A Traffic-Based Method to Predict and Map Urban Air Quality




Abstract
1. Introduction
2. Materials and Methods
2.1. Study Site
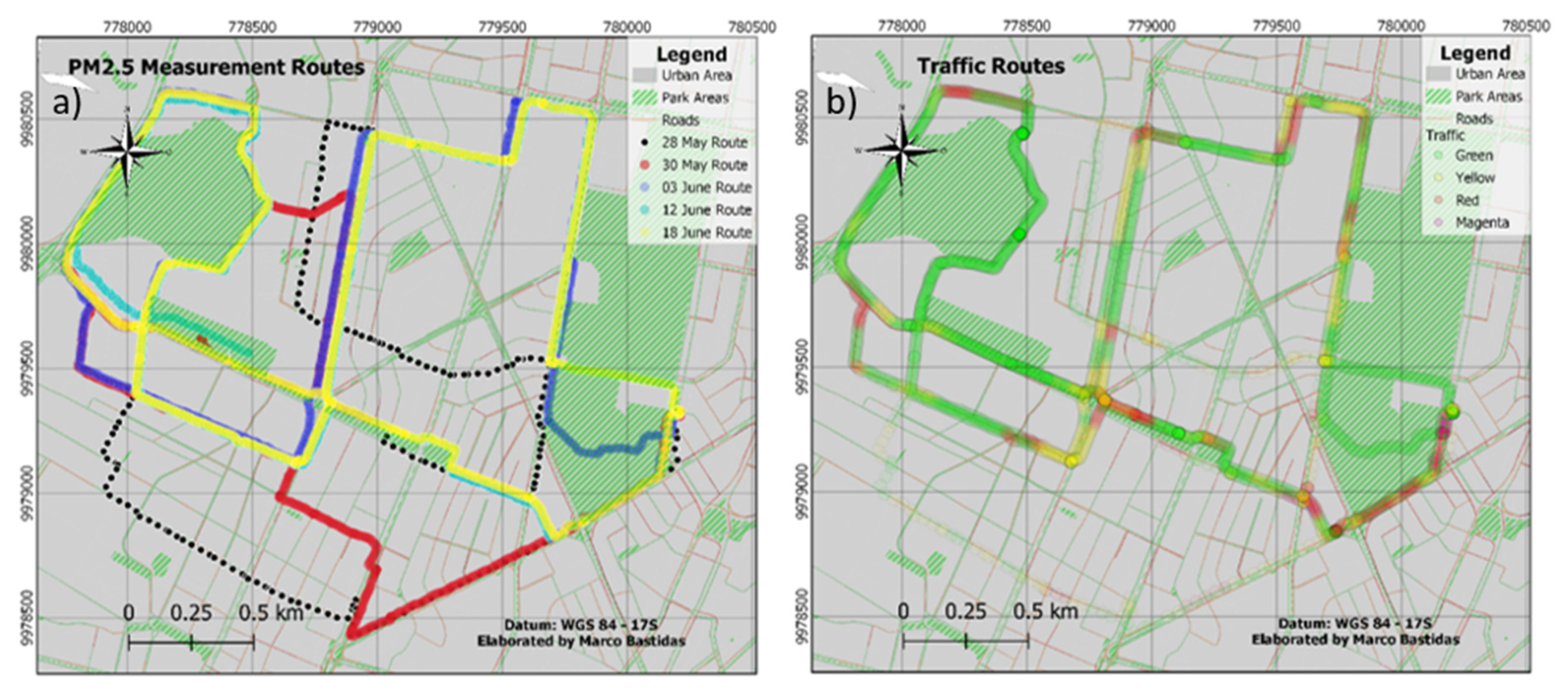
2.2. Pollution Measurement
2.3. Traffic Measurement
2.4. Modeling
2.4.1. Decision Trees Algorithm
2.4.2. Data Preparation and Assessment
2.4.3. Clustering Analysis
3. Results and Discussion
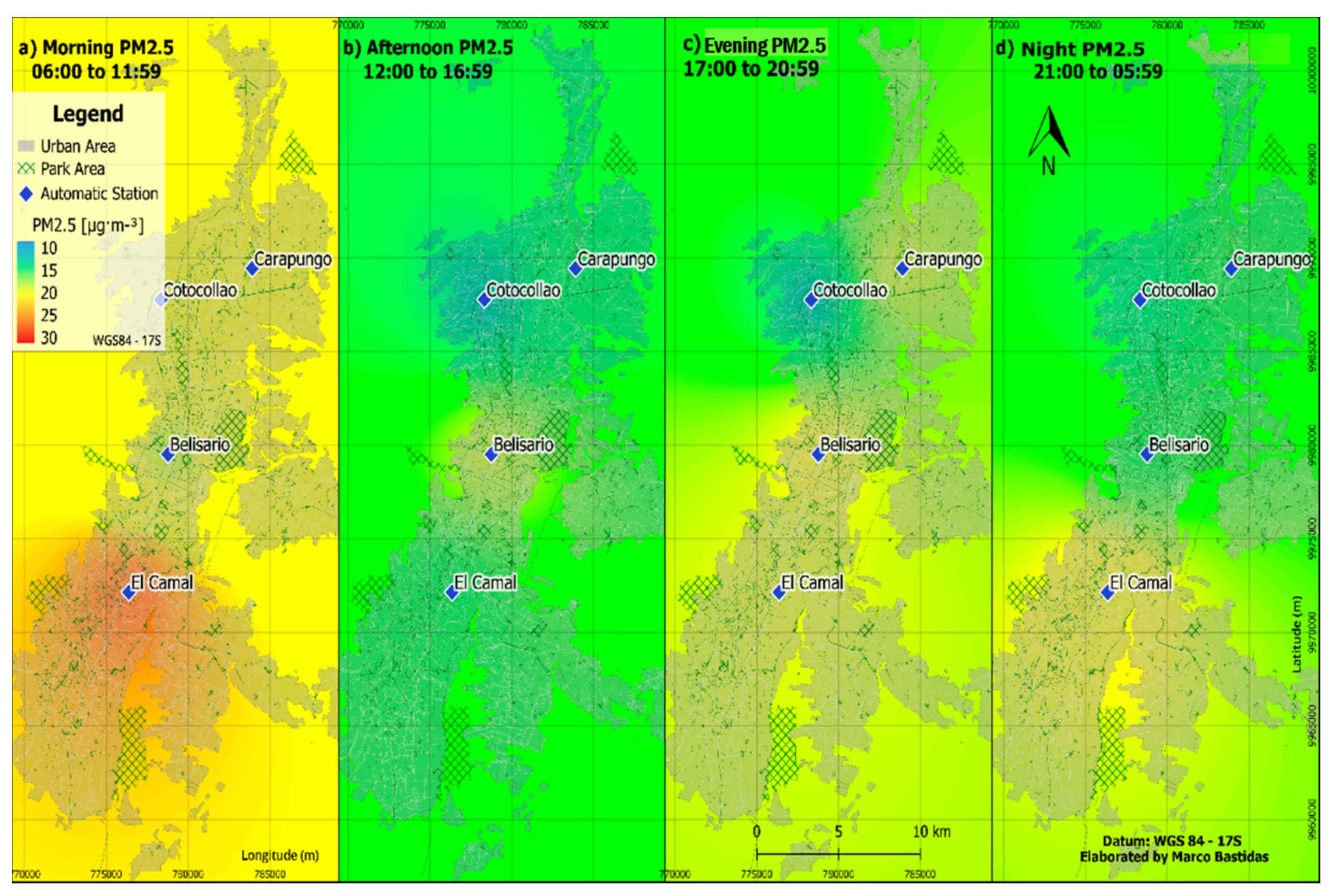
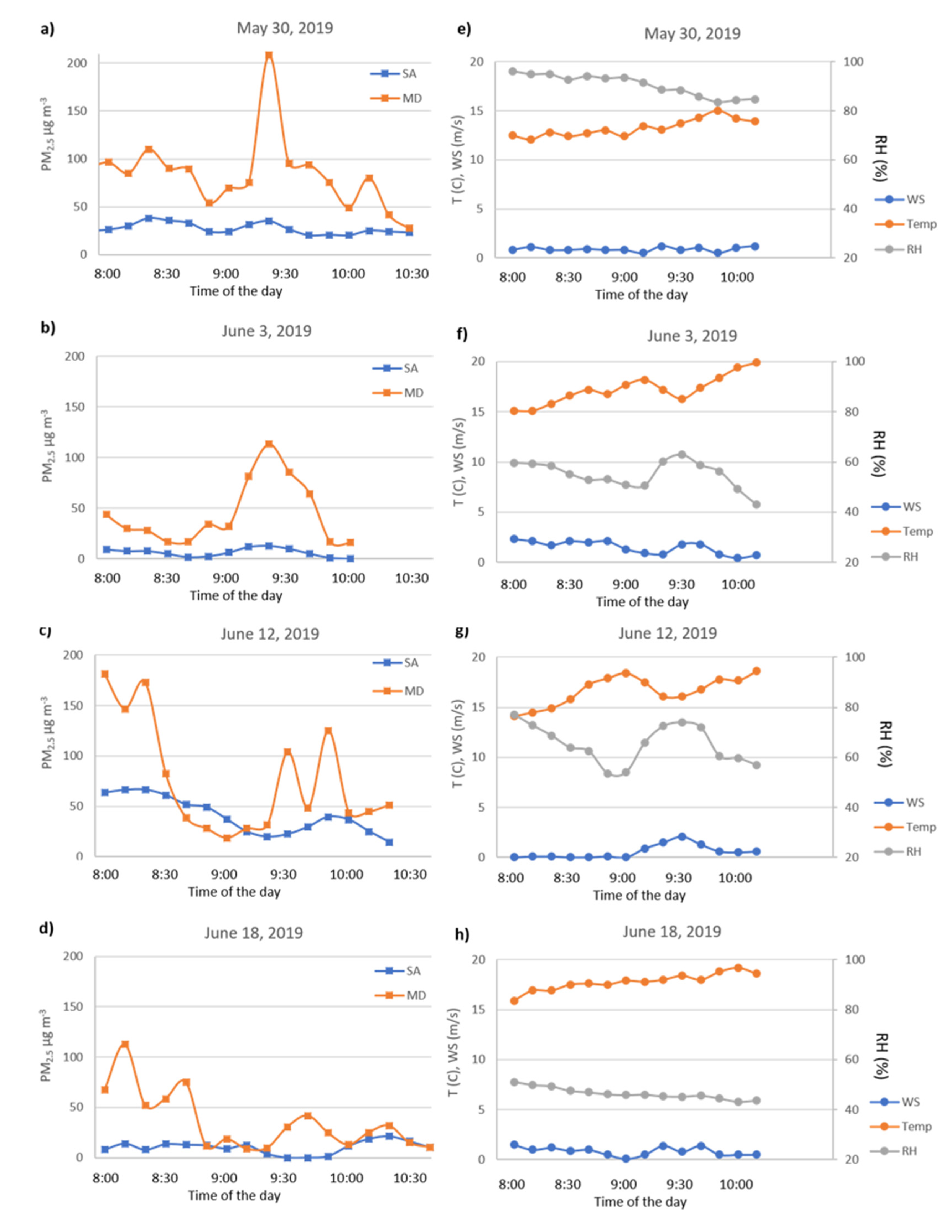
3.1. Urban PM2.5 Concentrations Based on the Air Quality Network
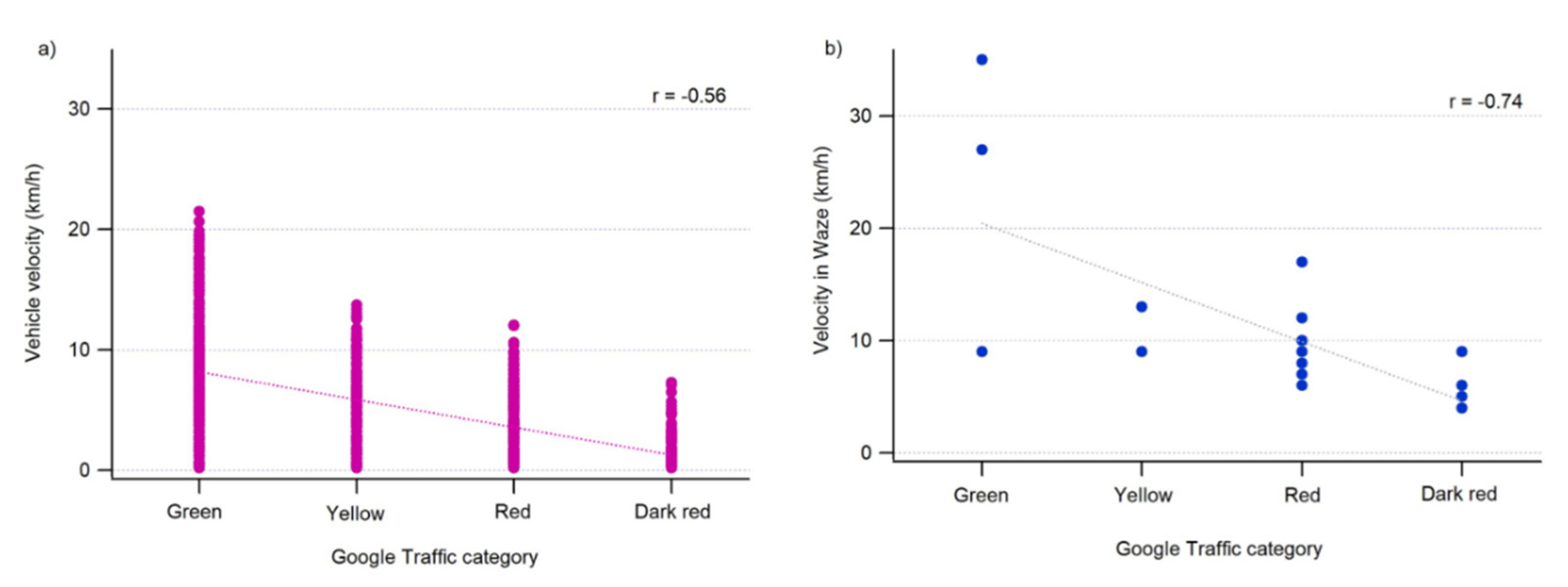
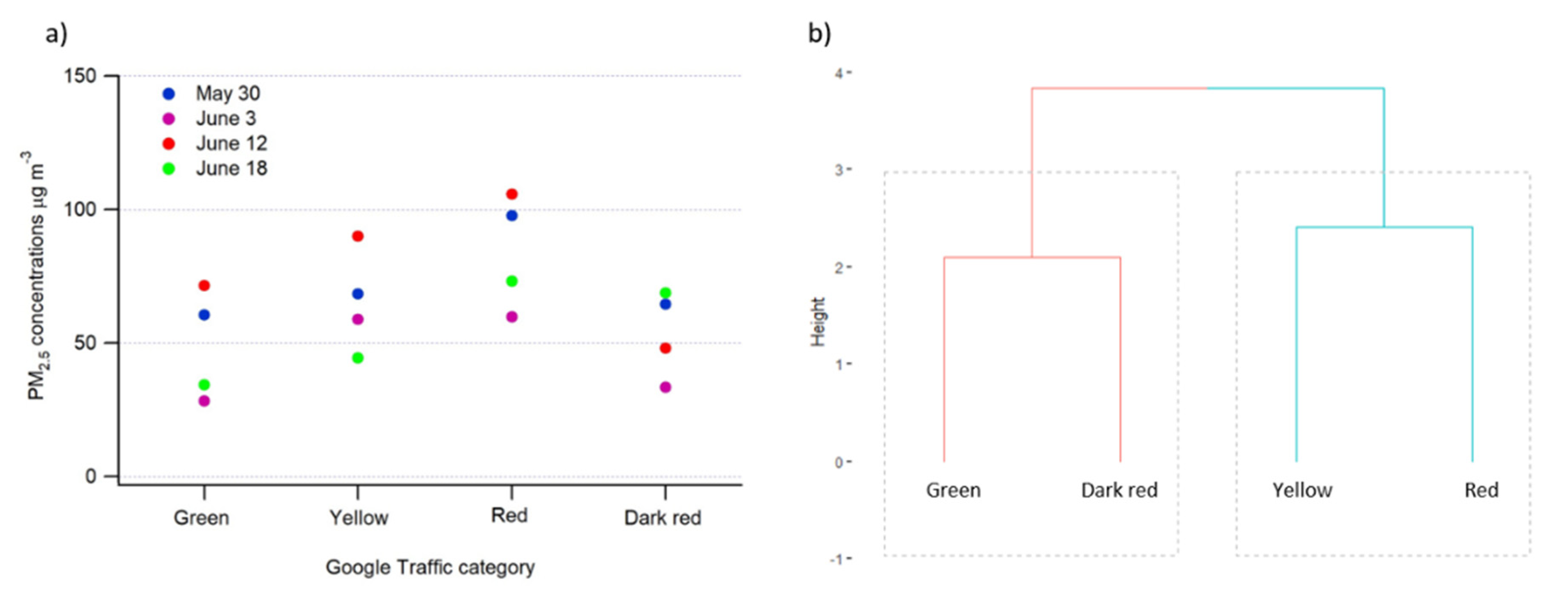
3.2. Traffic Data Validation and Relationship with PM2.5 Concentrations
3.3. Models and Prediction Accuracy
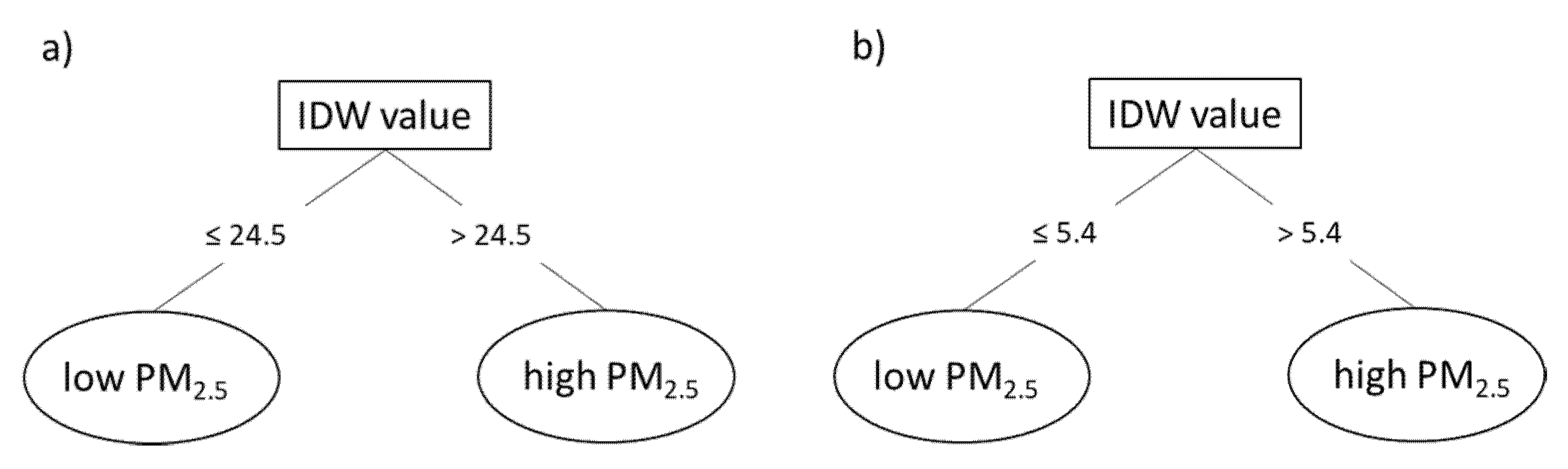
3.3.1. PM2.5 Prediction from Monitoring Stations and IDW
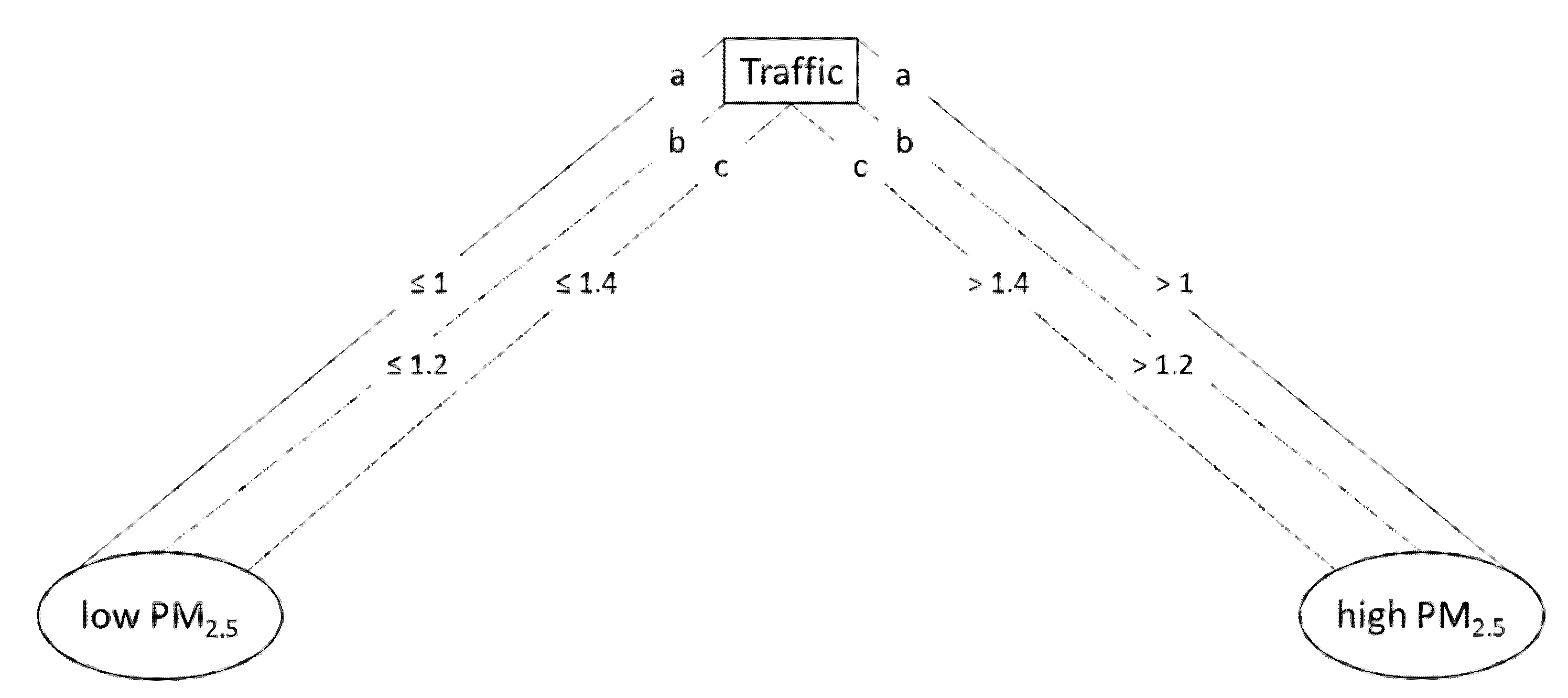
3.3.2. PM2.5 Prediction from Traffic Only
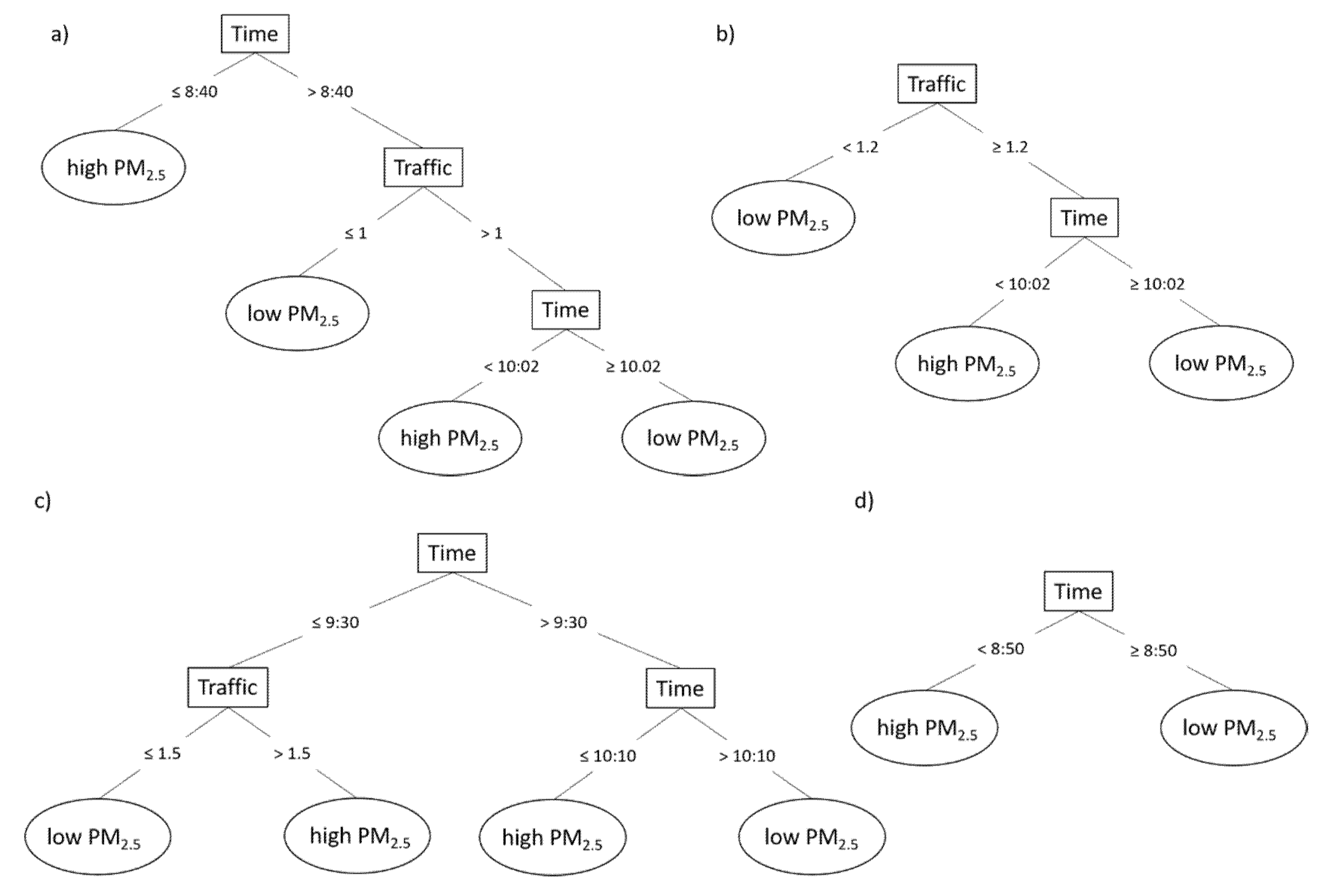
3.3.3. PM2.5 Prediction from Traffic and Time of the Day
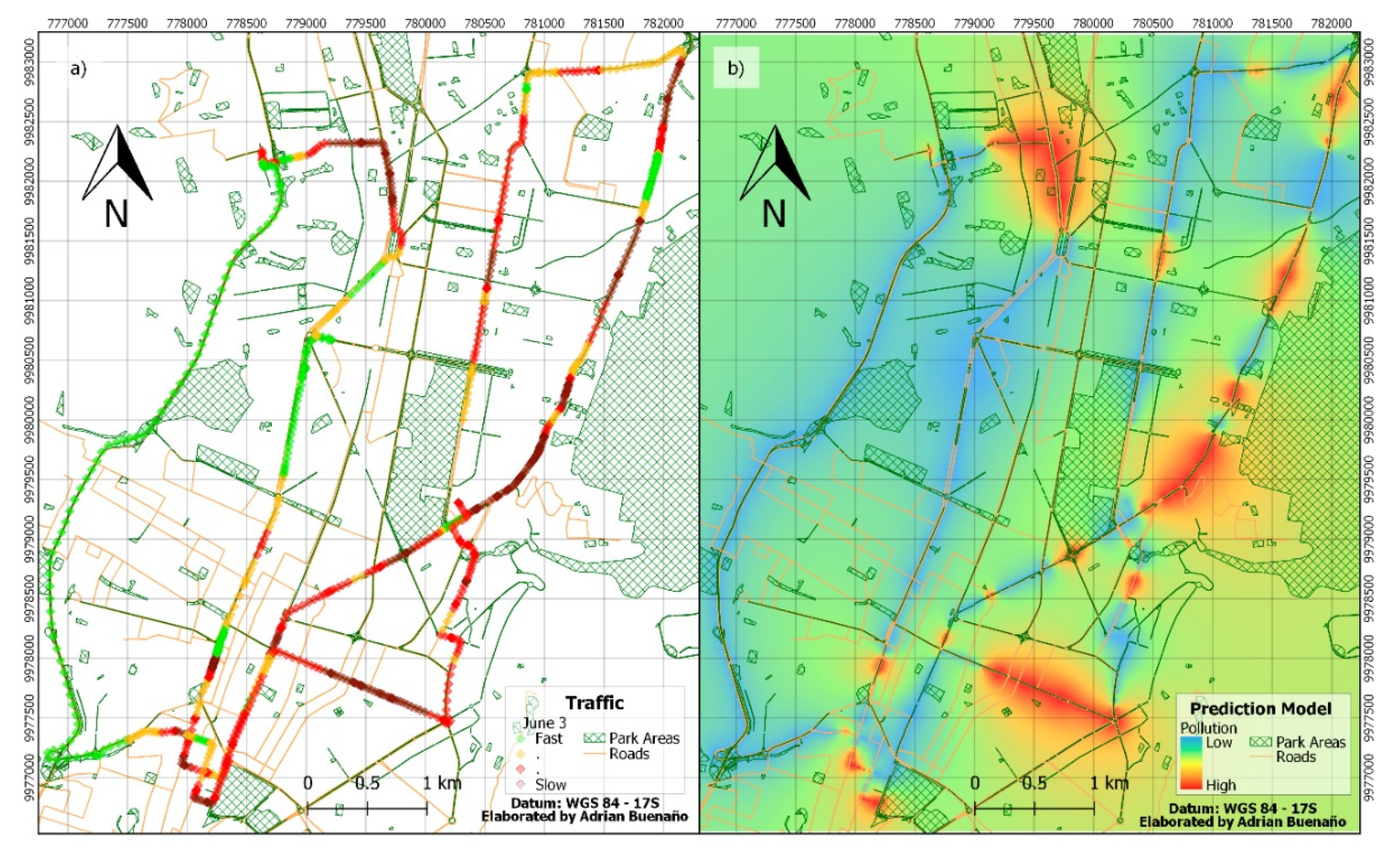
3.3.4. Model Generalization
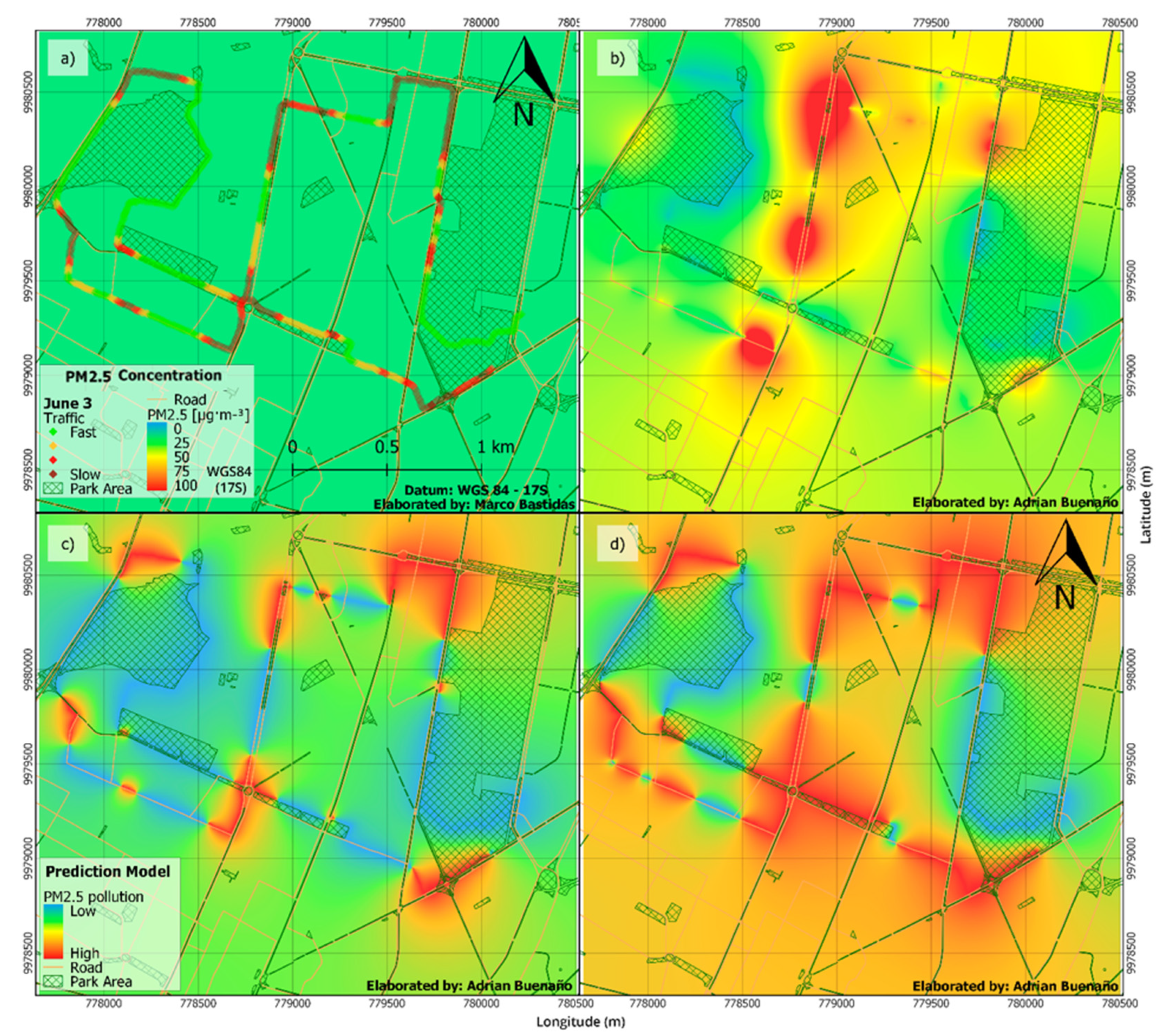
3.4. PM2.5 Mapping
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

References
- WHO. Air Pollution Levels Rising in Many of the World’s Poorest Cities. Available online: http://www.who.int/mediacentre/news/releases/2016/air-pollution-rising/en/#.WhOQc25vn1Q.mendeley (accessed on 21 November 2017).
- WHO. 7 Million Premature Deaths Annually Linked to Air Pollution. Available online: http://www.who.int/mediacentre/news/releases/2014/air-pollution/en/#.WqBfue47NRQ.mendeley (accessed on 7 March 2018).
- Lelieveld, J.; Evans, J.S.; Fnais, M.; Giannadaki, D.; Pozzer, A. The contribution of outdoor air pollution sources to premature mortality on a global scale. Nature 2015, 525, 367. [Google Scholar] [CrossRef] [PubMed]
- Pope, C.A.; Dockery, D.W. Health Effects of Fine Particulate Air Pollution: Lines that Connect. Air Waste Manag. Assoc. 2006, 56, 709–742. [Google Scholar] [CrossRef] [PubMed]
- Pope, C.A.; Coleman, N.; Pond, Z.A.; Burnett, R.T. Fine particulate air pollution and human mortality: 25+ years of cohort studies. Environ. Res. 2019, 108924. [Google Scholar] [CrossRef] [PubMed]
- European Environment Agency. Air Quality in Europe—2017 Report. Available online: https://www.eea.europa.eu/publications/air-quality-in-europe-2017 (accessed on 10 February 2020).
- European Environment Agency. Air Quality in Europe—2018 Report. Available online: https://www.eea.europa.eu/publications/air-quality-in-europe-2018 (accessed on 10 February 2020).
- United States Environmental Protection Agency. Particulate Matter (PM2.5) Trends. Available online: https://www.epa.gov/air-trends/particulate-matter-pm25-trends (accessed on 10 February 2020).
- Karagulian, F.; Belis, C.A.; Dora, C.F.C.; Prüss-Ustün, A.M.; Bonjour, S.; Adair-Rohani, H.; Amann, M. Contributions to cities’ ambient particulate matter (PM): A systematic review of local source contributions at global level. Atmos. Environ. 2015, 120, 475–483. [Google Scholar] [CrossRef]
- Zalakeviciute, R.; Rybarczyk, Y.; Lopez Villada, J.; Diaz Suarez, M.V. Quantifying decade-long effects of fuel and traf fi c regulations on urban ambient PM2.5 pollution in a mid-size South American city. Atmos. Pollut. Res. 2018, 9, 66–75. [Google Scholar] [CrossRef]
- Castell, N.; Dauge, F.R.; Schneider, P.; Vogt, M.; Lerner, U.; Fishbain, B.; Broday, D.; Bartonova, A. Can commercial low-cost sensor platforms contribute to air quality monitoring and exposure estimates? Environ. Int. 2017, 99, 293–302. [Google Scholar] [CrossRef]
- Kumar, P.; Morawska, L.; Martani, C.; Biskos, G.; Neophytou, M.; Di Sabatino, S.; Bell, M.; Norford, L.; Britter, R. The rise of low-cost sensing for managing air pollution in cities. Environ. Int. 2015, 75, 199–205. [Google Scholar] [CrossRef]
- Morawska, L.; Thai, P.K.; Liu, X.; Asumadu-Sakyi, A.; Ayoko, G.; Bartonova, A.; Bedini, A.; Chai, F.; Christensen, B.; Dunbabin, M.; et al. Applications of low-cost sensing technologies for air quality monitoring and exposure assessment: How far have they gone? Environ. Int. 2018, 116, 286–299. [Google Scholar] [CrossRef]
- Clements, A.L.; Griswold, W.G.; Abhijit, R.S.; Johnston, J.E.; Herting, M.M.; Thorson, J.; Collier-Oxandale, A.; Hannigan, M. Low-cost air quality monitoring tools: From research to practice (A workshop summary). Sensors 2017, 17, 2478. [Google Scholar] [CrossRef]
- Lewis, A.; Edwards, P. Validate personal air-pollution sensors. Nature 2016, 535, 29–31. [Google Scholar] [CrossRef]
- Mead, M.I.; Popoola, O.A.M.; Stewart, G.B.; Landshoff, P.; Calleja, M.; Hayes, M.; Baldovi, J.J.; McLeod, M.W.; Hodgson, T.F.; Dicks, J.; et al. The use of electrochemical sensors for monitoring urban air quality in low-cost, high-density networks. Atmos. Environ. 2013, 70, 186–203. [Google Scholar] [CrossRef]
- Spinelle, L.; Gerboles, M.; Kok, G.; Persijn, S.; Sauerwald, T. Review of portable and low-cost sensors for the ambient air monitoring of benzene and other volatile organic compounds. Sensors 2017, 17, 1520. [Google Scholar] [CrossRef]
- Apte, J.S.; Messier, K.P.; Gani, S.; Brauer, M.; Kirchstetter, T.W.; Lunden, M.M.; Marshall, J.D.; Portier, C.J.; Vermeulen, R.C.H.; Hamburg, S.P. High-Resolution Air Pollution Mapping with Google Street View Cars: Exploiting Big Data. Environ. Sci. Technol. 2017, 51, 6999–7008. [Google Scholar] [CrossRef] [PubMed]
- Leelőssy, Á.; Molnár, F.; Izsák, F.; Havasi, Á.; Lagzi, I.; Mészáros, R. Dispersion modeling of air pollutants in the atmosphere: A review. Cent. Eur. J. Geosci. 2014, 6, 257–278. [Google Scholar] [CrossRef]
- Seigneur, C.; Moran, M. CHAPTER 8 Chemical-Transport Models. Available online: https://www.narsto.org/sites/narsto-dev.ornl.gov/files/Ch71.3MB.pdf (accessed on 10 February 2020).
- Bravo-Moncayo, L.; Chávez, M.; Puyana, V.; Lucio-Naranjo, J.; Garzón, C.; Pavón-García, I. A cost-effective approach to the evaluation of traffic noise exposure in the city of Quito, Ecuador. Case Stud. Transp. Policy 2019, 7, 128–137. [Google Scholar] [CrossRef]
- Hoek, G.; Beelen, R.; de Hoogh, K.; Vienneau, D.; Gulliver, J.; Fischer, P.; Briggs, D. A review of land-use regression models to assess spatial variation of outdoor air pollution. Atmos. Environ. 2008, 42, 7561–7578. [Google Scholar] [CrossRef]
- Chen, L.; Wang, Y.; Li, P.; Ji, Y.; Kong, S.; Li, Z.; Bai, Z. A land use regression model incorporating data on industrial point source pollution. J. Environ. Sci. 2012, 24, 1251–1258. [Google Scholar] [CrossRef]
- Kashima, S.; Yorifuji, T.; Tsuda, T.; Doi, H. Application of land use regression to regulatory air quality data in Japan. Sci. Total Environ. 2009, 407, 3055–3062. [Google Scholar] [CrossRef]
- Hilpert, M.; Johnson, M.; Kioumourtzoglou, M.-A.; Domingo-Relloso, A.; Peters, A.; Adria-Mora, B.; Hernández, D.; Ross, J.; Chillrud, S.N. A new approach for inferring traffic-related air pollution: Use of radar-calibrated crowd-sourced traffic data. Environ. Int. 2019, 127, 142–159. [Google Scholar] [CrossRef] [PubMed]
- Zalakeviciute, R.; Buenaño, A.; Sannino, D.; Rybarczyk, Y. Urban air pollution mapping and traffic intensity: Active transport application. In Air Pollution: Monitoring, Quantification and Removal of Gases and Particles; Del Real Olvera, J., Ed.; IntechOpen: London, UK, 2018; p. 13. [Google Scholar]
- INEC. Poblacion, Superficie (km2), Densidad Poblacional A Nivel Parroquial; Gobierno de la Republica del Ecuador: Quito, Ecuador, 2011. [Google Scholar]
- Zalakeviciute, R.; López-Villada, J.; Rybarczyk, Y. Contrasted effects of relative humidity and precipitation on urban PM 2.5 pollution in high elevation urban areas. Sustainability 2018, 10, 2064. [Google Scholar] [CrossRef]
- Casella. Microdust Pro Real-Time Dust Monitor. 1–62. Available online: https://www.casellasolutions.com/content/dam/casella/ecommerce/handbooks/Microdust-Pro-CEL-712-Handbook-English.pdf (accessed on 28 February 2020).
- Garmin. eTrex Owner’s Manual. Available online: http://static.garmin.com/pumac/etrex%2022x_32x_OM_EN-US.pdf (accessed on 28 February 2020).
- Hernandez, W.; Mendez, A.; Diaz, A.; Zalakeviciute, R. Robust analysis of PM2.5 concentration measurements in the Ecuadorian park La Carolina. Sensors 2019, 19, 4643. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993; ISBN 1-55860-238-0. [Google Scholar]
- De Mesnard, L. Pollution Models and Inverse Distance Weighting: Some Critical Remarks. Comput. Geosci. 2013, 52, 459–469. [Google Scholar] [CrossRef]
- Shmueli, G.; Bruce, P.C.; Patel, N.R. Data Mining for Business Analytics: Concepts, Techniques, and Applications with XLMiner, 3rd ed.; Wiley Publishing: Hoboken, NJ, USA, 2016; ISBN 1118729277. [Google Scholar]
- Corani, G.; Scanagatta, M. Air pollution prediction via multi-label classification. Environ. Model. Softw. 2016, 80, 259–264. [Google Scholar] [CrossRef]
- Kleine Deters, J.; Zalakeviciute, R.; Gonzalez, M.; Rybarczyk, Y. Modeling PM2.5 Urban Pollution Using Machine Learning and Selected Meteorological Parameters. J. Electr. Comput. Eng. 2017, 2017, 1–14. [Google Scholar] [CrossRef]
- Rybarczyk, Y.; Zalakeviciute, R. Machine learning approach to forecasting urban pollution: A case study of Quito, Ecuador. In Proceedings of the IEEE ETCM, Guayaquil, Ecuador, 12–14 October 2016. [Google Scholar]
- Lei, M.T.; Monjardino, J.; Mendes, L.; Gonçalves, D.; Ferreira, F. Macao air quality forecast using statistical methods. Air Qual. Atmos. Health 2019, 12, 1049–1057. [Google Scholar] [CrossRef]
- Wang, J.; Ogawa, S. Effects of Meteorological Conditions on PM2.5 Concentrations in Nagasaki, Japan. Int. J. Environ. Res. Public Health 2015, 12, 9089–9101. [Google Scholar] [CrossRef]
- de la Paz, D.; Borge, R.; Vedrenne, M.; Lumbreras, J.; Amato, F.; Karanasiou, A.; Boldo, E.; Moreno, T. Implementation of road dust resuspension in air quality simulations of particulate matter in Madrid (Spain). Front. Environ. Sci. 2015, 3, 72. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| p Values | p = 1 | p = 2 | p = 3 | p = 4 | p = 5 |
|---|---|---|---|---|---|
| May 30th | 50% | 50% | 50% | 50% | 49% |
| June 3rd | 67% | 71% | 70% | 70% | 70% |
| June 12th | 57% | 57% | 57% | 57% | 57% |
| June 18th | 50% | 50% | 50% | 50% | 50% |
| Models | Traf_a | Traf_b | Traf_c | Traf_Tim_a | Traf_Tim_b | Traf_Tim_c | Traf_Tim_d |
|---|---|---|---|---|---|---|---|
| Within-cluster squared distance | 15.71 | 14.21 | 20.3 | 93.6 | 137.12 | 145.35 | 99.97 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zalakeviciute, R.; Bastidas, M.; Buenaño, A.; Rybarczyk, Y. A Traffic-Based Method to Predict and Map Urban Air Quality. Appl. Sci. 2020, 10, 2035. https://doi.org/10.3390/app10062035
Zalakeviciute R, Bastidas M, Buenaño A, Rybarczyk Y. A Traffic-Based Method to Predict and Map Urban Air Quality. Applied Sciences. 2020; 10(6):2035. https://doi.org/10.3390/app10062035
Chicago/Turabian StyleZalakeviciute, Rasa, Marco Bastidas, Adrian Buenaño, and Yves Rybarczyk. 2020. "A Traffic-Based Method to Predict and Map Urban Air Quality" Applied Sciences 10, no. 6: 2035. https://doi.org/10.3390/app10062035
APA StyleZalakeviciute, R., Bastidas, M., Buenaño, A., & Rybarczyk, Y. (2020). A Traffic-Based Method to Predict and Map Urban Air Quality. Applied Sciences, 10(6), 2035. https://doi.org/10.3390/app10062035