Synthetic Minority Oversampling Technique for Optimizing Classification Tasks in Botnet and Intrusion-Detection-System Datasets

 , , , , , , and
, , , , , , and
Abstract
1. Introduction
- Oversampling: samples from minority classes are duplicated until the amount is compensated with those from majority classes.
- Undersampling: samples belonging to majority classes are downsized at random until compensation with respect to the minority class is reached.
- Hybrid sampling: a superset is created with samples replicated from minority classes up to the same volume of the majority-class samples.
- Information ought to be from crude network flows as a main source of malicious-packet delivery;
- incorporation of a considerable collection of bot-based malware attacks obtained through environments closest to near-real contexts;
- data should cover requirements from operating cycles found in production deployments (working hours); and
- the proportion of more benign traffic packets must outnumber that of malicious ones since, in near-real-time conditions, only a slight portion of packets arise from infected sources.
2. Related Work
- Borderline-SMOTE1: only concentrates on edges of the smaller class; then, it crafts, calculates, and compares new synthetic samples around the distribution of the majority class to reconstruct the overall distribution of class samples.
- K-means SMOTE: identifies the area of the minority class and creates new instances on the basis of a seed pattern over the input space.
- Safe-level SMOTE: builds overall distribution upon a sale level of synthetic samples, using the nearest neighbor of minority instances.
- C-SMOTE: establishes a mean value center from the minority class samples as a basis, combining an interpolation algorithm to create and cluster new synthetic samples.
- CURE-SMOTE: provides synthetic samples by enhancing representative clusters from the original SMOTE distribution.
- SMOTE-TomekLinks: substantial feature examination is performed on most class samples, eliminating those that present an unbalancing factor against minority-class samples.
- SMOTE-ENN: aimed to weigh minority-class samples on the edge by employing Nearest Edited Neighbors (NEN).
- Borderline -SMOTE2: majority-class instances are oversampled, taking as reference their edge and inner-weighting factors.
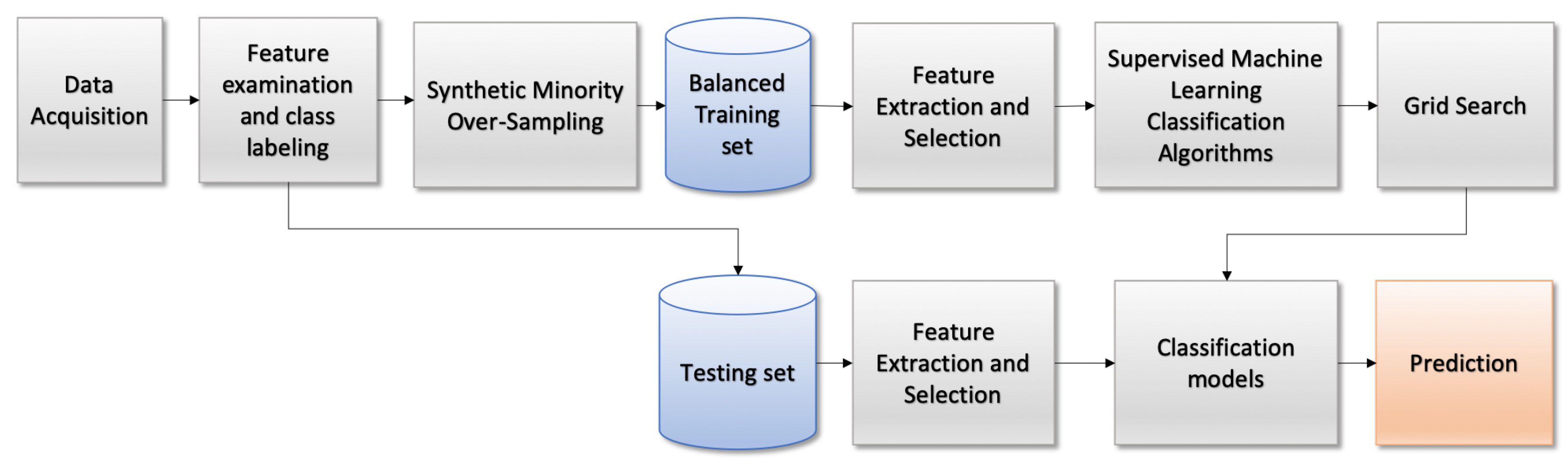
3. Proposed Methodology
3.1. Data Acquisition
- ISCX-Bot-2014: Provided by The Canadian Institute for Cybersecurity in which 16 different types of botnets are reported. These are, Neris, Rbot, Menti, Sogou, Murlo, Virut, NSIS, Zeus, SMTP Spam, UDP Storm, Tbot, Zero Access, Weasel, Smoke Bot, Zeus Control (C and C), and ISCX IRC bot. A total size of 5.3 GB of packet captures is formed by benign and malicious network traffic. As advised, 43.92% of overall network captures were identified as potentially malware-based. ISCX-Bot-2014 was built upon the consolidation of three main collections:
- ISOT dataset [46]: integrates various projects, particularly the Honeynet Project [47], Ericsson Research [48], and Lawrence Berkeley National Laboratory Research [49], each containing malicious traces from well-identified botnets like Flow Storm and Zeus. As for non-malicious connections, sources primarily came from game packages, HTTP traffic, and P2P applications.
- ISCX 2012 IDS Dataset [50]: crafted to be realistic, i.e., to include benign (HTTP, SMTP, SSH, IMAP, POP3, and FTP) and malicious (Botnet ISCX IRC) traffic produced by real devices.
- Malware Capture Facility Project [51]: the design of this dataset aims to generate and capture various traces of botnets, and it incorporates eight different kind of botnets (Neris, Rbot, Virut, NSIS, Menti, Sogou, and Murlo).
- CIDDS-001 - Coburg Intrusion Detection: provided by the University of Coburg in Germany, it was designed to gather real evidence of network intruders on the basis of anomaly-detection records and logs. Data mostly comprise network flows from small-business environments, including several email clients between rogue web-based modules and abnormal responses from multiple attacks, such as ping scanning, port scanning, brute force, and DoS.
3.2. Data Examination and Class Labeling
3.3. Synthetic Minority Oversampling
- CIDDS-001: comprised 248,134 samples, where 50% corresponded to benign and the rest to malicious.
- ISCX-Bot-2014: comprised 133,226 samples, where 50% corresponded to benign and the rest to M malicious,
3.4. Feature Extraction and Selection
3.5. Supervised Machine-Learning Algorithms
- Define supervised classification algorithms to use in a specific context;
- optimize each algorithm by means of hyperparameter tuning;
- evaluate each algorithm in isolation from its performance metrics;
- evaluate each algorithm in parallel in the same environment; and
- compare the performance of each algorithm with those used in the literature.
- K-Nearest-Neighbor (KNN);
- Support Vector Machine (SVM);
- Logistic Regression (LR);
- Decision Trees (DT); and
- Random Forest (RF).
3.6. Grid Search
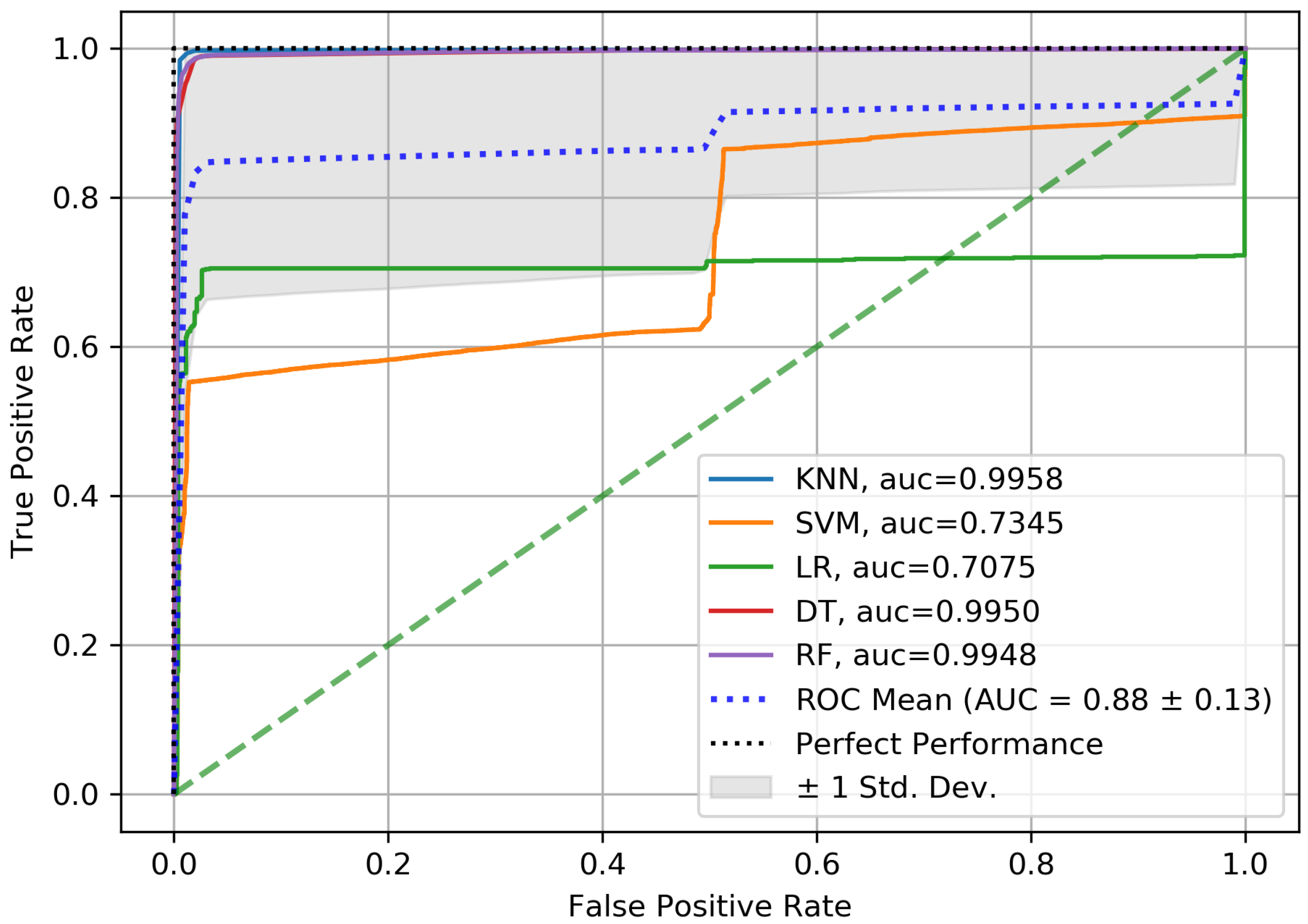
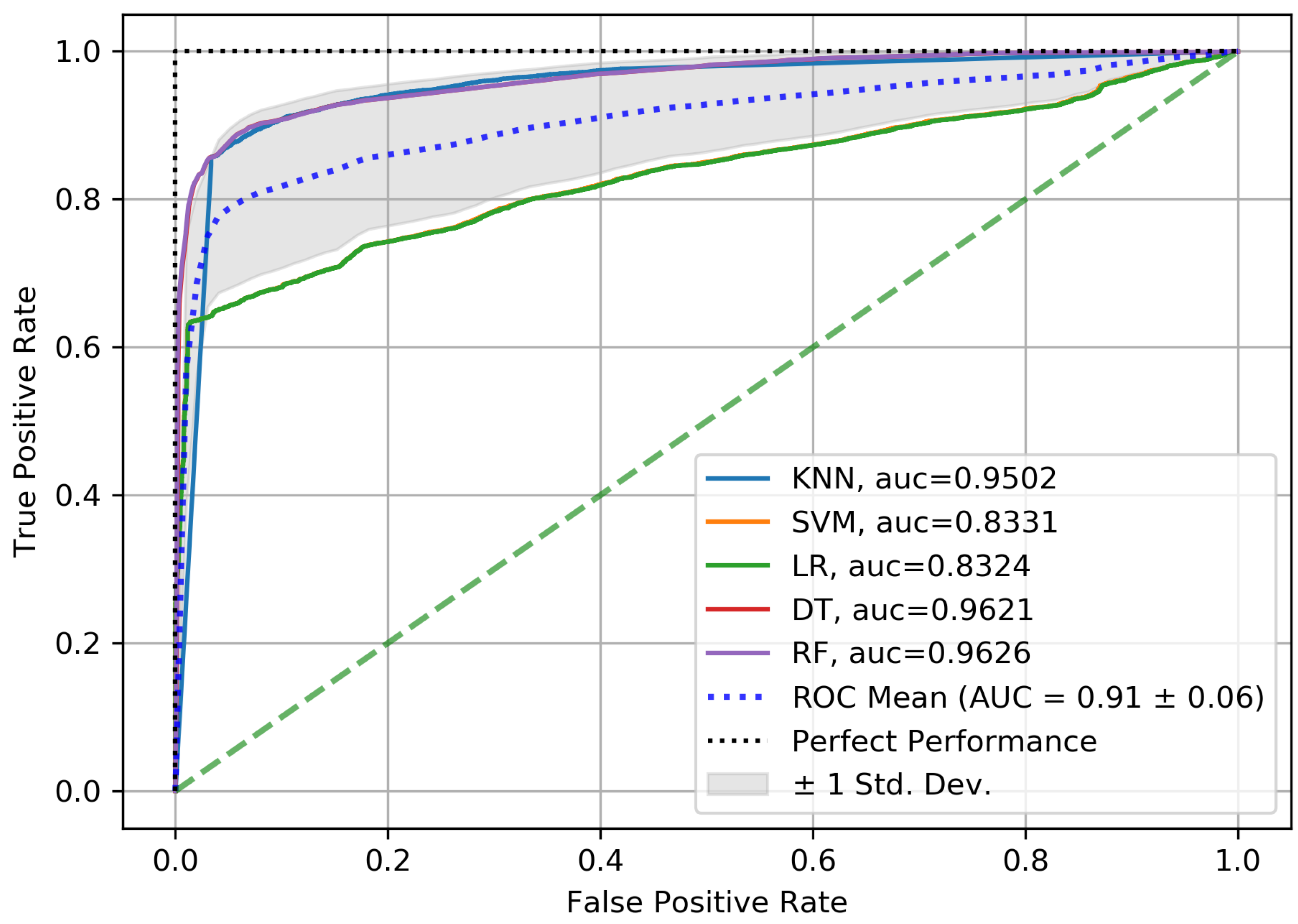
4. Experiment Results
5. Results and Discussion
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Hsu, F.H.; Ou, C.W.; Hwang, Y.L.; Chang, Y.C.; Lin, P.C. Detecting web-based botnets using bot communication traffic features. Secur. Commun. Netw. 2017, 2017, 11. [Google Scholar] [CrossRef]
- Idhammad, M.; Afdel, K.; Belouch, M. Detection system of HTTP DDoS attacks in a cloud environment based on information theoretic entropy and random forest. Secur. Commun. Netw. 2018, 2018, 13. [Google Scholar] [CrossRef]
- Varela-Vaca, Á.J.; Gasca, R.M.; Ceballos, R.; Gómez-López, M.T.; Torres, P.B. CyberSPL: A Framework for the Verification of Cybersecurity Policy Compliance of System Configurations Using Software Product Lines. Appl. Sci. 2019, 9, 5364. [Google Scholar] [CrossRef]
- Sinclair, C.; Pierce, L.; Matzner, S. An application of machine learning to network intrusion detection. In Proceedings of the 15th Annual Computer Security Applications Conference (ACSAC’99), Scottsdale, AZ, USA, 6–10 December 1999; pp. 371–377. [Google Scholar]
- Gupta, M. Handbook of Research on Emerging Developments in Data Privacy; IGI Global: Hershey, PA, USA, 2014; pp. 438–439. [Google Scholar]
- Małowidzki, M.; Berezinski, P.; Mazur, M. Network intrusion detection: Half a kingdom for a good dataset. In Proceedings of the NATO STO SAS-139 Workshop, Portugal, April 2015; Available online: https://pdfs.semanticscholar.org/b39e/0f1568d8668d00e4a8bfe1494b5a32a17e17.pdf (accessed on 16 May 2019).
- Hochschule Coburg. Available online: https://www.hs-coburg.de/fileadmin/hscoburg/WISENT-CIDDS-001.zip/ (accessed on 16 May 2019).
- Canadian Institute for Cybersecurity. Botnet Dataset. Available online: https://www.unb.ca/cic/datasets/botnet.html (accessed on 15 May 2019).
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the internet of things for network forensic analytics: Bot-iot dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, C.; Zheng, K.; Niu, X.; Yang, Y. Fuzzy–synthetic minority oversampling technique: Oversampling based on fuzzy set theory for Android malware detection in imbalanced datasets. Int. J. Distrib. Sens. Netw. 2017, 13. [Google Scholar] [CrossRef]
- Schubach, M.; Re, M.; Robinson, P.N.; Valentini, G. Imbalance-aware machine learning for predicting rare and common disease-associated non-coding variants. Sci. Rep. 2017, 7, 2959. [Google Scholar] [CrossRef]
- Pham, T.S.; Hoang, T.H. Machine learning techniques for web intrusion detection—A comparison. In Proceedings of the 2016 Eighth International Conference on Knowledge and Systems Engineering (KSE), Hanoi, Vietnam, 6–8 October 2016; pp. 291–297. [Google Scholar]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Seo, J.H.; Kim, Y.H. Machine-Learning Approach to Optimize SMOTE Ratio in Class Imbalance Dataset for Intrusion Detection. Comput. Intell. Neurosci. 2018, 2018, 11. [Google Scholar] [CrossRef]
- Ma, L.; Fan, S. CURE-SMOTE algorithm and hybrid algorithm for feature selection and parameter optimization based on random forests. BMC Bioinform. 2017, 18, 169. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Ring, M.; Wunderlich, S.; Grüdl, D.; Landes, D.; Hotho, A. Flow-based benchmark data sets for intrusion detection. In Proceedings of the 16th European Conference on Cyber Warfare and Security (ECCWS), Dublin, Ireland, 29–30 June 2017; pp. 361–369. [Google Scholar]
- Hoang, X.; Nguyen, Q. Botnet detection based on machine learning techniques using DNS query data. Future Internet 2018, 10, 43. [Google Scholar] [CrossRef]
- Conti, M.; Dargahi, T.; Dehghantanha, A. Cyber Threat Intelligence: Challenges and Opportunities; Springer: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Stevanovic, M.; Pedersen, J. MMachine Learning for Identifying Botnet Network Traffic; Technical Report; Networking and Security Section, Department of Electronic Systems, Aalborg University: Aalborg, Denmark, 2013. [Google Scholar]
- Biradar, A.D.; Padmavathi, B. BotHook: A Supervised Machine Learning Approach for Botnet Detection Using DNS Query Data. In Proceedings of the 2019 IEEE International Conference on Computation, Communication and Engineering (ICCCE), Fujian, China, 8–10 November 2019. [Google Scholar]
- Miller, S.; Busby-Earle, C. The role of machine learning in botnet detection. In Proceedings of the 2016 11th International Conference for Internet Technology and Secured Transactions (ICITST), Barcelona, Spain, 5–7 December 2016; pp. 359–364. [Google Scholar]
- Carrasco, A.; Ropero, J.; de Clavijo, P.R.; Benjumea, J.; Luque, A. A Proposal for a New Way of Classifying Network Security Metrics: Study of the Information Collected through a Honeypot. In Proceedings of the 2018 IEEE International Conference on Software Quality, Reliability and Security Companion (QRS-C), Lisbon, Portugal, 16–20 July 2018; pp. 633–634. [Google Scholar]
- Bapat, R.; Mandya, A.; Liu, X.; Abraham, B.; Brown, D.E.; Kang, H.; Veeraraghavan, M. Identifying malicious botnet traffic using logistic regression. In Proceedings of the 2018 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 27 April 2018; pp. 266–271. [Google Scholar]
- Lin, K.C.; Chen, S.Y.; Hung, J.C. Botnet detection using support vector machines with artificial fish swarm algorithm. J. Appl. Math. 2014, 2014, 9. [Google Scholar] [CrossRef]
- Letteri, I.; Del Rosso, M.; Caianiello, P.; Cassioli, D. Performance of Botnet Detection by Neural Networks in Software-Defined Networks. In Proceedings of the Second Italian Conference on Cyber Security (ITASEC), Milan, Italy, 6–9 February 2018. [Google Scholar]
- Bonneton, A.; Migault, D.; Senecal, S.; Kheir, N. Dga bot detection with time series decision trees. In Proceedings of the 2015 4th International Workshop on Building Analysis Datasets and Gathering Experience Returns for Security (BADGERS), Kyoto, Japan, 5 November 2015; pp. 42–53. [Google Scholar]
- Dollah, R.F.M.; Faizal, M.A.; Arif, F.; Mas’ud, M.Z.; Xin, L.K. Machine learning for HTTP botnet detection using classifier algorithms. J. Telecommun. Electron. Comput. Eng. 2018, 10, 27–30. [Google Scholar]
- Khan, R.U.; Zhang, X.; Kumar, R.; Sharif, A.; Golilarz, N.A.; Alazab, M. An Adaptive Multi-Layer Botnet Detection Technique Using Machine Learning Classifiers. Appl. Sci. 2019, 9, 2375. [Google Scholar] [CrossRef]
- Harun, S.; Bhuiyan, T.H.; Zhang, S.; Medal, H.; Bian, L. Bot Classification for Real-Life Highly Class-Imbalanced Dataset. In Proceedings of the 2017 IEEE 15th Intl Conf on Dependable, Autonomic and Secure Computing, 15th Intl Conf on Pervasive Intelligence and Computing, 3rd Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/ DataCom/CyberSciTech), Orlando, FL, USA, 6–10 November 2017; pp. 565–572. [Google Scholar]
- Le, D.C.; Zincir-Heywood, A.N.; Heywood, M.I. Data analytics on network traffic flows for botnet behaviour detection. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–7. [Google Scholar]
- Kudugunta, S.; Ferrara, E. Deep neural networks for bot detection. Inf. Sci. 2018, 467, 312–322. [Google Scholar] [CrossRef]
- Cho, C.Y.; Shin, E.C.R.; Song, D. Inference and analysis of formal models of botnet command and control protocols. In Proceedings of the 17th ACM Conference on Computer and Communications Security (CCS), Chicago, IL, USA, 4–8 October 2010; pp. 426–439. [Google Scholar]
- Chowdhary, C.L. Intelligent Systems: Advances in Biometric Systems, Soft Computing, Image Processing, and Data Analytics; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Zimmermann, H.J. Fuzzy Set Theory—and Its Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Fernández-Cerero, D.; Varela-Vaca, Á.J.; Fernández-Montes, A.; Gómez-López, M.T.; Alvárez-Bermejo, J.A. Measuring data-centre workflows complexity through process mining: The Google cluster case. J. Supercomput. 2019, 1–30. [Google Scholar] [CrossRef]
- Basgall, M.J.; Hasperué, W.; Naiouf, M.; Fernández, A.; Herrera, F. SMOTE-BD: An Exact and Scalable Oversampling Method for Imbalanced Classification in Big Data. In Proceedings of the VI Jornadas de Cloud Computing & Big Data (JCC&BD), La Plata, Argentina, 25–29 June 2018. [Google Scholar]
- Ramentol, E.; Caballero, Y.; Bello, R.; Herrera, F. SMOTE-RSB*: A hybrid preprocessing approach based on oversampling and undersampling for high imbalanced data-sets using SMOTE and rough sets theory. Knowl. Inf. Syst. 2012, 11, 245–265. [Google Scholar] [CrossRef]
- Lei, X.; Zhou, P. An intrusion detection model based on GSSVM Classifier. Inf. Technol. J. 2012, 11, 794–798. [Google Scholar] [CrossRef][Green Version]
- Gonzalez-Cuautle, D.; Corral-Salinas, U.Y.; Sanchez-Perez, G.; Perez-Meana, H.; Toscano-Medina, K.; Hernandez-Suarez, A. An Efficient Botnet Detection Methodology using Hyper-Parameter Optimization Trough Grid-Search Techniques. In Proceedings of the 2019 7th International Workshop on Biometrics and Forensics (IWBF), Cancun, Mexico, 2–3 May 2019; pp. 1–6. [Google Scholar]
- Abdulhammed, R.; Faezipour, M.; Abuzneid, A.; AbuMallouh, A. Deep and Machine Learning Approaches for Anomaly-Based Intrusion Detection of Imbalanced Network Traffic. IEEE Sens. Lett. 2019, 3, 1–4. [Google Scholar] [CrossRef]
- Putman, C.G.J.; Nieuwenhuis, L.J. Business Model of a Botnet. In Proceedings of the 2018 26th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), Cambridge, UK, 21–23 March 2018; pp. 441–445. [Google Scholar]
- Beigi, E.B.; Jazi, H.H.; Stakhanova, N.; Ghorbani, A.A. Towards effective feature selection in machine learning-based botnet detection approaches. In Proceedings of the Communications and Network Security (CNS), 2014 IEEE Conference, San Francisco, CA, USA, 29–31 October 2014; pp. 247–255. [Google Scholar]
- Ring, M.; Wunderlich, S.; Gruedl, D.; Landes, D.; Hotho, A. Creation of Flow-Based Data Sets for Intrusion Detection. J. Inf. Warf. 2017, 16, 40–53. [Google Scholar]
- Howley, T.; Madden, M.G.; O’Connell, M.L.; Ryder, A.G. The effect of principal component analysis on machine learning accuracy with high dimensional spectral. In Proceedings of the International Conference on Innovative Techniques and Applications of Artificial Intelligence Data, Cambridge, UK, 12–14 December 2005; pp. 209–222. [Google Scholar]
- Zhao, D.; Traore, I.; Sayed, B.; Lu, W.; Saad, S.; Ghorbani, A.; Garant, D. Botnet detection based on traffic behavior analysis and flow intervals. Comput. Secur. 2013, 39, 2–16. [Google Scholar] [CrossRef]
- Honeynet. Available online: https://www.honeynet.org/ (accessed on 15 May 2019).
- Szabó, G.; Orincsay, D.; Malomsoky, S.; Szabó, I. On the validation of traffic classification algorithms. In Proceedings of the International Conference on Passive and Active Network Measurement, Berlin, Germany, 26–27 March 2018; pp. 72–81. [Google Scholar]
- Lawrence Berkeley National Laboratory and icsi, lbnl/icsi Enterprise Tracing Project. lbnl Enterprise Trace Repository. 2005. Available online: http://www.icir.org/enterprise-tracing/ (accessed on 15 May 2019).
- Shiravi, A.; Shiravi, H.; Tavallaee, M.; Ghorbani, A. Toward developing a systematic approach to generate benchmark datasets for intrusion detection. Comput. Secur. 2012, 31, 357–374. [Google Scholar] [CrossRef]
- Malware Capture Facility Project. Available online: https://mcfp.weebly.com/ (accessed on 15 May 2019).
- Tshark. Available online: https://www.wireshark.org/docs/man-pages/tshark.html (accessed on 10 May 2019).
- Marnerides, A.K.; Watson, M.R.; Shirazi, N.; Mauthe, A.; Hutchison, D. Malware analysis in cloud computing: Network and system characteristics. In Proceedings of the 2013 IEEE Globecom Workshops (GC Wkshps), Atlanta, GA, USA, 9–14 December 2013; pp. 482–487. [Google Scholar]
- Watson, M.R.; Marnerides, A.K.; Mauthe, A.; Hutchison, D. Malware detection in cloud computing infrastructures. IEEE Trans. Dependable Secur. Comput. 2015, 13, 192–205. [Google Scholar] [CrossRef]
- Marnerides, A.K.; Mauthe, A.U. Analysis and characterisation of botnet scan traffic. In Proceedings of the 2016 International Conference on Computing, Networking and Communications (ICNC), Kauai, HI, USA, 15–18 February 2016; pp. 1–7. [Google Scholar]
- Venkatesh, G.K.; Nadarajan, R.A. HTTP botnet detection using adaptive learning rate multilayer feed-forward neural network. In Proceedings of the IFIP International Workshop on Information Security Theory and Practice, Egham, UK, 20–22 June 2012; pp. 38–48. [Google Scholar]
- Su, S.C.; Chen, Y.R.; Tsai, S.C.; Lin, Y.B. Detecting p2p botnet in software defined networks. Secur. Commun. Netw. 2018, 2018, 13. [Google Scholar] [CrossRef]
- Rice, J.R. The Algorithm Selection Problem; Advances in Computers; Elsevier: Amsterdam, The Netherlands, 1976; Volume 15, pp. 65–118. [Google Scholar]
- Liao, Y.; Vemuri, V.R. Use of k-nearest neighbor classifier for intrusion detection. Comput. Secur. 2002, 21, 439–448. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Caesarendra, W.; Widodo, A.; Yang, B.S. Application of relevance vector machine and logistic regression for machine degradation assessment. Mech. Syst Signal. Process. 2010, 24, 1161–1171. [Google Scholar] [CrossRef]
- Rokach, L.; Maimon, O.Z. Data Mining With Decision Trees: Theory and Applications; World Scientific: Singapore, 2018; Volume 69. [Google Scholar]
- Santos, I.; Brezo, F.; Ugarte-Pedrero, X.; Bringas, P.G. Opcode sequences as representation of executables for data-mining-based unknown malware detection. Inf. Sci. 2013, 231, 64–82. [Google Scholar] [CrossRef]
- Aviv, A.J.; Haeberlen, A. Challenges in experimenting with botnet detection systems. In Proceedings of the 4th Conference on Cyber Security Experimentation and Test (CSET), San Francisco, CA, USA, 8–12 August 2011; p. 6. [Google Scholar]
- Amos, B.; Turner, H.; White, J. Applying machine learning classifiers to dynamic android malware detection at scale. In Proceedings of the 2013 9th International Wireless Communications and Mobile Computing Conference (IWCMC), Sardinia, Italy, 1–5 July 2013; pp. 1666–1671. [Google Scholar]
- Verma, A.; Ranga, V. Statistical analysis of CIDDS-001 dataset for network intrusion detection systems using distance-based machine learning. Procedia Comput. Sci. 2018, 125, 709–716. [Google Scholar] [CrossRef]
- Bijalwan, A.; Chand, N.; Pilli, E.S.; Krishna, C.R. Botnet analysis using ensemble classifier. Perspect. Sci. 2016, 8, 502–504. [Google Scholar] [CrossRef]
- Thamilarasu, G.; Chawla, S. Towards Deep-Learning-Driven Intrusion Detection for the Internet of Things. Sensors 2019, 19, 1977. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Botnet | Type | Flow Portion |
|---|---|---|
| Neris | IRC | 25,967 (5.67%) |
| Rbot | IRC | 83 (0.018%) |
| Menti | IRC | 2878 (0.62%) |
| Sogou | HTTP | 89 (0.019%) |
| Murlo | IRC | 4881 (1.06%) |
| Virut | HTTP | 58,576 (12.80%) |
| NSIS | P2P | 757 (0.165%) |
| Zeus | P2P | 502 (0.109%) |
| SMTP Spam | P2P | 21,633 (4.72%) |
| UDP Storm | P2P | 44,062 (9.63%) |
| Tbot | IRC | 1296 (0.283%) |
| Zero Access | P2P | 1011 (0.221%) |
| Weasel | P2P | 42,313 (9.25%) |
| Smoke Bot | P2P | 78 (0.017%) |
| Zeus Control (C and C) | P2P | 31 (0.006%) |
| ISCX IRC bot | P2P | 1816 (0.387%) |
| Botnet | IP Addresses Ranges |
|---|---|
| IRC | 192.168.2.112 -> 131.202.243.84 |
| 192.168.5.122 -> 198.164.30.2 | |
| 192.168.2.110 -> 192.168.5.122 | |
| 192.168.4.118 -> 192.168.5.122 | |
| 192.168.2.113 -> 192.168.5.122 | |
| 192.168.1.103 -> 192.168.5.122 | |
| 192.168.4.120 -> 192.168.5.122 | |
| 192.168.2.112 -> 192.168.2.110 | |
| 192.168.2.112 -> 192.168.4.120 | |
| 192.168.2.112 -> 192.168.1.103 | |
| 192.168.2.112 -> 192.168.2.113 | |
| 192.168.2.112 -> 192.168.4.118 | |
| 192.168.2.112 -> 192.168.2.109 | |
| 192.168.2.112 -> 192.168.2.105 | |
| 192.168.1.105 -> 192.168.5.122 | |
| Neris | 147.32.84.180 |
| RBot | 147.32.84.170 |
| Menti | 147.32.84.150 |
| Sogou | 147.32.84.140 |
| Murlo | 147.32.84.130 |
| Virut | 147.32.84.160 |
| IRCbot and black hole1 | 10.0.2.15 |
| Black hole 2 | 192.168.106.141 |
| Black hole 3 | 192.168.106.131 |
| Tbot | 172.16.253.130, 172.16.253.131 |
| 172.16.253.129, 172.16.253.240 | |
| Weasel | Botmaster IP: 74.78.117.238 |
| Bot IP: 158.65.110.24 | |
| Zeus (zeus samples 1, 2 and 3, bin_zeus) | 192.168.3.35, 192.168.3.25 |
| 192.168.3.65, 172.29.0.116 | |
| Osx_trojan | 172.29.0.109 |
| Zero access (zero access 1 and 2) | 172.16.253.132, 192.168.248.165 |
| Smoke bot | 10.37.130.4 |
| Feature | Description | |
|---|---|---|
| 1 | Src_ip | Source IP Address |
| 2 | Src_port | Source Port |
| 3 | Dst_ip | Destination IP Address |
| 4 | Dst_port | Destination Port |
| 5 | Out_packets | Number of output packets |
| 6 | Out_bytes | Output byte number |
| 7 | Income_packets | Number of input packets |
| 8 | Income_bytes | Number of input bytes |
| 9 | Total_packets | Total number of transmitted packets |
| 10 | Total_bytes | Total number of transmitted bytes |
| 11 | Duration | Flow duration |
| Feature | Description | |
|---|---|---|
| 1 | Src ip | Source IP Address |
| 2 | Src port | Source Port |
| 3 | Dest ip | Destination IP Address |
| 4 | Dest port | Destination Port |
| 5 | Duration | Duration of the flow |
| 6 | Bytes | Number of transmitted bytes |
| 7 | Packets | Number of transmitted packets |
| 8 | Class | Class label (normal, attacker, victim, suspicious, or unknown) |
| Algorithm (a) | Values/Ranges | |
|---|---|---|
| KNN | Ball tree, | |
| Algorithm used to compute nearest neighbors | KD tree, | |
| Brute Force | ||
| No. of neighbors to use | {1, 50} | |
| Weight function used in prediction | Uniform, | |
| By distance | ||
| SVM | Penalty parameter C of error term | {0.0001, 0.001, 0.01, 0.1} |
| Decision function of shape | One-vs-one, | |
| One-vs-rest | ||
| Kernel type to be used in algorithm | Polynomial, | |
| Linear, | ||
| RBF | ||
| LR | Inverse of regularization strength of term C | {0.0001, 0.001, 0.01, 0.1} |
| Norm used in penalization function | , | |
| , | ||
| Algorithm to use in optimization problem | Linear | |
| LBFGS * | ||
| SAG , | ||
| SAGA | ||
| DT | Maximum tree depth | {1, 30} |
| No. of features to consider for best split | {1, 100} | |
| Strategy used to choose split at each node | Sqrt, | |
| Log | ||
| Best, | ||
| Random | ||
| RF | Use bootstrap samples when building trees | True, False |
| Function to measure split quality | Entropy, GINI | |
| Max tree depth | {1, 30} | |
| No. of features to consider for best split | {1, 30} | |
| Min. no. of samples required to be at leaf node | {1, 30} | |
| Min. no. of samples required to split internal node | {1, 30} | |
| No. of trees in forest | {1, 10} |
| Algorithm | Precision | Recall | F1-Score |
|---|---|---|---|
| KNN | 0.9949 | 0.9968 | 0.9958 |
| SVM | 0.8648 | 0.8968 | 0.8762 |
| LR | 0.7002 | 0.7012 | 0.7049 |
| DT | 0.9958 | 0.9928 | 0.9906 |
| RF | 0.9970 | 0.9922 | 0.9915 |
| Algorithm | Precision | Recall | F1-Score |
|---|---|---|---|
| KNN | 0.9936 | 0.9954 | 0.9915 |
| SVM | 0.7832 | 0.7907 | 0.7826 |
| LR | 0.6861 | 0.6944 | 0.6895 |
| DT | 0.9947 | 0.9929 | 0.9932 |
| RF | 0.9930 | 0.9951 | 0.9947 |
| Algorithm | Precision | Recall | F1-Score | Best Hyperparameter/Value |
|---|---|---|---|---|
| KNN | 0.9812 | 0.9817 | 0.9815 | Algorithm used to compute nearest neighbors: Ball tree |
| No. of neighbors to use: 4 | ||||
| Weight function used in prediction: By distance | ||||
| SVM | 0.8961 | 0.9344 | 0.9091 | Penalty parameter C of error term: 0.001 |
| Decision function of shape: One-vs-one | ||||
| Kernel type to be used in the algorithm: Linear | ||||
| LR | 0.7208 | 0.7188 | 0.7196 | Inverse of regularization strength of term C: 0.0001 |
| Norm used in penalization function: | ||||
| Algorithm to use in optimization problem: Linear | ||||
| DT | 0.9816 | 0.9836 | 0.9826 | Maximum tree depth: 9 |
| No. of features to consider for best split: 12 | ||||
| Strategy used to choose split at each node: Best | ||||
| RF | 0.9814 | 0.9833 | 0.9823 | Use bootstrap samples when building trees: False |
| Function to measure split quality: GINI | ||||
| Max tree depth: 9 | ||||
| No. of features to consider for best split: 12 | ||||
| Min. no. of samples required to be at leaf node: 2 | ||||
| Min. no. of samples required to split internal node: 9 | ||||
| No. of trees in forest: 1 |
| Algorithm | Precision | Recall | F1-Score | Best Hyperparameter Value |
|---|---|---|---|---|
| KNN | 0.9677 | 0.9676 | 0.9676 | Algorithm used to compute nearest neighbors: Ball tree |
| No. of neighbors to use: 4 | ||||
| Weight function used in prediction: by distance | ||||
| SVM | 0.8152 | 0.8261 | 0.8117 | Penalty parameter C of error term: 0.01 |
| Decision function of shape: One-vs-one | ||||
| Kernel type to be used in the algorithm: Linear | ||||
| LR | 0.7836 | 0.7789 | 0.7816 | Inverse of regularization strength of term C: 0.0001 |
| Norm used in penalization function: | ||||
| Algorithm to use in optimization problem: LBFGS | ||||
| DT | 0.9797 | 0.9800 | 0.9799 | Maximum tree depth: 9 |
| No. of features to consider for best split: 12 | ||||
| Strategy used to choose split at each node: Best | ||||
| RF | 0.9796 | 0.9799 | 0.9798 | Use bootstrap samples when building trees: False |
| Function to measure split quality: GINI | ||||
| Max tree depth: 9 | ||||
| No. of features to consider for best split: 7 | ||||
| Min. no. of samples required to be at leaf node: 2 | ||||
| Min. no. of samples required to split internal node: 9 | ||||
| No. of trees in forest: 1 |
| Methodology | Dataset | Algorithm | Accuracy |
|---|---|---|---|
| Verma A. et al. [66] | CIDDS-001 | KNN | 93.87% |
| SMOTE+GS | CIDDS-001 | KNN | 98.72% |
| Bijalwan A. et al. [67] | ISCX-Bot-2014 | KNN DT Bagging with KNN Ada-Boost with DT Soft voting of KNN and DT | 93.87% 93.37% 95.69% 94.78% 96.41% |
| SMOTE + GS | ISCX-Bot-2014 | KNN SVM LR DT RF | 98.72% 97.35% 97.89% 98.65% 98.84% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gonzalez-Cuautle, D.; Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, L.K.; Portillo-Portillo, J.; Olivares-Mercado, J.; Perez-Meana, H.M.; Sandoval-Orozco, A.L. Synthetic Minority Oversampling Technique for Optimizing Classification Tasks in Botnet and Intrusion-Detection-System Datasets. Appl. Sci. 2020, 10, 794. https://doi.org/10.3390/app10030794
Gonzalez-Cuautle D, Hernandez-Suarez A, Sanchez-Perez G, Toscano-Medina LK, Portillo-Portillo J, Olivares-Mercado J, Perez-Meana HM, Sandoval-Orozco AL. Synthetic Minority Oversampling Technique for Optimizing Classification Tasks in Botnet and Intrusion-Detection-System Datasets. Applied Sciences. 2020; 10(3):794. https://doi.org/10.3390/app10030794
Chicago/Turabian StyleGonzalez-Cuautle, David, Aldo Hernandez-Suarez, Gabriel Sanchez-Perez, Linda Karina Toscano-Medina, Jose Portillo-Portillo, Jesus Olivares-Mercado, Hector Manuel Perez-Meana, and Ana Lucila Sandoval-Orozco. 2020. "Synthetic Minority Oversampling Technique for Optimizing Classification Tasks in Botnet and Intrusion-Detection-System Datasets" Applied Sciences 10, no. 3: 794. https://doi.org/10.3390/app10030794
APA StyleGonzalez-Cuautle, D., Hernandez-Suarez, A., Sanchez-Perez, G., Toscano-Medina, L. K., Portillo-Portillo, J., Olivares-Mercado, J., Perez-Meana, H. M., & Sandoval-Orozco, A. L. (2020). Synthetic Minority Oversampling Technique for Optimizing Classification Tasks in Botnet and Intrusion-Detection-System Datasets. Applied Sciences, 10(3), 794. https://doi.org/10.3390/app10030794