Hybrid Local and Global Deep-Learning Architecture for Salient-Object Detection



Abstract
1. Introduction
- Generation of local and global deep feature maps to extract detailed structure of objects.
- Enhanced detection of objects in low-contrast images by integrating contrast features, and a global convolutional modules to introduce dense connections between features and classifiers.
- Boundary-refinement module to preserve boundary information present in initial layers.
- A residual refinement module is embedded that processes the predicted saliency map to refine boundaries by learning residuals.
2. Related Work
2.1. Traditional Approaches
2.2. Deep-Learning-Based Techniques
3. Proposed Approach
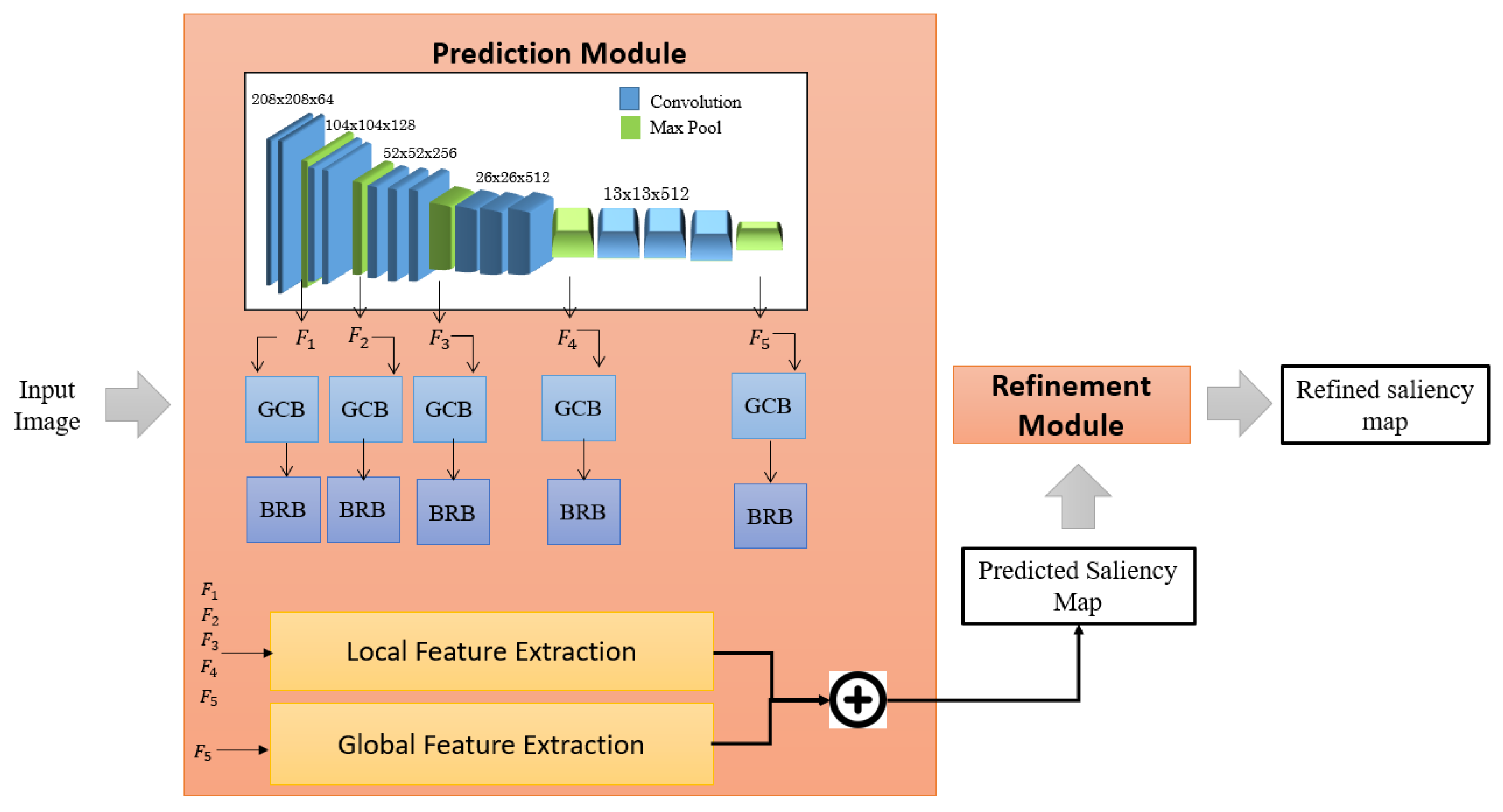
3.1. Architecture Overview
3.2. Prediction Module
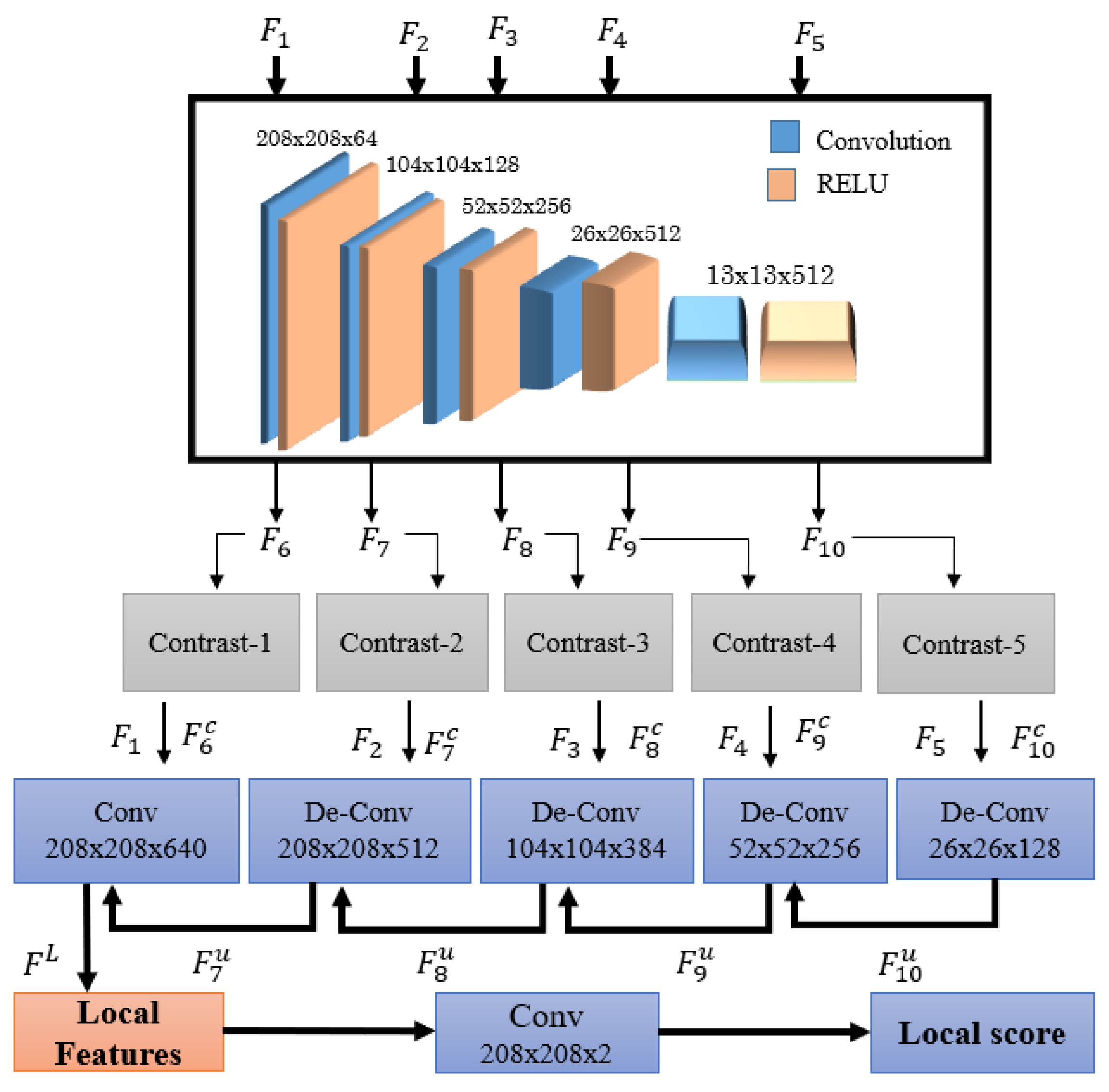
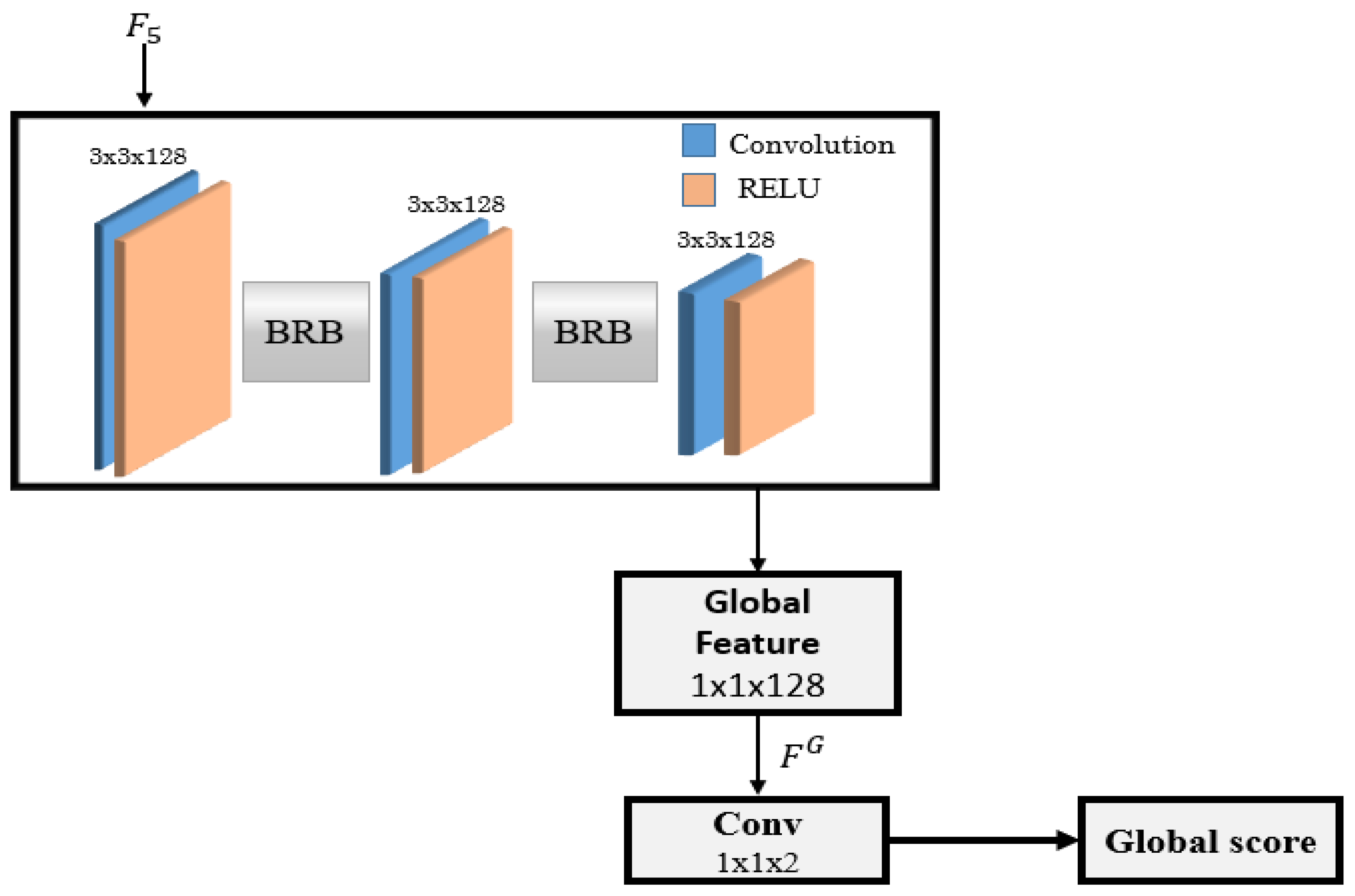
3.3. Global Convolutional Block
3.4. Boundary-Refinement Block
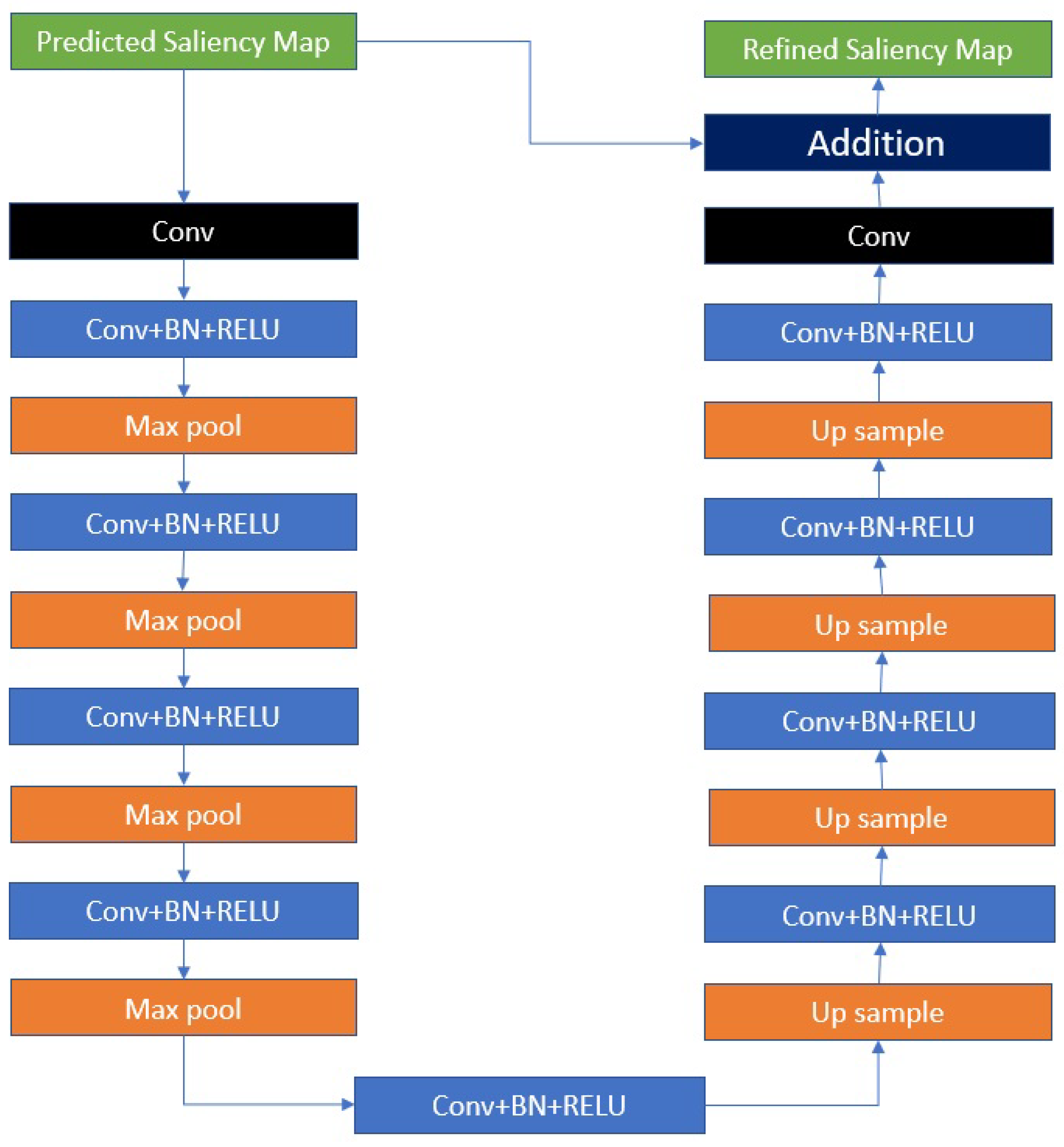
3.5. Refinement Module
4. Experimental Results
4.1. Datasets for Evaluation
- MSRA-B [31] comprises 5000 images and contains a single object mostly around the center position along with the bounding-box label.
- DUT-OMRON [32] includes 5168 images with complex backgrounds and a variety of content. Pixelwise ground-truth annotations are also available.
- The PASCAL-S [33] dataset contains 850 complex images. Eye-fixation records, and nonbinary and pixelwise annotations are also available.
- HKU-IS [34] comprises 4447 multiple distant objects. In these, a minimum of one object is present at the image boundary. Less difference between background and foreground makes these images more complex.
- DUTS [35] is very large Sod dataset containing 5019 test images and 10,553 training images. Many models use this dataset for training.
4.2. Evaluation Metrics
- Precision–recall (PR) curve: Calculated by the conversion of the predicted saliency map into a binarised map and ground truth. Thresholding of 0–255 is applied to produce the binary map. For all saliency maps present in a dataset, every binarising threshold comes in a set of average precision and recall. An order of precision–recall pair is generated when the threshold varies from 0 to 1, which is used to plot the PR curve.
- F-measure curve: To provide comprehensive analysis, is calculated on both precision and recall as:The value is set as 0.3 to highlight precision more because the rate of recall is not as significant as that of precision. The value of the average F-measure is also presented in this research. The F-measure curve is generated with a comparison of the binary map with the ground truth that is obtained by changing threshold to decide if a pixel is owned by a salient object.
- Mean absolute error (MAE) is used to correctly measure false-negative pixels. It calculates the pixelwise error between saliency map and ground truth:If the MAE value is less, it indicates that ground truth and predicted saliency map are highly similar.
4.3. Implementation and Experiment Setup
4.4. Comparison with the State of the Art
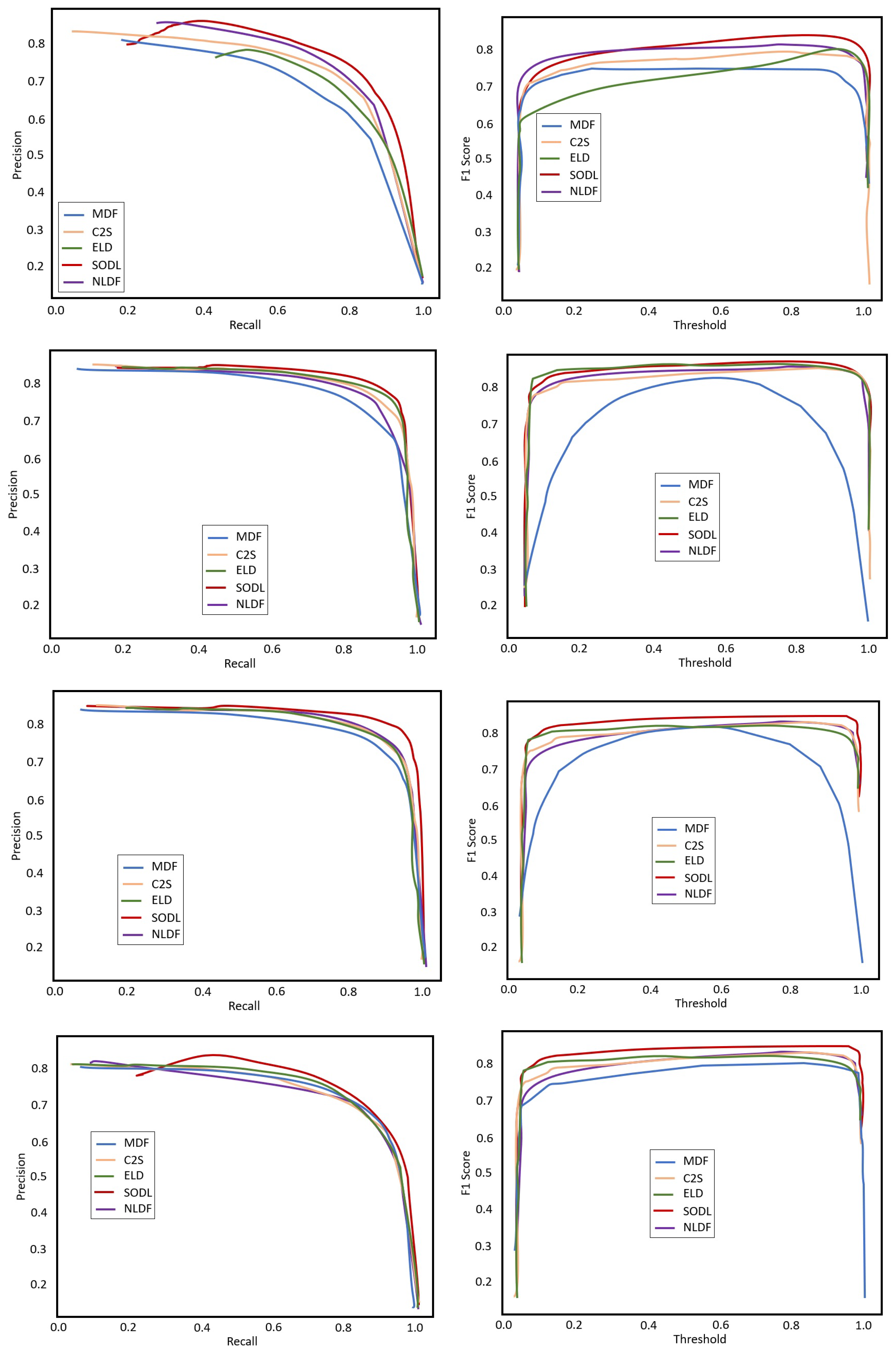
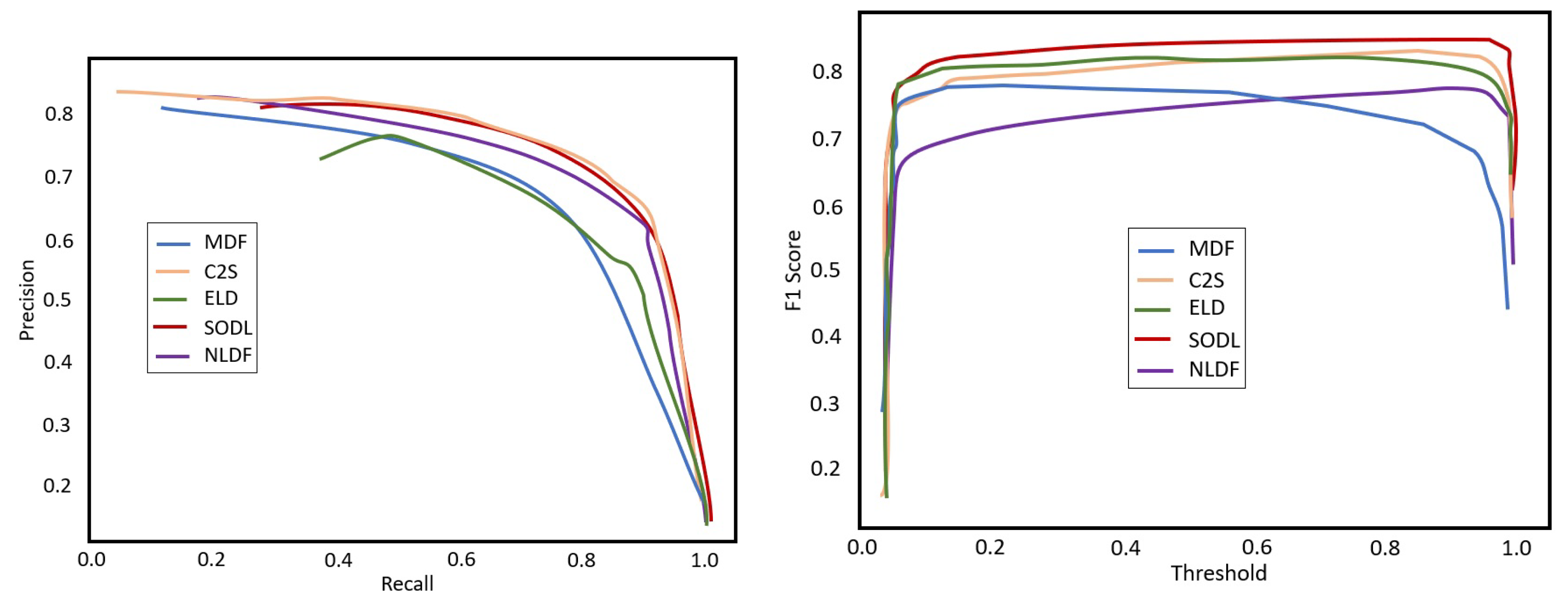
4.4.1. Quantitative Comparison
4.4.2. Qualitative Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Borji, A.; Cheng, M.-M.; Hou, Q.; Jiang, H.; Li, J. Salient Object Detection: A Survey. Comput. Vis. Media 2019, 5, 117–150. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Fang, H.; Gupta, S.; Iandola, F.; Srivastava, R. From Captions to Visual Concepts and Back. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Borji, A.; Ahmadabadi, M.N.; Araabi, B.N. Cost-sensitive learning of top-down modulation for attentional control. Mach. Vis. Appl. 2011, 22, 61–76. [Google Scholar] [CrossRef]
- Borji, A.; Itti, L. Scene classification with a sparse set of salient regions. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Wei, Y.; Liang, X.; Chen, Y. A simple to complex framework for weakly-supervised semantic segmentation. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Li, A.; She, X.; Sun, Q. Color image quality assessment combining saliency and FSIM. In Proceedings of the International Conference on Digital Image Processing, Beijing, China, 21–22 April 2013. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantics egmentation. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Lin, Q.J.; Tao, Y.; Li, W.; Shi, Y. Salient object detection via color and texture cues. Neurocomputing 2017, 243, 35–48. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Wang, L.; Wang, L.; Lu, H.; Zhang, P.; Ruan, X. Salient Object Detection with Recurrent Fully Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1734–1746. [Google Scholar] [CrossRef] [PubMed]
- Singh, V.K.; Kumar, N. Saliency bagging: A novel framework for robust salient object detection. Vis. Comput. 2019, 36, 1423–1441. [Google Scholar] [CrossRef]
- Feng, M.; Lu, H.; Ding, E. Attentive Feedback Network for Boundary-Aware Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, Y.; Zhao, X.; Hu, X.; Li, Y.; Huang, K. Focal Boundary Guided Salient Object Detection. IEEE Trans. Image Process. 2019, 28, 2813–2824. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Eitel, A.; Springenberg, J.T.; Spinello, L.; Riedmiller, M.; Burgard, W. Multimodal deep learning for robust RGB-D object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 681–687. [Google Scholar]
- Sokalski, J.; Breckon, T.P.; Cowling, I. Automatic salient object detection in UAV imagery. In Proceedings of the Automatic Salient Object Detection In UAV Imagery 25th International UAV Systems Conference, Bristol, UK, 12–14 April 2010; pp. 1–12. [Google Scholar]
- Cheng, M.-M.; Mitra, N.J.; Huang, X.; Torr, P.H.S.; Hu, S.-M. Global Contrast Based Salient Region Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 569–582. [Google Scholar] [CrossRef] [PubMed]
- Hou, X.; Harel, J.; Koch, C. Image Signature: Highlighting Sparse Salient Regions. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 194–201. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. BASNet: Boundary-Aware Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, J.; Levine, M.D.; An, X.; Xu, X.; He, H. Visual saliency based on scale-space analysis in the Frequency Domain. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 996–1010. [Google Scholar] [CrossRef] [PubMed]
- Imamoglu, N.; Lin, W.; Fang, Y. A Saliency Detection Model Using Low-Level Features Based on Wavelet Transform. IEEE Trans. Multimed. 2013, 15, 96–105. [Google Scholar] [CrossRef]
- Zou, W.; Liu, Z.; Kpalma, K.; Ronsin, J.; Zhao, Y.; Komodakis, N. Unsupervised Joint Salient Region Detection and Object Segmentation. IEEE Trans. Image Process. 2015, 24, 3858–3873. [Google Scholar] [PubMed]
- Tong, N.; Lu, H.; Ruan, X.; Yang, M.-H. Salient object detection via bootstrap learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Liu, Y.; Han, J.; Zhang, Q.; Shan, C. Deep Salient Object Detection with Contextual Information Guidance. IEEE Trans. Image Process. 2019, 29, 360–374. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Chen, Y.; Yuille, A.; Freeman, W. Latent hierarchical structural learning for object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Ding, X.; Luo, Y.; Li, Q.; Cheng, Y.; Cai, G.; Munnoch, R.; Xue, D.; Yu, Q.; Zheng, X.; Wang, B. Prior knowledge-based deep learning method for indoor object recognition and application. Syst. Sci. Control Eng. 2018, 6, 249–257. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, X.; Zhang, Z.; Wu, F.; Zhao, L. Deep learning driven blockwise moving object detection with binary scene modeling. Neurocomputing 2015, 168, 454–463. [Google Scholar] [CrossRef]
- Luo, Z.; Mishra, A.; Achkar, A.; Eichel, J.; Li, S.; Jodoin, P.-M. Non-local deep features for salient object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6593–6601. [Google Scholar]
- Lee, G.; Tai, Y.-W.; Kim, J. Deep saliency with encoded low level distance map and high level features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 660–668. [Google Scholar]
- Liu, T.; Sun, J.; Zheng, N.-N.; Tang, X.; Shum, H.-Y. Learning to Detect A Salient Object. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M. Saliency detection via graph-based manifold ranking. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The secrets of salient object segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to detect salient objects with image-level supervision. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3796–3805. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Li, G.; Yu, Y. Visual saliency detection based on multiscale deep cnn features. IEEE Trans. Image Process. 2016, 25, 5012–5024. [Google Scholar] [CrossRef] [PubMed]
- Mu, N.; Xu, X.; Zhang, X. Salient Object Detection in Low Contrast Images via Global Convolution and Boundary Refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Methods | Strengths | Limitations |
|---|---|---|---|
| [10] | Frequency-tuned model for | Efficiency in computation | Alignment issues and poor |
| large salient objects | Fine detection in large objects | performance for low contrast | |
| [11] | FCN-based saliency map | Good saliency refinement | Computational iterative process |
| [12] | Hybrid saliency detection | improved accuracy | Poor performance for low-contrast images |
| [16] | Multistage training | Good noise filter | Computationally complex |
| [17] | Mean shift | Robust against low noise | Low results for highly noisy images |
| [18] | Intensity- and contrast-based | Fine saliency map | Not efficient for large images |
| [19] | Image signature | Scalability | Poor performance for small objects |
| [20] | Background construction for saliency | Better accuracy | High computational cost |
| [21] | Graph-based manifold ranking | Combination of multiple methods | High dimensionality and computational cost |
| [22] | Wavelets | effective saliency detection | Loss of spatial information |
| [23] | Unsupervised technique for saliency | Joint and iterative optimisation | Computational cost is high |
| [24] | Bootstrap | Time reduction | Limited results shown |
| [25] | Contextual info | Good results | Perform low for complex backgrounds |
| [26] | Hierarchical and SVM | Lower computational cost | Perform poor for complex images |
| [27] | Uses scene knowledge | Good precision | Poor results for low-resolution images |
| [28] | Blockwise scene scanning | Improved accuracy | Computational cost |
| [29] | Regions based features | Efficient approach | Perform poor for low contrast images |
| [30] | Low- and high-level features | Improved accuracy | Bad segmentation for low-contrast images |
| Dataset | Criteria | Proposed | NLDF | C2S | MDF | ELD | GCBR | Amulet |
|---|---|---|---|---|---|---|---|---|
| MSRA-B | MAE | 0.0345 0.935 | 0.0477 0.910 | 0.0662 0.8309 | 0.104 0.885 | - - | 0.0373 0.8904 | - - |
| black DUTS | MAE | 0.0653 0.816 | 0.066 0.812 | 0.0663 0.790 | 0.094 0.730 | 0.093 0.738 | 0.0695 0.801 | 0.075 0.773 |
| DUT-OMRON | MAE | 0.0753 0.764 | 0.0795 0.753 | 0.0790 0.733 | 0.0915 0.694 | 0.0909 0.719 | 0.0763 0.7010 | 0.0830 0.7370 |
| PASCAL-S | MAE | 0.106 0.829 | 0.113 0.807 | 0.0991 0.827 | 0.143 0.771 | 0.133 0.768 | 0.0356 0.801 | 0.092 0.826 |
| HKU-IS | MAE | 0.0432 0.918 | 0.0485 0.914 | 0.0527 0.897 | 0.135 0.867 | 0.074 0.839 | 0.0432 0.8988 | 0.052 0.889 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sultan, W.; Anjum, N.; Stansfield, M.; Ramzan, N. Hybrid Local and Global Deep-Learning Architecture for Salient-Object Detection. Appl. Sci. 2020, 10, 8754. https://doi.org/10.3390/app10238754
Sultan W, Anjum N, Stansfield M, Ramzan N. Hybrid Local and Global Deep-Learning Architecture for Salient-Object Detection. Applied Sciences. 2020; 10(23):8754. https://doi.org/10.3390/app10238754
Chicago/Turabian StyleSultan, Wajeeha, Nadeem Anjum, Mark Stansfield, and Naeem Ramzan. 2020. "Hybrid Local and Global Deep-Learning Architecture for Salient-Object Detection" Applied Sciences 10, no. 23: 8754. https://doi.org/10.3390/app10238754
APA StyleSultan, W., Anjum, N., Stansfield, M., & Ramzan, N. (2020). Hybrid Local and Global Deep-Learning Architecture for Salient-Object Detection. Applied Sciences, 10(23), 8754. https://doi.org/10.3390/app10238754