1. Introduction
The present work sits in the scientific field known as grammatical inference (GI), automata learning, grammar identification, or grammar induction [
1,
2]. The matter under consideration is the set of rules that lie behind a given sequence of words (so-called strings). The main task is to discover the rule(s) that will help us to evaluate new, unseen words. Mathematicians investigate infinite sequences of words and for this purpose they proposed a few inference models. In the most popular model, Gold’s identification in the limit [
3], learning happens incrementally. After each new word, the algorithm returns some hypothesis, i.e., an automaton or a grammar, and a entire process is regarded as successful when the algorithm returns a correct answer at a certain iteration and does not change it afterwards. However, very often in practice we deal only with a limited number of words (some of them being examples and others counter-examples). In such cases the best option is to use a selected heuristic algorithm, among which the most recognized instances include: evidence driven state merging [
4], the
k-tails method [
5], the GIG method [
6], the TBL (tabular representation learning) algorithm [
7], the learning system ADIOS (automatic distillation of structure) [
8], error-correcting grammatical inference [
9], and alignment-based learning [
10]. However, all of these methods output classical acceptors like (non)deterministic finite state automata (FSA) or context-free grammars (CFG). FSAs are fast in recognition but lack in expressiveness. CFGs, on the other hand, are more expressive but need more computing time for recognizing. We propose here using parsing expression grammars (PEGs), which are as fast as FSAs and can express more than CFGs, in the sense that they can represent some context-sensitive grammars. To the best of our knowledge no one else devised a similar induction algorithm before. As far as non-Chomsky grammars are considered for representing acceptors, Eyraud et al. [
11] applied a string-rewriting system to the GI domain. However, as the authors claimed, pure context-sensitive languages can probably not be described with their tool. PEGs are relatively new, but have been implemented in few applications (e.g., Extensible Markup Language schema validation using Document Type Definition automatic transformation [
12] and a text pattern-matching tool [
13]).
The purpose of the present proposal is threefold. The first objective is to devise an induction algorithm that will suit well real biological data-amyloidogenic sequence fragments. Amyloids are proteins capable of forming fibrils instead of the functional structure of a protein, and are responsible for a group of serious diseases. The second objective is to determine that the proposed algorithm is also well suited for the benchmark data as selected comparative grammatical inference (GI) algorithms and a machine learning approach (SVM). We assume that the given strings do not contain periodically repeated substrings, which is why it has been decided to build up non-circular PEGs that represent finite sets of strings. The last objective is to write a Python library for handling PEGs and make it available to the community. Although there are at least three other Python packages for generating PEG parsers, namely Arpeggio (
http://www.igordejanovic.net/Arpeggio), Grako (
https://bitbucket.org/neogeny/grako), and pyPEG (
https://fdik.org/pyPEG), our implementation (
https://github.com/wieczorekw/wieczorekw.github.io/tree/master/PEG) is worth noting for its simple usage (integration with Python syntax via native operators) and because it is dozens of times faster in processing long strings, as will be shown in detail in
Section 3.3. In addition to Python libraries, to enrich the research, a library named EGG (
https://github.com/bruceiv/egg/tree/deriv) written in C++ was used for comparison, in which an expression has to be compiled into machine code before it is used [
14].
This paper is organized into five sections.
Section 2 introduces the notion of parsing expression grammars and also discusses their pros and cons in comparison with regular expressions and CFGs.
Section 3 section describes the induction algorithm.
Section 4 discusses the experimental results.
Section 5 summarizes the collected results.
2. Definition of PEGs
PEGs reference regular expressions (RE) and context-free grammars (CFGs), both derivative from formal language theory. We briefly introduce the most relevant definitions.
An alphabet is a non-empty set of symbols (characters without any meaning). A string or word (s, w) is a finite sequence of symbols. The special case of the string is an empty string (the empty sequence of symbols). The example of the alphabet is a set and an example of strings over the alphabet is . A formal language L over an alphabet is a subset of (Kleene star, all strings over ). A regular expression is a formal way of describing the class of languages called regular language. Let r, , and be the regular expression over , and ; the following operations are allowed in syntax:
, the empty string;
a, symbol or string occurrence;
, zero or more repetitions of regular expression;
a+, one or more repetitions;
, non-deterministic choice of symbol, formally defined as ;
, concatenation;
, parenthesis for grouping of expressions.
Given an alphabet
, a formal language
|
w begins with a and ends with
a} can be expressed as the regular expression
. CFG is a tuple of
, where
V is the final set of nonterminal symbols,
is the final set of terminal symbols disjoint from
V,
R is a finite relation
and defines rules, and
S is the start symbol, chosen from
V. The most common
R is defined as the production rule notation; for example, for formal language:
, the equivalent context-free grammar is
with the productions:
The word
can be accepted using the first production and the third one. The book by Hopcroft et al. [
15] contains more information related to the formal language field.
The formalism of PEGs was introduced by Bryan Ford in 2004 [
16]. However, herein we give definitions and notation compatible with the provided PEG library. Let us start with an informal introduction to parsing expression grammars (PEGs).
A parsing expression grammar (PEG) is a 4-tuple , where V is a finite set of nonterminal symbols, T is a finite set of terminal symbols (letters), R is a finite set of rules, s is a parsing expression called the start expression, and . Each rule is a pair (A, e), which we write as , where and e is a parsing expression. For any nonterminal A, there is exactly one e such that . We define parsing expressions inductively as follows. If e, , and are parsing expressions, then so is:
, the empty string;
a, any terminal, ;
A, any nonterminal, ;
, a sequence;
, prioritized choice;
+e, one or more repetitions;
, a not-predicate.
The choice of operators ≫, |, +, , and ⇐ is caused by being consistent with our Python library. The operators have their counterparts in Python (>>, |, +, ˜ and <=) with the proper precedence. Thus the reader is able to implement expressions in a very natural way, using the native operators.
A PEG is an instance of a recognition system, i.e., a program for recognizing and possibly structuring a string. It can be written in any programming language and looks like a grammar combined with a regex, but its interpretation is different. Take as an example the following regex:
. We can write a “similar” PEG expression:
. The regex accepts all words over the alphabet
that end with the letter
b. The PEG expression, on the contrary, does not recognize any word since PEGs behave greedily, so the part
will consume all letters, including the last
b. An appropriate PEG solution resembles a CFG:
The sign ⇐ associates an expression to a nonterminal. The sign ≫ denotes concatenation. What makes a difference is the ordered choice | and not-predicate
. The nonterminal
E first tries to consume the final
b; then, in the case of failure, it consumes
a or
b and recursively invokes itself. In order to write parsing expressions in a convenient way we will freely omit unnecessary parentheses assuming the following operators precedence (from highest to lowest):
, +, ≫, |, ⇐. The Kleene star operation can be performed via
(Python does not have a unary star operator and the PEG implementation library had to be adjusted). The power of PEGs is clearly visible in fast, linear-time parsing and in the possibility of expressing some context-sensitive languages [
17].
From now on we will use the symbols a, b, and c to represent pairwise different terminals, A, B, C, and D for pairwise different nonterminals, x, , , y, and z for strings of terminals, where , , and e, , and for parsing expressions. To formalize the syntactic meaning of a PEG , we define a function consume(e, x), which outputs a nonnegative integer (the number of “consumed” letters) or nothing (None):
.
; ; .
if .
If and , then the following holds: ; if , then ; if and , then we can be sure that .
If , then ; if and , then ; if and , then .
If and , then ; if , then ; if and , then .
If , then ; if , then .
The language of a PEG is the set of strings x for which . Please note that the definition of the language of a PEG differs fundamentally from the much more well-known CFGs: in the former it is enough to consume any prefix of a word (including the empty one) to accept it, and in the latter the whole word should be consumed to accept it. Direct (like ) as well as indirect left recursions are forbidden, since it can lead to an infinite loop while performing the consume function. It is worth emphasizing that the expression works as non-consuming matching. As a consequence, we can perform language intersection by writing if only , , and . Interestingly, it is not proven yet that there exist context-free languages that cannot be recognized by a PEG.
In the next section we deal with non-circular PEGs that will have to be understood as grammars without any recursions or repetitions. Note that such a non-circular PEG, say , can be written as a single expression e with no nonterminal and no + operation.
3. Induction Algorithm
The proposed algorithm is based on the genetic programming (GP) paradigm [
18]. In it, machine learning can be viewed as requiring discovery of a computer program (an expression in our case) that produces some desired output (the decision class in our case) for particular inputs (strings representing proteins in our case). When viewed in this way, the process of solving problems becomes equivalent to searching a space of possible computer programs for a fittest individual computer program. In this paradigm, populations of computer programs are bred using the principle of survival of the fittest and using a crossover (recombination) operator appropriate for mating computer programs.
This section is split into two subsections. In the first subsection, we will describe the scheme of the GP method adapted to the induction problem. In the second, a deterministic algorithm for the obtaining of an expression matched to the data will be presented. This auxiliary algorithm is used to feed an initial population of GP with promising individuals.
3.1. Genetic Programming
Commonly, genetic programming uses a generational evolutionary algorithm. In generational GP, there exist well-defined and distinct generations. Each generation is represented by a population of individuals. The newer population is created from and then replaces the older population. The execution cycle of the generational GP—which we used in experiments—includes the following steps:
Initialize the population.
Evaluate the individual programs in the current population. Assign a numerical fitness to each individual.
Until the emerging population is fully populated, repeat the following steps:
Select two individuals in the current population using a selection algorithm.
Perform genetic operations on the selected individuals.
Insert the result of crossover, i.e., the better one out of two children, into the emerging population.
If a termination criterion is fulfilled, go to step 5. Otherwise, replace the current population with the emerged population, saving the best individual, and repeat steps 2–4 (elitism strategy).
Present the best individual as the output from the algorithm.
In order to put the above procedure to work, we have to define the following elements and routines of GP: the primitives (known in GP as the terminal set and the function set), the structure of an individual, the initialization, genetic operators, and the fitness function.
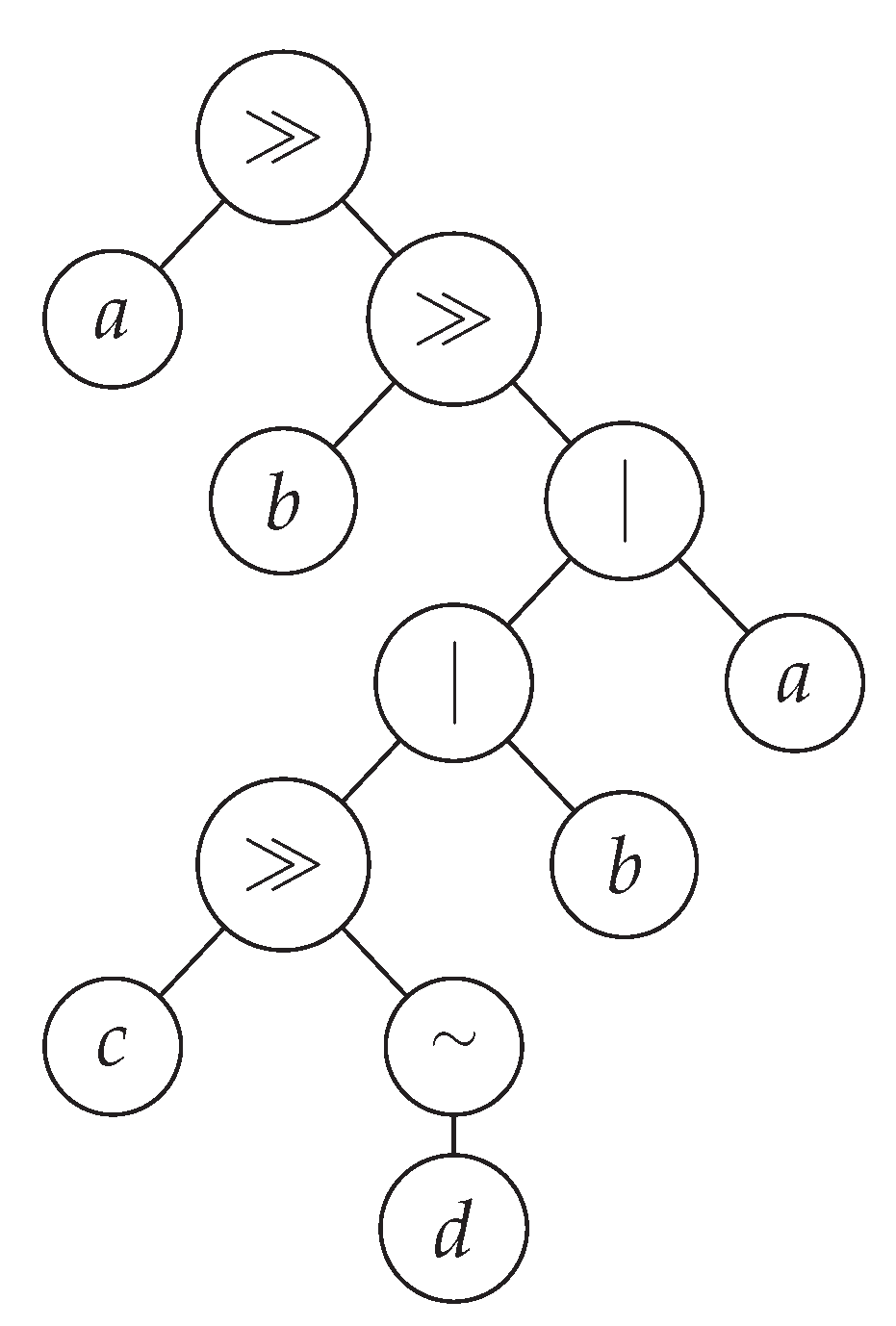
Individuals are parse trees composed of the PEG’s operators
, ≫, and |, and terminals are elements of
, where
is a finite alphabet (see an example in
Figure 1).
An initial population is built upon
(positive strings, examples) and
(negative strings, counterexamples) so that each tree is consistent with a randomly chosen
k-element subset,
X, of
and a randomly chosen
k-element subset,
Y, of
. An expression forming an individual in an initial population is created by means of a deterministic algorithm given further on. In a crossover procedure, two expressions given as parse trees are involved. A randomly chosen part of the first tree is replaced by another randomly chosen part from the second tree. The same operation is performed on the second tree in the same manner. We also used tournament selection, in which
r (the tournament size) individuals are chosen at random and one of them with the highest fitness is returned. Finally, the fitness function measures an expression’s accuracy based on an individual
e, and the sample
with Equation (
1):
where
is a non-circular PEG
.
3.2. Deterministic Algorithm Used in Initializing a GP Population
For a set of strings,
S, and a letter,
r, by a left quotient, denoted by
, we will mean the set
, i.e.,
=
. Let
X and
Y be pairwise disjoint, nonempty sets of words over an alphabet
. Our aim is to obtain a compact non-circular PEG
G satisfying the following two conditions: (i)
, (ii)
. The Algorithm 1 (function
) does it recursively.
| Algorithm 1: Inferring a single expression |
 |
The “Append” method used in lines 7, 9, and 13 in Algorithm 1 concatenates the existing rule
e with a new expression. The recursive call
I in line 9 cuts sets
X and
Y to words that start with terminal symbol
a and then all words that satisfy this condition are passed with words without the first symbol
a (according to the left quotient). Line 10 is used when set
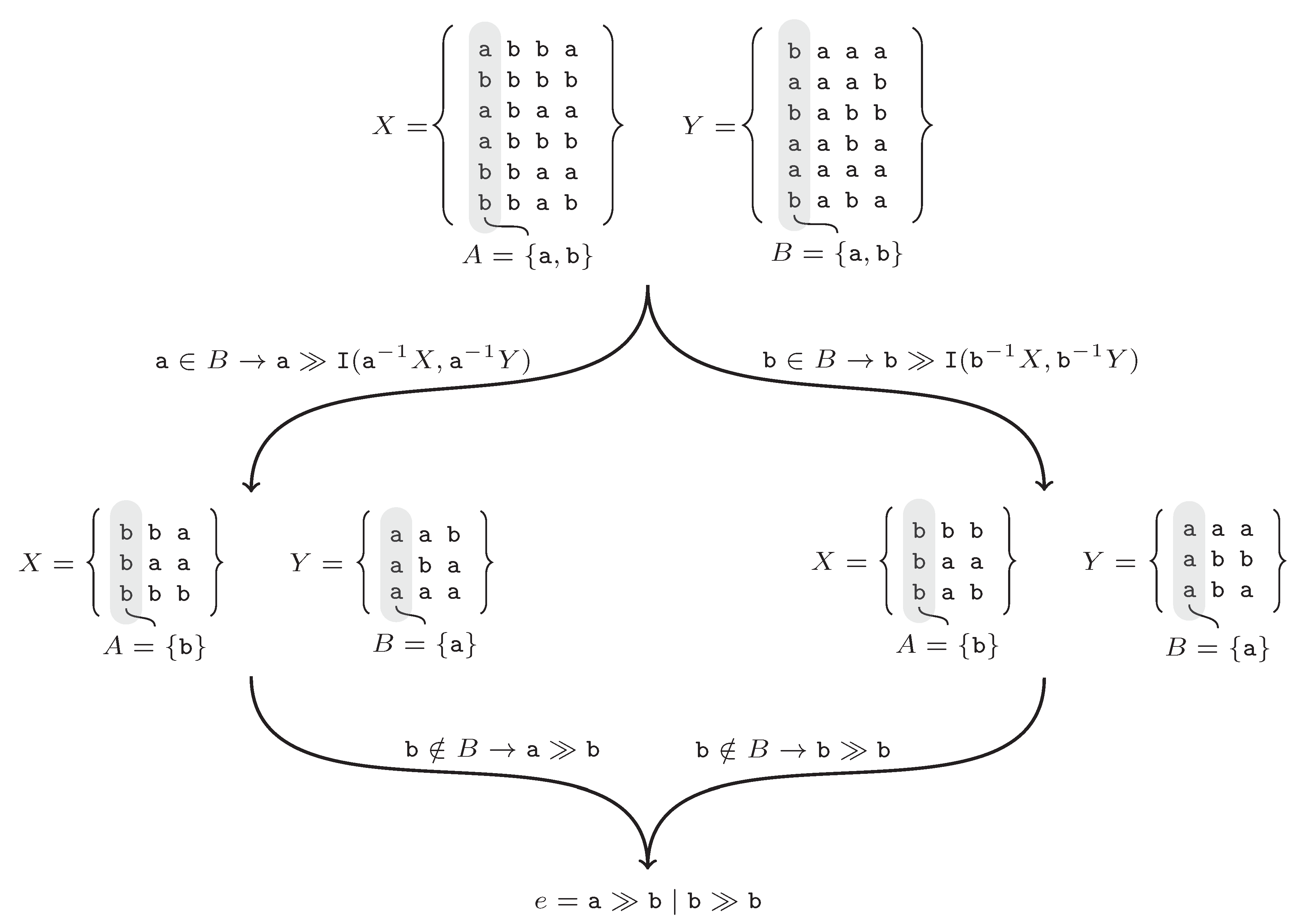
A is empty. The execution of the algorithm is shown by the following example. The input is
abba,
bbbb,
abaa,
abbb,
bbaa,
bbab},
{
baaa,
aaab,
babb,
aaba,
aaaa,
baba}.
Figure 2 shows the successive steps of the algorithm. At the beginning set,
A and
B are determined. The first symbols in the sets of words
X,
Y are equal to
. The terminal symbol
a of the set
A belongs to the set
B. The string
is added to the rule
e and the method is recursively invoked with left quotients
and
(left leaf from the root in the
Figure 2). In the next step, the
a symbol is not in the set
B. From the recursive call, the
b symbol is returned and added to the
e rule. After returning, the same procedure is repeated for the symbol
b.
The algorithm has the following properties: (i) the X, Y sets in successive calls are always nonempty, (ii) word lengths can be different, (iii) it always halts after a finite number of steps and returns some PEG, (iv) the resultant PEG is consistent with X (examples) and Y (counter-examples), and (v) for random words output PEGs are many times smaller than the input. Properties from (i) to (iii) are quite obvious, (iv) will be proven, and we have checked (v) in a series of experiments, and detailed results are given in the next subsection.
Let , the length of every word (from X and Y) not exceed d, and T be the running time of the algorithm. Then, for random input words, we can write , which leads to . In practice, m and d are small constants, so the running time of is usually linear with respect to n.
Lemma 1. Let Σ be a finite alphabet and X, Y be two disjoint, finite, nonempty sets of words over Σ. If and e is a parsing expression returned by then .
Proof. We will prove the above by induction on k, where is the length of x.
Basis: We use as the basis. Because , . Let us consider two cases: (1) is the only word in X, and (2) . In the first case, lines 5–9 of the algorithm are skipped and (in line 11) is returned, where a, b, c, … are the first letters of Y (since is in X, Y has to contain at least one nonempty word). implies . In the second case, the loop in lines 5–9 and line 13 are executed, so the returned expression e (in line 14) has the following form: , where is a single letter, say , or with being some parsing expression. For such an e, holds too.
Induction: Suppose that and that the statement of the lemma holds for all words of length j, where . Let , where . Obviously . Again let us consider two cases: (1) , and (2) . In the first case, e, which is returned in line 14, has the form or or , where and are some expressions. In either case (at least u will not fail for ). In the second case, e, which is returned in line 14, is a sequence of addends, one of which is , where . Suffix w is an element of the set so we invoke the inductive hypothesis to claim that . Then , because of the properties of the sequence and the prioritized choice operators (at least will not fail for x).□
Lemma 2. Let Σ be a finite alphabet and X, Y be two disjoint, finite, nonempty sets of words over Σ. If and e is a parsing expression returned by then .
Proof. We will prove the above by induction on k, where is the length of y.
Basis: We use as the basis, i.e., . Because , the returned (in line 13) expression e has the following form: , where is a single letter, say , or with being some parsing expression. For such an e, .
Induction: Suppose that and that the statement of the lemma holds for all words of length j, where . Let , where . Naturally . There are two main cases to consider: (1) A is empty (that happens only when ), and (2) A is not empty. In the first case, is returned, where a, b, c, …, u, … are the first letters of Y (the position of u in the sequence is not important). implies . In the second case (i.e., A is not empty), let us consider four sub-cases: (2.1) and , (2.2) and , (2.3) and , and (2.4) and . As for (2.1), the returned expression e is of the following form: , where is a single letter, say , or with being some parsing expression. Exactly one of has the form (exactly one ), where . Suffix w is an element of the set so by the induction hypothesis . Then . Notice that the last addend—i.e., the one with —will also fail due to . Sub-case (2.2) is provable similarly to (2.1). When (sub-cases 2.3 and 2.4), none of is u and it is easy to see that .□
Theorem 1. Let Σ be a finite alphabet and X, Y be two disjoint, finite, nonempty sets of words over Σ. If e is a parsing expression returned by and G is a non-circular PEG defined by then and .
Proof. This result follows immediately from the two previous Lemmas.□
3.3. Python’s PEG Library Performance Evaluation
In order to assess the fifth property of Algorithm 1 (for random words output PEGs are many times smaller than the input), we created random sets of words with different sizes, lengths and alphabets.
Table 1 shows our settings in this respect.
Naturally,
and
denote the number of examples and counter-examples, while words’ lengths vary from
to
. Those datasets are publicly available along with the source code of our PEG library.
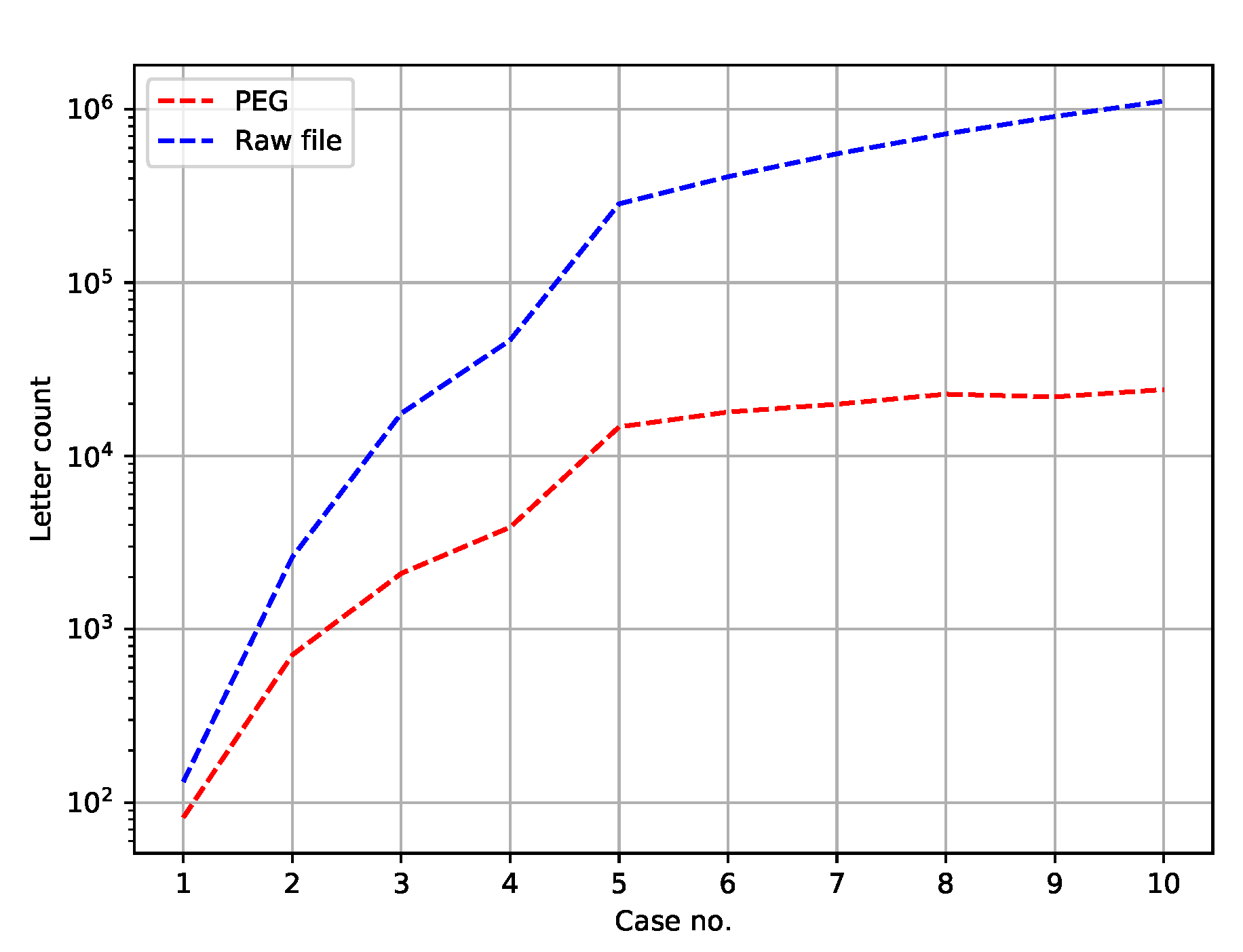
Figure 3 depicts the number of symbols in a PEG and the number of letters in a respective test set.
The number of letters in an input file simply equals
, where
stands for a new line sign (i.e., words’ separator). As for PEGs, the symbol ≫ has not been counted, since it may be omitted. Outside the Python language, concatenation of two symbols, for instance
a and
b, can be written as
instead of
. Notice also that in
Figure 3 the ordinates are in the logarithmic scale, because the differences are large.
The runtime of Python implementation of the proposed PEG library was benchmarked against comparable libraries, i.e., Arpeggio and Grako. The pyPEG library was rejected, because we were unable to define more complex expressions with it. As a testbed we have chosen Tomita’s languages [
19]. This test set contains seven different expressions that serve as rules for the generation of words over a binary alphabet. Their description in a natural language can be found in
Table 2. Seven regular expressions appropriate to the rules were created, and then the generators of random input words were implemented. Thus, for every language we had two sets: matching (positive) and non-matching (negative) words to a particular regular expression. These expressions take the following forms:
a*
(ab)*
((b|(aa))|(((a(bb))((bb)|(a(bb)))*)(aa)))*((a?)|(((a(bb))((bb)|(a(bb)))*)(a?)))
a*((b|bb)aa*)*(b|bb|a*)
(aa|bb)*((ba|ab)(bb|aa)*(ba|ab)(bb|aa)*)*(aa|bb)*
((a(ab)*(b|aa))|(b(ba)*(a|bb)))*
a*b*a*b*
Equivalent PEG expressionswere defined as well in every comparable library (see
Table 2).
Table 3 summarizes CPU time results. Every row contains the means for 30 runs. In all experiments we used the implementation of algorithms written in Python (our PEG library, Grako, and Arpeggio) and C
++ EGG. An interpreter ran on a four-core Intel i7-965, 3.2 GHz processor in a Windows 10 operating system with 12 GB RAM.
As can be seen, in all cases our library worked much faster than other Python libraries. Grammar 3 was skipped because we were unable to define it either by means of the Arpeggio or Grako libraries. It should be stated, however, that both of the libraries have more functionality than our PEG library, its principal function being only the membership operation, i.e., matching or not a word to a PEG. As a result, Arpeggio, Grako, and pyPeg are relatively not intuitive and obvious, especially for users not familiarized with formal languages theory. The dash character in the EGG result denotes segmentation runtime error. As expected the C++ library (EGG) overcame its Python counterparts.
4. Results and Discussion
The algorithm for generating non-circular parsing expression grammars (PEG) was tested over a recently published amyloidogenic dataset [
20]. The GP parameters (John Koza, a GP pioneer, has introduced a very lucid form of listing parameters in the tableau of
Table 4 named after him) are listed in
Table 4. From there, we can read that a population size of
individuals were used for GP runs along with others. The terminal set contains standard amino acid abbreviations; “A” stands for Alanine, “R” for Arginine, etc. Concerning the initialization method, see
Section 3.2. The best parameters were chosen in a trial-and-error manner until the values with the best classification quality were found. The dataset is composed of 1476 strings that represent protein fragments. The data came from four databases as shown in
Figure 4 and
Figure 5. A total of 439 are classified as being amyloidogenic (examples), and 1037 as not (counter-examples). The shortest sequence length is 4 and the longest is 83. Such a wide range of sequence lengths was an additional impediment to learning algorithms.
In order to compare our algorithm to other grammatical inference approaches, we took most of the methods mentioned in the introductory section as a reference. Error-correcting grammatical inference [
9] (ECGI) and alignment-based learning [
10] (ABL) are examples of substring-based algorithms. The former builds an automaton incrementally based on the Levenstein distance between the closest word stored in the automaton and an inserted word. This process begins with an empty automaton, and for each word adds the error rules (insertion, substitution, and deletion) belonging to the transition path with the least number of error rules. The algorithm provides an automaton without loops that is more and more general. The latter, ABL, is based on searching identical and distinct parts of input words. This algorithm consists of two stages. First, all words are aligned such that it finds a shared and a distinct part of all pairs of words, suggesting that the distinct parts have the same type. For example, consider the pair “abcd” and “abe”. Here, “cd” and “e” are correctly identified as examples of the same type. The second step, which takes the same corpus as input, tries to identify the right constituents. Because the generated constituents found in the previous step might overlap, the correct ones have to be selected. Simple heuristics are used to achieve this, for example to take the constituent that was generated first (ABL-first) or to take the constituent with the highest score on some probabilistic function. We used another approach, in which all constituents are stored, but in the end we tried to keep only the minimum number of constituents that cover all examples.
ADIOS uses statistical information present in sequential data to identify significant segments and to distill rule-like regularities that support structured generalization [
8]. It also brings together several crucial conceptual components; the structures it learns are (i) variable-order, (ii) hierarchically composed, (iii) context dependent, (iv) supported by a previously undocumented statistical significance criterion, and (v) dictated solely by the corpus at hand.
Blue-fringe [
21] and Traxbar [
22], the instances of state merging algorithms, can be downloaded from an internet archive (
http://abbadingo.cs.nuim.ie/dfa-algorithms.tar.gz). They start from building a prefix tree acceptor (PTA) based on examples, and then iteratively select two states and do merging unless compatibility is broken. The difference between them comes from many ways in which the pair of states needed to merge can be chosen. Trakhtenbrot and Barzdin [
23] described an algorithm for constructing the smallest deterministic FSA consistent with a complete labeled training set. The PTA is squeezed into a smaller graph by merging all pairs of states that represent compatible mappings from word suffixes to labels. This algorithm for completely labeled trees was generalized by Lang (1992) [
22] to produce a (not necessarily minimum) automaton consistent with a sparsely labeled tree. Blue-fringe grows a connected set of red nodes that are known to be unique states, surrounded by a fringe of blue nodes that will either be merged with red nodes or promoted to red status. Merges only occur between red nodes and blue nodes. Blue nodes are known to be the roots of trees, which greatly simplifies the code for correct merging.
We also included one machine learning approach. An unsupervised data-driven distributed representation, called ProtVec [
24], was applied and protein family classification was performed using a support vector machine classifier (SVM) [
25] with the linear kernel.
The data were randomly split into two subsets, a training (75% of total) and a test set (25% of total). Given the training set and the test set, we used all algorithms to infer predictors (automata or grammars) on the training set, tested them on the test set, and computed their performances. Comparative analyses of the following five measures: Precision, Recall, F-score, the AUC, and Matthews correlation coefficient are summarized in
Table 5. The measures are given below:
Precision, ;
Recall, ;
F-score, ;
Accuracy, ;
Area under the ROC curve, ;
Matthews correlation coefficient, ;
where the terms true positives (tp), true negatives (tn), false positives (fp), and false negatives (fn) compare the results of the classifier under test with trusted external judgments. Thus, in our case, tp is the number of correctly recognized amyloids, fp is the number of nonamyloids recognized as amyloids, fn is the number of amyloids recognized as nonamyloids, and tn is the number of correctly recognized nonamyloids. The last column concerns CPU time of computations (induction plus classification in s).
The results show that there is no single method that outperformed the remaining methods regardless of an established classification measure. However, the methods can be grouped as relatively good and relatively weak from a certain angle. As regards Recall and F-score, relatively good are Blue-fringe, ADIOS, and PEG. As regards MCC, which is generally recognized as being one of the best classification measures, relatively good are PEG and ABL. Moreover, PEG achieved the best AUC, which in the case of binary prediction is equivalent to balanced accuracy.
To evaluate the convergence toward an optimal solution, we studied average fitness change over generations along with the increasing of the expression sizes (see
Figure 6). The shape of the plot does not show any indication of premature convergence. Moreover, we did not observe excessive tree size expansion, which is quite often seen in genetic programming.
All programs ran on an Intel Xeon CPU E5-2650 v2, 2.6 GHz processor under an Ubuntu 16.04 operating system with 192 GB RAM. The computational complexity of all the algorithms is polynomially bounded; however, the differences in running time were quite significant and our approach ranked at the top. The algorithm for PEG induction (
https://github.com/wieczorekw/wieczorekw.github.io/tree/master/PEG) was written in the Python 3 programming language. The languages of implementation for six successive methods were: Python, Java, C, Python, C, and Python.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}