A Novel Hybrid Model for Cantonese Rumor Detection on Twitter


Abstract
:1. Introduction
- To cope with the complexity of Cantonese semantics and extract the deep features of Cantonese, we take both semantic and sentiment features into account for rumor detection. An XLNet model is used to produce text-based and sentiment-based embeddings. We perform joint learning of character and word embeddings to better fit in with the structre of Cantonese.
- A novel hybrid model XGA is proposed to improve the performance of Cantonese rumor detection, which takes advantage of XLNet, BiGRU and the attention mechanism. The Cantonese rumor dataset we constructed before is used to train our proposed model. The evaluation results show that XGA significantly outperforms other widely used rumor detection approaches in the Cantonese rumor detection.
2. Related Work
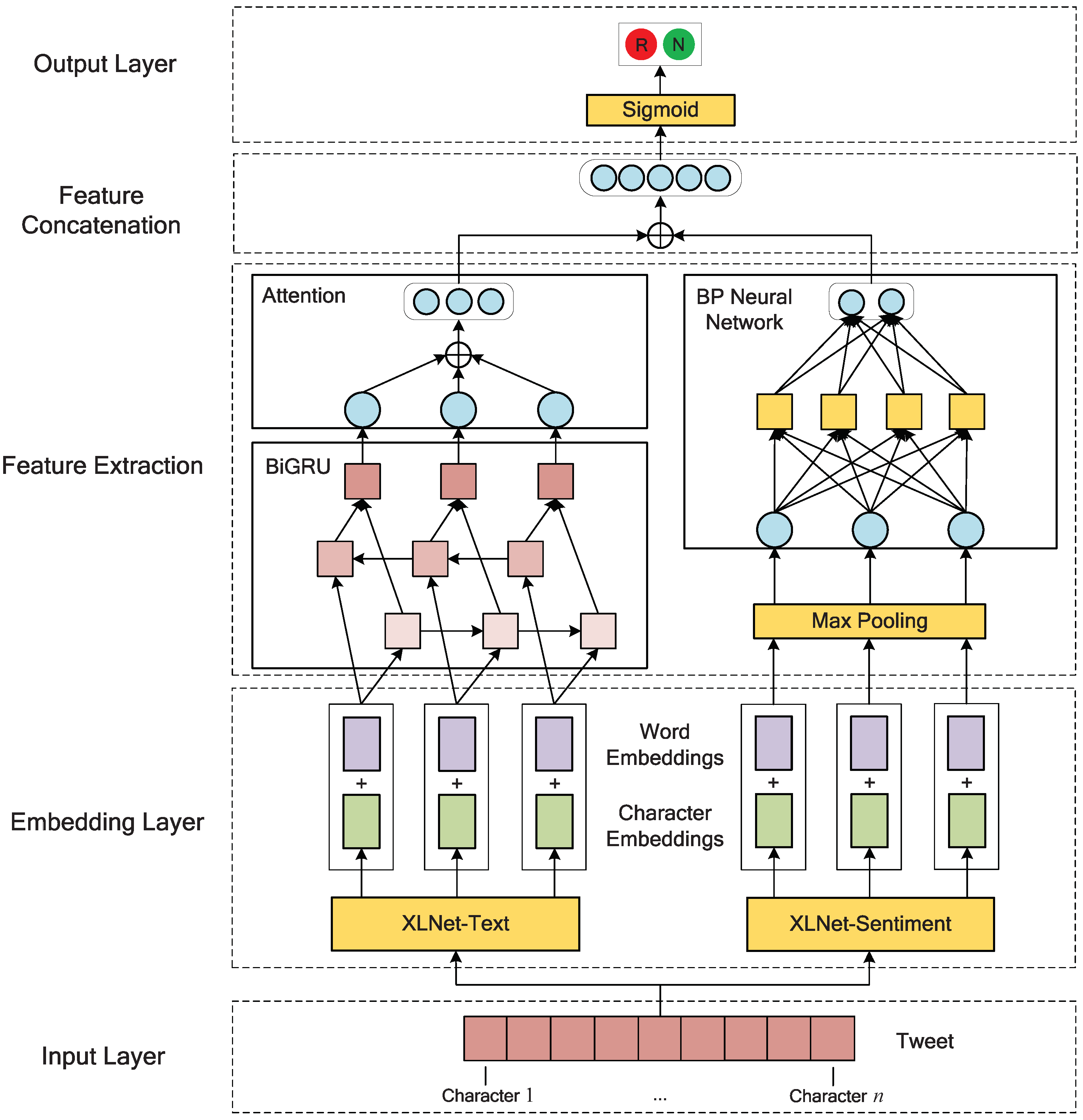
3. The Proposed Model
3.1. Input Layer
3.2. Embedding Layer
3.2.1. Text-based Embeddings
3.2.2. Sentiment-based Embeddings
3.2.3. Joint Learning of Character and Word Embeddings
3.3. Feature Extraction
3.3.1. Bidirectional Gated Recurrent Unit
3.3.2. Attention
3.3.3. Back Propagation Neural Network
3.4. Feature Concatenation
3.5. Output Layer
4. Experiments and Evaluation
4.1. Evaluation of the Embeddings
4.2. Ablation Study
- XGA-SF-1: Only the semantic features are used.
- XGA-SF-2: Only the sentiment features are used.
- XG: The attention mechanism is removed.
- XGA-CE: The word embeddings are removed and only the character embeddings are used.
- XGA: Full model.
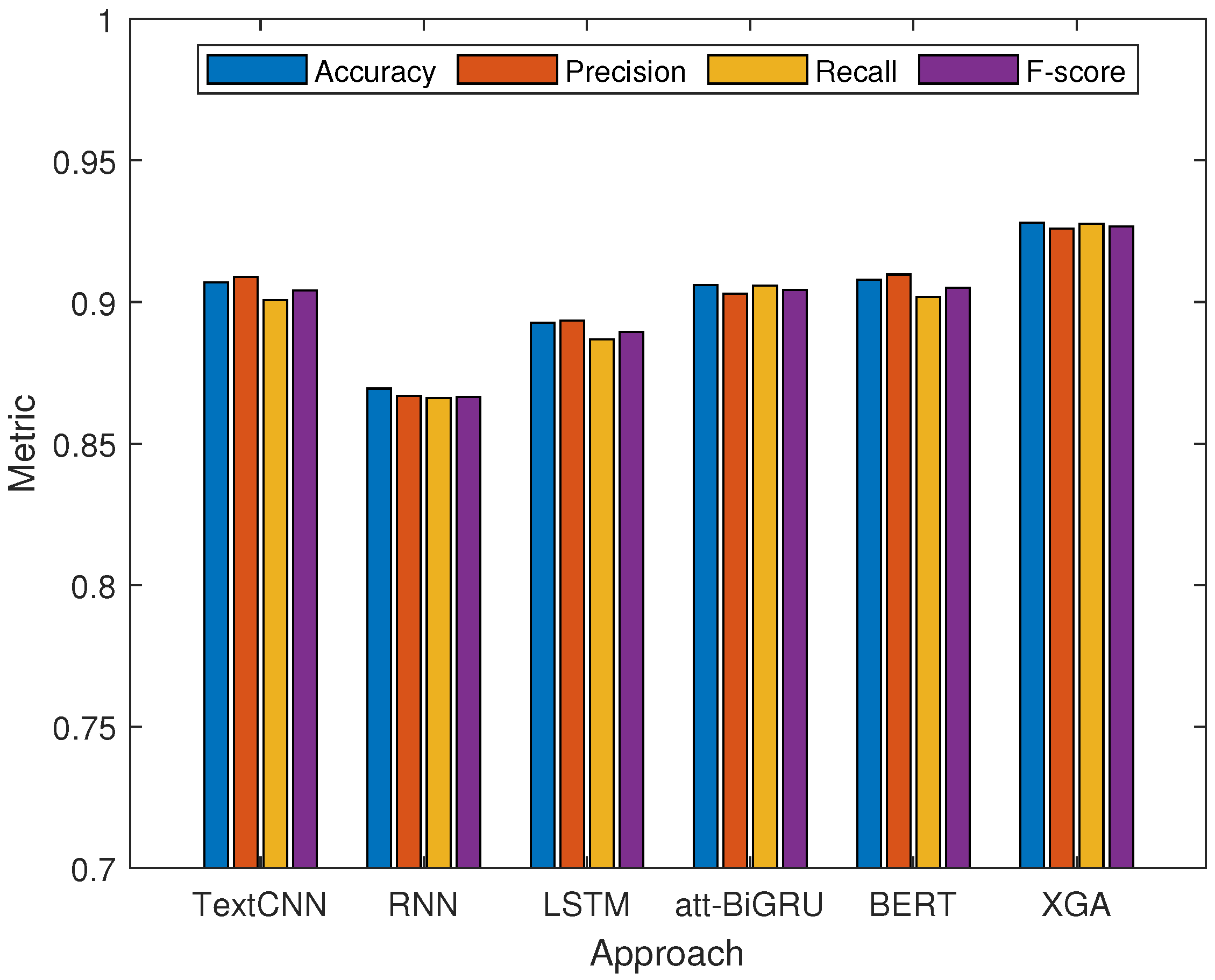
4.3. Evaluation of the XGA Model
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liang, G.; He, W.; Xu, C.; Chen, L.; Zeng, J. Rumor identification in microblogging systems based on users’ behavior. IEEE Trans. Comput. Soc. Syst. 2015, 2, 99–108. [Google Scholar] [CrossRef]
- Snopes. Available online: https://www.snopes.com (accessed on 28 August 2020).
- PolitiFact. Available online: https://www.politifact.com (accessed on 28 August 2020).
- Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.F.; Cha, M. Detecting rumors from microblogs with recurrent neural networks. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 3818–3824. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. CSI: A hybrid deep model for fake news detection. In Proceedings of the 26th 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 797–806. [Google Scholar]
- Liu, Y.; Wu, Y.F.B. Early detection of fake news on social media through propagation path classification with recurrent and convolutional networks. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 354–361. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.F. Rumor Detection on Twitter with Tree-structured Recursive Neural Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1980–1989. [Google Scholar]
- Bondielli, A.; Marcelloni, F. A survey on fake news and rumour detection techniques. Inf. Sci. 2019, 497, 38–55. [Google Scholar] [CrossRef]
- Meel, P.; Vishwakarma, D.K. Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities. Expert Syst. Appl. 2020, 153, 112986. [Google Scholar] [CrossRef]
- Zubiaga, A.; Aker, A.; Bontcheva, K.; Liakata, M.; Procter, R. Detection and resolution of rumours in social media: A survey. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Li, X.; Yin, H.; Zhang, J. Call attention to rumors: Deep attention based recurrent neural networks for early rumor detection. In Proceedings of the 22nd Pacific-Asia Conference on Knowledge Discovery and Data Mining, Melbourne, Australia, 3–6 June 2018; pp. 40–52. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.F. Detect rumors on twitter by promoting information campaigns with generative adversarial learning. In Proceedings of the 28th The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3049–3055. [Google Scholar]
- Kochkina, E.; Liakata, M.; Zubiaga, A. All-in-one: Multi-task Learning for Rumour Verification. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 3402–3413. [Google Scholar]
- Kumar, S.; Carley, K.M. Tree lstms with convolution units to predict stance and rumor veracity in social media conversations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5047–5058. [Google Scholar]
- Yu, F.; Liu, Q.; Wu, S.; Wang, L.; Tan, T. A convolutional approach for misinformation identification. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3901–3907. [Google Scholar]
- Qian, F.; Gong, C.; Sharma, K.; Liu, Y. Neural user response generator: Fake news detection with collective user intelligence. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3834–3840. [Google Scholar]
- Song, C.; Yang, C.; Chen, H.; Tu, C.; Liu, Z.; Sun, M. CED: Credible early detection of social media rumors. IEEE Trans. Knowl. Data Eng. 2019, 1. [Google Scholar] [CrossRef] [Green Version]
- Jin, Z.; Cao, J.; Guo, H.; Zhang, Y.; Luo, J. Multimodal fusion with recurrent neural networks for rumor detection on microblogs. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 795–816. [Google Scholar]
- Ma, J.; Gao, W.; Joty, S.; Wong, K.F. An Attention-based Rumor Detection Model with Tree-structured Recursive Neural Networks. ACM Trans. Intell. Syst. Technol. 2020, 11, 42. [Google Scholar] [CrossRef]
- Bian, T.; Xiao, X.; Xu, T.; Zhao, P.; Huang, W.; Rong, Y.; Huang, J. Rumor Detection on Social Media with Bi-Directional Graph Convolutional Networks. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 549–556. [Google Scholar]
- Dashtipour, K.; Gogate, M.; Li, J.; Jiang, F.; Kong, B.; Hussain, A. A hybrid Persian sentiment analysis framework: Integrating dependency grammar based rules and deep neural networks. Neurocomputing 2020, 380, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Cantonese Rumor Dataset. Available online: https://github.com/cxyccc/CR-Dataset (accessed on 28 August 2020).
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 5753–5763. [Google Scholar]
- XLNet-Base. Available online: https://github.com/zihangdai/xlnet (accessed on 28 August 2020).
- Encyclopedia of Virtual Communities in Hong Kong. Available online: https://evchk.wikia.org/zh/wiki/ (accessed on 28 August 2020).
- FastText Pre-trained Vectors. Available online: https://fasttext.cc/docs/en/pretrained-vectors (accessed on 28 August 2020).
- Sentiment Analysis of Baidu AI. Available online: https://ai.baidu.com/tech/nlp_apply/sentiment_classify (accessed on 28 August 2020).
- Openrice-senti Dataset. Available online: https://github.com/toastynews/openrice-senti (accessed on 28 August 2020).
- OpenRice Hong Kong Section. Available online: https://www.openrice.com/zh/hongkong (accessed on 28 August 2020).
- Chen, X.; Xu, L.; Liu, Z.; Sun, M.; Luan, H. Joint learning of character and word embeddings. In Proceedings of the 24th International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 1236–1242. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 17th Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 16th Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 19 May 2017; pp. 5998–6008.


{kind=link}
{kind=link}
{kind=link}
| Embedding | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| BERT | 0.9119 | 0.9099 | 0.9102 | 0.9101 |
| GPT | 0.9099 | 0.9092 | 0.9063 | 0.9076 |
| ELMo | 0.9048 | 0.9048 | 0.9046 | 0.9047 |
| fastText | 0.9030 | 0.9031 | 0.9028 | 0.9029 |
| Word2vec | 0.9079 | 0.9056 | 0.9063 | 0.9060 |
| XLNet | 0.9200 | 0.9224 | 0.9142 | 0.9176 |
| Model | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| XGA-SF-1 | 0.9175 | 0.9176 | 0.9178 | 0.9175 |
| XGA-SF-2 | 0.8794 | 0.8820 | 0.8784 | 0.8789 |
| XG | 0.9157 | 0.9158 | 0.9161 | 0.9157 |
| XGA-CE | 0.9030 | 0.9031 | 0.9028 | 0.9029 |
| XGA | 0.9281 | 0.9259 | 0.9276 | 0.9267 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Ke, L.; Lu, Z.; Su, H.; Wang, H. A Novel Hybrid Model for Cantonese Rumor Detection on Twitter. Appl. Sci. 2020, 10, 7093. https://doi.org/10.3390/app10207093
Chen X, Ke L, Lu Z, Su H, Wang H. A Novel Hybrid Model for Cantonese Rumor Detection on Twitter. Applied Sciences. 2020; 10(20):7093. https://doi.org/10.3390/app10207093
Chicago/Turabian StyleChen, Xinyu, Liang Ke, Zhipeng Lu, Hanjian Su, and Haizhou Wang. 2020. "A Novel Hybrid Model for Cantonese Rumor Detection on Twitter" Applied Sciences 10, no. 20: 7093. https://doi.org/10.3390/app10207093
APA StyleChen, X., Ke, L., Lu, Z., Su, H., & Wang, H. (2020). A Novel Hybrid Model for Cantonese Rumor Detection on Twitter. Applied Sciences, 10(20), 7093. https://doi.org/10.3390/app10207093