Contextual Identification of Windows Malware through Semantic Interpretation of API Call Sequence



Abstract
1. Introduction
2. Related Work
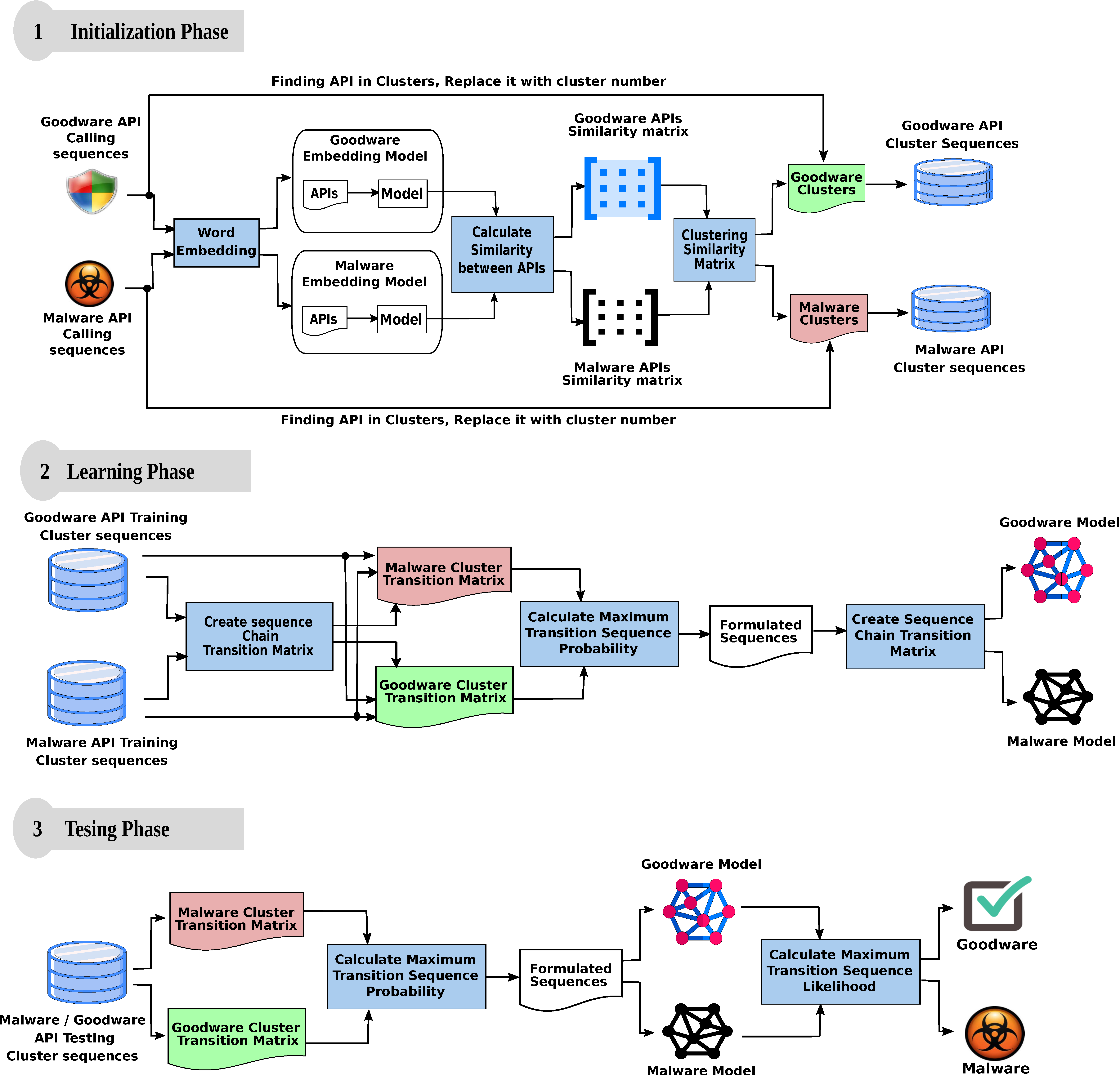
3. Proposed Model
3.1. Initialization Phase
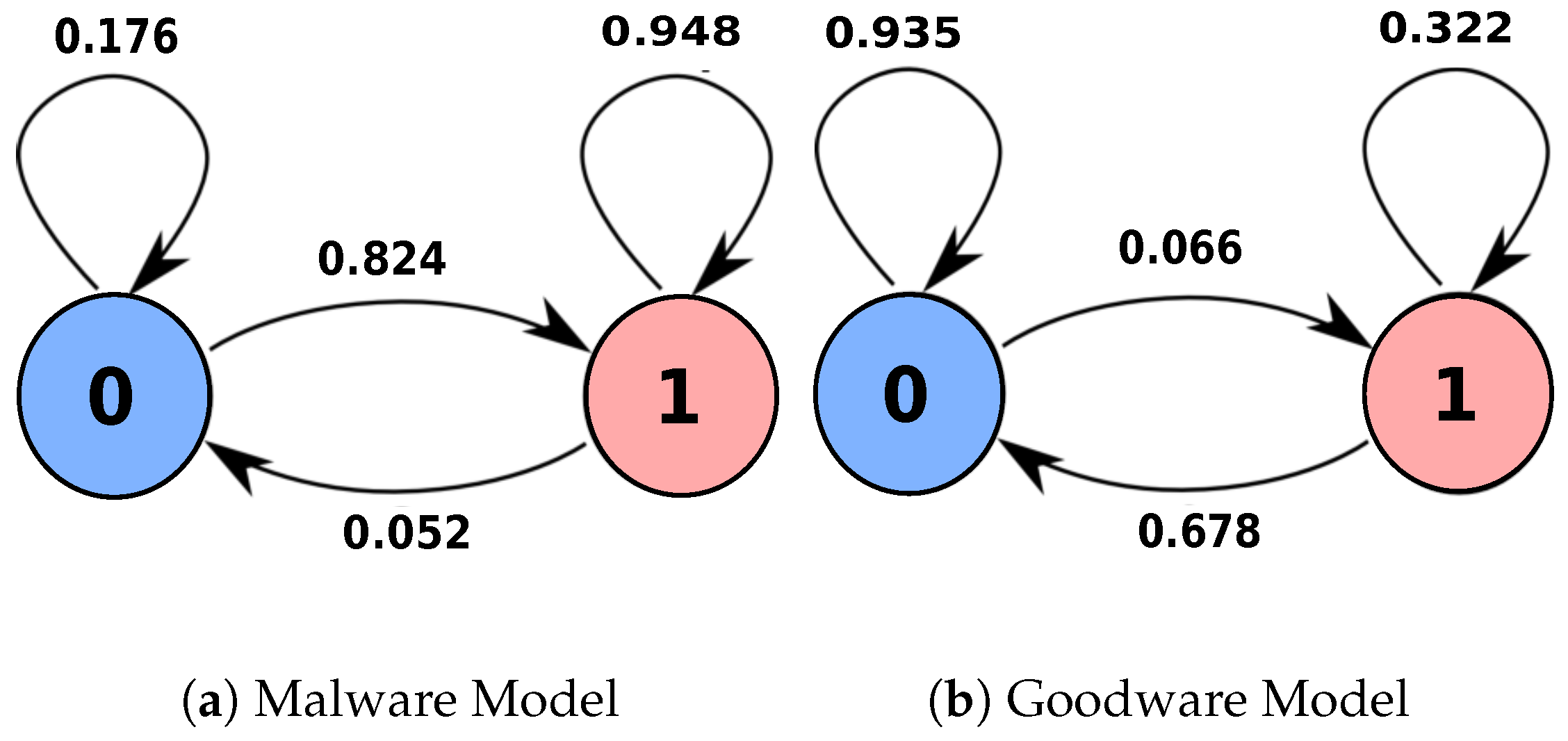
3.2. Learning Phase
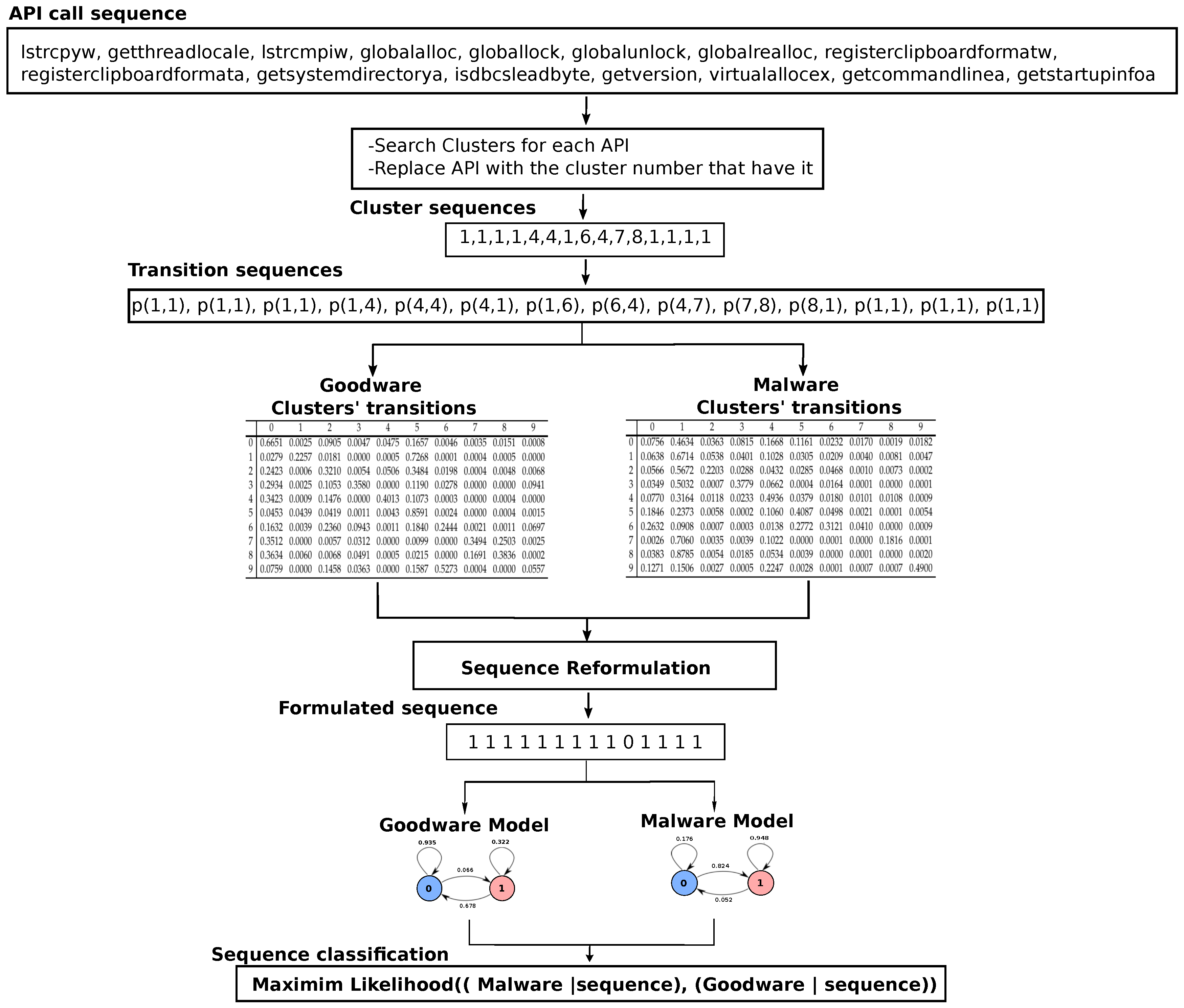
3.3. Testing Phase
4. Results and Discussion
4.1. Datasets
4.2. Evaluation Metrics
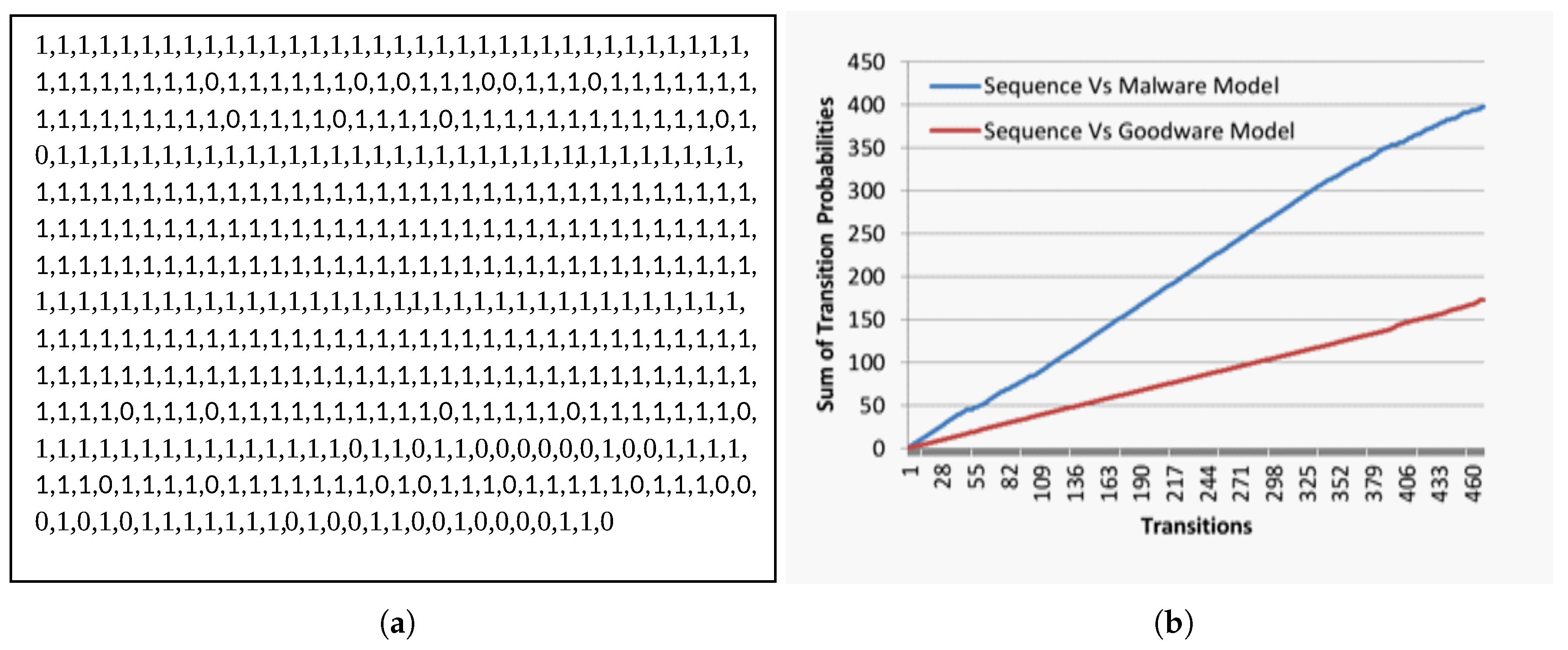
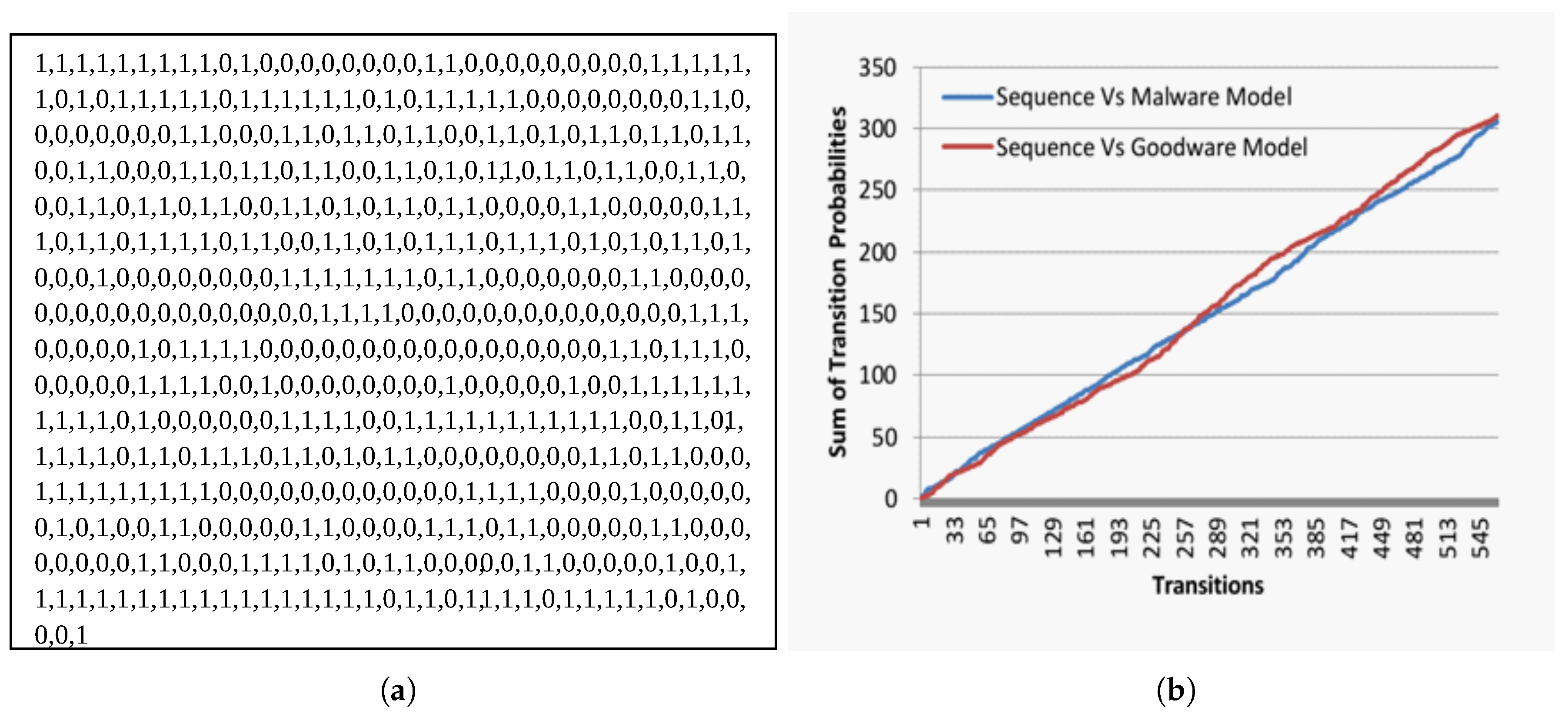
4.3. Malware Detection Evaluation
4.4. Fake Goodware Detection
- S denotes the input sequence,
- n is the total number of transitions of a given sequence,
- refers to cumulative transition probabilities for the sequence up to the i-th transition in malware and goodware models,
- The exterior summation counts the events concerning the internal comparison between the two inner sums judged as true.
- the numerator denotes the number of times where the inner comparison is evaluated as false,
- denotes the total number of transitions in the sequence S.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zelinka, I.; Amer, E. An Ensemble-Based Malware Detection Model Using Minimum Feature Set. Mendel 2019, 25, 1–10. [Google Scholar] [CrossRef]
- Gandotra, E.; Bansal, D.; Sofat, S. Malware analysis and classification: A survey. J. Inf. Secur. 2014, 5, 9. [Google Scholar] [CrossRef]
- Amer, E.; Zelinka, I. A dynamic Windows malware detection and prediction method based on contextual understanding of API call sequence. Comput. Secur. 2020, 92, 101760. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Alazab, M.; Soman, K.P.; Poornachandran, P.; Venkatraman, S. Robust intelligent malware detection using deep learning. IEEE Access 2019, 7, 46717–46738. [Google Scholar] [CrossRef]
- Yan, J.; Qi, Y.; Rao, Q. Detecting malware with an ensemble method based on deep neural network. Secur. Commun. Netw. 2018, 2018. [Google Scholar] [CrossRef]
- Qiao, Y.; Yang, Y.; He, J.; Tang, C.; Liu, Z. CBM: Free, automatic malware analysis framework using API call sequences. In Knowledge Engineering and Management; Springer: Berlin/Heidelberg, Germany, 2014; pp. 225–236. [Google Scholar]
- Galal, H.S.; Mahdy, Y.B.; Atiea, M.A. Behavior-based features model for malware detection. J. Comput. Virol. Hacking Tech. 2016, 12, 59–67. [Google Scholar] [CrossRef]
- Zeng, N.; Wang, Z.; Zineddin, B.; Li, Y.; Du, M.; Xiao, L.; Liu, X.; Young, T. Image-based quantitative analysis of gold immunochromatographic strip via cellular neural network approach. IEEE Trans. Med. Imaging 2014, 33, 1129–1136. [Google Scholar] [CrossRef] [PubMed]
- Ucci, D.; Aniello, L.; Baldoni, R. Survey of machine learning techniques for malware analysis. Comput. Secur. 2019, 81, 123–147. [Google Scholar] [CrossRef]
- Chumachenko, K. Machine Learning Methods for Malware Detection and Classification. Bachelor’s Thesis, University of Applied Sciences, Kempten, Germany, 2017. [Google Scholar]
- Corona, I.; Maiorca, D.; Ariu, D.; Giacinto, G. Lux0r: Detection of malicious pdf-embedded javascript code through discriminant analysis of api references. In Proceedings of the 2014 Workshop on Artificial Intelligent and Security Workshop, Scottsdale, AZ, USA, 7 November 2014; pp. 47–57. [Google Scholar]
- Smutz, C.; Stavrou, A. Malicious PDF detection using metadata and structural features. In Proceedings of the 28th Annual Computer Security Applications Conference, Orlando, FL, USA, 7–11 December 2012; pp. 239–248. [Google Scholar]
- Šrndic, N.; Laskov, P. Detection of malicious pdf files based on hierarchical document structure. In Proceedings of the 20th Annual Network & Distributed System Security Symposium, San Diego, CA, USA, 24–27 February 2013; pp. 1–16. [Google Scholar]
- Ranveer, S.; Hiray, S. Comparative analysis of feature extraction methods of malware detection. Int. J. Comput. Appl. 2015, 120. [Google Scholar] [CrossRef]
- Chakkaravarthy, S.S.; Sangeetha, D.; Vaidehi, V. A Survey on malware analysis and mitigation techniques. Comput. Sci. Rev. 2019, 32, 1–23. [Google Scholar] [CrossRef]
- Alaeiyan, M.; Parsa, S.; Conti, M. Analysis and classification of context-based malware behavior. Comput. Commun. 2019, 136, 76–90. [Google Scholar] [CrossRef]
- Ki, Y.; Kim, E.; Kim, H.K. A novel approach to detect malware based on API call sequence analysis. Int. J. Distrib. Sens. Netw. 2015, 11, 659101. [Google Scholar] [CrossRef]
- Zhao, Y.; Bo, B.; Feng, Y.; Xu, C.; Yu, B. A Feature Extraction Method of Hybrid Gram for Malicious Behavior Based on Machine Learning. Secur. Commun. Netw. 2019, 2019. [Google Scholar] [CrossRef]
- Fan, M.; Liu, J.; Luo, X.; Chen, K.; Tian, Z.; Zheng, Q.; Liu, T. Android malware familial classification and representative sample selection via frequent subgraph analysis. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1890–1905. [Google Scholar] [CrossRef]
- Lin, Z.; Xiao, F.; Sun, Y.; Ma, Y.; Xing, C.C.; Huang, J. A Secure Encryption-Based Malware Detection System. TIIS 2018, 12, 1799–1818. [Google Scholar]
- Fan, C.I.; Hsiao, H.W.; Chou, C.H.; Tseng, Y.F. Malware detection systems based on API log data mining. In Proceedings of the 2015 IEEE 39th Annual Computer Software and Applications Conference, Taichung, Taiwan, 1–5 July 2015; Volume 3, pp. 255–260. [Google Scholar]
- Li, Z.; Sun, L.; Yan, Q.; Srisa-an, W.; Chen, Z. Droidclassifier: Efficient adaptive mining of application-layer header for classifying android malware. In Proceedings of the International Conference on Security and Privacy in Communication Systems, Guangzhou, China, 10–12 October 2016; Springer: Cham, Switzerland, 2016; pp. 597–616. [Google Scholar]
- Souri, A.; Hosseini, R. A state-of-the-art survey of malware detection approaches using data mining techniques. Hum.-Cent. Comput. Inf. Sci. 2018, 8, 3. [Google Scholar] [CrossRef]
- Ficco, M. Comparing API Call Sequence Algorithms for Malware Detection. In Proceedings of the Workshops of the International Conference on Advanced Information Networking and Applications, Caserta, Italy, 15–17 April 2020; Springer: Cham, Switzerland, 2020; pp. 847–856. [Google Scholar]
- Lu, H.; Zhao, B.; Su, J.; Xie, P. Generating lightweight behavioral signature for malware detection in people-centric sensing. Wirel. Pers. Commun. 2014, 75, 1591–1609. [Google Scholar] [CrossRef]
- Liu, W.; Ren, P.; Liu, K.; Duan, H.X. Behavior-based malware analysis and detection. In Proceedings of the 2011 First International Workshop on Complexity and Data Mining, Jiangsu, China, 24–28 September 2011; pp. 39–42. [Google Scholar]
- Lee, T.; Choi, B.; Shin, Y.; Kwak, J. Automatic malware mutant detection and group classification based on the n-gram and clustering coefficient. J. Supercomput. 2018, 74, 3489–3503. [Google Scholar] [CrossRef]
- Tran, T.K.; Sato, H. NLP-based approaches for malware classification from API sequences. In Proceedings of the 2017 21st Asia Pacific Symposium on Intelligent and Evolutionary Systems (IES), Hanoi, Vietnam, 15–17 November 2017; pp. 101–105. [Google Scholar]
- Amer, E. Enhancing efficiency of web search engines through ontology learning from unstructured information sources. In Proceedings of the 2015 IEEE International Conference on Information Reuse and Integration, San Francisco, CA, USA, 13–15 August 2015; pp. 542–549. [Google Scholar]
- Youssif, A.A.; Ghalwash, A.Z.; Amer, E.A. HSWS: Enhancing efficiency of web search engine via semantic web. In Proceedings of the International Conference on Management of Emergent Digital EcoSystems, San Francisco, CA, USA, 21–24 November 2011; pp. 212–219. [Google Scholar]
- Biggio, B.; Corona, I.; Maiorca, D.; Nelson, B.; Šrndić, N.; Laskov, P.; Giacinto, G.; Roli, F. Evasion attacks against machine learning at test time. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Prague, Czech Republic, 23–27 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 387–402. [Google Scholar]
- Biggio, B.; Corona, I.; Nelson, B.; Rubinstein, B.I.; Maiorca, D.; Fumera, G.; Giacinto, G.; Roli, F. Security evaluation of support vector machines in adversarial environments. In Support Vector Machines Applications; Springer: Cham, Switzerland, 2014; pp. 105–153. [Google Scholar]
- Biggio, B.; Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef]
- Brückner, M.; Kanzow, C.; Scheffer, T. Static prediction games for adversarial learning problems. J. Mach. Learn. Res. 2012, 13, 2617–2654. [Google Scholar]
- Demontis, A.; Melis, M.; Biggio, B.; Maiorca, D.; Arp, D.; Rieck, K.; Corona, I.; Giacinto, G.; Roli, F. Yes, machine learning can be more secure! A case study on android malware detection. IEEE Trans. Dependable Secur. Comput. 2017, 16, 711–724. [Google Scholar] [CrossRef]
- Grosse, K.; Papernot, N.; Manoharan, P.; Backes, M.; McDaniel, P. Adversarial examples for malware detection. In European Symposium on Research in Computer Security; Springer: Cham, Switzerland, 2017; pp. 62–79. [Google Scholar]
- Kolosnjaji, B.; Demontis, A.; Biggio, B.; Maiorca, D.; Giacinto, G.; Eckert, C.; Roli, F. Adversarial malware binaries: Evading deep learning for malware detection in executables. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 533–537. [Google Scholar]
- Wang, Q.; Guo, W.; Zhang, K.; Ororbia, A.G.; Xing, X.; Liu, X.; Giles, C.L. Adversary resistant deep neural networks with an application to malware detection. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 23–27 August 2017; pp. 1145–1153. [Google Scholar]
- Ketkar, N.; Santana, E. Deep Learning with Python; Apress: Berkeley, CA, USA, 2017; Volume 1. [Google Scholar]
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python: A Guide for Data Scientists; O’Reilly Media, Inc.: Newton, MA, USA, 2016. [Google Scholar]
- Syakur, M.A.; Khotimah, B.K.; Rochman, E.M.S.; Satoto, B.D. Integration K-means clustering method and elbow method for identification of the best customer profile cluster. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2018; Volume 336, p. 012017. [Google Scholar]
- Andrews, B.; Davis, R.A.; Breidt, F.J. Maximum likelihood estimation for all-pass time series models. J. Multivar. Anal. 2006, 97, 1638–1659. [Google Scholar] [CrossRef][Green Version]
- Intelligence and Security Informatics Data Sets, BWorld Robot Control Software. Available online: http://www.azsecure-data.org/ (accessed on 5 July 2019).
- Kim, C.W. NtMalDetect: A machine learning approach to malware detection using native API system calls. arXiv 2018, arXiv:1802.05412. [Google Scholar]
- Catak, F.O.; Yazı, A.F.; Elezaj, O.; Ahmed, J. Deep learning based Sequential model for malware analysis using Windows exe API Calls. PeerJ Comput. Sci. 2020, 6, e285. [Google Scholar] [CrossRef]
- Ahmed, F.; Hameed, H.; Shafiq, M.Z.; Farooq, M. Using spatio-temporal information in API calls with machine learning algorithms for malware detection. In Proceedings of the 2nd ACM Workshop on Security and Artificial Intelligence, Chicago, IL, USA, 9–13 November 2009; pp. 55–62. [Google Scholar]
- Rieck, K.; Trinius, P.; Willems, C.; Holz, T. Automatic analysis of malware behavior using machine learning. J. Comput. Secur. 2011, 19, 639–668. [Google Scholar] [CrossRef]
- Qiao, Y.; Yang, Y.; Ji, L.; He, J. Analyzing malware by abstracting the frequent itemsets in API call sequences. In Proceedings of the 2013 12th IEEE International Conference on Trust, Security and Privacy in Computing and Communications, Melbourne, VIC, Australia, 16–18 July 2013; pp. 265–270. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0756 | 0.4634 | 0.0363 | 0.0815 | 0.1668 | 0.1161 | 0.0232 | 0.0170 | 0.0019 | 0.0182 |
| 1 | 0.0638 | 0.6714 | 0.0538 | 0.0401 | 0.1028 | 0.0305 | 0.0209 | 0.0040 | 0.0081 | 0.0047 |
| 2 | 0.0566 | 0.5672 | 0.2203 | 0.0288 | 0.0432 | 0.0285 | 0.0468 | 0.0010 | 0.0073 | 0.0002 |
| 3 | 0.0349 | 0.5032 | 0.0007 | 0.3779 | 0.0662 | 0.0004 | 0.0164 | 0.0001 | 0.0000 | 0.0001 |
| 4 | 0.0770 | 0.3164 | 0.0118 | 0.0233 | 0.4936 | 0.0379 | 0.0180 | 0.0101 | 0.0108 | 0.0009 |
| 5 | 0.1846 | 0.2373 | 0.0058 | 0.0002 | 0.1060 | 0.4087 | 0.0498 | 0.0021 | 0.0001 | 0.0054 |
| 6 | 0.2632 | 0.0908 | 0.0007 | 0.0003 | 0.0138 | 0.2772 | 0.3121 | 0.0410 | 0.0000 | 0.0009 |
| 7 | 0.0026 | 0.7060 | 0.0035 | 0.0039 | 0.1022 | 0.0000 | 0.0001 | 0.0000 | 0.1816 | 0.0001 |
| 8 | 0.0383 | 0.8785 | 0.0054 | 0.0185 | 0.0534 | 0.0039 | 0.0000 | 0.0001 | 0.0000 | 0.0020 |
| 9 | 0.1271 | 0.1506 | 0.0027 | 0.0005 | 0.2247 | 0.0028 | 0.0001 | 0.0007 | 0.0007 | 0.4900 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.6651 | 0.0025 | 0.0905 | 0.0047 | 0.0475 | 0.1657 | 0.0046 | 0.0035 | 0.0151 | 0.0008 |
| 1 | 0.0279 | 0.2257 | 0.0181 | 0.0000 | 0.0005 | 0.7268 | 0.0001 | 0.0004 | 0.0005 | 0.0000 |
| 2 | 0.2423 | 0.0006 | 0.3210 | 0.0054 | 0.0506 | 0.3484 | 0.0198 | 0.0004 | 0.0048 | 0.0068 |
| 3 | 0.2934 | 0.0025 | 0.1053 | 0.3580 | 0.0000 | 0.1190 | 0.0278 | 0.0000 | 0.0000 | 0.0941 |
| 4 | 0.3423 | 0.0009 | 0.1476 | 0.0000 | 0.4013 | 0.1073 | 0.0003 | 0.0000 | 0.0004 | 0.0000 |
| 5 | 0.0453 | 0.0439 | 0.0419 | 0.0011 | 0.0043 | 0.8591 | 0.0024 | 0.0000 | 0.0004 | 0.0015 |
| 6 | 0.1632 | 0.0039 | 0.2360 | 0.0943 | 0.0011 | 0.1840 | 0.2444 | 0.0021 | 0.0011 | 0.0697 |
| 7 | 0.3512 | 0.0000 | 0.0057 | 0.0312 | 0.0000 | 0.0099 | 0.0000 | 0.3494 | 0.2503 | 0.0025 |
| 8 | 0.3634 | 0.0060 | 0.0068 | 0.0491 | 0.0005 | 0.0215 | 0.0000 | 0.1691 | 0.3836 | 0.0002 |
| 9 | 0.0759 | 0.0000 | 0.1458 | 0.0363 | 0.0000 | 0.1587 | 0.5273 | 0.0004 | 0.0000 | 0.0557 |
| Sequence Transition | p(1,1) | p(1,1) | p(1,1) | p(1,4) | p(4,4) | p(4,1) | p(1,6) | p(6,4) | p(4,7) | p(7,8) | p(8,1) | p(1,1) | p(1,1) | p(1,1) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| p(sequence, Malware) | 0.6714 | 0.6714 | 0.6714 | 0.1028 | 0.4936 | 0.3164 | 0.0209 | 0.0138 | 0.0101 | 0.1816 | 0.8785 | 0.6714 | 0.6714 | 0.6714 |
| p(sequence, Goodware) | 0.2257 | 0.2257 | 0.2257 | 0.0005 | 0.4013 | 0.0009 | 0.0001 | 0.0011 | 0.0000 | 0.2503 | 0.0060 | 0.2257 | 0.2257 | 0.2257 |
| Formulation | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| Input Sequence | 1 1 1 1 1 1 1 1 1 0 1 1 1 1 | Likelihood Accumulation | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sequence Transitions | p(1,1) | p(1,1) | p(1,1) | p(1,1) | p(1,1) | p(1,1) | p(1,1) | p(1,1) | p(1,1) | p(1,0) | p(0,1) | p(1,1) | p(1,1) | p(1,1) | |
| Likelihood (Malware|Sequence) | 0.948 | 0.948 | 0.948 | 0.948 | 0.948 | 0.948 | 0.948 | 0.948 | 0.948 | 0.052 | 0.824 | 0.948 | 0.948 | 0.948 | 12.252 |
| Likelihood (Goodware|Sequence) | 0.322 | 0.322 | 0.322 | 0.322 | 0.322 | 0.322 | 0.322 | 0.322 | 0.322 | 0.678 | 0.066 | 0.322 | 0.322 | 0.322 | 4.608 |
| Datasets | Accuracy Measures | |||||
|---|---|---|---|---|---|---|
| Precision | Recall | F-Measure | Accuracy | FPR | FNR | |
| Ki et al., 2015 [17] | 0.999 | 0.998 | 0.999 | 0.999 | 0.001 | 0.001 |
| Kim et al., 2018 [44] | 0.994 | 0.986 | 0.990 | 0.990 | 0.006 | 0.014 |
| CSDMC [43] | 0.987 | 0.982 | 0.985 | 0.985 | 0.012 | 0.018 |
| Catak et al., 2020 [45] | 0.980 | 0.994 | 0.987 | 0.987 | 0.020 | 0.007 |
| Average | 0.990 | 0.990 | 0.990 | 0.990 | 0.010 | 0.010 |
| Datasets | Accuracy Measures | |||||
|---|---|---|---|---|---|---|
| Precision | Recall | F-Measure | Accuracy | FPR | FNR | |
| Testing Dataset | 0.965 | 1.000 | 0.983 | 0.983 | 0.034 | 0.000 |
| Study | # of Malware | F-Measure | Accuracy | Used Feature |
|---|---|---|---|---|
| Ahmed et al., 2009 [46] | 416 | - | 0.980 | API call sequence |
| Rieck et al., 2011 [47] | 3133 | 0.950 | - | API call sequence |
| Qiao et al., 2014 [6] | 3131 | 0.909 | - | API call sequence |
| Qiao et al., 2013 [48] | 3131 | 0.947 | - | API call sequence |
| Ki et al., 2015 [17] | 23,080 | 0.999 | 0.998 | API call sequence |
| Catak et al., 2020 [45] | 7101 | - | 0.950 | API call sequence |
| Proposed Work | 23,080 | 0.999 | 0.999 | API call sequence |
| 151 | 0.990 | 0.990 | API call sequence | |
| 320 | 0.985 | 0.985 | API call sequence | |
| 7107 | 0.987 | 0.987 | API call sequences |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amer, E.; El-Sappagh, S.; Hu, J.W. Contextual Identification of Windows Malware through Semantic Interpretation of API Call Sequence. Appl. Sci. 2020, 10, 7673. https://doi.org/10.3390/app10217673
Amer E, El-Sappagh S, Hu JW. Contextual Identification of Windows Malware through Semantic Interpretation of API Call Sequence. Applied Sciences. 2020; 10(21):7673. https://doi.org/10.3390/app10217673
Chicago/Turabian StyleAmer, Eslam, Shaker El-Sappagh, and Jong Wan Hu. 2020. "Contextual Identification of Windows Malware through Semantic Interpretation of API Call Sequence" Applied Sciences 10, no. 21: 7673. https://doi.org/10.3390/app10217673
APA StyleAmer, E., El-Sappagh, S., & Hu, J. W. (2020). Contextual Identification of Windows Malware through Semantic Interpretation of API Call Sequence. Applied Sciences, 10(21), 7673. https://doi.org/10.3390/app10217673