Continuous Genetic Algorithms in the Optimization of Logistic Networks: Applicability Assessment and Tuning



Abstract
Featured Application
Abstract
1. Introduction
- Investigate how to adjust the parameters of the popular inventory management policy when operating in a complex networked structure such that the cost and service level objectives are attained.
- Show how to select the CGA parameters for the task of optimizing the logistic network performance, which requires significant computational effort to evaluate the population fitness owing to non-trivial node interaction and the uncertain nature of the demand.
2. Related Works
3. System Model
3.1. Problem Statement and Preliminaries
3.2. System Actors and Their Relationships
- αij is the supplier fraction (SF), which designates how much of the current lot requested by node nj is to be obtained from node ni, αij ∈ [0, 1].
- βij is the lead-time delay (LTD), which is the time of order completion and shipment from node ni to node nj, βij ∈ [1, Β], where B denotes the maximum LTD between any two directly connected nodes.
3.3. State-Space Representation
- l(t) is the vector of on-hand stock levels.
- s(t) is the vector of satisfied demands.
- o(t) is the vector of stock replenishment orders.
- M0(t) is the hollow matrix representing the internal trans-shipments:
- Mβ(t) are the diagonal matrices describing the node interconnections, i.e., for each β ∈ [1, Β]:
3.4. Order-Up-To Policy
- Register the shipments obtained from the node suppliers (external sources and neighbors in the network).
- Fulfill the external demand, if possible.
- Fulfill the orders originating from other nodes in the network, if possible.
- Based on the discrepancy between the current stock and the RSL, generate a stock replenishment order.
3.5. Networked Order-Up-To Policy
4. GA Application in Goods Distribution Systems
4.1. Introductory Considerations
4.2. System Setting
- The vector of RSLs reflects an individual in the population. Consequently, the stock level at a controlled node will correspond to the chromosomes in a given individual.
- Since the domain of inventory stock levels is continuous (any value from the assumed range can form an individual), a CGA is employed instead of a binary-form GA.
- The fitness function value is obtained via numerical simulations of the system behavior, which is in response to the control inputs established either according to (12) (classical, distributed policy) or (14) (networked, centralized policy).
4.3. Initialization
4.4. Fitness Function
- The goods holding cost HC, HC ∈ [0, HCmax], which quantifies the internal efficiency regarding goods redistribution.
- The fill rate FR, where FR ∈ [0, 1], which quantifies the system interaction with the external actors that generate the demand.
4.5. Selection
4.6. Crossover
4.7. Mutation
4.8. CGA Summary
5. Numerical Study
- A simulation interval.
- The number of nodes.
- The type of inventory control strategy used to steer the goods distribution process.
- The type of statistical distribution used for generating demand requests.
5.1. CGA vs. Monte Carlo (MC) Method
5.2. The CGA in the Inventory Policy Optimization
- Simulation interval T = 50 periods.
- External demand was imposed on all the controlled nodes, which was generated using a gamma distribution with the shape and scale coefficients equal to 5 and 10, respectively.
- The CGA population comprised 10 individuals.
- Mutation probability = 15%.
- Stop conditions: generation limit = 104, the number of generations without improvement = 103.
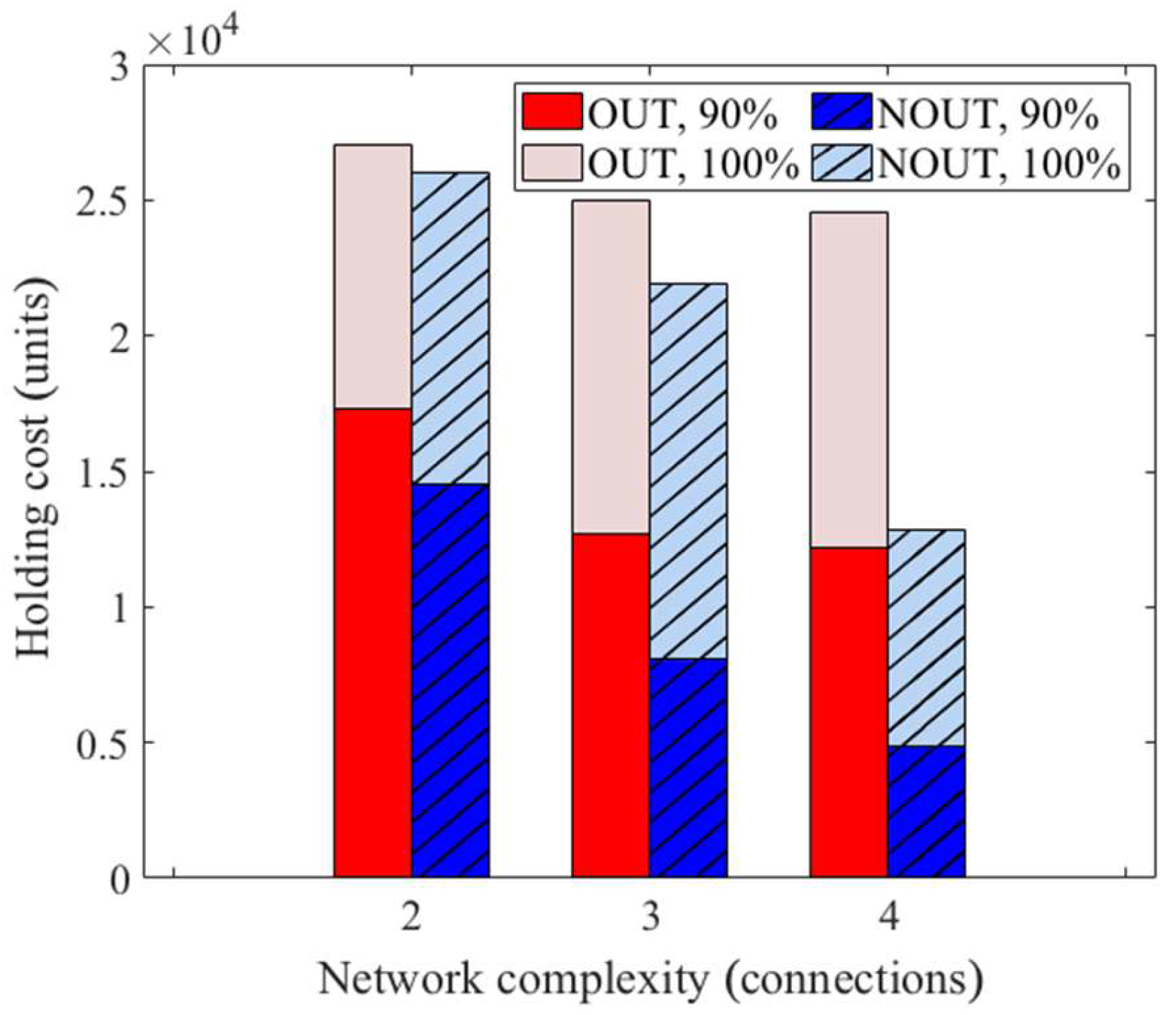
5.2.1. Small Network (N1)
5.2.2. Large Network (N2)
6. Results Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ignaciuk, P.; Bartoszewicz, A. Linear-quadratic optimal control of periodic-review perishable inventory systems. IEEE Trans. Control Syst. Technol. 2012, 20, 1400–1407. [Google Scholar] [CrossRef]
- Shaban, A.; Shalaby, M.A.; Di Gravio, G.; Patriarca, R. Analysis of Variance Amplification and Service Level in a Supply Chain with Correlated Demand. Sustainability 2020, 12, 6470. [Google Scholar] [CrossRef]
- Ignaciuk, P. Discrete inventory control in systems with perishable goods—A time-delay system perspective. IET Control Theory A 2014, 8, 11–21. [Google Scholar] [CrossRef]
- Yuan, B.; He, L.; Gu, B.; Zhang, Y. The Evolutionary Game Theoretic Analysis for Emission Reduction and Promotion in Low-Carbon Supply Chains. Appl. Sci. 2018, 8, 1965. [Google Scholar] [CrossRef]
- Ignaciuk, P. Nonlinear inventory control with discrete sliding modes in systems with uncertain delay. IEEE Trans. Ind. Inform. 2014, 10, 559–568. [Google Scholar] [CrossRef]
- Chu, Y.; You, F.; Wassick, J.M.; Agarwal, A. Simulation-based optimization framework for multi-echelon inventory systems under uncertainty. Comput. Chem. Eng. 2015, 73, 1–16. [Google Scholar] [CrossRef]
- Patriarca, R.; Hu, T.; Costantino, F.; Di Gravio, G.; Tronci, M. A System-Approach for Recoverable Spare Parts Management Using the Discrete Weibull Distribution. Sustainability 2019, 11, 5180. [Google Scholar] [CrossRef]
- Cattani, K.D.; Jacobs, F.R.; Schoenfelder, J. Common inventory modeling assumptions that fall short: Arborescent networks, Poisson demand, and single-echelon approximations. J. Oper. Manag. 2011, 29, 488–499. [Google Scholar] [CrossRef]
- Papadopoulos, C.T.; Li, J.; O’Kelly, M.E.J. A classification and review of timed Markov models of manufacturing systems. Comput. Ind. Eng. 2019, 128, 219–244. [Google Scholar] [CrossRef]
- Ignaciuk, P.; Wieczorek, Ł. Optimization of mesh-type logistic networks for achieving max service rate under order-up-to inventory policy. Adv. Intell. Syst. 2018, 657, 118–127. [Google Scholar] [CrossRef]
- Min, H. Artificial intelligence in supply chain management: Theory and applications. Int. J. Logist. Appl. 2010, 13, 13–39. [Google Scholar] [CrossRef]
- Baryannis, G.; Validi, S.; Dani, S.; Antoniou, G. Supply chain risk management and artificial intelligence: State of the art and future research directions. Int. J. Prod. Res. 2018, 57, 2179–2202. [Google Scholar] [CrossRef]
- Ko, M.; Tiwari, A.; Mehnen, J. A review of soft computing applications in supply chain management. Appl. Soft Comput. 2010, 10, 661–674. [Google Scholar] [CrossRef]
- Knoll, D.; Prüglmeier, M.; Reinhart, G. Predicting future inbound logistics processes using machine learning. Proc. CIRP 2016, 52, 145–150. [Google Scholar] [CrossRef]
- González-Reséndiz, J.; Arredondo-Soto, K.C.; Realyvásquez-Vargas, A.; Híjar-Rivera, H.; Carrillo-Gutiérrez, T. Integrating Simulation-Based Optimization for Lean Logistics: A Case Study. Appl. Sci. 2018, 8, 2448. [Google Scholar] [CrossRef]
- Rivera-Gómez, H.; Montaño-Arango, O.; Corona-Armenta, J.R.; Garnica-González, J.; Ortega-Reyes, A.O.; Anaya-Fuentes, G.E. JIT Production Strategy and Maintenance for Quality Deteriorating Systems. Appl. Sci. 2019, 9, 1180. [Google Scholar] [CrossRef]
- Pourhejazy, P.; Kwon, O.K. The New Generation of Operations Research Methods in Supply Chain Optimization: A Review. Sustainability 2016, 8, 1033. [Google Scholar] [CrossRef]
- Simon, D. Evolutionary Optimization Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Jauhar, S.K.; Pant, M. Genetic algorithms in supply chain management: A critical analysis of the literature. Sādhanā 2016, 41, 993–1017. [Google Scholar] [CrossRef]
- Lee, C.K.H. A review of applications of genetic algorithms in operations management. Eng. Appl. Artif. Intel. 2018, 76, 1–12. [Google Scholar] [CrossRef]
- Mihăiţă, A.S.; Dupont, L.; Camargo, M. Multi-objective traffic signal optimization using 3D mesoscopic simulation and evolutionary algorithms. Simul. Model. Pract. Theory 2018, 86, 120–138. [Google Scholar] [CrossRef]
- Axsäter, S. Inventory Control; Springer: New York, NJ, USA, 2015. [Google Scholar]
- Ignaciuk, P. Dynamic modeling and order-up-to inventory management in logistic networks with positive lead time. In Proceedings of the 2015 IEEE International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2015; pp. 507–510. [Google Scholar] [CrossRef]
- Dominguez, R.; Cannella, S.; Framinan, J.M. On bullwhip-limiting strategies in divergent supply chain networks. Comput. Ind. Eng. 2014, 73, 85–95. [Google Scholar] [CrossRef]
- Wangphanich, P.; Kara, S.; Kayis, B. Analysis of the bullwhip effect in multi-product, multi-stage supply chain systems—A simulation approach. Int. J. Prod. Res. 2010, 48, 4501–4517. [Google Scholar] [CrossRef]
- Basten, R.J.I.; van Houtum, G.J. Near-optimal heuristics to set base stock levels in a two-echelon distribution network. Int. J. Prod. Econ. 2013, 143, 546–552. [Google Scholar] [CrossRef]
- Chang, K.H.; Lu, Y.S. Inventory management in a base-stock controlled serial production system with finite storage space. Math. Comput. Model. 2011, 54, 2750–2759. [Google Scholar] [CrossRef]
- Albrecht, M. Determining near optimal base-stock levels in two-stage general inventory systems. Eur. J. Oper. Res. 2013, 232, 342–349. [Google Scholar] [CrossRef]
- Wang, Q. A periodic-review inventory control policy for a two-level supply chain with multiple retailers and stochastic demand. Eur. J. Oper. Res. 2013, 230, 53–62. [Google Scholar] [CrossRef]
- Guerrero, W.J.; Yeung, T.G.; Guéret, C. Joint-optimization of inventory policies on a multi-product multi-echelon pharmaceutical system with batching and ordering constraints. Eur. J. Oper. Res. 2013, 231, 98–108. [Google Scholar] [CrossRef]
- Eruguz, A.S.; Jemai, Z.; Sahin, E.; Dallery, Y. Optimising reorder intervals and order-up-to levels in guaranteed service supply chains. Int. J. Prod. Res. 2014, 52, 149–164. [Google Scholar] [CrossRef]
- Avci, M.G.; Selim, H. A Multi-objective, simulation-based optimization framework for supply chains with premium freights. Expert. Syst. Appl. 2017, 67, 95–106. [Google Scholar] [CrossRef]
- Horng, S.C.; Lin, S.S. Ordinal optimization based metaheuristic algorithm for optimal inventory policy of assemble-to-order systems. Appl. Math. Model. 2017, 42, 43–57. [Google Scholar] [CrossRef]
- Feng, P.; Wu, F.; Fung, R.Y.K.; Jia, T.; Zong, W. The order and transshipment decisions in a two-location inventory system with demand forecast updates. Comput. Ind. Eng. 2019, 135, 53–66. [Google Scholar] [CrossRef]
- Dominguez, R.; Cannella, S.; Framinan, J.M. The impact of the supply chain structure on bullwhip effect. Appl. Math. Model. 2015, 39, 7309–7325. [Google Scholar] [CrossRef]
- Ignaciuk, P.; Bartoszewicz, A. Linear-quadratic optimal control strategy for periodic-review inventory systems. Automatica 2010, 46, 1982–1993. [Google Scholar] [CrossRef]
- Lim, J.; Norman, B.A.; Rajgopal, J. Redesign of vaccine distribution networks. Int. Trans. Oper. Res. 2019. [Google Scholar] [CrossRef]
- Grob, C. Inventory Management in Multi-Echelon Networks: On the Optimization of Reorder Points; Springer: Wiesbaden, Germany, 2019. [Google Scholar]
- Ignaciuk, P.; Wieczorek, Ł. Networked base-stock inventory control in complex distribution systems. Math. Probl. Eng. 2019, 2019, 3754367. [Google Scholar] [CrossRef]
- Ivanov, D. Simulation-based ripple effect modelling in the supply chain. Int. J. Prod. Res. 2016, 55, 2083–2101. [Google Scholar] [CrossRef]
- Song, W.; Xi, H.; Kang, D.; Zhang, J. An agent-based simulation system for multi-project scheduling under uncertainty. Simul. Model. Pract. Theory 2018, 86, 187–203. [Google Scholar] [CrossRef]
- Wang, Y.; Shi, Q. Improved dynamic PSO-Based algorithm for critical spare parts supply optimization under (T, S) inventory policy. IEEE Access 2019, 7, 153694–153709. [Google Scholar] [CrossRef]
- Koulouriotis, D.E.; Xanthopoulos, A.S.; Tourassis, V.D. Simulation optimisation of pull control policies for serial manufacturing lines and assembly manufacturing systems using genetic algorithms. Int. J. Prod. Res. 2010, 48, 2887–2912. [Google Scholar] [CrossRef][Green Version]
- Paul, B.; Rajendran, C. Rationing mechanisms and inventory control-policy parameters for a divergent supply chain operating with lost sales and costs of review. Comput. Oper. Res. 2011, 38, 1117–1130. [Google Scholar] [CrossRef]
- Ambekar, S.; Kapoor, R. Optimization of inventory policies of food grain distribution stage in public distribution system. Benchmark Int. J. 2019, 26, 692–713. [Google Scholar] [CrossRef]
- Senoussi, A.; Dauzère-Pérès, S.; Brahimi, N.; Penz, B.; Mouss, N.K. Heuristics Based on Genetic Algorithms for the Capacitated Multi Vehicle Production Distribution Problem. Comput. Oper. Res. 2018, 96, 108–119. [Google Scholar] [CrossRef]
- Pal, A.; Kant, K. Smartporter: A Combined Perishable Food and People Transport Architecture in Smart Urban Areas. In Proceeding of the 2016 IEEE International Conference on Smart Computing (SMARTCOMP), St. Louis, MI, USA, 18–20 May 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Murali, P.; Ordóñez, F.; Dessouky, M.M. Modeling strategies for effectively routing freight trains through complex networks. Transp. Res. Part C Emerg. Technol. 2016, 70, 197–213. [Google Scholar] [CrossRef]
- Deng, L.B.; He, Y.; Zeng, N.X.; Zeng, J.H. Optimal Design of Feeder-Bus Network with Split Delivery. J. Transp. Eng. Part A Syst. 2020, 146, 04019078. [Google Scholar] [CrossRef]
- Zhou, K.; He, S.; Song, R.; Guo, X.; Li, K. Optimization Model and Algorithm of Empty Pallets Dispatching under the Time-Space Network of Express Shipment. J. Adv. Transp. 2018, 2018, 1897936. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, J.; Zhang, Y.; Gan, X. A multi-objective evolutionary algorithm for multi-period dynamic emergency resource scheduling problems. Transp. Res. Part E Logist. Transp. Rev. 2017, 99, 77–95. [Google Scholar] [CrossRef]
- Haghi, M.; Ghomi, S.M.T.F.; Jolai, F. Developing a robust multi-objective model for pre/post disaster times under uncertainty in demand and resource. J. Clean. Prod. 2017, 154, 188–202. [Google Scholar] [CrossRef]
- Petrović, M.; Miljković, Z.; Jokić, A. A novel methodology for optimal single mobile robot scheduling using whale optimization algorithm. Appl. Soft Comput. 2019, 81, 105520. [Google Scholar] [CrossRef]
- Wang, Y.; Geng, X.; Zhang, F.; Ruan, J. An immune genetic algorithm for multi-echelon inventory cost control of IoT based supply chains. IEEE Access 2018, 6, 8547–8555. [Google Scholar] [CrossRef]
- Ignaciuk, P. State-space modeling and analysis of order-up-to goods distribution networks with variable demand and positive lead time. Adv. Intell. Syst. 2017, 524, 55–65. [Google Scholar] [CrossRef]
- Roberge, V.; Tarbouchi, M.; Labonte, G. Fast genetic algorithm path planner for fixed-wing military UAV Using GPU. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 2105–2117. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| (…)+ | The saturation function restricting the argument to non-negative values |
| t = 1, 2, …, T | Period, where T is the planning horizon |
| ΘN = {1, 2, …, N} | The set containing the controlled node indices, where N is their total number |
| ΘM = {1, 2, …, M} | The set containing the external source indices, where M is their total number |
| αij | Nominal supplier fraction between nodes i and j, i.e., the part of the replenishment signals generated by node j that is requested from supplier i |
| αij(t) | Supplier fraction between nodes i and j in period t |
| βij | Lead-time delay between nodes i and j, i.e., the time from placing the order to its delivery |
| B | The highest lead-time delay between any two nodes in the system |
| li(t) | The on-hand stock level at node i in period t |
| di(t) | The external demand imposed on node i in period t |
| si(t) | The external demand satisfied by node i in period t |
| oi(t) | The amount of goods to be ordered by node i at the end of period t from its suppliers |
| The quantity of goods in replenishment orders sent by node i to its neighbors in period t | |
| The quantity of goods in replenishment orders received by node i from its suppliers in period t | |
| l(t) | The vector containing on-hand stock levels at the controlled nodes in period t |
| d(t) | The vector containing the external demands imposed on the controlled nodes in period t |
| s(t) | The vector containing the external demands satisfied by the controlled nodes in period t |
| o(t) | The vector containing the replenishment signals generated by the controlled nodes in period t |
| Population Size | Fitness Function Value | Best Fitness Value Ratio | Simulation Time (ms) |
|---|---|---|---|
| 4 | 0.8335 | 0.9362 | 16,914 |
| 10 | 0.8778 | 0.9859 | 43,292 |
| 50 | 0.8823 | 0.9910 | 479,072 |
| 100 | 0.8904 | 1.0000 | 583,971 |
| Selection Method | Fitness Function Value |
|---|---|
| Stochastic universal sampling | 0.4872 |
| Roulette wheel selection | 0.7655 |
| Tournament selection | 0.8831 |
| Crossover Method | Fitness Function Value |
|---|---|
| None | 0.0288 |
| Single-point crossover | 0.7853 |
| Multipoint crossover | 0.8865 |
| Uniform crossover | 0.8242 |
| Mutation Probability | Fitness Function Value |
|---|---|
| 0 | 0.3931 |
| 0.01 | 0.8706 |
| 0.05 | 0.8690 |
| 0.1 | 0.8709 |
| 0.15 | 0.8823 |
| 0.25 | 0.8800 |
| 0.5 | 0.8031 |
| Phase | Parameter | Setting |
|---|---|---|
| Initialization | Population size | 10 individuals |
| Stop criterion | 103–104 generations | |
| Fitness function | ||
| Evolution | Selection | Four-way tournament selection |
| Crossover | Two-point crossover | |
| Mutation | 15% mutation probability |
| Number of Nodes | Optimization Method | Fitness Function Coefficients | Performance Indicators | Best Fitness Function | Fitness Value Difference | ||
|---|---|---|---|---|---|---|---|
| γ | φ | Holding Cost | Fill Rate | ||||
| 5 | MC | 1 | 1 | 3086 | 94% | 0.84691098 | 0.0013 |
| 5 | CGA | 1 | 1 | 3043 | 94% | 0.84820807 | |
| 5 | MC | 1 | 10 | 7715 | 100% | 0.75242282 | 0.0097 |
| 5 | CGA | 1 | 10 | 7412 | 100% | 0.7621462 | |
| 5 | MC | 10 | 1 | 676 | 73% | 0.58623815 | 0.0031 |
| 5 | CGA | 10 | 1 | 660 | 73% | 0.58932219 | |
| 14 | MC | 1 | 1 | 8068 | 94% | 0.90066472 | 0.0427 |
| 14 | CGA | 1 | 1 | 9076 | 99% | 0.94339654 | |
| 14 | MC | 1 | 10 | 31,326 | 100% | 0.83752243 | 0.1008 |
| 14 | CGA | 1 | 10 | 11,892 | 100% | 0.93832014 | |
| 14 | MC | 10 | 1 | 4438 | 88% | 0.69718233 | 0.0485 |
| 14 | CGA | 10 | 1 | 3593 | 90% | 0.74566725 | |
| 27 | MC | 1 | 1 | 59,828 | 99% | 0.92887945 | 0.0425 |
| 27 | CGA | 1 | 1 | 18,210 | 99% | 0.97139658 | |
| 27 | MC | 1 | 10 | 105,453 | 100% | 0.89118056 | 0.0763 |
| 27 | CGA | 1 | 10 | 31,488 | 100% | 0.96750679 | |
| 27 | MC | 10 | 1 | 42,873 | 96% | 0.61059353 | 0.2361 |
| 27 | CGA | 10 | 1 | 13,086 | 97% | 0.84669328 | |
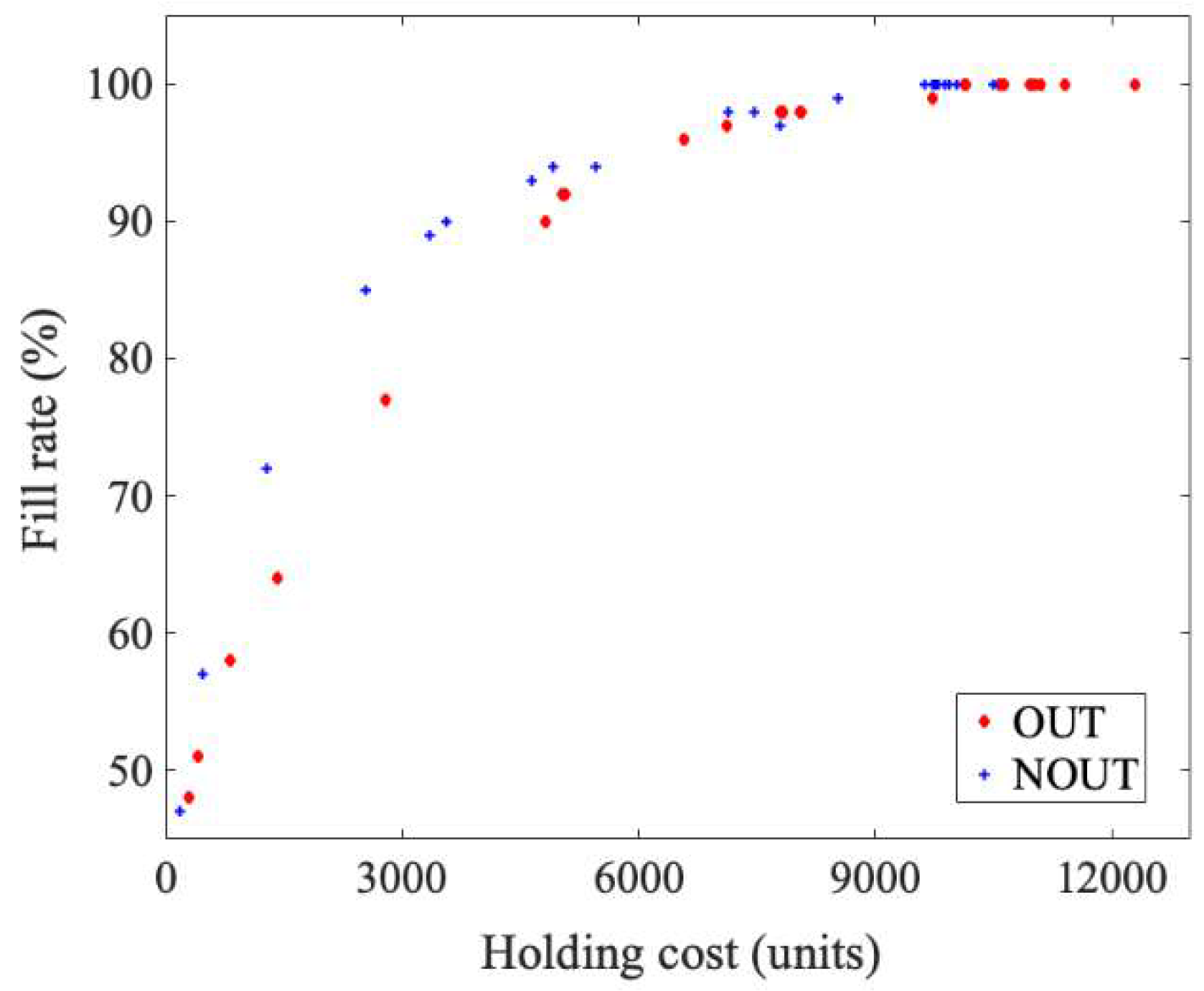
| Fitness Function Coefficients | Order-Up-To (OUT) Policy | Networked OUT (NOUT) Policy | |||
|---|---|---|---|---|---|
| γ | φ | Holding Cost | Fill Rate | Holding Cost | Fill Rate |
| 1 | 1 | 7831 | 98% | 8523 | 99% |
| 1 | 5 | 10,965 | 100% | 10,496 | 100% |
| 1 | 20 | 10,576 | 100% | 9882 | 100% |
| 1 | 50 | 11,092 | 100% | 10,036 | 100% |
| 1 | 100 | 11,407 | 100% | 9947 | 100% |
| 5 | 1 | 4814 | 90% | 3347 | 89% |
| 5 | 5 | 8036 | 98% | 7792 | 97% |
| 5 | 20 | 10,124 | 100% | 9808 | 100% |
| 5 | 50 | 10,160 | 100% | 9721 | 100% |
| 5 | 100 | 11,026 | 100% | 9748 | 100% |
| 20 | 1 | 819 | 58% | 1280 | 72% |
| 20 | 5 | 5073 | 92% | 3564 | 90% |
| 20 | 20 | 8060 | 98% | 7467 | 98% |
| 20 | 50 | 10,625 | 100% | 9804 | 100% |
| 20 | 100 | 12,287 | 100% | 9763 | 100% |
| 50 | 1 | 411 | 51% | 468 | 57% |
| 50 | 5 | 2783 | 77% | 2532 | 85% |
| 50 | 20 | 6585 | 96% | 4921 | 94% |
| 50 | 50 | 7804 | 98% | 7142 | 98% |
| 50 | 100 | 9728 | 99% | 9635 | 100% |
| 100 | 1 | 296 | 48% | 176 | 47% |
| 100 | 5 | 1414 | 64% | 1282 | 72% |
| 100 | 20 | 5028 | 92% | 3560 | 90% |
| 100 | 50 | 7111 | 97% | 4646 | 93% |
| 100 | 100 | 7803 | 98% | 5463 | 94% |
| Fitness Function Coefficients | OUT Policy | NOUT Policy | |||
|---|---|---|---|---|---|
| γ | φ | Holding Cost | Fill Rate | Holding Cost | Fill Rate |
| 1 | 1 | 70,538 | 100% | 54,079 | 99% |
| 1 | 5 | 71,022 | 100% | 67,596 | 100% |
| 1 | 20 | 75,454 | 100% | 61,101 | 100% |
| 1 | 50 | 76,549 | 100% | 63,390 | 100% |
| 1 | 100 | 93,568 | 100% | 62,277 | 100% |
| 5 | 1 | 34,999 | 90% | 24,977 | 93% |
| 5 | 5 | 65,246 | 99% | 55,363 | 99% |
| 5 | 20 | 79,339 | 100% | 57,843 | 100% |
| 5 | 50 | 87,859 | 100% | 60,545 | 100% |
| 5 | 100 | 73,144 | 100% | 67,893 | 100% |
| 20 | 1 | 15,840 | 68% | 10,456 | 77% |
| 20 | 5 | 41,023 | 93% | 23,463 | 92% |
| 20 | 20 | 58,958 | 98% | 49,282 | 99% |
| 20 | 50 | 77,607 | 100% | 56,149 | 99% |
| 20 | 100 | 86,818 | 100% | 56,969 | 99% |
| 50 | 1 | 6538 | 47% | 5349 | 63% |
| 50 | 5 | 27,577 | 84% | 16,686 | 86% |
| 50 | 20 | 42,402 | 94% | 30,863 | 95% |
| 50 | 50 | 62,475 | 98% | 54,078 | 99% |
| 50 | 100 | 71,686 | 100% | 53,318 | 99% |
| 100 | 1 | 3139 | 35% | 2915 | 52% |
| 100 | 5 | 13,594 | 64% | 10,746 | 78% |
| 100 | 20 | 36,217 | 90% | 26,947 | 93% |
| 100 | 50 | 53,074 | 97% | 33,801 | 96% |
| 100 | 100 | 63,704 | 99% | 56,342 | 100% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ignaciuk, P.; Wieczorek, Ł. Continuous Genetic Algorithms in the Optimization of Logistic Networks: Applicability Assessment and Tuning. Appl. Sci. 2020, 10, 7851. https://doi.org/10.3390/app10217851
Ignaciuk P, Wieczorek Ł. Continuous Genetic Algorithms in the Optimization of Logistic Networks: Applicability Assessment and Tuning. Applied Sciences. 2020; 10(21):7851. https://doi.org/10.3390/app10217851
Chicago/Turabian StyleIgnaciuk, Przemysław, and Łukasz Wieczorek. 2020. "Continuous Genetic Algorithms in the Optimization of Logistic Networks: Applicability Assessment and Tuning" Applied Sciences 10, no. 21: 7851. https://doi.org/10.3390/app10217851
APA StyleIgnaciuk, P., & Wieczorek, Ł. (2020). Continuous Genetic Algorithms in the Optimization of Logistic Networks: Applicability Assessment and Tuning. Applied Sciences, 10(21), 7851. https://doi.org/10.3390/app10217851