Deep Learning-Based Portable Device for Audio Distress Signal Recognition in Urban Areas

 ,
,  , ,
, , 
 and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Prototype Design
2.2. Database Collection
- Set up the base to its maximum height and point it to an angle of 45 with respect to the base.
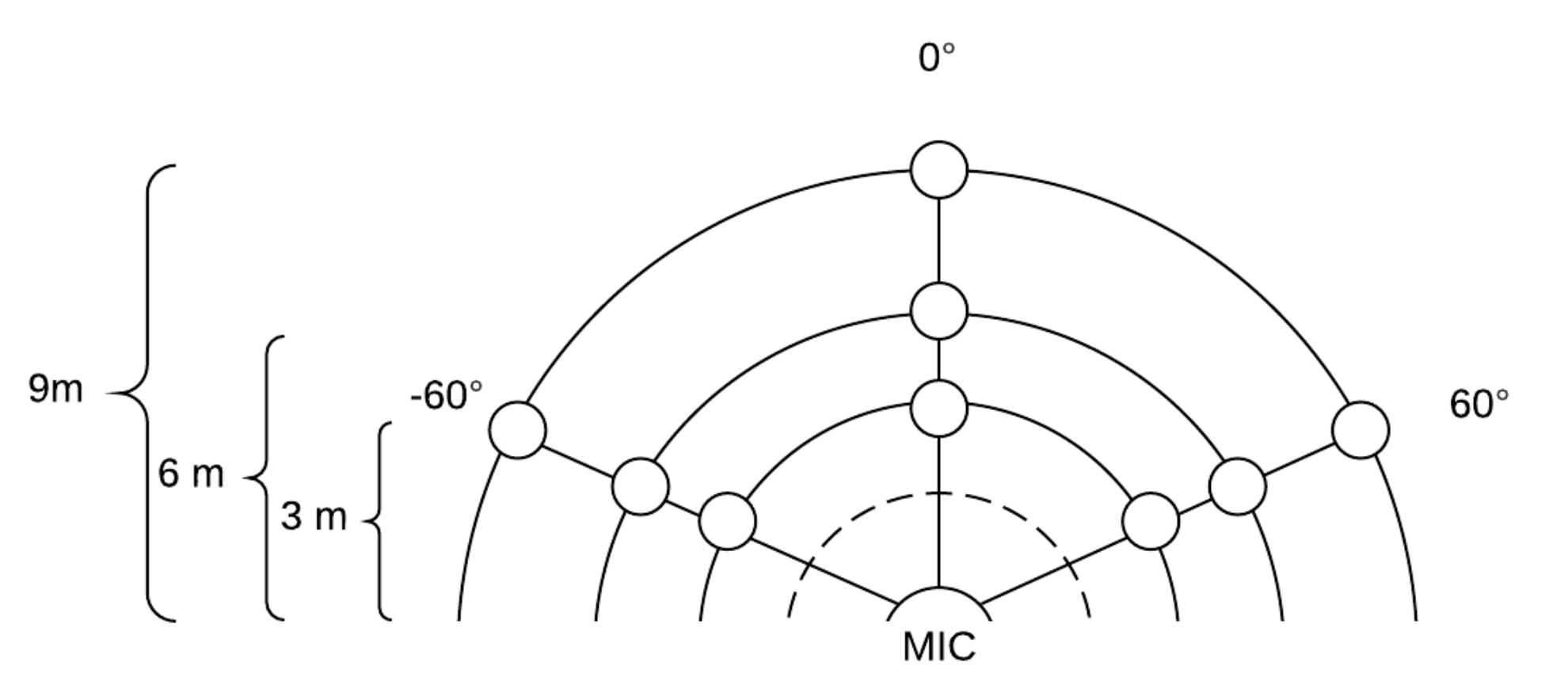
- Set the data acquisition points with masking tape in the ground, starting from −60 and marking a point for 3 m, 6 m and 9 m with respect to the base location, and repeat the process for angles 0 and 60 for a total of 9 points as is shown in Figure 2.
- Start to record the audios with the data acquisition program.
- Position the subject in the initial starting point, that is, (−60, 3 m), and ask them to scream the predefined expressions SN, HN and AN.
- Repeat the process for the following points.
- Stop recording the data.
- Snowball iCE Condenser microphone, Pressure Gradient With USB digital output. This has a cardioid profile with an even frequency response for human voice range to reduce the misdetection of distress signals.
- 3.5 m long Type-A to Type-B USB cable.
- 3 m long microphone base.
2.3. Feature Extraction
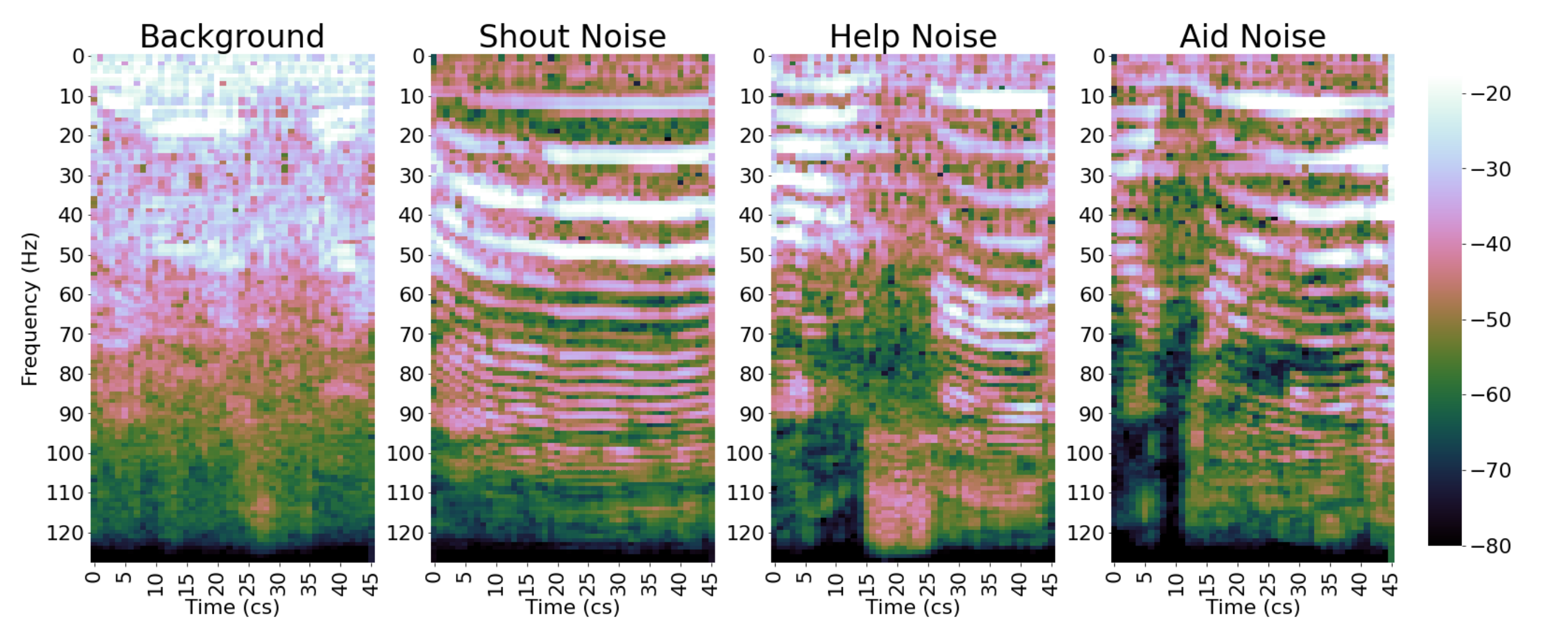
2.3.1. Mel Spectrogram
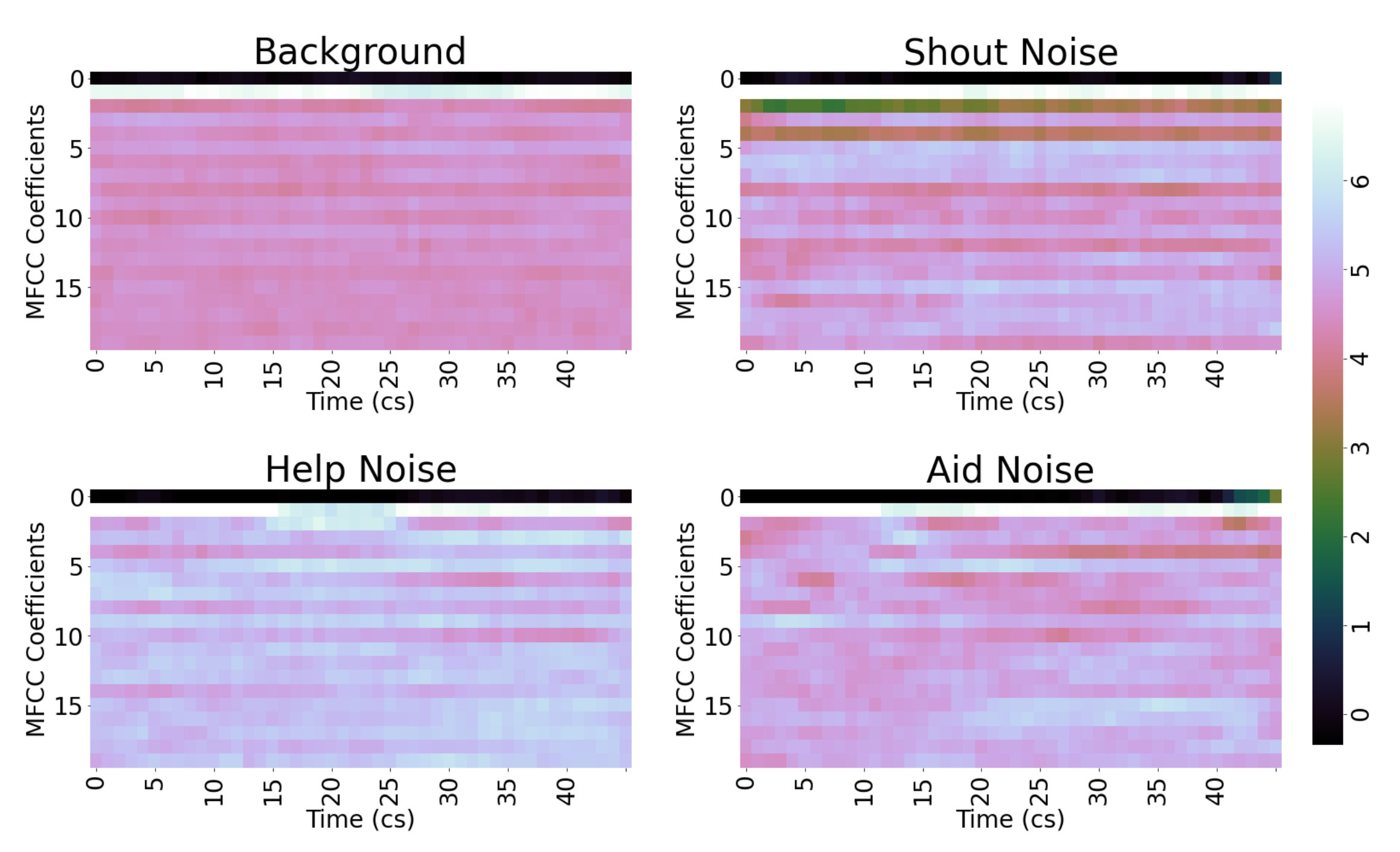
2.3.2. Mel Frequency Cepstral Coefficients
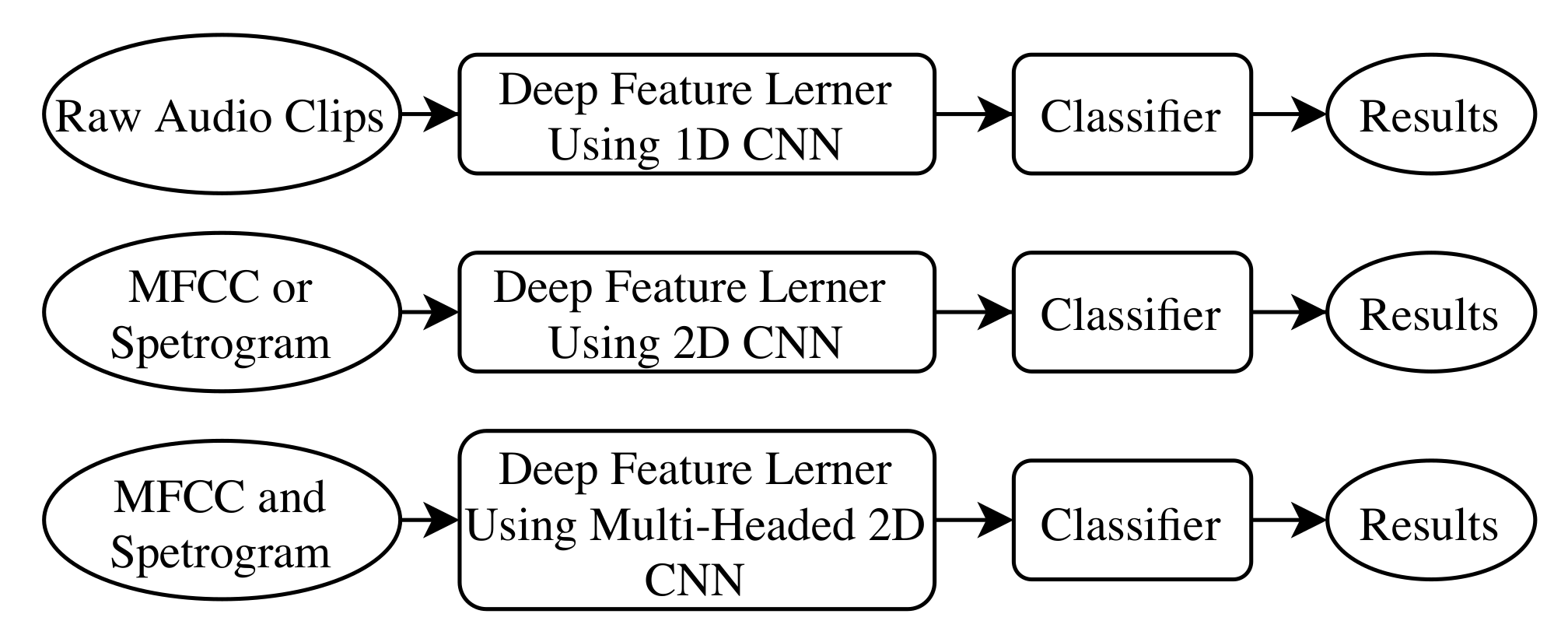
2.4. Convolutional Neural Network (CNN) Architectures
2.4.1. 1D CNN
2.4.2. 2D CNN
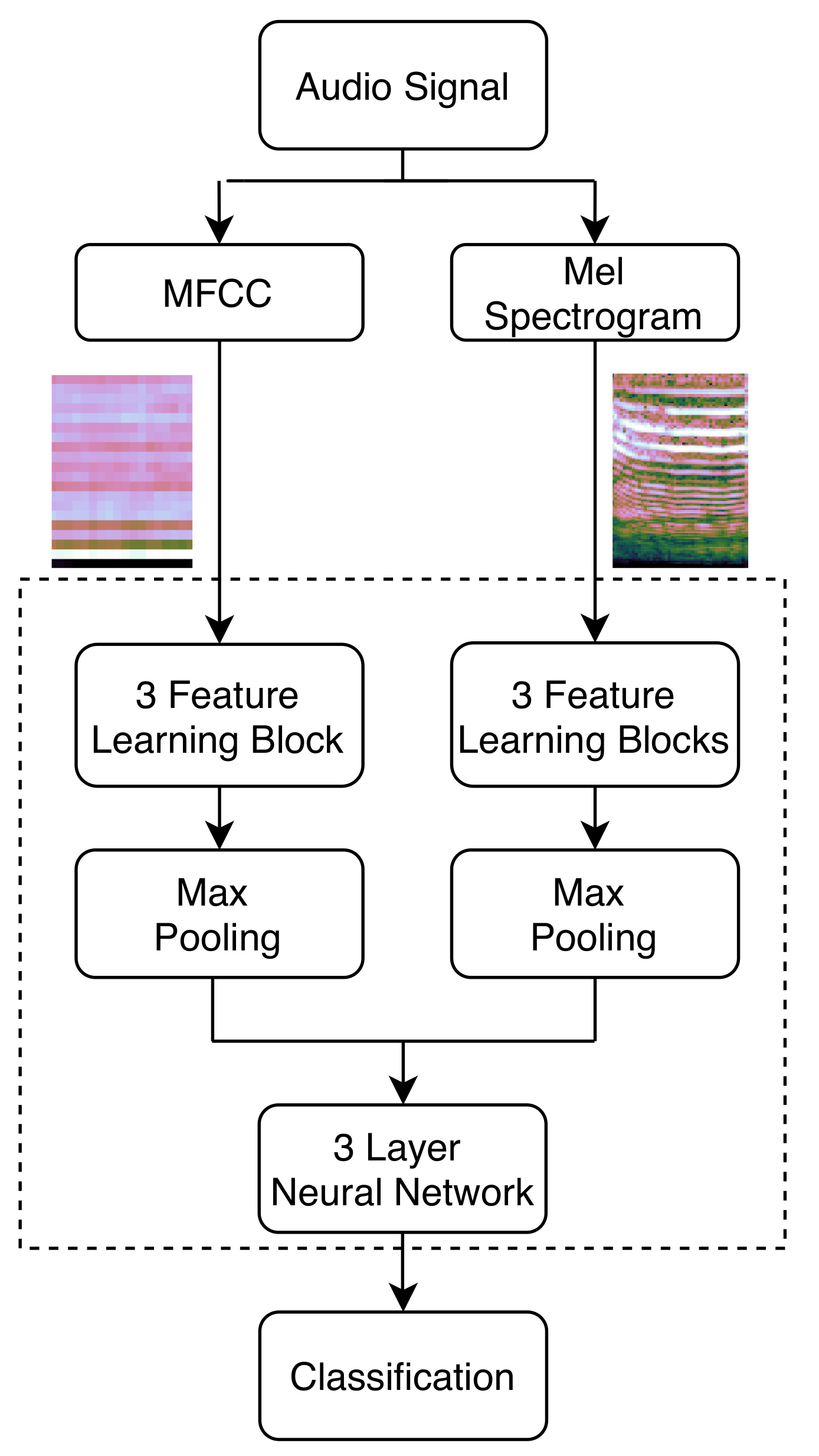
2.4.3. Multi-Headed CNN
3. Results
3.1. Performance 1D CNN
3.2. Performance 2D CNN
3.3. Performance Multi-Headed 2D CNN
3.4. Prototype Implementation
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| BN | Background Noise label |
| SN | Shout Noise label |
| HN | Help Noise label |
| AN | Aid Noise label |
| GB | Glass Breaking label |
| GS | Gunshot label |
| S | Scream label |
| MFCC | Mel Frequency Cepstral Coefficients |
| CNN | Convolutional Neural Network |
| SVM | Support Vector Machine |
References
- Vidal, J.B.I.; Kirchmaier, T. The Effect of Police Response Time on Crime Detection; Cep Discussion Papers; Centre for Economic Performance, LSE: London, UK, 2015. [Google Scholar]
- Mabrouk, A.B.; Zagrouba, E. Abnormal behavior recognition for intelligent video surveillance systems: A review. Expert Syst. Appl. 2018, 91, 480–491. [Google Scholar] [CrossRef]
- Eng, H.L.; Toh, K.A.; Yau, W.Y.; Wang, J. DEWS: A live visual surveillance system for early drowning detection at pool. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 196–210. [Google Scholar]
- Mubashir, M.; Shao, L.; Seed, L. A survey on fall detection: Principles and approaches. Neurocomputing 2013, 100, 144–152. [Google Scholar] [CrossRef]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005; pp. 1517–1520. [Google Scholar]
- Huang, W.; Chiew, T.K.; Li, H.; Kok, T.S.; Biswas, J. Scream detection for home applications. In Proceedings of the 2010 5th IEEE Conference on Industrial Electronics and Applications, Taichung, Taiwan, 15–17 June 2010; pp. 2115–2120. [Google Scholar]
- Parsons, C.E.; Young, K.S.; Craske, M.G.; Stein, A.L.; Kringelbach, M.L. Introducing the Oxford Vocal (OxVoc) Sounds database: A validated set of non-acted affective sounds from human infants, adults, and domestic animals. Front. Psychol. 2014, 5, 562. [Google Scholar] [CrossRef] [PubMed]
- Foggia, P.; Petkov, N.; Saggese, A.; Strisciuglio, N.; Vento, M. Reliable detection of audio events in highly noisy environments. Pattern Recognit. Lett. 2015, 65, 22–28. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Howard, N.; Huang, G.B.; Hussain, A. Fusing audio, visual and textual clues for sentiment analysis from multimodal content. Neurocomputing 2016, 174, 50–59. [Google Scholar] [CrossRef]
- Strisciuglio, N.; Vento, M.; Petkov, N. Learning representations of sound using trainable COPE feature extractors. Pattern Recognit. 2019, 92, 25–36. [Google Scholar] [CrossRef]
- Dhanalakshmi, P.; Palanivel, S.; Ramalingam, V. Pattern classification models for classifying and indexing audio signals. Eng. Appl. Artif. Intell. 2011, 24, 350–357. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2019, 47, 424. [Google Scholar]
- Alarcón-Paredes, A.; Francisco-García, V.; Guzmán-Guzmán, I.P.; Cantillo-Negrete, J.; Cuevas-Valencia, R.E.; Alonso-Silverio, G.A. An IoT-Based Non-Invasive Glucose Level Monitoring System Using Raspberry Pi. Appl. Sci. 2019, 9, 3046. [Google Scholar] [CrossRef]
- Ou, S.; Park, H.; Lee, J. Implementation of an obstacle recognition system for the blind. Appl. Sci. 2020, 10, 282. [Google Scholar] [CrossRef]
- Blue Microphones Snowball USB Microphone User Guide. 2009. Available online: https://s3.amazonaws.com/cd.bluemic.com/pdf/snowball/manual.pdf (accessed on 1 June 2020).
- Chou, W.; Juang, B.H. Pattern Recognition in Speech and Language Processing; CRC Press: Boca Raton, FL, USA, 2003. [Google Scholar]
- Piczak, K.J. The details that matter: Frequency resolution of spectrograms in acoustic scene classification. In Detection and Classification of Acoustic Scenes and Events; Warsaw University of Technology: Munich, Germany, 2017; pp. 103–107. [Google Scholar]
- Kadiri, S.R.; Alku, P. Mel-Frequency Cepstral Coefficients of Voice Source Waveforms for Classification of Phonation Types in Speech. In Interspeech; Department of Signal Processing and Acoustics, Aalto University: Espoo, Finland, 2019; pp. 2508–2512. [Google Scholar]
- Umesh, S.; Cohen, L.; Nelson, D. Frequency warping and the Mel scale. IEEE Signal Process. Lett. 2002, 9, 104–107. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep Learning; MIT Press: Cambridge, UK, 2015. [Google Scholar] [CrossRef]
- Velasco-Montero, D.; Fernández-Berni, J.; Carmona-Galán, R.; Rodríguez-Vázquez, Á. Performance analysis of real-time DNN inference on Raspberry Pi. In Proceedings of the Real-Time Image and Video Processing 2018. International Society for Optics and Photonics, Taichung, Taiwan, 9–12 December 2018; Volume 10670, p. 106700F. [Google Scholar]
- Arslan, Y. A New Approach to Real Time Impulsive Sound Detection for Surveillance Applications. arXiv 2019, arXiv:1906.06586. [Google Scholar]
- López, J.M.; Alonso, J.; Asensio, C.; Pavón, I.; Gascó, L.; de Arcas, G. A Digital Signal Processor Based Acoustic Sensor for Outdoor Noise Monitoring in Smart Cities. Sensors 2020, 20, 605. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Number of Samples | Percentage |
|---|---|---|
| BN | 20,645 | 82.04% |
| SN | 1228 | 4.88% |
| AN | 1771 | 7.04% |
| HN | 1521 | 6.04% |
| Training Set | Test Set | |||
|---|---|---|---|---|
| # Events | Duration (s) | # Events | Duration (s) | |
| BN | - | 58,371.6 | - | 25,036.8 |
| GB | 4200 | 6024.8 | 1800 | 2561.7 |
| GB | 4200 | 1883.6 | 1800 | 743.5 |
| S | 4200 | 5488.8 | 1800 | 2445.4 |
| Predicted Class | |||||
|---|---|---|---|---|---|
| GB | GS | S | BN | ||
| True Class | GB | 94.4% | 0.2% | 0.2% | 5.2% |
| GS | 3.5% | 84.9% | 0.5% | 11.1% | |
| S | 2.6% | 0.9% | 80.8% | 15.7% | |
| BN | - | - | - | 97.4% | |
| Predicted Class | |||||
|---|---|---|---|---|---|
| GB | GS | S | BN | ||
| True Class | GB | 92.8% | 0.0% | 0.0% | 7.2% |
| GS | 0.33% | 85.67% | 0.0% | 14.0% | |
| S | 0.0% | 0.0% | 86.0% | 14.0% | |
| BN | 0.33% | 0.1% | 0.48% | 99.09% | |
| Predicted Class | |||||
|---|---|---|---|---|---|
| BN | SN | HN | AN | ||
| True Class | BN | 94% | 1.4% | 1.6% | 2.6% |
| SN | 9.8% | 63% | 5.5% | 21% | |
| HN | 12% | 5.9% | 63% | 19% | |
| AN | 13% | 16% | 18% | 53% | |
| Predicted Class | |||||
|---|---|---|---|---|---|
| BN | SN | HN | AN | ||
| True Class | BN | 94% | 1.5% | 2.5% | 1.6% |
| SN | 8.8% | 66% | 12% | 12% | |
| HN | 7.3% | 3.5% | 81% | 8.1% | |
| AN | 10% | 14% | 15% | 61% | |
| Predicted Class | |||||
|---|---|---|---|---|---|
| BN | SN | HN | AN | ||
| True Class | BN | 96% | 0.92% | 1.2% | 1.4% |
| SN | 10% | 73% | 4.5% | 12% | |
| HN | 8.6% | 4% | 76% | 11% | |
| AN | 7.6% | 10% | 5.6% | 77% | |
| Predicted Class | |||||
|---|---|---|---|---|---|
| BN | SN | HN | AN | ||
| True Class | BN | 96% | 1.3% | 1.4% | 1.1% |
| SN | 7.7% | 79% | 3.1% | 10% | |
| HN | 5% | 3.1% | 84% | 6.7% | |
| AN | 5.5% | 9.7% | 8.3% | 76% | |
| Audio recollection time | 450 ms |
| Pre-processing time | 43 ms |
| Prediction time | 63 ms |
| Memory | 635 MB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gaviria, J.F.; Escalante-Perez, A.; Castiblanco, J.C.; Vergara, N.; Parra-Garces, V.; Serrano, J.D.; Zambrano, A.F.; Giraldo, L.F. Deep Learning-Based Portable Device for Audio Distress Signal Recognition in Urban Areas. Appl. Sci. 2020, 10, 7448. https://doi.org/10.3390/app10217448
Gaviria JF, Escalante-Perez A, Castiblanco JC, Vergara N, Parra-Garces V, Serrano JD, Zambrano AF, Giraldo LF. Deep Learning-Based Portable Device for Audio Distress Signal Recognition in Urban Areas. Applied Sciences. 2020; 10(21):7448. https://doi.org/10.3390/app10217448
Chicago/Turabian StyleGaviria, Jorge Felipe, Alejandra Escalante-Perez, Juan Camilo Castiblanco, Nicolas Vergara, Valentina Parra-Garces, Juan David Serrano, Andres Felipe Zambrano, and Luis Felipe Giraldo. 2020. "Deep Learning-Based Portable Device for Audio Distress Signal Recognition in Urban Areas" Applied Sciences 10, no. 21: 7448. https://doi.org/10.3390/app10217448
APA StyleGaviria, J. F., Escalante-Perez, A., Castiblanco, J. C., Vergara, N., Parra-Garces, V., Serrano, J. D., Zambrano, A. F., & Giraldo, L. F. (2020). Deep Learning-Based Portable Device for Audio Distress Signal Recognition in Urban Areas. Applied Sciences, 10(21), 7448. https://doi.org/10.3390/app10217448