PrimaVera: Synergising Predictive Maintenance

 , , , , , , , , and
, , , , , , , , and 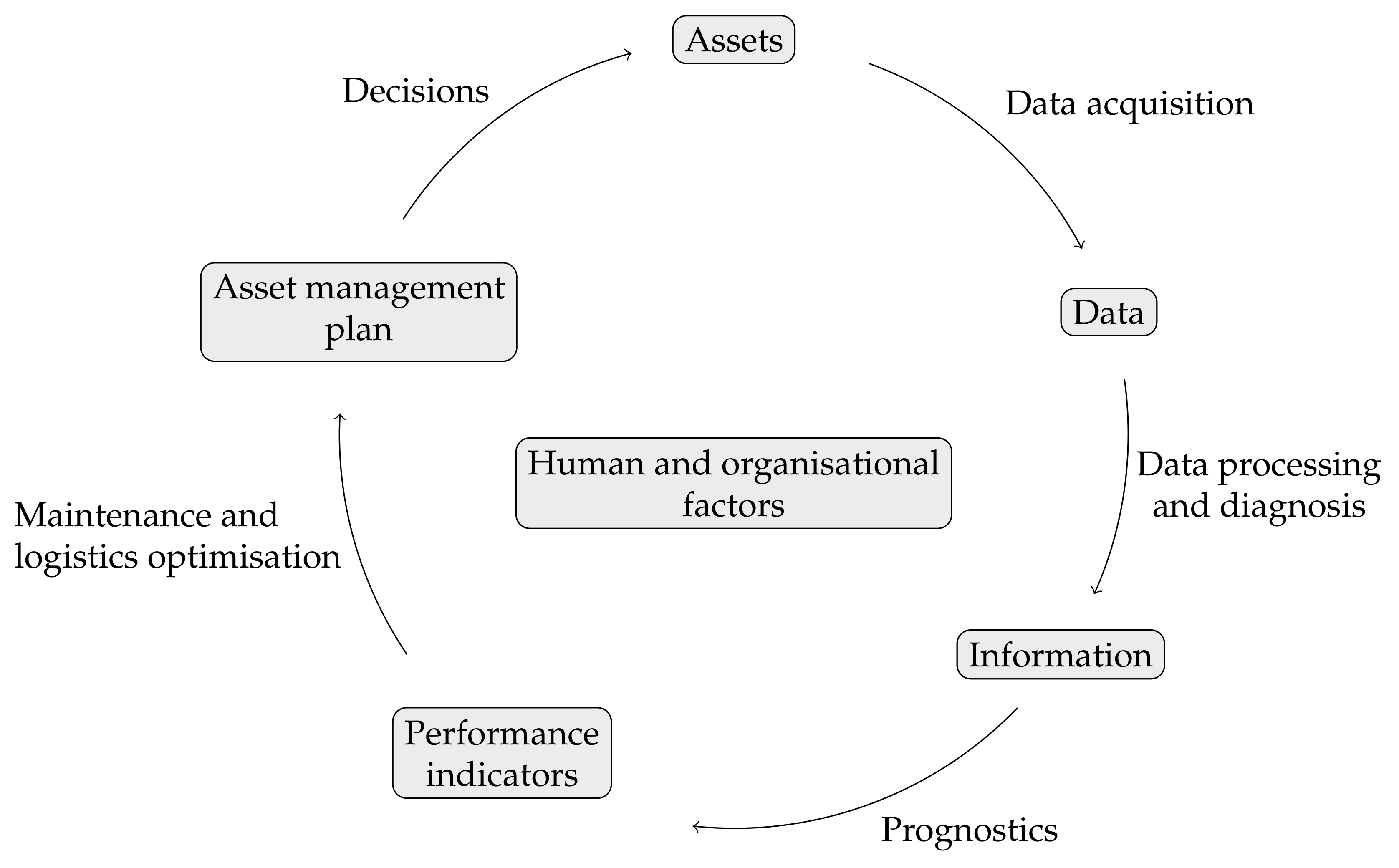{kind=link}
Abstract
1. Introduction
2. State of the Art
2.1. Data Acquisition
2.2. Data Processing and Diagnostics
2.3. Prognostics
2.4. Maintenance and Logistics Optimisation
2.5. Asset Management and Organisational Factors
“Preventive water filling based on real-time water level data and a predictive model seems to be an appropriate maintenance strategy; however, this requires the dynamic usage of human resources and filling stations … Trains move, making the logistic puzzle more complicated … Our overall goal is to maximise the availability of trains with functioning toilets in a cost-effective way.”
2.6. Human Factors
3. Obstacles to Overcome
3.1. Orchestration
3.2. Automation
3.3. Data Uncertainty
3.4. Human and Organisational Factors
4. Predictive Maintenance Process Model
4.1. PrimaVera Approach
4.1.1. Data Acquisition
4.1.2. Data Processing and Diagnostics
4.1.3. Prognostics
4.1.4. Maintenance and Logistics Optimisation
4.1.5. Decisions
5. Methodology
5.1. Demonstrators
- Health assessment and prognostics tool for infrastructure related equipment (PLC, e-drive). This demonstrator tool will implement the data collection, diagnostic and prognostic methods into a practical software tool that enables an asset owner to assess the system’s health and predict future failures.
- Planning and maintenance tool to optimise service logistics (high-tech). This demonstrator tool will implement the maintenance and supply chain optimisation methods into a user-friendly software tool.
- Digital twin to support ship maintenance fed by real-time sensor data (maritime). The digital twin is a computer model representing the physical components and functions of (part of) a real ship, as well as its degradation behaviour. By feeding sensor data from the real ship into its digital twin, the actual status can be used as starting point for the simulation of various scenarios. User-friendly visualisation capabilities then enable to present the present and future status of on-board critical systems, which will support maintenance decision making.
Implementation of Demonstrators
6. The Consortium
- Infrastructure
- Rijkswaterstaat, Rolsch Asset Management, Waterboard de Dommel
- High-tech
- ASML, Technobis, Nederlandse Spoorwegen, ORTEC
- Maritime
- Damen Shipyards, Alfa Laval, Royal IHC, Royal Netherlands Navy
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mobley, R.K. An Introduction to Predictive Maintenance, 2nd ed.; Butterworth-Heinemann: Oxford, UK, 2002. [Google Scholar] [CrossRef]
- Lee, J.; Kao, H.A.; Yang, S. Service Innovation and Smart Analytics for Industry 4.0 and Big Data Environment. Procedia CIRP 2014, 16, 3–8. [Google Scholar] [CrossRef]
- Thomas, D.S. The Costs and Benefits of Advanced Maintenance in Manufacturing; Advanced Manufacturing Series (NIST AMS 100-18); US Department of Commerce, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2018. [CrossRef]
- Tiddens, W.W.; Braaksma, A.J.J.; Tinga, T. The adoption of prognostic technologies in maintenance decision making: A multiple case study. Procedia CIRP 2015, 38, 171–176. [Google Scholar] [CrossRef]
- De Jonge, B.; Scarf, P. A review on maintenance optimization. Eur. J. Oper. Res. 2020, 285, 805–824. [Google Scholar] [CrossRef]
- Kowalkowski, C.; Gebauer, H.; Oliva, R. Service growth in product firms: Past, present, and future. Ind. Mark. Manag. 2017, 60, 82–88. [Google Scholar] [CrossRef]
- Sipos, R.; Fradkin, D.; Moerchen, F.; Wang, Z. Log-based predictive maintenance. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1867–1876. [Google Scholar] [CrossRef]
- McFadden, P.; Smith, J. Vibration monitoring of rolling element bearings by the high-frequency resonance technique—A review. Tribol. Int. 1984, 17, 3–10. [Google Scholar] [CrossRef]
- Atat, R.; Liu, L.; Wu, J.; Li, G.; Ye, C.; Yang, Y. Big Data Meet Cyber-Physical Systems: A Panoramic Survey. IEEE Access 2018, 6, 73603–73636. [Google Scholar] [CrossRef]
- Wagner, C.; Hellingrath, B. Implementing Predictive Maintenance in a Company: Industry Insights with Expert Interviews. In Proceedings of the 2019 IEEE International Conference on Prognostics and Health Management (ICPHM), San Francisco, CA, USA, 17–20 June 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Shearer, C. The CRISP-DM Model: The New Blueprint for Data Mining. J. Data Warehous. 2000, 5, 13–22. [Google Scholar]
- Guo, H.Y.; Zhang, L.; Zhang, L.L.; Zhou, J.X. Optimal placement of sensors for structural health monitoring using improved genetic algorithms. Smart Mater. Struct. 2004, 13, 528–534. [Google Scholar] [CrossRef]
- Yi, T.H.; Li, H.N.; Gu, M. A new method for optimal selection of sensor location on a high-rise building using simplified finite element model. Struct. Eng. Mech. 2011, 37, 671–684. [Google Scholar] [CrossRef]
- Debouk, R.; Lafortune, S.; Teneketzis, D. On an optimization problem in sensor selection for failure diagnosis. In Proceedings of the 38th IEEE Conference on Decision and Control (Cat. No.99CH36304), Phoenix, AZ, USA, 7–10 December 1999; Volume 5, pp. 4990–4995. [Google Scholar]
- Molodova, M.; Oregui, M.; Nunez, A.; Li, Z.; Moraal, J.; Dollevoet, R. Axle box acceleration for health monitoring of insulated joints: A case study in the Netherlands. In Proceedings of the 17th IEEE International Conference on Intelligent Transportation Systems, Qingdao, China, 8–11 October 2014. [Google Scholar] [CrossRef]
- Feng, M.; Fukuda, Y.; Mizuta, M.; Ozer, E. Citizen Sensors for SHM: Use of Accelerometer Data from Smartphones. Sensors 2015, 15, 2980–2998. [Google Scholar] [CrossRef]
- Seraj, F.; Meratnia, N.; Havinga, P.J. RoVi: Continuous transport infrastructure monitoring framework for preventive maintenance. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications (PerCom), Kona, HI, USA, 13–17 March 2017. [Google Scholar] [CrossRef]
- Alani, A.M.; Tosti, F.; Ciampoli, L.B.; Gagliardi, V.; Benedetto, A. An integrated investigative approach in health monitoring of masonry arch bridges using GPR and InSAR technologies. NDT E Int. 2020, 115. [Google Scholar] [CrossRef]
- Kusiak, A. Smart manufacturing. Int. J. Prod. Res. 2018, 56, 508–517. [Google Scholar] [CrossRef]
- Donders, A.; Van Der Heijden, G.J.; Stijnen, T.; Moons, K.G. A gentle introduction to imputation of missing values. J. Clin. Epidemiol. 2006, 59, 1087–1091. [Google Scholar] [CrossRef] [PubMed]
- Little, R.J.; Rubin, D.B. Statistical Analysis with Missing Data; John Wiley & Sons: Hoboken, NJ, USA, 2019; Volume 793. [Google Scholar]
- Koopmans, F.; Cornelisse, L.N.; Heskes, T.; Dijkstra, T.M. Empirical Bayesian random censoring threshold model improves detection of differentially abundant proteins. J. Proteome Res. 2014, 13, 3871–3880. [Google Scholar] [CrossRef]
- Cui, R.; Bucur, I.G.; Groot, P.; Heskes, T. A novel Bayesian approach for latent variable modeling from mixed data with missing values. Stat. Comput. 2019, 29, 977–993. [Google Scholar] [CrossRef]
- Cui, R.; Groot, P.; Heskes, T. Learning causal structure from mixed data with missing values using Gaussian copula models. Stat. Comput. 2019, 29, 311–333. [Google Scholar] [CrossRef]
- Candès, E.J.; Recht, B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009, 9, 717. [Google Scholar] [CrossRef]
- Mardani, M.; Mateos, G.; Giannakis, G.B. Subspace learning and imputation for streaming big data matrices and tensors. IEEE Trans. Signal Process. 2015, 63, 2663–2677. [Google Scholar] [CrossRef]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. In Proceedings of the 23rd Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 2080–2088. [Google Scholar]
- Xiong, L.; Chen, X.; Schneider, J. Direct robust matrix factorization for anomaly detection. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 844–853. [Google Scholar] [CrossRef]
- Weese, M.; Martinez, W.; Megahed, F.M.; Jones-Farmer, L.A. Statistical Learning Methods Applied to Process Monitoring: An Overview and Perspective. J. Qual. Technol. 2016, 48, 4–24. [Google Scholar] [CrossRef]
- Capizzi, G.; Masarotto, G. A least angle regression control chart for multidimensional data. Technometrics 2011, 53, 285–296. [Google Scholar] [CrossRef]
- Kenbeek, T.; Kapodistria, S.; Di Bucchianico, A. Data-driven online monitoring of wind turbines. In Proceedings of the 12th EAI International Conference on Performance Evaluation Methodologies and Tools, Palma de Mallorca, Spain, 13–15 March 2019; pp. 143–150. [Google Scholar] [CrossRef]
- Wang, L.; Long, H.; Zhang, Z.; Xu, J.; Liu, R. Wind turbine gearbox failure monitoring based on SCADA data analysis. In Proceedings of the Power and Energy Society General Meeting (PESGM), Boston, MA, USA, 17–21 July 2016; pp. 1–5. [Google Scholar]
- Tinga, T.; Loendersloot, R. Physical Model-Based Prognostics and Health Monitoring to Enable Predictive Maintenance. In Predictive Maintenance in Dynamic Systems; Lughofer, E., Sayed-Mouchaweh, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; pp. 313–353. [Google Scholar] [CrossRef]
- Pearl, J.; Mackenzie, D. The Book of Why: The New Science of Cause and Effect; Basic Books: New York, NY, USA, 2018. [Google Scholar]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef]
- Sigtermans, D.; Fussenich, R.; Kielczewski, A.; Zalmijn, E.; Brunt, M.; Voinea, S.L. Methods of Modelling Systems or Performing Predictive Maintenance of Lithographic Systems. U.S. Patent Application No. 15/760228, 20 November 2018. [Google Scholar]
- Claassen, T.; Heskes, T. A Bayesian approach to constraint based causal inference. In Proceedings of the UAI 2012, 28th Conference on Uncertainty in Artificial Intelligence, Catalina Island, CA, USA, 15–17 August 2012; pp. 207–216. [Google Scholar]
- Spirtes, P.; Zhang, K. Causal discovery and inference: Concepts and recent methodological advances. In Applied Informatics; Springer: Berlin/Heidelberg, Germany, 2016; Volume 3. [Google Scholar] [CrossRef]
- Hlinka, J.; Hartman, D.; Vejmelka, M.; Runge, J.; Marwan, N.; Kurths, J.; Paluš, M. Reliability of inference of directed climate networks using conditional mutual information. Entropy 2013, 15, 2023–2045. [Google Scholar] [CrossRef]
- Vicente, R.; Wibral, M.; Lindner, M.; Pipa, G. Transfer entropy—A model-free measure of effective connectivity for the neurosciences. J. Comput. Neurosci. 2011, 30, 45–67. [Google Scholar] [CrossRef] [PubMed]
- Sachs, K.; Perez, O.; Pe’er, D.; Lauffenburger, D.A.; Nolan, G.P. Causal protein-signaling networks derived from multiparameter single-cell data. Science 2005, 308, 523–529. [Google Scholar] [CrossRef] [PubMed]
- Sokolova, E.; Oerlemans, A.M.; Rommelse, N.N.; Groot, P.; Hartman, C.A.; Glennon, J.C.; Claassen, T.; Heskes, T.; Buitelaar, J.K. A causal and mediation analysis of the comorbidity between attention deficit hyperactivity disorder (ADHD) and autism spectrum disorder (ASD). J. Autism Dev. Disord. 2017, 47, 1595–1604. [Google Scholar] [CrossRef] [PubMed]
- Rommel, D.; Di Maio, D.; Tinga, T. Calculating loads and life-time reduction of wind turbine gearbox and generator bearings due to shaft misalignment. Wind Eng. 2020. [Google Scholar] [CrossRef]
- Meghoe, A.; Loendersloot, R.; Tinga, T. Rail wear and remaining life prediction using meta-models. Int. J. Rail Transp. 2020, 8, 1–26. [Google Scholar] [CrossRef]
- Woldman, M.; Tinga, T.; van der Heide, E.; Masen, M. Abrasive wear based predictive maintenance for systems operating in sandy conditions. Wear 2015, 338–339, 316–324. [Google Scholar] [CrossRef]
- Ruijters, E.; Guck, D.; Drolenga, P.; Peters, M.; Stoelinga, M. Maintenance analysis and optimization via statistical model checking: Evaluating a train pneumatic compressor. In Proceedings of the QEST 2016: 13th International Conference on Quantitative Evaluation of SysTems, Québec City, QC, Canada, 23–25 August 2016; Agha, G., Van Houdt, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 331–347. [Google Scholar]
- Tinga, T. Application of physical failure models to enable usage and load based maintenance. Reliab. Eng. Syst. Saf. 2010, 95, 1061–1075. [Google Scholar] [CrossRef]
- Tiddens, W.W.; Braaksma, A.J.J.; Tinga, T. Towards Informed Maintenance Decision Making: Guiding the Application of Advanced Maintenance Analyses. In Optimum Decision Making in Asset Management; IGI Global: Hershey, PA, USA, 2016; Chapter 13; pp. 288–309. [Google Scholar] [CrossRef]
- ten Zeldam, S.; de Jong, A.; Loendersloot, R.; Tinga, T. Automated Failure Diagnosis in Aviation Maintenance Using eXplainable Artificial Intelligence (XAI). In Proceedings of the European Conference of the PHM Society, 4th European Conference of the Prognostics and Health Management Society, PHME 2018—Muntgebouw Utrecht, Utrecht, The Netherlands, 3–6 July 2018; Volume 4. [Google Scholar]
- Barlow, R.; Hunter, L. Optimum preventive maintenance policies. Oper. Res. 1960, 8, 90–100. [Google Scholar] [CrossRef]
- Olde Keizer, M.C.; Flapper, S.D.P.; Teunter, R.H. Condition-based maintenance policies for systems with multiple dependent components: A review. Eur. J. Oper. Res. 2017, 261, 405–420. [Google Scholar] [CrossRef]
- Zhu, Q. Maintenance Optimization for Multi-Component Systems under Condition Monitoring. Ph.D. Thesis, Eindhoven University of Technology, Eindhoven, The Netherlands, 2015. [Google Scholar]
- Arts, J.; Basten, R. Design of multi-component periodic maintenance programs with single-component models. IISE Trans. 2018, 50, 606–615. [Google Scholar] [CrossRef]
- Van Horenbeek, A.; Buré, J.; Cattrysse, D.; Pintelon, L.; Vansteenwegen, P. Joint maintenance and inventory optimization systems: A review. Int. J. Prod. Econ. 2013, 143, 499–508. [Google Scholar] [CrossRef]
- Basten, R.; Ryan, J. The value of maintenance delay flexibility for improved spare parts inventory management. Eur. J. Oper. Res. 2019, 278, 646–657. [Google Scholar] [CrossRef]
- uit het Broek, M.A.; Teunter, R.H.; de Jonge, B.; Veldman, J.; Van Foreest, N.D. Condition-based production planning: Adjusting production rates to balance output and failure risk. Manuf. Serv. Oper. Manag. 2019, 22, 645–867. [Google Scholar] [CrossRef]
- Karabağ, O.; Eruguz, A.S.; Basten, R. Integrated optimization of maintenance interventions and spare part selection for a partially observable multi-component system. Reliab. Eng. Syst. Saf. 2020, 200, 106955. [Google Scholar] [CrossRef]
- Carr, S.; Jansen, N.; Wimmer, R.; Serban, A.C.; Becker, B.; Topcu, U. Counterexample-Guided Strategy Improvement for POMDPs Using Recurrent Neural Networks. arXiv 2019, arXiv:1903.08428. [Google Scholar]
- Ravdeep, K.; Adithya, T.; Sarbjeet, S.; Martinetti, A. Big Data Analytics for Maintaining Transportation Systems. In Transportation Systems; Springer: Berlin/Heidelberg, Germany, 2004; Chapter 6; pp. 85-1–85-11. [Google Scholar] [CrossRef]
- van de Kerkhof, R. It’s about Time: Managing Implementation Dynamics of Condition-Based Maintenance. Ph.D. Thesis, University of Tilburg, Tilburg, The Netherlands, 2020. [Google Scholar]
- Garg, A.; Deshmukh, S.G. Maintenance management: Literature review and directions. J. Qual. Maint. Eng. 2006, 12, 205–238. [Google Scholar] [CrossRef]
- van de Kerkhof, R.; Akkermans, H.A. Noorderhaven, N. Knowledge Lost in Data: Organizational Impediments to Condition-Based Maintenance in the Process Industry. In Logistics and Supply Chain Innovation; Springer: Berline/Heidelberg, Germany, 2015; p. 19. [Google Scholar]
- Veldman, J.; Wortmann, H.; Klingenberg, W. Typology of condition based maintenance. J. Qual. Maint. Eng. 2011, 17, 183–202. [Google Scholar] [CrossRef]
- Tiddens, W.W.; Braaksma, A.J.J.; Tinga, T. Selecting Suitable Candidates for Predictive Maintenance. Int. J. Progn. Health Manag. 2018, 9, 20. [Google Scholar]
- Ruitenburg, R.J.; Braaksma, A.J.J. Mitigating change in the goals and context of capital assets: Design of the Lifetime Impact Identification Analysis. CIRP J. Manuf. Sci. Technol. 2017, 17, 50–59. [Google Scholar] [CrossRef]
- Koochaki, J. CBM in Multi-Component Systems. Ph.D. Thesis, University of Groningen, Groningen, The Netherlands, 2012. Available online: https://www.rug.nl/ (accessed on 31 July 2020).
- Martinetti, A.; Moerman, J.J.; van Dongen, L.A. Storytelling as a strategy in managing complex systems: Using antifragility for handling an uncertain future in reliability. Saf. Reliab. 2017, 37, 233–247. [Google Scholar] [CrossRef]
- van Aken, J.E.; Chandrasekaran, A.; Halman, J. Conducting and publishing design science research: Inaugural essay of the design science department of the Journal of Operations Management. J. Oper. Manag. 2016, 47–48, 1–8. [Google Scholar] [CrossRef]
- Wieringa, R.J. Design science methodology: For information systems and software engineering. In Design Science Methodology: For Information Systems and Software Engineering; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–332. [Google Scholar] [CrossRef]
- Bendoly, E.; Donohue, K.; Schultz, K.L. Behavior in operations management: Assessing recent findings and revisiting old assumptions. J. Oper. Manag. 2006, 24, 737–752. [Google Scholar] [CrossRef]
- Gino, F.; Pisano, G. Toward a Theory of Behavioral Operations. Manuf. Serv. Oper. Manag. 2008, 10, 676–691. [Google Scholar] [CrossRef]
- von Neumann, J.; Morgenstern, O. Theory of Games and Economic Behavior. J. Philos. 1945, 42, 550. [Google Scholar] [CrossRef]
- Donohue, K.; Özer, Ö.; Zheng, Y. Behavioral Operations: Past, Present, and Future. Manuf. Serv. Oper. Manag. 2020, 22, 191–202. [Google Scholar] [CrossRef]
- Dietvorst, B.J.; Simmons, J.P.; Massey, C. Algorithm aversion: People erroneously avoid algorithms after seeing them err. J. Exp. Psychol. Gen. 2015, 144, 114–126. [Google Scholar] [CrossRef]
- Efendić, E.; Van de Calseyde, P.P.; Evans, A.M. Slow response times undermine trust in algorithmic (but not human) predictions. Organ. Behav. Hum. Decis. Process. 2020, 157, 103–114. [Google Scholar] [CrossRef]
- Manyika, J.; Chui, M.; Bisson, P.; Woetzel, J.; Dobbs, R.; Bughin, J.; Aharon, D. The Internet of Things: Mapping the Value beyond the Hype; Technical Report; McKinsey Global Institute: New York, NY, USA, 2015. [Google Scholar]
- Haarman, M.; Mulders, M.; Vassiliadis, C. Predictive Maintenance 4.0: Predict the Unpredictable; Technical Report; PwC Netherlands and Mainnovation: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Bokrantz, J.; Skoogh, A.; Berlin, C.; Stahre, J. Maintenance in digitalised manufacturing: Delphi-based scenarios for 2030. Int. J. Prod. Econ. 2017, 191, 154–169. [Google Scholar] [CrossRef]
- Heng, A.; Zhang, S.; Tan, A.C.; Mathew, J. Rotating machinery prognostics: State of the art, challenges and opportunities. Mech. Syst. Signal Process. 2009, 23, 724–739. [Google Scholar] [CrossRef]
- Kipper, L.M.; Furstenau, L.B.; Hoppe, D.; Frozza, R.; Iepsen, S. Scopus scientific mapping production in industry 4.0 (2011–2018): A bibliometric analysis. Int. J. Prod. Res. 2020, 58, 1605–1627. [Google Scholar] [CrossRef]
- Sun, B.; Zeng, S.; Kang, R.; Pecht, M.G. Benefits and Challenges of System Prognostics. IEEE Trans. Reliab. 2012, 61, 323–335. [Google Scholar] [CrossRef]
- Jardine, A.K.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Javed, K.; Gouriveau, R.; Zerhouni, N.; Nectoux, P. Enabling Health Monitoring Approach Based on Vibration Data for Accurate Prognostics. IEEE Trans. Ind. Electron. 2015, 62, 647–656. [Google Scholar] [CrossRef]
- Vachtsevanos, G.; Goebel, K. Introduction to Prognostics. 2015. Available online: https://www.phmsociety.org/sites/phmsociety.org/files/PROGNOSTICS_TUTORIAL.pdf (accessed on 23 November 2020).
- Vachtsevanos, G.J.; Valavanis, K.P. A Novel Approach to Integrated Vehicle Health Management; Technical Report; NATO STO: Brussels, Belgium, 2018. [Google Scholar] [CrossRef]
- Benedettini, O.; Baines, T.S.; Lightfoot, H.W.; Greenough, R.M. State-of-the-art in integrated vehicle health management. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2009, 223, 157–170. [Google Scholar] [CrossRef]
- Ran, Y.; Zhou, X.; Lin, P.; Wen, Y.; Deng, R. A Survey of Predictive Maintenance: Systems, Purposes and Approaches. arXiv 2019, arXiv:eess.SP/1912.07383. [Google Scholar]
- Lee, J.; Jin, C.; Liu, Z.; Davari Ardakani, H. Introduction to Data-Driven Methodologies for Prognostics and Health Management. In Probabilistic Prognostics and Health Management of Energy Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 9–32. [Google Scholar] [CrossRef]
- Jin, X.; Siegel, D.; Weiss, B.A.; Gamel, E.; Wang, W.; Lee, J.; Ni, J. The present status and future growth of maintenance in US manufacturing: Results from a pilot survey. Manuf. Rev. 2016, 3, 10. [Google Scholar] [CrossRef]
- Hevner, A.; March, S.T.; Park, J.; Ram, S. Design Science in Information Systems Research. MIS Q. 2004, 28, 75. [Google Scholar] [CrossRef]
- Peffers, K.; Tuunanen, T.; Rothenberger, M.A.; Chatterjee, S. A Design Science Research Methodology for Information Systems Research. J. Manag. Inf. Syst. 2007, 24, 45–77. [Google Scholar] [CrossRef]
- Asset Management—Overview, Principles and Terminology; Standard, International Organization for Standardization: Geneva, Switzerland, 2014.
- Tiddens, W.W.; Braaksma, J.; Tinga, T. Exploring predictive maintenance applications in industry. J. Qual. Maint. Eng. 2020. [Google Scholar] [CrossRef]
- Gupta, V.; Sharma, M.; Thakur, N. Optimization Criteria for Optimal Placement of Piezoelectric Sensors and Actuators on a Smart Structure: A Technical Review. J. Intell. Mater. Syst. Struct. 2010, 21, 1227–1243. [Google Scholar] [CrossRef]
- Ribeiro, F. Machinery Fault Database. 2017. Available online: http://www02.smt.ufrj.br/~offshore/mfs/index.html (accessed on 11 September 2020).
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Sankararaman, S.; Goebel, K. Uncertainty in prognostics and systems health management. Int. J. Progn. Health Manag. 2015, 6. [Google Scholar]
- Liu, D.; Luo, Y.; Peng, Y. Uncertainty processing in prognostics and health management: An overview. In Proceedings of the IEEE 2012 Prognostics and System Health Management Conference (PHM-2012 Beijing), Beijing, China, 23–25 May 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Ng, K.C.; Abramson, B. Uncertainty management in expert systems. IEEE Expert 1990, 5, 29–48. [Google Scholar] [CrossRef]
- van der Hofstad, R. Random Graphs and Complex Networks; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar] [CrossRef]
- Imbens, G.W.; Rubin, D.B. Causal Inference for Statistics, Social, and Biomedical Sciences; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar] [CrossRef]
- Kenett, R.S. On generating high InfoQ with Bayesian networks. Qual. Technol. Quant. Manag. 2016, 13, 309–332. [Google Scholar] [CrossRef]
- Nielsen, T.D.; Jensen, F.V. Bayesian Networks and Decision Graphs; Springer: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Ding, M.; Chen, Y.; Bressler, S.L. Granger Causality: Basic Theory and Application to Neuroscience. In Handbook of Time Series Analysis; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2006; Chapter 17; pp. 437–460. [Google Scholar] [CrossRef]
- Duan, P.; Yang, F.; Chen, T.; Shah, S.L. Direct Causality Detection via the Transfer Entropy Approach. IEEE Trans. Control Syst. Technol. 2013, 21, 2052–2066. [Google Scholar] [CrossRef]
- Lee, J.; Wu, F.; Zhao, W.; Ghaffari, M.; Liao, L.; Siegel, D. Prognostics and health management design for rotary machinery systems—Reviews, methodology and applications. Mech. Syst. Signal Process. 2014, 42, 314–334. [Google Scholar] [CrossRef]
- Schwabacher, M.; Goebel, K. A Survey of Artificial Intelligence for Prognostics; Aritficial Intelligence for Prognostics; The AAAI Press: Menlo Park, CA, USA, 2007; pp. 108–115. [Google Scholar]
- Tinga, T. Principles of Loads and Failure Mechanisms; Springer: London, UK, 2013. [Google Scholar] [CrossRef]
- Ruijters, E.; Guck, D.; Drolenga, P.; Stoelinga, M. Fault maintenance trees: Reliability centered maintenance via statistical model checking. In Proceedings of the 2016 Annual Reliability and Maintainability Symposium (RAMS), Tucson, AZ, USA, 25–28 January 2016; pp. 1–6. [Google Scholar]
- Nauta, M.; Bucur, D.; Stoelinga, M. LIFT: Learning Fault Trees from Observational Data. In Proceedings of the 15th International Conference on Quantitative Evaluation of Systems; Lecture Notes in Computer Science; McIver, A., Horváth, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11024, pp. 306–322. [Google Scholar] [CrossRef]
- Linard, A.; Bucur, D.; Stoelinga, M. Fault Trees from Data: Efficient Learning with an Evolutionary Algorithm. In Proceedings of the 5th International Symposium on Dependable Software Engineering: Theories, Tools, and Applications SETTA; Lecture Notes in Computer Science; Guan, N., Katoen, J., Sun, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11951, pp. 19–37. [Google Scholar] [CrossRef]
- Yamada, S.; Osaki, S. Software Reliability Growth Modeling: Models and Applications. IEEE Trans. Softw. Eng. 1985, SE-11, 1431–1437. [Google Scholar] [CrossRef]
- Jatain, A.; Mehta, Y. Metrics and models for Software Reliability: A systematic review. In Proceedings of the International Conference on Issues and Challenges in Intelligent Computing Techniques (ICICT), Ghaziabad, India, 7–8 February 2014; pp. 210–214. [Google Scholar] [CrossRef]
- Tian, L.; Noore, A. Evolutionary neural network modeling for software cumulative failure time prediction. Reliab. Eng. Syst. Saf. 2005, 87, 45–51. [Google Scholar] [CrossRef]
- Li, Z. Using Data Mining Techniques to Improve Software Reliability. Ph.D. Thesis, University of Illinois, Champaign, IL, USA, 2006. [Google Scholar]
- Heijblom, R.; Postma, W.; Natarajan, V.; Stoelinga, M. DFT Analysis Incorporating Spare Parts in Fault Trees. In Proceedings of the 2018 Annual Reliability and Maintainability Symposium (RAMS), Reno, NV, USA, 22–25 January 2018; pp. 1–7. [Google Scholar]
- Basten, R.J.I.; van Houtum, G.J. System-oriented inventory models for spare parts. Surv. Oper. Res. Manag. Sci. 2014, 19, 34–55. [Google Scholar] [CrossRef]
- Häkkinen, L.; Hilmola, O. Life after ERP implementation: Long-term development of user perceptions of system success in an after-sales environment. J. Enterp. Inf. Manag. 2008, 21, 285–310. [Google Scholar] [CrossRef]
- Venkatesh, V.; Bala, H. Technology Acceptance Model 3 and a Research Agenda on Interventions. Decis. Sci. 2008, 39, 273–315. [Google Scholar] [CrossRef]
- Venkatesh, V.; Morris, M.G.; Davis, G.B.; Davis, F.D. User Acceptance of Information Technology: Toward a Unified View. Manag. Inf. Syst. Q. 2003, 27. [Google Scholar] [CrossRef]
- Wiers, V. The relationship between shop floor autonomy and APS implementation success: Evidence from two cases. Prod. Plan. Control 2009, 20, 576–585. [Google Scholar] [CrossRef]
- Fildes, R.; Goodwin, P.; Lawrence, M.; Nikolopoulos, K. Effective forecasting and judgmental adjustments: An empirical evaluation and strategies for improvement in supply-chain planning. Int. J. Forecast. 2009, 25, 3–23. [Google Scholar] [CrossRef]
- Stringer, E. Action Research, 4th ed.; SAGE Publications, Inc.: Los Angeles, CA, USA, 2013. [Google Scholar]
- Ebert, C.; Gallardo, G.; Hernantes, J.; Serrano, N. DevOps. IEEE Softw. 2016, 33, 94–100. [Google Scholar] [CrossRef]
- Boettiger, C. An Introduction to Docker for Reproducible Research. SIGOPS Oper. Syst. Rev. 2015, 49, 71–79. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ton, B.; Basten, R.; Bolte, J.; Braaksma, J.; Di Bucchianico, A.; van de Calseyde, P.; Grooteman, F.; Heskes, T.; Jansen, N.; Teeuw, W.; et al. PrimaVera: Synergising Predictive Maintenance. Appl. Sci. 2020, 10, 8348. https://doi.org/10.3390/app10238348
Ton B, Basten R, Bolte J, Braaksma J, Di Bucchianico A, van de Calseyde P, Grooteman F, Heskes T, Jansen N, Teeuw W, et al. PrimaVera: Synergising Predictive Maintenance. Applied Sciences. 2020; 10(23):8348. https://doi.org/10.3390/app10238348
Chicago/Turabian StyleTon, Bram, Rob Basten, John Bolte, Jan Braaksma, Alessandro Di Bucchianico, Philippe van de Calseyde, Frank Grooteman, Tom Heskes, Nils Jansen, Wouter Teeuw, and et al. 2020. "PrimaVera: Synergising Predictive Maintenance" Applied Sciences 10, no. 23: 8348. https://doi.org/10.3390/app10238348
APA StyleTon, B., Basten, R., Bolte, J., Braaksma, J., Di Bucchianico, A., van de Calseyde, P., Grooteman, F., Heskes, T., Jansen, N., Teeuw, W., Tinga, T., & Stoelinga, M. (2020). PrimaVera: Synergising Predictive Maintenance. Applied Sciences, 10(23), 8348. https://doi.org/10.3390/app10238348