Synthesis of Normal Heart Sounds Using Generative Adversarial Networks and Empirical Wavelet Transform


Abstract
1. Introduction
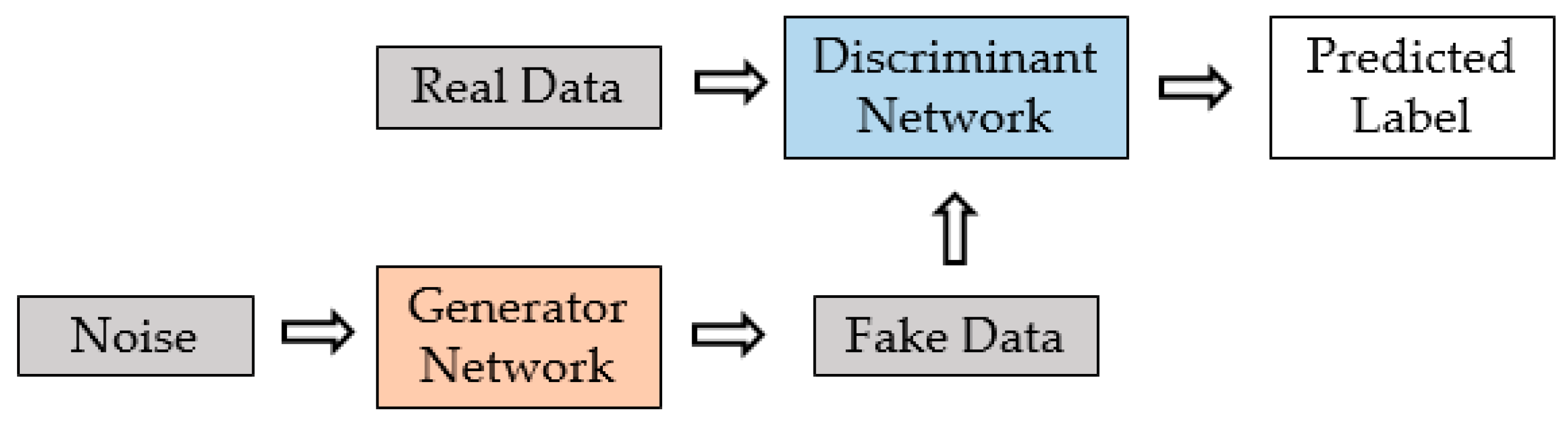
2. Generative Adversarial Networks (GANs)
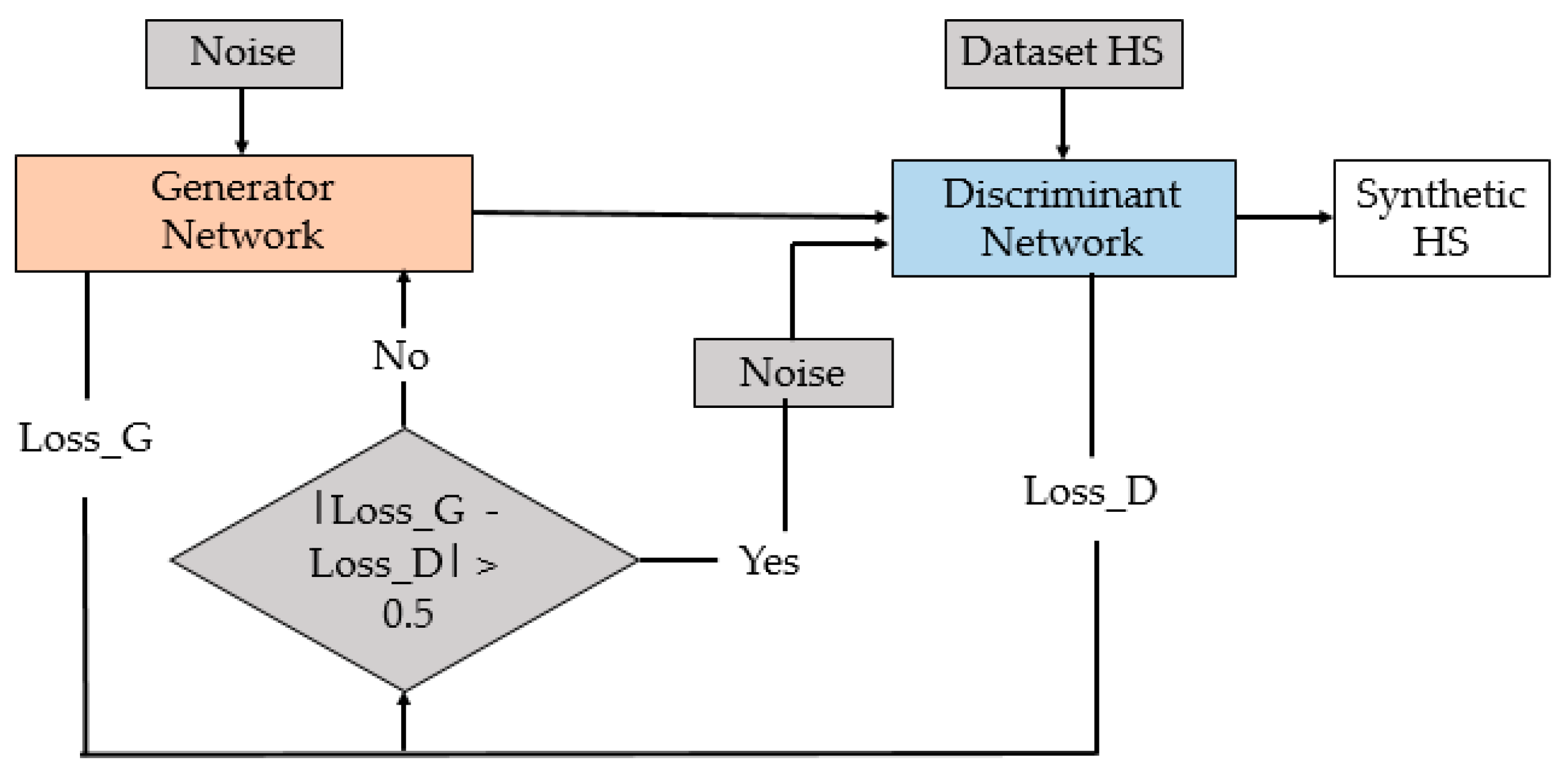
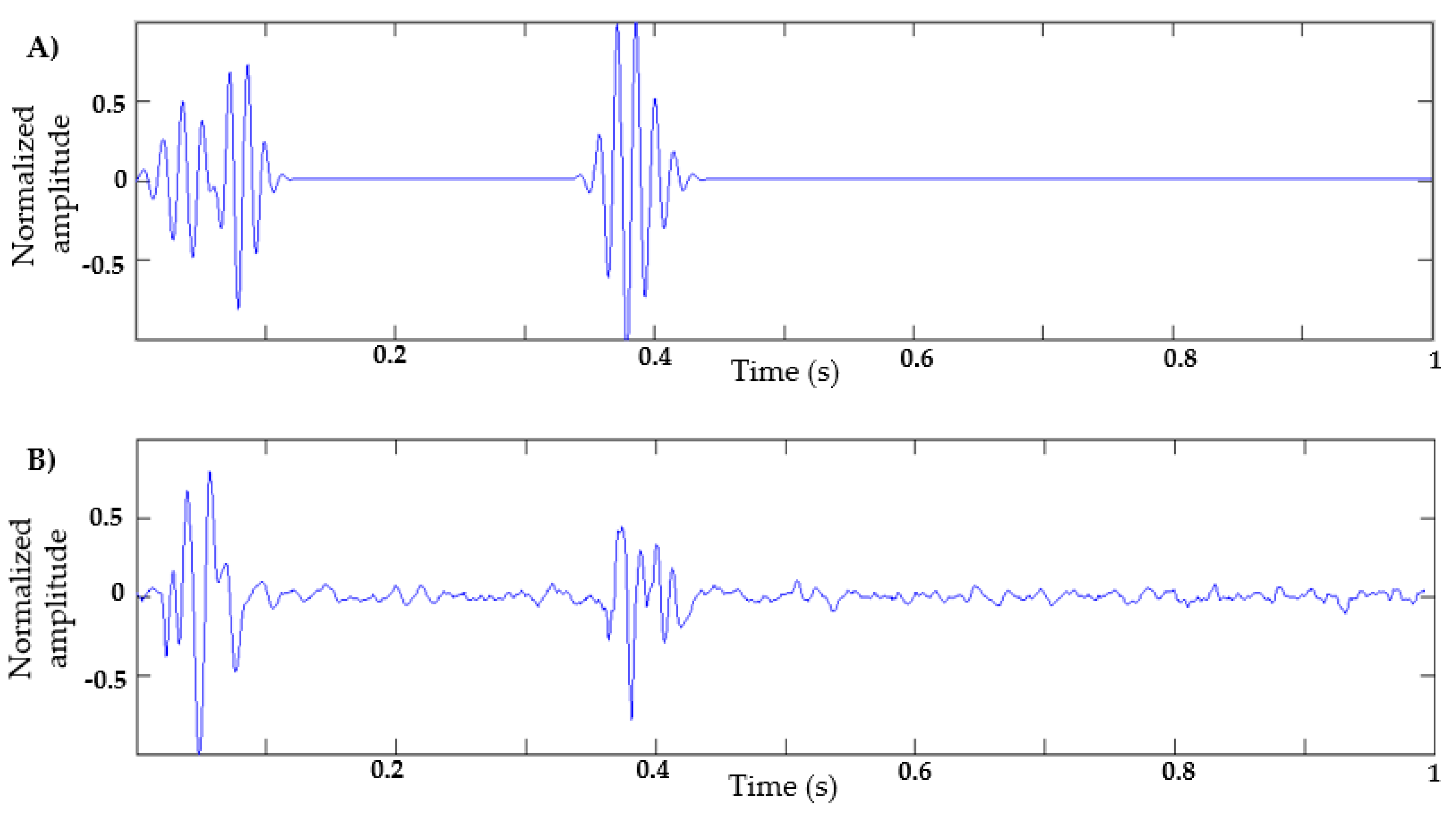
3. Proposed Method
- Noise: a gaussian noise with a size of 2000 samples is used as input to the generator. The mean and standard deviation of the noise’s distribution are 0 and 1, respectively;
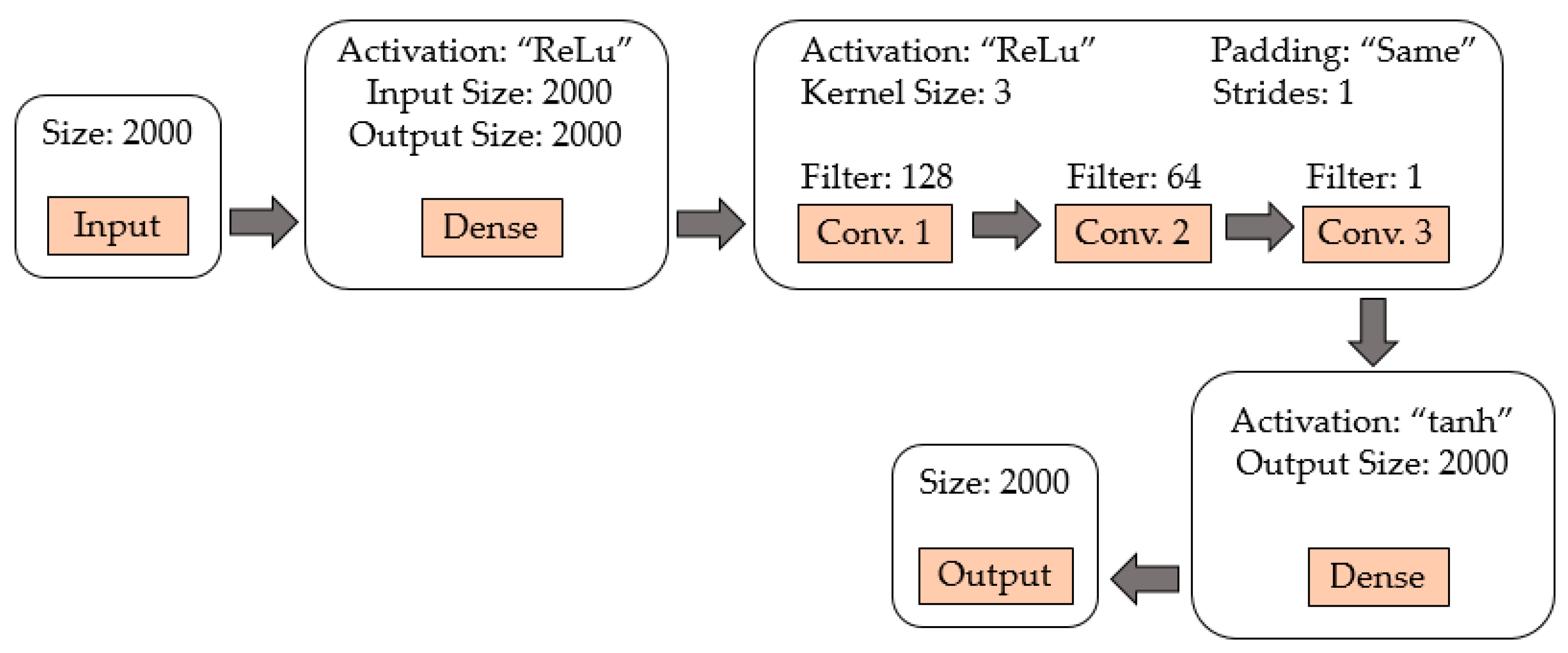
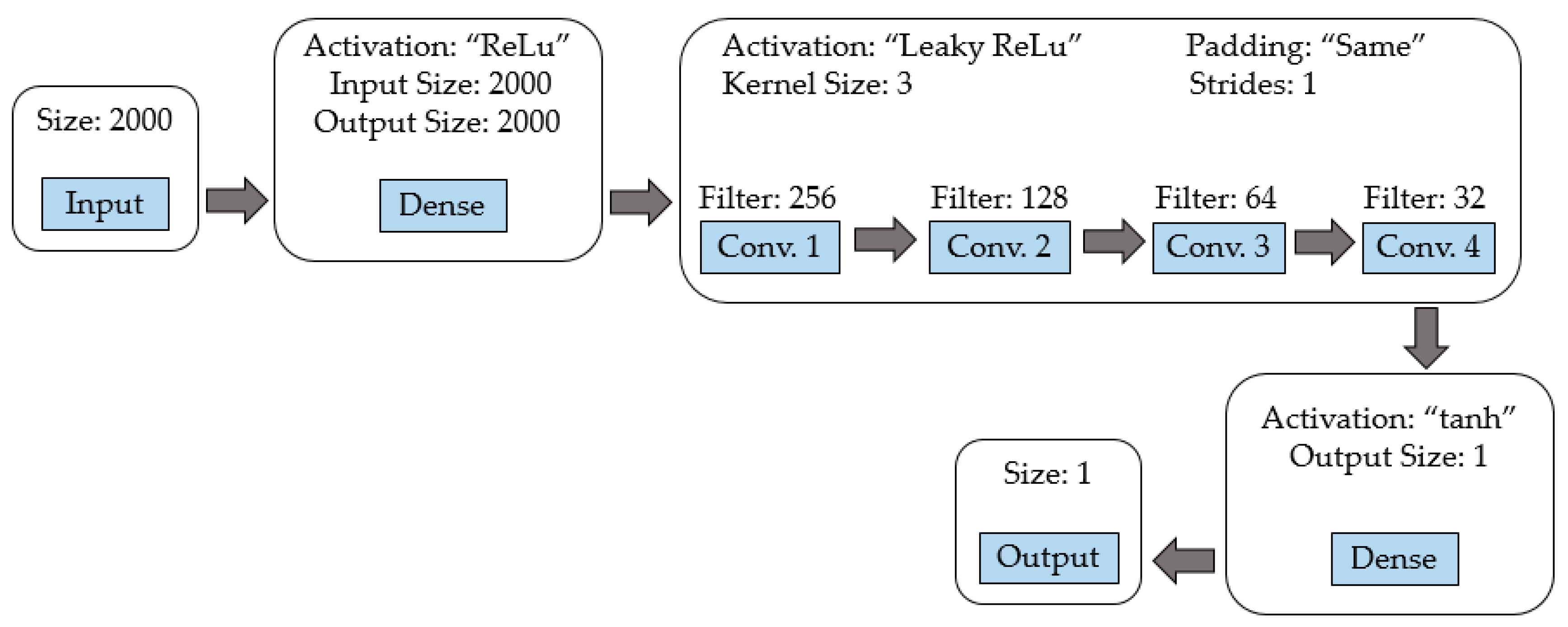
- Generator model: Figure 5 shows a diagram of the generating network, and the hyperparameters of each layer are specified. It begins with a dense layer with ReLu activation function, followed by three convolutional layers with filters of size 128, 64, and 1, respectively; each of these layers have ReLu activation function, a kernel size of 3, and a stride of 1. Finally, there is a dense layer with a tanh activation function. The padding parameter is set to “same” to maintain the same data dimension in the input and output of the convolutional layer;
- Discriminator model: Figure 6 shows a diagram of the discriminator network. It begins with a dense layer with ReLu activation function, followed by four convolutional layers with filters of size 256, 128, 64, and 32, respectively; each of these layers uses Leaky ReLu activation function, a kernel size of 3, and a stride of 1; additionally, between each convolution layer there is a dropout of 0.25. Finally, there is a dense layer with a tanh activation function. The padding parameter is set to “same” to maintain the same data dimension in the input and output of the convolutional layer;
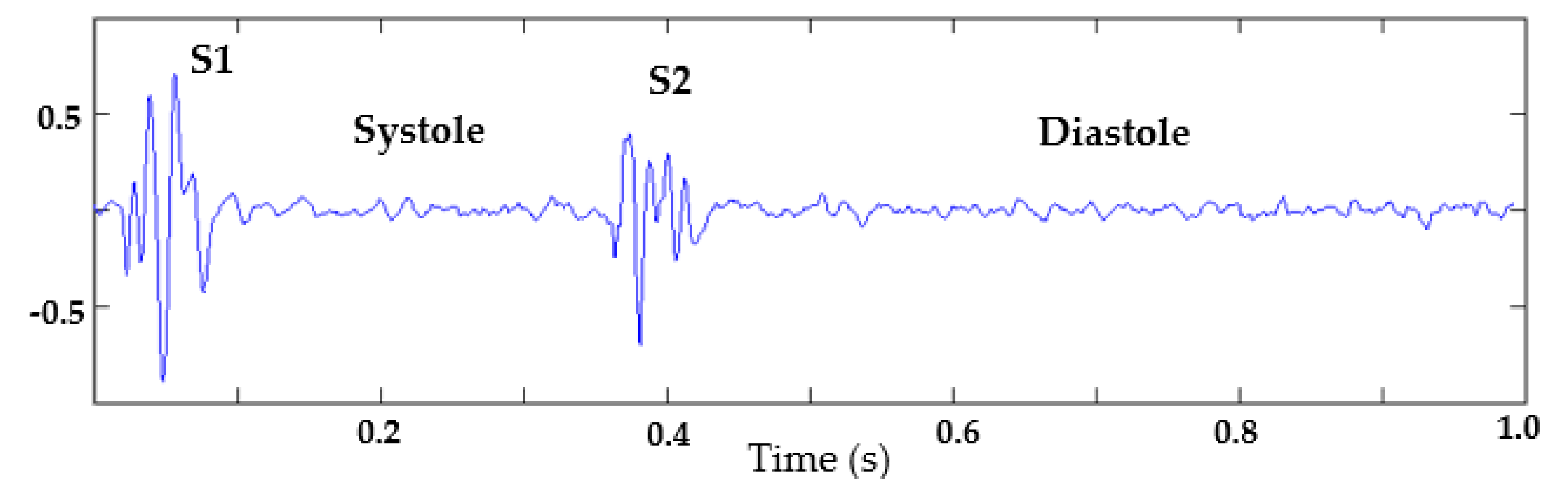
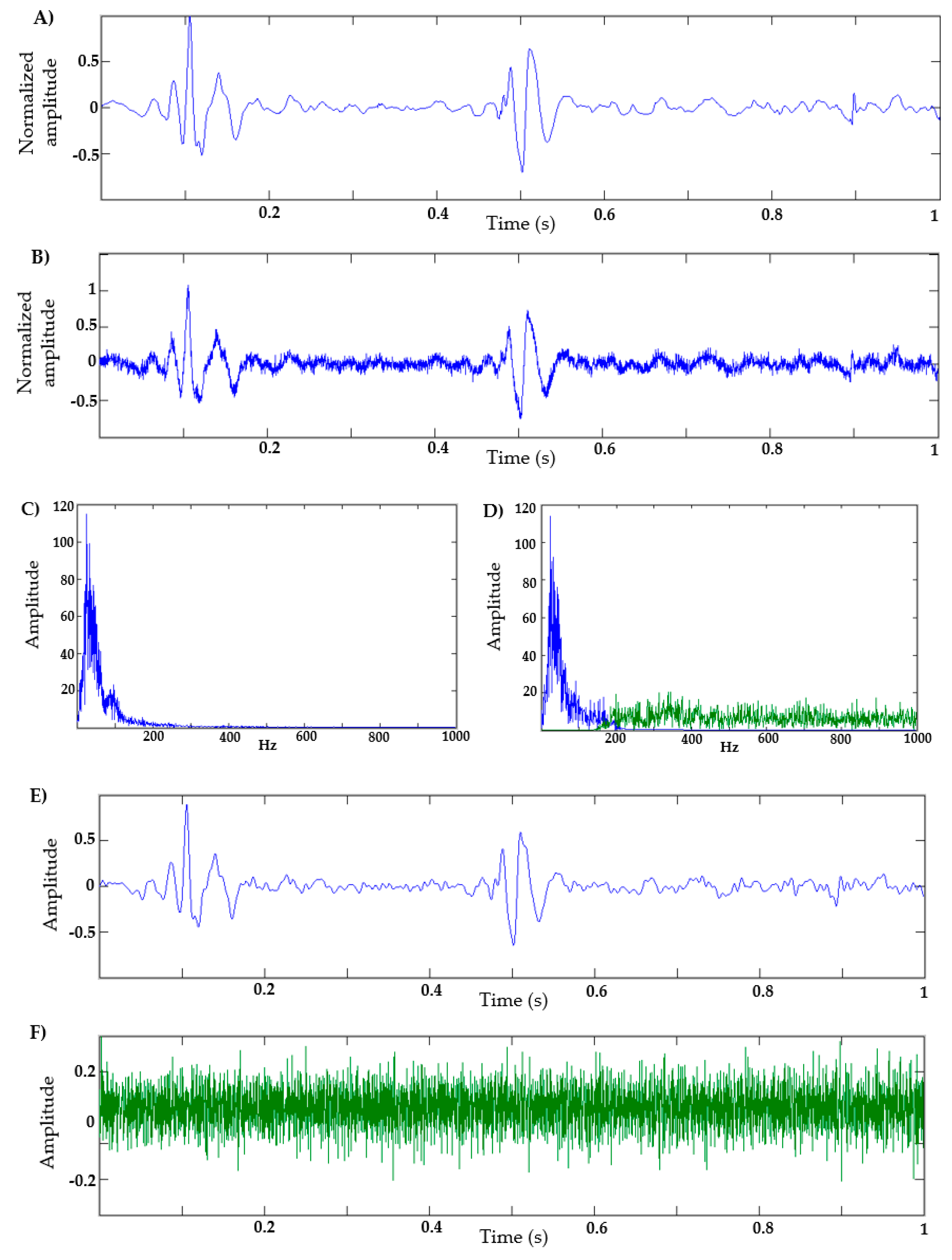
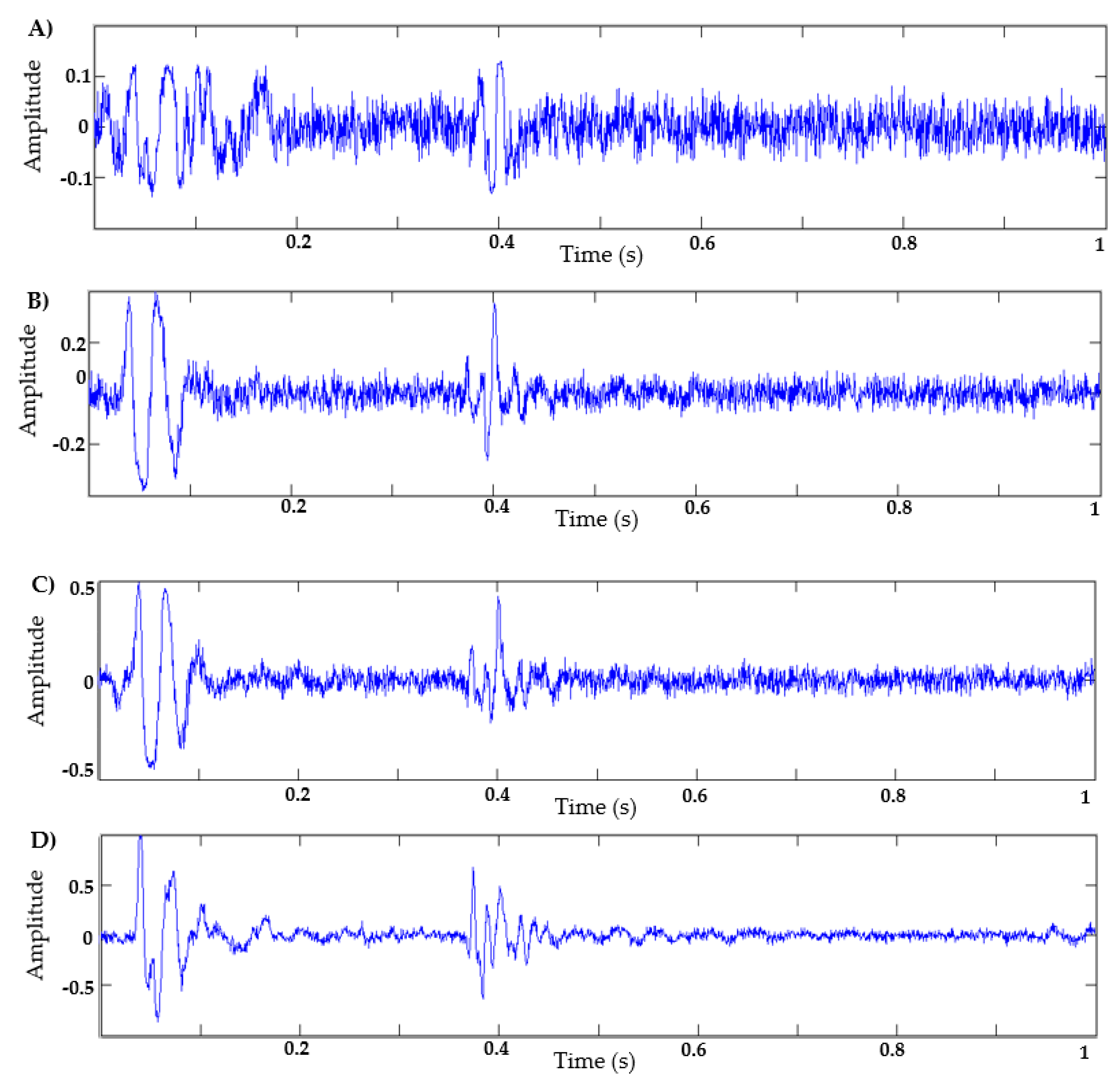
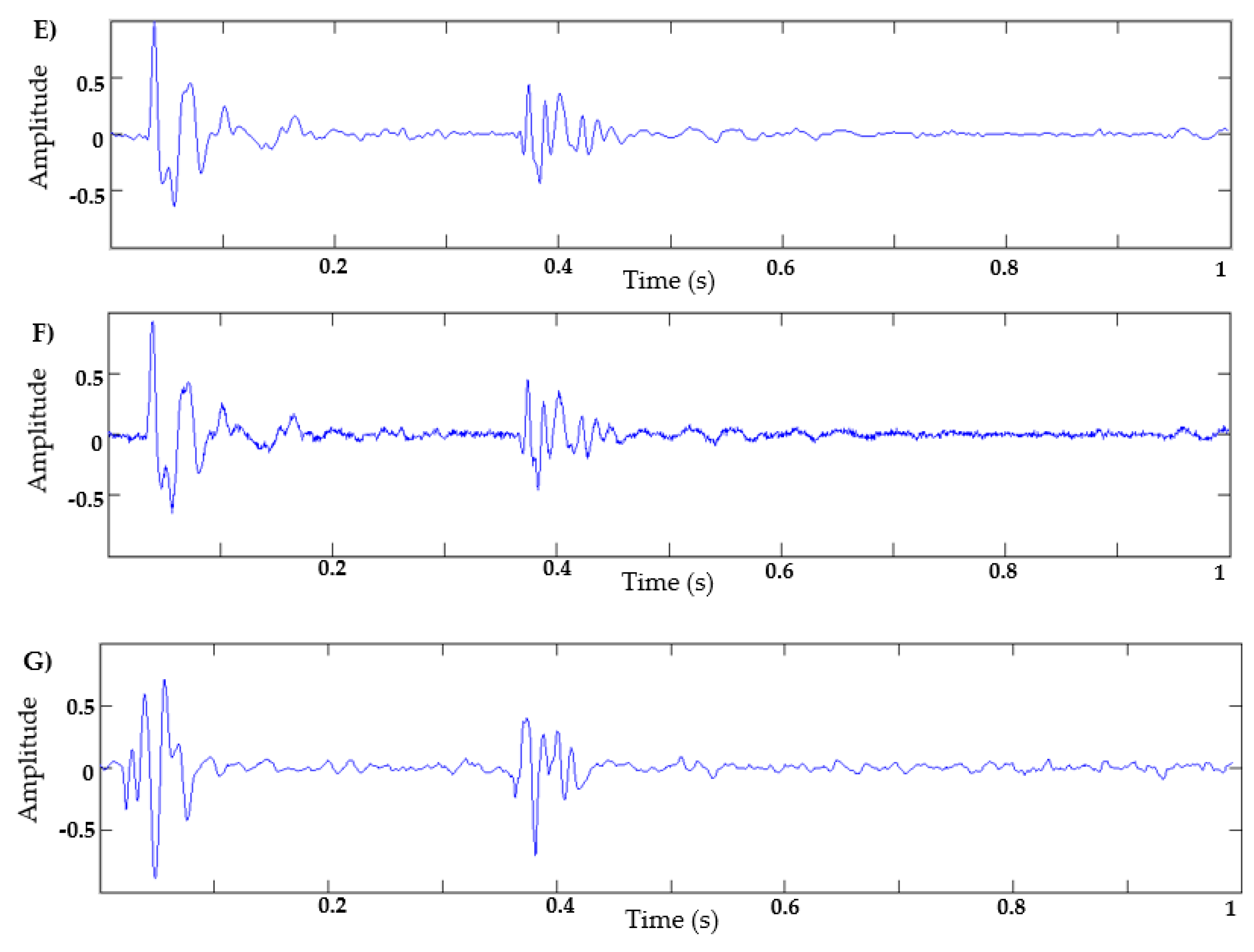
- Dataset of heart sounds: 100 normal heart sounds obtained from the Physionet database [30] were used, with a sampling frequency of 2 KHz and 1 s of duration. For this dataset, those signals with a similar heart rate were selected—that is, all signals have a similar systolic and diastolic interval duration;
- Optimization: the Adam optimizer was used, since it is one of the best performers in this type of architecture. A learning rate of 0.0002 and a beta of 0.3 were set;
- Loss function: a binary, cross-entropy function weas used in this work. This function computes the cross-entropy loss between true labels and predicted labels.
4. Experiments and Results
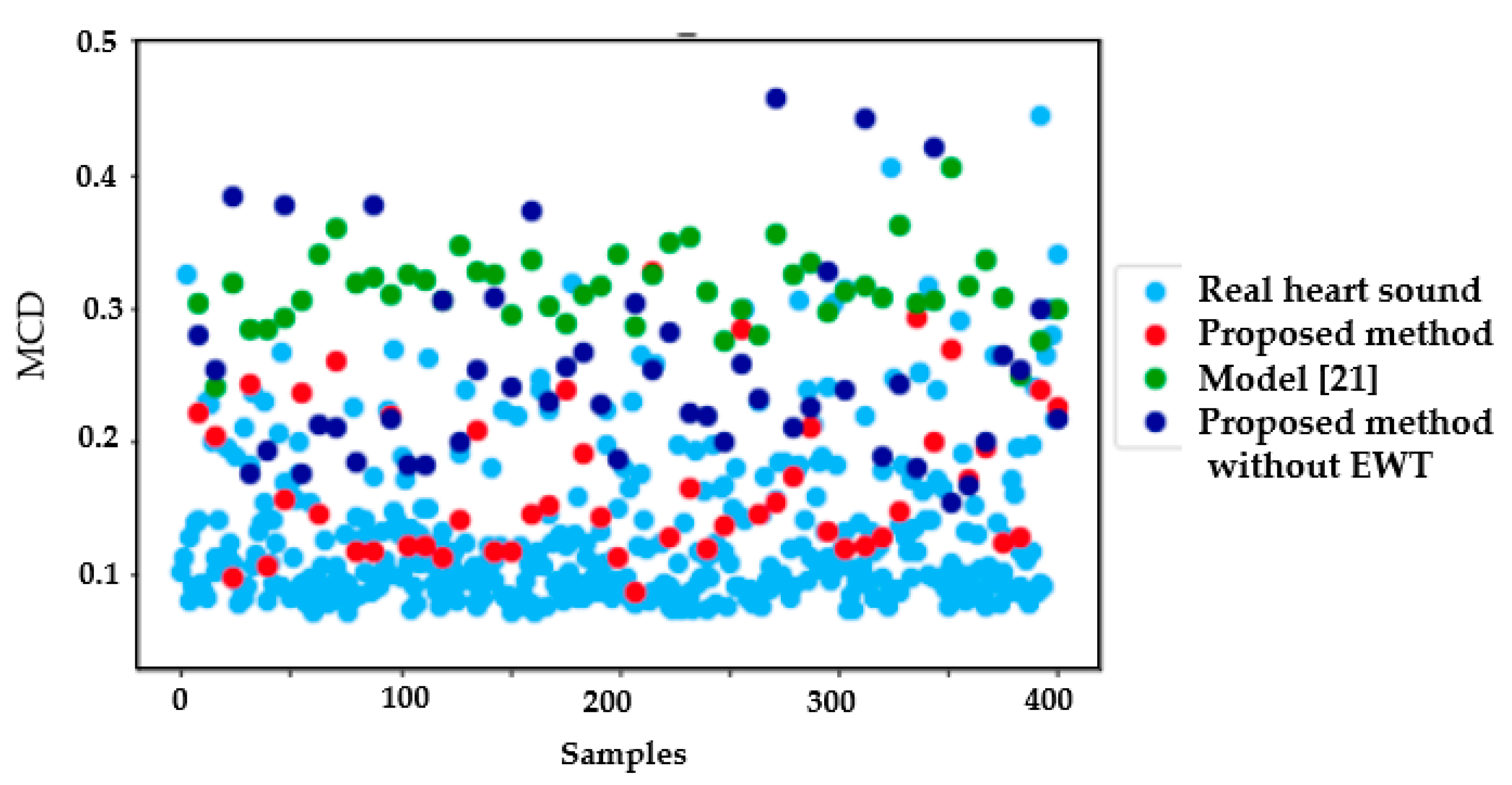
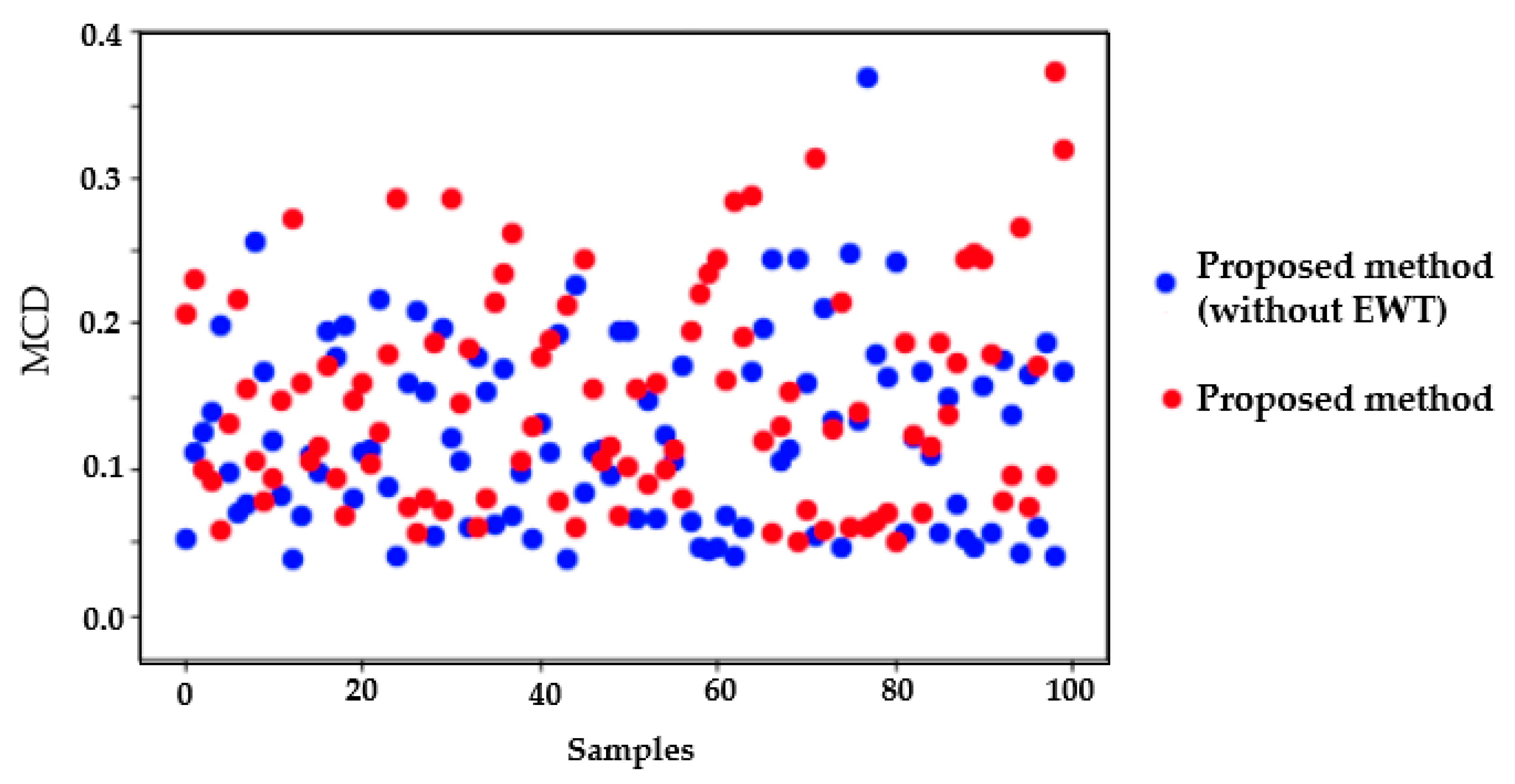
4.1. Results Using Mel–Cepstral Distortion (MCD)
4.2. Results Using Classification Models
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization. A Global Brief on Hypertension. Available online: http://www.who.int/cardiovascular_diseases/publications/global_brief_hypertension/en/ (accessed on 15 September 2020).
- Benjamin, E.J.; Blaha, M.J.; Chiuve, S.E.; Cushman, M.; Das, S.R.; Deo, R.; De Ferranti, S.D.; Floyd, J.; Fornage, M.; Gillespie, C.; et al. Heart Disease and Stroke Statistics—2017 Update: A Report From the American Heart Association. Circulation 2017, 135, 146–603. [Google Scholar] [CrossRef]
- Camic, P.M.; Knight, S.J. Clinical Handbook of Health Psychology: A Practical Guide to Effective Interventions; Hogrefe & Huber Publishers: Cambridge, MA, USA, 2004; pp. 31–32. [Google Scholar]
- Alvarez, C.; Patiño, A. State of emergency medicine in Colombia. Int. J. Emerg. Med. 2015, 8, 1–6. [Google Scholar]
- Shank, J. Auscultation Skills: Breath & Heart Sounds, 5th ed.; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2013. [Google Scholar]
- Alam, U.; Asghar, O.; Khan, S.; Hayat, S.; Malik, R. Cardiac auscultation: An essential clinical skill in decline. Br. J. Cardiol. 2010, 17, 8. [Google Scholar]
- Roelandt, J.R.T.C. The decline of our physical examination skills: Is echocardiography to blame? Eur. Heart J. Cardiovasc. Imaging 2014, 15, 249–252. [Google Scholar]
- Clark, D.; Ahmed, M.; Dell’Italia, L.; Fan, P.; McGiffin, D. An argument for reviving the disappearing skill of cardiac auscultation. Clevel. Clin. J. Med. 2012, 79, 536–537. [Google Scholar]
- Narváez, P.; Gutierrez, S.; Percybrooks, W. Automatic Segmentation and Classification of Heart Sounds using Modified Empirical Wavelet Transform and Power Features. Appl. Sci. 2020, 10, 4791. [Google Scholar] [CrossRef]
- Yaseen; Gui-Young, S.; Kwon, S. Classification of Heart Sound Signal Using Multiple Features. Appl. Sci. 2018, 8, 2344. [Google Scholar] [CrossRef]
- Arora, V.; Leekha, R.; Singh, R.; Chana, I. Heart sound classification using machine learning and phonocardiogram. Mod. Phys. Lett. B. 2019, 33, 1950321. [Google Scholar] [CrossRef]
- Narváez, P.; Vera, K.; Bedoya, N.; Percybrooks, W. Classification of heart sounds using linear prediction coefficients and mel-frequency cepstral coefficients as acoustic features. In Proceedings of the IEEE Colombian Conference on Communications and Computing, Cartagena, Colombia, 16 August 2017. [Google Scholar]
- Noman, F.; Ting, C.; Salleh, S.; Ombao, H. Short-segment heart sound classification using an ensemble of deep convolutional neural networks. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP), Brighton, UK, 12 May 2019. [Google Scholar]
- Raza, A.; Mehmood, A.; Ullah, S.; Ahmad, M.; Sang, G.; Byung-Won, O. Heartbeat Sound Signal Classification Using Deep Learning. Sensors 2019, 19, 4819. [Google Scholar] [CrossRef]
- Abdollahpur, M.; Ghaffari, A.; Ghiasi, S.; Mollakazemi, M.J. Detection of pathological heart sound. Physiol. Meas. 2017, 38, 1616–1630. [Google Scholar]
- Tang, Y.; Danmin, C.H.; Durand, L.G. The synthesis of the aortic valve closure sound on the dog by the mean filter of forward and backward predictor. IEEE Trans. Biomed. Eng. 1992, 39, 1–8. [Google Scholar] [PubMed]
- Tran, T.; Jones, N.B.; Fothergill, J.C. Heart sound simulator. Med. Biol. Eng. Comput. 1995, 33, 357–359. [Google Scholar] [PubMed]
- Zhang, X.; Durand, L.G.; Senhadji, L.; Lee, H.C.; Coatrieux, J.L. Analysis—synthesis of the phonocardiogram based on the matching pursuit method. IEEE Trans. Biomed. Eng. 1998, 45, 962–971. [Google Scholar] [PubMed]
- Xu, J.; Durand, L.; Pibarot, P. Nonlinear transient chirp signal modelling of the aortic and pulmonary components of the second heart sound. IEEE Trans. Biomed. Eng. 2000, 47, 1328–1335. [Google Scholar]
- Toncharoen, C.; Srisuchinwong, B. A heart-sound-like chaotic attractor and its synchronization. In Proceedings of the 6th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, ECTI-CON, Pattaya, Thailand, 6 May 2009. [Google Scholar]
- Almasi, A.; Shamsollahi, M.B.; Senhadji, L. A dynamical model for generating synthetic phonocardiogram signals. In Proceedings of the 33rd Annual International Conference of the IEEE EMBS, Boston, MA, USA, 30 August–3 September 2011. [Google Scholar]
- Tao, Y.W.; Cheng, X.F.; He, S.Y.; Ge, Y.P.; Huang, Y.H. Heart sound signal generator Based on LabVIEW. Appl. Mech. Mater. 2012, 121, 872–876. [Google Scholar]
- Jablouna, M.; Raviera, P.; Buttelli, O.; Ledeea, R.; Harbaa, R.; Nguyenb, L. A generating model of realistic synthetic heart sounds for performance assessment of phonocardiogram processing algorithms. Biomed. Signal Process. Control 2013, 8, 455–465. [Google Scholar]
- Sæderup, R.G.; Hoang, P.; Winther, S.; Boettcher, M.; Struijk, J.J.; Schmidt, S.E.; Ostergaard, J. Estimation of the second heart sound split using windowed sinusoidal models. Biomed. Signal Process. Control 2018, 44, 229–236. [Google Scholar]
- Joseph, A.; Martínek, R.; Kahankova, R.; Jaros, R.; Nedoma, J.; Fajkus, M. Simulator of Foetal Phonocardiographic Recordings and Foetal Heart Rate Calculator. J. Biomim. Biomater. Biomed. Eng. 2018, 39, 57–64. [Google Scholar]
- McConnell M., E.; Branigan, A. Pediatric Heart Sounds; Springer: London, UK, 2008. [Google Scholar] [CrossRef]
- Brown, E.; Leung, T.; Collis, W.; Salmon, A. Heart Sounds Made Easy, 2nd ed.; Churchill Livingstone Elsevier: Philadelphia, PA, USA, 2008. [Google Scholar]
- Etoom, Y.; Ratnapalan, S. Evaluation of Children With Heart Murmurs. Clin. Pediatr. 2013, 53, 111–117. [Google Scholar] [CrossRef]
- Johnson, W.; Moller, J. Pediatric Cardiology: The Essential Pocket Guide; Wiley-Blackwell: Oxford, UK, 2008. [Google Scholar]
- PhysioNet/Computing in Cardiology Challenge. Classification of Normal/Abnormal Heart Sound Recordings. Available online: https://www.physionet.org/challenge/2016/1.0.0/ (accessed on 15 September 2020).
- Bentley, P.; Nordehn, G.; Coimbra, M.; Mannor, S.; Getz, R. Classifying Heart Sounds Callenge. Available online: http://www.peterjbentley.com/heartchallenge/#downloads (accessed on 15 September 2020).
- Van den oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. Available online: https://arxiv.org/abs/1609.03499 (accessed on 15 September 2020).
- Engel, J.; Resnick, C.; Roberts, A.; Dieleman, S.; Eck, D.; Simonyan, K.; Norouzi, M. Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Bollepalli, B.; Juvela, L.; Alku, P. Generative Adversarial Network-Based Glottal Waveform Model for Statistical Parametric Speech Synthesis. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar] [CrossRef]
- Biagetti, G.; Crippa, P.; Falaschetti, L.; Turchetti, C. HMM speech synthesis based on MDCT representation. Int. J. Speech Technol. 2018, 21, 1045–1055. [Google Scholar] [CrossRef]
- Chrism, D.; Julian, M.; Miller, P. Adversarial Audio Synthesis. Available online: https://arxiv.org/abs/1802.04208 (accessed on 15 September 2020).
- Huang, H.; Yu, P.S.; Wang, C. An Introduction to Image Synthesis with Generative Adversarial Nets. arXiv 2018, arXiv:1803.04469. [Google Scholar]
- Goodfellow, J.I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Neural Information Processing Systems 27, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Hany, J.; Walters, G. Hands-On Generative Adversarial Networks with PyTorch 1.x.; Pckt publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Gilles, J. Empirical wavelet transform. IEEE Trans. Signal Process. 2013, 61, 3999–4010. [Google Scholar]
- Oung, Q.; Muthusamy, H.; Basah, S.; Lee, H.; Vijean, V. Empirical Wavelet Transform Based Features for Classification of Parkinson’s Disease Severity. J. Med. Syst. 2017, 42, 29. [Google Scholar]
- Qin, C.; Wang, D.; Xu, Z.; Tang, G. Improved Empirical Wavelet Transform for Compound Weak Bearing Fault Diagnosis with Acoustic Signals. Appl. Sci. 2020, 10, 682. [Google Scholar]
- Chavez, O.; Dominguez, A.; Valtierra-Rodriguez, M.; Amezquita-Sanchez, J.P.; Mungaray, A.; Rodriguez, L.M. Empirical Wavelet Transform-based Detection of Anomalies in ULF Geomagnetic Signals Associated to Seismic Events with a Fuzzy Logic-based System for Automatic Diagnosis. In Wavelet Transform and Some of Its Real-World Applications; InTech: Rijeka, Croatia, 2015. [Google Scholar]
- Debbal, S.M.; Bereksi-Reguig, F. Computerized Heart Sounds Analysis. Comput. Biol. Med. 2008, 38, 263–280. [Google Scholar] [CrossRef]
- McSharry, P.; Clifford, G.; Tarassenko, L.; Smith, L. A Dynamical Model for Generating Synthetic Electrocardiogram Signals. IEEE Trans. Biomed. Eng. 2003, 50, 289–294. [Google Scholar] [PubMed]
- Di Persia, L.; Yanagida, M.; Rufiner, H.; Milone, D. Objective quality evaluation in blind source separation for speech recognition in a real room. Signal Process. 2007, 87, 1951–1965. [Google Scholar]
- Vasilijevic, A.; Petrinovic, D. Perceptual significance of cepstral distortion measures in digital speech processing. Automatika 2011, 52, 132–146. [Google Scholar]
- University of Michigan. Heart Sound and Murmur Library. Available online: https://open.umich.edu/find/open-educational-resources/medical/heart-sound-murmur-library (accessed on 15 September 2020).
- University of Washington. Heart Sound and Murmur. Available online: https://depts.washington.edu/physdx/heart/demo.html (accessed on 15 September 2018).
- Thinklabs. Heart Sounds Library. Available online: http://www.thinklabs.com/heart-sounds (accessed on 15 September 2020).
- Littmann Stethoscope. Heart Sounds Library. Available online: www.3m.com/healthcare/littmann/mmm-library.html (accessed on 15 September 2020).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Author | Previous Method |
|---|---|---|
| 1992 | Tang et al. [16] | Exponentially damped sinusoidal model |
| 1995 | Trang et al. [17] | S1 and S2 as transient–linear chirp signals |
| 1998 | Zhang et al. [18] | Sum of Gaussian-modulated sinusoidal |
| 2000 | Xu et al. [19] | S1 and S2 as transient–nonlinear chirp signal |
| 2009 | Toncharoen et al. [20] | A heart-sound-like chaotic attractor |
| 2011 | Almasi et al. [21] | A dynamical model based in electrocardiogram (ECG) signal |
| 2012 | Tao et al. [22] | Amplitude and width modification of S1 and S2 sounds from real heart sounds, and combining them with noise |
| 2013 | Jablouna et al. [23] | Coupled ordinary differential equations |
| 2018 | Saederup [24] | Estimation of the second heart-sound split using windowed sinusoidal models |
| 2018 | Joseph et al. [25] | Sum of almost periodically recurring deterministic “wavelets”; S1 and S2 are modeled by two sinusoidal pulses of Gaussian modulation. |
| Year | Author | Previous Method | Synthetic Signal |
|---|---|---|---|
| 2015 | van den Oord et al. [32] | WaveNet: Probabilistic and autoregressive model based on deep neural networks (DNNs) | Music; text-to-speech |
| 2017 | Engel et al. [33] | WaveNet and autoenconders | Musical notes |
| 2017 | Bollepalli et al. [34] | Generative adversarial network (GAN) | Glottal waveform |
| 2018 | Biagetti et al. [35] | Hidden Markov model | Text-to-speech |
| 2019 | Donahue et al. [36] | WaveGAN: GANs unsupervised | Intelligible words |
| Index (i) | S1 (-) | S1 (+) | S2 (-) | S2 (+) |
|---|---|---|---|---|
| 0.4250 | 0.6875 | 0.5575 | 0.4775 | |
| (radians) | π/12 | 3π/19 | 3π/4 | 7π/9 |
| 0.1090 | 0.0816 | 0.0723 | 0.1060 | |
| (Hz) | 10.484 | 11.874 | 11.316 | 10.882 |
| (radians) | 3π/4 | 9π/11 | 7π/8 | 3π/4 |
| Reference | Features |
|---|---|
| [9] | Six power values (three in systole and three in diastole) |
| [10] | Nineteen mel–frequency cepstral coefficients (MFCCs) and 24 discrete wavelet transform features |
| [11] | Statistical domain: mean value, median value, standard deviation, mean absolute deviation, quartile 25, quartile 75, inter-quartile range (IQR), skewness, kurtosis, and coefficient of variation. Frequency domain: entropy, dominant frequency value, dominant frequency magnitude, and dominant frequency ratio. Perceptual domain: 13 MFCCs. |
| [12] | Six linear prediction coefficient (LPCs) + 14 MFCCs per segment (S1, S2, systole, and diastole) |
| Feature Extraction | Classifier | |||
|---|---|---|---|---|
| SVM | KNN | RF | MLP | |
| EWT + power [9] | 92.42% | 99.25% | 99.00% | 98.63% |
| MFCC + DWT [10] | 90.68% | 91.18% | 91.42% | 91.55% |
| Statistical, frequency, and perceptual [11] | 84.47% | 93.66% | 93.66% | 92.54% |
| LPC + MFCC [12] | 96.27% | 95.52% | 95.27% | 97.26% |
| Feature Extraction | Classifier | |||
|---|---|---|---|---|
| SVM | KNN | RF | MLP | |
| EWT + power [9] | 100% | 100% | 100% | 100% |
| MFCC + DWT [10] | 80% | 90% | 78% | 82% |
| Statistical, frequency, and perceptual [11] | 98% | 78% | 78% | 60% |
| LPC + MFCC [12] | 98% | 96% | 96% | 82% |
| Feature Extraction | Classifier | |||
|---|---|---|---|---|
| SVM | KNN | RF | MLP | |
| EWT + power [9] | 100% | 100% | 100% | 100% |
| MFCC + DWT [10] | 85% | 88% | 80% | 90% |
| Statistical, frequency, and perceptual [11] | 90% | 78% | 75% | 60% |
| LPC + MFCC [12] | 95% | 90% | 90% | 78% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Narváez, P.; Percybrooks, W.S. Synthesis of Normal Heart Sounds Using Generative Adversarial Networks and Empirical Wavelet Transform. Appl. Sci. 2020, 10, 7003. https://doi.org/10.3390/app10197003
Narváez P, Percybrooks WS. Synthesis of Normal Heart Sounds Using Generative Adversarial Networks and Empirical Wavelet Transform. Applied Sciences. 2020; 10(19):7003. https://doi.org/10.3390/app10197003
Chicago/Turabian StyleNarváez, Pedro, and Winston S. Percybrooks. 2020. "Synthesis of Normal Heart Sounds Using Generative Adversarial Networks and Empirical Wavelet Transform" Applied Sciences 10, no. 19: 7003. https://doi.org/10.3390/app10197003
APA StyleNarváez, P., & Percybrooks, W. S. (2020). Synthesis of Normal Heart Sounds Using Generative Adversarial Networks and Empirical Wavelet Transform. Applied Sciences, 10(19), 7003. https://doi.org/10.3390/app10197003