Encoding, Exchange and Manipulation of Captured Immersive VR Sessions for Learning Environments: the PRISMIN Framework



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- lightweight transmission of captured data in networked environments and over Internet connections.
- small computational load for encoding/decoding routines.
- direct manipulation of complex records on GPU hardware and offline image processing.
- basic image-based operations to compare or assess specific patterns.
2. Related Work
3. The Image-Based Model
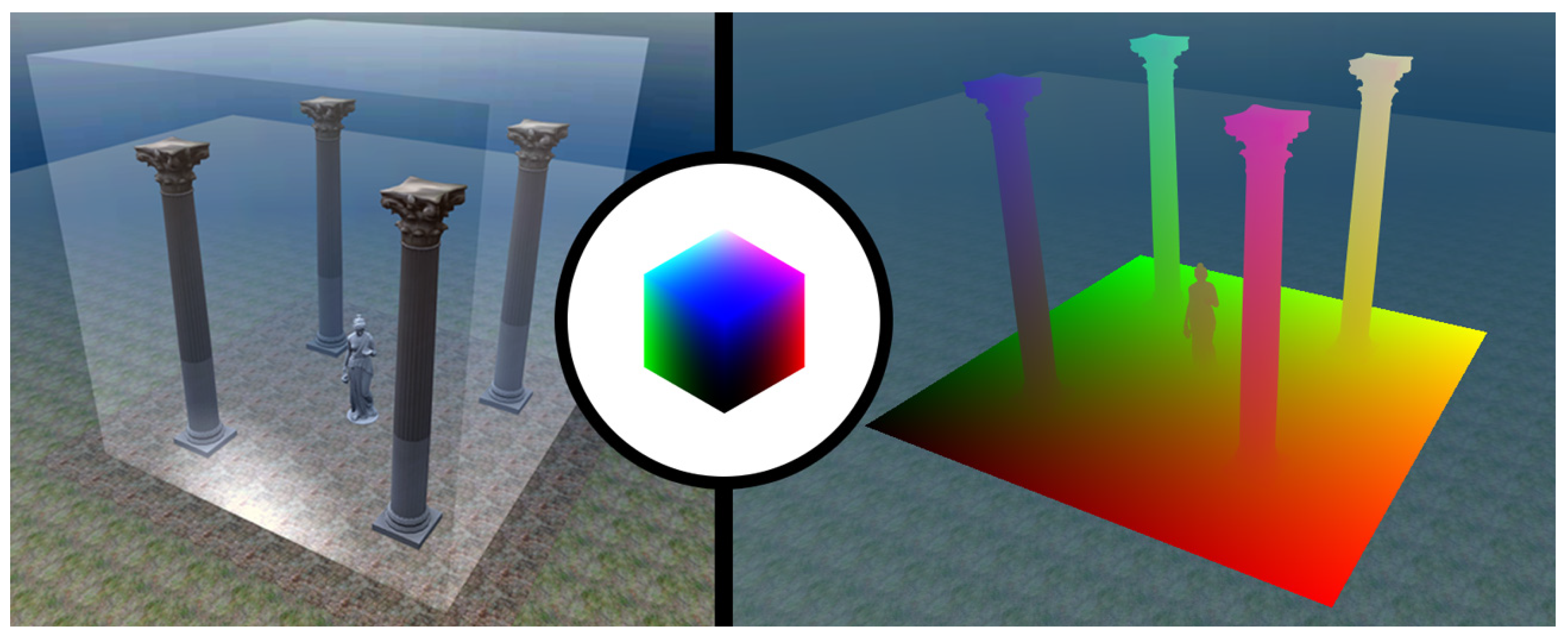
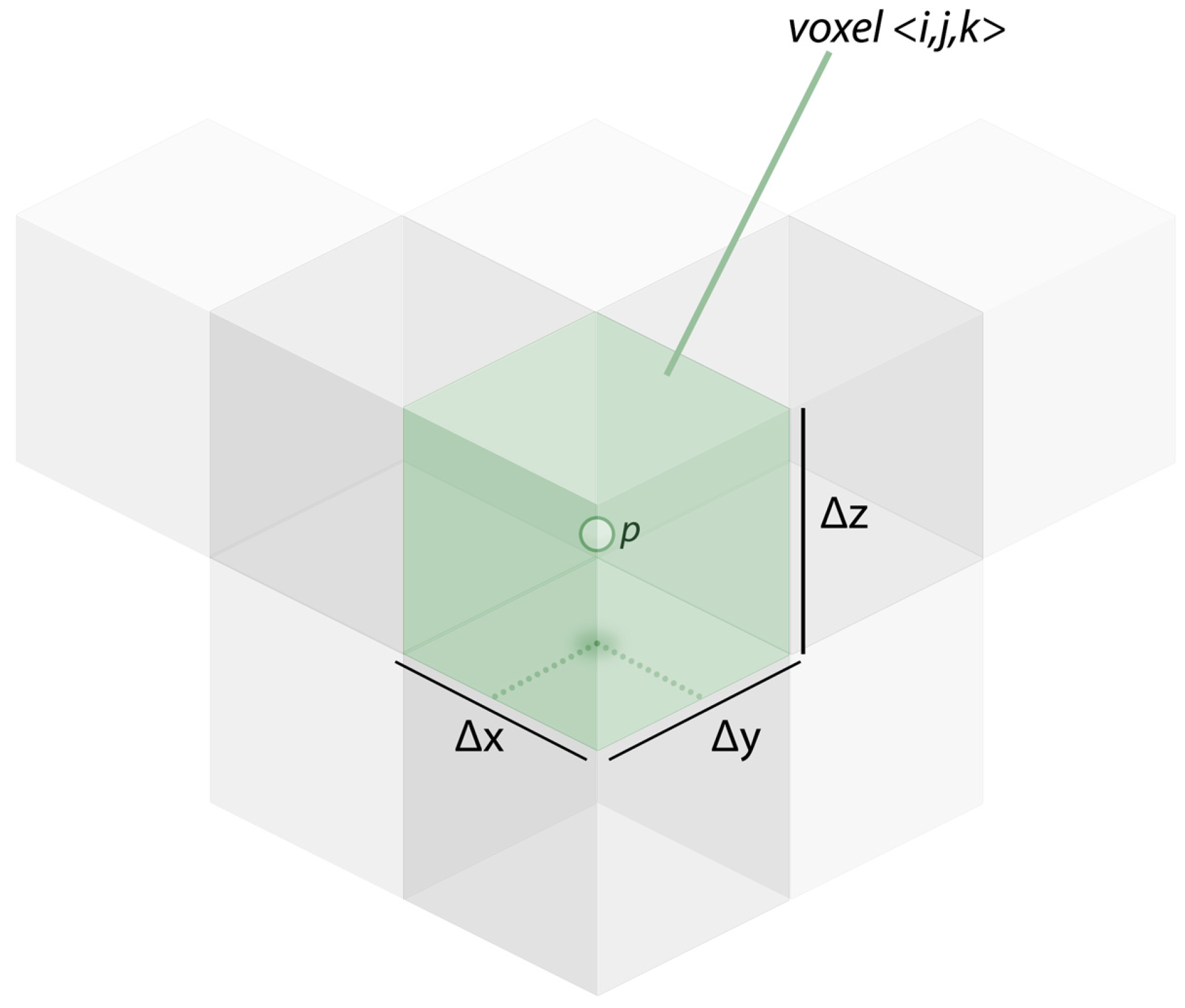
3.1. Session Volumes
3.1.1. Quantization Error
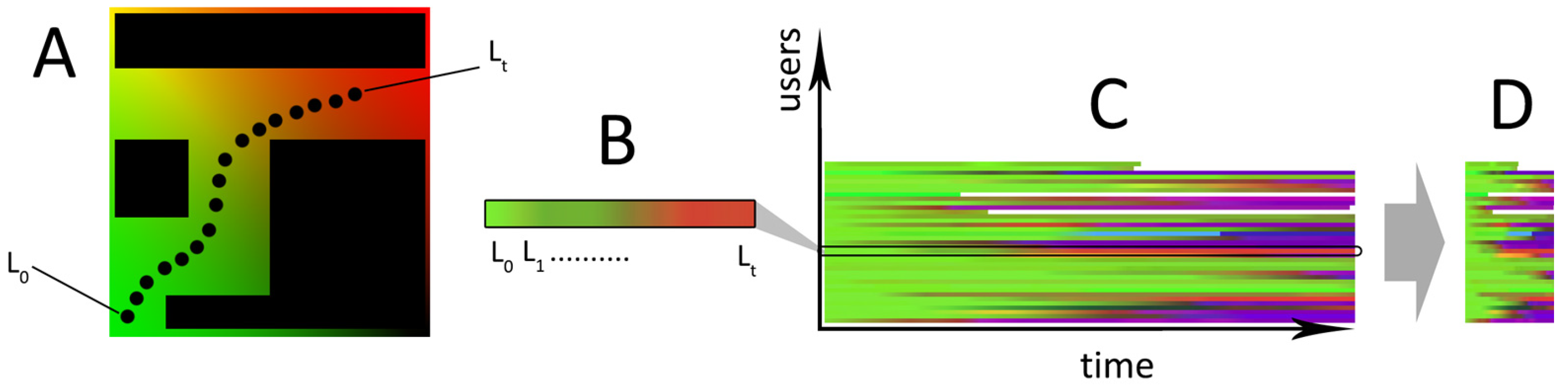
3.2. Time-Driven Layout
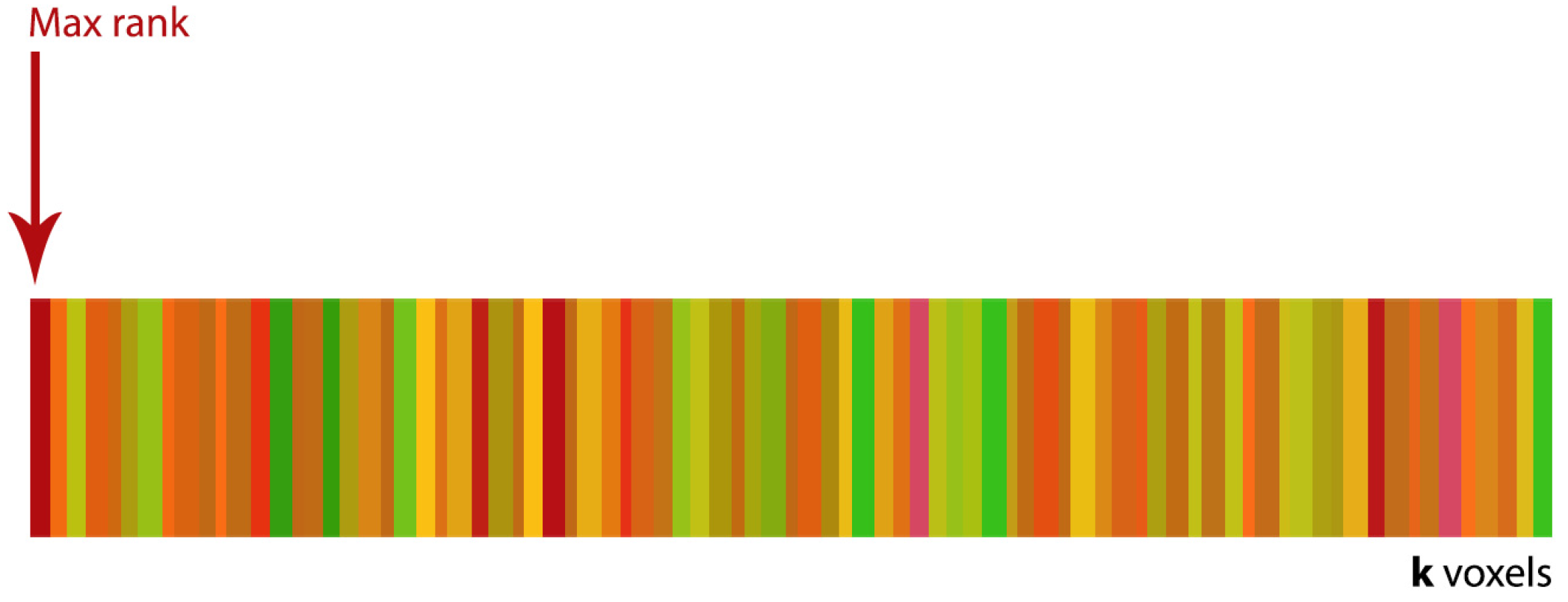
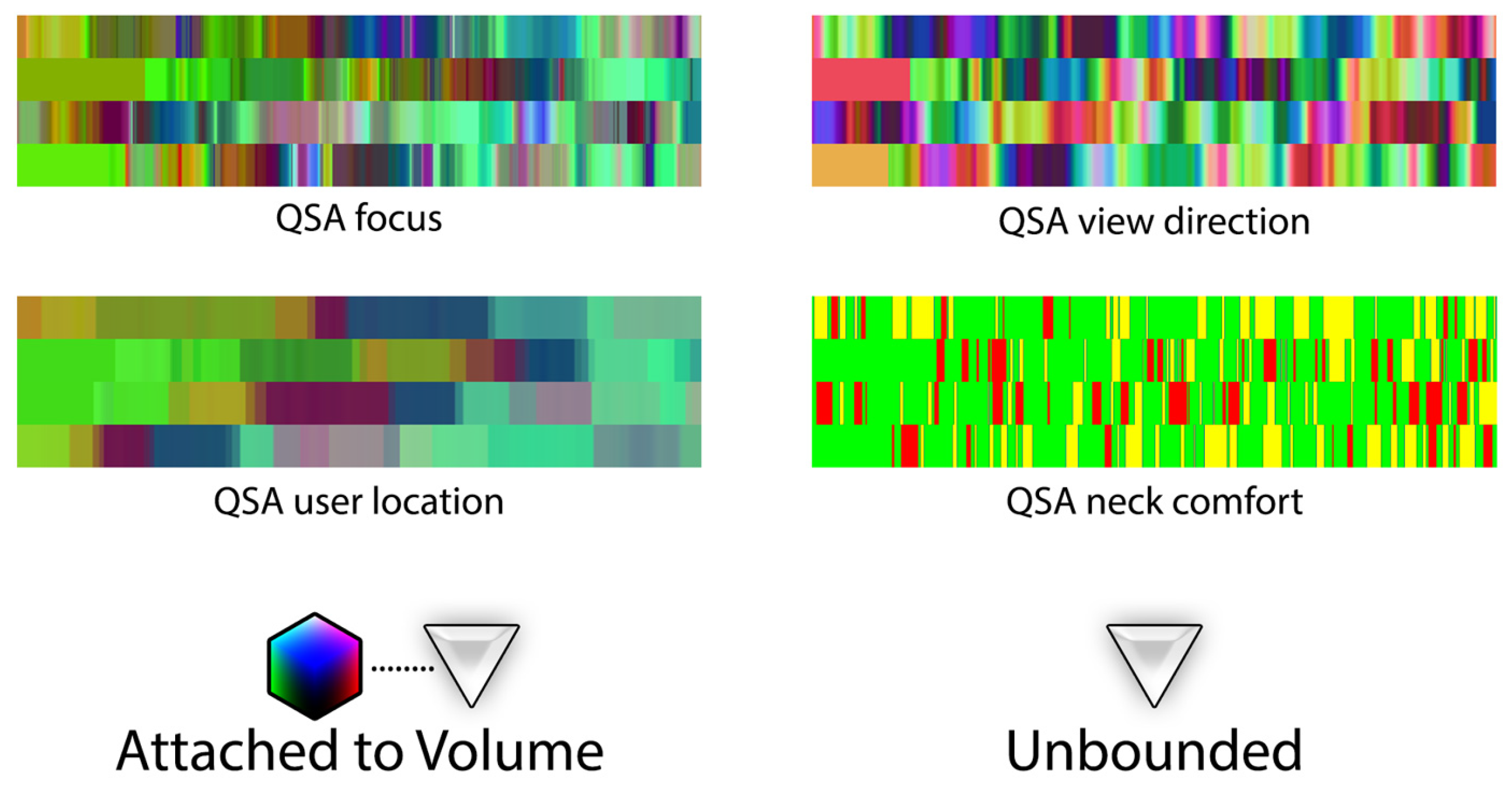
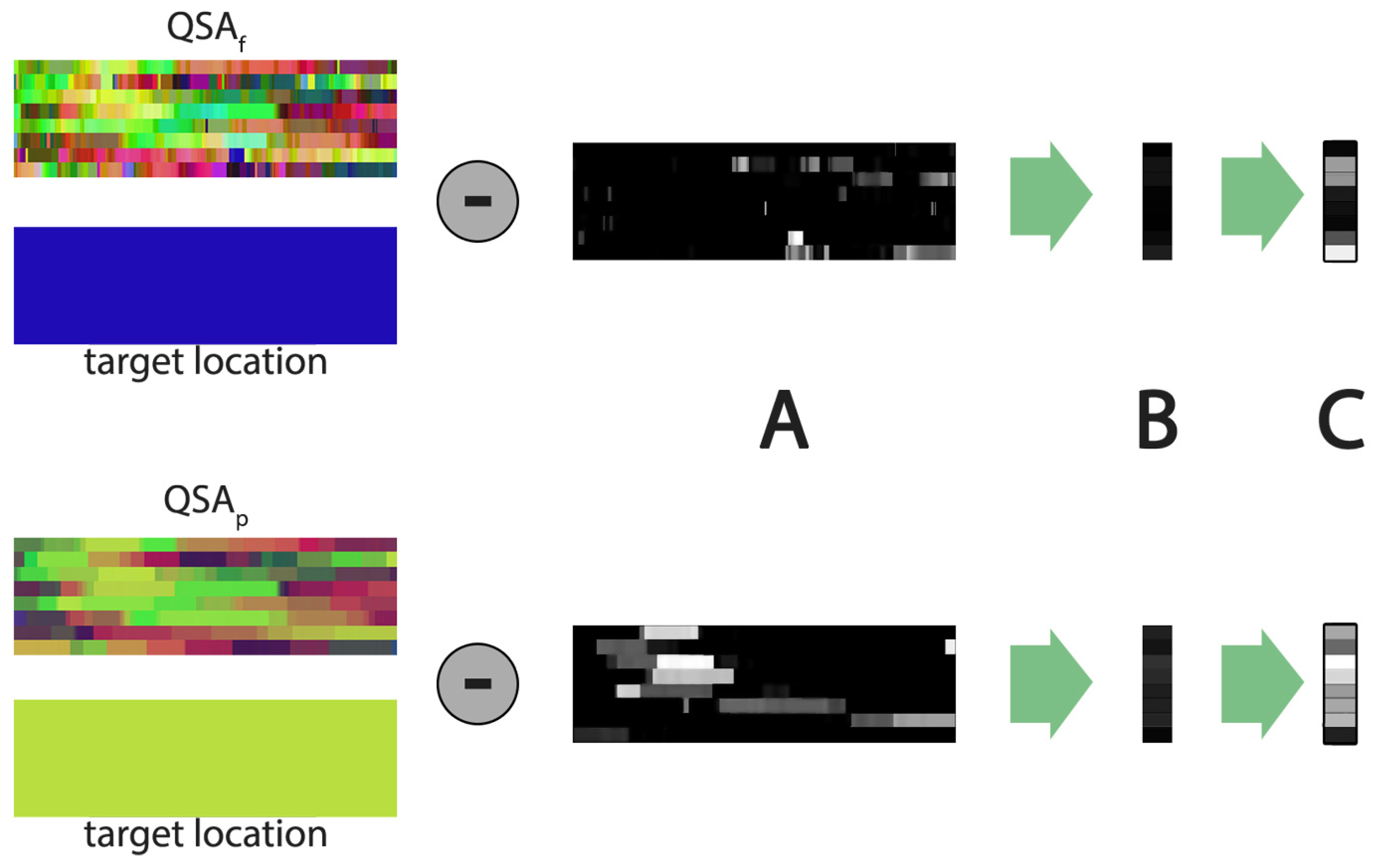
3.3. Saliency-Driven Layout
- compactness: the layout suits very well networked scenarios and remote analytics (see results in Section 5).
- partial evaluation: the sorted approach of allows the rightmost pixel to be discarded (less relevant voxels for chosen policy) maintaining overall approximation of the signature.
- multiple attributes: different spatial attributes can be arranged in one atlas (like QSA layout in Section 3.2) to transport multiple per volume, using a single lightweight image.
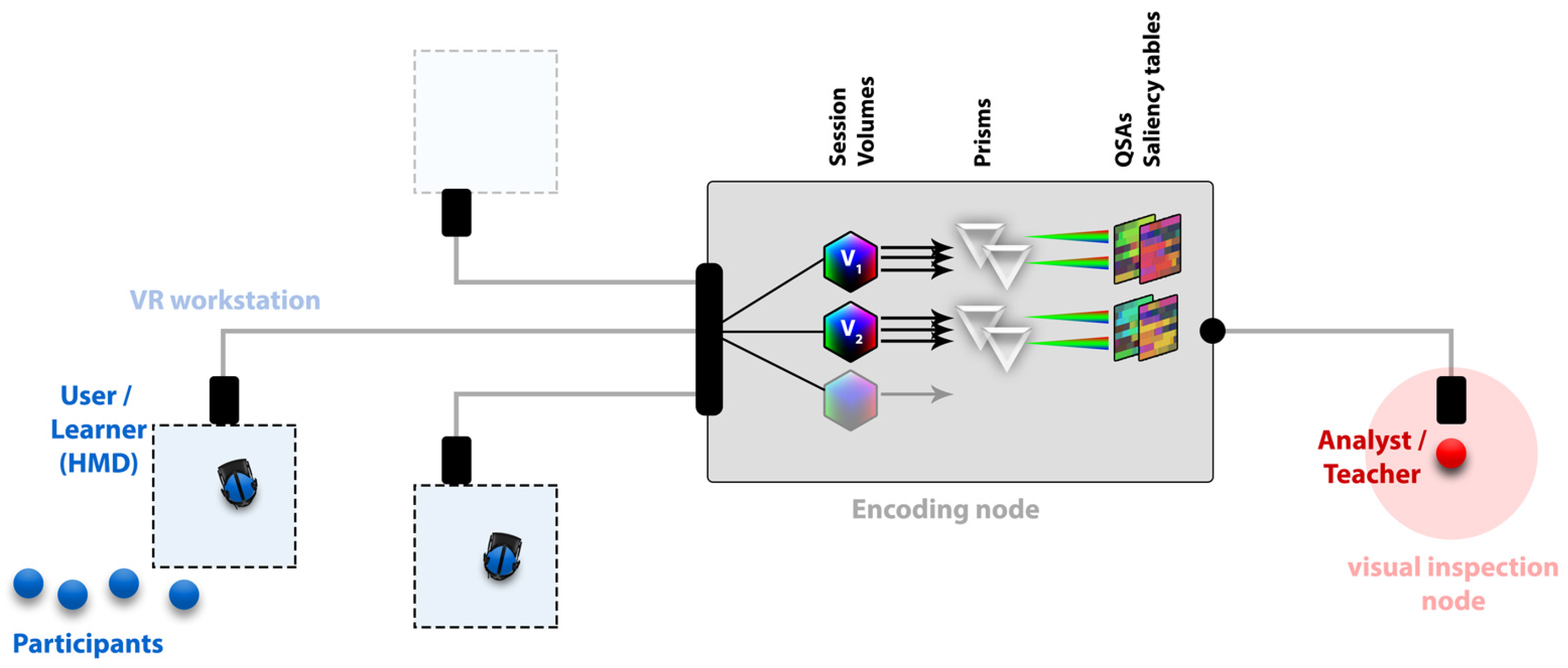
4. PRISMIN Framework Overview
- 1.
- immersive VR workstation node (users).
- 2.
- encoding node (server).
- 3.
- visual inspection node (analysts).
4.1. Encoding Node
- Atlas: this represents the 2D image that is physically generated on disk and exchanged among peers (learners and teachers/analysts). Each atlas may have a specific layout (how data is accessed) and quantization mechanics (how state attribute is encoded into a color). QSA and saliency tables are examples of image atlas—see Section 3.2 and Section 3.3.
- Prism: an interaction prism object allows the ability to define how incoming user states are projected into atlases. It must implement a refract method (how state attributes are mapped onto the atlas image or images) and a bake method (write the actual image or images on disk).
- Volume: this represents a classic AABB structure (see Section 3.1) that operates in a well-defined portion of the scene. Several prisms can be attached to a single volume, providing maximum flexibility on which attributes a teacher is willing to track and how. Notice that each volume operates independently, thus they can be overlapped or nested within the virtual space of the IVE without any issues.
4.2. Visual Inspection Node
4.3. Integration with Existing Projects
5. Experimental Results
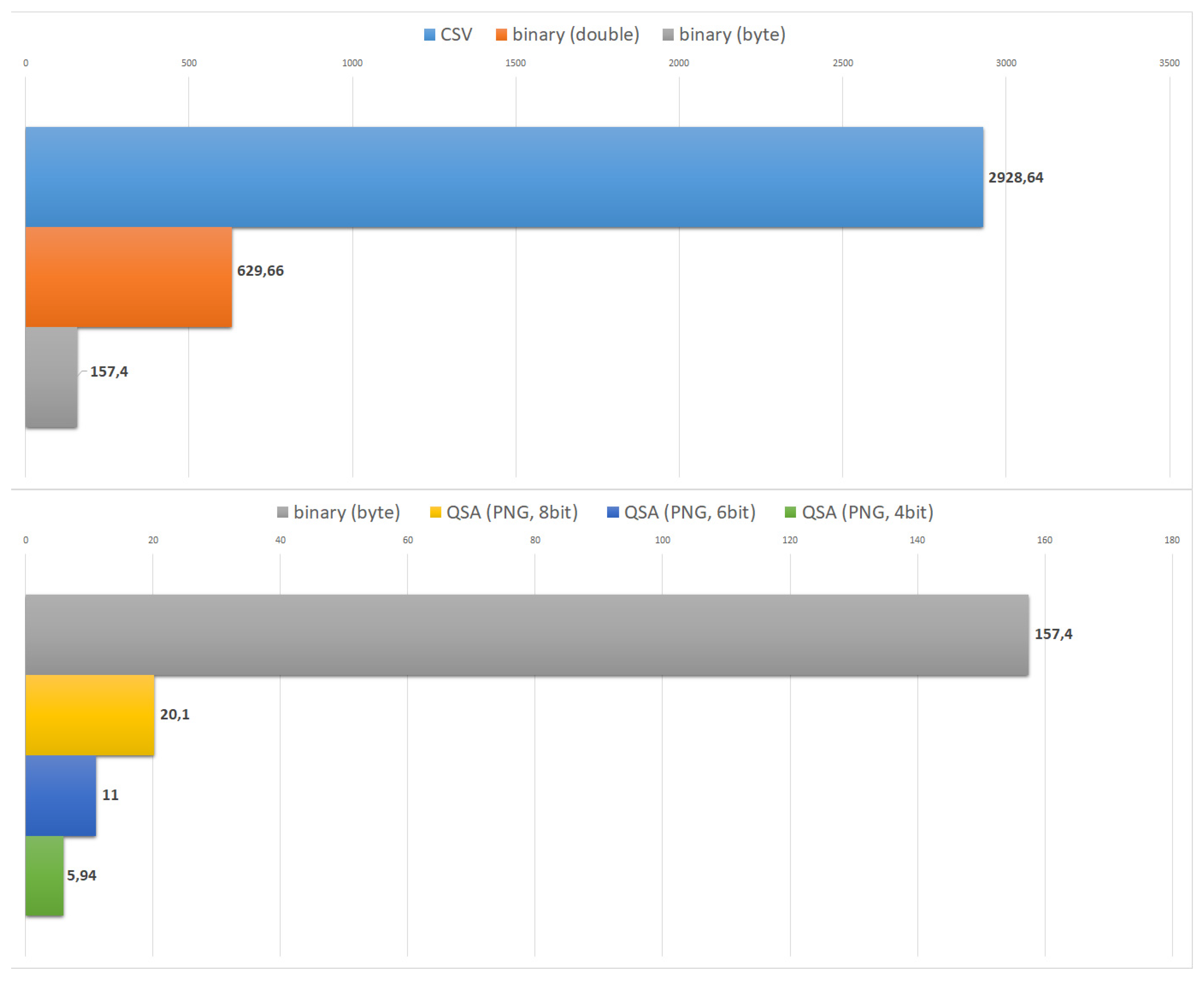
5.1. Offline Encoding
5.2. Direct Encoding and Manipulation
- (A)
- one HMD workstation for eight students to explore a sample scene Picture Gallery, created by Hallwyl Museum (Stockholm, Sweden) and available online on SketchFab. using the WebVR/XR online front-end (using Firefox web browser—see Figure 9, top row).
- (B)
- one server node serving 3D content and encoding incoming user states.
- (C)
- one workstation where the remote analyst could inspect ongoing sessions, visualizing running QSAs and saliency tables generated by (A) in real-time.
- 4 archaeologists.
- 2 art historians.
- 1 architect.
- 1 computer scientist.
6. Conclusions and Future Developments
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| IVE | Immersive Virtual Environment |
| HMD | Head-mounted Display |
| DOF | Degrees of Freedom (3 or 6 for head-mounted displays) |
| QSA | Quantized Session Atlas |
References
- Maher, D. Altered Realities: How Virtual and Augmented Realities Are Supporting Learning. In Handbook of Research on Innovative Pedagogies and Best Practices in Teacher Education; IGI Global: Hershey, PA, USA, 2020; pp. 34–51. [Google Scholar]
- Mantovani, G. VR learning: Potential and challenges for the use of 3D. In Towards Cyberpsychology: Mind, Cognitions, and Society in the Internet Age; IOS Press: Amsterdam, The Netherlands, 2003; pp. 208–225. [Google Scholar]
- Herz, M.; Rauschnabel, P.A. Understanding the diffusion of virtual reality glasses: The role of media, fashion and technology. Technol. Forecast. Soc. Chang. 2019, 138, 228–242. [Google Scholar] [CrossRef]
- Shute, V.; Rahimi, S.; Emihovich, B. Assessment for Learning in Immersive Environments. In Virtual, Augmented, and Mixed Realities in Education; Springer: Cham, Switzerland, 2017; pp. 71–87. [Google Scholar]
- Airey, D.; Benckendorff, P. Standards, benchmarks and assurance of learning. In Handbook of Teaching and Learning in Tourism; Edward Elgar Publishing: Cheltenham, UK, 2017. [Google Scholar]
- Wong, P.C.; Thomas, J. Visual analytics. IEEE Comput. Graph. Appl. 2004, 24, 20–21. [Google Scholar] [CrossRef] [PubMed]
- Agus, M.; Marton, F.; Bettio, F.; Gobbetti, E. Interactive 3D exploration of a virtual sculpture collection: An analysis of user behavior in museum setting. In Proceedings of the 13th Eurographics Worhshop on Graphics and Cultural Heritage, Genoa, Italy, 5–7 October 2016. [Google Scholar]
- Jankowski, P.; Andrienko, N.; Andrienko, G.; Kisilevich, S. Discovering landmark preferences and movement patterns from photo postings. Trans. GIS 2010, 14, 833–852. [Google Scholar] [CrossRef]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Battersby, S.A.; Lavelle, M.; Healey, P.G.; McCabe, R. Analysing Interaction: A comparison of 2D and 3D techniques. In Proceedings of the Programme of the Workshop on Multimodal Corpora, Marrakech, Morocco, 27 May 2008; p. 73. [Google Scholar]
- Boletsis, C. The new era of virtual reality locomotion: A systematic literature review of techniques and a proposed typology. Multimodal Technol. Interact. 2017, 1, 24. [Google Scholar] [CrossRef]
- Scopigno, R.; Callieri, M.; Dellepiane, M.; Ponchio, F.; Potenziani, M. Delivering and using 3D models on the web: Are we ready? Virtual Archaeol. Rev. 2017, 8, 1–9. [Google Scholar] [CrossRef]
- Maclntyre, B.; Smith, T.F. Thoughts on the Future of WebXR and the Immersive Web. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Munich, Germany, 16–20 October 2018; pp. 338–342. [Google Scholar]
- See, Z.S.; Lee, X.S.; Brimo, A.; Thwaites, H.; Goodman, L. MOOC for AR VR Training. In Proceedings of the IEEE Games, Entertainment, Media Conference (GEM), Galway, Ireland, 16–17 August 2018; pp. 1–9. [Google Scholar]
- Sitzmann, V.; Serrano, A.; Pavel, A.; Agrawala, M.; Gutierrez, D.; Masia, B.; Wetzstein, G. Saliency in VR: How do people explore virtual environments? IEEE Trans. Vis. Comput. Graph. 2018, 24, 1633–1642. [Google Scholar] [CrossRef] [PubMed]
- Upenik, E.; Ebrahimi, T. A simple method to obtain visual attention data in head mounted virtual reality. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 73–78. [Google Scholar]
- Knorr, S.; Ozcinar, C.; Fearghail, C.O.; Smolic, A. Director’s Cut-A Combined Dataset for Visual A ention Analysis in Cinematic VR Content. In Proceedings of the CVMP ’18 15th ACM SIGGRAPH European Conference on Visual Media Production, London, UK, 13–14 December 2018. [Google Scholar]
- Chandler, T.; Cordeil, M.; Czauderna, T.; Dwyer, T.; Glowacki, J.; Goncu, C.; Klapperstueck, M.; Klein, K.; Marriott, K.; Schreiber, F.; et al. Immersive analytics. In Proceedings of the Big Data Visual Analytics (BDVA), Hobart, Australia, 22–25 September 2015; pp. 1–8. [Google Scholar]
- Butcher, P.W.; Roberts, J.C.; Ritsos, P.D. Immersive Analytics with WebVR and Google Cardboard. In Proceedings of the Posters of IEEE VIS, Baltimaore, MD, USA, 23–28 October 2016. [Google Scholar]
- Butcher, P.W.; John, N.W.; Ritsos, P.D. Towards a Framework for Immersive Analytics on the Web. In Proceedings of the IEEE Conference on Visualization: InfoVis, Berlin, Germany, 21–26 October 2018. [Google Scholar]
- Hadjar, H.; Meziane, A.; Gherbi, R.; Setitra, I.; Aouaa, N. WebVR based interactive visualization of open health data. In Proceedings of the 2nd International Conference on Web Studies, Paris, France, 8–10 October 2018; pp. 56–63. [Google Scholar]
- Wiggins, R.H.; Davidson, H.C.; Harnsberger, H.R.; Lauman, J.R.; Goede, P.A. Image file formats: Past, present, and future. Radiographics 2001, 21, 789–798. [Google Scholar] [CrossRef] [PubMed]
- Limper, M.; Jung, Y.; Behr, J.; Sturm, T.; Franke, T.; Schwenk, K.; Kuijper, A. Fast, progressive loading of binary-encoded declarative-3d web content. IEEE Comput. Graph. Appl. 2013, 33, 26–36. [Google Scholar] [CrossRef] [PubMed]
- Dworak, D.; Pietruszka, M. Fast encoding of huge 3D data sets in lossless PNG format. In New Research in Multimedia and Internet Systems; Springer: Berlin, Germany, 2015; pp. 15–24. [Google Scholar]
- Gu, X.; Gortler, S.J.; Hoppe, H. Geometry images. ACM Trans. Graph. 2002, 21, 355–361. [Google Scholar] [CrossRef]
- Fanini, B.; Cinque, L. An Image-Based Encoding to Record and Track Immersive VR Sessions. In International Conference on Computational Science and Its Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 299–310. [Google Scholar]
- Fanini, B.; Cinque, L. Encoding immersive sessions for online, interactive VR analytics. Virtual Real. 2019. [Google Scholar] [CrossRef]
- Manku, G.S.; Motwani, R. Approximate frequency counts over data streams. In Proceedings of the VLDB’02, 28th International Conference on Very Large Databases, HongKong, China, 20–23 August 2002; pp. 346–357. [Google Scholar]
- Habgood, M.J.; Moore, D.; Wilson, D.; Alapont, S. Rapid, continuous movement between nodes as an accessible virtual reality locomotion technique. In Proceedings of the 2018 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Reutlingen, Germany, 18–22 March 2018; pp. 371–378. [Google Scholar]
- Meghini, C.; Scopigno, R.; Richards, J.; Wright, H.; Geser, G.; Cuy, S.; Fihn, J.; Fanini, B.; Hollander, H.; Niccolucci, F.; et al. ARIADNE: A research infrastructure for archaeology. J. Comput. Cult. Herit. 2017, 10, 18. [Google Scholar] [CrossRef]
- Fanini, B.; Pescarin, S.; Palombini, A. A cloud-based architecture for processing and dissemination of 3D landscapes online. Digit. Appl. Archaeol. Cult. Herit. 2019, e00100. [Google Scholar] [CrossRef]
- Antal, A.; Bota, E.; Ciongradi, C.; D’Annibale, E.; Demetrescu, E.; Dima, C.; Fanini, B.; Ferdani, D. A complete workflow from the data collection on the field to the deployment of a Virtual Museum: The case of Virtual Sarmizegetusa. Digit. Appl. Archaeol. Cult. Herit. 2016. [Google Scholar] [CrossRef]
- Barsanti, S.G.; Malatesta, S.G.; Lella, F.; Fanini, B.; Sala, F.; Dodero, E.; Petacco, L. The winckelmann300 project: Dissemination of culture with virtual reality at the capitoline museum in rome. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2018, 42. [Google Scholar] [CrossRef]
- Cantelon, M.; Harter, M.; Holowaychuk, T.; Rajlich, N. Node js in Action; Manning Greenwich: Shelter Island, NY, USA, 2014. [Google Scholar]
- Tilkov, S.; Vinoski, S. Node.js: Using JavaScript to build high-performance network programs. IEEE Internet Comput. 2010, 14, 80–83. [Google Scholar] [CrossRef]
- Fanini, B.; d’Annibale, E.; Demetrescu, E.; Ferdani, D.; Pagano, A. Engaging and shared gesture-based interaction for museums the case study of K2R international expo in Rome. In Proceedings of the 2015 Digital Heritage, Granada, Spain, 28 September–2 October 2015; Volume 1, pp. 263–270. [Google Scholar]
- Antonaci, A.; Pagano, A. Technology enhanced visit to museums. A case study: Keys to Rome. In Proceedings of the INTED2015, Madrid, Spain, 2–4 March 2015; pp. 2–4. [Google Scholar]
- Liu, X.; Wang, Y.; Hu, Q.; Yu, D. A scan-line-based data compression approach for point clouds: Lossless and effective. In Proceedings of the 2016 4th International Workshop on Earth Observation and Remote Sensing Applications (EORSA), Guangzhou, China, 4–6 July 2016; pp. 270–274. [Google Scholar]
- Ferdani, D.; Fanini, B.; Piccioli, M.C.; Carboni, F.; Vigliarolo, P. 3D reconstruction and validation of historical background for immersive VR applications and games: The case study of the Forum of Augustus in Rome. J. Cult. Herit. 2020. [Google Scholar] [CrossRef]
- Bozgeyikli, E.; Raij, A.; Katkoori, S.; Dubey, R. Point & teleport locomotion technique for virtual reality. In Proceedings of the 2016 Annual Symposium on Computer-Human Interaction in Play, Austin, TX, USA, 16–19 October 2016; pp. 205–216. [Google Scholar]
- Concannon, B.J.; Esmail, S.; Roduta Roberts, M. Head-Mounted Display Virtual Reality in Post-Secondary Education and Skill Training: A Systematic Review. Frontiers in Education. Frontiers 2019, 4, 80. [Google Scholar]










© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fanini, B.; Cinque, L. Encoding, Exchange and Manipulation of Captured Immersive VR Sessions for Learning Environments: the PRISMIN Framework. Appl. Sci. 2020, 10, 2026. https://doi.org/10.3390/app10062026
Fanini B, Cinque L. Encoding, Exchange and Manipulation of Captured Immersive VR Sessions for Learning Environments: the PRISMIN Framework. Applied Sciences. 2020; 10(6):2026. https://doi.org/10.3390/app10062026
Chicago/Turabian StyleFanini, Bruno, and Luigi Cinque. 2020. "Encoding, Exchange and Manipulation of Captured Immersive VR Sessions for Learning Environments: the PRISMIN Framework" Applied Sciences 10, no. 6: 2026. https://doi.org/10.3390/app10062026
APA StyleFanini, B., & Cinque, L. (2020). Encoding, Exchange and Manipulation of Captured Immersive VR Sessions for Learning Environments: the PRISMIN Framework. Applied Sciences, 10(6), 2026. https://doi.org/10.3390/app10062026