Blur Kernel Estimation by Structure Sparse Prior

Abstract
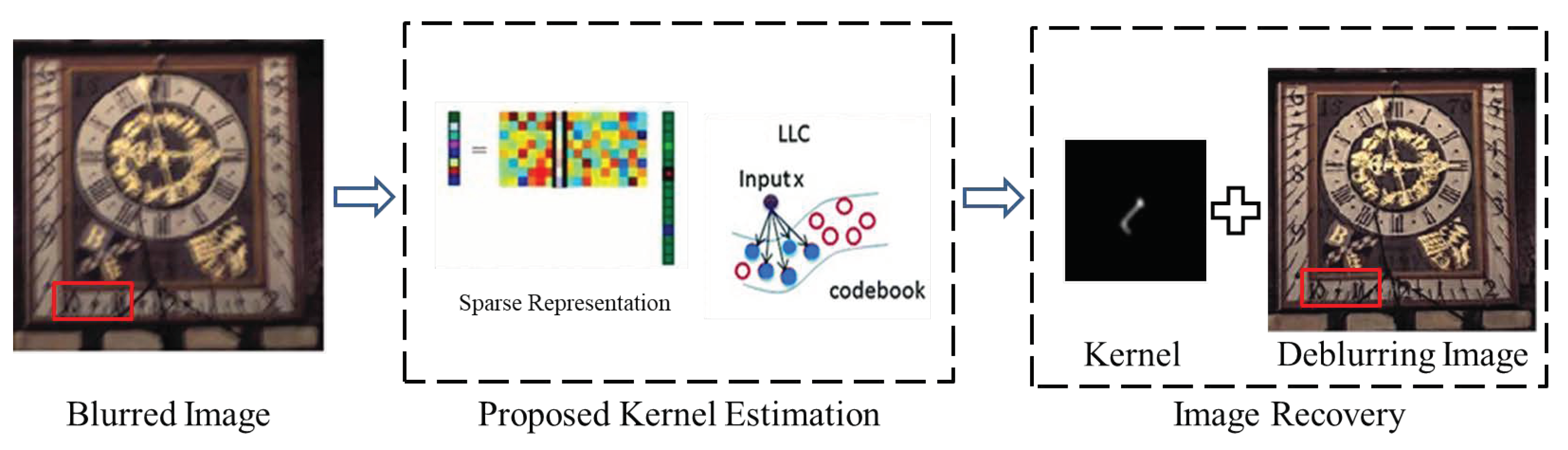
:1. Introduction
- A new blur kernel estimation method is proposed by considering the structure information of the image, which can effectively estimate the blur kernel. Both the sparsity regularization and the locality constraint are incorporated to exploit the structure relationships among pixels.
- A structure sparse prior is proposed by introducing the locality constraint into sparse representation framework. The structure sparse prior can preserve the inherent attribute of the sharp image.
2. Materials
3. Method
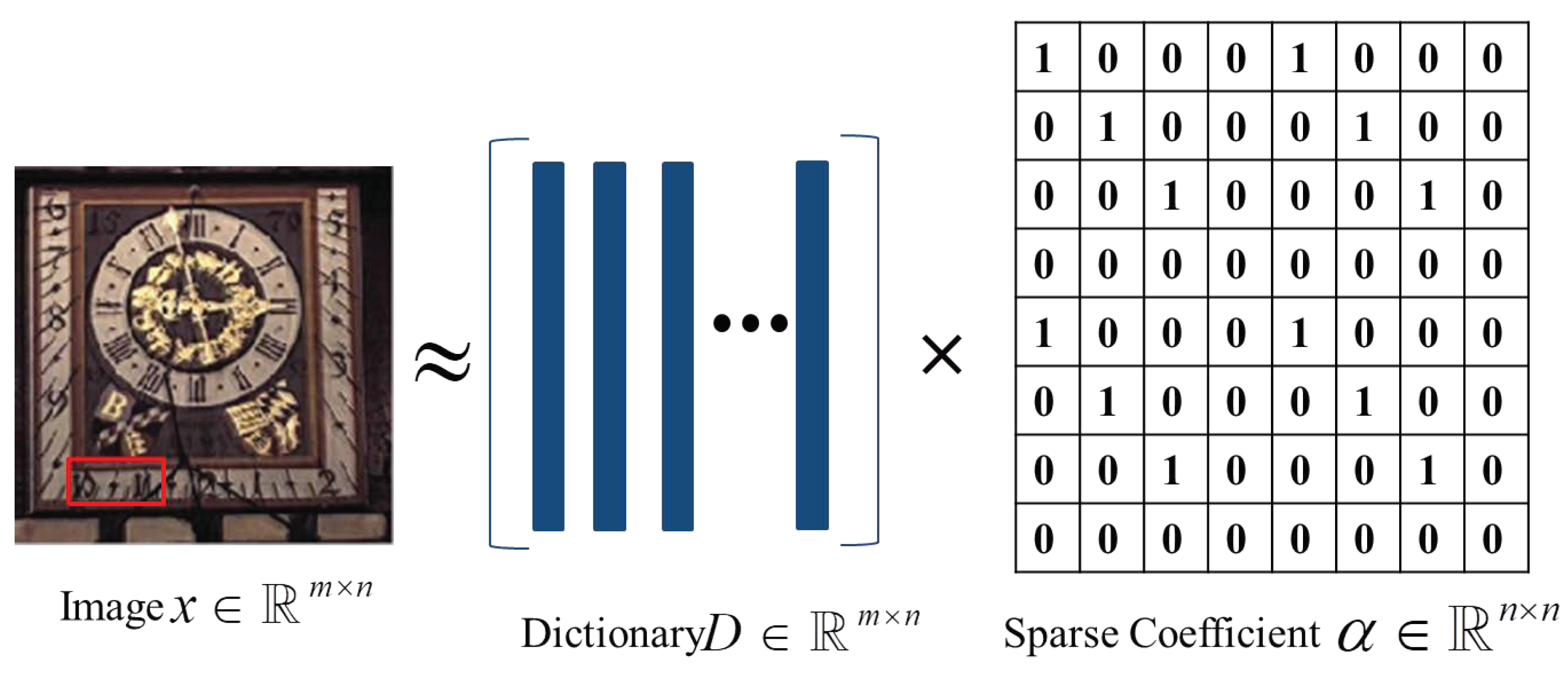
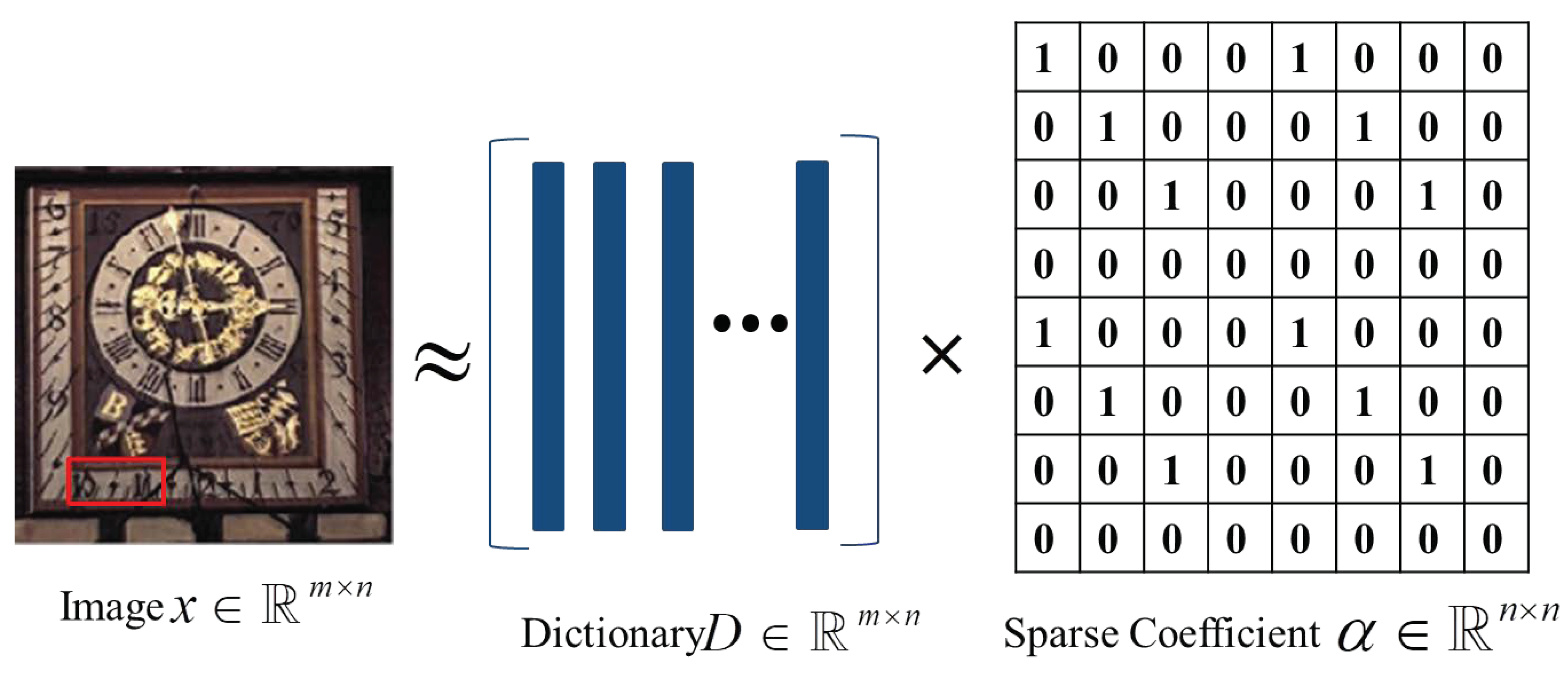
3.1. Sparse Representation
3.2. Structure Sparse Prior
- The first term in the objective function is a conventional constraint, which measures the likelihood between the recovered image and the blurred image.
- The second term means the recovered image is sparse representation.
- The third term represents the -norm regularization on k to enforce sparsity.
- The last term, , is the locality constraint, which ensures each descriptor is represented by multiple bases and regularizes the x and at the same time.
3.3. Optimization Procedure
3.3.1. k Update
3.3.2. x Update
3.3.3. Update
| Algorithm 1: Blur kernel estimation by structure sparse prior. |
 |
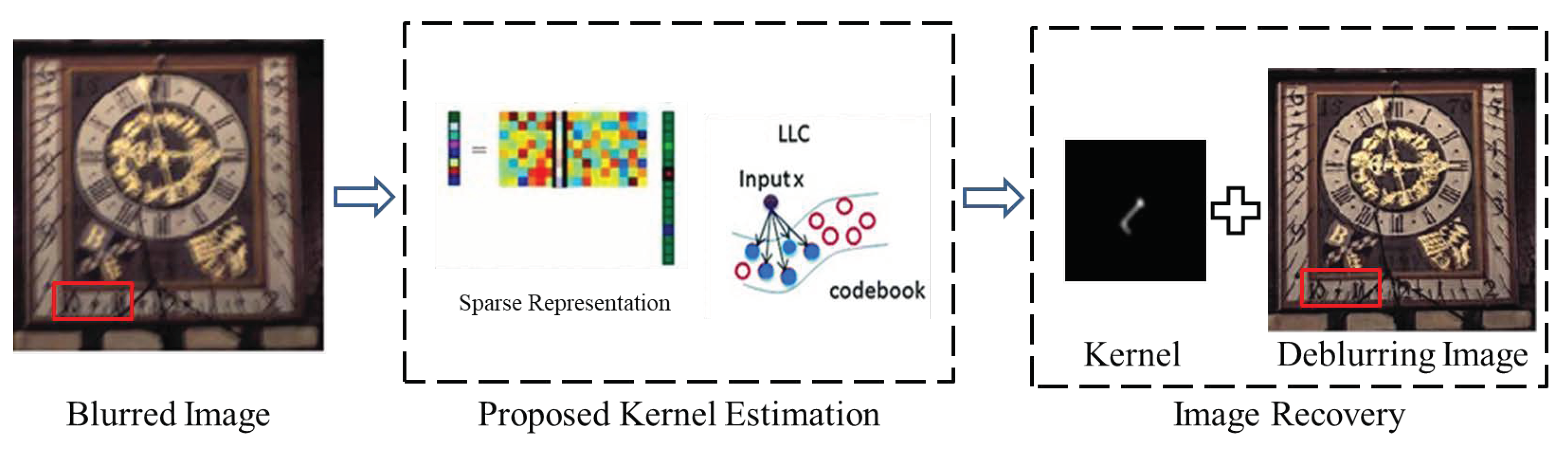
3.4. Final Image Recovery
4. Experiments and Results
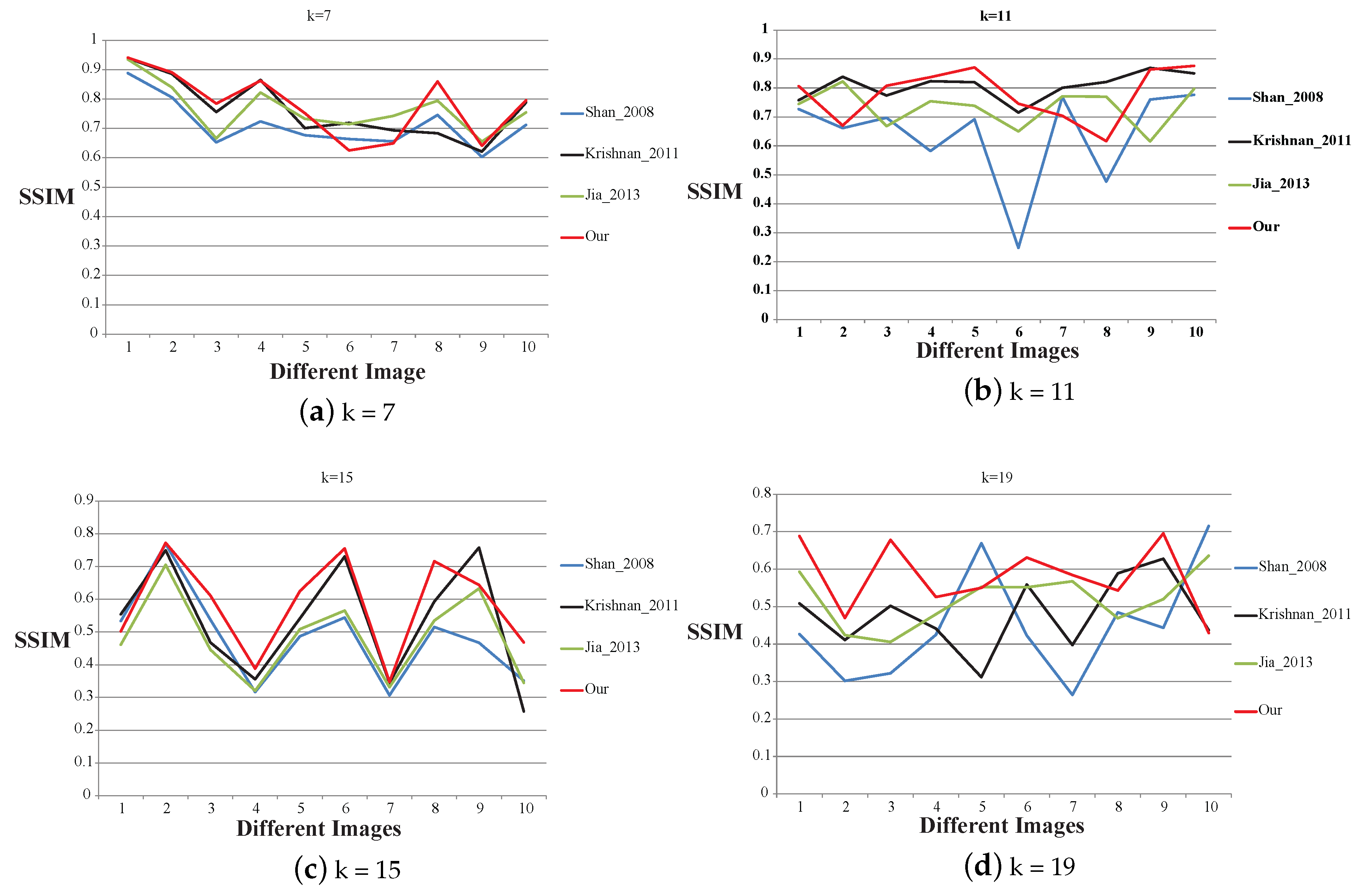
4.1. The Competitors and Experimental Images
- Shan_2008: The first method is from Q. Shan et al. [27]. The method recovers the clear image in a unified probabilistic model, including blur kernel estimation and image restoration.
- Krishnan_2011: The second method is from D. Krishnan et al. [8]. The method introduces a new type of regularization term, namely norm, which gives lowest cost for the true sharp image.
- Jia_2013: The final method is from L. Xu et al. [28]. The method provides a unified framework for removing the blur kernel. A generalized and mathematically sound sparse expression is proposed.
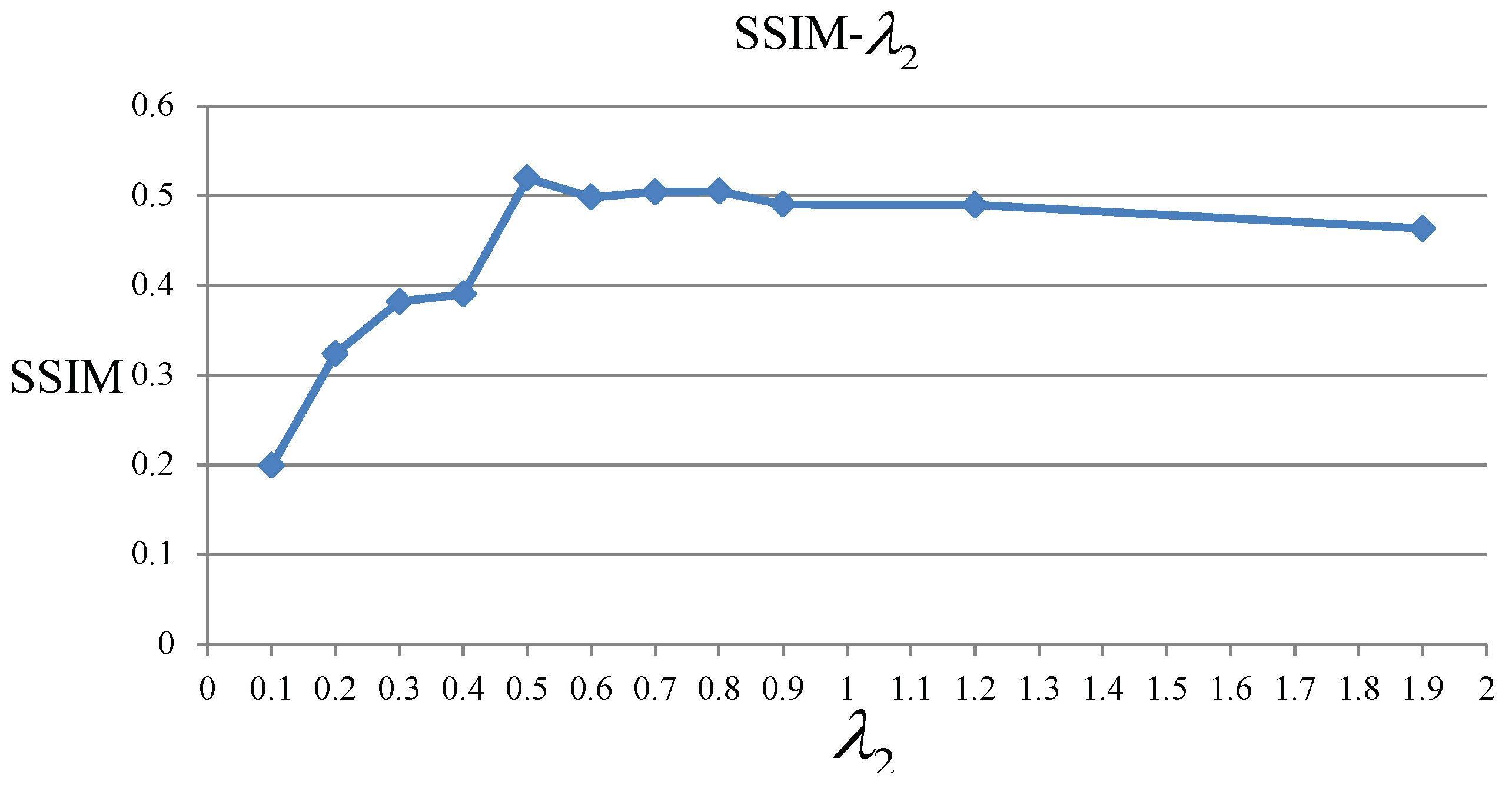
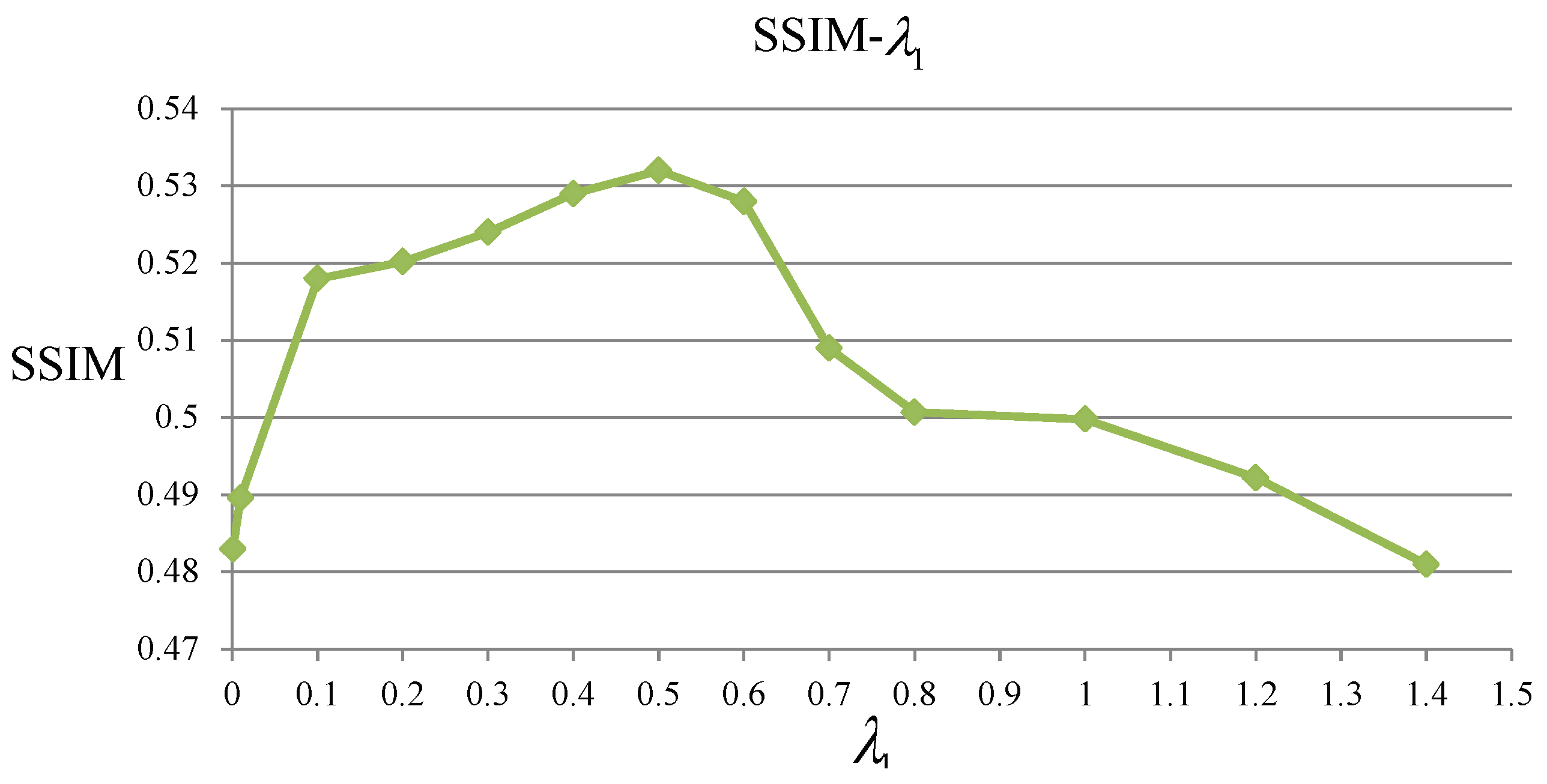
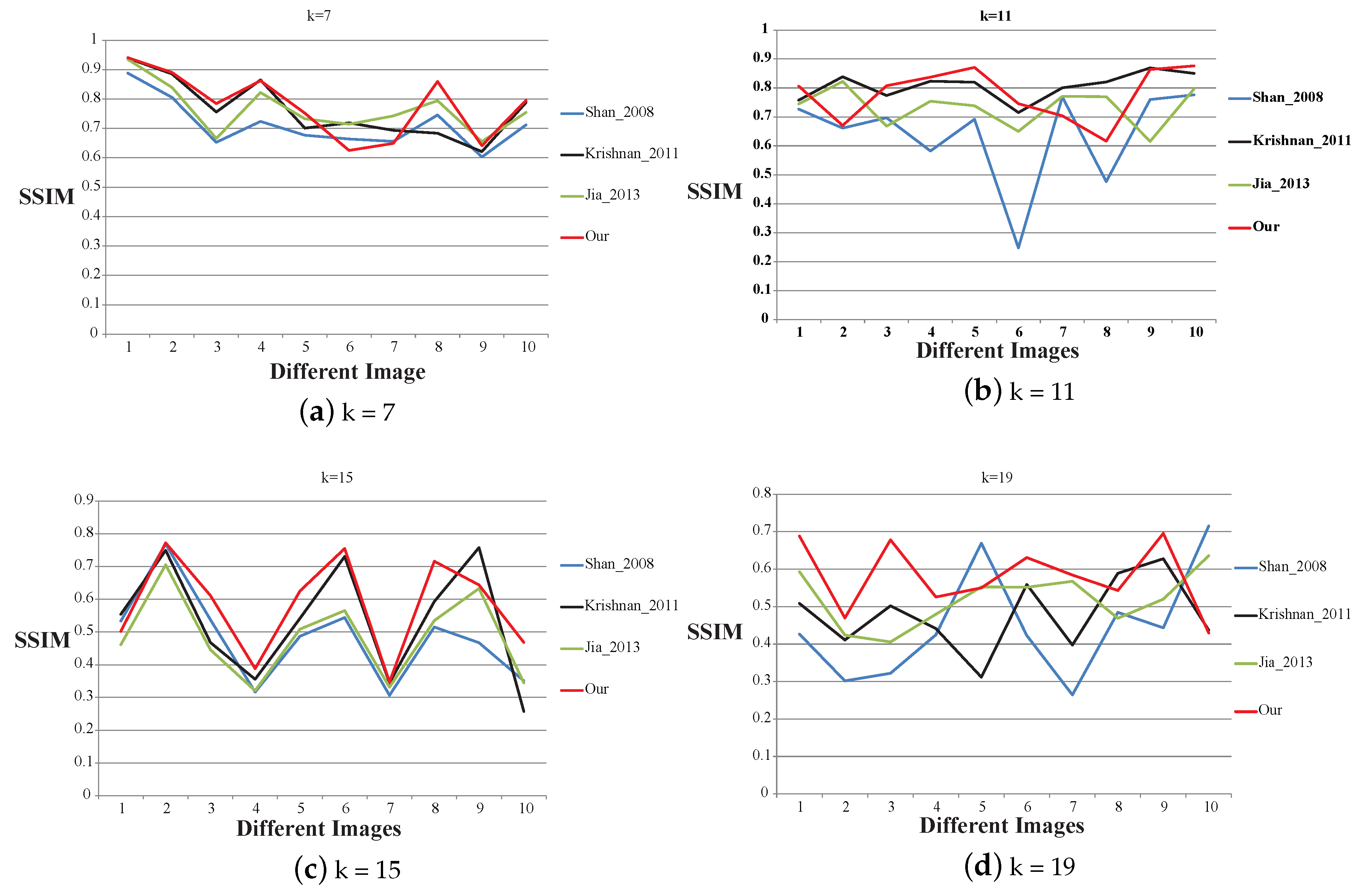
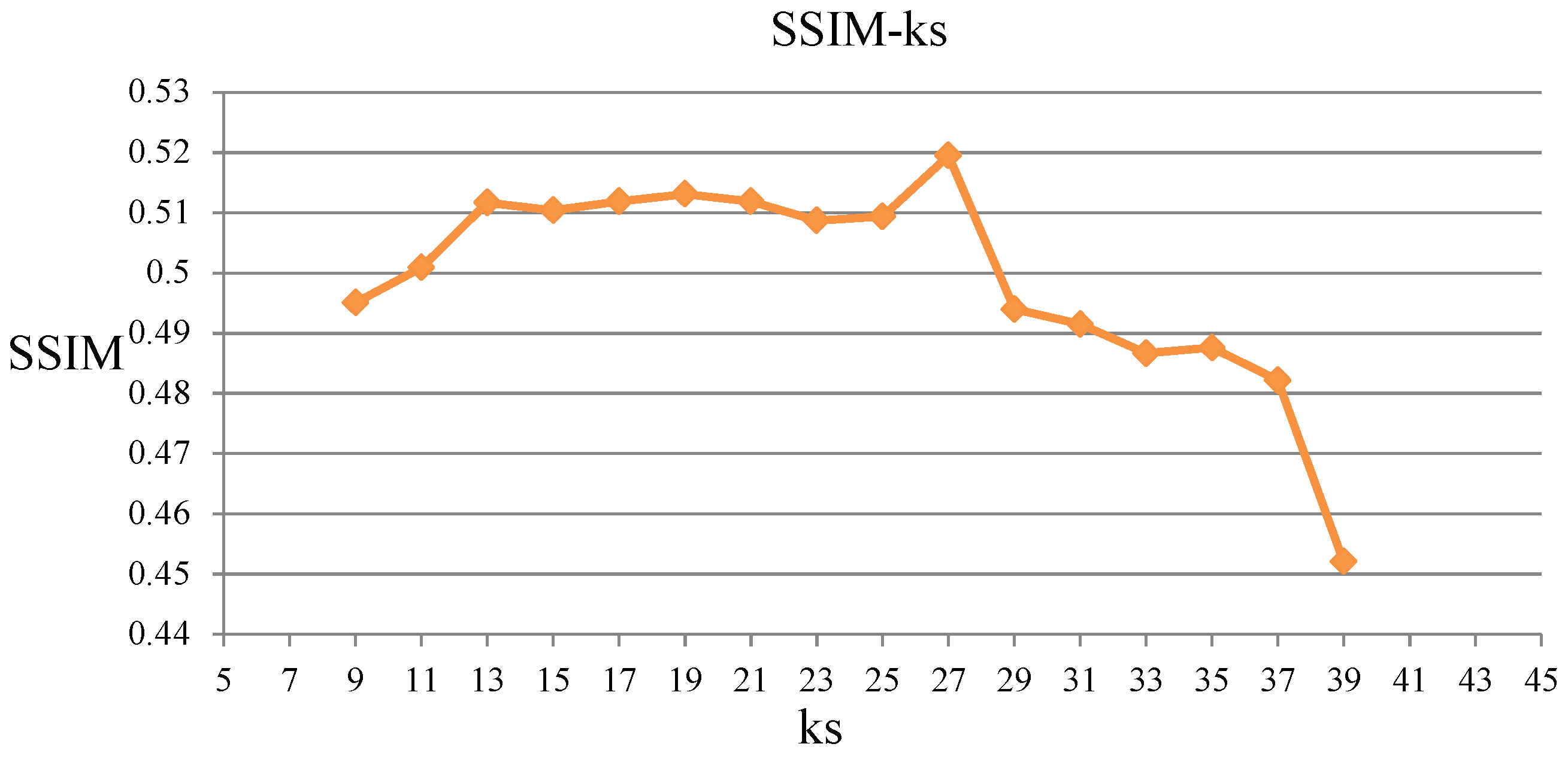
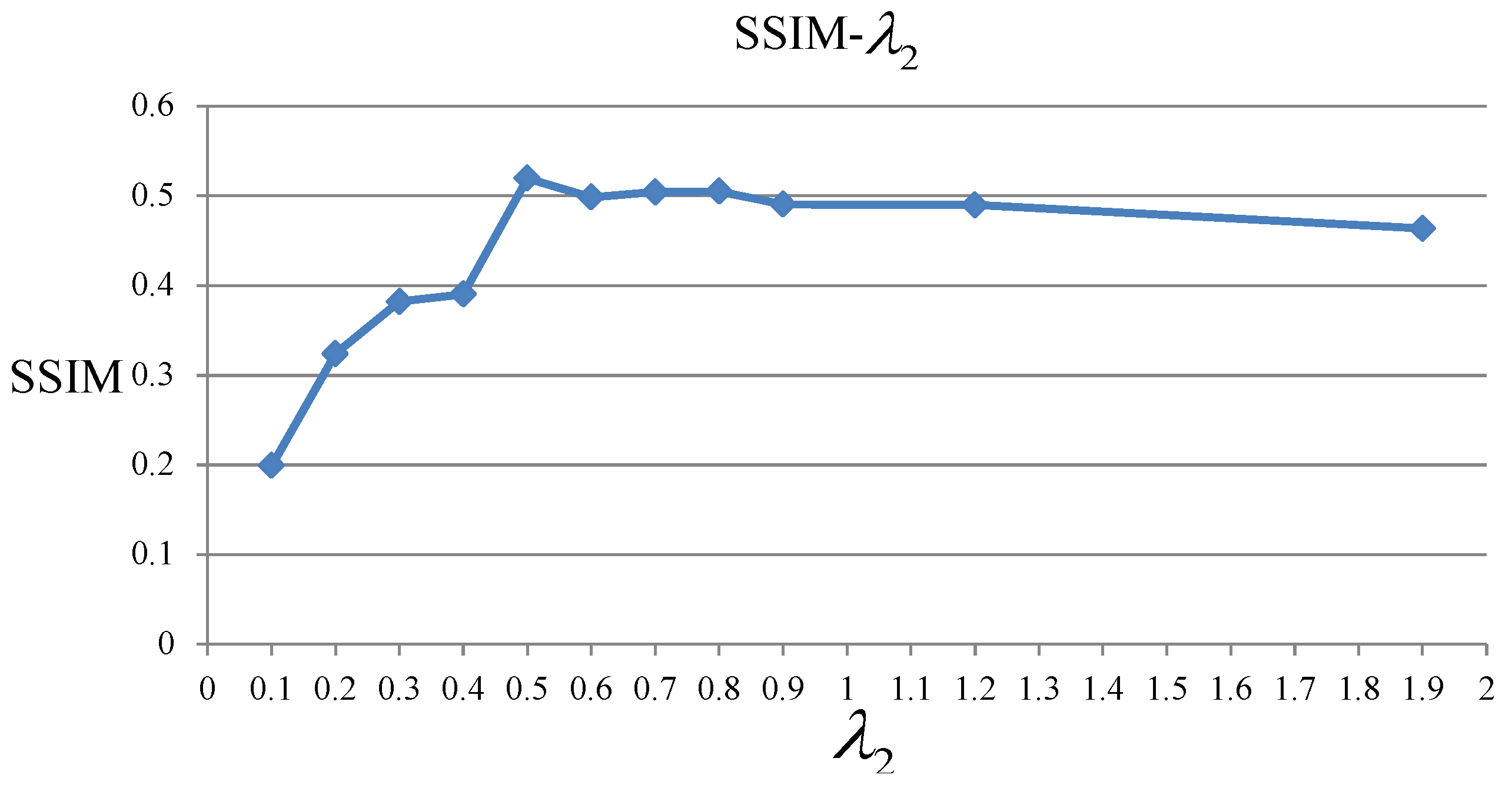
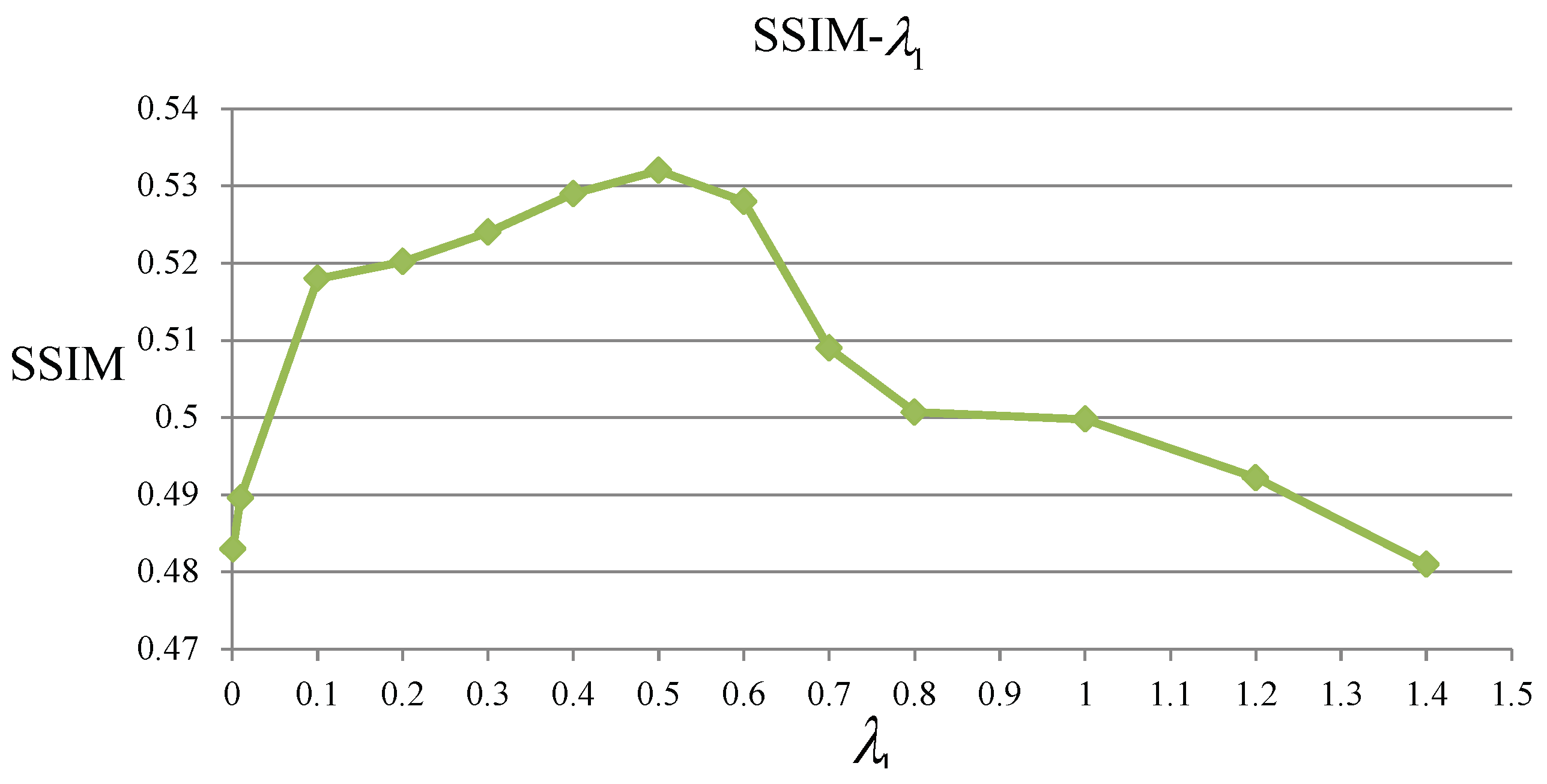
4.2. Evaluation of The Parameters
4.3. Result
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Uzer, F. Camera Motion Blur and Its Effect on Feature Detectors. Master’s Thesis, Middle East Technical University, Ankara, Turkey, 2010. [Google Scholar]
- Zheng, X.; Yuan, Y.; Lu, X. Hyperspectral Image Denoising by Fusing the Selected Related Bands. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2596–2609. [Google Scholar] [CrossRef]
- Donatelli, M.; Estatico, C.; Martinelli, A.; SerraCapizzano, S. Improved image deblurring with antireflective boundary conditions and reblurring. Inverse Probl. 2006, 22, 2035–2053. [Google Scholar] [CrossRef]
- Levin, A.; Fergus, R.; Durand, F.; Freeman, W.T. Image and depth from a conventional camera with a coded aperture. ACM Trans. Graph. 2007, 26, 70. [Google Scholar] [CrossRef]
- Yuan, L.; Sun, J.; Quan, L.; Shum, H.Y. Progressive inter-scale and intra-scale non-blind image deconvolution. ACM Trans. Graph. 2008, 27, 74. [Google Scholar] [CrossRef]
- Gupta, A.; Joshi, N.; Zitnick, L.; Cohen, M.; Curless, B. Single image deblurring using motion density functions. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 171–184. [Google Scholar]
- Bar, L.; Sapiro, G. Generalized Newton methods for energy formulations in image procesing. In Proceedings of the IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 809–812. [Google Scholar]
- Krishnan, D.; Tay, T.; Fergus, R. Blind deconvolution using a normalized sparsity measure. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 20–25 June 2011; pp. 233–240. [Google Scholar]
- Levin, A.; Weiss, Y.; Durand, F.; Freeman, W.T. Understanding and evaluating blind deconvolution algorithms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1964–1971. [Google Scholar]
- Chen, Y.; Ding, J.; Lai, W.; Chen, Y.; Chang, C.W.; Chang, C.C. High Quality Image Deblurring Scheme Using the Pyramid Hyper-Laplacian L2 Norm Priors Algorithm. In Pacific-Rim Conference on Multimedia; Springer: Cham, Switzerland, 2013; pp. 134–145. [Google Scholar]
- Almeida, M.; Almeida, L. Blind and semi-blind deblurring of natural images. IEEE Trans. Image Process. 2010, 19, 36–52. [Google Scholar] [CrossRef] [PubMed]
- Dong, W.; Shi, G.; Li, X. Image Deblurring with Low-rank Approximation Structured Sparse Representation. In Proceedings of the Signal & Information Processing Association Annual Summit and Conference, Hollywood, CA, USA, 3–6 December 2012; pp. 1–5. [Google Scholar]
- Wipf, D.P.; Zhang, H. Revisiting Bayesian Blind Deconvolution. J. Mach. Learn. Res. 2014, 15, 3595–3634. [Google Scholar]
- Babacan, S.; Molina, R.; Do, M.N.; Katsaggelos, A.K. Bayesian blind deconvolution with general sparse image priors. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 341–355. [Google Scholar]
- Levin, A.; Weiss, Y.; Durand, F.; Freeman, W. Efficient marginal likelihood optimization in blind deconvolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 20–25 June 2011; pp. 2657–2664. [Google Scholar]
- Fergus, R.; Singh, B.; Hertzmann, A.; Roweis, S.T.; Freeman, W.T. Removing camera shake from a single photograph. ACM Trans. Graph. 2006, 25, 787–794. [Google Scholar] [CrossRef]
- Zhang, H.; Wipf, D.; Zhang, Y. Multi-Observation Blind Deconvolution with an Adaptive Sparse Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1628–1643. [Google Scholar] [CrossRef] [PubMed]
- Cho, T.; Joshi, N.; Zitnick, C.L.; Sing, K.; Szeliski, R.; Freeman, W.T. A content-aware image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 169–176. [Google Scholar]
- Cai, J.; Hui, J.; Liu, C.; Shen, Z. Blind motion deblurring from a single image using sparse approximation. In Proceedings of the IEEE Confernece on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 104–111. [Google Scholar]
- Aharon, M.; Elad, M.; Bruckstein, A. K-svd: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, J.; Nasrabadi, N.M.; Huang, T.S. Close the loop: Joint blind image restoration and recognition with sparse representation prior. In Proceedings of the IEEE Confenece on Computer Vision and Pattern Recognition, Barcelona, Spain, 6–13 November 2011; pp. 770–777. [Google Scholar]
- Jia, C.; Brain, L. Patch-based image deconvolution via joint modeling of sparse priors. In Proceedings of the IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 681–684. [Google Scholar]
- Elad, M.; Figueiredo, M.; Ma, Y. On the role of sparse and redundant representations in image processing. Proc. IEEE 2010, 98, 972–982. [Google Scholar] [CrossRef]
- Cho, S.; Lee, S. Fast motion deblurring. ACM Trans. Graph. 2009, 28, 145. [Google Scholar] [CrossRef]
- Wang, J.; Yang, J.; Yu, K.; Lv, F.; Huang, T. Locality-constrained linear coding for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3360–3367. [Google Scholar]
- Krishnan, D.; Fergus, R. Fast image deconvolution using hyper-Laplacian priors. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 1033–1041. [Google Scholar]
- Shan, Q.; Jia, J.; Agarwala, A. High-Quality Motion Deblurring from a Single Image. ACM Trans. Graph. 2008, 27, 73. [Google Scholar] [CrossRef]
- Xu, L.; Zheng, S.; Jia, J. Unnatural L0 Sparse Representation for Natural Image Deblurring. In Proceedings of the IEEE International Conference on Image Processing, Portland, OR, USA, 23–28 June 2013; pp. 1107–1114. [Google Scholar]
- Köhler, R.; Hirsch, M.; Mohler, B.; Schölkopf, B.; Harmeling, S. Recording and playback of camera shake: Benchmarking blind deconvolution with a real-world database. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 27–40. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A Database of Human Segmented Natural Images and its Application to Evaluating Segmentation Algorithms and Measuring Ecological Statistics. In Proceedings of the 8th International Conference on Computer Vision, Vancouver, BC, Canada, 9–12 July 2001; pp. 416–423. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Explanation |
|---|---|
| x | the latent sharp image |
| y | the input blurred image |
| k | the blur kernel |
| the additive noise | |
| * | the convolution operator |
| the over-complete dictionary | |
| the sparse coefficient matrix |
| Image | Image Size | Shan [27] | Krishnan [8] | Jia [28] | Our |
|---|---|---|---|---|---|
| Image1 (church) | 800 × 800 | 0.5884 | 0.6145 | 0.6128 | 0.6180 |
| Image2 (clock) | 800 × 800 | 0.334 | 0.2874 | 0.3872 | 0.4847 |
| Image3 (backyard) | 800 × 800 | 0.6395 | 0.6245 | 0.6463 | 0.6851 |
| Image4 (roof) | 800 × 800 | 0.4899 | 0.4748 | 0.4819 | 0.5200 |
| Image | Image Size | Shan [27] | Krishnan [8] | Jia [28] | Our |
|---|---|---|---|---|---|
| Image1 (church) | 800 × 800 | 23.05 | 22.951 | 23.031 | 23.3618 |
| Image2 (clock) | 800 × 800 | 26.002 | 28.448 | 28.448 | 28.521 |
| Image3 (backyard) | 800 × 800 | 22.1814 | 21.6318 | 22.197 | 23.3827 |
| Image4 (roof) | 800 × 800 | 18.1483 | 17.1282 | 17.6505 | 18.9445 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, X.; Zhu, J.; Li, X. Blur Kernel Estimation by Structure Sparse Prior. Appl. Sci. 2020, 10, 657. https://doi.org/10.3390/app10020657
Yuan X, Zhu J, Li X. Blur Kernel Estimation by Structure Sparse Prior. Applied Sciences. 2020; 10(2):657. https://doi.org/10.3390/app10020657
Chicago/Turabian StyleYuan, Xiaobin, Jingping Zhu, and Xiaobin Li. 2020. "Blur Kernel Estimation by Structure Sparse Prior" Applied Sciences 10, no. 2: 657. https://doi.org/10.3390/app10020657
APA StyleYuan, X., Zhu, J., & Li, X. (2020). Blur Kernel Estimation by Structure Sparse Prior. Applied Sciences, 10(2), 657. https://doi.org/10.3390/app10020657