KsponSpeech: Korean Spontaneous Speech Corpus for Automatic Speech Recognition

 ,
,
Abstract
1. Introduction
2. KsponSpeech Corpus
2.1. Recording Environment
2.1.1. Speaker Information
2.1.2. Collection Environment
2.1.3. Conversation Topic
2.1.4. Post-Processing
2.2. Transcription Rules
2.2.1. Dual Transcription
2.2.2. Disfluent Speech Transcription
2.2.3. Ambiguous Pronunciation
2.2.4. Non-Speech and Noise Notation
2.2.5. Numeric Notation
2.2.6. Abbreviation Notation
2.2.7. Word Spacing and Punctuation
2.3. Corpus Partitions for Speech Recognition
3. Speech Recognition Results
3.1. Experimental Setups
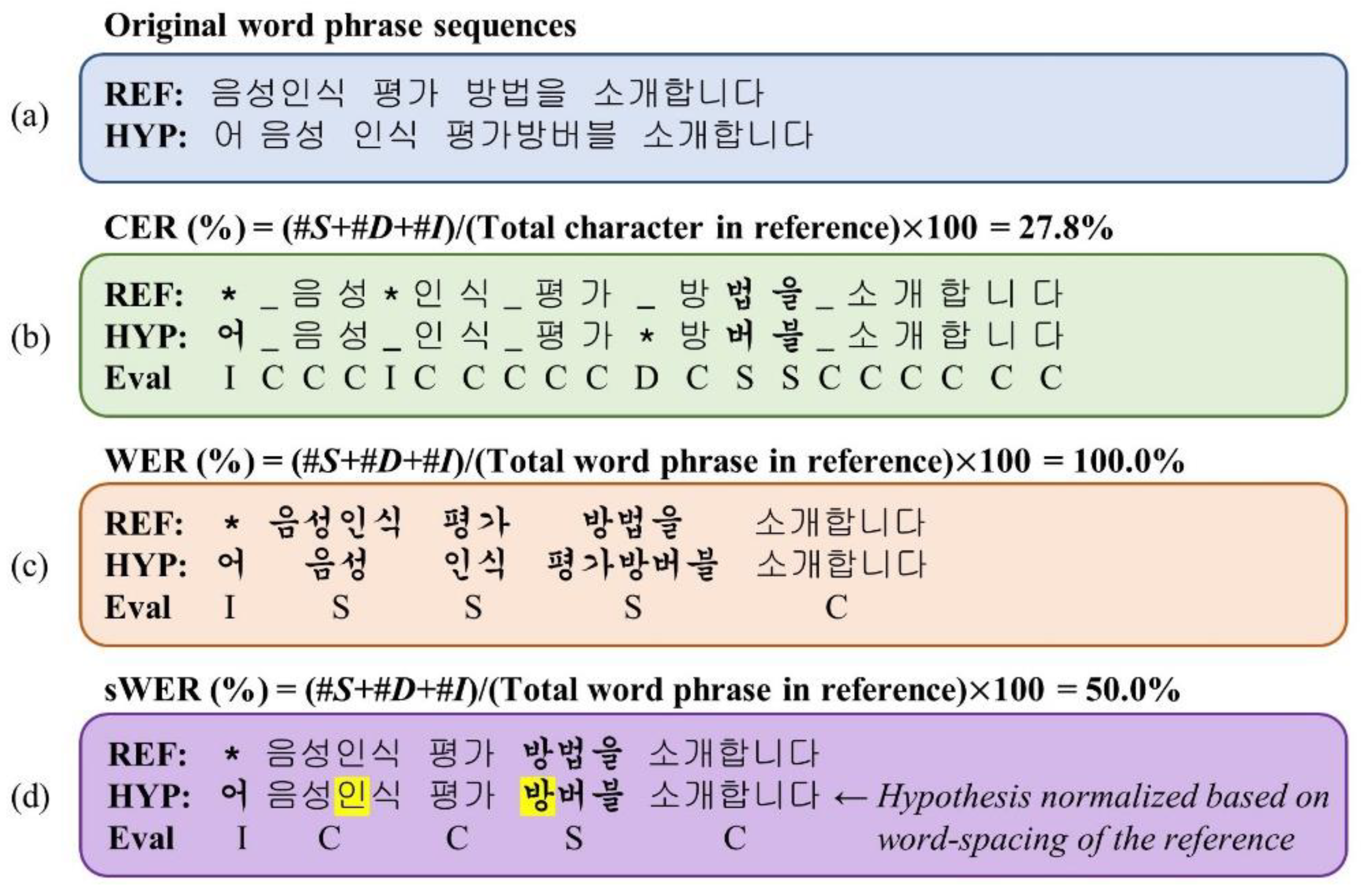
3.2. Evaluation Metrics
3.3. Comparison of RNN and Transformer Architectures
3.4. The Number of Sub-Word Units
3.5. Size of Transformer Model
3.6. Clean Transcription Generation
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| Models | Configurations | Hyperparameters | |
|---|---|---|---|
| RNN | Model | Encoder type | VGGBLSTM |
| No. input layers | 2 VGG (subsampling = 4) | ||
| No. encoder layers × cells | 5 × 1024 | ||
| Decoder type | LSTM | ||
| No. decoder layers × cells | 2 × 1024 | ||
| Attention type | Location-aware | ||
| No. feature maps | 10 | ||
| Window size | 100 | ||
| Training | Optimizer | AdaDelta | |
| CTC weight | 0.5 | ||
| Epochs | 20 | ||
| Early stop (patience) | 3 | ||
| Dropout | 0.2 | ||
| Decoding | Beam size | 20 | |
| CTC weight | 0.5 | ||
| Transformer | Model | Encoder and decoder types | Transformer |
| No. input layers | 2 VGG (subsampling = 4) | ||
| No. encoder layers × dim | 12 × 2048 | ||
| No. decoder layers × dim | 6 × 2048 | ||
| No. attention heads × dim | 4 × 256 or 8 × 512 1 | ||
| Training | Optimizer | Noam | |
| CTC weight | 0.3 | ||
| Label smoothing | 0.1 | ||
| Epochs | 100 or 120 1 | ||
| Early stop (patience) | 0 | ||
| Dropout | 0.1 | ||
| Accumulating gradients | 2 or 5 1 | ||
| Gradient clipping | 5 | ||
| Warmup-steps | 25,000 | ||
| Decoding | Beam size | 10 or 60 1 | |
| CTC weight | 0.5 or 0.4 1 | ||
Appendix B
| Algorithm A1. Calculation of CER, WER, & sWER (%) |
| Input: Character-level reference and hypothesis texts (,) Output: Character, word, & space-normalized word error rates 1: function (,) 2: //check the number of lines in two texts 3: if length() != length() then 4: return 5: 6: //get word-level texts 7: 8: 9: 10: //get word-spacing normalized texts 11: , = [], [] 12: for each in do 13: , = () 14: 15: 16: 17: //compute CER, WER, and sWER with the sclite toolkit 18: (, ) 19: 20: 21: return ; |
| Algorithm A2. Word-spacing normalization |
| Input: Reference and hypothesis texts () Output: Word-spacing normalized texts 1: function () 2: //do character-level tokenizing with space symbol (‘_’) 3: //ref: “” refs: [‘_’, ‘’, ‘_’] 4: , , 5: , 6: 7: //initialization 8: (+1, +1) 9: for = 0 to do = ; 10: for = 1 to do 11: = + 1 12: for = 1 to do 13: , = (, ) 14: = + (== ? 0:1) 15: , = + 1, + 1 16: = (, , ) 17: 18: //traceback and compute alignment 19: , = , 20: , = [], [] 21: while > 0 or > 0 do 22: if == 0 then = ; = ; 23: else if == 0 then = ; = ; 24: else 25: , = (, ) 26: = + (==. ? 0:1) 27: , = + 1, + 1 28: if (, ) then 29: , = , 30: else 31: , = ( ? , :, ) 32: = ( = ? : ) 33: = ( = ? : ) 34: , = , 35: 36: //do word-spacing normalization 37: if and are the same after removing space symbol then 38: = 39: , (, ) 40: (, ) (, ) 41: return list_to_string( |
References
- Wang, D.; Wang, X.; Lv, S. An overview of end-to-end automatic speech recognition. Symmetry 2019, 11, 1018. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 30–42. [Google Scholar] [CrossRef]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–26 March 2016; pp. 4960–4964. [Google Scholar]
- Zhang, Q.; Lu, H.; Sak, H.; Tripathi, A.; McDermott, E.; Koo, S.; Kumar, S. Transformer transducer: A streamable speech recognition model with transformer encoders and rnn-t loss. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7829–7833. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the 33rd International Conference on Machine Learning (ICML), New York City, NY, USA, 19–24 June 2016; pp. 173–182. [Google Scholar]
- Chiu, C.C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z.; Kannan, A.; Weiss, R.J.; Rao, K.; Gonina, E.; et al. State-of-the-art speech recognition with sequence-to-sequence models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar]
- Deng, Y.C.; Wang, Y.R.; Chen, S.H.; Chiang, C.Y. Recent progress of mandarin spontaneous speech recognition on mandarin conversation dialogue corpus. In Proceedings of the 22nd Conference of the Oriental Chapter of the International Committee for the Co-ordination and Standardization of Speech Databases and Assessment Techniques (O-COCOSDA), Cebu, Philippines, 25–27 October 2019; pp. 1–6. [Google Scholar]
- Bang, J.-U.; Kim, S.-H.; Kwon, O.-W. Acoustic data-driven subword units obtained through segment embedding and clustering for spontaneous speech recognition. Appl. Sci. 2020, 10, 2079. [Google Scholar] [CrossRef]
- Zayats, V.; Ostendorf, M.; Hajishirzi, H. Disfluency detection using a bidirectional LSTM. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), San Francisco, CA, USA, 8–12 September 2016; pp. 2523–2527. [Google Scholar]
- Salesky, E.; Sperber, M.; Waibel, A. Fluent translations from disfluent speech in end-to-end speech translation. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; pp. 2786–2792. [Google Scholar]
- Chen, X.W.; Lin, X. Big data deep learning: Challenges and perspectives. IEEE Access 2014, 2, 514–525. [Google Scholar] [CrossRef]
- Cieri, C.; Miller, D.; Walker, K. The Fisher corpus: A resource for the next generations of speech-to-text. In Proceedings of the 4th International Conference of the Language Resources and Evaluation (LREC), Baltimore, MD, USA, 24–30 May 2004; pp. 69–71. [Google Scholar]
- Rousseau, A.; Deléglise, P.; Esteve, Y. Enhancing the TED-LIUM corpus with selected data for language modeling and more TED talks. In Proceedings of the 9th International Conference of the Language Resources and Evaluation (LREC), Reykjavik, Iceland, 26–31 May 2014; pp. 3935–3939. [Google Scholar]
- Hernandez, F.; Nguyen, V.; Ghannay, S.; Tomashenko, N.; Estève, Y. TED-LIUM 3: Twice as much data and corpus repartition for experiments on speaker adaptation. In Proceedings of the International Conference on Speech and Computer (SPECOM), Leipzig, Germany, 18–22 September 2018; pp. 198–208. [Google Scholar]
- Liu, Y.; Fung, P.; Yang, Y.; Cieri, C.; Huang, S.; Graff, D. HKUST/MTS: A Very Large Scale Mandarin Telephone Speech Corpus; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4274, pp. 724–735. [Google Scholar]
- Maekawa, K.; Koiso, H.; Furui, S.; Isahara, H. Spontaneous Speech Corpus of Japanese. In Proceedings of the 2nd International Conference of the Language Resources and Evaluation (LREC), Athens, Greece, 31 May–2 June 2000; pp. 947–9520. [Google Scholar]
- Pratap, V.; Sriram, A.; Tomasello, P.; Hannun, A.; Liptchinsky, V.; Synnaeve, G.; Collobert, R. Massively Multilingual ASR: 50 languages, 1 model, 1 billion parameters. arXiv 2020, arXiv:2007.03001. [Google Scholar]
- Zeroth Project Homepage. Available online: https://github.com/goodatlas/zeroth (accessed on 5 August 2020).
- Ha, J.W.; Nam, K.; Kang, J.G.; Lee, S.W.; Yang, S.; Jung, H.; Kim, E.; Kim, H.; Kim, S.; Kim, H.A.; et al. ClovaCall: Korean Goal-Oriented Dialog Speech Corpus for Automatic Speech Recognition of Contact Centers. arXiv 2020, arXiv:2004.09367. [Google Scholar]
- AIHub Homepage. Available online: http://www.aihub.or.kr/aidata/105 (accessed on 5 August 2020).
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Yalta, N.; Heymann, J.; Wiesner, M.; Chen, N.; et al. ESPnet: End-to-end speech processing toolkit. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Hyderabad, India, 2–6 September 2018; pp. 2207–2211. [Google Scholar]
- Kim, S.; Hori, T.; Watanabe, S. Joint CTC-attention based end-to-end speech recognition using multi-task learning. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4835–4839. [Google Scholar]
- Watanabe, S.; Hori, T.; Kim, S.; Hershey, J.R.; Hayashi, T. Hybrid CTC/attention architecture for end-to-end speech recognition. JSTSP 2017, 11, 1240–1253. [Google Scholar] [CrossRef]
- Karita, S.; Soplin, N.E.; Watanabe, S.; Delcroix, M.; Ogawa, A.; Nakatani, T. Improving Transformer-based end-to-end speech recognition with connectionist temporal classification and language model integration. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Graz, Austria, 15–19 September 2019; pp. 1408–1412. [Google Scholar]
- Karita, S.; Chen, N.; Hayashi, T.; Hori, T.; Inaguma, H.; Jiang, Z.; Someki, M.; Soplin, N.E.; Yamamoto, R.; Wang, X.; et al. A comparative study on Transformer vs RNN in speech applications. In Proceedings of the 2019 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Singapore, 14–18 December 2019; pp. 449–456. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning (ICML), Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Graz, Austria, 15–19 September 2019; pp. 2613–2617. [Google Scholar]
- Kudo, T. Subword regularization: Improving neural network translation models with multiple subword candidates. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), Melbourne, Australia, 15–20 July 2018; pp. 66–75. [Google Scholar]
- Stolcke, A. SRILM—An extensible language modeling toolkit. In Proceedings of the 7th International Conference on Spoken Language Processing (ICSLP), Warsaw, Poland, 13–14 September 2002; pp. 901–904. [Google Scholar]
- Kudo, T.; Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing: System Demonstrations (EMNLP), Brussels, Belgium, 31 October–4 November 2018; pp. 66–71. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Librispeech Recipe. Available online: https://github.com/espnet/espnet/tree/master/egs/librispeech (accessed on 5 August 2020).
- Chorowski, J.K.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montréal, QC, Canada, 7–12 December 2015; pp. 577–585. [Google Scholar]
- Zeiler, M.D. ADADELTA: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Score Lite Toolkit. Available online: https://github.com/usnistgov/SCTK (accessed on 5 August 2020).
- Zhou, S.; Dong, L.; Xu, S.; Xu, B. A comparison of modeling units in sequence-to-sequence speech recognition with the transformer on mandarin chinese. arXiv 2018, arXiv:1805.06239. [Google Scholar]
- Kwon, O.-W.; Park, J. Korean large vocabulary continuous speech recognition with morpheme-based recognition units. Speech Commun. 2003, 39, 287–300. [Google Scholar] [CrossRef]
- Levenshtein Distance Provided on the Kaldi Toolkit. Available online: https://github.com/kaldi-asr/kaldi/blob/master/src/util/edit-distance-inl.h (accessed on 5 August 2020).


| Topic | Sub-Topic | Topic | Sub-Topic |
|---|---|---|---|
| Daily conversation | Anniversary | Weather | Hot/cold weather |
| Corporate life | Rainy/heavy snow | ||
| Reason friends | Season | ||
| Residence | Snow/rain/fog | ||
| School life | Temperature | ||
| Self-introduction | Yellow/fine dust | ||
| Shopping | Clothing | Hobbies | Blog |
| Electronics | Book | ||
| Household goods | Car | ||
| Musical Instrument | Exercise | ||
| Broadcasts | Celebrity | Exhibition | |
| Current | Food | ||
| Drama | Game | ||
| Entertainment | Music | ||
| Movie | Picture | ||
| Politics and Economy | Politics | Show | |
| Real estate | Sports | ||
| Stocks | Travel |
| Subset | Hours | No. Utterances | No. Speakers (Male/Female) | Filenames |
|---|---|---|---|---|
| Train | 965.2 | 620,000 | 2000 (923/1077) | KsponSpeech_000001–620000 |
| Dev | 3.9 | 2545 | 1348 (619/729) | KsponSpeech_620001–622545 |
| Eval-clean | 2.6 | 3000 | 60 (30/30) | KsponSpeech_E00001–E03000 |
| Eval-other | 3.8 | 3000 | 60 (30/30) | KsponSpeech_E03001–E06000 |
| Models | SpecAugment | Metric (%) | Dev | Eval-Clean | Eval-Other |
|---|---|---|---|---|---|
| RNN | No | CER | 7.7 | 9.2 | 10.6 |
| WER | 19.7 | 24.5 | 30.0 | ||
| sWER | 15.3 | 16.9 | 20.2 | ||
| Yes | CER | 7.5 | 8.6 | 9.8 | |
| WER | 19.1 | 23.2 | 28.3 | ||
| sWER | 14.7 | 15.6 | 18.5 | ||
| Transformer | No | CER | 7.2 | 8.7 | 9.7 |
| WER | 18.5 | 23.5 | 28.3 | ||
| sWER | 14.1 | 15.9 | 18.3 | ||
| Yes | CER | 6.5 | 8.0 | 9.0 | |
| WER | 17.1 | 21.9 | 26.6 | ||
| sWER | 12.7 | 14.2 | 16.5 |
| Eval Sets | Metric (%) | No. Sub-Words | ||||
|---|---|---|---|---|---|---|
| 2306 | 5000 | 8000 | 10,000 | 12,000 | ||
| Dev | CER | 6.5 | 6.9 | 6.8 | 6.8 | 7.2 |
| WER | 17.1 | 17.7 | 17.6 | 17.4 | 18.4 | |
| sWER | 12.7 | 13.4 | 13.2 | 13.2 | 14.0 | |
| Eval-clean | CER | 8.0 | 8.1 | 8.2 | 8.3 | 8.5 |
| WER | 21.9 | 22.0 | 22.1 | 22.3 | 22.7 | |
| sWER | 14.2 | 14.4 | 14.6 | 14.6 | 15.1 | |
| Eval-other | CER | 9.0 | 9.1 | 9.3 | 9.0 | 9.7 |
| WER | 26.6 | 26.5 | 27.1 | 26.5 | 27.8 | |
| sWER | 16.5 | 16.7 | 17.2 | 16.6 | 18.0 | |
| Models | Metric (%) | Dev | Eval-Clean | Eval-Other |
|---|---|---|---|---|
| Small Transformer | CER | 6.5 | 8.0 | 9.0 |
| WER | 17.1 | 21.9 | 26.6 | |
| sWER | 12.7 | 14.2 | 16.5 | |
| Large Transformer | CER | 6.1 | 7.6 | 8.5 |
| WER | 16.4 | 21.1 | 25.5 | |
| sWER | 11.9 | 13.4 | 15.4 |
| Types | Example of Transcription 1 |
|---|---|
| (a) Original | 나중에 내+ 내 목소리랑 똑같은 (AI/에이아이) 막/나오는 거 아니야? I/ |
| (b) Disfluent w/tag | 나중에 내+ 내 목소리랑 똑같은 AI 막/나오는 거 아니야 |
| (c) Fluent | 나중에 내 목소리랑 똑같은 AI 나오는 거 아니야 |
| Eval Sets | Models | Cor | Sub | Del | Ins | sWER |
|---|---|---|---|---|---|---|
| Dev | Disfluent w/tag | 88.1 | 9.4 | 2.5 | 2.5 | 14.4 |
| Fluent | 87.8 | 9.4 | 2.8 | 2.2 | 14.4 | |
| Eval-clean | Disfluent w/tag | 85.8 | 10.6 | 3.6 | 2.6 | 16.7 |
| Fluent | 85.5 | 10.4 | 4.4 | 2.0 | 16.5 | |
| Eval-other | Disfluent w/tag | 84.9 | 12.1 | 3.0 | 2.6 | 17.6 |
| Fluent | 84.6 | 12.0 | 3.4 | 2.4 | 17.8 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bang, J.-U.; Yun, S.; Kim, S.-H.; Choi, M.-Y.; Lee, M.-K.; Kim, Y.-J.; Kim, D.-H.; Park, J.; Lee, Y.-J.; Kim, S.-H. KsponSpeech: Korean Spontaneous Speech Corpus for Automatic Speech Recognition. Appl. Sci. 2020, 10, 6936. https://doi.org/10.3390/app10196936
Bang J-U, Yun S, Kim S-H, Choi M-Y, Lee M-K, Kim Y-J, Kim D-H, Park J, Lee Y-J, Kim S-H. KsponSpeech: Korean Spontaneous Speech Corpus for Automatic Speech Recognition. Applied Sciences. 2020; 10(19):6936. https://doi.org/10.3390/app10196936
Chicago/Turabian StyleBang, Jeong-Uk, Seung Yun, Seung-Hi Kim, Mu-Yeol Choi, Min-Kyu Lee, Yeo-Jeong Kim, Dong-Hyun Kim, Jun Park, Young-Jik Lee, and Sang-Hun Kim. 2020. "KsponSpeech: Korean Spontaneous Speech Corpus for Automatic Speech Recognition" Applied Sciences 10, no. 19: 6936. https://doi.org/10.3390/app10196936
APA StyleBang, J.-U., Yun, S., Kim, S.-H., Choi, M.-Y., Lee, M.-K., Kim, Y.-J., Kim, D.-H., Park, J., Lee, Y.-J., & Kim, S.-H. (2020). KsponSpeech: Korean Spontaneous Speech Corpus for Automatic Speech Recognition. Applied Sciences, 10(19), 6936. https://doi.org/10.3390/app10196936