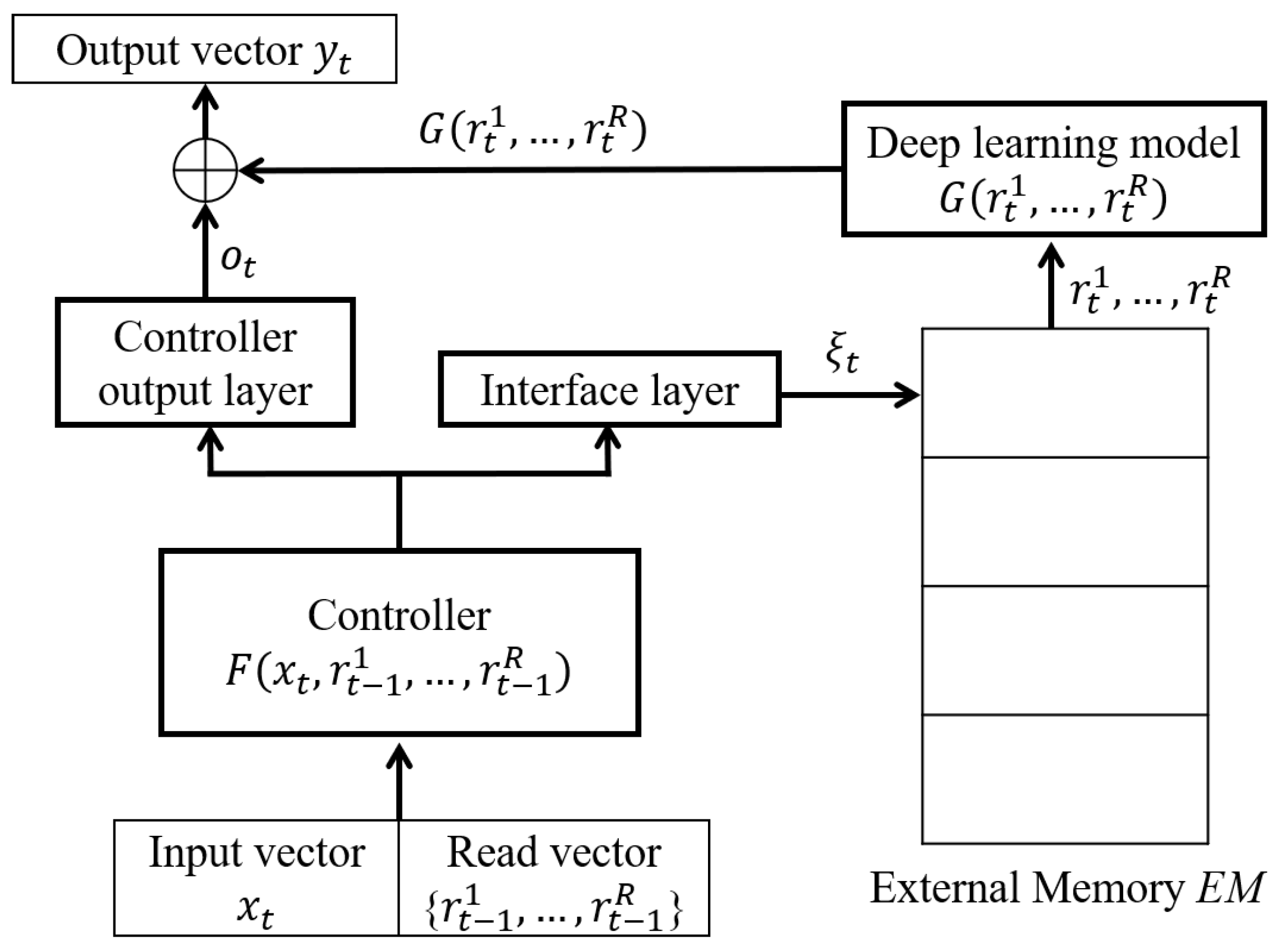
5.1. Experimental Environment
The PTB dataset is composed of sentences collected from the Wall Street Journal news domain. The character-level PTB dataset was used in the experiments. However, the character-level PTB dataset does not contain spaces between characters; therefore, it is difficult to recognize a specific word from the character sequence. Hence, space markers (-space-) and a marker for the beginning of a sentence (-bos-) were added to the character-level PTB dataset. Therefore, the total number of characters used for the experiments was 50. The character-level PTB dataset used for the experiments contained 4.88, 0.38, and 0.43 M characters, as the training, validation, and test sets, respectively. The PTB LM task experiment was repeated five times because we verify the stability of hyper-parameters in different LMs and test their generalization.
The enwik8 dataset contains 100 M characters of unprocessed Wikipedia text. The total number of characters was 206. Following previous studies, we split the enwik8 dataset into 90, 5, and 5 M characters for the training, validation, and test sets, respectively. The enwik8 LM task experiment was repeated three times.
We used a 3.40GHz Intel Xeon E5-2643 v4 CPU and four Nvidia GTX 1080 Ti GPUs. We used two evaluation metrics: BPC and training time. BPC is the average number of bits required to encode one character [
31]. A bit is used as a unit of entropy. We defined BPC as
. To evaluate the inference time of each model, we measured the inference time per batch.
5.2. Experimental Results in Character-Level Penn Treebank LM Task
The LSTM RNN is the baseline LM in the experiments. We trained the baseline LM on PyTorch with the following hyper-parameters: the number of nodes in the embedding layer was 50, the number of hidden layers was 3, the dimension of each hidden layer was 1024, the learning rate was initialized at
, the number of epochs was 300, the number of batches was 6, the weight decay was
, and the length of the back-propagation through time (BPTT) was 120. For training the Transformer-based LM, we used the following hyper-parameters (We used the following open source to train the LSTM RNN and Transformer-based LM:
https://github.com/pytorch/examples/blob/master/word_language_model): the number of nodes in the embedding layer was 50, the number of heads in the encoder and decoder was 4, the number of hidden layers was 3, the dimension of each hidden layer was 1024, the learning rate was initialized at
, the number of epochs was 300, the number of batches was 6, the weight decay was
, and the length of the input chunks was 120.
Moreover, we compared the MDM-NTM-based LM with the trellis (
https://github.com/locuslab/trellisnet) and AWD-LSTM networks (
https://github.com/salesforce/awd-lstm-lm). The hyper-parameters of the trellis and AWD-LSTM networks were the same as those used in previous studies. However, the number of batches was 6 and the BPTT length was 120 for the experiments. In addition, we only applied a dropout factor to the hidden layers, and not the embedding, input, or output layers.
To train the MDM-NTM-based LM, we used the LSTM RNN as the controller. The following hyper-parameters were used for the experiments: the number of nodes in the embedding layer was 50, the number of hidden layers was 3, and the numbers of dimensions of each hidden layer were 1024, 512, and 512. We used the external memory consisting of 1024 vectors. The dimensions of each vector were 512. The learning rate was initialized at and reduced on the plateau of an objective function with a factor of . The number of epochs was 300, the size of the batch was 6, the weight decay was , and the character sequence length was 120.
Table 1 shows the evaluation results of MDM-NTM-based LMs on the PTB LM task. All MDM-NTM-based LMs had a faster inference time than the trellis network. We measured the performance of the MDM-NTM architecture according to the number of read vectors. The number of read vectors was doubled to evaluate their effect. The MDM-NTM-based LM using a single read vector demonstrated a higher performance with a BPC of 1.5986 than the MDM-NTM-based LMs using two and four read vectors. Each BPC sample of experiment results on the PTB LM task is shown in
Table A1.
The analysis for the performance of the MDM-NTM-based LM according to the number of read vectors led to three important findings: (1) the number of weight parameters increased with the number of read vectors. To generate the read vectors, the controller outputs the key vectors. The number of key vectors was the same as the number of read vectors. The key vectors were M-dimensional vectors, where M is a dimension of the vector in the external memory. Furthermore, the number of read vectors affected the dimension of the input layer in the controller, because the read vectors generated at time were used as the input to the controller. (2) BPC decreased depending on the number of read vectors. When the MDM-NTM-based LM used one to four read vectors, the performance decreased. This implies that the PTB LM task was insufficient for training all weight parameters of the MDM-NTM-based LM using two or more read vectors. (3) The inference time was disproportional to the number of read vectors. We assumed that a larger number of read vectors required a longer inference time. However, the MDM-NTM-based LM using two read vectors showed a faster inference time than that using one read vector.
We evaluated the performance of the MDM-NTM architecture according to the weight decay. The weight decay reduced the model overfitting by imposing increasingly large penalties as the weight parameters increased [
36]. To implement the weight decay, a set of assumed weight parameters such as
W,
was added to the loss function and a penalty is imposed. Here, as
increases, an increasingly large penalty was imposed on
W. We used two
values,
and
, during the experiments.
Table 1 presents the evaluation results of the MDM-NTM architecture according to weight decay. When we used
for the weight decay, the MDM-NTM-based LM using one and two read vectors demonstrated a BPC of 1.6998 and 1.7341, respectively. The performance of the MDM-NTM-based LM using
for the weight decay was lower than that using
.
Two important findings were observed after analyzing the performance of the MDM-NTM-based LM according to the weight decay: (1) BPC decreased according to the weight decay. When the value of of the weight decay used in the MDM-NTM-based LM along with a single read vector ranged from to , the performance degraded, that is, BPC increased from 1.5986 to 1.6998. When of the weight decay was extremely high, the model was trained to underfit. When of the weight decay was extremely low, the model was trained to overfit. Therefore, the MDM-NTM-based LM using for the weight decay showed an underfitting in the experiments. (2) The inference time was disproportional to of the weight decay. We assumed that the training time was the same, even when the MDM-NTM-based LM was trained with any value assigned to of the weight decay, because the number of weight parameters did not change. However, the experimental results demonstrated that the inference times of each model are different.
We measured the performance of the MDM-NTM architecture according to the number of vectors in the external memory;
Table 1 presents the evaluation results. When we used 1024 as the number of vectors in the external memory, the MDM-NTM-based LM demonstrated the highest performance, with a BPC of 1.5986. The inference time decreased when the number of vectors in the external memory decreased.
Three important findings were observed regarding the performance of the MDM-NTM-based LM according to the number of vectors in the external memory: (1) the number of weight parameters is the same, although the number of vectors in the external memory decreased. All MDM-NTM-based LMs used the same controller and all the vectors in the external memory had the same dimensions. The number of weight parameters is related to the controller and the dimension of the vector in the external memory. Therefore, the number of weight parameters is not related to the number of vectors in the external memory. (2) BPC is not proportional to the number of vectors in the external memory. We assumed that the MDM-NTM-based LM demonstrated the highest performance when the number of vectors in the external memory was 120, because the length of the character sequence was limited and the LM could predict the next character without additional vectors in the external memory. However, the MDM-NTM-based LM using the external memory consisting of 129 vectors exhibited a BPC result which was the same as that of the MDM-NTM-based LM using the external memory consisting of 1024 vectors. (3) The inference time is proportional to the number of vectors in the external memory. The time complexity of content-based addressing is because of the denominator of the softmax normalization. Therefore, the time spent in the calculation required for softmax normalization influenced the inference time.
We applied the proposed LCA mechanism to the pre-trained MDM-NTM architecture during the evaluation stage. The pre-trained MDM-NTM architecture showed that the highest performance in
Table 1 was used. In
Table 2, when the selected memory address was 257, the performance of the LCA-NTM-based LM was 1.5648 BPC. The performance was higher than that of the MDM-NTM-based LM.
Two important findings were observed regarding the performance of the LCA-NTM-based LM: (1) the BPC of the proposed architecture was lower than that of the MDM-NTM-based LM, except when the selected memory address was 257. We analyzed errors with cosine similarities and discovered that negative values or values close to zero existed, although positive values were also obtained in the cosine similarities of the selected memory address. In the LCA, these cosine similarities were used to generate an attention vector. The proposed NTM architecture yields worse results than the MDM-NTM-based LM. Furthermore, although many of the cosine similarity values were approximately unity, the maximum cosine similarity was always selected in the LCA. If two maximum cosine similarities exist, LCA selects only the first cosine similarity that has the maximum value. These drawbacks led to the performance degradation of the proposed LCA-NTM architecture. (2) The inference time of the proposed NTM architecture in the test stage was twice that of the MDM-NTM-based LM in the test stage. To obtain the maximum cosine similarity, we used the search algorithm for the LCA. The time complexity of the previous content-based addressing was because the denominator of softmax normalization had to be computed. However, the time complexity of the LCA was .
5.3. Experimental Results in enwik8 LM Task
We compared the results achieved through the proposed LCA-NTM architecture with those of the Transformer [
10]. For the baseline LM, we also used the previous experimental result of the LSTM RNN-based LM [
37]. For training the MDM-NTM-based LM, we used the LSTM RNN as the controller. The number of dimensions of the hidden layers was 1024, and the number of hidden layers was 4. We used an external memory consisting of 128 vectors. The number of dimensions of each vector was 256. In addition, the batch size was 20. We could not train or evaluate the large-scale MDM-NTM-based LM because the Nvidia GTX 1080 Ti GPU has a 11-GB memory capacity, and the batch size would have been considerably small if we trained a large-scale MDM-NTM-based LM.
We evaluated the performance of the MDM-NTM architecture according to the number of read vectors.
Table 3 shows the evaluation results. When we used four read vectors, the MDM-NTM-based LM demonstrated the highest BPC performance of 1.3922. The inference time increased when the number of read vectors was increased. Each BPC sample of experiment results on the PTB LM Task is shown in
Table A2.
The analysis of the performance of the MDM-NTM-based LM according to the number of read vectors led to two important findings: (1) BPC decreased depending on the number of read vectors. When the MDM-NTM-based LM used from one to four read vectors, the performance improved. (2) The inference time was proportional to the number of read vectors. We assumed that a larger number of read vectors required a longer inference time. The MDM-NTM-based LM using one read vector showed a faster inference time than that using two or more read vectors.
Furthermore, we applied the proposed LCA mechanism to the pre-trained MDM-NTM architecture during the test stage. The pre-trained MDM-NTM architecture showed that the highest performance in
Table 3 was used. In
Table 4, when the selected memory address was 97, the performance of the LCA-NTM-based LM showed a BPC of 1.3887. The performance was higher than that of the MDM-NTM-based LM. An important finding was observed regarding the performance of the LCA-NTM-based LM. The BPC of the proposed architecture was lower than that of the MDM-NTM-based LM, except when the selected memory address was 97. The performance improvement was not insignificant compared to that observed through the experimental results on the PTB LM task. We analyzed the errors with cosine similarities and discovered that more negative values existed than those in the experimental results on the PTB LM task. Therefore, the proposed NTM architecture applied vanilla content-based addressing, not LCA. These drawbacks led to the performance degradation of the proposed LCA-NTM architecture.




{kind=link}
{kind=link}