; Dessouky, Y. A bibliometric analysis of supply chain analytical techniques published in Computers & Industrial Engineering. Comput. Ind. Eng. 2019, 137, 106015. [Google Scholar]
- Clare, S.M.; Hickey, G.M. Modelling Research Topic Trends in Community Forestry. Small Scale For. 2019, 18, 149–163. [Google Scholar] [CrossRef]
- Lee, J.D.; Kolodge, K. Exploring trust in self-driving vehicles through text analysis. Hum. Factors 2019, 62, 260–277. [Google Scholar] [CrossRef] [PubMed]
- Bennett, R.; Vijaygopal, R.; Kottasz, R. Willingness of people with mental health disabilities to travel in driverless vehicles. J. Transp. Health 2019, 12, 1–12. [Google Scholar] [CrossRef]
- Chen, X.; Chen, B.; Zhang, C.; Hao, T. Discovering the recent research in natural language processing field based on a statistical approach. In Proceedings of the International Symposium on Emerging Technologies for Education, Cape Town, South Africa, 20–22 September 2017. [Google Scholar]
- Chen, X.; Ding, R.; Xu, K.; Wang, S.; Hao, T.; Zhou, Y. A bibliometric review of natural language processing empowered mobile computing. Wirel. Commun. Mob. Comput. 2018, 2018, 1827074. [Google Scholar] [CrossRef]
- Radev, D.R.; Joseph, M.T.; Gibson, B.; Muthukrishnan, P. A bibliometric and network analysis of the field of computational linguistics. J. Am. Soc. Inf. Sci. Technol. 2009, 1001. [Google Scholar] [CrossRef]
- Romero, A.; Cortés, J.; Escudero, C.; López, J.; Moreno, J. Measuring the influence of clinical trials citations on several bibliometric indicators. Scientometrics 2009, 80, 747–760. [Google Scholar] [CrossRef]
- Yang, G.-Y.; Wang, L.-Q.; Ren, J.; Zhang, Y.; Li, M.-L.; Zhu, Y.-T.; Luo, J.; Cheng, Y.-J.; Li, W.-Y.; Wayne, P.M. Evidence base of clinical studies on Tai Chi: A bibliometric analysis. PLoS ONE 2015, 10, e0120655. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Yang, G.; Li, X.; Zhang, Y.; Yang, J.; Chang, J.; Sun, X.; Zhou, X.; Guo, Y.; Xu, Y. Traditional Chinese medicine in cancer care: A review of controlled clinical studies published in Chinese. PLoS ONE 2013, 8, e60338. [Google Scholar]
- Tao, T.; Zhao, X.; Lou, J.; Bo, L.; Wang, F.; Li, J.; Deng, X. The top cited clinical research articles on sepsis: A bibliometric analysis. Crit. Care 2012, 16, R110. [Google Scholar] [CrossRef] [PubMed]
- Hong, S.J.; Yoon, D.Y.; Cho, Y.K.; Yoon, S.J.; Moon, J.Y.; Baek, S.; Lim, K.J. Characteristics and quality of radiologic randomized controlled trials: A bibliometric analysis between 1995 and 2014. Am. J. Roentgenol. 2016, 206, 917–923. [Google Scholar] [CrossRef] [PubMed]
- Rosas, S.R.; Kagan, J.M.; Schouten, J.T.; Slack, P.A.; Trochim, W.M. Evaluating research and impact: A bibliometric analysis of research by the NIH/NIAID HIV/AIDS clinical trials networks. PLoS ONE 2011, 6, e17428. [Google Scholar] [CrossRef]
- Kim, S.; Sagong, H.S.; Kong, J.C.; Choi, J.-Y.; Lee, M.S.; Wieland, L.S.; Manheimer, E.; Shin, B.-C. Randomised clinical trials on acupuncture in the Korean literature: Bibliometric analysis and methodological quality. Acupunct. Med. 2014, 32, 160–166. [Google Scholar] [CrossRef]
- Cramer, H.; Lauche, R.; Dobos, G. Characteristics of randomized controlled trials of yoga: A bibliometric analysis. BMC Complement. Altern. Med. 2014, 14, 328. [Google Scholar] [CrossRef]
- Cramer, H.; Lauche, R.; Langhorst, J.; Dobos, G. Are Indian yoga trials more likely to be positive than those from other countries? A systematic review of randomized controlled trials. Contemp. Clin. Trials 2015, 41, 269–272. [Google Scholar] [CrossRef]
- Bayram, B.; Limon, Ö.; Limon, G.; Hancı, V. Bibliometric analysis of top 100 most-cited clinical studies on ultrasound in the Emergency Department. Am. J. Emerg. Med. 2016, 34, 1210–1216. [Google Scholar] [CrossRef]
- Zeng, Z.; Deng, Y.; Li, X.; Naumann, T.; Luo, Y. Natural language processing for EHR-based computational phenotyping. IEEE Trans. Comput. Biol. Bioinform. 2018, 16, 139–153. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, Y.; Porter, A.L.; Zhang, G.; Lu, J. Discovering and forecasting interactions in big data research: A learning-enhanced bibliometric study. Technol. Forecast. Soc. Chang. 2019, 146, 795–807. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, H.; Zhu, D. Semi-automatic technology roadmapping composing method for multiple science, technology, and innovation data incorporation. In Anticipating Future Innovation Pathways Through Large Data Analysis; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Adriaanse, L.S.; Rensleigh, C. Web of Science, Scopus and Google Scholar: A content comprehensiveness comparison. Electron. Libr. 2013, 31, 727–744. [Google Scholar] [CrossRef]
- Mongeon, P.; Paul-Hus, A. The journal coverage of Web of Science and Scopus: A comparative analysis. Scientometrics 2016, 106, 213–228. [Google Scholar] [CrossRef]
- Gao, W.; Chen, Y.; Liu, Y.; Guo, H.-C. Scientometric analysis of phosphorus research in eutrophic lakes. Scientometrics 2015, 102, 1951–1964. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, Y.; Cai, G.; Jiang, Z.; Liu, K.; Chen, B.; Jiang, J.; Gu, H. A bibliometric analysis of PubMed literature on middle east respiratory syndrome. Int. J. Environ. Res. Public Health 2016, 13, 583. [Google Scholar] [CrossRef]
- Hassan, S.-U.; Haddawy, P.; Zhu, J. A bibliometric study of the world’s research activity in sustainable development and its sub-areas using scientific literature. Scientometrics 2014, 99, 549–579. [Google Scholar] [CrossRef]
- Kowsari, K.; Brown, D.E.; Heidarysafa, M.; Meimandi, K.J.; Gerber, M.S.; Barnes, L.E. Hdltex: Hierarchical deep learning for text classification. In Proceedings of the 2017 16th IEEE international conference on machine learning and applications (ICMLA), Cancun, Mexico, 18–21 December 2017. [Google Scholar]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Jiang, H.; Qiang, M.; Lin, P. A topic modeling based bibliometric exploration of hydropower research. Renew. Sustain. Energy Rev. 2016, 57, 226–237. [Google Scholar] [CrossRef]
- Peng, B.; Guo, D.; Qiao, H.; Yang, Q.; Zhang, B.; Hayat, T.; Alsaedi, A.; Ahmad, B. Bibliometric and visualized analysis of China’s coal research 2000–2015. J. Clean. Prod. 2018, 197, 1177–1189. [Google Scholar] [CrossRef]
- Hirsch, J.E.; Buela-Casal, G. The meaning of the h-index. Int. J. Clin. Health Psychol. 2014, 14, 161–164. [Google Scholar] [CrossRef]
- Serrat, O. Social network analysis. In Knowledge Solutions; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Small, H. Visualizing science by citation mapping. J. Am. Soc. Inf. Sci. 1999, 50, 799–813. [Google Scholar] [CrossRef]
- Cobo, M.J.; López-Herrera, A.G.; Herrera-Viedma, E.; Herrera, F. Science mapping software tools: Review, analysis, and cooperative study among tools. J. Am. Soc. Inf. Sci. Technol. 2011, 62, 1382–1402. [Google Scholar] [CrossRef]
- Cobo, M.J.; Herrera, F. An approach for detecting, quantifying, and visualizing the evolution of a research field: A practical application to the Fuzzy Sets Theory field. J. Informetr. 2011, 5, 146–166. [Google Scholar] [CrossRef]
- Garfield, E. Scientography: Mapping the tracks of science. Curr. Contents Soc. Behav. Sci. 1994, 7, 5–10. [Google Scholar]
- Cabeza-Ramírez, L.J.; Sánchez Cañizares, S.M.; Fuentes García, F.J. Past Themes and Tracking Research Trends in Entrepreneurship: A Co-Word, Cites and Usage Count Analysis. Sustainability 2019, 11, 1–32. [Google Scholar]
- Canino, G.; Suo, Q.; Guzzi, P.H.; Tradigo, G.; Zhang, A.; Veltri, P. Feature selection model for diagnosis, electronic medical records and geographical data correlation. In Proceedings of the 7th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Seattle, WA, USA, 2–5 October 2016. [Google Scholar]
- Wu, Y.; Lei, J.; Wei, W.-Q.; Tang, B.; Denny, J.C.; Rosenbloom, S.T.; Miller, R.A.; Giuse, D.A.; Zheng, K.; Xu, H. Analyzing differences between Chinese and English clinical text: A cross-institution comparison of discharge summaries in two languages. Stud. Health Technol. Inform. 2013, 192, 662. [Google Scholar]
- Jonnalagadda, S.R.; Adupa, A.K.; Garg, R.P.; Corona-Cox, J.; Shah, S.J. Text mining of the electronic health record: An information extraction approach for automated identification and subphenotyping of HFPEF patients for clinical trials. J. Cardiovasc. Transl. Res. 2017, 10, 313–321. [Google Scholar] [CrossRef]
- Dhuliawala, M.; Fay, N.; Gruen, D.; Das, A. What Happens When? Interpreting Schedule of Activity Tables in Clinical Trial Documents. In Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Washington, DC, USA, 29 August–1 September 2018. [Google Scholar]
- Alonso, O.; De La Peña, P.; Moreno, A.; Anzaldi, G.; Domingo, X. Data Mining and Query Answer techniques applied to a bio-nutritional trials focused Expert System. In Proceedings of the CCIA, Alicante, Spain, 24–26 October 2012. [Google Scholar]
- Hassanpour, S.; Langlotz, C.P. Information extraction from multi-institutional radiology reports. Artif. Intell. Med. 2016, 66, 29–39. [Google Scholar] [CrossRef]
- Bakal, G.; Talari, P.; Kakani, E.V.; Kavuluru, R. Exploiting semantic patterns over biomedical knowledge graphs for predicting treatment and causative relations. J. Biomed. Inform. 2018, 82, 189–199. [Google Scholar] [CrossRef]
- Bucur, A.; Van Leeuwen, J.; Chen, N.-Z.; Claerhout, B.; De Schepper, K.; Pérez del Rey, D.; Alonso Calvo, R.; Pugliano, L.; Saini, K. Supporting patient screening to identify suitable clinical trials. Stud. Health Technol. Inform. 2014, 205, 823–827. [Google Scholar]
- van Leeuwen, J.; Bucur, A.I.; Claerhout, B.; de Schepper, K.; Pérez-Rey, D.; Alonso-Calvo, R. BRIDG-based Trial Metadata Repository-Need for Standardized Machine Interpretable Trial Descriptions. In Proceedings of the HEALTHINF, Loire Valley, France, 3–6 March 2014. [Google Scholar]
- Boscá, D.; Marco, L.; Burriel, V.; Jaijo, T.; Millán, J.M.; Levin, A.M.; Pastor, O.; Robles, M.; Maldonado, J.A. Genetic testing information standardization in HL7 CDA and ISO13606. In Proceedings of the MedInfo, Copenhagen, Denmark, 20–13 August 2013. [Google Scholar]
- Fernandes, F.; Vicente, H.; Abelha, A.; Machado, J.; Novais, P.; Neves, J. Artificial neural networks in diabetes control. In Proceedings of the 2015 Science and Information Conference (SAI), London, UK, 28–30 July 2015. [Google Scholar]
- Caballero-Ruiz, E.; García-Sáez, G.; Rigla, M.; Villaplana, M.; Pons, B.; Hernando, M.E. A web-based clinical decision support system for gestational diabetes: Automatic diet prescription and detection of insulin needs. Int. J. Med. Inform. 2017, 102, 35–49. [Google Scholar] [CrossRef] [PubMed]
- Cole-Lewis, H.J.; Smaldone, A.M.; Davidson, P.R.; Kukafka, R.; Tobin, J.N.; Cassells, A.; Mynatt, E.D.; Hripcsak, G.; Mamykina, L. Participatory approach to the development of a knowledge base for problem-solving in diabetes self-management. Int. J. Med. Inform. 2016, 85, 96–103. [Google Scholar] [CrossRef] [PubMed]
- Geßner, S.; Neuhaus, P.; Varghese, J.; Bruland, P.; Meidt, A.; Soto-Rey, I.; Storck, M.; Doods, J.; Dugas, M. The Portal of Medical Data Models: Where Have We Been and Where Are We Going? In Proceedings of the MedInfo, Hangzhou, China, 21–25 August 2017. [Google Scholar]
- Priyatna, F.; Alonso-Calvo, R.; Paraiso-Medina, S.; Corcho, O. Querying clinical data in HL7 RIM based relational model with morph-RDB. J. Biomed. Semant. 2017, 8, 49. [Google Scholar] [CrossRef] [PubMed]
- Alonso-Calvo, R.; Paraiso-Medina, S.; Perez-Rey, D.; Alonso-Oset, E.; van Stiphout, R.; Yu, S.; Taylor, M.; Buffa, F.; Fernandez-Lozano, C.; Pazos, A. A semantic interoperability approach to support integration of gene expression and clinical data in breast cancer. Comput. Biol. Med. 2017, 87, 179–186. [Google Scholar] [CrossRef]
- Gazzarata, R.; Giannini, B.; Giacomini, M. A SOA-based platform to support clinical data sharing. J. Healthc. Eng. 2017, 2017, 1–25. [Google Scholar] [CrossRef]
- Dietrich, G.; Krebs, J.; Fette, G.; Ertl, M.; Kaspar, M.; Störk, S.; Puppe, F. Ad hoc information extraction for clinical data warehouses. Methods Inf. Med. 2018, 57, e22–e29. [Google Scholar] [CrossRef]
- Patterson, O.V.; Freiberg, M.S.; Skanderson, M.; Fodeh, S.J.; Brandt, C.A.; DuVall, S.L. Unlocking echocardiogram measurements for heart disease research through natural language processing. BMC Cardiovasc. Disord. 2017, 17, 151. [Google Scholar] [CrossRef]
- Milosevic, N.; Gregson, C.; Hernandez, R.; Nenadic, G. Extracting Patient Data from Tables in Clinical Literature-Case Study on Extraction of BMI, Weight and Number of Patients. In Proceedings of the HEALTHINF, Rome, Italy, 21–23 February 2016. [Google Scholar]
- Lee, Y.; Krishnamoorthy, S.; Dinakarpandian, D. A semantic framework for intelligent matchmaking for clinical trial eligibility criteria. ACM Trans. Intell. Syst. Technol. 2013, 4, 71. [Google Scholar] [CrossRef]
- Milian, K.; Bucur, A.; van Harmelen, F.; ten Teije, A. Identifying Most Relevant Concepts to Describe Clinical Trial Eligibility Criteria. In Proceedings of the HEALTHINF, Barcelona, Spain, 11–14 February 2013. [Google Scholar]
- van Engen-Verheul, M.M.; Peek, N.; Haafkens, J.A.; Joukes, E.; Vromen, T.; Jaspers, M.W.; de Keizer, N.F. What is needed to implement a web-based audit and feedback intervention with outreach visits to improve care quality: A concept mapping study among cardiac rehabilitation teams. Int. J. Med. Inform. 2017, 97, 76–85. [Google Scholar] [CrossRef]
- van Engen-Verheul, M.M.; de Keizer, N.F.; van der Veer, S.N.; Kemps, H.M.; op Reimer, W.J.S.; Jaspers, M.W.; Peek, N. Evaluating the effect of a web-based quality improvement system with feedback and outreach visits on guideline concordance in the field of cardiac rehabilitation: Rationale and study protocol. Implement. Sci. 2014, 9, 780. [Google Scholar] [CrossRef]
- Chen, Z.; Koh, P.W.; Ritter, P.L.; Lorig, K.; Bantum, E.O.C.; Saria, S. Dissecting an online intervention for cancer survivors: Four exploratory analyses of internet engagement and its effects on health status and health behaviors. Health Educ. Behav. 2015, 42, 32–45. [Google Scholar] [CrossRef] [PubMed]
- Vidhya, K.; Soorya, R.; Saranavan, N.; Geetha, T.; Singaravelan, M. Entity resolution for symptom vs disease for top-K treatments. In Proceedings of the 2017 4th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 January 2017. [Google Scholar]
- Byrne-Davis, L.; Wetherell, M.; Dieppe, P.; Weinman, J.; Byron, M.; Donovan, J.; Horne, R.; Brookes, S.; Vedhara, K. Emotional disclosure in rheumatoid arthritis: Participants’ views on mechanisms. Psychol. Health 2006, 21, 667–682. [Google Scholar] [CrossRef]
- Livas, C.; Delli, K.; Pandis, N. “My Invisalign experience”: Content, metrics and comment sentiment analysis of the most popular patient testimonials on YouTube. Prog. Orthod. 2018, 19, 3. [Google Scholar] [CrossRef] [PubMed]
- Bekhuis, T.; Demner-Fushman, D. Screening nonrandomized studies for medical systematic reviews: A comparative study of classifiers. Artif. Intell. Med. 2012, 55, 197–207. [Google Scholar] [CrossRef]
- Li, Q.; Zhai, H.; Deleger, L.; Lingren, T.; Kaiser, M.; Stoutenborough, L.; Solti, I. A sequence labeling approach to link medications and their attributes in clinical notes and clinical trial announcements for information extraction. J. Am. Med. Inform. Assoc. 2012, 20, 915–921. [Google Scholar] [CrossRef][Green Version]
- Rajapaksha, P.; Weerasinghe, R. Identifying adverse drug reactions by analyzing Twitter messages. In Proceedings of the 2015 Fifteenth International Conference on Advances in ICT for Emerging Regions (ICTer), Colombo, Sri Lanka, 24–26 August 2015. [Google Scholar]
- Bisgin, H.; Liu, Z.; Kelly, R.; Fang, H.; Xu, X.; Tong, W. Investigating drug repositioning opportunities in FDA drug labels through topic modeling. BMC Bioinform. 2012, 13, 1–9. [Google Scholar] [CrossRef]
- Petkov, V.I.; Penberthy, L.T.; Dahman, B.A.; Poklepovic, A.; Gillam, C.W.; McDermott, J.H. Automated determination of metastases in unstructured radiology reports for eligibility screening in oncology clinical trials. Exp. Biol. Med. 2013, 238, 1370–1378. [Google Scholar] [CrossRef]
- Huang, Z.; Ten Teije, A.; Van Harmelen, F. SemanticCT: A semantically-enabled system for clinical trials. In Process Support and Knowledge Representation in Health Care; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Oellrich, A.; Collier, N.; Smedley, D.; Groza, T. Generation of silver standard concept annotations from biomedical texts with special relevance to phenotypes. PLoS ONE 2015, 10, e0116040. [Google Scholar] [CrossRef]
- Bean, D.M.; Wu, H.; Iqbal, E.; Dzahini, O.; Ibrahim, Z.M.; Broadbent, M.; Stewart, R.; Dobson, R.J. Knowledge graph prediction of unknown adverse drug reactions and validation in electronic health records. Sci. Rep. 2017, 7, 16416. [Google Scholar] [CrossRef]
- Tarazona-Santabalbina, F.J.; Gómez-Cabrera, M.C.; Pérez-Ros, P.; Martínez-Arnau, F.M.; Cabo, H.; Tsaparas, K.; Salvador-Pascual, A.; Rodriguez-Manas, L.; Viña, J. A multicomponent exercise intervention that reverses frailty and improves cognition, emotion, and social networking in the community-dwelling frail elderly: A randomized clinical trial. J. Am. Med. Dir. Assoc. 2016, 17, 426–433. [Google Scholar] [CrossRef]
- Segura-Bedmar, I.; Raez, P. Cohort selection for clinical trials using deep learning models. J. Am. Med. Inform. Assoc. 2019, 26, 1181–1188. [Google Scholar] [CrossRef] [PubMed]
- Timimi, F.; Ray, S.; Jones, E.; Aase, L.; Hoffman, K. Patient-Reported Outcomes in Online Communications on Statins, Memory, and Cognition: Qualitative Analysis Using Online Communities. J. Med. Internet Res. 2019, 21, e14809. [Google Scholar] [CrossRef] [PubMed]
- Stubbs, A.; Filannino, M.; Soysal, E.; Henry, S.; Uzuner, Ö. Cohort selection for clinical trials: n2c2 2018 shared task track 1. J. Am. Med. Inform. Assoc. 2019, 26, 1163–1171. [Google Scholar] [CrossRef] [PubMed]
- Vydiswaran, V.; Strayhorn, A.; Zhao, X.; Robinson, P.; Agarwal, M.; Bagazinski, E.; Essiet, M.; Iott, B.E.; Joo, H.; Ko, P. Hybrid bag of approaches to characterize selection criteria for cohort identification. J. Am. Med. Inform. Assoc. 2019, 26, 1172–1180. [Google Scholar] [CrossRef]
- Xiong, Y.; Shi, X.; Chen, S.; Jiang, D.; Tang, B.; Wang, X.; Chen, Q.; Yan, J. Cohort selection for clinical trials using hierarchical neural network. J. Am. Med. Inform. Assoc. 2019, 26, 1203–1208. [Google Scholar] [CrossRef]
- Chen, L.; Gu, Y.; Ji, X.; Lou, C.; Sun, Z.; Li, H.; Gao, Y.; Huang, Y. Clinical trial cohort selection based on multi-level rule-based natural language processing system. J. Am. Med. Inform. Assoc. 2019, 26, 1218–1226. [Google Scholar] [CrossRef]
- Chen, C.-J.; Warikoo, N.; Chang, Y.-C.; Chen, J.-H.; Hsu, W.-L. Medical knowledge infused convolutional neural networks for cohort selection in clinical trials. J. Am. Med. Inform. Assoc. 2019, 26, 1227–1236. [Google Scholar] [CrossRef]
- Liu, C.; Yuan, C.; Butler, A.M.; Carvajal, R.D.; Li, Z.R.; Ta, C.N.; Weng, C. DQueST: Dynamic questionnaire for search of clinical trials. J. Am. Med. Inform. Assoc. 2019, 26, 1333–1343. [Google Scholar] [CrossRef]
- Kehl, K.L.; Elmarakeby, H.; Nishino, M.; Van Allen, E.M.; Lepisto, E.M.; Hassett, M.J.; Johnson, B.E.; Schrag, D. Assessment of deep natural language processing in ascertaining oncologic outcomes from radiology reports. JAMA Oncol. 2019, 5, 1421–1429. [Google Scholar] [CrossRef]
- Thompson, J.; Hu, J.; Mudaranthakam, D.P.; Streeter, D.; Neums, L.; Park, M.; Koestler, D.C.; Gajewski, B.; Jensen, R.; Mayo, M.S. Relevant Word Order Vectorization for Improved Natural Language Processing in Electronic Health Records. Sci. Rep. 2019, 9, 9253. [Google Scholar] [CrossRef]











| Reviewer(s) and Year | No. of Articles | Methods | Period | Research Goals |
|---|---|---|---|---|
| Sheikhalishahi et al. (2019) [18] | 43 | Systematic review | 2007–2018 | To thoroughly review the development and uptake of the applications of NLP in dealing with unstructured clinical notes data regarding chronic diseases |
| Dreisbach et al. (2019) [19] | 21 | Systematic review | 2003–2017 | To summarize studies concerning the applications of NLP and text mining to extract and process symptom information contained in electronic patient-authored texts. |
| Demner-Fushman & Elhadad (2016) [11] | Less than 100 | Systematic review | Till 2016 | To summarize studies concerning the applications of NLP in processing clinical and consumer-produced texts. |
| Gonzalez-Hernandez et al. (2017) [20] | 149 | Systematic review | Till 2017 | To summarize studies concerning the applications of NLP for processing health-associated information contained in EHRs and social media posts. |
| Névéol & Zweigenbaum (2015) [21] | 154 | Systematic review | 2014 | To review and select the best papers concerning clinical NLP. |
| Luo et al. (2017) [22] | 48 | Systematic review | 2000–2015 | To summarize the state-of-the-art in methodology advances of NLP for EHRs-based pharmacovigilance. |
| Koleck et al. (2019) [23] | 27 | Systematic review | 1999–2017 | To summarize studies concerning the applications of NLP for processing and analyzing symptom information contained in EHRs narratives. |
| Kreimeyer et al. (2017) [5] | 86 | Systematic review | 2006–2016 | To summarize current-in-use NLP solutions for clinical texts that could encode free textual data into standardized clinical terminologies and to capture common data elements to fill specified templates. |
| Velupillai et al. (2015) [24] | Less than 100 | Systematic review | 2008–2014 | To summarize the latest advances in clinical NLP, particularly focusing on semantic analysis and its supporting subtasks. |
| Area | Type | ID | Criteria |
|---|---|---|---|
| Clinical trials research | Inclusion criteria | I1 | Randomized controlled trials |
| I2 | Clinical research studies | ||
| Exclusion criteria | E2 | Not focused on clinical trial | |
| E3 | Not a scientific research | ||
| E4 | Without abstract | ||
| NLP research | Inclusion criteria | I1 | Use of NLP algorithms/approaches/technologies |
| I2 | Improvement of NLP technology/algorithm | ||
| Exclusion criteria | E1 | Use of pure mathematical or statistical algorithms | |
| E4 | Without abstract |
| Research Domain | Paper Count | Proportion |
|---|---|---|
| Computer Science | 93 | 23.66% |
| Medical Informatics | 79 | 20.10% |
| Health Care Sciences & Services | 50 | 12.72% |
| Mathematical & Computational Biology | 18 | 4.58% |
| Engineering | 16 | 4.07% |
| Information Science & Library Science | 16 | 4.07% |
| Psychology | 13 | 3.31% |
| Public, Environmental & Occupational Health | 12 | 3.05% |
| Research & Experimental Medicine | 7 | 1.78% |
| Science & Technology - Other Topics | 7 | 1.78% |
| Before Transformation | |||
|---|---|---|---|
| Paper ID | Authors’ address | ||
| WOS:000179539400023 | [Tu, Samson W.; Peleg, Mor] Stanford Univ, Stanford Ctr Biomed Informat Res, Stanford, CA 94305 USA.<;>[Peleg, Mor] Univ Haifa, Dept Management Informat Syst, IL-31999 Haifa, Israel.<;>[Carini, Simona; Bobak, Michael; Sim, Ida] Univ Calif San Francisco, Dept Med, San Francisco, CA USA.<;>[Ross, Jessica] Univ Calif San Francisco, Dept Psychiat, San Francisco, CA 94143 USA.<;>[Rubin, Daniel] Stanford Univ, Dept Radiol, Stanford, CA 94305 USA. | ||
| After transformation | |||
| Paper ID | Author | Affiliation | Country/region |
| WOS:000289030100006 | Peleg, Mor | Stanford Univ | USA |
| WOS:000289030100006 | Rubin, Daniel | Stanford Univ | USA |
| WOS:000289030100006 | Tu, Samson W. | Stanford Univ | USA |
| WOS:000289030100006 | Bobak, Michael | Univ Calif San Francisco | USA |
| WOS:000289030100006 | Carini, Simona | Univ Calif San Francisco | USA |
| WOS:000289030100006 | Ross, Jessica | Univ Calif San Francisco | USA |
| WOS:000289030100006 | Sim, Ida | Univ Calif San Francisco | USA |
| WOS:000289030100006 | Peleg, Mor | Univ Haifa | Israel |
| Journal/Conference | H | A (R) | TC | ACP | ≥100 | ≥50 | A1 | A2 |
|---|---|---|---|---|---|---|---|---|
| Journal of Biomedical Informatics | 20 | 37 (1) | 1224 | 33.08 | 3 | 7 | 1 | 36 |
| Journal of the American Medical Informatics Association | 17 | 23 (3) | 1357 | 59 | 2 | 5 | 7 | 16 |
| American Medical Informatics Association (AMIA) Annual Symposium | 12 | 22 (4) | 315 | 14.32 | 0 | 0 | 13 | 9 |
| Lecture Notes in Computer Science | 9 | 16 (5) | 222 | 13.88 | 0 | 1 | 4 | 12 |
| Studies in Health Technology and Informatics | 8 | 26 (2) | 258 | 9.92 | 0 | 0 | 4 | 22 |
| BMC Medical Informatics and Decision Making | 7 | 11 (6) | 175 | 15.91 | 0 | 1 | 1 | 10 |
| Artificial Intelligence in Medicine | 6 | 7 (12) | 290 | 41.43 | 0 | 2 | 1 | 6 |
| International Journal of Medical Informatics | 6 | 8 (7) | 123 | 15.38 | 0 | 0 | 1 | 7 |
| PLoS ONE | 6 | 8 (7) | 101 | 12.63 | 0 | 0 | 0 | 8 |
| Methods of Information in Medicine | 5 | 8 (7) | 81 | 10.13 | 0 | 0 | 2 | 6 |
| BMC Bioinformatics | 4 | 4 (14) | 147 | 36.75 | 0 | 1 | 0 | 4 |
| World Congress on Medical and Health Informatics (MEDINFO) | 4 | 8 (7) | 61 | 7.63 | 0 | 0 | 3 | 5 |
| International Conference on Health Informatics (HEALTHINF) | 4 | 8 (7) | 52 | 6.5 | 0 | 0 | 3 | 5 |
| C | H | A (R) | TC | ACP | ≥100 | ≥50 | A1 | A2 | Main collaborator (CT ≥ 5) |
|---|---|---|---|---|---|---|---|---|---|
| the USA | 42 | 231 (1) | 6425 | 27.81 | 11 | 30 | 58 | 173 | the UK; Germany; China; Canada; Australia |
| Germany | 17 | 57 (2) | 793 | 13.91 | 0 | 3 | 7 | 50 | Greece; Spain; the UK; the Netherlands; USA; Belgium |
| the UK | 16 | 51 (3) | 1013 | 19.86 | 1 | 5 | 7 | 44 | USA; the Netherlands; Germany |
| the Netherlands | 14 | 39 (4) | 541 | 13.87 | 0 | 2 | 5 | 34 | Spain; Belgium; Germany; the UK; Greece |
| Canada | 12 | 17 (9) | 1164 | 68.47 | 1 | 6 | 6 | 11 | the USA |
| Australia | 10 | 19 (7) | 245 | 12.89 | 0 | 0 | 2 | 17 | the USA |
| Spain | 9 | 27 (5) | 423 | 15.67 | 0 | 3 | 4 | 23 | the Netherlands; Germany; Greece; Belgium |
| France | 8 | 20 (6) | 366 | 18.30 | 0 | 3 | 4 | 16 | |
| China | 8 | 17 (9) | 286 | 16.82 | 0 | 2 | 1 | 16 | the USA |
| Greece | 8 | 19 (7) | 308 | 16.21 | 0 | 2 | 6 | 13 | Germany; Spain; the Netherlands |
| Institution | Country | H | A (R) | TC | ACP | ≥100 | ≥50 | A1 | A2 |
|---|---|---|---|---|---|---|---|---|---|
| Stanford University | the USA | 16 | 25 (1) | 770 | 30.80 | 1 | 5 | 14 | 11 |
| National Institutes of Health | the USA | 12 | 14 (5) | 833 | 59.50 | 3 | 6 | 4 | 10 |
| University of California, San Francisco | the USA | 11 | 14 (5) | 1062 | 75.86 | 2 | 4 | 7 | 7 |
| Columbia University | the USA | 10 | 21 (2) | 392 | 18.67 | 0 | 1 | 3 | 18 |
| Foundation for Research and Technology - Hellas | Greece | 8 | 13 (7) | 274 | 21.08 | 0 | 2 | 6 | 7 |
| Vrije University Amsterdam | the Netherlands | 8 | 12 (8) | 175 | 14.58 | 0 | 1 | 0 | 12 |
| Philips Research | the Netherlands | 7 | 16 (4) | 134 | 8.38 | 0 | 0 | 2 | 14 |
| Technical University of Madrid | Spain | 7 | 17 (3) | 200 | 11.76 | 0 | 1 | 3 | 14 |
| University of Washington | the USA | 7 | 7 (16) | 228 | 32.57 | 0 | 1 | 1 | 6 |
| King’s College London | the UK | 6 | 8 (13) | 292 | 36.50 | 1 | 1 | 1 | 7 |
| Mayo Clinic | the USA | 6 | 6 (22) | 175 | 29.17 | 1 | 1 | 1 | 5 |
| Northwestern University | the USA | 6 | 6 (22) | 174 | 29.00 | 0 | 0 | 1 | 5 |
| Saarland University | Germany | 6 | 8 (13) | 243 | 30.38 | 0 | 2 | 3 | 5 |
| University of Amsterdam | the Netherlands | 6 | 10 (9) | 208 | 20.80 | 0 | 1 | 1 | 9 |
| University College London | the UK | 6 | 8 (13) | 283 | 35.38 | 1 | 1 | 1 | 7 |
| University of Oxford | the UK | 6 | 9 (11) | 357 | 39.67 | 1 | 2 | 1 | 8 |
| University of Texas Health Science Center at Houston | the USA | 6 | 7 (16) | 197 | 28.14 | 1 | 1 | 0 | 7 |
| Author | Institution | H | A (R) | TC | ACP | ≥100 | ≥50 | A1 | A2 |
|---|---|---|---|---|---|---|---|---|---|
| Ida Sim | University of California, San Francisco | 10 | 12 (4) | 1015 | 84.58 | 2 | 4 | 7 | 5 |
| Manolis Tsiknakis | Foundation for Research and Technology - Hellas | 8 | 13 (2) | 274 | 42.67 | 0 | 2 | 6 | 7 |
| Amar K. Das | Stanford University | 8 | 10 (5) | 176 | 39.50 | 0 | 0 | 8 | 2 |
| Chunhua Weng | Columbia University | 7 | 13 (2) | 208 | 27.20 | 0 | 0 | 0 | 13 |
| Anca Bucur | Philips Research | 7 | 15 (1) | 117 | 25.57 | 0 | 0 | 1 | 14 |
| Martin O’Connor | Stanford University | 7 | 8 (8) | 136 | 22.00 | 0 | 0 | 7 | 1 |
| Ravi D. Shankar | Stanford University | 7 | 7 (10) | 124 | 21.50 | 0 | 0 | 6 | 1 |
| Simona Carini | University of California, San Francisco | 7 | 9 (6) | 384 | 21.50 | 1 | 3 | 4 | 5 |
| Stelios Sfakianakis | Foundation for Research and Technology - Hellas | 6 | 7 (10) | 179 | 21.08 | 0 | 2 | 3 | 4 |
| Mathias Brochhausen | Saarland University | 6 | 6 (18) | 237 | 20.57 | 0 | 2 | 3 | 3 |
| Alberto Anguita | Technical University of Madrid | 6 | 7 (10) | 144 | 17.71 | 0 | 1 | 3 | 4 |
| Hua Xu | University of Texas Health Science Center at Houston | 5 | 6 (18) | 95 | 17.60 | 0 | 0 | 0 | 6 |
| Todd Lingren | Cincinnati Children’s Hospital Medical Center | 5 | 6 (18) | 129 | 17.00 | 0 | 0 | 0 | 6 |
| Imre Solti | Cincinnati Children’s Hospital Medical Center | 5 | 6 (18) | 129 | 16.00 | 0 | 0 | 0 | 6 |
| David B. Parrish | Immune Tolerance Network | 5 | 5 (23) | 110 | 15.83 | 0 | 0 | 4 | 1 |
| Martin Dugas | University of Munster | 5 | 9 (6) | 97 | 10.78 | 0 | 0 | 0 | 9 |
| Victor Maojo | Technical University of Madrid | 5 | 7 (10) | 65 | 9.29 | 0 | 0 | 2 | 5 |
| Luis Martin | Technical University of Madrid | 5 | 5 (23) | 136 | 7.80 | 0 | 1 | 3 | 2 |
| David Perez-Rey | Technical University of Madrid | 5 | 8 (8) | 39 | 4.88 | 0 | 0 | 0 | 8 |
| Period | Name | Articles | Citations | H-index |
|---|---|---|---|---|
| 1999–2008 | HUMAN | 43 | 1889 | 20 |
| COMPUTER-PROGRAM | 35 | 1833 | 16 | |
| SYSTEM | 26 | 639 | 17 | |
| QUALITY | 11 | 815 | 7 | |
| ONTOLOGY-BASED | 3 | 86 | 3 | |
| 2009–2013 | HUMAN | 79 | 1703 | 24 |
| MEDICAL-RECORD | 51 | 1132 | 19 | |
| ARTIFICIAL-INTELLIGENCE | 48 | 1366 | 23 | |
| FACTUAL-DATABASE | 46 | 1232 | 18 | |
| RANDOMIZED-TRIAL | 43 | 1157 | 19 | |
| MEDICAL-APPLICATION | 41 | 723 | 14 | |
| NATURAL-LANGUAGE-PROCESSING | 24 | 654 | 13 | |
| OUTCOME | 8 | 104 | 6 | |
| 2014–2018 | PROCEDURE | 106 | 1166 | 20 |
| MACHINE-LEARNING | 73 | 822 | 17 | |
| RANDOMIZED-CONTROLLED-TRIAL | 72 | 932 | 17 | |
| ELECTRONIC-HEALTH-RECORD | 69 | 735 | 14 | |
| ACCURACY | 60 | 677 | 14 | |
| MEDICAL-INFORMATICS | 53 | 646 | 14 | |
| STANDARD | 51 | 568 | 14 | |
| FEMALE | 49 | 576 | 13 | |
| ELIGIBILITY-CRITERION | 42 | 662 | 15 | |
| COMPUTER-ASSISTED | 36 | 440 | 11 | |
| GENETICS | 33 | 353 | 10 | |
| DIABETES-MELLITUS | 23 | 264 | 8 |
| Discriminating Terms | % | Suggested Topic | Trend |
|---|---|---|---|
| ACGT, RDF, ODM, project, genomic, MDM integration, metadata, grid, interoperability, clinico, infrastructure, service, CDISC, portal | 13.21 | Interoperability | ↑↑ |
| CDSS, PCROM, archetype, ontology, terminology, interoperability, EC, EHR, EMR, healthcare, practice, AskHERMES, nutritional, clinical, supporting, | 10.38 | Clinical decision support | ↑ |
| extraction, ADRs, natural, radiology, extract, precision, summarization, information, NLP, biomedical, free, text, processing, SR, mining | 9.36 | Information extraction | ↑↑ |
| annotation, eligibility, criterion, UMLS, SNOMED, automatic, semantic, relatedness, AnnSim, FSTs, CT clinicaltrials.gov, pattern, matching, exclusion | 8.68 | Eligibility criteria | ↑↑ |
| protocol, temporal, constraint, TBNS, management, representation, accrual, TA, enrollment, eligibility, eligible, criterion, trial, querying, conflict | 8.08 | Protocol | ↓↓ |
| landmark, protein, gene, graph, Taxane, interaction, phenotype, diacetylmorphine, DTOME, candidate, QA, anti, caffeine, genotype, PGX | 6.76 | Protein & Gene | ↑ |
| bank, RCTS, systematic, cochrane, registration, pro, randomized, HTA, controlled, search, delivery, alteration, CDA, register, update | 5.57 | Randomized controlled trials | ↓ |
| QI, resident, professional, factor, sexual, team, alert, health, feedback, importance, HRA, cluster, CR, DDI, mental | 5.55 | Life quality | ↑↑↑ |
| IMS, glycemic, nursing, indicator, diabetes, obesity, disclosure, APN, EBM, intervention, control, family, evidence, management, telemedicine | 5.32 | Intervention | ↑↑ |
| OAR, ADHD, rapidplan, AI, EOL, exercise, RD, HIV, treatment, disorder, EFV, TDM, BDETs, therapy, therapist | 5.22 | Treatments | ↑ |
| classifier, sentence, corpus, binary, naive, consent, performance, PECODR, ethic, bayes, machine, feature, SVM, vector, classification | 5.18 | Text mining | ↑↑ |
| COIS, ECIG, abutment, dissection, delirium, PWPD, HCPs, similarity, OAE, connection, category, term, financial, minority, AES | 4.22 | Terms & management | ↓ |
| meta, rectum, SDCT, IMR, IR, RDCT, activation, dose, PC, sealant, tagging, consistency, plan, rule, DRPs | 3.76 | Drug | ↑↑↑ |
| HCI, cohesion, display, CTPT, time, trend, visitor, iconic, pneumonia, T2DM, exploration, representativeness, comprehension, temporal, imaging | 3.18 | Human–computer interaction | ↑↑ |
| NRT, comment, sentiment, ADE, video, cessation, exposure, negative, positive, engagement, self, twitter, depression, emotion, compassion | 3.05 | Social & emotional | ↑↑↑ |
| side, industry, event, adverse, drug, pipeline, authored, safety, adjective, approved, effect, product, market, serious, repositioning | 2.5 | Drug side effect | ↑↑ |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Xie, H.; Cheng, G.; Poon, L.K.M.; Leng, M.; Wang, F.L. Trends and Features of the Applications of Natural Language Processing Techniques for Clinical Trials Text Analysis. Appl. Sci. 2020, 10, 2157. https://doi.org/10.3390/app10062157
Chen X, Xie H, Cheng G, Poon LKM, Leng M, Wang FL. Trends and Features of the Applications of Natural Language Processing Techniques for Clinical Trials Text Analysis. Applied Sciences. 2020; 10(6):2157. https://doi.org/10.3390/app10062157
Chicago/Turabian StyleChen, Xieling, Haoran Xie, Gary Cheng, Leonard K. M. Poon, Mingming Leng, and Fu Lee Wang. 2020. "Trends and Features of the Applications of Natural Language Processing Techniques for Clinical Trials Text Analysis" Applied Sciences 10, no. 6: 2157. https://doi.org/10.3390/app10062157
APA StyleChen, X., Xie, H., Cheng, G., Poon, L. K. M., Leng, M., & Wang, F. L. (2020). Trends and Features of the Applications of Natural Language Processing Techniques for Clinical Trials Text Analysis. Applied Sciences, 10(6), 2157. https://doi.org/10.3390/app10062157