Adaptive Graph Convolution Using Heat Kernel for Attributed Graph Clustering

Abstract
Featured Application
Abstract
1. Introduction
- We replace the weak linear low-pass filter in standard AGC [7] by heat kernel to enhance the low-pass characteristics of the graph filter.
- We leverage the scaling parameter to restrict the neighborhood of the center node, which is flexible to exploit distant-distance nodes while excluding some irrelevant close-distance nodes.
- We choose the Davies–Bouldin index (DBI) as the criterion to evaluate the cluster quality, which can exactly determine the order of adaptive graph convolution.
- Experimental results show that AGCHK is obviously superior to other compared methods in the task of attribute graph clustering on benchmark datasets such as Cora, Citeseer, Pubmed, and Wiki.
2. Preliminary
2.1. Problem Formalization
2.1.1. Graph Definition
2.1.2. Goal
2.2. Graph Convolution
3. Clustering via Adaptive Graph Convolution Using Heat Kernel
3.1. Motivation
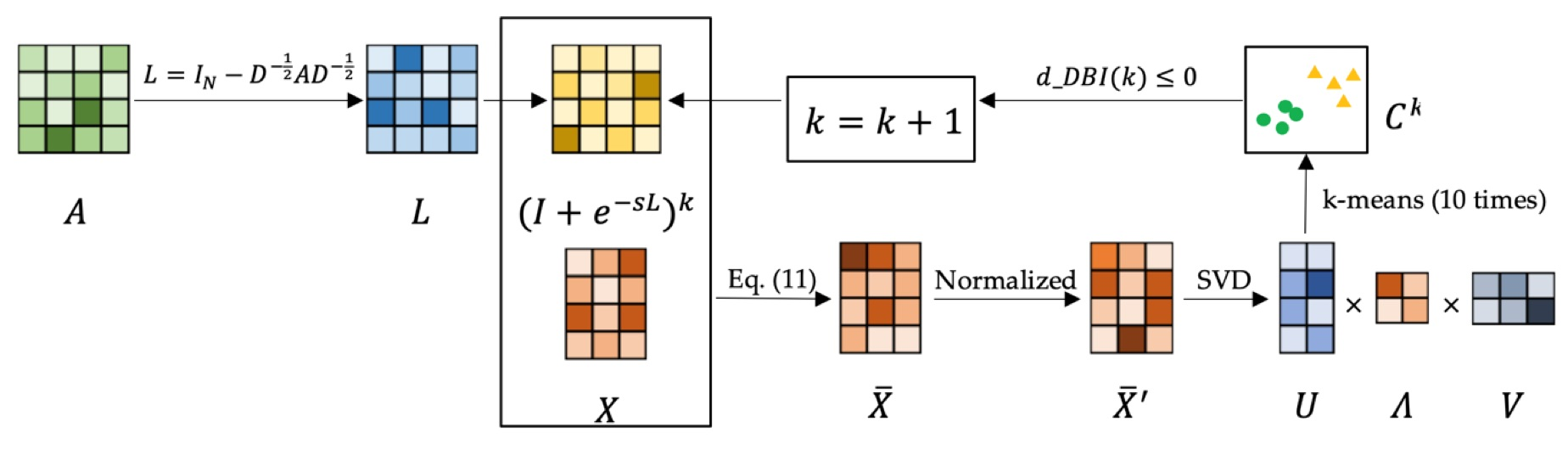
3.2. Adaptive Graph Convolution Using Heat Kernel
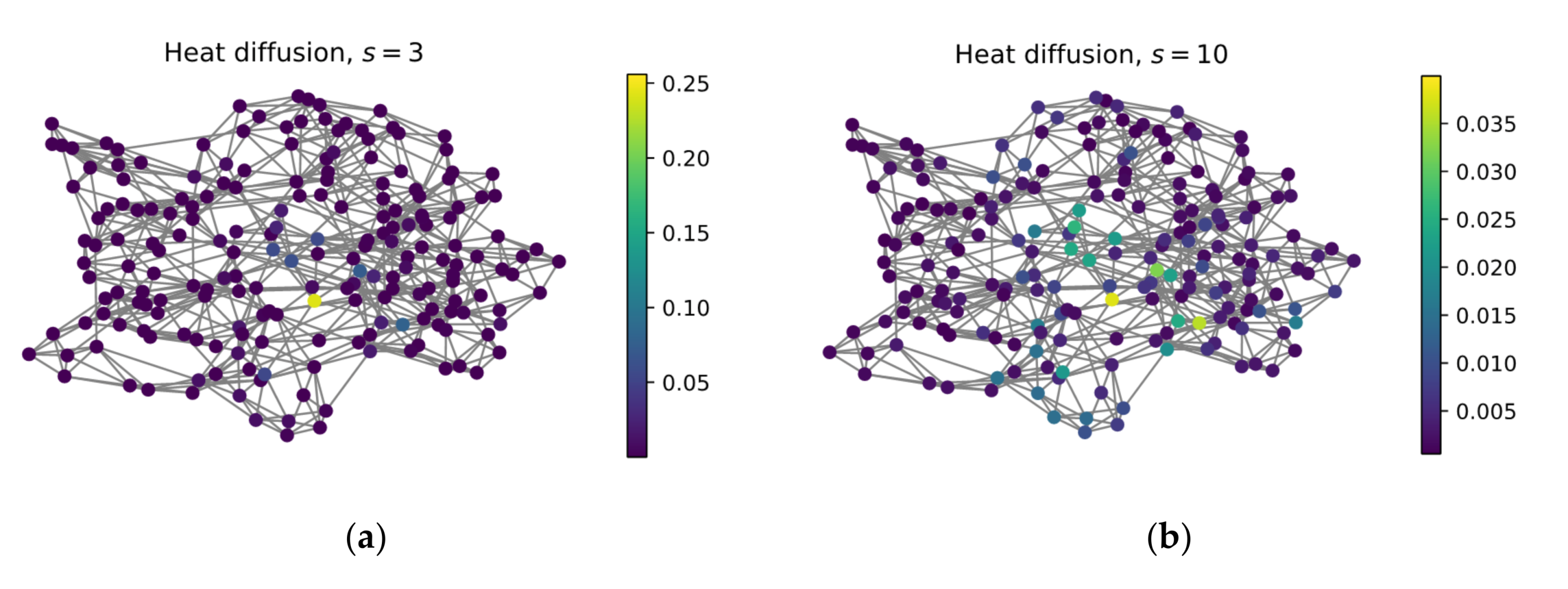
3.2.1. Graph Convolution Using Heat Kernel
3.2.2. K-Order Adaptive Graph Convolution
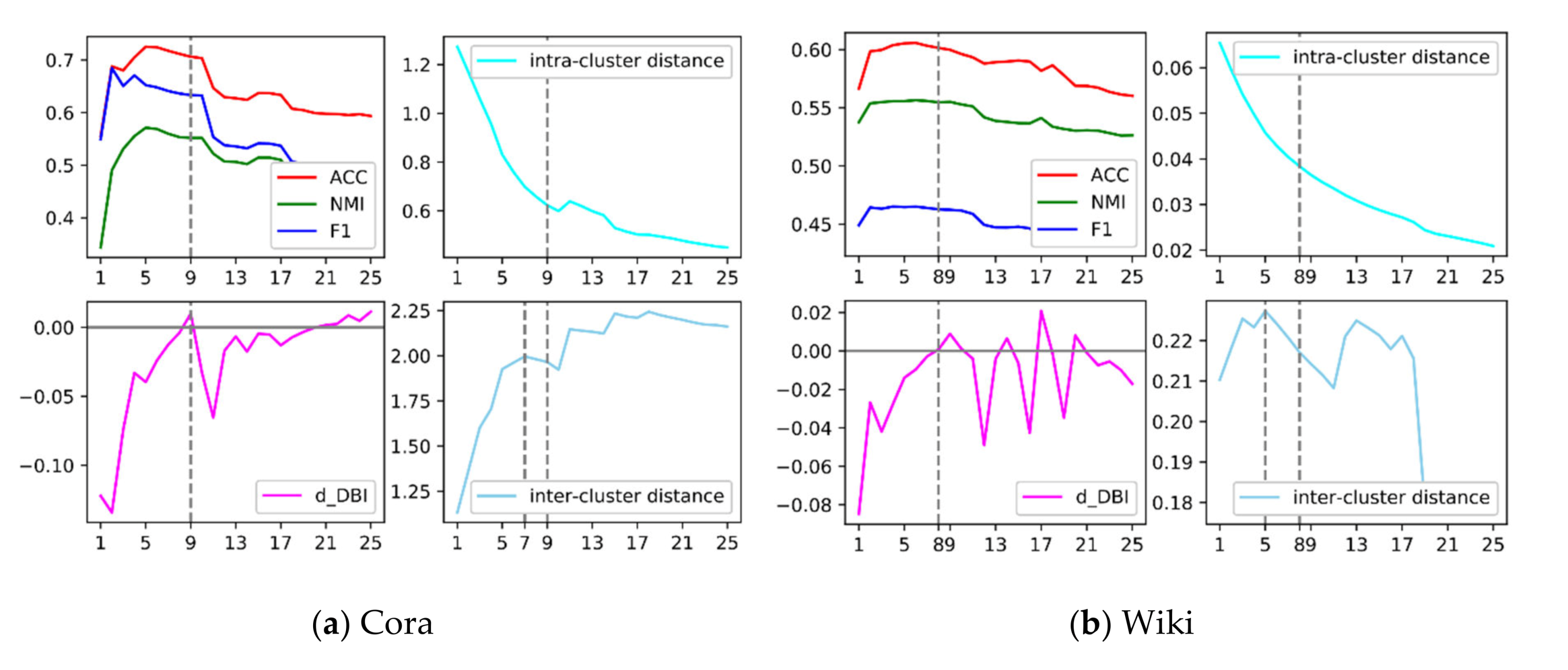
3.2.3. Cluster Evaluation Index
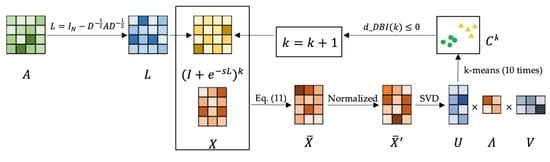
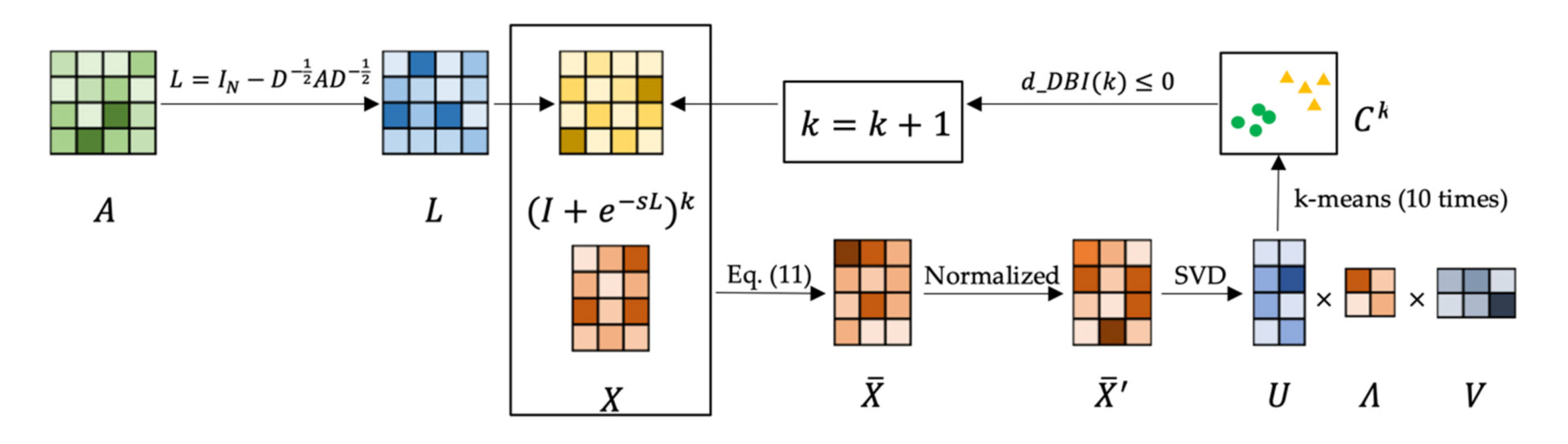
3.2.4. Architecture and Algorithm
| Algorithm 1 AGCHK |
| Input: Node features , adjacency matrix , and maximum iteration number . Output: Cluster partition .
|
3.3. Algorithm Time Complexity
4. Experiments
4.1. Datasets
4.2. Baselines and Evaluation Metrics
- Methods that only exploit node features: classic spectral clustering methods such as -means and spectral-f, which perform clustering on the similarity matrix constructed by node features directly.
- Attributed graph clustering methods utilize graph structures and graph node features jointly: AGC [7], which does not need to train graph neural network parameters, Graph neural network methods based on autoencoder such as graph autoencoder (GAE) and graph variational autoencoder (VGAE) [4], marginalized graph autoencoder (MGAE) [5], adversarially regularized graph autoencoder (ARGE), and variational graph autoencoder (ARVGE) [6].
4.3. Parameter Settings
4.4. Result Analysis
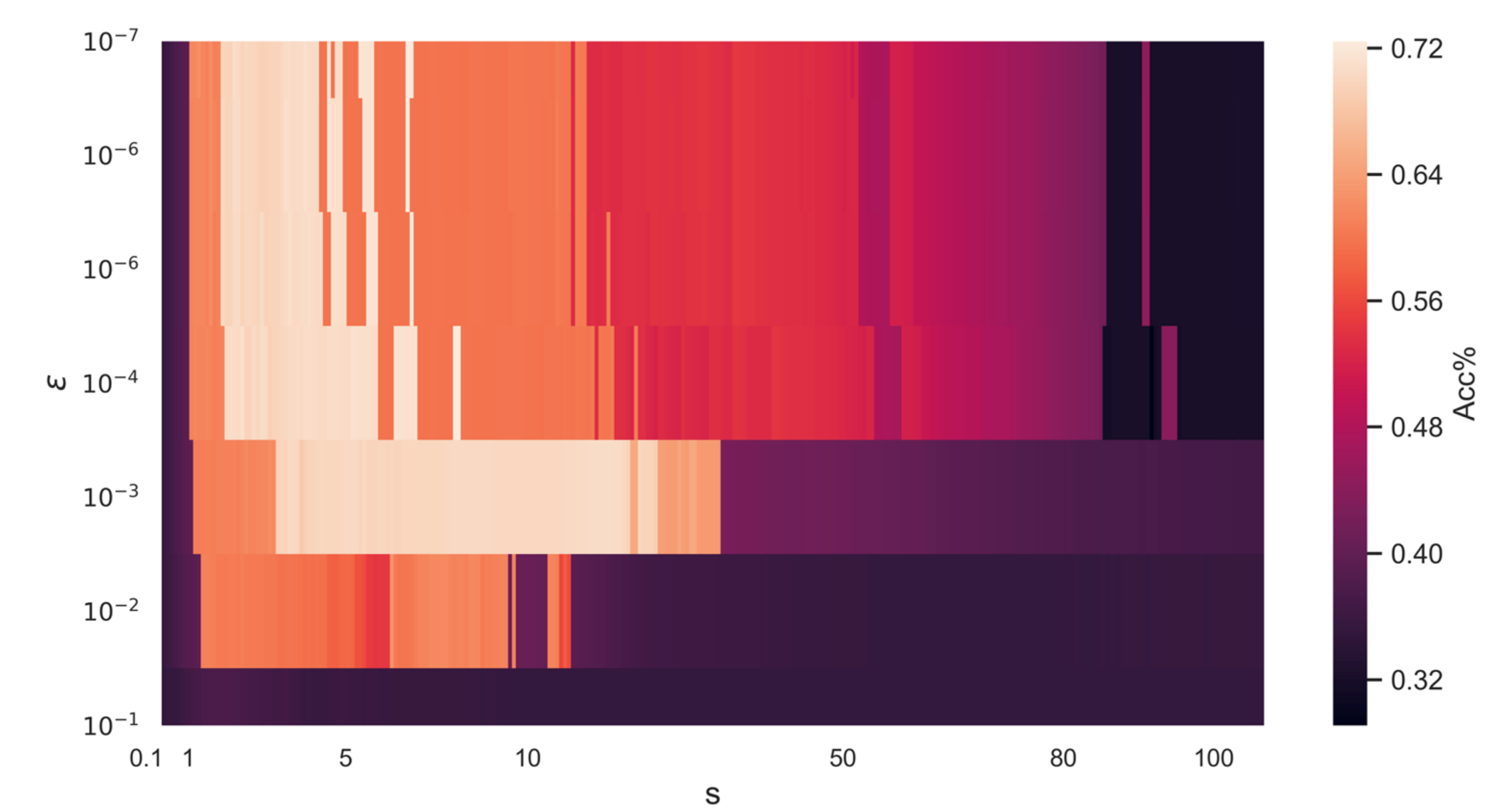
4.5. Influence of Hyper-Parameters and
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Newman, M. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E 2006, 74, 036104. [Google Scholar] [CrossRef] [PubMed]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational graph auto-encoders. In Proceedings of the NIPS Workshop on Bayesian Deep Learning, Barcelona, Spain, 10 December 2016. [Google Scholar]
- Wang, C.; Pan, S.; Long, G.; Zhu, X.; Jiang, J. Mgae: Marginalized graph autoencoder for graph clustering. In Proceedings of the 2017 ACM Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 889–898. [Google Scholar]
- Pan, S.; Hu, R.; Long, G.; Jiang, J.; Yao, L.; Zhang, C. Adversarially regularized graph autoencoder for graph embedding. In Proceedings of the Twenty-Seventh International Joint Conferences on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 2609–2615. [Google Scholar]
- Zhang, X.; Liu, H.; Li, Q.; Wu, X.-M. Attributed graph clustering via adaptive graph convolution. In Proceedings of the International Joint Conferences on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 4327–4333. [Google Scholar]
- Shuman, D.I.; Narang, S.K.; Frossard, P.; Ortega, A.; Vandergheynst, P. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Process. Mag. 2013, 30, 83–98. [Google Scholar] [CrossRef]
- Bruna, J.; Zaremba, W.; Szlam, A.; Lecun, Y. Spectral networks and locally connected networks on graphs. In Proceedings of the 2nd International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Defferrard, M.; Perraudin, N.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 3837–3845. [Google Scholar]
- Chung, F.R.; Graham, F.C. Spectral Graph Theory; American Mathematical Society: Providence, RI, USA, 1997. [Google Scholar]
- Li, Q.; Wu, X.; Liu, H.; Zhang, X.; Guan, Z. Label efficient semi-supervised learning via graph filtering. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9582–9591. [Google Scholar]
- Xu, B.; Shen, H.; Cao, Q.; Cen, K.; Cheng, X. Graph convolutional networks using heat kernel for semi-supervised learning. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1928–1934. [Google Scholar]
- Perraudin, N.; Paratte, J.; Shuman, D.; Martin, L.; Kalofolias, V.; Vandergheynst, P.; Hammond, D.K. Gspbox: A toolbox for signal processing on graphs. arXiv 2014, arXiv:1408.5781. [Google Scholar]
- Nikolentzos, G.; Meladianos, P.; Vazirgiannis, M. Matching node embeddings for graph similarity. In Proceedings of the Thirty-First Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 2429–2435. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 224–227. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Liu, Z.; Zhao, D.; Sun, M.; Chang, E.Y. Network representation learning with rich text information. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2111–2117. [Google Scholar]
- Cao, S.; Lu, W.; Xu, Q. Deep neural networks for learning graph representations. In Proceedings of the Thirtieth Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1145–1152. [Google Scholar]
- Aggarwal, C.C.; Reddy, C.K. Data Clustering: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
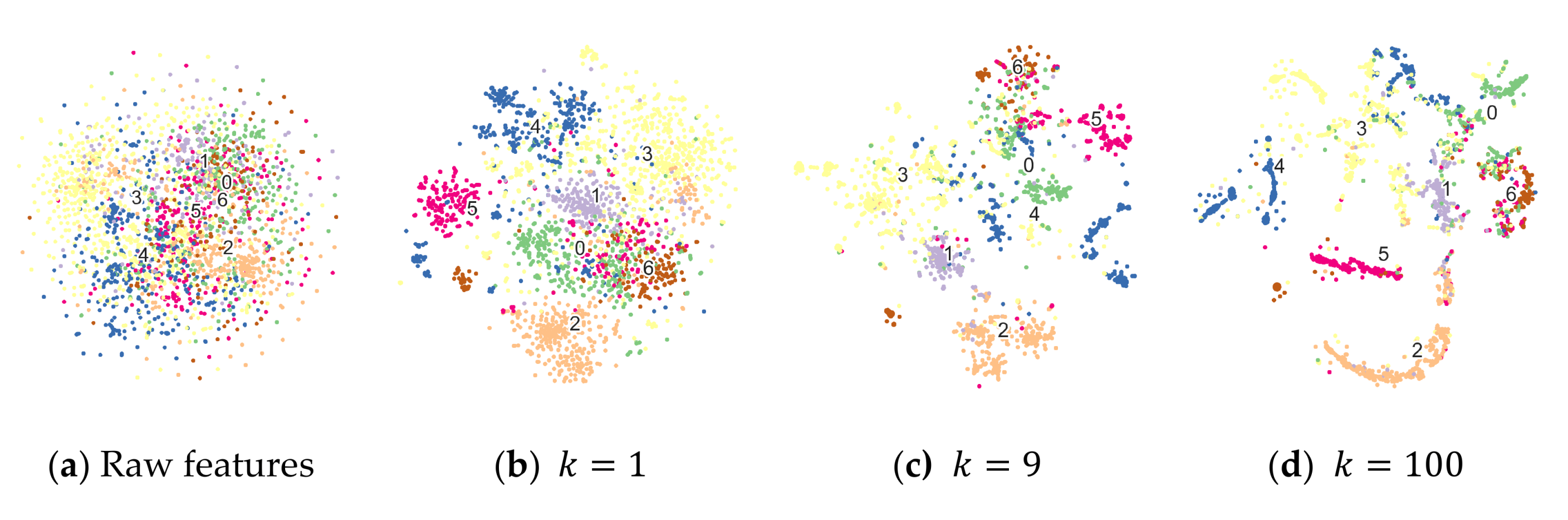{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Nodes | Edges | Features | Classes |
|---|---|---|---|---|
| Cora | 2708 | 5429 | 1433 | 7 |
| Citeseer | 3327 | 4732 | 3703 | 6 |
| Pubmed | 19,717 | 44,338 | 500 | 3 |
| Wiki | 2405 | 17,981 | 4973 | 17 |
| Methods | Input | Cora | Citeseer | Pubmed | Wiki | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc% | NMI% | F1% | Acc% | NMI% | F1% | Acc% | NMI% | F1% | Acc% | NMI% | F1% | ||
| -means | Feature | 34.65 | 16.73 | 25.42 | 38.49 | 17.02 | 30.47 | 57.32 | 29.12 | 57.35 | 33.37 | 30.20 | 24.51 |
| Spectral-f | Feature | 36.26 | 15.09 | 25.64 | 46.23 | 21.19 | 33.70 | 59.91 | 32.55 | 58.61 | 41.28 | 43.99 | 25.20 |
| Spectral-g | Graph | 34.19 | 19.49 | 30.17 | 25.91 | 11.84 | 29.48 | 39.74 | 3.46 | 51.97 | 23.58 | 19.28 | 17.21 |
| Deepwalk | Graph | 46.74 | 31.75 | 38.06 | 36.15 | 9.66 | 26.70 | 61.86 | 16.71 | 47.06 | 38.46 | 32.38 | 25.38 |
| DNGR | Graph | 49.24 | 37.29 | 37.29 | 32.59 | 18.02 | 44.19 | 45.35 | 15.38 | 17.90 | 37.58 | 35.85 | 25.38 |
| GAE | Both | 53.25 | 40.69 | 41.97 | 41.26 | 18.34 | 29.13 | 64.08 | 22.97 | 49.26 | 17.33 | 11.93 | 15.35 |
| VGAE | Both | 55.95 | 38.45 | 41.50 | 44.38 | 22.71 | 31.88 | 65.48 | 25.09 | 50.95 | 28.67 | 30.28 | 20.49 |
| MGAE | Both | 63.43 | 45.57 | 38.01 | 63.56 | 39.75 | 39.49 | 43.88 | 8.16 | 41.98 | 50.14 | 47.97 | 39.20 |
| ARGE | Both | 64.00 | 44.90 | 61.90 | 57.30 | 35.00 | 54.60 | 59.12 | 23.17 | 58.41 | 41.40 | 39.50 | 38.27 |
| ARVGE | Both | 63.80 | 45.00 | 62.70 | 54.40 | 26.10 | 52.90 | 58.22 | 20.62 | 23.04 | 41.55 | 40.01 | 37.80 |
| AGC | Both | 68.92 | 53.68 | 65.61 | 67.00 | 41.13 | 62.48 | 69.78 | 31.59 | 68.72 | 47.65 | 45.28 | 40.36 |
| AGCHK | Both | 70.560.18 | 55.44 | 67.09 | 68.35 | 42.25 | 63.89 | 70.82 | 32.40 | 69.95 | 60.13 | 55.47 | 46.27 |
| Methods | Cora | Citeseer | Pubmed | Wiki |
|---|---|---|---|---|
| GAE | 38.72 s | 57.95 s | 2265.55 s | - |
| VGAE | 41.66 s | 61.34 s | 2433.76 s | - |
| ARGE | 48.49 s | 68.59 s | 2021.94 s | - |
| ARVGE | 43.16 s | 62.33 s | 1850.21 s | - |
| AGC | 17.46 s | 111.04 s | 151.71 s | 22.09 s |
| AGCHK | 8.23 s | 22.92 s | 854.55 s | 23.64 s |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, D.; Chen, S.; Ma, X.; Du, R. Adaptive Graph Convolution Using Heat Kernel for Attributed Graph Clustering. Appl. Sci. 2020, 10, 1473. https://doi.org/10.3390/app10041473
Zhu D, Chen S, Ma X, Du R. Adaptive Graph Convolution Using Heat Kernel for Attributed Graph Clustering. Applied Sciences. 2020; 10(4):1473. https://doi.org/10.3390/app10041473
Chicago/Turabian StyleZhu, Danyang, Shudong Chen, Xiuhui Ma, and Rong Du. 2020. "Adaptive Graph Convolution Using Heat Kernel for Attributed Graph Clustering" Applied Sciences 10, no. 4: 1473. https://doi.org/10.3390/app10041473
APA StyleZhu, D., Chen, S., Ma, X., & Du, R. (2020). Adaptive Graph Convolution Using Heat Kernel for Attributed Graph Clustering. Applied Sciences, 10(4), 1473. https://doi.org/10.3390/app10041473