Performance of Fine-Tuning Convolutional Neural Networks for HEp-2 Image Classification





Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
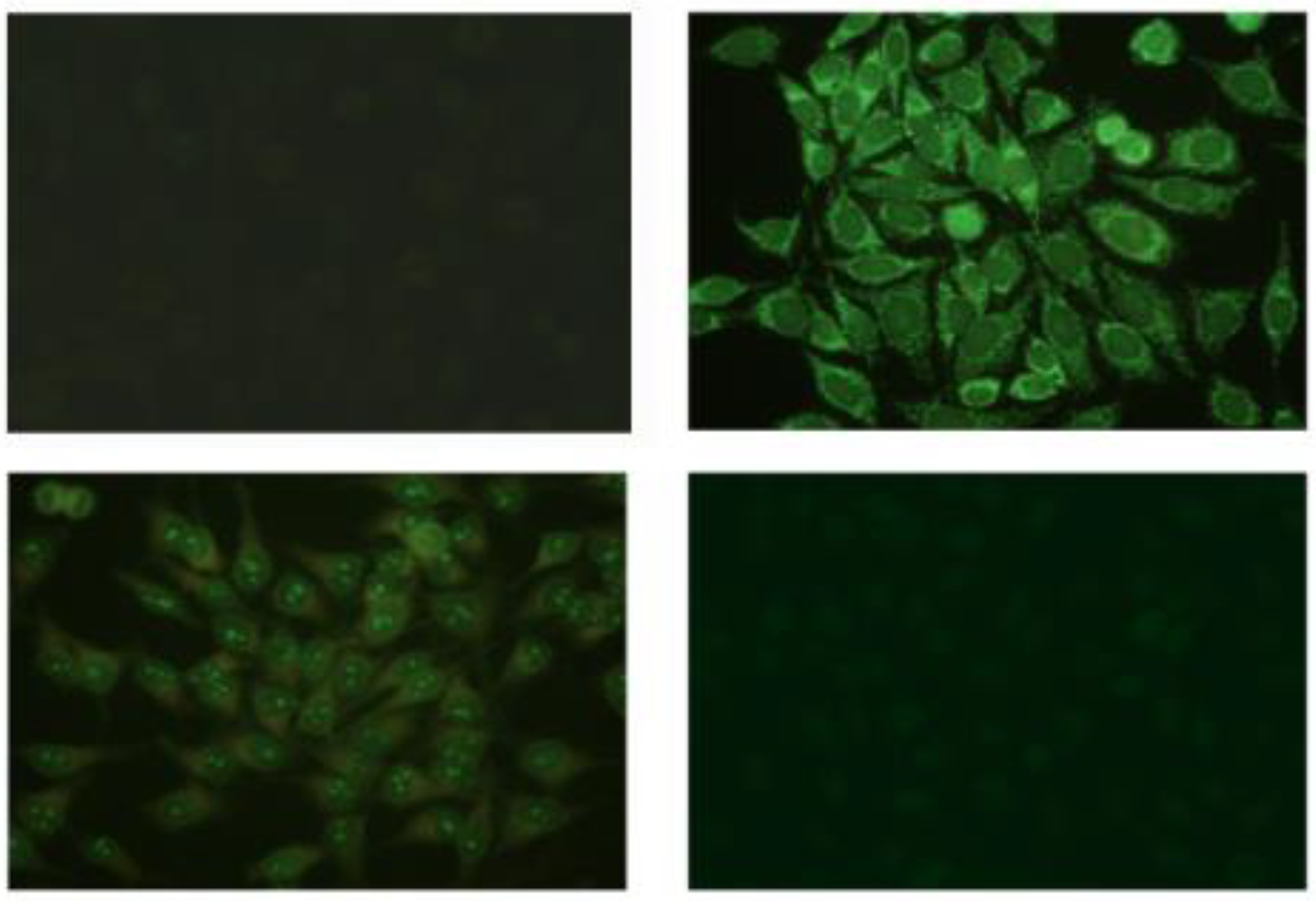
3.1. Database and Cross-Validation Strategy
3.2. Statistics
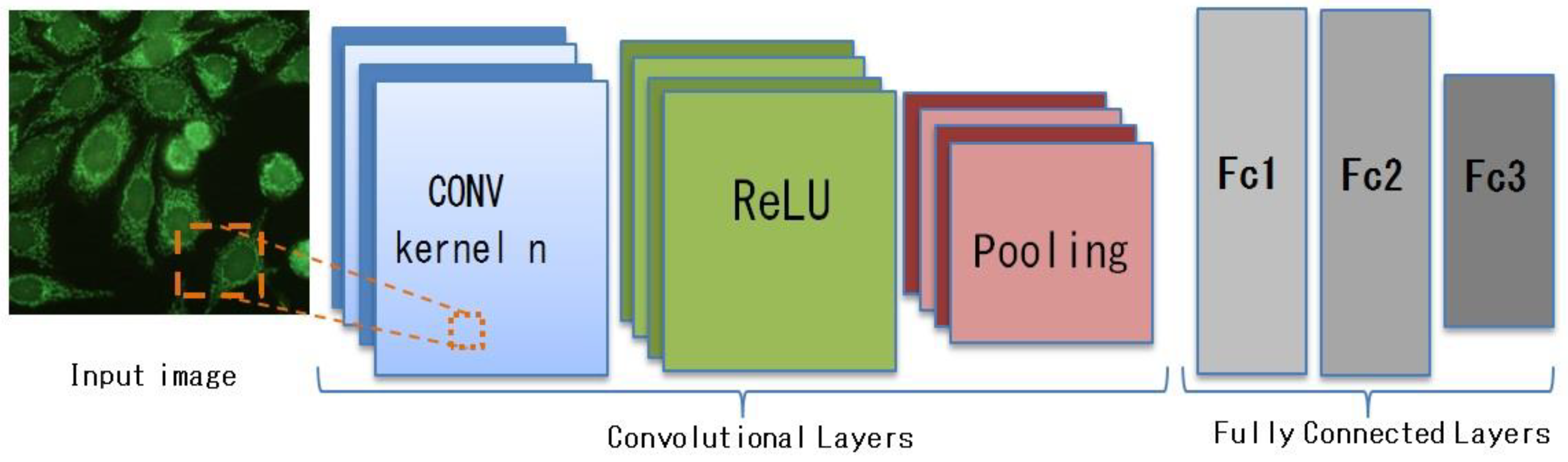
3.3. Convolutional Neural Networks
3.4. Pre-Trained CNNs
- AlexNet [10]: the AlexNet network is one of the first convolutional neural networks that has achieved great classification successes. The winner of the 2012 Image-Net Large-Scale Visual Recognition Challenge (ILSVRC) competition, this network was the first to obtain more than good results on a very complex dataset such as ImageNet. This network consists of 25 layers, the part relating to convolutional layers sees 5 levels of convolution with the use of ReLU and (only for the first two levels of convolution and for the fifth) the max pooling technique. The second part of the CNN is composed of fully connected layers with the use of ReLU and Dropout techniques and finally by softmax for a 1000-d output.
- SqueezeNet [39]: in 2016 the architecture of this CNN was designed to have performances comparable to AlexNet, but with fewer parameters, so as to have an advantage in distributed training, in exporting new models from the cloud, and in deployment on a FPGA with limited memory. Specifically, this network consists of 68 layers with the aim of producing large activation maps. The filters used instead of being 3 × 3 are 1 × 1 precisely to reduce the computation by 1/9. CNN is made up of blocks called “fire modules”, which contain a squeeze convolution layer with 1x1 filters and a expand layer with a mix of 1 × 1 and 3 × 3 convolution filters. This CNN has an initial and a final convolution layer, while the central part of the CNN is composed of 8 fire module blocks. No fully connected layers are used but an average pooling before the final softmax.
- ResNet18 [40]: this CNN, introduced in 2015, and inspired by the connection between neurons in the cerebral cortex, uses a residual connection or skip connections, which jump over some layers. With this method, it is possible to counteract the problem of degradation of performance as the depth of the net increases, in particular the “vanishing gradient”. This CNN is made up of 72 layers, the various convolutions are followed by batch normalization and ReLU, while the residual connection exploits an additional layer of two inputs. The last layers consist of an average pooling, a fully connected layer and softmax.
- GoogLeNet [41]: this architecture is based on the use of “inception modules”, each of which includes different convolutional sub-networks subsequently chained at the end of the module. This network is made up of 144 layers, the inception blocks are made up of four branches, the first three with 1 × 1, 3 × 3, and 5 × 5 convolutions, and the fourth with 3 × 3 max pooling. After that, all feature maps at different paths are concatenated together as the input of the next module. The last layers are composed of an average pooling and a fully connected layers and the softmax for the final output.
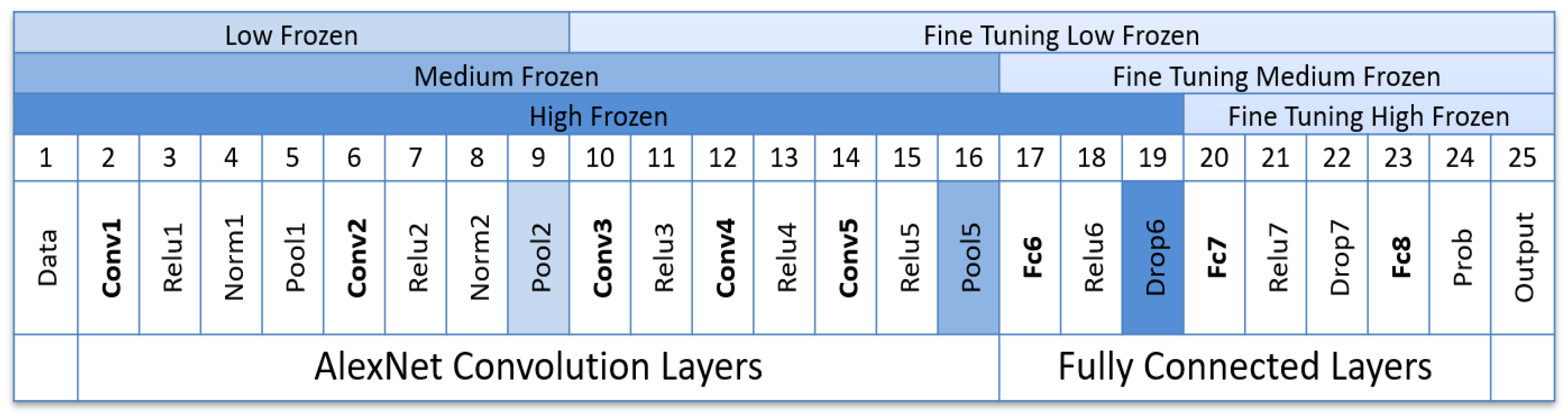
3.5. Fine-Tuning Description
3.6. Hyperparameter Optimization
3.7. Training Strategy and Classification
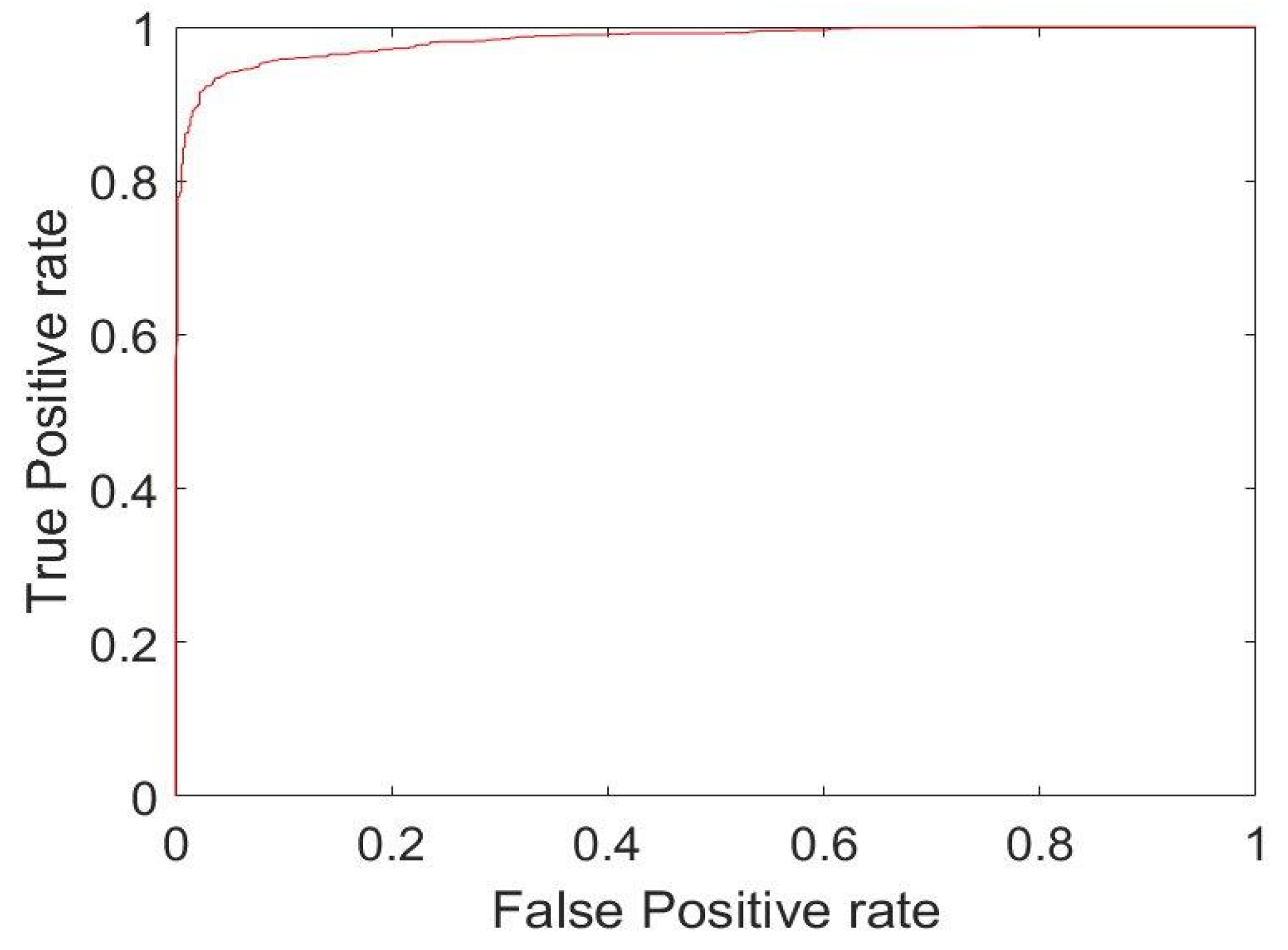
4. Results
Running Time
5. Discussions and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- The Autoimmune Disease Coordinating Committee. Progress in Autoimmune Diseases Research; National Institutes of Health: Bethesda, MD, USA, 2005; pp. 1–146. Available online: https://www.niaid.nih.gov/sites/default/files/adccfinal.pdf (accessed on 7 December 2018).
- Chinnathmbi, A.; Alyousef, M.; Al Mofeez, F.; Alsenaid, A.; Alanzi, M.; Al-Madani, S.; Alharbi, F.; Al-Mosilhi, A.; Alyousef, H.; Eid, M.A.-S.; et al. Novel approaches to autoimmune diseases: A review of new studies. Biosci. Biotechnol. Res. Asia 2016, 13, 1421–1428. [Google Scholar] [CrossRef]
- Agmon-Levin, N.; Damoiseaux, J.; Kallenberg, C.; Sack, U.; Witte, T.; Herold, M.; Bossuyt, X.; Musset, L.; Cervera, R.; Plaza-Lopez, A.; et al. International recommendations for the assessment of autoantibodies to cellular antigens referred to as anti-nuclear antibodies. Ann. Rheum. Dis. 2014, 73, 17–23. [Google Scholar] [CrossRef] [PubMed]
- Bennamar Elgaaied, A.; Cascio, D.; Bruno, S.; Ciaccio, M.C.; Cipolla, M.; Fauci, A.; Morgante, R.; Taormina, V.; Gorgi, Y.; Triki, R.M.; et al. Computer-assisted classification patterns in autoimmune diagnostics: The A.I.D.A. Project. BioMed Res. Int. 2016, 2016, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Hobson, P.; Lovell, B.C.; Percannella, G.; Saggese, A.; Vento, M.; Wiliem, A. Computer aided diagnosis for anti-nuclear antibodies HEp-2 images: Progress and challenges. Pattern Recognit. Lett. 2016, 82, 3–11. [Google Scholar] [CrossRef]
- Cascio, D.; Taormina, V.; Raso, G. An automatic HEp-2 specimen analysis system based on an active contours model and an SVM classification. Appl. Sci. 2019, 9, 307. [Google Scholar] [CrossRef]
- Rahman, S.; Wang, L.; Sun, C.; Zhou, L. Deep learning based HEp-2 image classification: A comprehensive review. Med. Image Anal. 2020, 101764. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.Z.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Software Available from Tensorflow.org. 2015. Available online: https://www.tensorflow.org (accessed on 8 September 2020).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Massachusetts Institute of Technology Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- El-Din, Y.S.; Moustafa, M.N.; Mahdi, H. Deep convolutional neural networks for face and iris presentation attack detection: Survey and case study. IET Biom. 2020, 179–193. [Google Scholar] [CrossRef]
- Cui, H.; Yuan, G.; Liu, N.; Xu, M.; Song, H. Convolutional neural network for recognizing highway traffic congestion. J. Intell. Transp. Syst. Technol. Plan. Oper. 2020, 24, 279–289. [Google Scholar] [CrossRef]
- Hussain, I.; Zeng, J.; Xinhong Tan, S. A survey on deep convolutional neural networks for image steganography and steganalysis. KSII Trans. Internet Inf. Syst. 2020, 14, 1228–1248. [Google Scholar] [CrossRef]
- Zhu, X.-P.; Dai, J.-M.; Bian, C.-J.; Chen, Y.; Chen, S.; Hu, C. Galaxy morphology classification with deep convolutional neural networks. Astrophys. Space Sci. 2019, 364, 55. [Google Scholar] [CrossRef]
- Taha, B.; Shoufan, A. Machine learning-based drone detection and classification: State-of-the-art in research. IEEE Access 2019, 7, 138669–138682. [Google Scholar] [CrossRef]
- Coluccia, A.; Parisi, G.; Fascista, A. Detection and classification of multirotor drones in radar sensor networks: A review. Sensors 2020, 20, 4172. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Receptive fields and functional architecture of monkey striate cortex. J. Physiol. 1968, 195, 215–243. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Cascio, D.; Taormina, V.; Raso, G. Deep convolutional neural network for HEp-2 fluorescence intensity classification. Appl. Sci. 2019, 9, 408. [Google Scholar] [CrossRef]
- Foggia, P.; Percannella, G.; Soda, P.; Vento, M. Benchmarking hep-2 cells classification methods. IEEE Trans. Med. Imaging 2013, 32, 1878–1889. [Google Scholar] [CrossRef]
- Hobson, P.; Percannella, G.; Vento, M.; Wiliem, A. Competition on cells classification by fluorescent image analysis. In Proceedings of the 20th IEEE International Conference on Image Processing, ICIP 2013, Melbourne, Australia, 15–18 September 2013; pp. 2–9. [Google Scholar]
- Lovell, B.C.; Percannella, G.; Vento, M.; Wiliem, A. Performance evaluation of indirect immunofluorescence image analysis systems. In Proceedings of the ICPR Workshop, Stockholm, Sweden, 24 August 2014. [Google Scholar]
- Shen, L.; Jia, X.; Li, Y. Deep cross residual network for HEp-2 cell staining pattern classification. Pattern Recognit. 2018, 82, 68–78. [Google Scholar] [CrossRef]
- Manivannan, S.; Li, W.; Akbar, S.; Wang, R.; Zhang, J.; McKenna, S.J. An automated pattern recognition system for classifying indirect immunofluorescence images of HEp-2 cells and specimens. Pattern Recognit. 2016, 51, 12–26. [Google Scholar] [CrossRef]
- Zhao, Y.; Gao, Z.; Wang, L.; Zhou, L. Experimental study of unsupervised feature learning for HEp-2 cell images clustering. In Proceedings of the 2014 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Tasmania, Australia, 26–28 November 2013; pp. 1–8. [Google Scholar]
- Vivona, L.; Cascio, D.; Taormina, V.; Raso, G. Automated approach for indirect immunofluorescence images classification based on unsupervised clustering method. IET Comput. Vis. 2018, 12, 989–995. [Google Scholar] [CrossRef]
- Gao, Z.; Wang, L.; Zhou, L.; Zhang, J. HEp-2 cell image classification with deep convolutional neural networks. IEEE J. Biomed. Health Inform. 2016, 21, 416–428. [Google Scholar] [CrossRef]
- Cascio, D.; Taormina, V.; Raso, G. Deep CNN for IIF images classification in autoimmune diagnostics. Appl. Sci. 2019, 9, 1618. [Google Scholar] [CrossRef]
- Percannella, G.; Soda, P.; Vento, M. A classification-based approach to segment HEp-2 cells. In Proceedings of the 25th International Symposium on Computer-Based Medical Systems, Roma, Italy, 20–21 June 2012. [Google Scholar]
- Gupta, K.; Bhavsar, A.; Sao, A.K. CNN based mitotic HEp-2 cell image detection. In Proceedings of the BIOIMAGING 2018—5th International Conference on Bioimaging, Funchal, Portugal, 19–21 January 2018. [Google Scholar]
- Merone, M.; Sansone, C.; Soda, P. A computer-aided diagnosis system for HEp-2 fluorescence intensity classification. Artif. Intell. Med. 2019, 97, 71–78. [Google Scholar] [CrossRef] [PubMed]
- Di Cataldo, S.; Tonti, S.; Bottino, A.; Ficarra, E. ANAlyte: A modular image analysis tool for ANA testing with indirect immunofluorescence. Comput. Methods Programs Biomed. 2016, 128, 86–99. [Google Scholar] [CrossRef]
- Iannello, G.; Onofri, L.; Soda, P. A slightly supervised approach for positive/negative classification of fluorescence intensity in hep-2 images. In Proceedings of the International Conference on Image Analysis and Processing, Naples, Italy, 9–13 September 2013; Springer: Berlin, Heidelberg, 2013; pp. 319–328. [Google Scholar]
- Zhou, J.; Li, Y.; Zhou, X.; Shen, L. Positive and negative HEp-2 image classification fusing global and local features. In Proceedings of the 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017. [Google Scholar]
- Taormina, V.; Cascio, D.; Abbene, L.; Raso, G. HEp-2 intensity classification based on deep fine-tuning. In Proceedings of the 7th International Conference on Bioimaging, BIOIMAGING 2020, Valletta, Malta, 24–26 February 2020; pp. 143–149. [Google Scholar]
- Chan, E.K.; Damoiseaux, J.; Cruvinel, W.D.M.; Carballo, O.G.; Conrad, K.; Francescantonio, P.L.C.; Fritzler, M.J.; La Torre, I.G.-D.; Herold, M.; Mimori, T.; et al. Report on the second International Consensus on ANA Pattern (ICAP) workshop in Dresden 2015. Lupus 2016, 25, 797–804. [Google Scholar] [CrossRef] [PubMed]
- Lu, L.; Zheng, Y.; Carneiro, G.; Yang, L. Deep learning and convolutional neural networks for medical image computing. In Advances in Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. IJCV 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keytzer, K. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <0.5 mb model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- West, J.; Ventura, D.; Warnick, S. Spring Research Presentation: A Theoretical Foundation for Inductive Transfer; College of Physical and Mathematical Sciences: Provo, UT, USA, 2007. [Google Scholar]
- MATLAB. R2020a; The MathWorks Inc.: Natick, MA, USA, 2020. [Google Scholar]
- Christianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Method and Database | Pros | Cons | Purpose of the Research |
|---|---|---|---|---|
| Percannella [29] | -Preprocessing with histogram equalization and morphological operations. Double segmentation phase based on the use of a classifier. | Accurate segmentation masks. A public database was used. | The analysis was conducted on only six cell patterns. Mitoses were not considered. | HEp-2 cells segmentation. |
| -MIVIA dataset. | ||||
| Gupta [28] | -Data augmentation. Linear Support Vector Machine (SVM) trained with features extracted from AlexNet. | It is one of the few works for the classification of mitosis. A public database was used. | A classification phase of fluoroscopic patterns, to verify whether the identification of mitosis allows a substantial improvement in performance, is missing. | HEp-2 cells classification into mitotic and non-mitotic classes. |
| -I3A dataset. | ||||
| Shen [23] | -Preprocessing with stretching and data augmentation. Classification based on Deep Co-Interactive Relation Network (DCR-Net). | The implemented method proved to be robust and performing by winning the ICPR 2016 contest on the I3A task1 dataset. | The classification is cell level based, but the cells was manually segmented. | Classification of (six) staining patterns. |
| -I3A task1 and MIVIA dataset. | ||||
| Manivannan [24] | -Preprocessing with intensity normalization. Pyramidal decomposition of the cells in the central part and in the crown. Four types of local descriptors as features and sparse coding as aggregation. Classification based on linear SVM classifiers. | The pyramidal decomposition proved to be very efficient, in fact the method won the ICPR 2014 contest on the I3A task1 and task2 dataset. | The final classification is obtained considering the maximum value of the classifiers used. The use of an additional classifier could give greater robustness and better performance. | Classification of (six/seven) staining patterns with/without segmentation masks. |
| -I3A task1 and I3A task2 dataset. | ||||
| Gao [25] | -Preprocessing with intensity normalization. Bag of Words based on scale-invariant feature transform (SIFT) features, comparing with deep learning model (Single-layer networks for patches classification and multi-layer network for full images classification). Classification by k-means clustering. | A comparison between the traditional method based on Bag of Words and the method based on deep learning was made. | The classification is cell level based, but the cells was manually segmented. | Classification of (six) staining patterns. |
| -I3A task1 and MIVIA dataset. | ||||
| Vivona [26] | -Preprocessing with contrast limited adaptive histogram equalization (CLAHE) and morphological operations like dilatation and holes filling. Automatic segmentation of the Centromere pattern. Classification by k-means clustering. | Good performance of centromere identification without manual segmentation and supervised dataset. A public database was used. | Only one fluorescence pattern was analyzed. | Classification of centromere pattern. |
| -AIDA and MIVIA dataset. | ||||
| Gao [27] | -Preprocessing with intensity normalization and data augmentation. CNN (Convolutional Neural Network) with eight layers (six convolutional layers and two fully connected layers). | A comparison between the traditional methods such Bag of words and Fisher Vector (FV) was made. | The classification is cell level based, but the cells was manually segmented. | Classification of (six) staining patterns. |
| -I3A task1 and MIVIA dataset. | ||||
| Cascio [28] | -Preprocessing with stretching and data augmentation. Six linear SVM trained with features extracted from CNN. Final classification with KNN (K-nearest neighbors) to improve classic one-against-all strategy. | An intensive analysis of procedures and parameters was conducted, which allowed performances among the highest on the I3A task1 public database. | The classification is cell level based, but the cells was manually segmented. | Classification of (six) staining patterns. |
| -I3A task1 dataset. | ||||
| Di Cataldo [32] | -Preprocessing based on histogram equalization and morphological opening. Segmentation with the Watershed technique. KNN classifier with morphological features and global/local texture descriptors to classify the patterns and KNN with local contrast features at multiple scale to classify intensity fluorescence. | One of the most comprehensive works for HEp-2 image classification. | Probably due to the database at their disposal, they do not analyze the positive/negative fluorescence intensity. | Classification between positive and weak positive fluorescence classes. Classification of (six) staining patterns. |
| -I3A and MIVIA dataset. | ||||
| Merone [31] | -Three SVM with Gaussian kernel trained on features extracted from Invariant Scattering Convolutional Network based on wavelet modules. Final classification based on one-against-one strategy. | The network was based on multiple wavelet module operators and was used as a texture description, in this way it was particularly effective. | The use of a private dataset of HEp-2 images for training/test the method. | Classification between positive, negative and weak positive fluorescence classes. |
| -Private dataset. | ||||
| Bennamar [4] | -Separate preprocessing for each class to recognize. Traditional features extraction and separate features reduction for each class. Classification based on seven SVM with Gaussian kernel. Final classification with KNN. | The only work published in which a complete Computer aided diagnosis (CAD) system is presented to classify HEp-2 images in terms of fluorescence intensity and florescence pattern. The CAD performance is comparable with the Junior immunologist. | Perfectible classification performance. | Fluorescence intensity classification and classification of (seven) staining patterns. |
| -AIDA database. | ||||
| Iannello [33] | -SIFT algorithm to detect patches and features extracted from first and second order gray level histograms. Features selection with Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA). Final classification with Gaussian mixture model. | The features reduction process was particularly careful | A private database was used. | Fluorescence intensity classification |
| -Private dataset. | ||||
| Zhou [34] | -An adaptive local thresholding was applied to cell image segmentation. Two step classification: (1) with global features based on mean and variance of each channel RGB; (2) with local features based on SIFT and bag of words for doubt cases. | The classification process is very effective because it is trained on the segmented cells (without the background). | A private database was used. | Fluorescence intensity classification |
| -Private dataset. | ||||
| Cascio [19] | -Data augmentation. Pre-trained CNNs dataset used as features extractors coupled with linear SVM. | An intense analysis of the parameters involved was conducted in order to maximize performance. | Convolutional neural networks were used only as feature extractors. | Fluorescence intensity classification. |
| -AIDA dataset. | ||||
| Taormina [35] | -Data augmentation. The GoogLeNet network was used, both as a feature extractor and training it with fine-tuning mode. | The use of fine tuning has proved very promising. | Limited configurations explored. | Fluorescence intensity classification. |
| -AIDA dataset. |
| Parameter | Configurations |
|---|---|
| Training mode | Stochastic Gradient Descent with Momentum with mini-batch |
| Mini-batch size | {4, 8, 16, 32, 64, 128, 256} |
| Learning Rate | {0.01, 0.001, 0.0001} |
| Momentum coefficient | 0.9 |
| Epoch | max 10 epoch if freeze some layers max 30 epoch if training CNN from scratch |
| CNN Name | Total Layers | Low Frozen | Medium Frozen | High Frozen |
|---|---|---|---|---|
| AlexNet | 25 | 9 | 16 | 19 |
| SqueezeNet | 68 | 11 | 34 | 62 |
| ResNet18 | 72 | 12 | 52 | 67 |
| GoogLeNet | 144 | 11 | 110 | 139 |
| Step 1: load AlexNet pre-trained CNN and take input image size. After download and install Deep Learning Toolbox Model for AlexNet Network support package, set “myNet” as AlexNet CNN pre-trained on the ImageNet data set. set “inputSize” because AlexNet requires input images of size 227×227×3. | %%% load pre-trained network myNet = alexnet; %%% take input image size inputSize = myNet.Layers(1). InputSize; |
| Step 2: load images. Load the training/validation/test images with the imageDatastore function that automatically labels the images based on folder names and stores the data as an ImageDatastore object. The imageDatastore function is optimized for large image data and efficiently read batches of images during training. | %%% load training / validation / test imdsTrain = imageDatastore(dir_training), ‘IncludeSubfolders’,true, ‘LabelSource’, ‘foldernames’); imdsValid = imageDatastore(dir_validation), ‘IncludeSubfolders’,true, ‘LabelSource’, ‘foldernames’); imdsTest = imageDatastore(dir_test), ‘IncludeSubfolders’,true, ‘LabelSource’, ‘foldernames’); |
| Step 3: resize images and apply augmentation with rotation. With the augmentedImageDatastore function, the training/validation/test images are resized and augmented with rotation of 20°. | %%% resize images and augmentation with rotation imageAugmenter = imageDataAugmenter(‘RandRotation’,(−20,20)); augimdsTrain = augmentedImageDatastore(inputSize(1:2), imdsTrain, ‘DataAugmentation’, imageAugmenter); augimdsValid = augmentedImageDatastore(inputSize(1:2), imdsValid, ‘DataAugmentation’, imageAugmenter); augimdsTest = augmentedImageDatastore(inputSize(1:2), imdsTest, ‘DataAugmentation’, imageAugmenter); |
| Step 4: replace final layers. Replace final layers considering that the new classes are only positive and negative while the pre-trained AlexNet are configured for 1000 classes. | %%% replace final layers layersTransfer = myNet.Layers(1:end-3); layers = (layersTransfer fullyConnectedLayer (2) % two class: positive and negative softmaxLayer classificationLayer); |
| Step 5: freeze initial layers. With the freezeWeights function, the first network layers chosen are frozen so the new training does not change these weights. | %%% freeze initial layers freeze = 16; % the first 16 layers layers(1:freeze) = freezeWeights(layers(1:freeze)); |
| Step 6: training network. ”Option” set the various training parameters such as the optimization algorithm, the learning rate, etc. The function trainNetwork executes the training on the network “myNet” considering the options, the freeze weights and the validation images set. | %%% training options options = trainingOptions(‘sgdm’, … % sgd with momentum ‘MiniBatchSize’, 32, ‘MaxEpochs’, 10, … ‘LearnRate’, 0.001, … ‘Momentum’, 0,9, … ‘ValidationData’, augimdsValid’); %%% train network using the training and validation data myNet = trainNetwork(augimdsTrain, layers, options); |
| Step 7: test network. With the classify function, the network trained on the validation set is tested on the test set, and the performance measures are extracted, such as ACC and AUC. Perfcurve function find the AUC and then the ROC curve is drawn with plot function. | %%% test network fine tuned [pred, probs] = classify(myNet, augimdsTest); %%% extract performance (X,Y,T,AUC) = perfcurve(imdsTest.Labels, probs, ‘POS’); fprintf(‘ACC: %d\n’, accuracy); %print ACC fprintf(‘AUC: %d\n’, AUC); %print AUC figure, plot(X,Y,‘r’); %ROC curve accuracy = mean(pred == imdsTest.Labels); |
| CNN Name | High Frozen | Medium Frozen | Low Frozen | Scratch | Low Frozen + Data Augmentation | Scratch + Data Augmentation |
|---|---|---|---|---|---|---|
| AlexNet | 97.20% | 97.93% | 97.82% | 98.00% | 98.08% | 98.02% |
| SqueezeNet | 97.96% | 98.39% | 98.55% | 98.38% | 98.63% | 98.46% |
| ResNet18 | 97.27% | 97.88% | 98.11% | 98.24% | 98.33% | 98.32% |
| GoogLeNet | 96.30% | 96.78% | 98.00% | 97.96% | 98.37% | 98.20% |
| CNN | AUC | Learning Rate | Mini-batch | Epoch |
|---|---|---|---|---|
| AlexNet | 98.08% | 0.001 | 16 | 4 |
| SqueezeNet | 98.63% | 0.001 | 16 | 6 |
| ResNet18 | 98.33% | 0.001 | 16 | 8 |
| GoogLeNet | 98.37% | 0.01 | 32 | 7 |
| CNN | AUC | Best Layers |
|---|---|---|
| AlexNet | 95.52% | ‘Conv 5′ |
| SqueezeNet | 95.50% | ‘Pool 10′ |
| ResNet18 | 97.80% | ‘Fc 1000′ |
| GoogLeNet | 95.76% | ‘Inception 3a output’ |
| Method | Images Dataset | Accuracy | AUC |
|---|---|---|---|
| Iannello [32] | 914 | 89.49% | - |
| Bennamar Elgaaied [4] | 1006 | 85.5% | - |
| Zhou [34] | 1290 | 98.68% | - |
| Cascio [19] | 2080 | 92.8% | 97.4% |
| Taormina [35] | 2080 | 93.0% | 98.4% |
| Present method | 2080 | 93.93% | 98.63% |
| CNN Name | Training Time in Hours (min–max) | |||
|---|---|---|---|---|
| High Frozen | Medium Frozen | Low Frozen | Scratch | |
| AlexNet | (3.42–9.57) | (4.33–12.58) | (4.69–17.24) | (5.65–26.3) |
| SqueezeNet | (6.26–10.22) | (7.43–14.15) | (11.93–27.96) | (12.56–36.57) |
| ResNet18 | (4.28–9.94) | (4.51–10.51) | (4.91–11.52) | (5.86–18.12) |
| GoogLeNet | (4.02–8.26) | (4.13–16.32) | (4.27–18.54) | (5.37–24.4) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taormina, V.; Cascio, D.; Abbene, L.; Raso, G. Performance of Fine-Tuning Convolutional Neural Networks for HEp-2 Image Classification. Appl. Sci. 2020, 10, 6940. https://doi.org/10.3390/app10196940
Taormina V, Cascio D, Abbene L, Raso G. Performance of Fine-Tuning Convolutional Neural Networks for HEp-2 Image Classification. Applied Sciences. 2020; 10(19):6940. https://doi.org/10.3390/app10196940
Chicago/Turabian StyleTaormina, Vincenzo, Donato Cascio, Leonardo Abbene, and Giuseppe Raso. 2020. "Performance of Fine-Tuning Convolutional Neural Networks for HEp-2 Image Classification" Applied Sciences 10, no. 19: 6940. https://doi.org/10.3390/app10196940
APA StyleTaormina, V., Cascio, D., Abbene, L., & Raso, G. (2020). Performance of Fine-Tuning Convolutional Neural Networks for HEp-2 Image Classification. Applied Sciences, 10(19), 6940. https://doi.org/10.3390/app10196940