Fast Reaction to Sudden Concept Drift in the Absence of Class Labels


Abstract
:Featured Application
Abstract
1. Introduction
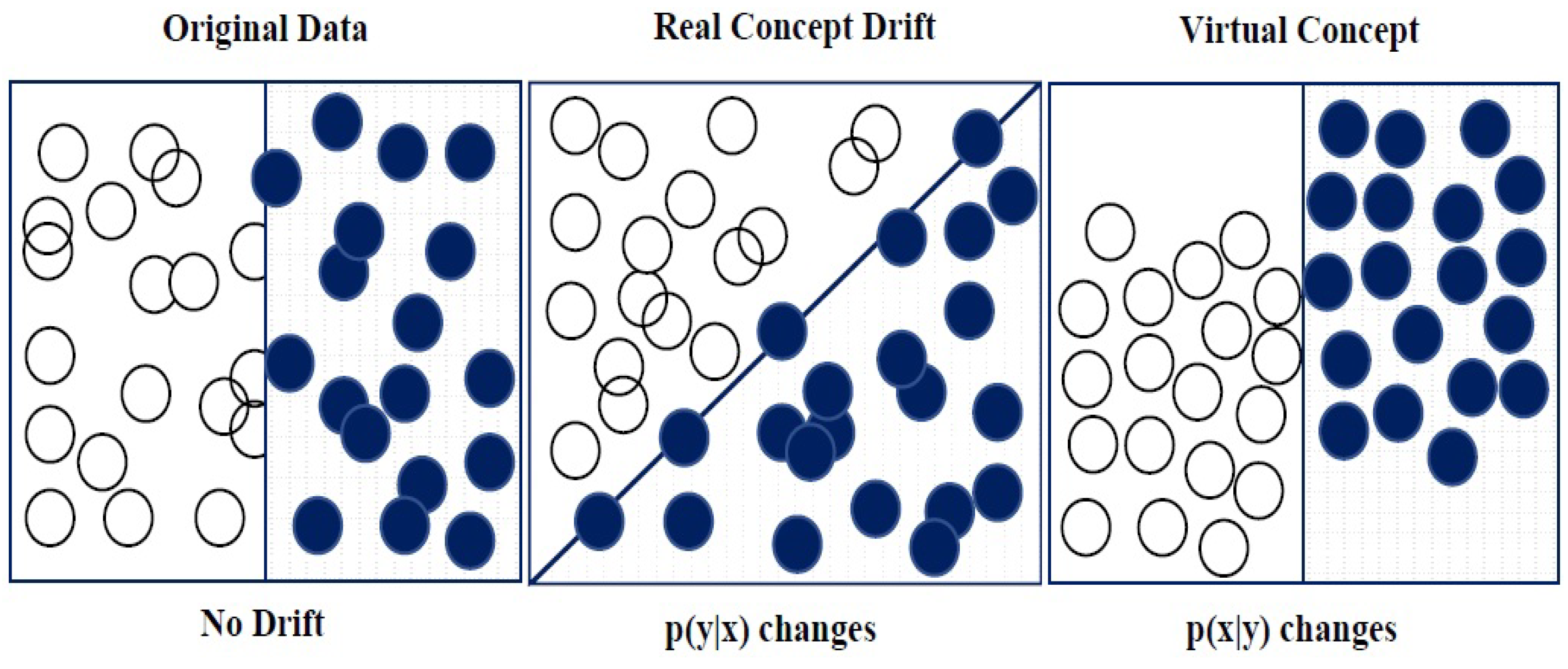
2. Problem Definition and Related Work
- Prior probabilities are prone to changes.
- Probabilities of class conditional are also prone to changes.
- Consequently, posterior probabilities may/may not change.
Existing Concept Drift Detection Methods
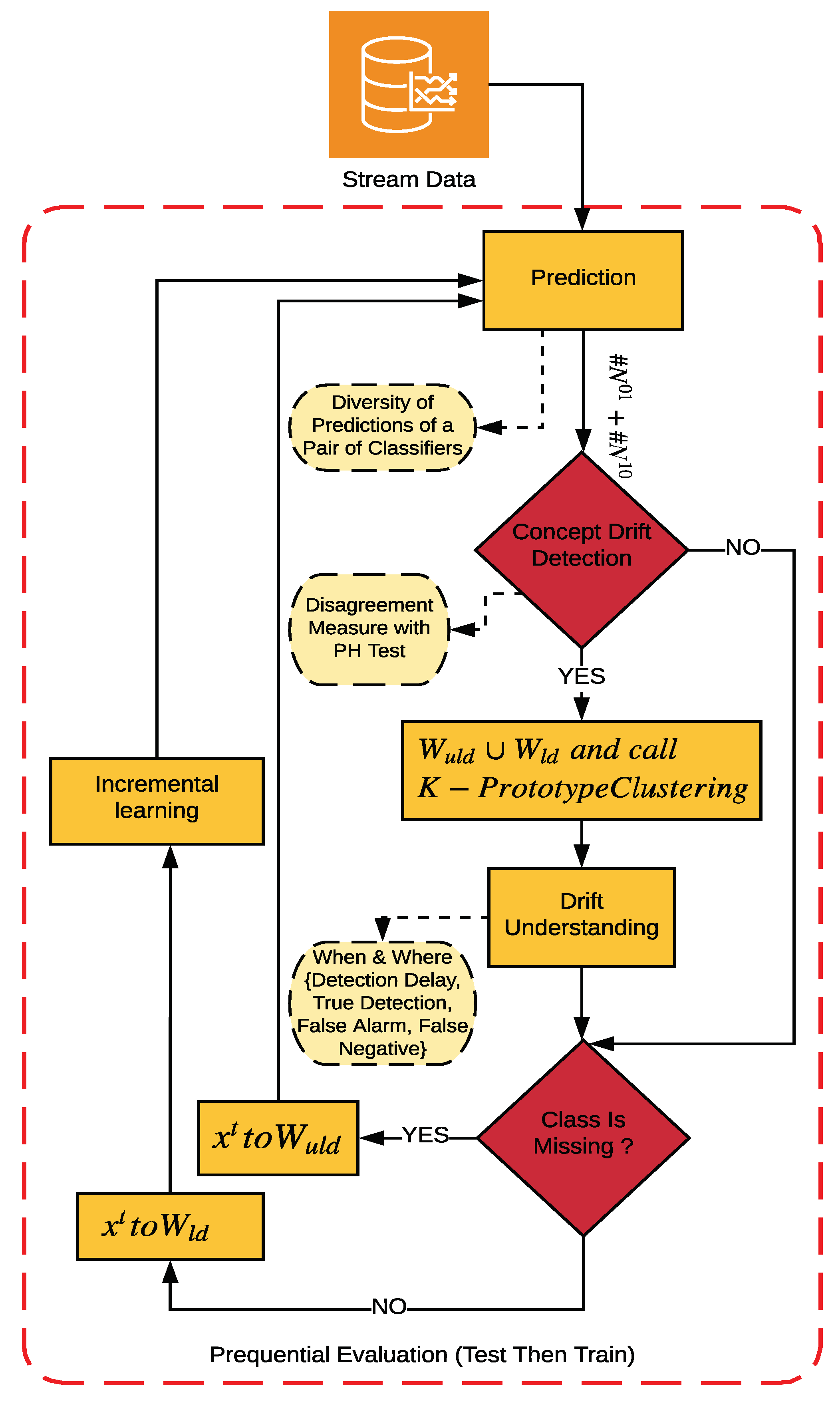
3. The Proposed Approach
3.1. Pairwise Diversity Measures
- number of examples where predicts class 1 and predicts class 0.
- number of examples where predicts class 1 and predicts class 0.
- number of examples where predicts class 1 and predicts class 1.
- number of examples where predicts class 0 and predicts class 0.
3.2. K-Prototype Clustering
3.3. The DMDDM-S Algorithm
| Algorithm 1: Pseudocode of Diversity Measure as a Drift Detection Method in a Semi-Supervised Environment (DMDDM-S) |
 |
4. Drift Detector Evaluation
- Mixed: This dataset has two numeric attributes, x and y, uniformly distributed in [0, 1] as well as two Boolean attributes v and w. The instances are classified as positive if at least two of the three following conditions are satisfied: . The classification is reversed after drifts. Sudden drifts happen at every 20,000 instances.
- Sine1: This comes with two attributes (x and y), which are uniformly distributed in [0, 1]. Following a function for classification, any instances below the curve are classified as positive, while the others are classified as negative, till the first drift occurs. At every 20,000 instances, a drift will occur and then the classification is reversed.
- Sine2: This comes with two attributes (x and y) which are uniformly distributed in [0, 1]. Following a function 0.5 + 0.3 , instances under the curve are classified as positive while the other instances are classified as negative. At every 20,000 instances, a drift will occur and then the classification is reversed.
- Detection Delay (Delay): The number of examples between the actual position of the drift and the detected one.
- True Detection (TD): Detects a drift occurring at time t and within [].
- False Alarm: A detector falsely signals a drift outside [].
- Detection Runtime (Time): The time required to detect the drift.
- Memory Usage: Memory requirement.
- Accuracy: Accuracy of classifiers after the drift is detected (calculated by counting the number of correct predictions). This value is displayed by MOA.
- MeanAccuracy: Mean accuracy over the data stream (also by MOA).
Experiment Results and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Prasad, B.R.; Agarwal, S. Stream data mining: Platforms, algorithms, performance evaluators and research trends. Int. J. Database Theory Appl. 2016, 9, 201–218. [Google Scholar] [CrossRef]
- Haque, A.; Khan, L.; Baron, M.; Thuraisingham, B.; Aggarwal, C. Efficient handling of concept drift and concept evolution over stream data. In Proceedings of theIEEE 32nd International Conference On Data Engineering (ICDE), Helsinki, Finland, 16–20 May 2016; pp. 481–492. [Google Scholar]
- Chen, Y.; Li, O.; Sun, Y.; Li, F. Ensemble Classification of Data Streams Based on Attribute Reduction and a Sliding Window. Appl. Sci. 2018, 8, 620. [Google Scholar] [CrossRef] [Green Version]
- Khamassi, I.; Sayed-Mouchaweh, M.; Hammami, M.; Gh edira, K. Discussion and review on evolving data streams and concept drift adapting. Evol. Syst. 2018, 9, 1–23. [Google Scholar] [CrossRef]
- Alippi, C.; Qi, W.; Roveri, M. Learning in nonstationary environments: A hybrid approach. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 11–15 June 2017; Springer: Cham, Switzerland, 2017; pp. 703–714. [Google Scholar]
- Ditzler, G.; Roveri, M.; Alippi, C.; Polikar, R. Learning in nonstationary environments: A survey. IEEE Comput. Intell. Mag. 2015, 10, 12–25. [Google Scholar] [CrossRef]
- Barros, R.S.M.; Santos, S.G.T.C. A large-scale comparison of concept drift detectors. Inf. Sci. 2018, 451, 348–370. [Google Scholar] [CrossRef]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. 2014, 46, 44. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern classification. Int. J. Comput. Intell. Appl. 2001, 1, 335–339. [Google Scholar]
- Gao, J.; Fan, W.; Han, J.; Yu, P.S. A general framework for mining concept-drifting data streams with skewed distributions. In Proceedings of the the 2007 SIAM International Conference on Data Mining SIAM (2007), Minneapolis, MN, USA, 26–28 April 2007; pp. 3–14. [Google Scholar]
- Pesaranghader, A.; Viktor, H.L.; Paquet, E. McDiarmid drift detection methods for evolving data streams. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–9. [Google Scholar]
- Brzezinski, D. Block-Based and Online Ensembles for Concept-Drifting Data Streams. Ph.D. Thesis, Poznan University of Technology, Poznań, Poland, 2015. [Google Scholar]
- Gama, J.; Medas, P.; Castillo, G.; Rodrigues, P. Learning with drift detection. In Proceedings of the Brazilian Symposium on Artificial Intelligence, São Luís, Brazil, 29 September–1 October 2004; pp. 286–295. [Google Scholar]
- Baena Garca, M.; del Campo Avila, J.; Fidalgo, R.; Bifet, A.; Gavalda, R.; Morales Bueno, R. Early drift detection method. In Proceedings of the Fourth International Workshop on Knowledge Discovery from Data Streams, Berlin, Germany, 18–22 September 2006; Volume 6, pp. 77–86. [Google Scholar]
- Pesaranghader, A.; Viktor, H.L. Fast hoeffding drift detection method for evolving data streams. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Riva del Garda, Italy, 19–23 September 2016; pp. 96–111. [Google Scholar]
- Gama, J.; Sebastiao, R.; Rodrigues, P.P. On evaluating stream learning algorithms. Mach. Learn. 2013, 90, 317–346. [Google Scholar] [CrossRef] [Green Version]
- Huang, D.T.J.; Koh, Y.S.; Dobbie, G.; Pears, R. Detecting volatility shift in data streams. In Proceedings of the 2014 IEEE International Conference on Data Mining, Shenzhen, China, 14–17 December 2014; pp. 863–868. [Google Scholar]
- Nishida, K.; Yamauchi, K. Detecting concept drift using statistical testing. In Proceedings of the International Conference on Discovery Science, Sendai, Japan, 1–4 October 2007; pp. 264–269. [Google Scholar]
- Barros, R.S.; Cabral, D.R.; Goncalves, P.M., Jr.; Santos, S.G. Rddm: Reactive drift detection method. Expert Syst. Appl. 2017, 90, 344–355. [Google Scholar] [CrossRef]
- Escovedo, T.; Koshiyama, A.; da Cruz, A.A.; Vellasco, M. DetectA: Abrupt concept drift detection in nonstationary environments. Appl. Soft Comput. 2018, 62, 119–133. [Google Scholar] [CrossRef]
- Liu, A.; Lu, J.; Liu, F.; Zhang, G. Accumulating regional density dissimilarity for concept drift detection in data streams. Pattern Recognit. 2018, 76, 256–272. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Abraham, Z. Concept drift detection with hierarchical hypothesis testing. In Proceedings of the 2017 SIAM International Conference on Data Mining, Houston, TX, USA, 27–29 April 2017; pp. 768–776. [Google Scholar]
- de Lima Cabral, D.R.; de Barros, R.S.M. Concept drift detection based on Fisher’s Exact test. Inf. Sci. 2018, 442, 220–234. [Google Scholar] [CrossRef]
- Banfield, R.E.; Hall, L.O.; Bowyer, K.W.; Kegelmeyer, W.P. A new ensemble diversity measure applied to thinning ensembles. In Proceedings of the International Workshop on Multiple Classifier Systems, Guildford, UK, 11–13 June 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 306–316. [Google Scholar]
- Giacinto, G.; Roli, F. An approach to the automatic design of multiple classifier systems. Pattern Recognit. Lett. 2001, 22, 25–33. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Skalak, D.B. The sources of increased accuracy for two proposed boosting algorithms. In Proceedings of the American Association for Arti Intelligence, AAAI-96, Integrating Multiple Learned Models Workshop, Portland, OR, USA, 4–5 August 1996; pp. 120–125. [Google Scholar]
- Minku, L.L.; White, A.P.; Yao, X. The impact of diversity on online ensemble learning in the presence of concept drift. IEEE Trans. Knowl. Data Eng. 2009, 22, 730–742. [Google Scholar] [CrossRef]
- Brzezinski, D.; Stefanowski, J. Ensemble diversity in evolving data streams. In Proceedings of the International Conference on Discovery Science, Bari, Italy, 19–21 October 2016; Springer: Cham, Switzerland, 2016; pp. 229–244. [Google Scholar]
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms; Wiley Interscience: New York, NY, USA, 2004. [Google Scholar]
- Huang, Z. Clustering large data sets with mixed numeric and categorical values. In Proceedings of the First Pacifc Asia Conference on Knowledge Discovery and Data Mining, Singapore, 23–24 February 1997; pp. 21–34. [Google Scholar]
- Bifet, A.; Holmes, G.; Kirkby, R.; Pfahringer, B. MOA: Massive online analysis. J. Mach. Learn. Res. 2010, 11, 1601–1604. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sine1 (A) | Sine1 (B) | |||||
|---|---|---|---|---|---|---|
| Classifier | Detector | Delay | TP | Time | Memory | MeanAccuracy |
| HT & Pre | DMDDM-S | 36.375 | 4 | 1.6 | 168 | 86.631 |
| HT | FHDDM | 47.375 | 4 | 7.7 | 1048 | 85.242 |
| DDM | 196.225 | 2 | 3.3 | 472 | 66.633 | |
| PHTest | 238.275 | 1.2 | 2.1 | 1240 | 66.211 | |
| STEPD | 27.05 | 4 | 6.4 | 936 | 87.047 | |
| SEED | 58.4 | 4 | 12 | 3572.588 | 86.969 | |
| RDDM | 93 | 4 | 2.6 | 8656 | 86.894 | |
| EDDM | 244.525 | 0.1 | 1.6 | 144 | 83.34 | |
| Pre | FHDDM | 46.562 | 4 | 7.75 | 1048 | 87.177 |
| DDM | 154.636 | 4 | 2.545 | 472 | 86.870 | |
| PHTest | 249.568 | 0.090 | 1.363 | 1240 | 72.199 | |
| STEPD | 27.35 | 4 | 5.2 | 936 | 87.199 | |
| SEED | 56.8 | 4 | 11.5 | 3593.608 | 87.098 | |
| RDDM | 99.875 | 4 | 2.6 | 8656 | 87.075 | |
| EDDM | 250 | 0 | 1.6 | 144 | 72.181 | |
| Sine2 (A) | Sine2 (B) | |||||
|---|---|---|---|---|---|---|
| Classifier | Detector | Delay | TP | Time | Memory | MeanAccuracy |
| HT & Pre | DMDDM-S | 23.75 | 4 | 1.7 | 168 | 78.294 |
| HT | FHDDM | 52.125 | 4 | 9.2 | 1048 | 79.834 |
| DDM | 209.2 | 3.6 | 1.5 | 472 | 77.399 | |
| PHTest | 230 | 0 | 1.9 | 1240 | 57.738 | |
| STEPD | 33.1 | 4 | 6.4 | 936 | 79.855 | |
| SEED | 62.4 | 4 | 11.4 | 3638.354 | 79.729 | |
| RDDM | 134.575 | 4 | 3.8 | 8656 | 79.55 | |
| EDDM | 250 | 0 | 2 | 144 | 57.738 | |
| Pre | FHDDM | 56.675 | 4 | 10.5 | 1048 | 74.843 |
| DDM | 246.25 | 0.3 | 2.1 | 472 | 74.269 | |
| PHTest | 250 | 0 | 1 | 1240 | 49.882 | |
| STEPD | 41.725 | 4 | 6.5 | 936 | 74.851 | |
| SEED | 70.4 | 4 | 10.6 | 3688.576 | 74.813 | |
| RDDM | 189.625 | 3.4 | 2 | 8656 | 74.623 | |
| EDDM | 250 | 0 | 1.4 | 144 | 74.256 | |
| Mixed (A) | Mixed (B) | |||||
|---|---|---|---|---|---|---|
| Classifier | Detector | Delay | TP | Time | Memory | MeanAccuracy |
| HT & Pre | DMDDM-S | 36.45 | 4 | 1.2 | 168 | 83.171 |
| HT | FHDDM | 48.1 | 4 | 9 | 1048 | 72.767 |
| DDM | 214.575 | 1.8 | 1.9 | 427 | 69.828 | |
| PHTest | 236.025 | 1.3 | 1.6 | 1240 | 67.876 | |
| STEPD | 28.7 | 4 | 7.6 | 936 | 83.373 | |
| SEED | 60 | 4 | 11.1 | 3609.606 | 83.294 | |
| RDDM | 100.125 | 4 | 3.4 | 8656 | 83.265 | |
| EDDM | 250 | 0 | 2.1 | 144 | 57.858 | |
| Pre | FHDDM | 47.45 | 4 | 7.6 | 1048 | 82.125 |
| DDM | 220.925 | 2.1 | 1.9 | 427 | 79.316 | |
| PHTest | 246.55 | 0.2 | 1.4 | 1240 | 76.743 | |
| STEPD | 30.725 | 4 | 7 | 936 | 82.143 | |
| SEED | 60 | 4 | 11 | 3641.589 | 82.065 | |
| RDDM | 117.575 | 4 | 2.5 | 8656 | 82.006 | |
| EDDM | 244.65 | 0.1 | 1.5 | 144 | 76.483 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahdi, O.A.; Pardede, E.; Ali, N.; Cao, J. Fast Reaction to Sudden Concept Drift in the Absence of Class Labels. Appl. Sci. 2020, 10, 606. https://doi.org/10.3390/app10020606
Mahdi OA, Pardede E, Ali N, Cao J. Fast Reaction to Sudden Concept Drift in the Absence of Class Labels. Applied Sciences. 2020; 10(2):606. https://doi.org/10.3390/app10020606
Chicago/Turabian StyleMahdi, Osama A., Eric Pardede, Nawfal Ali, and Jinli Cao. 2020. "Fast Reaction to Sudden Concept Drift in the Absence of Class Labels" Applied Sciences 10, no. 2: 606. https://doi.org/10.3390/app10020606
APA StyleMahdi, O. A., Pardede, E., Ali, N., & Cao, J. (2020). Fast Reaction to Sudden Concept Drift in the Absence of Class Labels. Applied Sciences, 10(2), 606. https://doi.org/10.3390/app10020606