An Effective Multi-Label Feature Selection Model Towards Eliminating Noisy Features




Abstract
1. Introduction
- We present a novel multi-label feature selection model to address the issue of noisy features. This model qualitatively measures label correlations and employs feature-label space consistency to steer feature selection.
- We devised a compact framework to optimize the proposed model. This framework resorts to the multi-task learning strategy and promises globally optimal solutions and efficient convergence.
- Comprehensive experiments on openly available benchmarks were conducted to validate the performance of the proposed model in feature selection and noise elimination.
2. Related Work
3. The Methodology: ELC
3.1. Model Description
3.2. Property Analysis
4. Multi-Task Optimization for ELC
| Algorithm 1 ELC |
|
5. Experimental Evaluation
- MIFS (multi-label informed feature selection) [33]: a label correlation-based multi-label feature selection approach, which maps label information into a low-dimensional subspace and captures the correlations among multiple labels;
- CMFS (correlated and multi-label feature selection) [35]: a feature selection approach based on non-negative matrix factorization, which exploits the label correlation information in features, labels, and instances to select the relevant features and remove the noisy ones;
- LLSF (learning label-specific features) [36]: a unified multi-label learning framework for both feature selection and classification, which models high-order label correlations to select label-specific features.
5.1. Example 1: Classification Performance
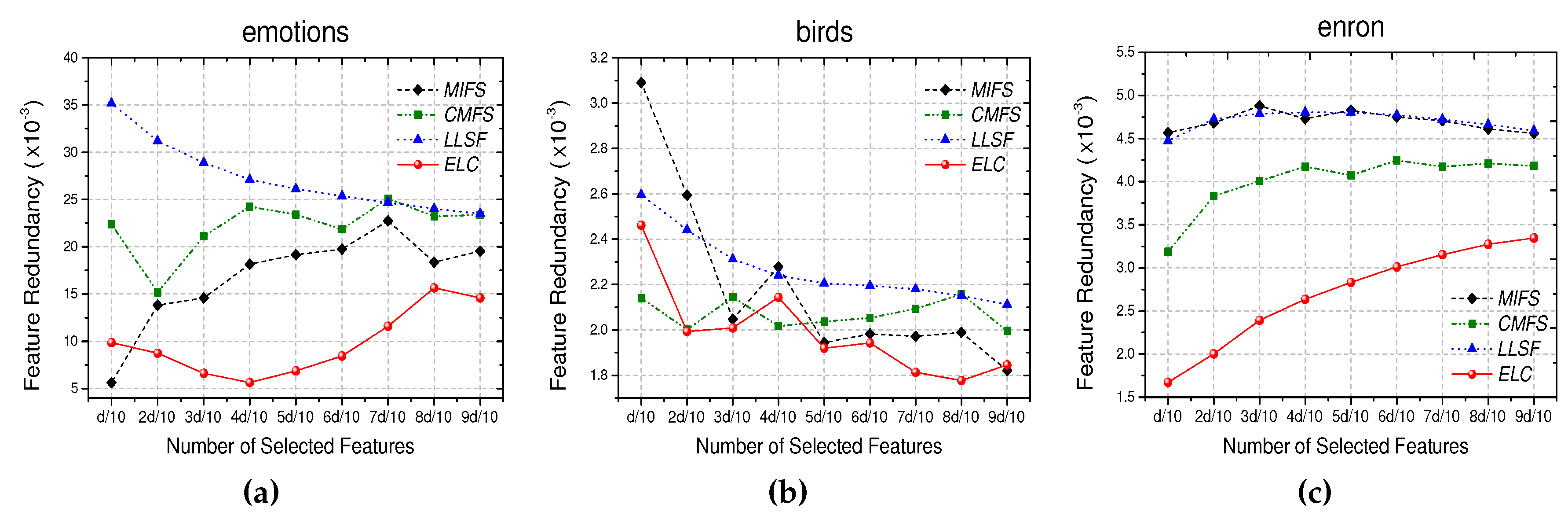
5.2. Example 2: Eliminating Noisy Features
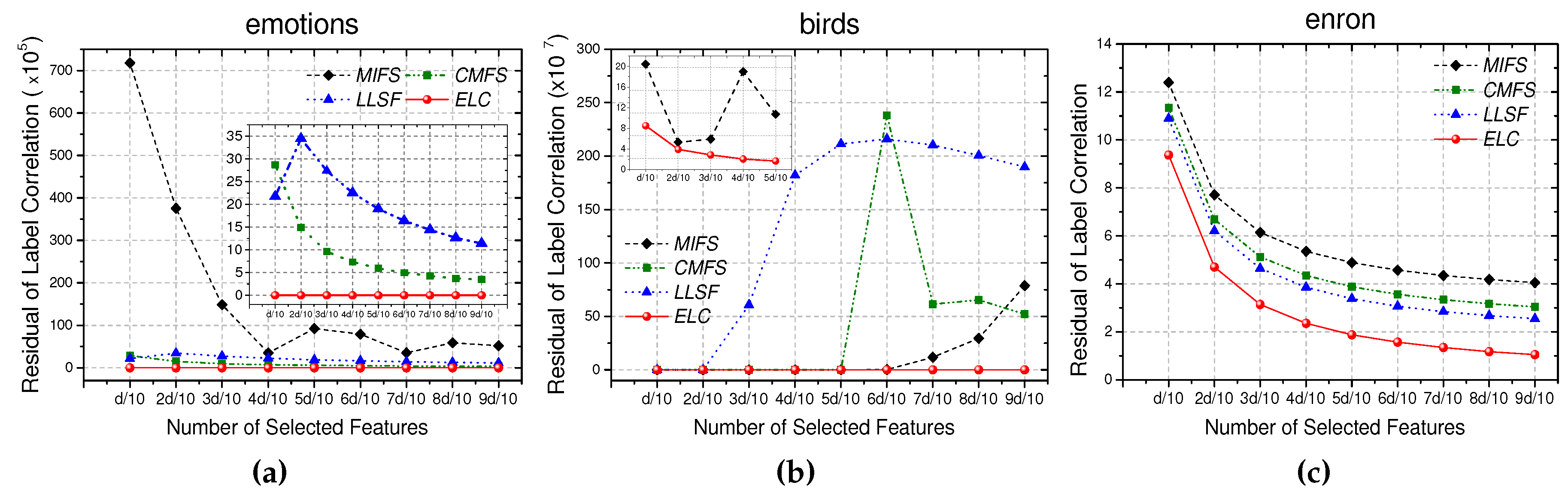
5.3. Example 3: Embedding Label Correlations
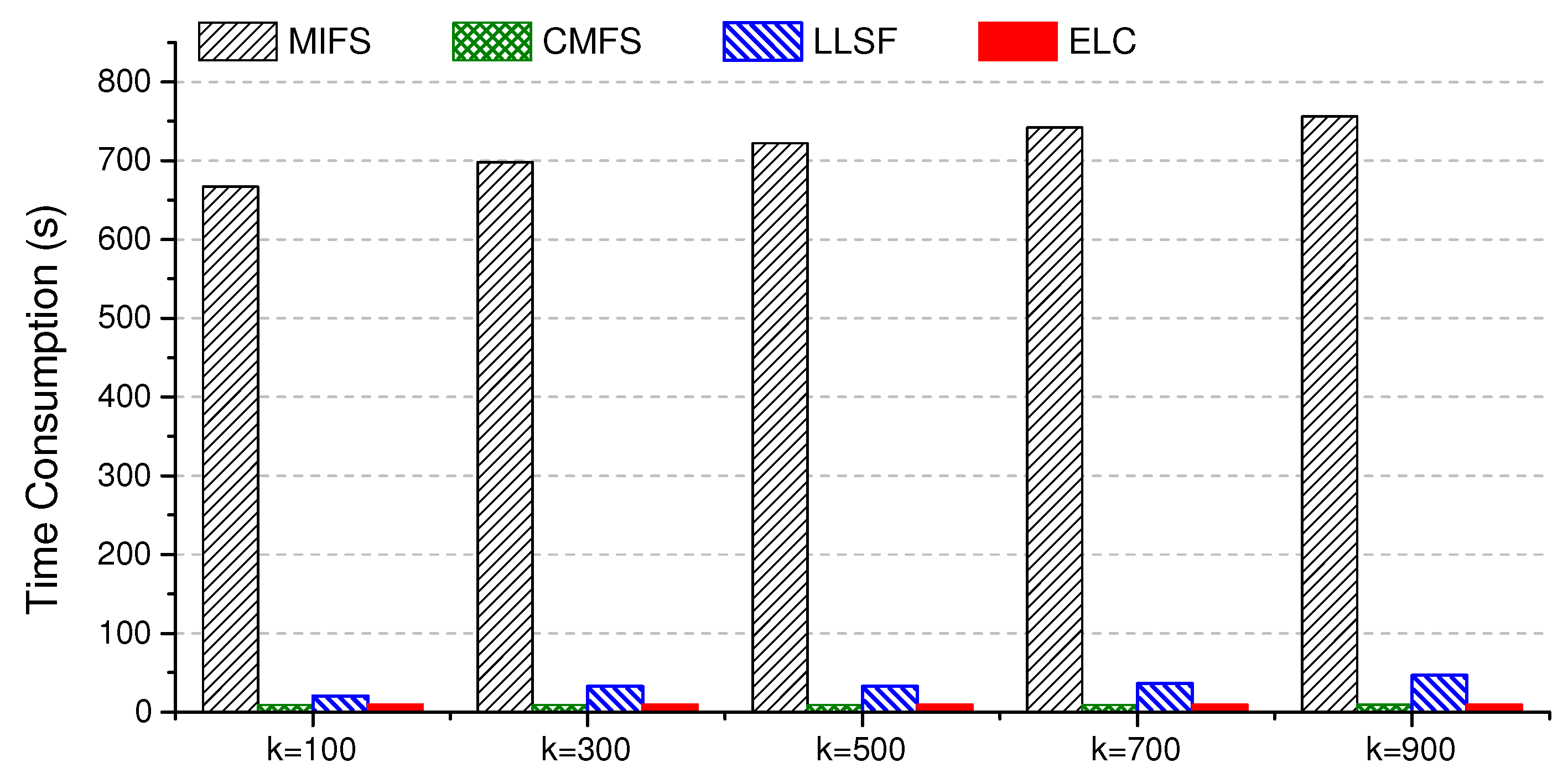
5.4. Example 4: Time Consumption
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B. Experimental Configuration
References
- Tang, J.; Alelyani, S.; Liu, H. Feature felection for classification: A review. In Data Classification: Algorithms and Applications; CRC Press: Chapman, CA, USA, 2014. [Google Scholar]
- Wang, J.; Wei, J.; Yang, Z. Supervised feature selection by preserving class correlation. In Proceedings of the 25th ACM International Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 1613–1622. [Google Scholar]
- Cai, D.; Zhang, C.; He, X. Efficient and robust feature selection via joint l2,1-norms minimization. In Proceedings of the KDD ’10: The 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 333–342. [Google Scholar]
- Xu, Y.; Wang, J.; An, S.; Wei, J.; Ruan, J. Semi-supervised multi-label feature selection by preserving feature-label space consistency. In Proceedings of the CIKM ’18: Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Orino, Italy, 22–26 October 2018; pp. 783–792. [Google Scholar]
- Brown, G.; Pocock, A.; Zhao, M.; Luján, M. Conditional Likelihood Maximisation: A unifying framework for information theoretic feature selection. J. Mach. Learn. Res. 2012, 12, 27–66. [Google Scholar]
- Gu, Q.; Li, Z.; Han, J. Generalized fisher score for feature selection. In Proceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence, Barcelona, Spain, 14–17 July 2011; pp. 266–273. [Google Scholar]
- He, X.; Cai, D.; Niyogi, P. Laplacian score for feature selection. In Proceedings of the 18th International Conference on Neural Information Processing Systems, Shanghai, China, 13–17 November 2011; pp. 507–514. [Google Scholar]
- Lin, D.; Tang, X. Conditional Infomax Learning: An Integrated Framework for Feature Extraction and Fusion. In Proceedings of the Computer Vision—ECCV 2006, 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 68–82. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Robnik-Šikonja, M.; Kononenko, I. Theoretical and empirical analysis of ReliefF and RReliefF. Mach. Learn. 2003, 53, 23–69. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Bermejo, P.; Gámez, J.A.; Puerta, J.M. Speeding up incremental wrapper feature subset selection with Naive Bayes classifier. Knowl.-Based Syst. 2014, 55, 140–147. [Google Scholar] [CrossRef]
- Gütlein, M.; Frank, E.; Hall, M.; Karwath, A. Large-scale attribute selection using wrappers. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence and Data Mining, CIDM 2009, Nashville, TN, USA, 30 March–2 April 2009; pp. 332–339. [Google Scholar]
- Xu, Y.; Wang, J.; Wei, J. To avoid the pitfall of missing labels in feature selection: A generative model gives the answer. In Proceedings of the AAAI Conference on Artificial Intelligence 2020, New York, NY, USA, 7–12 February 2020; pp. 6534–6541. [Google Scholar]
- Chen, W.; Yan, J.; Zhang, B.; Chen, Z.; Yang, Q. Document transformation for multi-label feature selection in text categorization. In Proceedings of the 2007 Seventh IEEE International Conference on Data Mining, Washington, DC, USA, 28–31 October 2007; pp. 451–456. [Google Scholar]
- Ma, Z.; Nie, F.; Yang, Y.; Uijlings, J.R.; Sebe, N. Web image annotation via subspace-sparsity collaborated feature selection. IEEE Trans. Multimedia 2012, 14, 1021–1030. [Google Scholar] [CrossRef]
- Wang, X.; Li, G.Z. Multilabel learning via random label selection for protein subcellular multilocations prediction. IEEE/ACM Trans. Comput. Biol Bioinform. 2013, 10, 436–446. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.L.; Zhou, Z.H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Rivolli, A.; J, J.R.; Soares, C.; Pfahringer, B.; de Carvalho, A.C. An empirical analysis of binary transformation strategies and base algorithms for multi-label learning. Mach. Learn. 2020, 9, 1–55. [Google Scholar]
- Zhao, Z.; Wang, L.; Liu, H.; Ye, J. On similarity preserving feature selection. IEEE Trans. Knowl. Data Eng. 2013, 25, 619–632. [Google Scholar] [CrossRef]
- Zhao, J.; Lu, K.; He, X. Locality sensitive semi-supervised feature selection. Neurocomputing 2008, 71, 1842–1849. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, Z.H. Multi-label dimensionality reduction via dependence maximization. ACM Trans. Knowl. Discovery Data 2010, 4, 1503–1505. [Google Scholar]
- Nie, F.; Xiang, S.; Jia, Y. Trace ratio criterion for feature selection. In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence, AAAI 2008, Chicago, IL, USA, 13–17 July 2008; pp. 671–676. [Google Scholar]
- Zhao, Z.; Liu, H. Spectral feature selection for supervised and unsupervised learning. In Proceedings of the 24th International Conference on Machine Learning, ICML 2007, Corvallis, OR, USA, 20–24 June 2007; pp. 1151–1157. [Google Scholar]
- Zhao, Z.; Wang, L.; Liu, H. Efficient spectral feature selection with minimum redundancy. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010; pp. 673–678. [Google Scholar]
- Verikas, A.; Bacauskiene, M. Feature selection with neural networks. Pattern Recog. Lett. 2002, 23, 1323–1335. [Google Scholar] [CrossRef]
- Arefnezhad, S.; Samiee, S.; Eichberger, A.; Nahvi, A. Driver drowsiness detection based on steering wheel data applying adaptive neuro-fuzzy feature selection. Sensors 2019, 14, 943. [Google Scholar] [CrossRef]
- Cateni, S.; Colla, V.; Vannucci, M. A fuzzy system for combining filter features selection methods. Int. J. Fuzzy Syst. 2017, 19, 1168–1180. [Google Scholar] [CrossRef]
- Wang, J.; Wei, J.M.; Yang, Z.; Wang, S.Q. Feature selection by maximizing independent classification information. IEEE Trans. Knowl. Data Eng. 2017, 29, 828–841. [Google Scholar] [CrossRef]
- Kong, D.; Ding, C.; Huang, H.; Zhao, H. Multi-label ReliefF and F-statistic feature selections for image annotation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2352–2359. [Google Scholar]
- Ji, S.; Ye, J. Linear dimensionality reduction for multi-label classification. In Proceedings of the 21st International Joint Conference on Artificial Intelligence, Pasadena, CA, USA, 11–17 July 2009; pp. 1077–1082. [Google Scholar]
- Wang, H.; Ding, C.; Huang, H. Multi-label linear discriminant analysis. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; pp. 126–139. [Google Scholar]
- Jian, L.; Li, J.; Shu, K.; Liu, H. Multi-label informed feature selection. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 1627–1633. [Google Scholar]
- Huang, J.; Li, G.; Huang, Q.; Wu, X. Joint feature selection and classification for multilabel learning. IEEE Trans. Cybern. 2018, 48, 876–889. [Google Scholar] [CrossRef]
- Braytee, A.; Liu, W.; Catchpoole, D.R.; Kennedy, P.J. Multi-label feature selection using correlation information. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1649–1656. [Google Scholar]
- Huang, J.; Li, G.; Huang, Q.; Wu, X. Learning label-specific features and class-dependent labels for multi-label classification. IEEE Trans. Knowl. Data Eng. 2016, 28, 3309–3323. [Google Scholar] [CrossRef]
- Ji, S.; Tang, L.; Yu, S.; Ye, J. Extracting shared subspace for multi-label classification. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 381–389. [Google Scholar]
- Nie, F.; Huang, H.; Cai, X.; Ding, C.H. Efficient and robust feature selection via joint 2,1-norms minimization. In Proceedings of the 4th Annual Conference on Neural Information Processing Systems 2010, Vancouver, BC, Canada, 6–9 December 2010; pp. 1813–1821. [Google Scholar]
- Zhang, M.L.; Wu, L. LIFT: Multi-label learning with label-specific features. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 107–119. [Google Scholar] [CrossRef]
- Xiao, Y.H.; Song, H.N. An inexact alternating directions algorithm for constrained total variation regularized compressive sensing problems. J. Math Imaging Vision 2012, 44, 114–127. [Google Scholar] [CrossRef]
- Gong, P.; Zhou, J.; Fan, W.; Ye, J. Efficient multi-task feature learning with calibration. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 10–13 August 2014; pp. 761–770. [Google Scholar]
- Horn, R.A.; Johnson, C.R. Matrix Analysis, 2nd ed.; Cambridge University: Cambridge, UK, 2012. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. ML-kNN: A lazy learning approach to multi-label learning. Pattern Recog. 2007, 40, 2038–2048. [Google Scholar] [CrossRef]
- Kingma, D.K.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Data Set | ♯Features | ♯Instances | ♯Labels | Domain |
|---|---|---|---|---|
| emotions | 72 | 539 | 6 | music |
| yeast | 103 | 2417 | 14 | biology |
| birds | 260 | 645 | 19 | audio |
| enron | 1001 | 1702 | 53 | text |
| genbase | 1186 | 662 | 27 | biology |
| business | 21,924 | 11,214 | 30 | text |
| arts | 23146 | 7484 | 26 | text |
| education | 27,534 | 12,030 | 33 | text |
| reaction | 30,324 | 12,828 | 22 | text |
| health | 30,605 | 9205 | 32 | text |
| computers | 34,096 | 12,444 | 33 | text |
| science | 37,187 | 6428 | 40 | text |
| reference | 39,679 | 8027 | 33 | text |
| society | 49,060 | 14,512 | 22 | text |
| (a) Precision (the higher the better). | ||||||||
| Approaches | Data Sets | AVG. | ||||||
| Emotions | Yeast | Birds | Enron | Genbase | Business | Arts | ||
| MIFS | 0.66670.04 | 0.75200.02 | 0.39380.02 | 0.61390.03 | 0.73610.15 | 0.88120.00 | 0.51080.01 | 0.6506 |
| CMFS | 0.72210.02 | 0.74640.01 | 0.41160.03 | 0.62060.01 | 0.73420.15 | 0.8920.00 | 0.56110.00 | 0.6697 |
| LLSF | 0.70160.02 | 0.75320.01 | 0.42310.07 | 0.61970.04 | 0.73520.15 | 0.89240.00 | 0.56150.01 | 0.6695 |
| ELC | 0.73060.02 | 0.75640.01 | 0.46710.08 | 0.63470.01 | 0.98680.00 | 0.89310.00 | 0.56460.00 | 0.7190 |
| Education | Reaction | Health | Computers | Science | Reference | Society | ||
| MIFS | 0.51290.01 | 0.58360.01 | 0.73910.02 | 0.66290.01 | 0.45920.02 | 0.62670.01 | 0.58990.01 | 0.5963 |
| CMFS | 0.61640.01 | 0.58830.01 | 0.74370.01 | 0.69310.00 | 0.54770.01 | 0.67180.01 | 0.64630.01 | 0.6439 |
| LLSF | 0.61630.01 | 0.58800.01 | 0.74350.01 | 0.69320.00 | 0.54780.01 | 0.67200.00 | 0.64600.01 | 0.6438 |
| ELC | 0.62130.00 | 0.59520.00 | 0.74690.01 | 0.69620.00 | 0.55650.00 | 0.67420.00 | 0.65000.00 | 0.6486 |
| (b) AUC (the higher the better). | ||||||||
| Approaches | Data Sets | AVG. | ||||||
| Emotions | Yeast | Birds | Enron | Genbase | Business | Arts | ||
| MIFS | 0.66010.53 | 0.65540.03 | 0.64970.02 | 0.59680.03 | 0.78860.10 | 0.63710.01 | 0.61000.01 | 0.6568 |
| CMFS | 0.73070.03 | 0.6470.03 | 0.64030.04 | 0.61940.01 | 0.78830.10 | 0.68210.01 | 0.66060.01 | 0.6812 |
| LLSF | 0.70690.02 | 0.66010.02 | 0.67930.05 | 0.60920.03 | 0.78870.10 | 0.68240.01 | 0.66080.01 | 0.6839 |
| ELC | 0.75130.02 | 0.67060.02 | 0.70180.06 | 0.63850.01 | 0.96630.00 | 0.68340.00 | 0.66590.00 | 0.7254 |
| Education | Reaction | Health | Computers | Science | Reference | Society | ||
| MIFS | 0.58300.02 | 0.70650.01 | 0.69940.01 | 0.63640.01 | 0.61090.02 | 0.62460.01 | 0.59640.01 | 0.6423 |
| CMFS | 0.67530.00 | 0.71110.01 | 0.70140.01 | 0.68640.01 | 0.67320.01 | 0.66740.01 | 0.64300.01 | 0.6867 |
| LLSF | 0.67610.01 | 0.71140.01 | 0.70320.01 | 0.68590.01 | 0.67230.01 | 0.66720.01 | 0.64270.01 | 0.6867 |
| ELC | 0.67790.00 | 0.71880.01 | 0.70530.01 | 0.69050.00 | 0.67890.00 | 0.66810.01 | 0.64650.00 | 0.6911 |
| (c) Hamming loss (the lower the better). | ||||||||
| Approaches | Data Sets | AVG. | ||||||
| Emotions | Yeast | Birds | Enron | Genbase | Business | Arts | ||
| MIFS | 0.28650.02 | 0.20060.01 | 0.05380.00 | 0.05440.00 | 0.03030.02 | 0.02700.00 | 0.06100.00 | 0.1019 |
| CMFS | 0.26000.01 | 0.20310.01 | 0.05350.00 | 0.05270.00 | 0.03030.02 | 0.02530.00 | 0.05680.00 | 0.0974 |
| LLSF | 0.26970.01 | 0.19990.01 | 0.05320.00 | 0.05390.00 | 0.03030.02 | 0.02530.00 | 0.05680.00 | 0.0984 |
| ELC | 0.25170.02 | 0.19820.01 | 0.05180.00 | 0.05230.00 | 0.00490.00 | 0.02510.00 | 0.05670.00 | 0.0915 |
| Education | Reaction | Health | Computers | Science | Reference | Society | ||
| MIFS | 0.04300.00 | 0.05390.00 | 0.03730.00 | 0.03790.00 | 0.03530.00 | 0.03170.00 | 0.05570.00 | 0.0399 |
| CMFS | 0.03710.00 | 0.05360.00 | 0.03680.00 | 0.03500.00 | 0.03220.00 | 0.02800.00 | 0.05110.00 | 0.0394 |
| LLSF | 0.03710.00 | 0.05360.00 | 0.03690.00 | 0.03490.00 | 0.03220.00 | 0.02800.00 | 0.05120.00 | 0.0394 |
| ELC | 0.03680.00 | 0.05310.00 | 0.03660.00 | 0.03480.00 | 0.03190.00 | 0.02780.00 | 0.05080.00 | 0.0391 |
| (d) Ranking loss (the lower the better). | ||||||||
| Approaches | Data Sets | AVG. | ||||||
| Emotions | Yeast | Birds | Enron | Genbase | Business | Arts | ||
| MIFS | 0.31540.05 | 0.17670.01 | 0.29880.01 | 0.09860.01 | 0.05860.03 | 0.03770.00 | 0.15100.05 | 0.1624 |
| CMFS | 0.24040.02 | 0.18100.01 | 0.28870.02 | 0.09590.00 | 0.05940.03 | 0.03360.00 | 0.13410.00 | 0.1476 |
| LLSF | 0.27110.02 | 0.17560.01 | 0.27770.05 | 0.09620.01 | 0.05910.03 | 0.03350.00 | 0.13410.00 | 0.1496 |
| ELC | 0.23790.02 | 0.17330.01 | 0.25680.05 | 0.09240.00 | 0.00650.00 | 0.03340.00 | 0.13320.00 | 0.1334 |
| Education | Reaction | Health | Computers | Science | Reference | Society | ||
| MIFS | 0.09880.00 | 0.14590.01 | 0.04980.00 | 0.08200.00 | 0.13510.01 | 0.08490.00 | 0.13720.00 | 0.0994 |
| CMFS | 0.07680.00 | 0.14380.01 | 0.04920.00 | 0.07350.00 | 0.11120.00 | 0.07340.00 | 0.11750.00 | 0.0897 |
| LLSF | 0.07680.00 | 0.14380.01 | 0.04920.00 | 0.07360.00 | 0.11110.00 | 0.07360.00 | 0.11760.00 | 0.0898 |
| ELC | 0.07590.00 | 0.14050.00 | 0.04860.00 | 0.07280.00 | 0.10850.00 | 0.07310.00 | 0.11610.00 | 0.0883 |
| (e) One error (the lower the better). | ||||||||
| Approaches | Data Sets | AVG. | ||||||
| Emotions | Yeast | Birds | Enron | Genbase | Business | Arts | ||
| MIFS | 0.44510.05 | 0.24030.01 | 0.72260.03 | 0.32300.03 | 0.36980.21 | 0.11870.00 | 0.62150.01 | 0.4059 |
| CMFS | 0.38710.02 | 0.24450.01 | 0.69680.04 | 0.30930.02 | 0.37190.21 | 0.10610.00 | 0.55180.01 | 0.3811 |
| LLSF | 0.39860.03 | 0.23870.01 | 0.68790.08 | 0.31580.05 | 0.37070.21 | 0.10580.00 | 0.55090.01 | 0.3812 |
| ELC | 0.36640.03 | 0.23610.01 | 0.61920.11 | 0.29880.01 | 0.01230.00 | 0.10500.00 | 0.54640.00 | 0.3120 |
| Education | Reaction | Health | Computers | Science | Reference | Society | ||
| MIFS | 0.64520.02 | 0.52920.02 | 0.33350.03 | 0.40410.01 | 0.67610.02 | 0.47430.01 | 0.46840.01 | 0.5104 |
| CMFS | 0.49890.01 | 0.52340.02 | 0.32660.02 | 0.37380.01 | 0.56050.02 | 0.42080.01 | 0.39330.01 | 0.4537 |
| LLSF | 0.49930.01 | 0.52370.02 | 0.32670.02 | 0.37350.00 | 0.56050.02 | 0.42020.01 | 0.39370.01 | 0.4536 |
| ELC | 0.49230.00 | 0.51470.01 | 0.32230.02 | 0.36990.00 | 0.54900.01 | 0.41720.00 | 0.38850.00 | 0.4771 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Xu, Y.; Xu, H.; Sun, Z.; Yang, Z.; Wei, J. An Effective Multi-Label Feature Selection Model Towards Eliminating Noisy Features. Appl. Sci. 2020, 10, 8093. https://doi.org/10.3390/app10228093
Wang J, Xu Y, Xu H, Sun Z, Yang Z, Wei J. An Effective Multi-Label Feature Selection Model Towards Eliminating Noisy Features. Applied Sciences. 2020; 10(22):8093. https://doi.org/10.3390/app10228093
Chicago/Turabian StyleWang, Jun, Yuanyuan Xu, Hengpeng Xu, Zhe Sun, Zhenglu Yang, and Jinmao Wei. 2020. "An Effective Multi-Label Feature Selection Model Towards Eliminating Noisy Features" Applied Sciences 10, no. 22: 8093. https://doi.org/10.3390/app10228093
APA StyleWang, J., Xu, Y., Xu, H., Sun, Z., Yang, Z., & Wei, J. (2020). An Effective Multi-Label Feature Selection Model Towards Eliminating Noisy Features. Applied Sciences, 10(22), 8093. https://doi.org/10.3390/app10228093