Thermogram Breast Cancer Detection: A Comparative Study of Two Machine Learning Techniques



Abstract
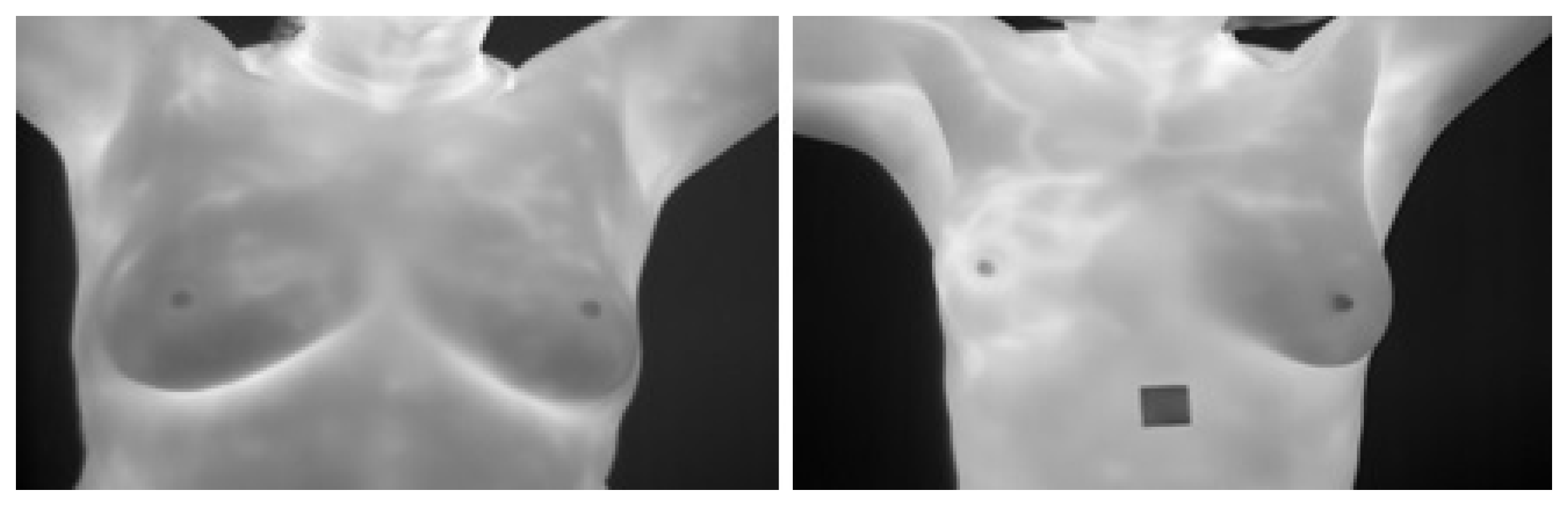
:1. Introduction
2. Related Work
3. Background
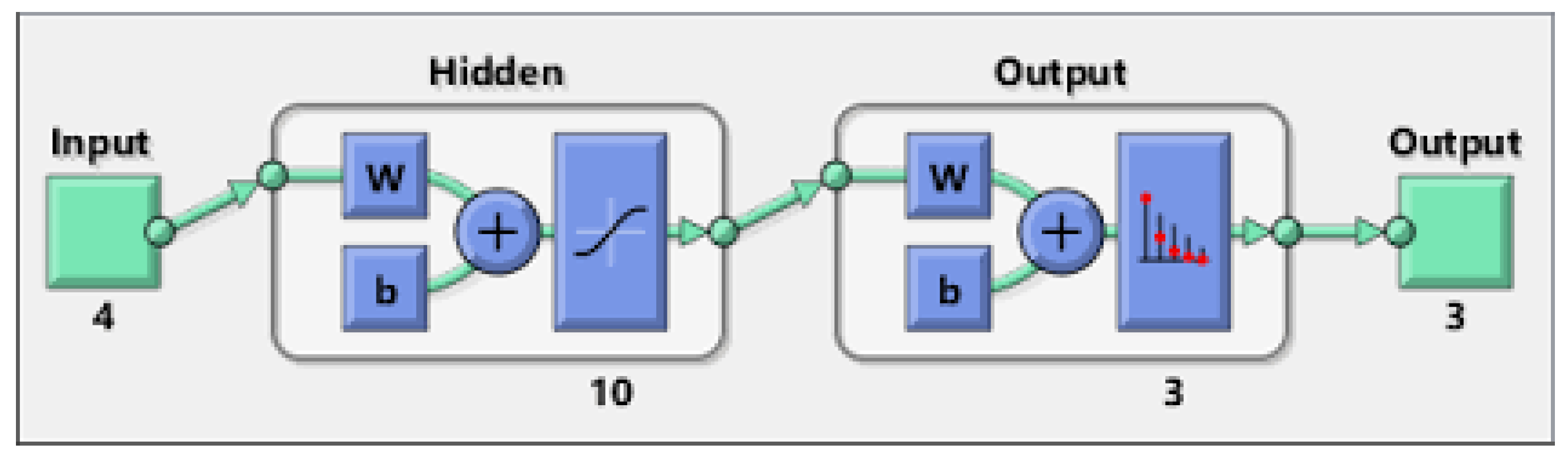
3.1. Multilayer Perceptron (MLP) Classifier
3.2. Extreme Learning Machine (ELM) Classifier
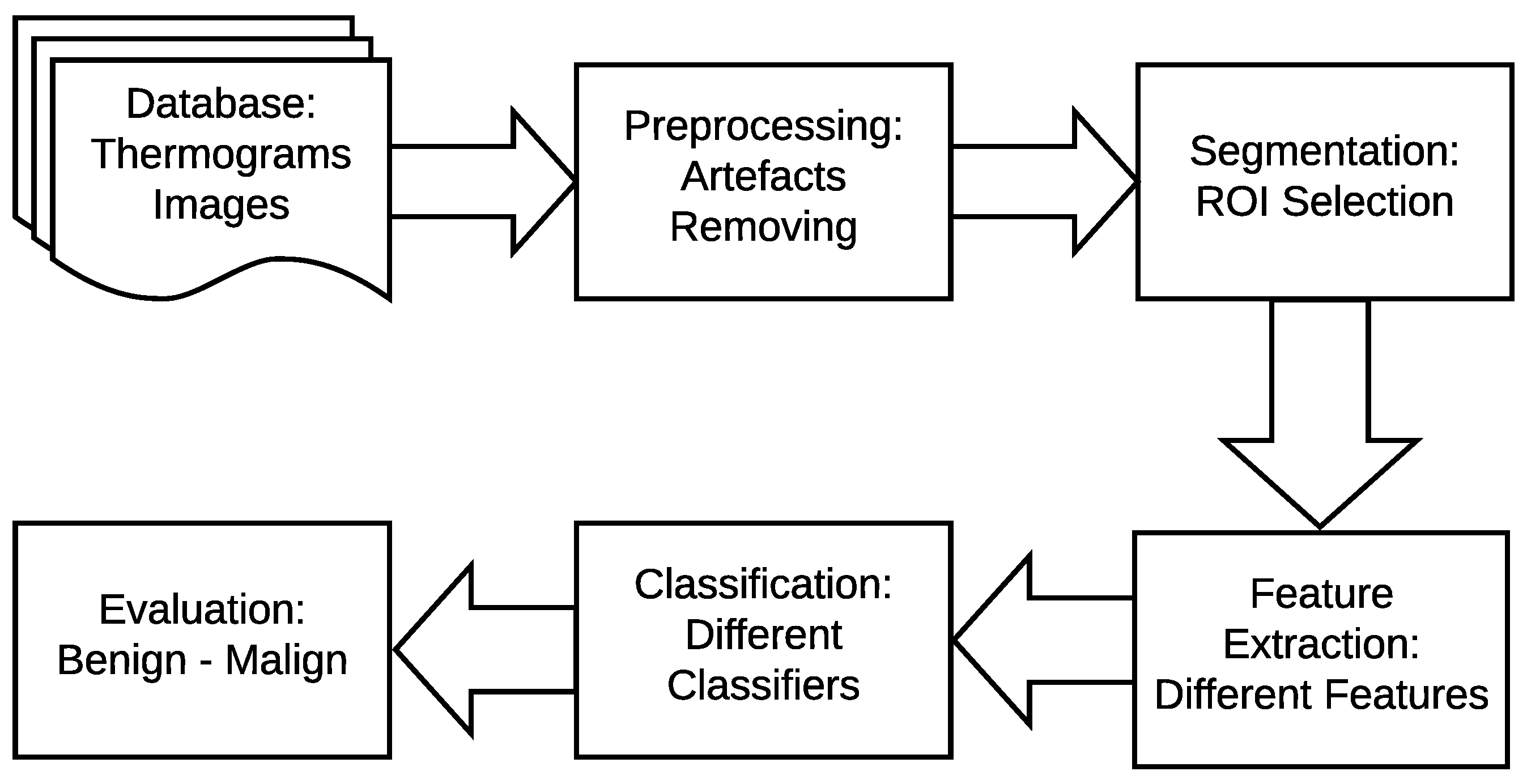
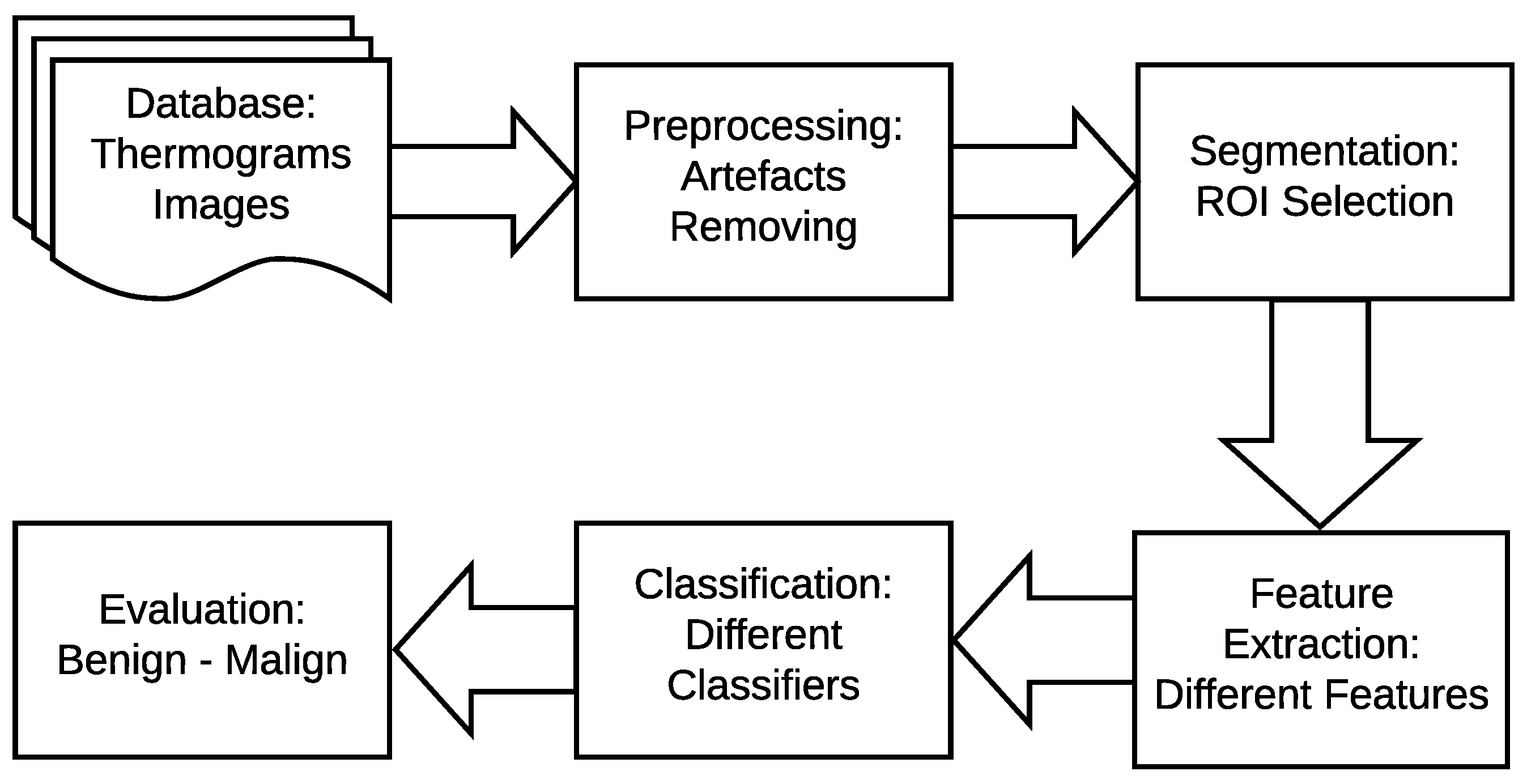
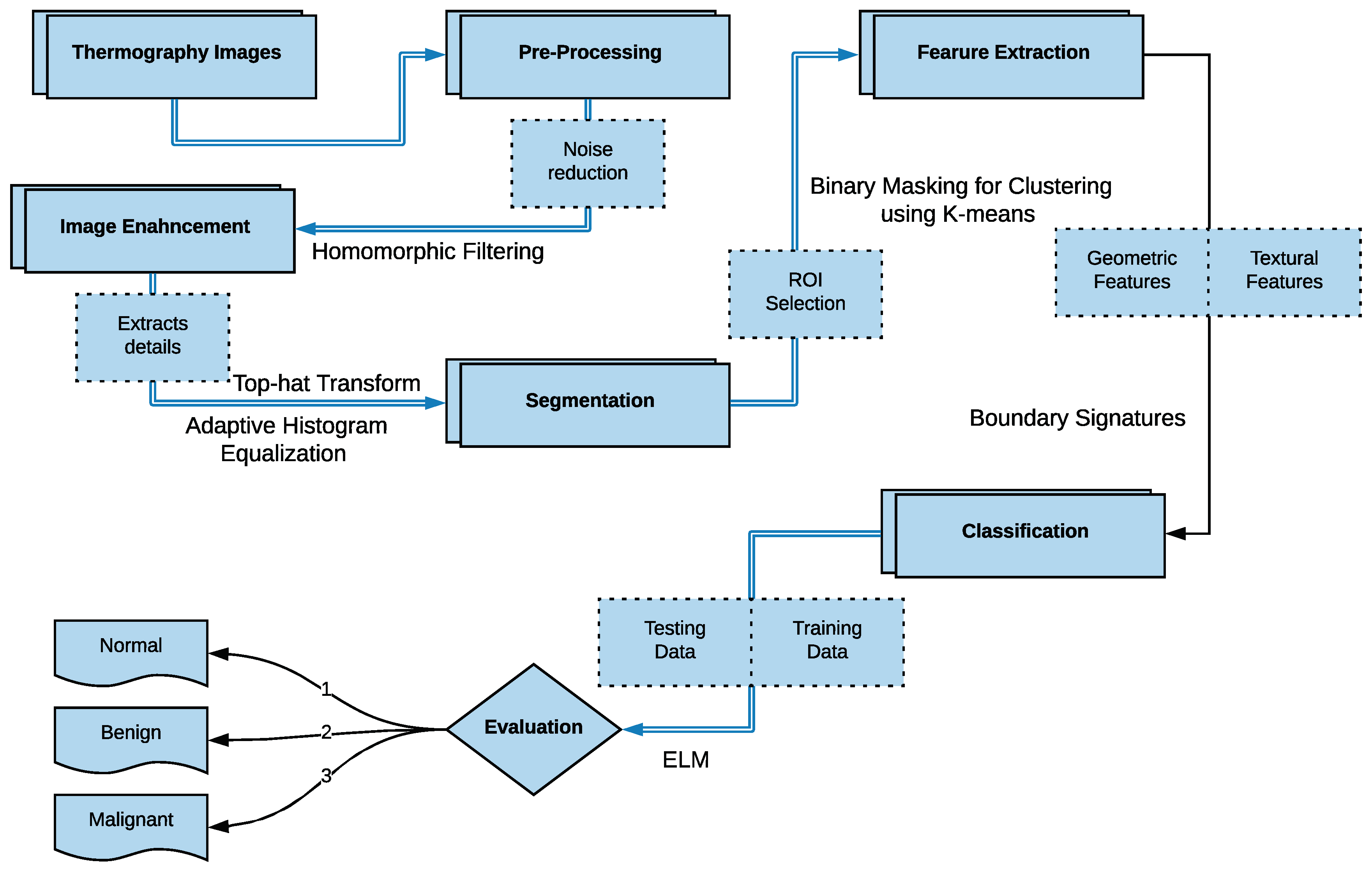
4. The Proposed Method
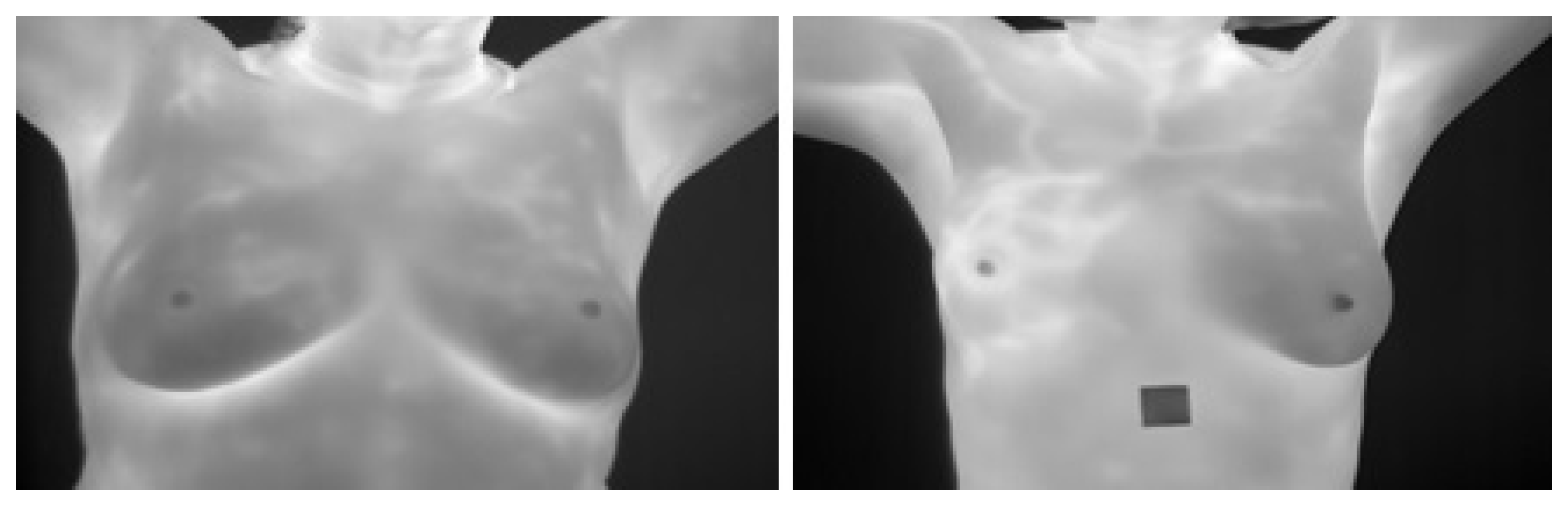
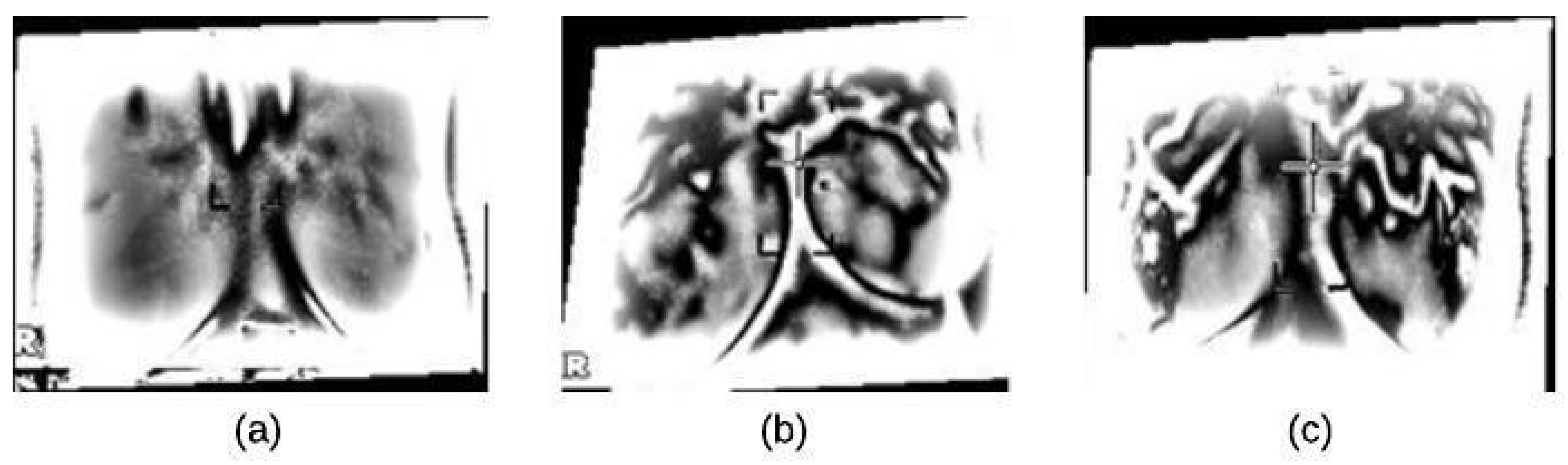
- In the image pre-processing stage: Noise reduction was achieved using the combination of homomorphic filtering and spatial domain morphology and image enhancement was accomplished using top-hat transform and adaptive histogram equalization.
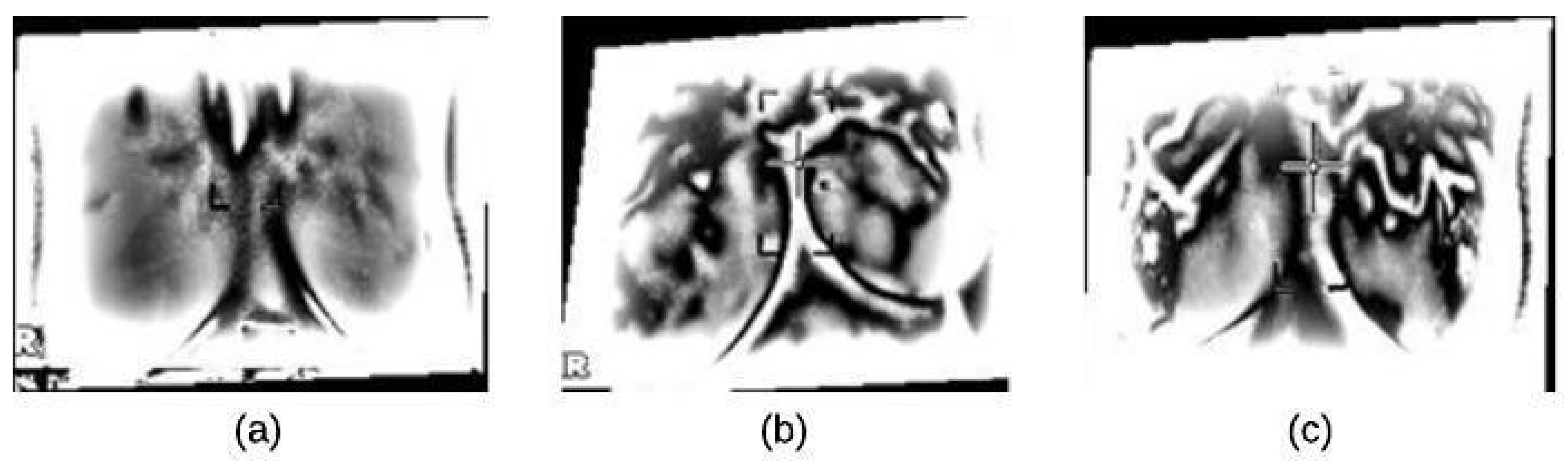
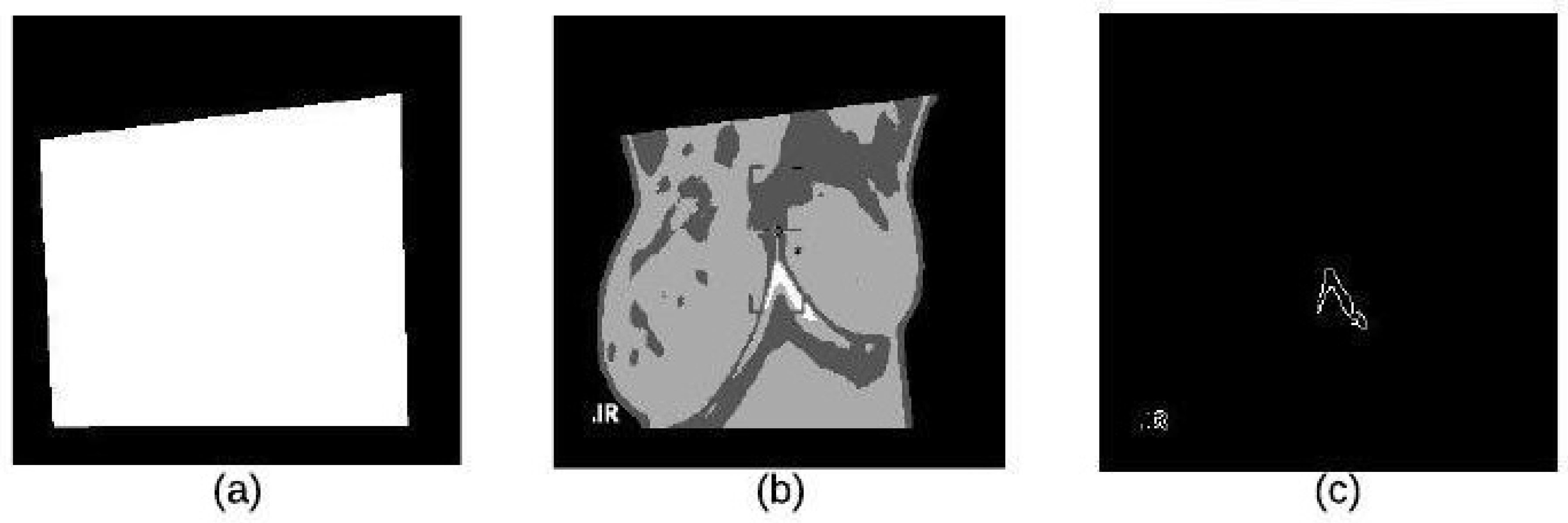
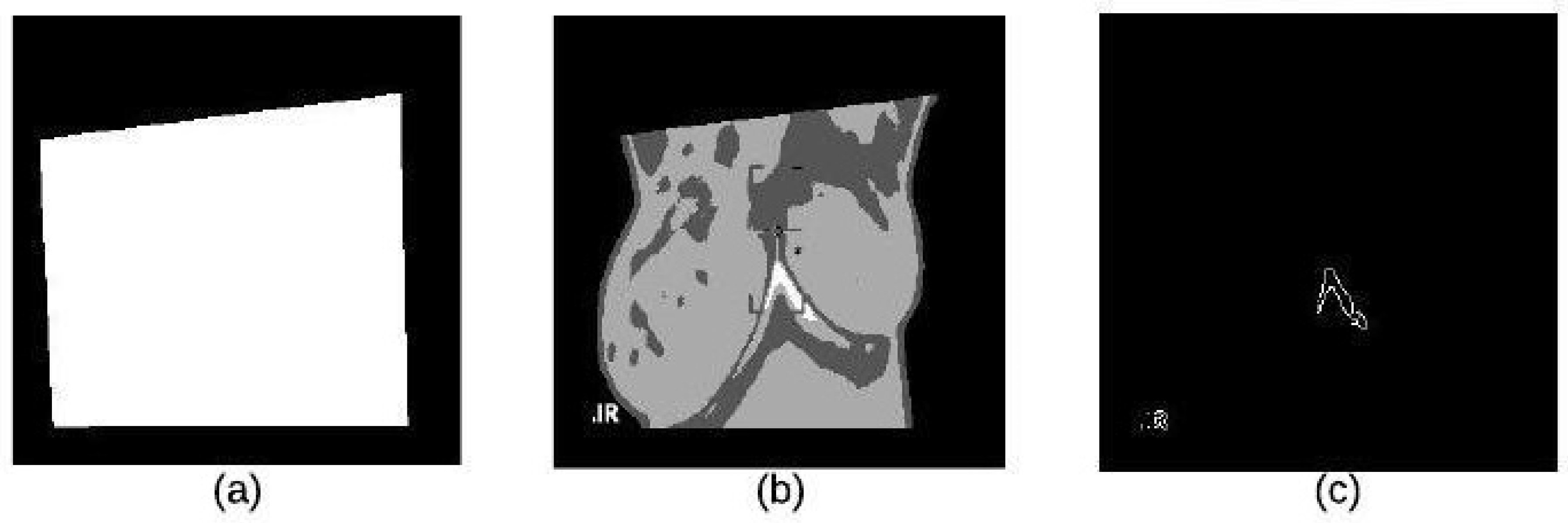
- In the segmentation stage, the tumor was segmented using binary masking and K-means clustering to produce the boundary image.
- In the feature extraction stage, two types of features were extracted: geometrical and textural features.
- In the tumor detection stage, MLP and ELM classifiers were used and compared.
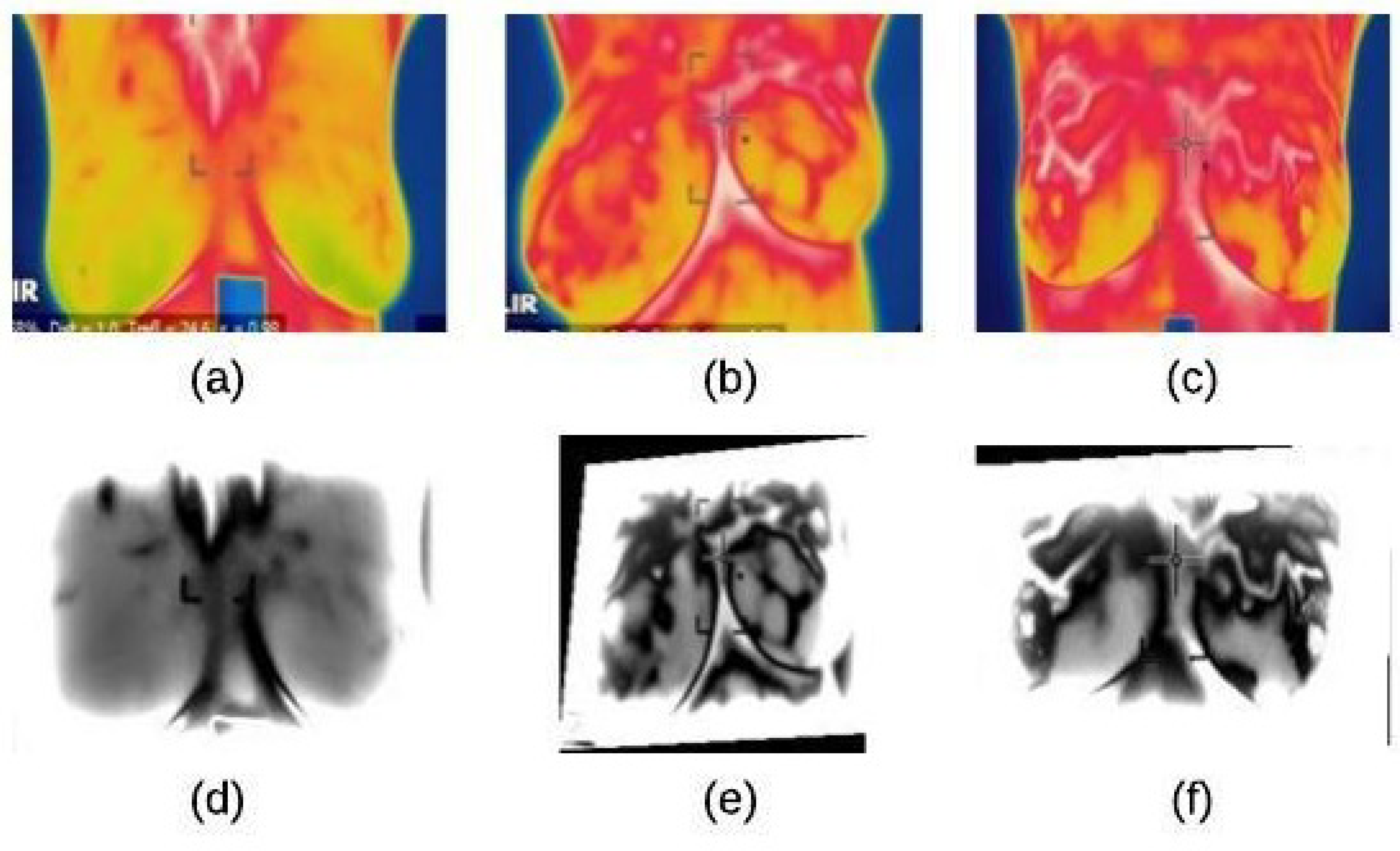
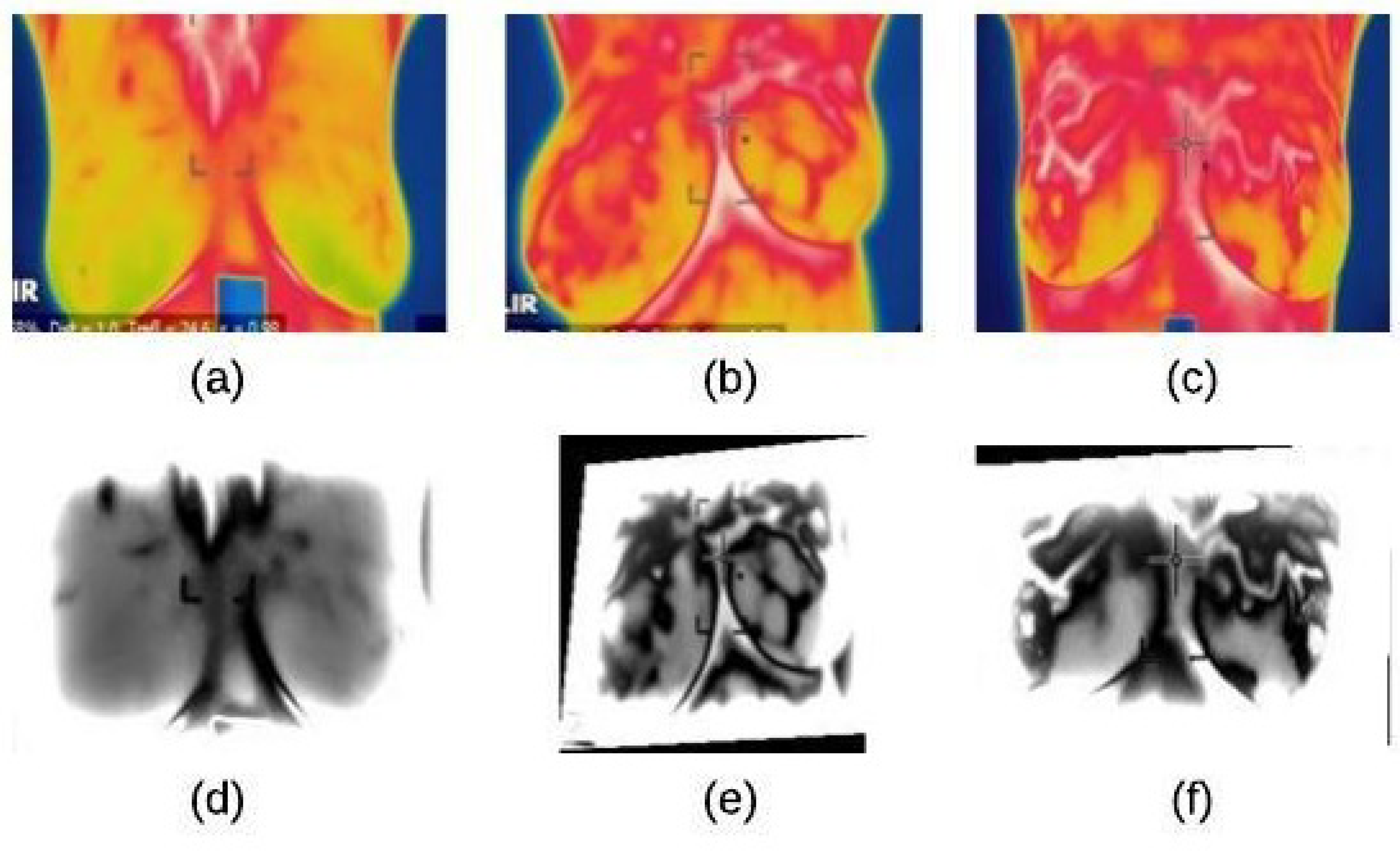
4.1. Image Preprocessing Stage
4.1.1. Noise Reduction
| Algorithm 1 A homomorphic filtering technique |
|
4.1.2. Image Enhancement
| Algorithm 2 The enhancement process |
|
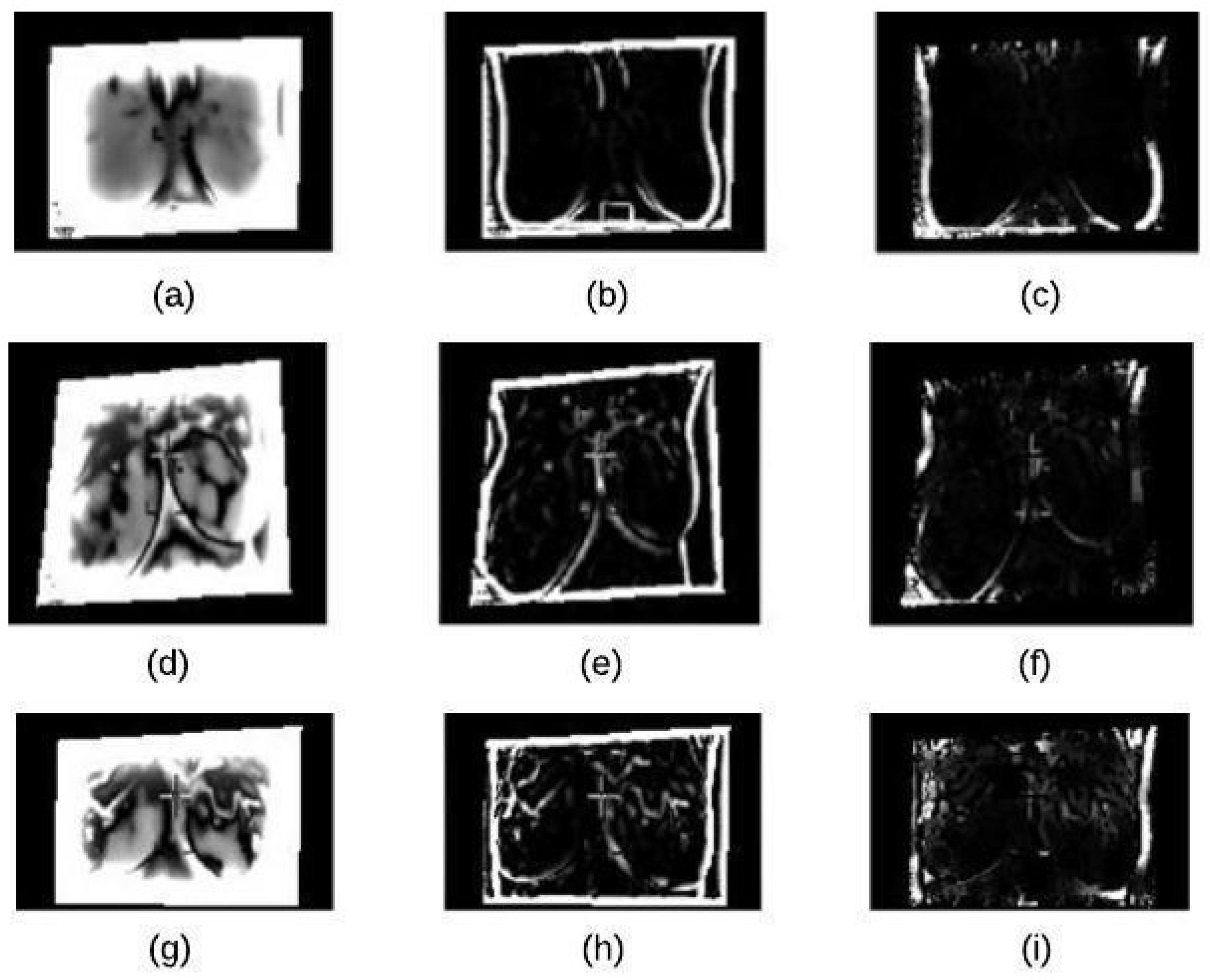
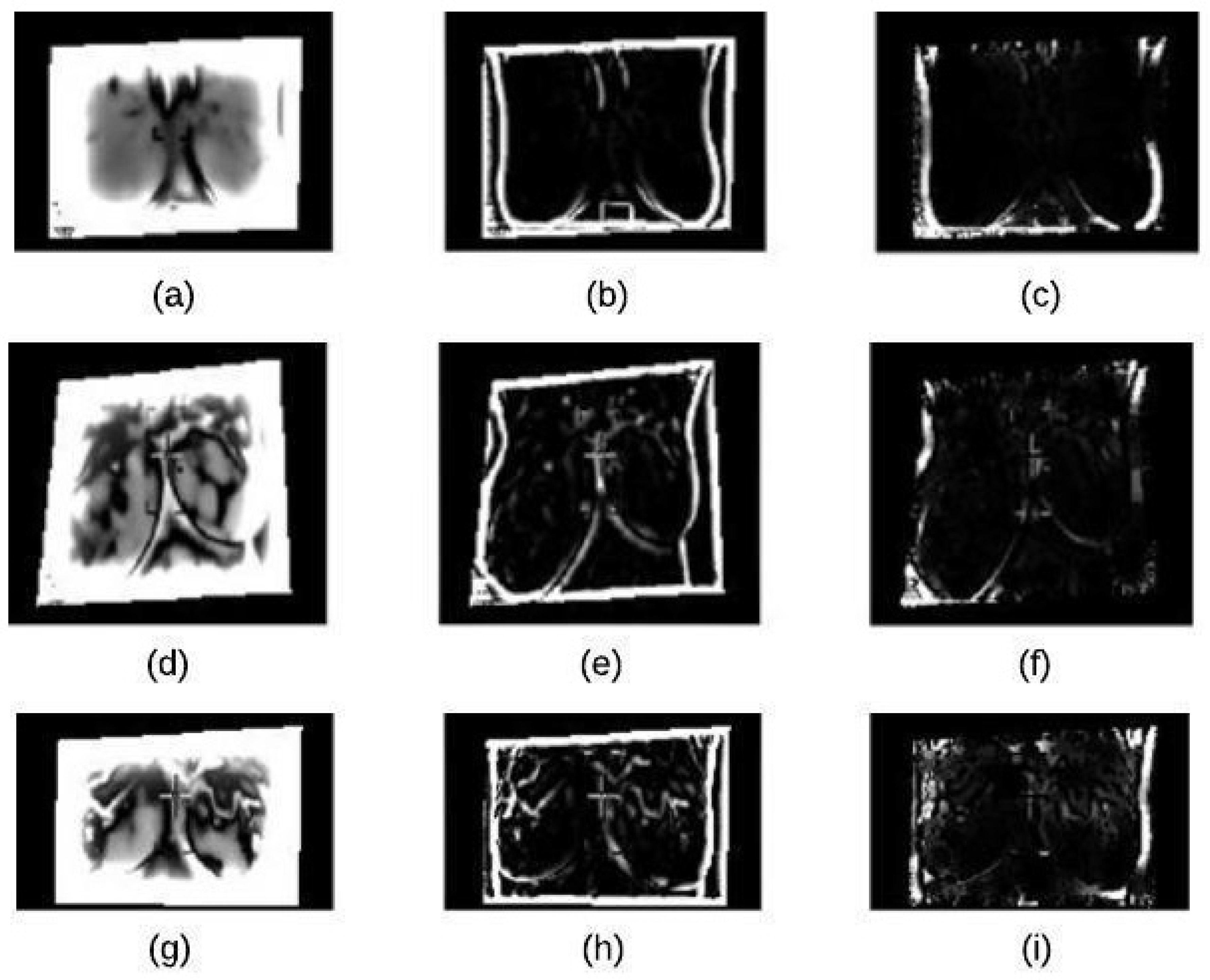
4.2. Segmentation Stage
4.2.1. K-Means Clustering
4.2.2. Binary Morphology
4.2.3. Morphological Gradient
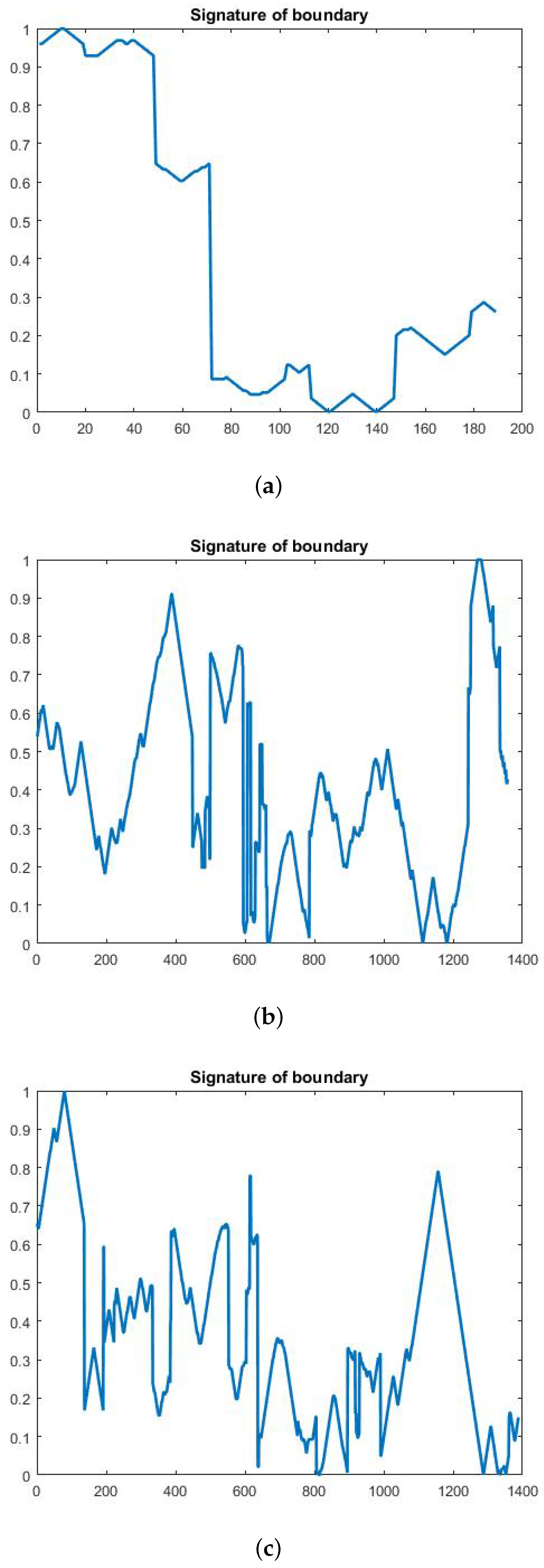
4.3. Feature Extraction Stage
4.3.1. Geometrical Feature Extraction
- Area: The total of all pixels (p) of the segmented nucleus (n).
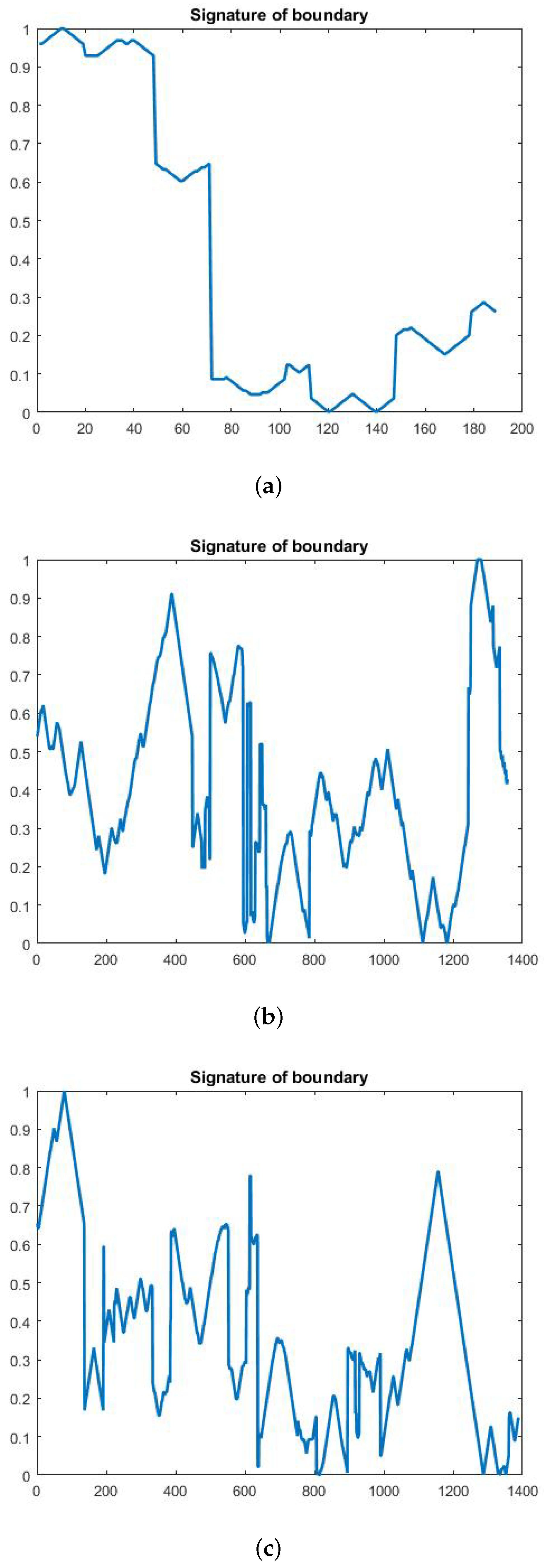
- Perimeter: The nuclear envelope length is computed as a polygonal length approximation of the boundary (B).
- P/A ratio: It is measured the degree to which the perimeter of the boundary (B) is exposed area ratio of the boundary (B).
- Major Axis Length (in pixels): It is computed as the length of the major axis of an ellipse having the same second moments as the region.
- Minor Axis Length (in pixels): It is computed as the length of the minor axis of an ellipse having the same second moments as the region.
- LS Ratio: It is computed as the length ratio of the major axis length to the minor axis length of the equivalent ellipse of the lesion.
- Elliptical normalized circumference(ENC): ENC features are computed in terms of the lesion circumference ratio and its equivalent ellipse.
4.3.2. Textural Feature Extraction
- Entropy: It is a statistical measure of randomness of an intensity image. It is used to represent the texture of a given image. Mathematically, an entropy of an image is computed as, , where h denotes the histogram counts for the intensity image [13].
- Edge-Based Contrast Measure (EBCM): This is a feature which depends on the human perception and is very sensitive to edges. Mathematically, EBCM feature of an image, I, is calculated as given in the following equation:is a contrast value for an image pixel located at and is calculated aswhere the mean gray level is:where is set of all neighboring pixels with the center pixel at and is the edge value which is the image gradient magnitude. For EBCM, if EBCM value of output image is greater than the original image, it indicates the better contrast of output image.
- Standard Deviation: The standard deviation of gray-scale values, is the estimate of the mean square deviation of the grey pixel value from its mean volume. It describes dispersion within a local region. It is calculated using the formula
4.4. Classification Stage
5. Experiments
5.1. Dataset Description and Experiments Setup
5.2. Experiments Scenarios
5.2.1. Scenario 1: MLP Activation Functions
- The MLP number of layers was one for input, one hidden and one for the output.
- These layers were constant for each MLP activation function.
- The set of features were fixed for each MLP activation function.
- This experiment for each MLP activation function above.
5.2.2. Scenario 2: Training Time of MLP Activation Functions
- The MLP number of layers was one for input, one hidden and one for the output)
- These layers were constant for each MLP activation function.
- The set of features were fixed for each MLP activation function.
- This experiment for each MLP activation function above
- The CPU time consumed was computed o get the final classification accuracy each MLP activation function.
5.2.3. Scenario 3: Numbers of Layers and Neurons per Each Hidden Layer of the Best MLP Activation Function
- We have tested the following parameters for the used neural network:
- (a)
- 3 hidden layers and a number of neurons 4,5 and 10 respectively,
- (b)
- 5 hidden layers and a number of neurons 4, 5 and 10 respectively and
- (c)
- 7 hidden layers and a number of neurons 4, 5 and 10 respectively.
- For each of the above setup, a set of features were fixed for each experiment with the same chosen MLP activation function.
- the CPU time consumed was computed to get the final classification accuracy for each (1.a, 1.b, 1.c)
5.2.4. Scenario 4: Learning Rate of the Best MLP Activation Function
- We have tested the following parameters for the used neural network:
- (a)
- 3 hidden layers using number of neurons of 4, 5 and 10 respectively.
- (b)
- 5 hidden layers using number of neurons of 4, 5 and 10 respectively.
- (c)
- 7 hidden layers using number of neurons of 4, 5 and 10 respectively.
- For each of the above setup, learning rate = 1, 3, 5, 7, 9 was tested and the obtained results were recorded.
- For each of the above setup, the set of features were fixed for each experiment with the same chosen MLP activation function.
- The CPU time consumed was computed to get the final classification accuracy for each value of set in Step 2.
5.2.5. Scenario 5: ELM Activation Functions
- Three layers of ELM were used: one for input, one hidden and one for the output.
- These layers were constant for each ELM activation function.
- The set of features were fixed for each ELM activation function.
- This experiment was repeated for each ELM activation function above.
5.2.6. Scenario 6: Training Time of ELM Activation Functions
- Three layers of ELM were used: one for input, one hidden and one for the output)
- These layers were constant for each ELM activation function.
- The set of features were fixed for each ELM activation function.
- This experiment was repeated for each ELM activation function above
- The CPU time consumed was computed to get the final classification accuracy each ELM activation function.
6. Results and Discussions
6.1. The Results of Scenario 1
6.2. The Results of Scenario 2
6.3. The Results of Scenario 3
6.4. The Results of Scenario 4
6.5. The Results of Scenario 5
6.6. The Results of Scenario 6
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gaber, T.; Ismail, G.; Anter, A.; Soliman, M.; Ali, M.; Semary, N.; Hassanien, A.E.; Snasel, V. Thermogram breast cancer prediction approach based on Neutrosophic sets and fuzzy c-means algorithm. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 4254–4257. [Google Scholar]
- Sickles, E.A. Mammographic Features of early Breast Cancer. Am. J. Roentgenol. 1984, 143, 461–464. [Google Scholar] [CrossRef] [PubMed]
- Nover, A.B.; Jagtap, S.; Anjum, W.; Yegingil, H.; Shih, W.Y.; Shih, W.H.; Brooks, A.D. Modern Breast Cancer Detection: A technological Review. J. Biomed. Imaging 2009. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Chen, Y.P.P. Image Based Computer Aided Diagnosis System for Cancer Detection. Expert Syst. Appl. 2015, 42, 5356–5365. [Google Scholar] [CrossRef]
- Etehad Tavakol, M.; Chandran, V.; Ng EKafieh, R. Breast Cancer Detection from Thermal Images Using Bispectral Invariant Features. Int. J. Therm. Sci. 2013, 69, 21–36. [Google Scholar] [CrossRef]
- Tan, T.Z.; Quek, C.; Ng, G.; Ng, E. A novel Cognitive Interpretation of Breast Cancer Thermography with Complementary Learning Fuzzy Neural Memory Structure. Expert Syst. Appl. 2007, 33, 652–666. [Google Scholar] [CrossRef]
- Arakeri, M.P.; Reddy, G.R. Computer-Aided Diagnosis System for Tissue Characterization of Brain Tumor on Magnetic Resonance images. SIViP 2015, 9, 409–425. [Google Scholar] [CrossRef]
- Etehadtavakol, M.; Ng, E.Y. Breast Thermography as A potential Non-Contact Method in the Early Detection of Cancer: A review. J. Mech. Med. Biol. 2013, 13, 1330001. [Google Scholar] [CrossRef]
- Sathish, D.; Kamath, S.; Rajagopal, K.V.; Prasad, K. Medical Imaging Techniques and Computer Aided Diagnosis Approaches for the Detection of Breast Cancer with an Emphasis on Thermography A review. Int. J. Med. Eng. Inform. 2016, 8, 275–299. [Google Scholar] [CrossRef]
- Ali, M.A.; Sayed, G.I.; Gaber, T.; Hassanien, A.E.; Snasel, V.; Silva, L.F. Detection of breast abnormalities of thermograms based on a new segmentation method. In Proceedings of the 2015 Federated Conference on Computer Science and Information Systems (FedCSIS), Lodz, Poland, 13–16 September 2015; pp. 255–261. [Google Scholar]
- Lipari, C.A.; Head, J. Advanced Infrared Image Processing for Breast Cancer Risk Assessment. In Proceedings of the 19th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 30 October–2 November 1997; Volume 2, pp. 673–676. [Google Scholar]
- Moghbel, M.; Mashohor, S. A review of Computer Assisted Detection/Diagnosis (CAD) in Breast Thermography for Breast Cancer Detection. Artif. Intell. Rev. 2013, 39, 305–313. [Google Scholar] [CrossRef]
- Lee, M.Y.; Yang, C.S. Entropy-based feature extraction and decision tree induction for breast cancer diagnosis with standardized thermograph images. Comput. Methods Programs Biomed. 2010, 100, 269. [Google Scholar] [CrossRef] [PubMed]
- Kennedy, D.A.; Lee, T.; Seely, D. A comparative review of thermography as a breast cancer screening technique. Integr. Cancer Ther. 2009, 8, 9–16. [Google Scholar] [CrossRef] [PubMed]
- Pramanik, S.; Bhattacharjee, D.; Nasipuri, M. Texture analysis of breast thermogram for differentiation of malignant and benign breast. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 8–14. [Google Scholar]
- Okuniewski, R.; Nowak, R.M.; Cichosz, P.; Jagodziński, D.; Matysiewicz, M.; Neumann, Ł.; Oleszkiewicz, W. Contour classification in thermographic images for detection of breast cancer. Proc. SPIE 2016. [Google Scholar] [CrossRef]
- Acharya, U.R.; Ng, E.Y.K.; Tan, J.-H.; Sree, S.V. Thermography based breast cancer detection using texture features and support vector machine. J. Med. Syst. 2010, 36, 1503–1510. [Google Scholar] [CrossRef] [PubMed]
- Gogoi, U.R.; Bhowmik, M.K.; Bhattacharjee, D.; Ghosh, A.K. Singular value based characterization and analysis of thermal patches for early breast abnormality detection. Australas. Phys. Eng. Sci. Med. 2018, 41, 861–879. [Google Scholar] [CrossRef] [PubMed]
- Sathish, D.; Kamath, S. Detection of Breast Thermograms using Ensemble Classifiers. J. Telecommun. Electron. Comput. Eng. (JTEC) 2018, 10, 35–39. [Google Scholar]
- Jadoon, M.; Zhang, Q.; Haq, I.U.; Jadoon, A.; Basit, A.; Butt, S. Classification of Mammograms for Breast Cancer Detection Based on Curvelet Transform and Multi-Layer Perceptron. Biomed. Res. 2017, 28, 4311–4315. [Google Scholar]
- Wang, Z.; Yu, G.; Kang, Y.; Zhao, Y.; Qu, Q. Breast Tumor Detection in Digital Mammography Based on Extreme Learning Machine. Neuro Comput. 2014, 128, 175–184. [Google Scholar] [CrossRef]
- Paramkusham, S.; Rao, K.M.; Rao, B.P. Automatic Detection of Breast Lesion Contour and Analysis using Fractals through Spectral Methods. In Proceedings of the International Conference on Advances in Computer Science, AETACS, National Capital Region, India, 13–14 December 2013. [Google Scholar]
- Mencattini, A.; Salmeri, M.; Casti, P.; Raguso, G.; L’Abbate, S.; Chieppa, L.; Ancona, A.; Mangieri, F.; Pepe, M.L. Automatic breast masses boundary extraction in digital mammography using spatial fuzzy c-means clustering and active contour models. In Proceedings of the IEEE International Workshop on Medical Measurements and Applications Proceedings (MeMeA), Bari, Italy, 30–31 May 2011; pp. 632–637. [Google Scholar]
- Bai, X.; Wang, K.; Wang, H. Research on the Classification of Wood Texture Based on Gray Kevel Co-occurrence Matrix. J. Harbin Inst. Technol. 2005, 37, 1667–1670. [Google Scholar]
- Silva, L.F.; Saade, D.C.M.; Sequeiros, G.O.; Silva, A.C.; Paiva, A.C.; Bravo, R.S.; Conci, A. A new database for breast research with infrared image. J. Med. Imaging Health Inform. 2014, 4, 92–100. [Google Scholar] [CrossRef]
- Tello-Mijares, S.; Woo, F.; Flores, F. Breast Cancer Identification via Thermography Image Segmentation with a Gradient Vector Flow and a Convolutional Neural Network. J. Healthc. Eng. 2019. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activation Functions | Accuracy |
|---|---|
| tansig | 0.7424 |
| logistic | 0.6996 |
| poslin | 0.615 |
| satlins | 0.6076 |
| satlin | 0.6142 |
| purlin | 0.6466 |
| Activation Functions | Training Time |
|---|---|
| tansig | 3.086165 |
| logistic | 3.473274 |
| poslin | 3.182216 |
| satlins | 3.047807 |
| satlin | 2.957490 |
| purlin | 2.890241 |
| No. of Layers | Neurons = 4 | Neurons = 10 | Neurons = 5 | |||
|---|---|---|---|---|---|---|
| Accuracy | Time | Accuracy | Time | Accuracy | Time | |
| 3 | 0.6892 | 3.29759 s | 0.7834 | 5.615519 s | 0.7010 | 3.416063 s |
| 5 | 0.6684 | 4.014458 s | 0.8042 | 10.3971355 s | 0.6788 | 4.145014 s |
| 7 | 0.6958 | 3.838878 s | 0.8220 | 15.811615 s | 0.7025 | 5.98080 s |
| Learning Rate | Accuracy | Training Time |
|---|---|---|
| 1 | 0.8004 | 17.687415 s |
| 3 | 0.7730 | 13.623254 s |
| 5 | 0.7886 | 13.707897 s |
| 7 | 0.7834 | 13.646803 s |
| 9 | 0.7864 | 13.244280 s |
| Activation Function | Accuracy |
|---|---|
| sigmoid | 0.9887 |
| sin | 0.9901 |
| hardlim | 0.8902 |
| tribas | 0.9910 |
| radbas | 0.9889 |
| Activation Function | Training Time |
|---|---|
| sigmoid | 0.0469 |
| sin | 0.0035 |
| hardlim | 0.0625 |
| tribas | 0.0015 |
| radbas | 0.0050 |
| Paper/Criteria | Dataset Size | Public/Private Dataset | Classifiers | Accuracy | Specificity | Sensitivity |
|---|---|---|---|---|---|---|
| A. Kennedy [2009] | − | Private | TH(1:5)scale | − | − | 95% |
| Pramanik [2016] | 40 malignant 60 benign | Public(DMR) | FANN | 90% | 85% | 95% |
| Rafal [2016] | 325 examin. | Private | Naive Bayes Decision Tree | − | − | − |
| SVM R. Forrest | ||||||
| Acharya [2010] | 40 normal 60 malignant | Private | SVM | 88.10% | 90.48% | 85.71% |
| Gaber [2015] | 29 healthy 34 malignant | Public(benchmark) | SVM | 92.06% | − | − |
| Gogo [2018] | 70 abnormal 50 normal | Private | SVM(Poly) | 98% | 98% | 98% |
| Sathish [2018] | − | Public (DMR) | E. Bagg. Trees AdaBoost | 87% | 90.6% | 83% |
| Our Solution | 705 normal 200 benign 440 malignant | Public (DMR-IR) | MLP ELM | 80.04% 99.10% | 84% 98.05% | 61.6% 97.03% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
AlFayez, F.; El-Soud, M.W.A.; Gaber, T. Thermogram Breast Cancer Detection: A Comparative Study of Two Machine Learning Techniques. Appl. Sci. 2020, 10, 551. https://doi.org/10.3390/app10020551
AlFayez F, El-Soud MWA, Gaber T. Thermogram Breast Cancer Detection: A Comparative Study of Two Machine Learning Techniques. Applied Sciences. 2020; 10(2):551. https://doi.org/10.3390/app10020551
Chicago/Turabian StyleAlFayez, Fayez, Mohamed W. Abo El-Soud, and Tarek Gaber. 2020. "Thermogram Breast Cancer Detection: A Comparative Study of Two Machine Learning Techniques" Applied Sciences 10, no. 2: 551. https://doi.org/10.3390/app10020551
APA StyleAlFayez, F., El-Soud, M. W. A., & Gaber, T. (2020). Thermogram Breast Cancer Detection: A Comparative Study of Two Machine Learning Techniques. Applied Sciences, 10(2), 551. https://doi.org/10.3390/app10020551