A Proposed Extended Version of the Hadi-Vencheh Model to Improve Multiple-Criteria ABC Inventory Classification


Abstract
:Featured Application
Abstract
1. Introduction
2. Literature Review on the HV Model and the WPM
3. The Solution Algorithm
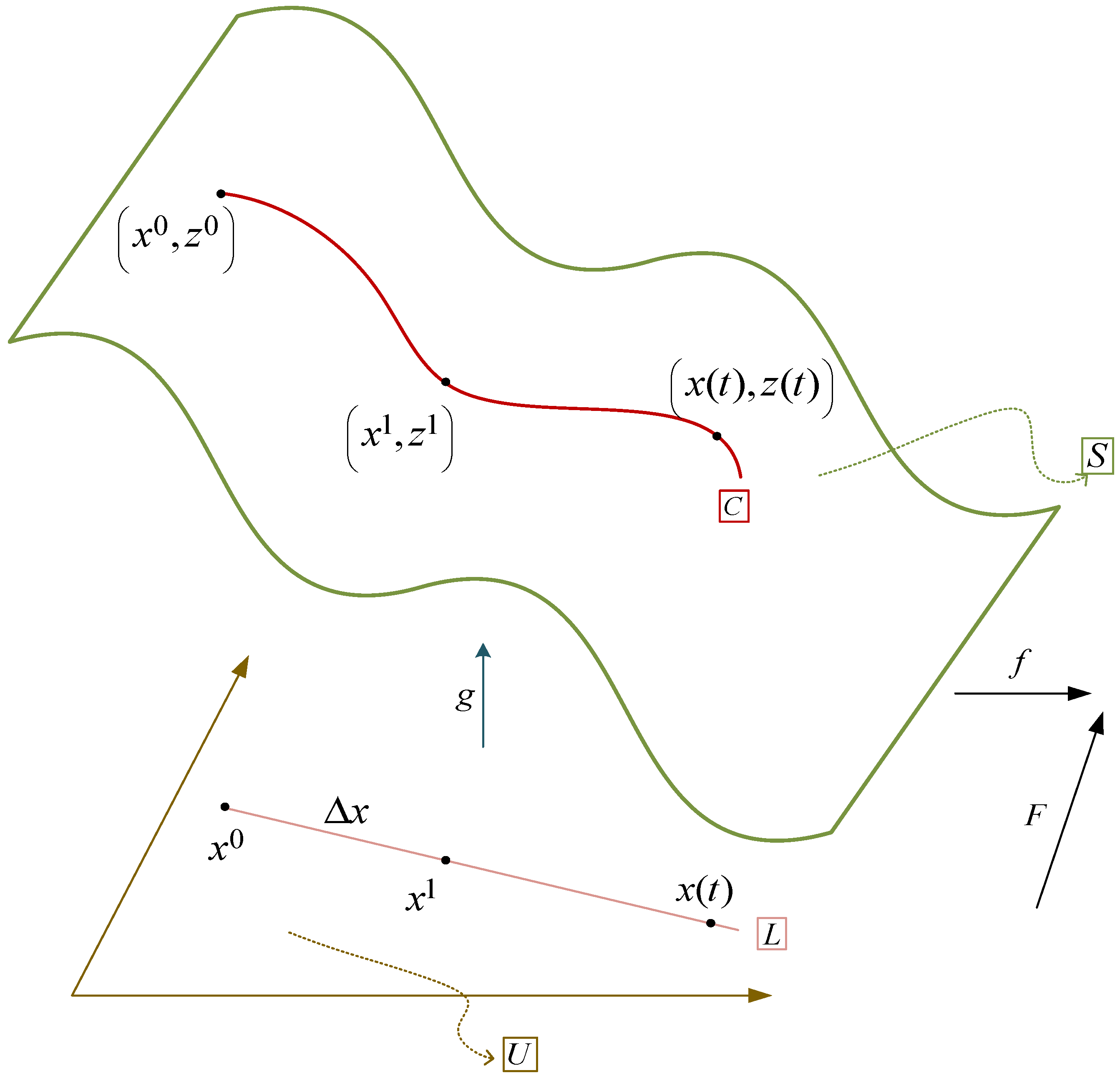
3.1. Nomenclature
3.1.1. Notation of the Weighted Product Method for ABC Classification
- : set of inventory items;
- : set of evaluation criteria;
- : the th inventory item in terms of the th criteria;
- : the weight of performance contribution of the th item under the th criteria;
- : score of the item .
3.1.2. Notation of the CCM Algorithm
- : the set of all real numbers;
- : decision variables;
- : feasible initial solution;
- : set of constraints, ;
- : the objective function;
- : the optimal solution.
3.2. The CCM Algorithm
| Algorithm 1. CCM Algorithm |
| Input: The nonlinear program: Output: A critical point of satisfying . Steps:
|
3.3. Improvement of the Algorithm Using Efficient Selection of Bases
3.4. Accuracy Improvement
4. Illustrative Example
4.1. Quality of Solutions
4.2. Elapsed Runtime and Iterations
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ng, W.L. A simple classifier for multiple criteria abc analysis. Eur. J. Oper. Res. 2007, 177, 344–353. [Google Scholar] [CrossRef]
- Flores, B.E.; Whybark, D.C. Multiple criteria ABC analysis. Int. J. Oper. Prod. Man. 1986, 6, 38–46. [Google Scholar] [CrossRef]
- Teunter, R.H.; Babai, M.Z.; Syntetos, A.A. ABC classification: Service levels and inventory costs. Prod. Oper. Manag. 2010, 19, 343–352. [Google Scholar] [CrossRef]
- Harirchian, E.; Jadhav, K.; Mohammad, K.; Aghakouchaki Hosseini, S.E.; Lahmer, T. A comparative study of MCDM methods integrated with rapid visual seismic vulnerability assessment of existing RC structures. Appl. Sci. 2020, 10, 6411. [Google Scholar] [CrossRef]
- Carneiro, J.; Martinho, D.; Alves, P.; Conceição, L.; Marreiros, G.; Novais, P. A multiple criteria decision analysis framework for dispersed group decision-making contexts. Appl. Sci. 2020, 10, 4614. [Google Scholar] [CrossRef]
- Flores, B.E.; Olson, D.L.; Dorai, V. Management of multicriteria inventory classification. Math. Comput. Model. 1992, 16, 71–82. [Google Scholar] [CrossRef]
- Ramanathan, R. ABC inventory classification with multiple-criteria using weighted linear optimization. Comput. Oper. Res. 2006, 33, 695–700. [Google Scholar] [CrossRef]
- Flores, B.E.; Whybark, D.C. Implementing multiple criteria ABC analysis. J. Oper. Manag. 1987, 7, 79–85. [Google Scholar] [CrossRef]
- Adida, E.; Perakis, G. A nonlinear continuous time optimal control model of dynamic pricing and inventory control with no backorders. Nav. Res. Log. 2007, 54, 767–795. [Google Scholar] [CrossRef]
- Aggarwal, V. A closed-from approach for multi-item inventory grouping. Nav. Res. Log. 1983, 30, 471–485. [Google Scholar] [CrossRef]
- Leap, N.J.; Bauer, K.W. A confidence paradigm for classification systems. Nav. Res. Log. 2011, 58, 236–254. [Google Scholar] [CrossRef]
- Liang, X.; Yan, H. Inventory control and replenishment with flexible delivery-time upgrade. Nav. Res. Log. 2014, 61, 418–426. [Google Scholar] [CrossRef]
- Hadi-Vencheh, A. An improvement to multiple criteria ABC inventory classification. Eur. J. Oper. Res. 2010, 201, 962–965. [Google Scholar] [CrossRef]
- Triantaphyllou, E. Multi-Criteria Decision Making Methods: A Comparative Study; Boston, M.A., Ed.; Springer: Berlin/Heidelberg, Germany, 2000; Chapter 2; pp. 5–21. [Google Scholar]
- Chang, H.-C.; Prabhu, N. Canonical coordinates method for equality-constrained nonlinear optimization. Appl. Math. Comput. 2003, 140, 135–158. [Google Scholar] [CrossRef]
- Chang, H.-C.; Lin, P.-C. A demonstration of the improved efficiency of the canonical coordinates method using nonlinear combined heat and power economic dispatch problems. Eng. Optimiz. 2014, 46, 261–269. [Google Scholar] [CrossRef]
- Zhou, P.; Fan, L. A note on multi-criteria ABC inventory classification using weighted linear optimization. Eur. J. Oper. Res. 2007, 182, 1488–1491. [Google Scholar] [CrossRef]
- Lindo System Inc. Extended Lingo (Release 8.0) [Computer Software]; Lindo System Inc.: Chicago, IL, USA, 2003. [Google Scholar]
- Jahn, O.; Möhring, R.; Schulz, A.; Stier-Moses, N. System-optimal routing of traffic flows with user constraints in networks with congestion. Oper. Res. 2005, 53, 600–616. [Google Scholar] [CrossRef]

{kind=link}
| Item Parameter | LINGO | CCM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Objective Value | Decision Variable | Objective Value | Decision Variable | ||||||||
| ADU | AUC | LT | Score | ADU Weight | AUC Weight | LT Weight | Score | ADU Weight | AUC Weight | LT Weight | |
| 1 | 5840.64 | 49.92 | 2 | 8.92 | 7.050 × 10−1 | 7.050 × 10−1 | 7.770 × 10−2 | 8.92 | 7.050 × 10−1 | 7.049 × 10−1 | 7.790 × 10−2 |
| 2 | 5670 | 210 | 5 | 10.02 | 6.979 × 10−1 | 6.979 × 10−1 | 1.606 × 10−1 | 10.02 | 6.980 × 10−1 | 6.978 × 10−1 | 1.608 × 10−1 |
| 3 | 5037.12 | 23.76 | 4 | 8.38 | 6.974 × 10−1 | 6.974 × 10−1 | 1.654 × 10−1 | 8.38 | 6.974 × 10−1 | 6.973 × 10−1 | 1.658 × 10−1 |
| 4 | 4769.56 | 27.73 | 1 | 8.34 | 7.071 × 10−1 | 7.071 × 10−1 | 0.000 × 100 | 8.34 | 7.072 × 10−1 | 7.071 × 10−1 | 2.360 × 10−4 |
| 5 | 3478.8 | 57.98 | 3 | 8.71 | 7.015 × 10−1 | 7.015 × 10−1 | 1.262 × 10−1 | 8.71 | 7.015 × 10−1 | 7.014 × 10−1 | 1.264 × 10−1 |
| 6 | 2936.67 | 31.24 | 3 | 8.15 | 7.007 × 10−1 | 7.007 × 10−1 | 1.347 × 10−1 | 8.15 | 7.007 × 10−1 | 7.006 × 10−1 | 1.350 × 10−1 |
| 7 | 2820 | 28.2 | 3 | 8.05 | 7.005 × 10−1 | 7.005 × 10−1 | 1.364 × 10−1 | 8.05 | 7.005 × 10−1 | 7.004 × 10−1 | 1.367 × 10−1 |
| 8 | 2640 | 55 | 4 | 8.52 | 6.977 × 10−1 | 6.977 × 10−1 | 1.627 × 10−1 | 8.52 | 6.977 × 10−1 | 6.976 × 10−1 | 1.630 × 10−1 |
| 9 | 2423.52 | 73.44 | 6 | 8.73 | 6.921 × 10−1 | 6.921 × 10−1 | 2.051 × 10−1 | 8.73 | 6.921 × 10−1 | 6.920 × 10−1 | 2.053 × 10−1 |
| 10 | 2407.5 | 160.5 | 4 | 9.20 | 6.990 × 10−1 | 6.990 × 10−1 | 1.507 × 10−1 | 9.20 | 6.991 × 10−1 | 6.989 × 10−1 | 1.509 × 10−1 |
| 11 | 1057.2 | 5.12 | 2 | 6.12 | 7.026 × 10−1 | 7.026 × 10−1 | 1.133 × 10−1 | 6.12 | 7.025 × 10−1 | 7.024 × 10−1 | 1.145 × 10−1 |
| 12 | 1043.5 | 20.87 | 5 | 7.24 | 6.894 × 10−1 | 6.894 × 10−1 | 2.222 × 10−1 | 7.24 | 6.894 × 10−1 | 6.893 × 10−1 | 2.226 × 10−1 |
| 13 | 1038 | 86.5 | 7 | 8.30 | 6.874 × 10−1 | 6.874 × 10−1 | 2.346 × 10−1 | 8.30 | 6.875 × 10−1 | 6.873 × 10−1 | 2.347 × 10−1 |
| 14 | 883.2 | 110.4 | 5 | 8.28 | 6.936 × 10−1 | 6.936 × 10−1 | 1.944 × 10−1 | 8.28 | 6.938 × 10−1 | 6.934 × 10−1 | 1.945 × 10−1 |
| 15 | 854.4 | 71.2 | 3 | 7.87 | 7.002 × 10−1 | 7.002 × 10−1 | 1.397 × 10−1 | 7.87 | 7.003 × 10−1 | 7.000 × 10−1 | 1.399 × 10−1 |
| 16 | 810 | 45 | 3 | 7.51 | 6.995 × 10−1 | 6.995 × 10−1 | 1.463 × 10−1 | 7.51 | 6.996 × 10−1 | 6.994 × 10−1 | 1.465 × 10−1 |
| 17 | 703.68 | 14.66 | 4 | 6.68 | 6.917 × 10−1 | 6.917 × 10−1 | 2.075 × 10−1 | 6.68 | 6.917 × 10−1 | 6.916 × 10−1 | 2.081 × 10−1 |
| 18 | 594 | 49.5 | 6 | 7.49 | 6.866 × 10−1 | 6.866 × 10−1 | 2.391 × 10−1 | 7.49 | 6.867 × 10−1 | 6.865 × 10−1 | 2.393 × 10−1 |
| 19 | 570 | 47.5 | 5 | 7.39 | 6.902 × 10−1 | 6.902 × 10−1 | 2.177 × 10−1 | 7.39 | 6.902 × 10−1 | 6.900 × 10−1 | 2.178 × 10−1 |
| 20 | 467.6 | 58.45 | 4 | 7.36 | 6.944 × 10−1 | 6.944 × 10−1 | 1.885 × 10−1 | 7.36 | 6.946 × 10−1 | 6.942 × 10−1 | 1.887 × 10−1 |
| 21 | 463.6 | 24.4 | 4 | 6.74 | 6.920 × 10−1 | 6.920 × 10−1 | 2.056 × 10−1 | 6.74 | 6.920 × 10−1 | 6.919 × 10−1 | 2.058 × 10−1 |
| 22 | 455 | 65 | 4 | 7.41 | 6.946 × 10−1 | 6.946 × 10−1 | 1.871 × 10−1 | 7.41 | 6.948 × 10−1 | 6.944 × 10−1 | 1.873 × 10−1 |
| 23 | 432.5 | 86.5 | 4 | 7.57 | 6.952 × 10−1 | 6.952 × 10−1 | 1.830 × 10−1 | 7.57 | 6.954 × 10−1 | 6.949 × 10−1 | 1.832 × 10−1 |
| 24 | 398.4 | 33.2 | 3 | 6.80 | 6.978 × 10−1 | 6.978 × 10−1 | 1.616 × 10−1 | 6.80 | 6.979 × 10−1 | 6.977 × 10−1 | 1.618 × 10−1 |
| 25 | 370.5 | 37.05 | 1 | 6.74 | 7.071 × 10−1 | 7.071 × 10−1 | 0.000 × 10−0 | 6.74 | 7.071 × 10−1 | 7.071 × 10−1 | 2.570 × 10−4 |
| 26 | 338.4 | 33.84 | 3 | 6.70 | 6.975 × 10−1 | 6.975 × 10−1 | 1.640 × 10−1 | 6.70 | 6.975 × 10−1 | 6.975 × 10−1 | 1.642 × 10−1 |
| 27 | 336.12 | 84.03 | 1 | 7.25 | 7.071 × 10−1 | 7.071 × 10−1 | 0.000 × 100 | 7.25 | 7.071 × 10−1 | 7.071 × 10−1 | 2.860 × 10−4 |
| 28 | 313.6 | 78.4 | 6 | 7.37 | 6.859 × 10−1 | 6.859 × 10−1 | 2.431 × 10−1 | 7.37 | 6.859 × 10−1 | 6.859 × 10−1 | 2.433 × 10−1 |
| 29 | 268.68 | 134.34 | 7 | 7.67 | 6.840 × 10−1 | 6.840 × 10−1 | 2.537 × 10−1 | 7.67 | 6.840 × 10−1 | 6.840 × 10−1 | 2.539 × 10−1 |
| 30 | 224 | 56 | 1 | 6.67 | 7.071 × 10−1 | 7.071 × 10−1 | 0.000 × 100 | 6.67 | 7.071 × 10−1 | 7.071 × 10−1 | 2.880 × 10−4 |
| 31 | 216 | 72 | 5 | 7.01 | 6.882 × 10−1 | 6.882 × 10−1 | 2.295 × 10−1 | 7.01 | 6.882 × 10−1 | 6.882 × 10−1 | 2.297 × 10−1 |
| 32 | 212.08 | 53.02 | 2 | 6.63 | 7.032 × 10−1 | 7.032 × 10−1 | 1.045 × 10−1 | 6.63 | 7.032 × 10−1 | 7.032 × 10−1 | 1.048 × 10−1 |
| 33 | 197.92 | 49.48 | 5 | 6.69 | 6.864 × 10−1 | 6.864 × 10−1 | 2.404 × 10−1 | 6.69 | 6.864 × 10−1 | 6.864 × 10−1 | 2.406 × 10−1 |
| 34 | 190.89 | 7.07 | 7 | 5.46 | 6.606 × 10−1 | 6.606 × 10−1 | 3.567 × 10−1 | 5.46 | 6.606 × 10−1 | 6.606 × 10−1 | 3.595 × 10−1 |
| 35 | 181.8 | 60.6 | 3 | 6.67 | 6.975 × 10−1 | 6.975 × 10−1 | 1.647 × 10−1 | 6.67 | 6.975 × 10−1 | 6.975 × 10−1 | 1.649 × 10−1 |
| 36 | 163.28 | 40.82 | 3 | 6.32 | 6.963 × 10−1 | 6.963 × 10−1 | 1.738 × 10−1 | 6.32 | 6.963 × 10−1 | 6.963 × 10−1 | 1.740 × 10−1 |
| 37 | 150 | 30 | 5 | 6.16 | 6.826 × 10−1 | 6.826 × 10−1 | 2.612 × 10−1 | 6.16 | 6.826 × 10−1 | 6.826 × 10−1 | 2.613 × 10−1 |
| 38 | 134.8 | 67.4 | 3 | 6.54 | 6.971 × 10−1 | 6.971 × 10−1 | 1.680 × 10−1 | 6.54 | 6.971 × 10−1 | 6.971 × 10−1 | 1.683 × 10−1 |
| 39 | 119.2 | 59.6 | 5 | 6.47 | 6.849 × 10−1 | 6.849 × 10−1 | 2.486 × 10−1 | 6.47 | 6.849 × 10−1 | 6.849 × 10−1 | 2.488 × 10−1 |
| 40 | 103.36 | 51.68 | 6 | 6.33 | 6.782 × 10−1 | 6.782 × 10−1 | 2.831 × 10−1 | 6.33 | 6.782 × 10−1 | 6.782 × 10−1 | 2.833 × 10−1 |
| 41 | 79.2 | 19.8 | 2 | 5.25 | 7.009 × 10−1 | 7.009 × 10−1 | 1.321 × 10−1 | 5.25 | 7.009 × 10−1 | 7.009 × 10−1 | 1.323 × 10−1 |
| 42 | 75.4 | 37.7 | 2 | 5.67 | 7.018 × 10−1 | 7.018 × 10−1 | 1.223 × 10−1 | 5.66 | 7.018 × 10−1 | 7.018 × 10−1 | 1.227 × 10−1 |
| 43 | 59.78 | 29.89 | 5 | 5.53 | 6.765 × 10−1 | 6.765 × 10−1 | 2.908 × 10−1 | 5.53 | 6.765 × 10−1 | 6.765 × 10−1 | 2.910 × 10−1 |
| 44 | 48.3 | 48.3 | 3 | 5.59 | 6.933 × 10−1 | 6.933 × 10−1 | 1.964 × 10−1 | 5.59 | 6.933 × 10−1 | 6.933 × 10−1 | 2.000 × 10−1 |
| 45 | 34.4 | 34.4 | 7 | 5.37 | 6.590 × 10−1 | 6.590 × 10−1 | 3.625 × 10−1 | 5.37 | 6.590 × 10−1 | 6.590 × 10−1 | 3.639 × 10−1 |
| 46 | 28.8 | 28.8 | 3 | 4.88 | 6.889 × 10−1 | 6.889 × 10−1 | 2.252 × 10−1 | 4.88 | 6.889 × 10−1 | 6.889 × 10−1 | 2.291 × 10−1 |
| 47 | 25.38 | 8.46 | 5 | 4.12 | 6.510 × 10−1 | 6.510 × 10−1 | 3.903 × 10−1 | 4.12 | 6.510 × 10−1 | 6.510 × 10−1 | 3.931 × 10−1 |
| Item | Optimal Score (CCM) | ADU | AUC | LT | WPM Model (CCM) | WPM Model (LINGO) | HV model | Ng Model | ZF Model |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 10.0222 | 5670 | 210 | 5 | A | A | A | A | A |
| 10 | 9.20134 | 2407.5 | 160.5 | 4 | A | A | A | A | A |
| 1 | 8.92424 | 5840.64 | 49.92 | 2 | A | A | A | A | A |
| 9 | 8.73406 | 2423.52 | 73.44 | 6 | A | A | A | A | A |
| 5 | 8.70633 | 3478.8 | 57.98 | 3 | A | A | A | A | B |
| 8 | 8.51791 | 2640 | 55 | 4 | A | A | B | B | B |
| 3 | 8.38316 | 5037.12 | 23.76 | 4 | A | A | A | A | A |
| 4 | 8.33829 | 4769.56 | 27.73 | 1 | A | A | A | A | C |
| 13 | 8.29587 | 1038 | 86.5 | 7 | A | A | A | A | A |
| 14 | 8.28055 | 883.2 | 110.4 | 5 | A | A | A | B | A |
| 6 | 8.15406 | 2936.67 | 31.24 | 3 | B | B | B | A | C |
| 7 | 8.05394 | 2820 | 28.2 | 3 | B | B | B | B | C |
| 15 | 7.86615 | 854.4 | 71.2 | 3 | B | B | C | C | C |
| 29 | 7.67051 | 268.68 | 134.34 | 7 | B | B | A | A | A |
| 23 | 7.57315 | 432.5 | 86.5 | 4 | B | B | B | B | B |
| 16 | 7.50776 | 810 | 45 | 3 | B | B | C | C | C |
| 18 | 7.49247 | 594 | 49.5 | 6 | B | B | B | B | A |
| 22 | 7.40991 | 455 | 65 | 4 | B | B | C | C | B |
| 19 | 7.39402 | 570 | 47.5 | 5 | B | B | B | B | B |
| 28 | 7.36954 | 313.6 | 78.4 | 6 | B | B | B | B | A |
| 20 | 7.35514 | 467.6 | 58.45 | 4 | B | B | C | C | B |
| 27 | 7.24598 | 336.12 | 84.03 | 1 | B | B | C | C | C |
| 12 | 7.24393 | 1043.5 | 20.87 | 5 | B | B | B | B | B |
| 31 | 7.01167 | 216 | 72 | 5 | B | B | B | B | B |
| 24 | 6.79949 | 398.4 | 33.2 | 3 | C | C | C | C | C |
| 21 | 6.74367 | 463.6 | 24.4 | 4 | C | C | C | C | C |
| 25 | 6.73618 | 370.5 | 37.05 | 1 | C | C | C | C | C |
| 26 | 6.69892 | 338.4 | 33.84 | 3 | C | C | C | C | C |
| 33 | 6.69389 | 197.92 | 49.48 | 5 | C | C | B | B | B |
| 17 | 6.67996 | 703.68 | 14.66 | 4 | C | C | C | C | C |
| 30 | 6.67213 | 224 | 56 | 1 | C | C | C | C | C |
| 35 | 6.67164 | 181.8 | 60.6 | 3 | C | C | C | C | C |
| 32 | 6.63135 | 212.08 | 53.02 | 2 | C | C | C | C | C |
| 38 | 6.53696 | 134.8 | 67.4 | 3 | C | C | C | C | C |
| 39 | 6.47356 | 119.2 | 59.6 | 5 | C | C | B | B | B |
| 40 | 6.32774 | 103.36 | 51.68 | 6 | C | C | B | B | B |
| 36 | 6.32156 | 163.28 | 40.82 | 3 | C | C | C | C | C |
| 37 | 6.16169 | 150 | 30 | 5 | C | C | C | C | B |
| 11 | 6.11791 | 1057.2 | 5.12 | 2 | C | C | C | C | C |
| 42 | 5.66488 | 75.4 | 37.7 | 2 | C | C | C | C | C |
| 44 | 5.59151 | 48.3 | 48.3 | 3 | C | C | C | C | C |
| 43 | 5.5337 | 59.78 | 29.89 | 5 | C | C | C | C | C |
| 34 | 5.45517 | 190.89 | 7.07 | 7 | C | C | B | B | B |
| 45 | 5.36813 | 34.4 | 34.4 | 7 | C | C | B | B | B |
| 41 | 5.24818 | 79.2 | 19.8 | 2 | C | C | C | C | C |
| 46 | 4.87682 | 28.8 | 28.8 | 3 | C | C | C | C | C |
| 47 | 4.12265 | 25.38 | 8.46 | 5 | C | C | C | C | C |
| Item | ADU | AUC | LT | WPM | HV Model | Ng Model | ZF Model |
|---|---|---|---|---|---|---|---|
| 8 | 2640 | 55 | 4 | A | B | B | B |
| 29 | 268.68 | 134.34 | 7 | B | A | A | A |
| 15 | 854.4 | 71.2 | 3 | B | C | C | C |
| 16 | 810 | 45 | 3 | B | C | C | C |
| 27 | 336.12 | 84.03 | 1 | B | C | C | C |
| 33 | 197.92 | 49.48 | 5 | C | B | B | B |
| 39 | 119.2 | 59.6 | 5 | C | B | B | B |
| 40 | 103.36 | 51.68 | 6 | C | B | B | B |
| 34 | 190.89 | 7.07 | 7 | C | B | B | B |
| 45 | 34.4 | 34.4 | 7 | C | B | B | B |
| Item 4 | Step size | Item 5 | Step size | ||
| 0.0003 | 1.000009 | 0.00045 | 1.000062 | ||
| 0.000295 | 0.999993 | 0.000448 | 1.000059 | ||
| 0.000298 | 1.000003 | 0.00044 | 1.000046 | ||
| 0.000297 | 1 | 0.00041 | 0.999997 | ||
| 0.000413 | 1.000002 | ||||
| 0.000412 | 1 | ||||
| Item | LINGO | CCM | Item | LINGO | CCM | Item | LINGO | CCM | Item | LINGO | CCM |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 60 | 1720 | 13 | 60 | 1505 | 25 | 35 | 2482 | 37 | 60 | 1367 |
| 2 | 60 | 1866 | 14 | 55 | 1852 | 26 | 60 | 1646 | 38 | 50 | 2369 |
| 3 | 60 | 1207 | 15 | 60 | 1911 | 27 | 35 | 3213 | 39 | 50 | 1888 |
| 4 | 35 | 1867 | 16 | 59 | 1673 | 28 | 55 | 1741 | 40 | 50 | 1657 |
| 5 | 60 | 1627 | 17 | 60 | 1090 | 29 | 50 | 2024 | 41 | 58 | 1903 |
| 6 | 60 | 1419 | 18 | 59 | 1377 | 30 | 35 | 3045 | 42 | 50 | 2452 |
| 7 | 60 | 1388 | 19 | 57 | 1456 | 31 | 55 | 1900 | 43 | 55 | 1496 |
| 8 | 60 | 1495 | 20 | 60 | 1729 | 32 | 55 | 2397 | 44 | 75 | 555 |
| 9 | 58 | 1428 | 21 | 60 | 1287 | 33 | 55 | 1645 | 45 | 55 | 215 |
| 10 | 57 | 1995 | 22 | 55 | 1802 | 34 | 60 | 1158 | 46 | 75 | 492 |
| 11 | 60 | 1086 | 23 | 55 | 2009 | 35 | 50 | 2223 | 47 | 60 | 2712 |
| 12 | 60 | 1105 | 24 | 60 | 1612 | 36 | 55 | 1932 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, P.-C.; Chang, H.-C. A Proposed Extended Version of the Hadi-Vencheh Model to Improve Multiple-Criteria ABC Inventory Classification. Appl. Sci. 2020, 10, 8233. https://doi.org/10.3390/app10228233
Lin P-C, Chang H-C. A Proposed Extended Version of the Hadi-Vencheh Model to Improve Multiple-Criteria ABC Inventory Classification. Applied Sciences. 2020; 10(22):8233. https://doi.org/10.3390/app10228233
Chicago/Turabian StyleLin, Pei-Chun, and Hung-Chieh Chang. 2020. "A Proposed Extended Version of the Hadi-Vencheh Model to Improve Multiple-Criteria ABC Inventory Classification" Applied Sciences 10, no. 22: 8233. https://doi.org/10.3390/app10228233
APA StyleLin, P.-C., & Chang, H.-C. (2020). A Proposed Extended Version of the Hadi-Vencheh Model to Improve Multiple-Criteria ABC Inventory Classification. Applied Sciences, 10(22), 8233. https://doi.org/10.3390/app10228233