A Novel and Effective Image Super-Resolution Reconstruction Technique via Fast Global and Local Residual Learning Model †


Abstract
Featured Application
Abstract

1. Introduction
2. Related Work
2.1. SRCNN((Super-Resolution Convolutional Neural Network)
2.2. FSRCNN
2.3. DRCN
2.4. DRRN
2.5. GLRL
3. Method
3.1. Feature Extraction
3.2. Shrinking
3.3. Non-Linear Mapping
3.4. Expanding
3.5. Deconvolution
3.6. PReLU
3.7. Loss Function
4. Experiments and Results
4.1. Experimental Details
4.2. Comparison with Other Methods
4.2.1. In Terms of a Reconstruction Effect
4.2.2. In Terms of Runtime
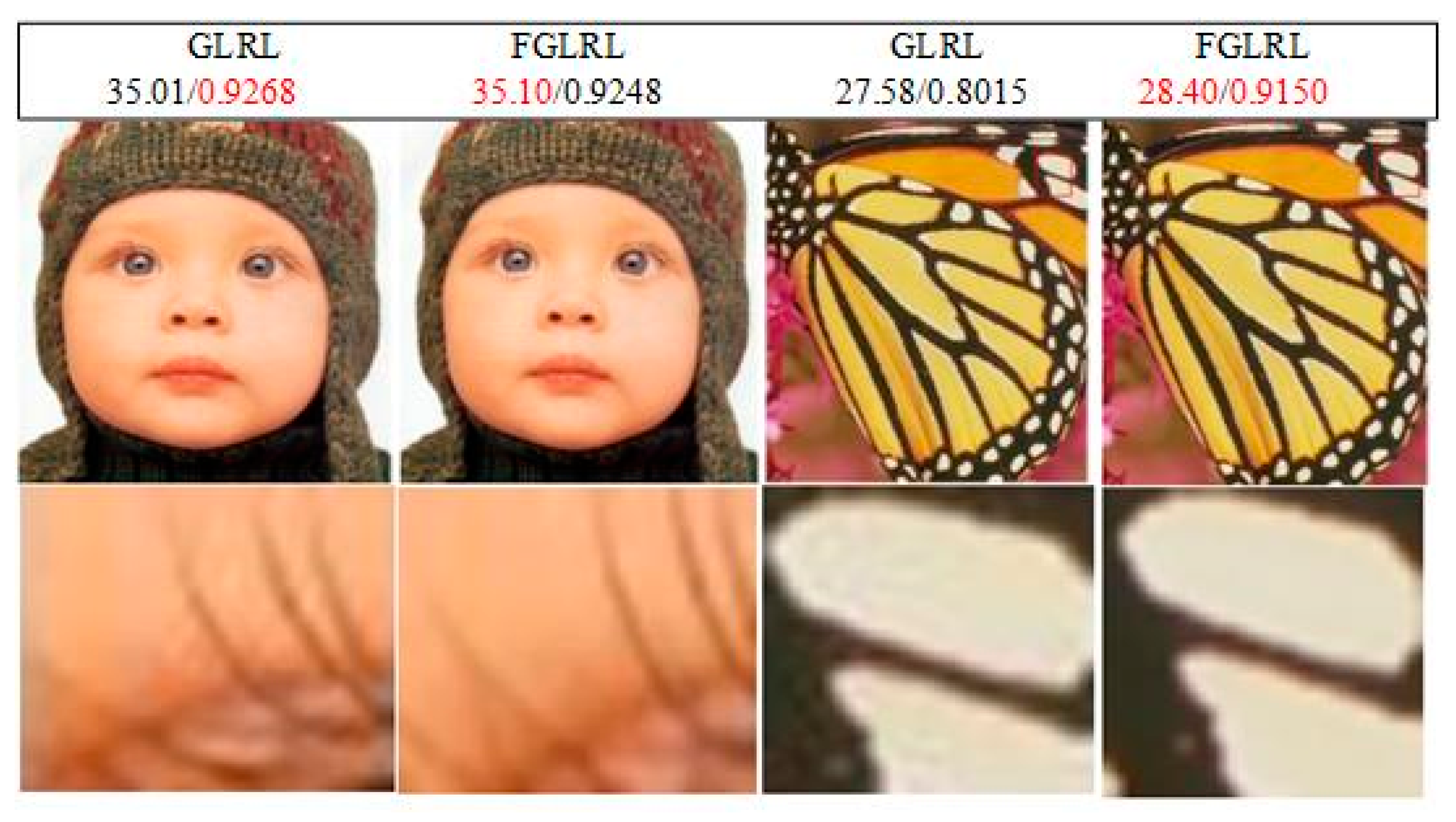
4.3. Discussion of the GLRL and FGLRL
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Thornton, M.W.; Atkinson, P.M.; Holland, D.A. Sub-pixel mapping of rural land cover objects from fine spatial resolution satellite sensor imagery using super-resolution pixel-swapping. Int. J. Remote Sens. 2006, 27, 473–491. [Google Scholar] [CrossRef]
- Shi, W.; Caballero, J.; Ledig, C.; Zhuang, X.; Rueckert, D. Cardiac image super-resolution with global correspondence using multi-atlas patch match. Med. Image Comput. Comput. Assist. Interv. 2013, 16, 9–16. [Google Scholar] [PubMed]
- Temizel, A.L.P.T.E.K.İ.N.; Vlachos, T.H.E.O. Wavelet domain image resolution enhancement. IEEE Proc. Vis. Image Signal Process. 2006, 153, 25–30. [Google Scholar] [CrossRef]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 2599–2613. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Chen, C.L.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the Computer Vision, ECCV 2014—13th European Conference, Zurich, Switzerland, 6–12 September 2014; Volume 8692, pp. 184–199. [Google Scholar]
- Dong, C.; Chen, C.L.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision—14th European Conference, Amsterdam, The Netherlands, 8–16 October 2016; pp. 391–407. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the 2016 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2790–2798. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image Super-Resolution Using Dense Skip Connections. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV) IEEE Computer Society, Venice, Italy, 22–29 October 2017; pp. 4809–4817. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Liu, Q.; Wang, C.; Zhang, Q.; Ying, S.; Xu, H. Super-resolution reconstruction of MR image with a novel residual learning network algorithm. Phys. Med. Biol. 2018, 63, 085011. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hou, J.; Si, Y.; Li, L. Image Super-Resolution Reconstruction Method Based on Global and Local Residual Learning. In Proceedings of the 4th International Conference on Image, Vision and Computing, Xiamen, China, 5–7 July 2019. (Accepted). [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.; Ma, Y. Image super-resolution as sparse representation of raw image patches. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; p. 2378. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low complexity single-image super-resolution based on non-negative neighbor embedding. In Proceedings of the British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012; p. 216. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In International Conference on Curves and Surfaces; Springer: Avignon, France, 24–30 June 2012; pp. 711–730. [Google Scholar]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image superresolution from transformed self-exemplars. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Timofte, R.; De Smet, V.; Van Gool, L. A+: Adjusted anchored neighborhood regression for fast super-resolution. In Asian Conference on Computer Vision; Springer: Singapore, 1–5 November 2014; pp. 111–126. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Scale | Bicubic | Aplus | SRCNN | VDSR | DRCN | FGLRL |
|---|---|---|---|---|---|---|---|
| Set5 | ×2 | 33.66/0.9299 | 36.55/0.9341 | 36.34/0.9542 | 37.53/0.9587 | 37.63/0.9588 | 37.75/0.9633 |
| ×3 | 30.39/0.8682 | 32.59/0.9270 | 32.39/0.9090 | 33.66/0.9213 | 33.82/0.9226 | 32.95/0.9105 | |
| ×4 | 28.42/0.8104 | 30.28/0.8603 | 30.09/0.8628 | 31.35/0.8838 | 31.53/0.8854 | 31.44/0.8846 | |
| Set14 | ×2 | 30.24/0.8688 | 32.28/0.8986 | 32.45/0.9067 | 33.03/0.9124 | 33.04/0.9118 | 33.11/0.9133 |
| ×3 | 27.55/0.7742 | 29.13/0.8311 | 29.00/0.8215 | 29.77/0.8314 | 29.76/0.8311 | 29.51/0.8325 | |
| ×4 | 26.00/0.7027 | 27.33/0.7491 | 27.50/0.7513 | 28.01/0.7674 | 28.02/0.7670 | 28.05/0.7688 | |
| Urban100 | ×2 | 26.88/0.8403 | 28.58/0.8744 | 29.50/0.8946 | 30.76/0.9140 | 30.75/0.9133 | 29.99/0.9102 |
| ×3 | 24.46/0.7349 | 26.11/0.7869 | 26.24/0.7989 | 27.14/0.8279 | 27.15/0.8276 | 27.30/0.8280 | |
| ×4 | 23.14/0.6577 | 24.32/0.7183 | 24.52/0.7221 | 25.18/0.7524 | 25.14/0.7510 | 25.13/0.7501 | |
| BSD100 | ×2 | 29.56/0.8431 | 30.78/0.8766 | 31.36/0.8879 | 31.90/0.8960 | 31.85/0.8942 | 32.30/0.8842 |
| ×3 | 27.21/0.7385 | 28.18/0.7644 | 28.41/0.7863 | 28.82/0.7976 | 28.80/0.7963 | 28.66/0.7870 | |
| ×4 | 25.96/0.6675 | 26.77/0.7087 | 26.90/0.7101 | 27.29/0.7251 | 27.23/0.7233 | 27.26/0.7244 |
| Dataset | Bicubic | Aplus | SRCNN | VDSR | DRCN | FGLRL |
|---|---|---|---|---|---|---|
| Set5 | —— | 0.35 | 0.18 | 0.74 | 0.63 | 0.29 |
| Set14 | —— | 0.69 | 0.39 | 1.35 | 0.98 | 0.23 |
| Urban100 | —— | 0.54 | 0.33 | 0.89 | 0.73 | 0.43 |
| BSD100 | —— | 0.46 | 0.23 | 0.75 | 0.66 | 0.32 |
| Set5 | GLRL | FGLRL |
|---|---|---|
| Baby | 35.01/0.9268/0.79 | 35.10/0.9248/0.40 |
| Bird | 37.09/0.9664/0.68 | 35.66/0.9552/0.27 |
| Butterfly | 27.58/0.8015/0.43 | 28.40/0.9150/0.28 |
| Head | 33.58/0.8340/0.57 | 33.81/0.8283/0.29 |
| Woman | 31.33/0.9428/0.63 | 31.76/0.9290/0.25 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, J.; Si, Y.; Yu, X. A Novel and Effective Image Super-Resolution Reconstruction Technique via Fast Global and Local Residual Learning Model. Appl. Sci. 2020, 10, 1856. https://doi.org/10.3390/app10051856
Hou J, Si Y, Yu X. A Novel and Effective Image Super-Resolution Reconstruction Technique via Fast Global and Local Residual Learning Model. Applied Sciences. 2020; 10(5):1856. https://doi.org/10.3390/app10051856
Chicago/Turabian StyleHou, Jingru, Yujuan Si, and Xiaoqian Yu. 2020. "A Novel and Effective Image Super-Resolution Reconstruction Technique via Fast Global and Local Residual Learning Model" Applied Sciences 10, no. 5: 1856. https://doi.org/10.3390/app10051856
APA StyleHou, J., Si, Y., & Yu, X. (2020). A Novel and Effective Image Super-Resolution Reconstruction Technique via Fast Global and Local Residual Learning Model. Applied Sciences, 10(5), 1856. https://doi.org/10.3390/app10051856