1. Introduction
Brain–computer interfaces (BCI) can provide a direct communication method between the brain and a computer or other external devices [
1,
2,
3]. There are several types of electroencephalograms (EEG) signals used in BCI, such as P300 potential [
4], steady state visual evoked potential (SSVEP) [
5], motor imagery (MI) [
6], and so on. Specifically, P300-based BCI is one of the most common BCI systems, as the P300 potential is easy to be stimulated. Compared with other signals, the P300-based BCI system has some advantages: (1) P300 signal is extremely easy to measure and non-invasive; (2) less training time; (3) suitable for most subjects, including those with severe neurological diseases; and (4) users only need to provide a simple control signal [
7]. It can implement a variety of different functions, and can even be used in the home of people with disability [
7,
8].
Farwell and Donchin of the United States introduced the first P300-based character input system in 1988 [
9,
10], which has been applied until now. The system contained a 6*6 matrix of visual stimulation interface, which was composed of English letters, numbers, and spaces. Before the experiment, the subjects were told that a specified character in the visual stimulator was the target character, and each experiment randomly assigned a character. During the experiment, the subjects were asked to keep an eye on the target character position in the visual stimulator, while any row or column in the visual stimulator flashed randomly. When the target character’s row or column was flashing, a positive potential (called P300 ERP) related to the event could be detected in the subject’s scalp (about 300 ms after receiving the stimulus); if not, the detected EEG data were non-P300 event-related potentials (N-P300 ERP) [
11]. In addition to this standard speller system, there are other paradigms, such as row-column (RC) paradigm [
12], single character (SC) paradigm [
13], region-based(RB) paradigm [
14], and so on. For all these systems, how to identify quickly and accurately is critical to improving the performance of BCI systems.
Due to the collected P300 signals often being high dimensional and feature dependent, some methods were proposed to enhance the feature extraction. PCA (Principal Component Analysis), a principal component analysis method, is widely used in feature extraction and data dimensionality reduction. The principle of PCA is to transform the original signal matrix into a covariance matrix [
15] through linear transformation [
16], and obtain a new signal matrix by filtering the eigenvalues and eigenvectors of the matrix [
17]. The new signal matrix retains some of the most important original signal features in the original signals matrix, and eliminates noise and unimportant features to achieve the purpose of dimensionality reduction. In recent years, many researchers have applied the PCA to reduce the dimensionality of the obtained EEG signals. Salma Tayeb used different dimensionality reduction algorithms to process the EEG signals for the dimensionality reduction part of the data, and found that the use of PCA for dimensionality reduction of P300 signals performed best, compared to independent component analysis (ICA) and linear discriminant analysis (LDA) [
18]. Kundu and Sourav used PCA to reduce the dimensionality of P300 signals, and then used SVM to classify the reduced-dimensional signals. PCA reduced the computational burden of weighted classifiers and speeds up the classification speed [
19]. Like combined multi-scale filters and PCA to classify EEG signals, the classification accuracy can reach 91.13% [
20]. PCA fits in a brain–computer interface, especially the P300 brain–computer interface.
Previous works on P300 classification mainly employed traditional machine learning algorithms, such as support vector machine (SVM), linear discriminant analysis (LDA), and so on. Rakotomamonjy divided P300 EEG signals into several equal parts, and then used SVM to train corresponding classifiers for each part, which improved the accuracy of P300 EEG signals recognition [
21]. Chandra S. Throckmorton proposed a Bayesian P300 recognition method to complete classification by determining the maximum regression target probability value. Although the accuracy of classification was improved, it took too much calculation time [
22]. With the rapid development of deep learning, many scholars began to use convolutional neural network (CNN) to classify P300 EEG signals [
23]. Cecotti realized the use of convolutional neural networks in deep learning to recognize and classify P300 EEG signals. He used convolutional layers to separate the time and space domains of P300 EEG signals. The convolutional neural network is fast but very easy to overfit, which affects the accuracy of recognition [
24]. Lawhern Vernon used compact convolutional neural network (CNN) to classify four types of EEG data including P300 EEG signals, and the results shown that the compact CNN has the best classification effect on P300 EEG signals [
25]. Sobhani proposed to use deep belief network (DBN) to classify P300 EEG signals which were extracted from each channel, but only a few subjects have good recognition accuracy [
26]. Maddula proposed a 3D recurrent convolution neural network (3DRCNN) based on a recurrent convolution neural network (RCNN) to classify P300 EEG signals. It was processed into 3D-EEG signals, and then input them into the RCNN to achieve nice classification [
27]. LIU improved the convolutional neural network on the basis of Cecotti’s algorithm which was named BN3 algorithm, taking the batch normalization (BN) layer and the dropout (DP) layer to deepen the network layers and overcome the problem of overfitting. The BN3 algorithm achieved good results in classification, but still need to improve the recognition accuracy when the number of experiments are reduced [
28].
In this paper, we combined PCA algorithms with new convolution neural network framework to complete the P300 signals classification and recognition (named PCA-CNN). Specifically, the PCA algorithm was used to reduce the dimension of the EEG signal, which not only reduced the calculation time, but also improved the signal-to-noise ratio of the data. The new convolution neural network framework improved single convolution kernel model of traditional convolutional neural network. It contacted multiple convolution kernels to classify P300 EEG signals in the convolution layer, which improved the recognition ability of the convolutional neural network. Two datasets (competition data and self-collected data) were used to verify the effectiveness of the algorithm. The results indicated that the proposed algorithm had a significant effect on the recognition accuracy of P300 EEG signals.
2. Method
2.1. The Dataset
Two sets of experimental data were analyzed in this paper. One was the dataset in the BCI Competition III provided by the Wadsworth Research Center NYS Department of Health [
29]. The other was provided by South China University of Technology using a different paradigm. There are two and ten subjects, respectively, in the two datasets. All subjects are healthy persons, who were selected randomly. Specifically, the two subjects (A and B) were chosen from five people in the public BCI Competition III in 2004. The other ten subjects in the dataset II were recruited randomly and participated in the brain–computer interface experiments for the first time, provided by the South China University of Technology.
Dataset I: The graphical user interface (GUI) of the competition was presented in
Figure 1a, which is a 6*6 character matrix. When the experiment began, each of the 12 rows and columns flashed randomly. A flashing lasts 100 ms and the interval between two flashing is 75 ms. A subject was asked to focus on the target character, and silently count the flashing repetitions of the row and column containing the target character. Each row or column repeats 15 times when outputting one character. The dataset was consisted of one training (85 characters) and one test (100 characters) sets for each of the two subjects A and B. All EEG signals were collected by a 64-electrode scalp, which were bandpass filtered from 0.1–60 Hz and digitized at 240 Hz. The information details can be found in the BCI competition webpage.
Dataset II: The second dataset was collected in the laboratory from South China University of Technology using a 4*10 paradigm (see
Figure 1b). Different from the first dataset, each character flashed separately and randomly. A flashing lasts 100 ms and the interval is 30 ms. A subject was asked to focus on the target character, and silently count the flashing repetitions of the target character. Each character in paradigm repeats 10 times when outputting one character. The dataset was consisted of one training (20 characters) and one test (30 characters) set for each of ten subjects. All EEG signals were collected by a 32-electrode scalp, which were bandpass filtered from 0.1–60 Hz and digitized at 250 Hz.
2.2. Data Preprocessing
As the raw EEG signals are weak and mixed with non-EEG signals or background noise, the raw data should preprocess first. In order to remove the influence of these interference information [
30], we used the 8th-order bandpass Butterworth filter [
31] to filter the collected raw data and intercept the potential frequency to 0.1–20 Hz. Then, the number of positive samples should be increased before the next step, in order to prevent the classification problems caused by the imbalance of positive and negative samples. We will increase the number of P300 EEG signals to the number of non-P300 EEG signals; that is, copying P300 EEG signals so that the number of P300 EEG signals is the same as or close to non-P300 signals.
2.3. PCA Algorithm
PCA transforms the original data into a set of linearly independent data vectors in various dimensions through linear transformation, which can be used to extract the main feature components of the data and often be used for dimensionality reduction of high-dimensional data. Therefore, before EEG signals were input into the neural network, we used the PCA algorithm to reduce the signal dimension. After preprocessing of the raw signals, a data matrix X is obtained, of which the abscissa and ordinate are the time and space domains, respectively. We input the matrix X into the PCA algorithm and calculated the covariance matrix (Cov(X)); then, the eigenvalue eigenvectors of the covariance matrix were obtained. We could select a matrix of eigenvectors corresponding to the features with the largest eigenvalues. In this way, the data matrix could be transformed into a new space, and the dimension reduction of the data features could be realized. Through dimensionality reduction using PCA, the size of feature vectors changed from 64*240 and 30*160 to 64*120 and 30*80 (two datasets respectively). The mathematical formula is as follows:
Input the matrix , and reduce the matrix X to K dimensions, .
Find the covariance matrix of matrix X:
Find the eigenvalues and eigenvectors of the covariance matrix CovX:
where
is the eigenvalue of the
X covariance matrix, and
L is the eigenvector of the
X covariance matrix.
Sort the eigenvalues
from large to small, and select the largest k of them. Then, use the corresponding k feature vectors as row vectors to form a feature vector matrix
P and the data are transformed into a new matrix
Y constructed by k feature vectors:
where
Y is the matrix after dimensionality reduction.
2.4. Parallel Convolutional Network
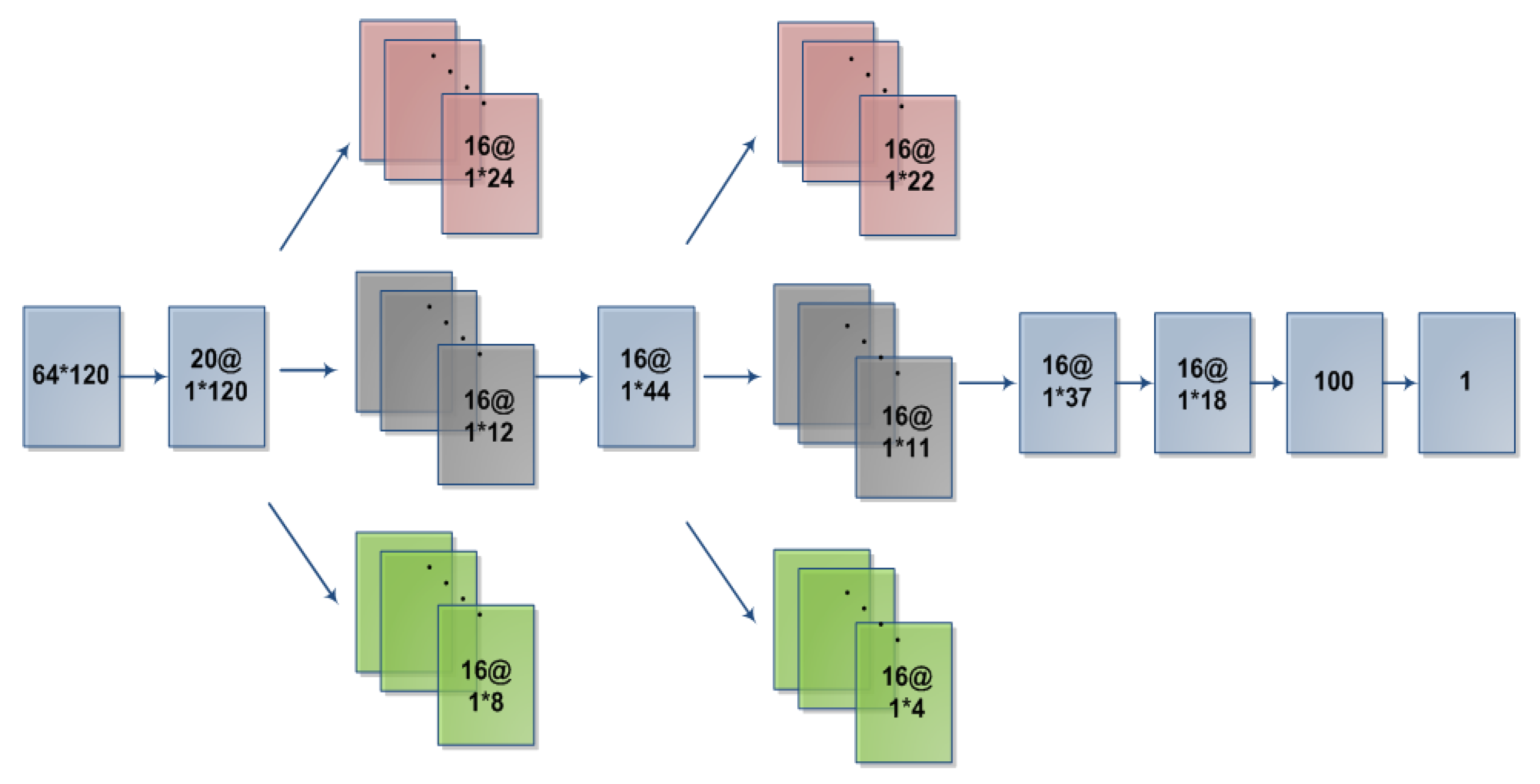
In this paper, we proposed an improved neural network architecture (as shown in
Figure 2). The specific network contained 9 layers, the parameters of which were illustrated in
Table 1 and
Table 2. L1 is the data input layer. L2 is the spatial domain convolution layer. L3 to L6 are the parallel convolution layer [
32,
33] to extract time domain features. L7 is the pooling layer. L8 and L9 are fully connected layer and softmax layer. The computations in each layer (following, as an example,
Table 1 Parameters setting) were described in detail as follows:
L1: The input layer loads the pre-processed EEG data into the network and uses a to represent the data tensor transmitted to the neural network.
L2: Convolution layer, which is a spatial filter for all channels of the input signal, can improve the signal-to-noise ratio [
34], and remove redundant signals in the spatial domain.The formulas are as follows:
where
is output data for L2,
i (
) denotes the Spatial dimension, and
j (
) denotes the time dimension.
denotes the weight,
denotes the deviation (all
, and
(
) denotes the deviation of different values below).
L3 and L4: convolutional layer and dropout layer. This layer is arranged in parallel by three convolutional layers of different convolution sizes. Each convolution and size is the same. Different convolution kernels can be extracted to different values for the same input: information, increasing the complexity of features. After filtering in the time domain after L2 layer spatial filtering, we use 16*5*1, 16*10*1 and 16*15*1 convolution kernels for convolution. After convolution, we can get 16*1*24, 16*1*12 and 16*1*8 feature vectors; these feature vectors are combined into 16*1*44 feature vectors. A dropout layer is added after the convolutional layer to prevent overfitting in the case of too many model parameters [
35]. The formula is as follows:
where
is output data for L3,
s (
) denotes the depth of convolution kernels,
j denotes the time dimension, and
is output data after dropout layer.
r and
p denote the dropout value,
r = 0.5.
L5 and L6: Structures of these two layers are the same as that of L3 and L4. These layers are convolved with 16*2*1, 16*4*1, and 16*11*1 convolution kernels, which can get 16*1*22, 16*1*11, and 16*1*4 feature vectors, and are combined into 16*1*37 feature vectors. A dropout(DP) layer is added after the convolution layer, and the value is 0.5. The calculation formula is as follows:
L7: The pooling layer consists of a pooling filter of size 2, which is used to reduce the parameters of the network.
L8 and L9: Fully connected layer and softmax layer. Data after L7 which are connected with 100 neurons, and then classification by softmax layer. We use rectified linear unit (ReLU) as the activation function [
36].
and
denote the output data after fully connected(FC) layer.
k is the number of feature maps. The calculation formula is as follows:
When the calculated network output probability is greater than or equal to 0.5, the current input signals are determined to be P300 signals, otherwise not. The judgment is as follows:
where
Q represents the judgment result and
P represents the probability value.
The scintillation of 6 rows and 6 columns in the experiment will be repeated 15 times. This is because the position of the target character can not be accurately determined by single experiment scintillation. The probability values corresponding to multiple row scintillation and multiple column scintillation can be accumulated. The target character can be determined by selecting the rows and columns corresponding to the maximum probability values. The formula is as follows:
X denotes the position of column target characters, Y denotes the position of row target characters, n denotes the number of experiments, P denotes the probability value, K denotes the serial number of experiments, and i denotes the row and column numbers.
Dataset II is a random single flicker of 40 characters, from which the location of the maximum probability value can be selected to determine the target character. The formula is as follows:
Z denotes the position of the target character, n denotes the number of experiments, P denotes the probability value, K denotes the serial number of experiments, and i denotes the position number.
2.5. Evaluation
To measure the performance of the algorithms, we used two indices, the accuracy rate and the information translate rate (ITR) [
24,
37] to compare the proposed PCA-CNN with other CNN algorithms in the literature. The accuracy can evaluate the effectiveness of the algorithm. The accuracy rate in the article is the number of correct classified characters classified compared with the number of total actual test characters. The calculation formula is as follows:
where
is the accuracy rate of character recognitions,
P is the number of correct detected characters,
n is the number of repeats, and
S is the number of total characters.
ITR can display the recognition speed of the test characters by the classification algorithm in bits per minute. The formula is as follows:
where
N represents the number of classes,
P represents the accuracy rate of character recognitions, and
T represents the time taken for character recognitions [
24,
28].
In dataset I, as each flash lasts for 100 ms followed by a pause of 75 ms (
) and a pause of 2.5 s between each character epoch,
T can thus be defined as:
where
n is the number of repeats,
.
In dataset II, as each flash lasts for 100 ms followed by a pause of 30 ms (
) and a pause of 1.2 s between each character epoch, so
T can be defined as:
where
n is the number of repeats,
.
3. Experimental Results
In this paper, we used the accuracy rate and ITR to evaluate the P300 signals detection performance on two datasets of different subjects. In dataset I, there are 85 training and 100 test characters for each subject, each of which is repeated 15 times.
Table 3 and
Table 4 present the test accuracy rates of the proposed PCA-CNN and other classification methods in the literature, including CNN algorithms BN3 [
28] and CNN-1 [
24], and a traditional SVM algorithm [
21], on the datasets I of subjects A and B. Bold numbers in the table indicate the best accuracy rate in the
repeats. For both subjects, the proposed PCA-CNN is one of the best algorithms in 15 repeats, and can obtain the accuracy rate higher than 95%. Furthermore, the PCA-CNN is superior to other three methods from 7 repeats for the subject A in the dataset I, and from 8 repeats for the subject B in the dataset I.
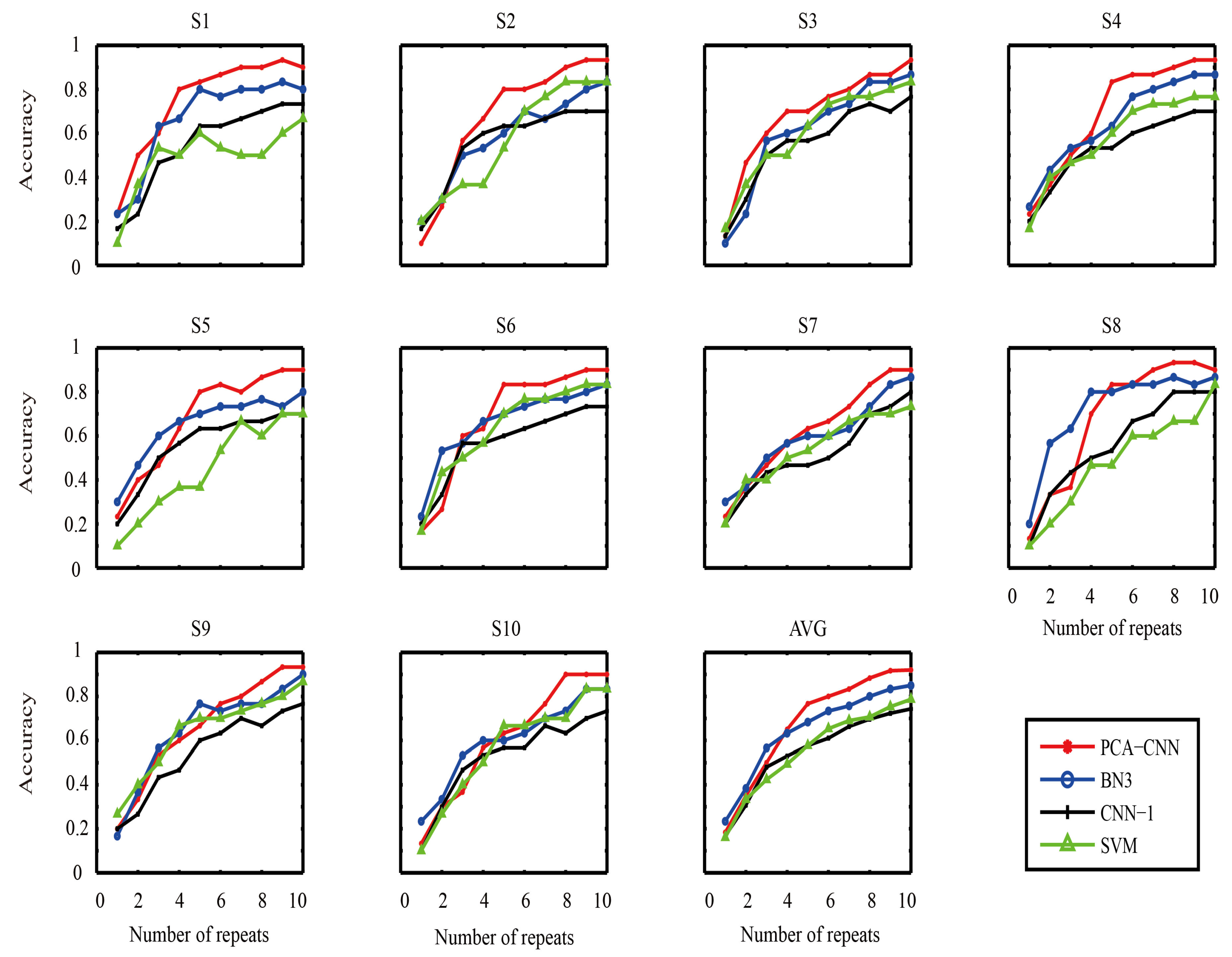
In dataset II, there are 20 training characters and 30 test characters for each subject, each of which is repeated 10 times.
Figure 3 presents the test accuracy rates of the proposed PCA-CNN and other classification methods in the literature, including CNN algorithms BN3 [
28] and CNN-1 [
24], and the traditional SVM algorithm [
21], on datasets II of 10 subjects. The different color line in the figure records the results of all subjects that used different methods on each repeat. For all subjects, the average accuracy rate of PCA-CNN is higher than the other three algorithms in 4th repeats. Furthermore, the average accuracy rate of PCA-CNN is the best algorithm in 10 repeats, and can obtain an average accuracy rate higher than 90%. The experimental results show that the PCA-CNN is superior to others in character recognition.
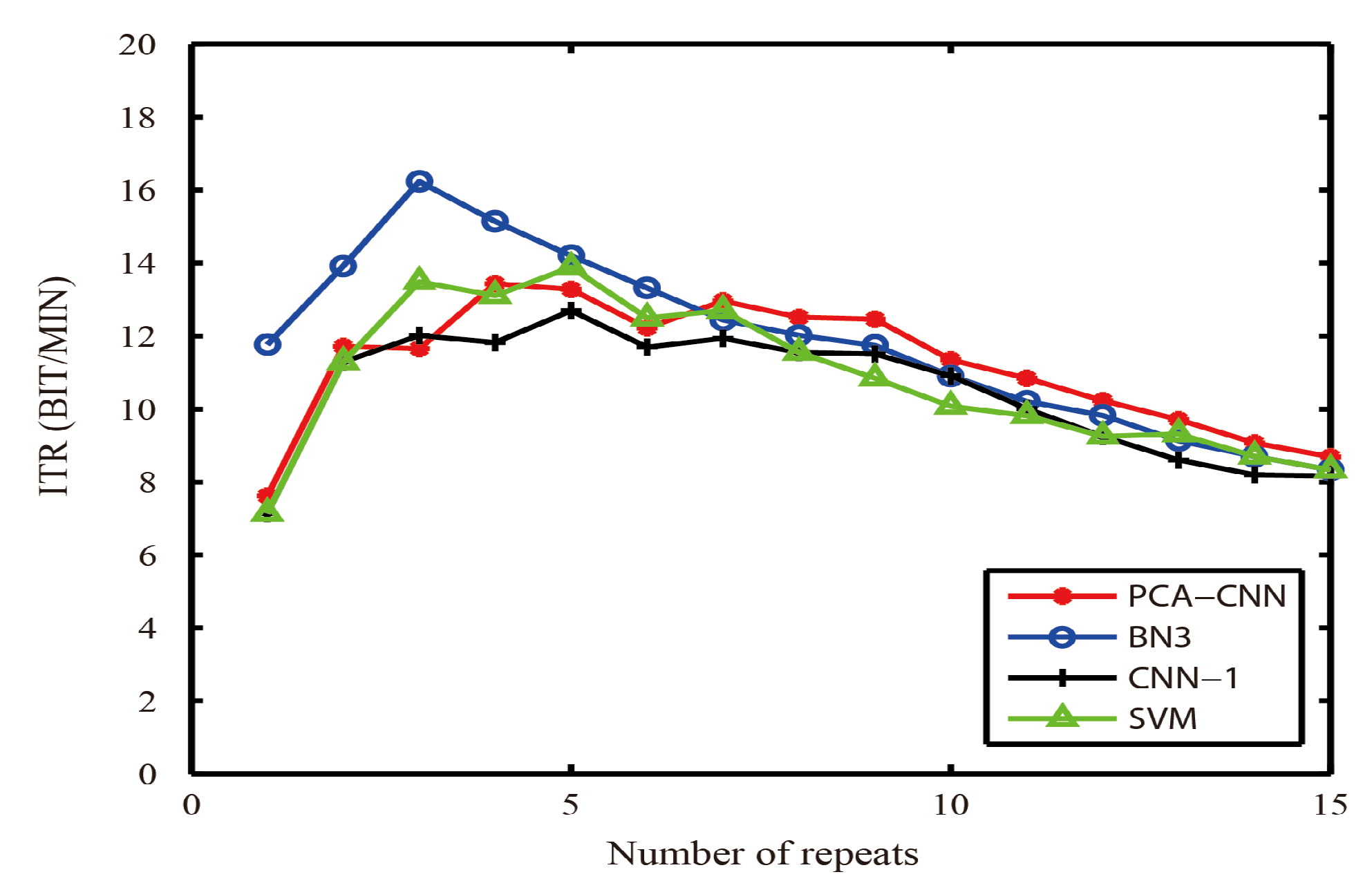
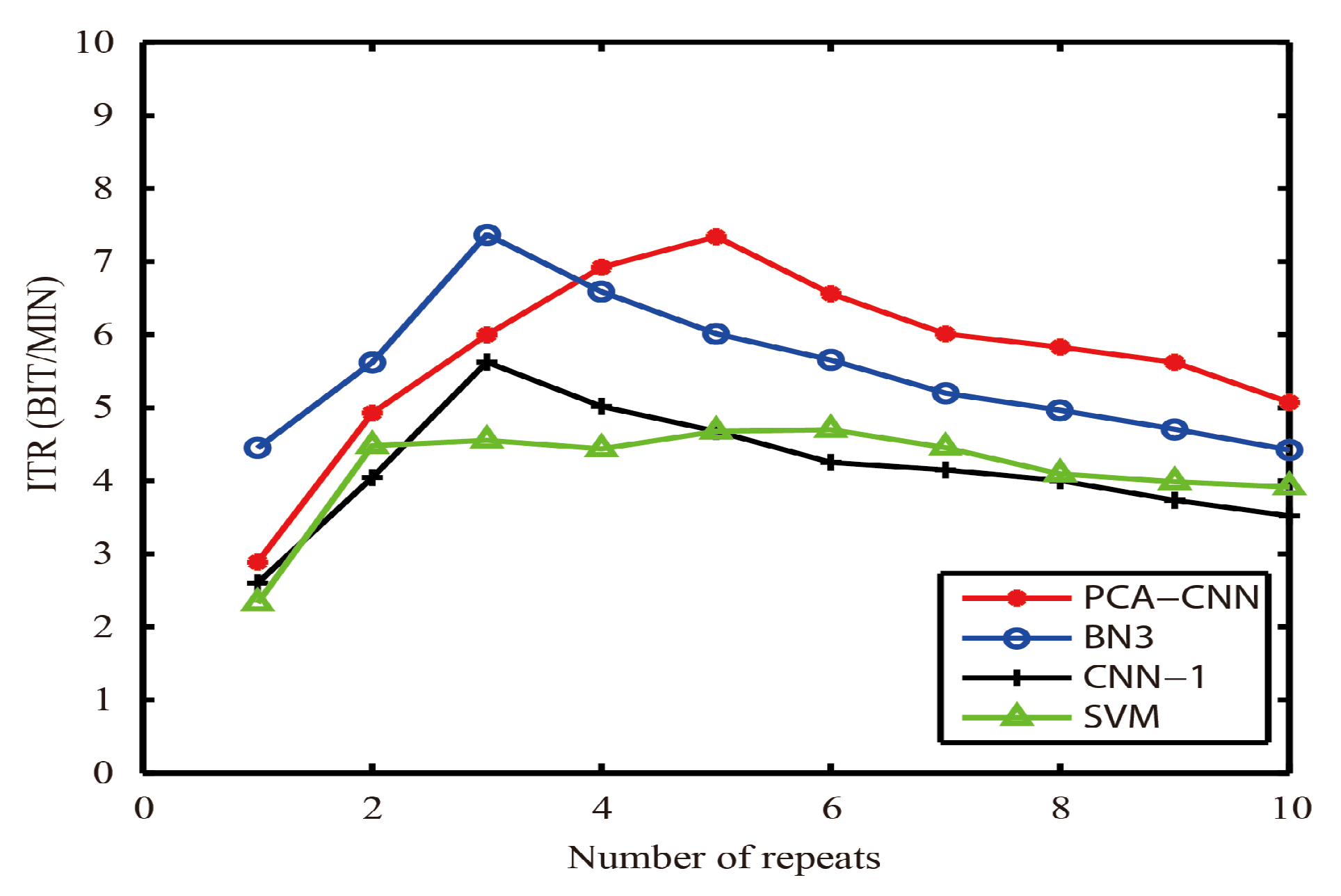
We record the information translate rates of datasets I and II in different algorithms. As shown in
Figure 4 and
Figure 5, the ITR value of the PCA-CNN is higher than that of the other three algorithms (BN3 [
28], CNN-1 [
24], and SVM [
21]) in the maximum repeat. In
Figure 4, after the 7th repeat, the ITR value of PCA-CNN is higher than the other three algorithms (BN3 [
28], CNN-1 [
24] and SVM [
21]). In
Figure 5, after the 4th repeat, the ITR value of PCA-CNN is higher than the other three algorithms (BN3 [
28], CNN-1 [
24] and SVM [
21]). From the overall results of
Figure 4 and
Figure 5, the PCA-CNN is faster than the CNN-1 [
24] and SVM [
21]. These indicate that, on the basis of ensuring the characters recognition accuracy rate, the characters’ recognition speed of PCA-CNN is still fast, and the PCA-CNN algorithm has application value.
4. Discussion
This paper proposed a PCA-CNN algorithm to improve the classification performance of P300-based BCI system. The PCA was used to reduce the P300 EEG signals dimension, as PCA could not only removed the noise and unimportant features of P300 EEG signals, but also improved the speed of EEG data processing. Furthermore, we used the improved convolutional neural network to classify P300 EEG signals and recognition. The experiment results show that, with the same experimental data and the number of experiments, the classification accuracy of the PCA-CNN algorithm is one of the best among algorithms SVM [
21], CNN-1 [
24], and BN3 [
28].
For dataset I and dataset II, the algorithm produced some identical and a few different results. In both datasets, the PCA-CNN has higher accuracy rates of characters recognition than the other three algorithms (BN3 [
28], CNN-1 [
24], and SVM [
21]) with repeat number increases, and can obtain the highest accuracy rate of character recognition in the last repeat. However, in dataset I, the comparison of the classification accuracy results of the algorithm PCA-CNN and the other three algorithms (BN3 [
28], CNN-1 [
24] and SVM [
21]) is not as obvious as that in the dataset II. This difference may be due to the different number of subjects in dataset I and dataset II. There are only two subjects in dataset I. Thus, too small sample size may lead to insignificant differences in the comparison of classification accuracy results. In both dataset I and dataset II, the ITR value of the PCA-CNN is higher than that of the other three algorithms (BN3 [
28], CNN-1 [
24] and SVM [
21]) in most repeats. The difference is that the comparison of the ITR value results of the algorithm PCA-CNN and the other three algorithms (BN3 [
28], CNN-1 [
24] and SVM [
21]) is not obvious in two datasets. One possible reason is related to the difference of classification accuracy in the two datasets. According to the ITR calculation formula, its value is proportional to the classification accuracy. In dataset I, the classification accuracy rate of the PCA-CNN algorithm is not significantly higher than that of other algorithms in data II, at the maximum repeat.
The PCA algorithm was widely used in various fields of research data analysis, especially suitable for analyzing two-dimensional data matrix [
38]. Researchers found that PCA could well express the basic features of the original data with less data [
39]. Therefore, P300 EEG signals still retain the integrity of original EEG signals after PCA dimensionality reduction. Although the convolutional neural network can also directly extract features by itself, we find that the classification accuracy rates are higher after using PCA. As shown in
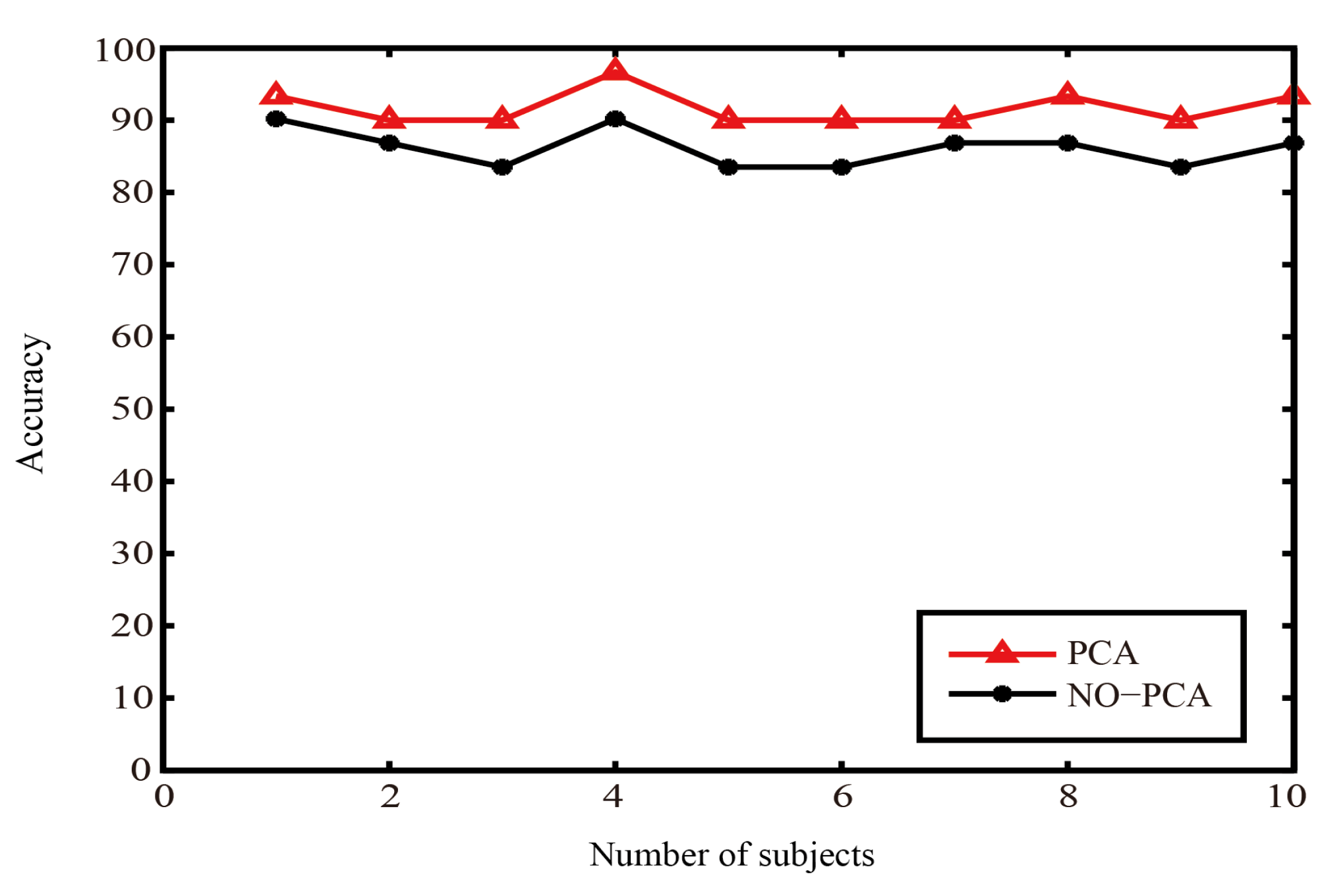
Table 5, when the PCA algorithm is not added in the classification process, the accuracy of classification is lower than the accuracy of adding the PCA algorithm.The average recognition accuracy rates (subject A and subject B in the dataset I) of the PCA-CNN algorithm is 97%, while the average accuracy of recognize characters without the PCA algorithm is 94%. The former is 3% higher than the accuracy in the latter category. In
Figure 6, the average accuracy rate (ten subjects in the dataset II) of recognized characters related to the CNN algorithm which added the PCA algorithm is 90%, while the average accuracy of recognize characters without the PCA algorithm is 80%. The former is 10% higher than the accuracy in the latter category. These may be caused by the overfitting problem when the convolutional neural network processes a large amount of data, which affects the experimental performance. Adding the PCA algorithm in the convolutional neural network may solve this problem that has been proven by some literature [
40,
41].
In order to obtain a classifier with better classification ability, we improved the convolutional layer of the traditional convolutional neural network to a parallel convolution layer [
42]. The parallel convolution layer adds multiple convolution kernels of different sizes to filter out the P300 EEG signal features. The number of convolution kernels determines the output of the convolution layer, so the convolution layer needs to appropriately increase the number of convolution kernels in order to more fully extract the features of signals [
43]. In the previous works on the convolution neural network, such as CNN-1 [
24] and BN3 [
28], a single convolution kernel layer was used in the convolution part. However, when the number of signals is too large, the effect of a single convolution kernel layer in filtering features will become worse, and it is easy to ignore some features. The parallel convolution layer could increase the data capacity of the network, and may overcome the lack of features caused by improper selection of the convolution kernel size [
44].
Based on the traditional convolution neural network, this paper constructed the algorithm PCA-CNN, a new algorithm for the P300 EEG signals classification. Compared with some traditional convolutional neural algorithms, the PCA-CNN algorithm has a higher classification accuracy rate for the P300 EEG signals’ recognition. As shown in
Table 3 and
Table 4, and
Figure 3, the results show that the PCA-CNN algorithm has good classification performance in datasets I and II. As shown in
Figure 4 and
Figure 5, the ITR of PCA-CNN is higher than the traditional SVM classification algorithm, which proves the stability of the algorithm performance. The PCA-CNN algorithm can obtain the classification accuracy rate higher than 90% on both datasets I and II; when the classification accuracy rate of P300 EEG signals is higher than 80%, the classification algorithm is effective [
45]. The proposed PCA-CNN algorithm can be employed in a brain–computer interface system, and be applied for people with disability in daily lives.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}