Data Sampling Methods to Deal With the Big Data Multi-Class Imbalance Problem


 ,
,
Abstract
1. Introduction
2. Deep Learning Multi-Layer Perceptron
3. Sampling Class Imbalance Approaches
3.1. Over-Sampling Methods
3.2. Under-Sampling Methods
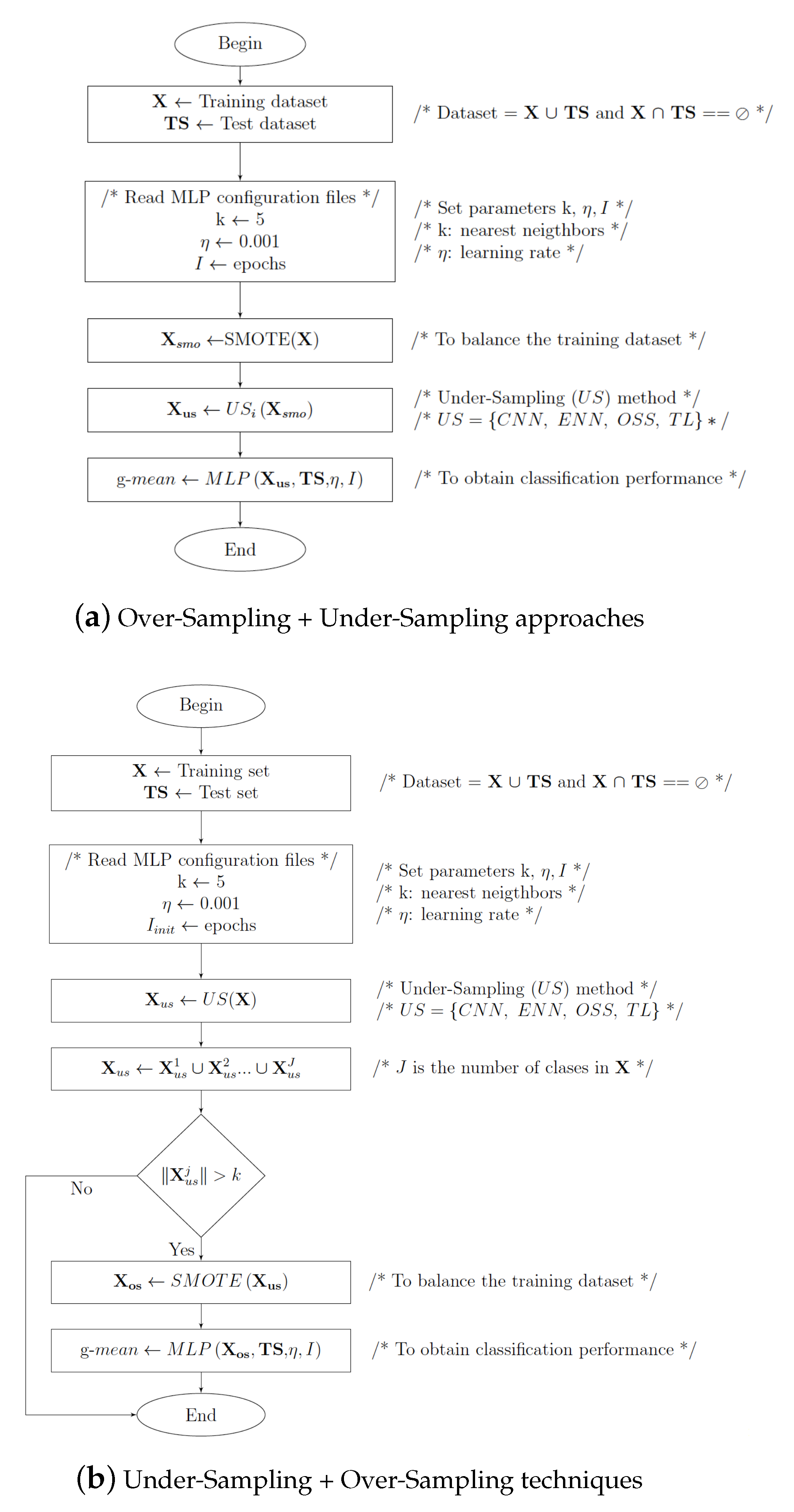
3.3. Hybrid Sampling Class Imbalance Strategies
3.4. SMOTE+ENN*
| Algorithm 1: SMOTE+ENN* |
| Input: Training dataset X; Test dataset TS; // X ∩TS , i.e., they are a disjunts sets. Output: g-mean values;
|
4. Experimental Set-Up
4.1. Database Description
4.2. Parameter Specification for the Algorithms Used in the Experimentation
4.3. Classifier Performance and Tests of Statistical Significance
5. Experimental Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Basgall, M.J.; Hasperué, W.; Naiouf, M.; Fernández, A.; Herrera, F. An Analysis of Local and Global Solutions to Address Big Data Imbalanced Classification: A Case Study with SMOTE Preprocessing. In Cloud Computing and Big Data; Naiouf, M., Chichizola, F., Rucci, E., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 75–85. [Google Scholar]
- Fernández, A.; del Río, S.; Chawla, N.V.; Herrera, F. An insight into imbalanced Big Data classification: Outcomes and challenges. Complex Intell. Syst. 2017, 3, 105–120. [Google Scholar] [CrossRef]
- Elshawi, R.; Sakr, S.; Talia, D.; Trunfio, P. Big Data Systems Meet Machine Learning Challenges: Towards Big Data Science as a Service. Big Data Res. 2018, 14, 1–11. [Google Scholar] [CrossRef]
- Oussous, A.; Benjelloun, F.Z.; Lahcen, A.A.; Belfkih, S. Big Data technologies: A survey. J. King Saud Univ. Comput. Inf. Sci. 2018, 30, 431–448. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Reyes-Nava, A.; Sánchez, J.; Alejo, R.; Flores-Fuentes, A.; Rendón-Lara, E. Performance Analysis of Deep Neural Networks for Classification of Gene-Expression microarrays. In Proceedings of the Pattern Recognition—10th Mexican Conference, MCPR 2018, Puebla, Mexico, 27–30 June 2018; Volume 10880, pp. 105–115. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache Spark: A Unified Engine for Big Data Processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-scale Machine Learning. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, OSDI’16, USENIX Association, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.H.; Hayat, M.; Bennamoun, M.; Sohel, F.A.; Togneri, R. Cost-Sensitive Learning of Deep Feature Representations From Imbalanced Data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3573–3587. [Google Scholar] [PubMed]
- Yang, K.; Yu, Z.; Wen, X.; Cao, W.; Chen, C.L.P.; Wong, H.; You, J. Hybrid Classifier Ensemble for Imbalanced Data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Wong, M.L.; Seng, K.; Wong, P.K. Cost-sensitive ensemble of stacked denoising autoencoders for class imbalance problems in business domain. Expert Syst. Appl. 2020, 141, 112918. [Google Scholar] [CrossRef]
- Błaszczyński, J.; Stefanowski, J. Local Data Characteristics in Learning Classifiers from Imbalanced Data. In Advances in Data Analysis with Computational Intelligence Methods: Dedicated to Professor Jacek Żurada; Springer International Publishing: Cham, Switzerland, 2018; pp. 51–85. [Google Scholar] [CrossRef]
- Leevy, J.L.; Khoshgoftaar, T.M.; Bauder, R.A.; Seliya, N. A survey on addressing high-class imbalance in big data. J. Big Data 2018, 5, 42. [Google Scholar] [CrossRef]
- González-Barcenas, V.M.; Rendón, E.; Alejo, R.; Granda-Gutiérrez, E.E.; Valdovinos, R.M. Addressing the Big Data Multi-class Imbalance Problem with Oversampling and Deep Learning Neural Networks. In Pattern Recognition and Image Analysis; Morales, A., Fierrez, J., Sánchez, J.S., Ribeiro, B., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 216–224. [Google Scholar]
- Kubat, M.; Matwin, S. Addressing the curse of imbalanced training sets: One-sided selection. In Proceedings of the 14th International Conference on Machine Learning, Nashville, TN, USA, 8–12 July 1997; Morgan Kaufmann: Burlington, MA, USA, 1997; pp. 179–186. [Google Scholar]
- Yıldırım, P. Pattern Classification with Imbalanced and Multiclass Data for the Prediction of Albendazole Adverse Event Outcomes. Procedia Comput. Sci. 2016, 83, 1013–1018. [Google Scholar] [CrossRef][Green Version]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Prati, R.C.; Batista, G.E.; Monard, M.C. Data mining with imbalanced class distributions: Concepts and methods. In Proceedings of the 4th Indian International Conference on Artificial Intelligence, IICAI 2009, Tumkur, India, 16–18 December 2009; pp. 359–376. [Google Scholar]
- Vuttipittayamongkol, P.; Elyan, E. Neighbourhood-based undersampling approach for handling imbalanced and overlapped data. Inf. Sci. 2020, 509, 47–70. [Google Scholar] [CrossRef]
- Fernandez, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for Learning from Imbalanced Data: Progress and Challenges, Marking the 15-year Anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- García, V.; Sánchez, J.; Marqués, A.; Florencia, R.; Rivera, G. Understanding the apparent superiority of over-sampling through an analysis of local information for class-imbalanced data. Expert Syst. Appl. 2019, 113026, in press. [Google Scholar] [CrossRef]
- Tomek, I. Two Modifications of CNN. IEEE Trans. Syst. Man Cybern. 1976, 7, 679–772. [Google Scholar]
- Wilson, D. Asymptotic properties of nearest neighbor rules using edited data. IEEE Trans. Syst. Man Cybern. 1972, 2, 408–420. [Google Scholar] [CrossRef]
- Hart, P. The Condensed Nearest Neighbour Rule. IEEE Trans. Inf. Theory 1968, 14, 515–516. [Google Scholar] [CrossRef]
- He, H.; Garcia, E. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- López, V.; Fernández, A.; García, S.; Palade, V.; Herrera, F. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Inf. Sci. 2013, 250, 113–141. [Google Scholar] [CrossRef]
- Nanni, L.; Fantozzi, C.; Lazzarini, N. Coupling Different Methods for Overcoming the Class Imbalance Problem. Neurocomputing 2015, 158, 48–61. [Google Scholar] [CrossRef]
- Abdi, L.; Hashemi, S. To Combat Multi-class Imbalanced Problems by Means of Over-sampling Techniques. IEEE Trans. Knowl. Data Eng. 2016, 28, 1041–4347. [Google Scholar] [CrossRef]
- Devi, D.; kr. Biswas, S.; Purkayastha, B. Redundancy-driven modified Tomek-link based undersampling: A solution to class imbalance. Pattern Recognit. Lett. 2017, 93, 3–12. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Liu, X.Y. Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Trans. Knowl. Data Eng. 2006, 18, 63–77. [Google Scholar] [CrossRef]
- Shon, H.S.; Batbaatar, E.; Kim, K.O.; Cha, E.J.; Kim, K.A. Classification of Kidney Cancer Data Using Cost-Sensitive Hybrid Deep Learning Approach. Symmetry 2020, 12, 154. [Google Scholar] [CrossRef]
- Chris, D.; Robert C., H. C4.5, Class Imbalance, and Cost Sensitivity: Why Under-sampling beats Over-sampling. In Workshop on Learning from Imbalanced Datasets II; Citeseer: Washington, DC, USA, 2003; pp. 1–8. [Google Scholar]
- Kukar, M.; Kononenko, I. Cost-Sensitive Learning with Neural Networks. In Proceedings of the 13th European Conference on Artificial Intelligence (ECAI-98), Brighton, UK, 23–28 August 1998; pp. 445–449. [Google Scholar]
- Wang, S.; Yao, X. Multiclass Imbalance Problems: Analysis and Potential Solutions. IEEE Trans. Syst. Man Cybern. Part B 2012, 42, 1119–1130. [Google Scholar] [CrossRef]
- Galar, M.; Fernández, A.; Tartas, E.B.; Sola, H.B.; Herrera, F. A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches. IEEE Trans. Syst. Man Cybern. Part C 2012, 42, 463–484. [Google Scholar] [CrossRef]
- He, H.; Ma, Y. Imbalanced Learning: Foundations, Algorithms, and Applications, 1st ed.; Wiley-IEEE Press: Hoboken, NJ, USA, 2013. [Google Scholar]
- Parvin, H.; Minaei-Bidgoli, B.; Alinejad-Rokny, H. A New Imbalanced Learning and Dictions Tree Method for Breast Cancer Diagnosis. J. Bionanosci. 2013, 7, 673–678. [Google Scholar] [CrossRef]
- Sun, T.; Jiao, L.; Feng, J.; Liu, F.; Zhang, X. Imbalanced Hyperspectral Image Classification Based on Maximum Margin. IEEE Geosci. Remote Sens. Lett. 2015, 12, 522–526. [Google Scholar] [CrossRef]
- Pandey, S.K.; Mishra, R.B.; Tripathi, A.K. BPDET: An effective software bug prediction model using deep representation and ensemble learning techniques. Expert Syst. Appl. 2020, 144, 113085. [Google Scholar] [CrossRef]
- García-Gil, D.; Holmberg, J.; García, S.; Xiong, N.; Herrera, F. Smart Data based Ensemble for Imbalanced Big Data Classification. arXiv 2020, arXiv:2001.05759. [Google Scholar]
- Li, Q.; Song, Y.; Zhang, J.; Sheng, V.S. Multiclass imbalanced learning with one-versus-one decomposition and spectral clustering. Expert Syst. Appl. 2020, 147, 113152. [Google Scholar] [CrossRef]
- Tao, X.; Li, Q.; Guo, W.; Ren, C.; He, Q.; Liu, R.; Zou, J. Adaptive weighted over-sampling for imbalanced datasets based on density peaks clustering with heuristic filtering. Inf. Sci. 2020, 519, 43–73. [Google Scholar] [CrossRef]
- Andresini, G.; Appice, A.; Malerba, D. Dealing with Class Imbalance in Android Malware Detection by Cascading Clustering and Classification. In Complex Pattern Mining: New Challenges, Methods and Applications; Appice, A., Ceci, M., Loglisci, C., Manco, G., Masciari, E., Ras, Z.W., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 173–187. [Google Scholar] [CrossRef]
- Reyes-Nava, A.; Cruz-Reyes, H.; Alejo, R.; Rendón-Lara, E.; Flores-Fuentes, A.A.; Granda-Gutiérrez, E.E. Using Deep Learning to Classify Class Imbalanced Gene-Expression Microarrays Datasets. In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications; Vera-Rodriguez, R., Fierrez, J., Morales, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 46–54. [Google Scholar]
- Amin, A.; Anwar, S.; Adnan, A.; Nawaz, M.; Howard, N.; Qadir, J.; Hawalah, A.; Hussain, A. Comparing Oversampling Techniques to Handle the Class Imbalance Problem: A Customer Churn Prediction Case Study. IEEE Access 2016, 4, 7940–7957. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, X.; Guo, D.; Song, M.; Teng, Y.; Wang, X. PCCN: Parallel Cross Convolutional Neural Network for Abnormal Network Traffic Flows Detection in Multi-Class Imbalanced Network Traffic Flows. IEEE Access 2019, 7, 119904–119916. [Google Scholar] [CrossRef]
- Bhowmick, K.; Shah, U.B.; Shah, M.Y.; Parekh, P.A.; Narvekar, M. HECMI: Hybrid Ensemble Technique for Classification of Multiclass Imbalanced Data. In Information Systems Design and Intelligent Applications; Satapathy, S.C., Bhateja, V., Somanah, R., Yang, X.S., Senkerik, R., Eds.; Springer: Singapore, 2019; pp. 109–118. [Google Scholar]
- Shekar, B.H.; Dagnew, G. Classification of Multi-class Microarray Cancer Data Using Ensemble Learning Method. In Data Analytics and Learning; Nagabhushan, P., Guru, D.S., Shekar, B.H., Kumar, Y.H.S., Eds.; Springer: Singapore, 2019; pp. 279–292. [Google Scholar]
- Cao, J.; Lv, G.; Chang, C.; Li, H. A Feature Selection Based Serial SVM Ensemble Classifier. IEEE Access 2019, 7, 144516–144523. [Google Scholar] [CrossRef]
- Li, D.; Huang, F.; Yan, L.; Cao, Z.; Chen, J.; Ye, Z. Landslide Susceptibility Prediction Using Particle-Swarm-Optimized Multilayer Perceptron: Comparisons with Multilayer-Perceptron-Only, BP Neural Network, and Information Value Models. Appl. Sci. 2019, 9, 3664. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks. A Comprehensive Foundation, 2nd ed.; Pretince Hall: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Lecun, Y.; Bottou, L.; Orr, G.B.; Müller, K.R. Efficient BackProp. In Neural Networks—Tricks of the Trade; Orr, G., Müller, K., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1524, pp. 5–50. [Google Scholar]
- Pacheco-Sánchez, J.; Alejo, R.; Cruz-Reyes, H.; Álvarez Ramírez, F. Neural networks to fit potential energy curves from asphaltene-asphaltene interaction data. Fuel 2019, 236, 1117–1127. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar] [CrossRef]
- Alejo, R.; Monroy-de Jesús, J.; Pacheco-Sánchez, J.; López-González, E.; Antonio-Velázquez, J. A Selective Dynamic Sampling Back-Propagation Approach for Handling the Two-Class Imbalance Problem. Appl. Sci. 2016, 6, 200. [Google Scholar] [CrossRef]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Millán-Giraldo, M.; García, V.; Sánchez, J.S. Instance Selection Methods and Resampling Techniques for Dissimilarity Representation with Imbalanced Data Sets. In Pattern Recognition—Applications and Methods; Latorre Carmona, P., Sánchez, J.S., Fred, A.L., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 149–160. [Google Scholar] [CrossRef]
- Mar, N.M.; Thidar, L.K. KNN–Based Overlapping Samples Filter Approach for Classification of Imbalanced Data. In Software Engineering Research, Management and Applications; Springer International Publishing: Cham, Switzerland, 2020; pp. 55–73. [Google Scholar] [CrossRef]
- Marqués, A.; García, V.; Sánchez, J. On the suitability of resampling techniques for the class imbalance problem in credit scoring. J. Oper. Res. Soc. 2013, 64, 1060–1070. [Google Scholar] [CrossRef]
- Duda, R.; Hart, P.; Stork, D. Pattern Classification, 2nd ed.; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Cover, T.; Hart, P. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 2006, 13, 21–27. [Google Scholar] [CrossRef]
- Li, Y.; Ding, L.; Gao, X. On the Decision Boundary of Deep Neural Networks. arXiv 2018, arXiv:1808.05385. [Google Scholar]
- Iman, R.L.; Davenport, J.M. Approximations of the critical region of the friedman statistic. Commun. Stat. Theory Methods 1980, 9, 571–595. [Google Scholar] [CrossRef]
- Triguero, I.; Gonzalez, S.; Moyano, J.; Garcia, S.; Alcala-Fdez, J.; Luengo, J.; Fernandez, A.; del Jesus, M.; Sanchez, L.; Herrera, F. KEEL 3.0: An Open Source Software for Multi-Stage Analysis in Data Mining. Int. J. Comput. Intell. Syst. 2017, 10, 1238–1249. [Google Scholar] [CrossRef]
- Olvera-López, J.A.; Carrasco-Ochoa, J.A.; Martínez-Trinidad, J.F.; Kittler, J. A Review of Instance Selection Methods. Artif. Intell. Rev. 2010, 34, 133–143. [Google Scholar] [CrossRef]


{kind=link}
| Data Set | Classes | Samples | Features | Major | Minor | IR | Distribution |
|---|---|---|---|---|---|---|---|
| Indian | 17 | 21,025 | 220 | 10,776 | 20 | 538.8 | 0:10776; 1:46; 2:1428; 3:830; 4:237; 5:483; 6:730; 7:28; 8:478; 9:20; 10:972; 11:2455; 12::593; 13:205; 14:1265; 15:386; 16:93 |
| Salinas | 17 | 111,104 | 224 | 56,975 | 916 | 62.2 | 0:10776; 1:2009; 2:3726; 3:1976; 4:1394; 5:2678; 6:3959; 7:3579; 8:11271; 9:6203; 10:3278; 11:1068; 12:1927; 13:916; 14:1070; 15:7268; 16:1807 |
| PaviaU | 10 | 207,400 | 103 | 164,624 | 947 | 173.8 | 0:164624; 1:6631; 2:18649; 3:2099; 4:3064; 5:1345; 6:5029; 7:1330; 8::3682; 9:947 |
| Pavia | 10 | 783,640 | 102 | 635,488 | 2685 | 236.7 | 0:635488; 1:65971; 2:7598; 3:3090; 4:2685; 5:6584; 6:9248; 7:7287; 8:42826; 9:2863 |
| Botswana | 15 | 377,856 | 145 | 374,608 | 95 | 3943.2 | 0:374608; 1:270; 2:101; 3:251; 4:215; 5:269; 6:269; 7:259; 8:203; 9:314; 10:248; 11:305; 12:181; 13:268; 14:95 |
| KSC | 14 | 314,368 | 176 | 309,157 | 105 | 2944.4 | 0:309157; 1:761; 2:243; 3:256; 4:252; 5:161; 6:229; 7:105; 8:431; 9:520; 10:404; 11:419; 12:503; 13:927 |
| Name | Layer Int | Layer 1 | Layer 2 | Layer 3 | Layer 4 | Layer 5 | Layer 6 | Layer Output | Epoch | Size of Batch |
|---|---|---|---|---|---|---|---|---|---|---|
| Salinas | 220/Relu | 60/Relu | 60/Relu | 60/Relu | 60/Relu | 60/Relu | 60/Relu | 17/SoftMax | 500 | 1000 |
| Indian | 224/Relu | 60/Relu | 60/Relu | 60/Relu | 60/Relu | – | – | 17/SoftMax | 500 | 100 |
| PaviaU | 103/Relu | 40/Relu | 40/Relu | 40/Relu | 40/Relu | 40/Relu | – | 10/SoftMax | 500 | 1000 |
| Pavia | 102/Relu | 40/Relu | 40/Relu | 40/Relu | 40/Relu | 40/Relu | 40/Relu | 10/SoftMax | 250 | 1000 |
| Botswana | 145/Relu | 30/Relu | 30/Relu | 30/Relu | 30/Relu | 30/Relu | 30/Relu | 15/SoftMax | 250 | 1000 |
| KSC | 176/Relu | 60/Relu | 60/Relu | 60/Relu | 60/Relu | 60/Relu | 60/Relu | 14/SoftMax | 250 | 1000 |
| Method | Indian | Salinas | PaviaU | Pavia | Botswana | KSC | Average Rank | |
|---|---|---|---|---|---|---|---|---|
| Original | 0.8848 | 0.0000 | 0.5369 | 0.0000 | 0.0000 | 0.0000 | 11.1 | |
| Under-sampling | RUS | 0.8834 | 0.4280 | 0.7369 | 0.8460 | 0.4594 | 0.5640 | 9.5 |
| TL | 0.8891 | 0.0000 | 0.5272 | 0.0000 | 0.0000 | 0.0000 | 11.1 | |
| ENN | 0.8728 | 0.0000 | 0.3809 | 0.0000 | 0.0000 | 0.0000 | 11.8 | |
| OSS+SMOTE | N/A | N/A | N/A | N/A | N/A | N/A | N/A | |
| Over-sampling | ROS | 0.9627 | 0.8202 | 0.8723 | 0.8984 | 0.7243 | 0.6752 | 3.7 |
| SMOTE | 0.9603 | 0.8140 | 0.8704 | 0.8892 | 0.7256 | 0.7284 | 4.4 | |
| ADASYN | 0.9603 | 0.8037 | 0.8633 | 0.8892 | 0.7462 | 0.6974 | 5.1 | |
| Hybrid | SMOTE+ENN* | 0.8201 | 0.9542 | 0.8797 | 0.9074 | 0.8139 | 0.7863 | 2.5 |
| SMOTE+ENN | 0.9610 | 0.8138 | 0.8670 | 0.8879 | 0.7346 | 0.7076 | 5.0 | |
| SMOTE+TL | 0.9610 | 0.8068 | 0.8609 | 0.8812 | 0.7410 | 0.7177 | 5.0 | |
| SMOTE+OSS | 0.0000 | 0.0000 | 0.8684 | 0.8888 | 0.7372 | 0.7410 | 6.8 | |
| TL+SMOTE | 0.9604 | 0.7706 | 0.8522 | 0.8747 | 0.6554 | 0.6079 | 7.5 | |
| SMOTE+CNN | 0.0000 | 0.0000 | 0.8417 | 0.0000 | 0.8657 | 0.8200 | 7.7 | |
| ENN+SMOTE | 0.9274 | N/A | 0.6331 | 0.4996 | N/A | N/A | N/A | |
| CNN+SMOTE | N/A | N/A | N/A | N/A | N/A | N/A | N/A | |
| OSS+SMOTE | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rendón, E.; Alejo, R.; Castorena, C.; Isidro-Ortega, F.J.; Granda-Gutiérrez, E.E. Data Sampling Methods to Deal With the Big Data Multi-Class Imbalance Problem. Appl. Sci. 2020, 10, 1276. https://doi.org/10.3390/app10041276
Rendón E, Alejo R, Castorena C, Isidro-Ortega FJ, Granda-Gutiérrez EE. Data Sampling Methods to Deal With the Big Data Multi-Class Imbalance Problem. Applied Sciences. 2020; 10(4):1276. https://doi.org/10.3390/app10041276
Chicago/Turabian StyleRendón, Eréndira, Roberto Alejo, Carlos Castorena, Frank J. Isidro-Ortega, and Everardo E. Granda-Gutiérrez. 2020. "Data Sampling Methods to Deal With the Big Data Multi-Class Imbalance Problem" Applied Sciences 10, no. 4: 1276. https://doi.org/10.3390/app10041276
APA StyleRendón, E., Alejo, R., Castorena, C., Isidro-Ortega, F. J., & Granda-Gutiérrez, E. E. (2020). Data Sampling Methods to Deal With the Big Data Multi-Class Imbalance Problem. Applied Sciences, 10(4), 1276. https://doi.org/10.3390/app10041276