An Efficient Radio Frequency Interference (RFI) Recognition and Characterization Using End-to-End Transfer Learning

Abstract
1. Introduction
2. Related Works
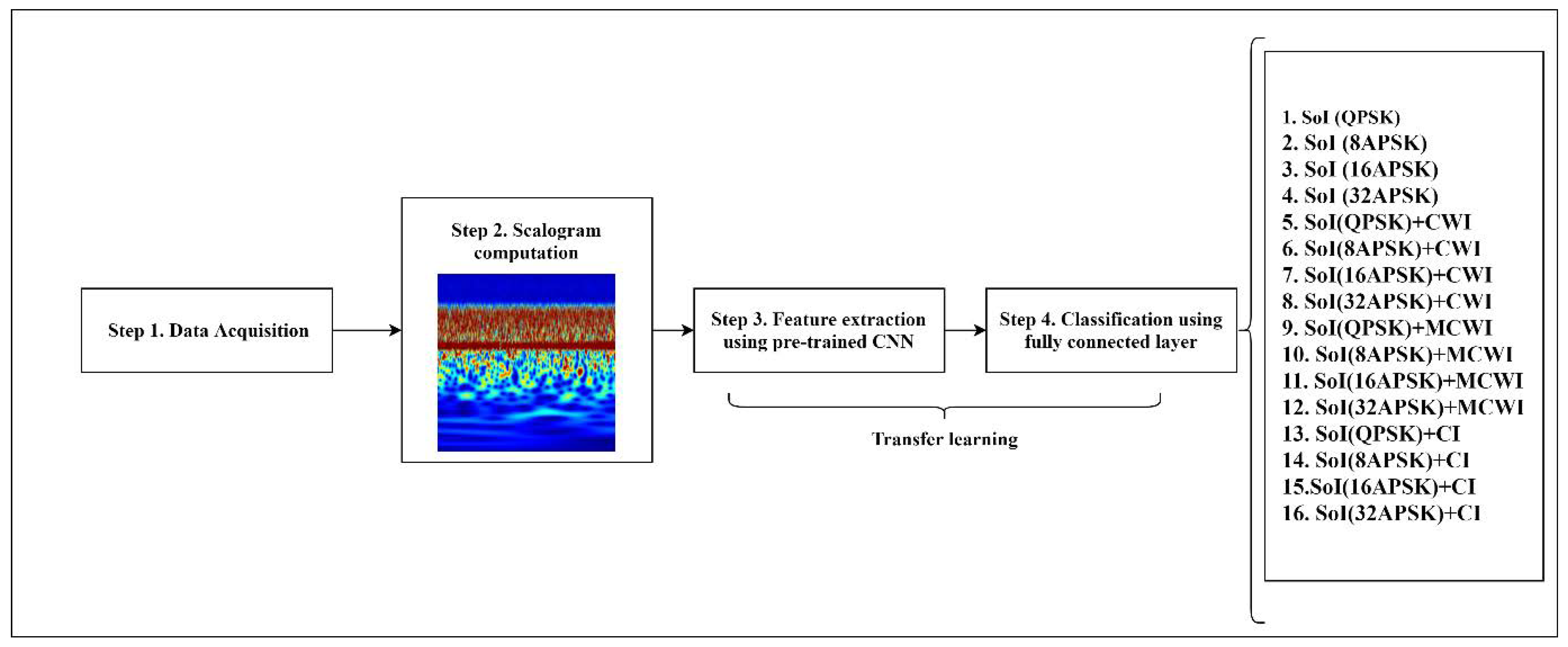
3. Proposed Methodology
3.1. Data Acquisition Set-Up
- (1)
- Continuous Wave Interference (CWI):where and t represent the center frequency and the duration of interference respectively.
- (2)
- Multi Continuous Wave Interference (MCWI): In this study, we have considered two-tone CW, which is defined as:where and are the center frequencies of each wave.
- (3)
- Chirp Interference (CI): The CI has been generated according to [24] as follows:where so that the signal sweeps from to and T is the sweeping duration.
Dataset Generation
3.2. Transfer Learning Process
- Training the entire dataset: The pretrained CNN can be trained from scratch using a new dataset. Therefore, a large dataset and lots of computational power are required.
- Training some layers and leaving the others frozen: As the lower layers extract the general features while higher layers represent the most specific features, it can be decided how many layers need to be retrained depending on the application. For a small dataset with a large number of parameters, it is efficient to leave more layers frozen. Because the frozen layers are kept unchanged during the training process to avoid overfitting. On the other hand, for a large dataset with a small number of parameters, training more layers would be reasonable to the new task, since overfitting is not an issue.
- Freezing the convolutional part: In this scenario, the convolutional part can be kept unchanged, and its output can be fed to a new classifier. In other words, the pretrained model is considered as a fixed feature extraction basis, which is beneficial in case of having a small dataset and suffering from a lack of computational power. Notably, in this study, we have applied this strategy.
3.2.1. Pretrained CNNs
- AlexNet: In 2012, AlexNet could outperform other prior architectures in ImageNet LSVRC-2012 competition, designed by the SuperVision group [9]. AlexNet includes five convolutional layers and three FC layers in which Relu is applied after every convolutional and FC layer. In addition, the dropout technique is applied before the first and the second FC layer [9].
- GoogleNet: GoogleNet won ILSVRC 2014 competition with a high precision close to human perception. Its architecture has taken benefits of several small convolutions to reduce the number of parameters drastically. It consists of a 22-layer deep CNN, but it decreased the number of parameters from 60 million (in AlexNet) to 4 million [31].
3.2.2. Fully Connected (FC) Layer
4. Results And Discussion
4.1. Simulation Results for RFI Classification
4.2. Simulation Results of AMC
4.3. Prediction Phase
5. Conclusions
6. Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Weerasinghe, S.; Alpcan, T.; Erfani, S.M.; Leckie, C.; Pourbeik, P.; Riddle, J. Deep learning based game-theoretical approach to evade jamming attacks. In Proceedings of the International Conference on Decision and Game Theory for Security, Seattle, WA, USA, 29–31 October 2018; Springer: Cham, Switzerland, 2018; pp. 386–397. [Google Scholar]
- Geier, J. Wireless LAN Implications, Problems, and Solutions. Available online: http://www.ciscopress.com/articles/article.asp?p=2351131&seqNum=2 (accessed on 10 February 2020).
- Grover, K.; Lim, A.; Yang, Q. Jamming and anti-jamming techniques in wireless networks: A survey. Int. J. Ad Hoc Ubiquitous Comput. 2014, 17, 197–215. [Google Scholar] [CrossRef]
- Dobre, O.A.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137–156. [Google Scholar] [CrossRef]
- Ujan, S.; Same, M.H.; Landry, R., Jr. A Robust Jamming Signal Classification and Detection Approach Based on Multi-Layer Perceptron Neural Network. Int. J. Res. Stud. Comput. Sci. Eng. (IJRSCSE) 2020, 7, 1–12. [Google Scholar] [CrossRef]
- Ujan, S.; Navidi, N. Hierarchical Classification Method for Radio Frequency Interference Recognition and Characterization. Appl. Sci. 2020, 10, 4608. [Google Scholar] [CrossRef]
- Khan, S.; Islam, N.; Jan, Z.; Din, I.U.; Rodrigues, J.J.C. A novel deep learning based framework for the detection and classification of breast cancer using transfer learning. Pattern Recognit. Lett. 2019, 125, 1–6. [Google Scholar] [CrossRef]
- Lateef, A.A.A.; Al-Janabi, S.; Al-Khateeb, B. Survey on intrusion detection systems based on deep learning. Period. Eng. Nat. Sci. 2019, 7, 1074–1095. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; NIPS: Lake Tahoe, NV, USA, 2012; pp. 1097–1105. [Google Scholar]
- Hagos, M.T.; Kant, S. Transfer Learning based Detection of Diabetic Retinopathy from Small Dataset. arXiv 2019, arXiv:1905.07203. [Google Scholar]
- Marcelino, P. Transfer Learning from Pre-Trained Models. Towards Data Science. Available online: https://towardsdatascience.com/transfer-learning-from-pre-trained-models-f2393f124751 (accessed on 15 January 2020).
- Stevens, D.L.; Schuckers, S.A. Low probability of intercept frequency hopping signal characterization comparison using the spectrogram and the scalogram. Glob. J. Res. Eng. 2016, 16, 1–12. [Google Scholar] [CrossRef]
- Zhang, L.; You, W.; Wu, Q.; Qi, S.; Ji, Y. Deep learning-based automatic clutter/interference detection for HFSWR. Remote Sens. 2018, 10, 1517. [Google Scholar] [CrossRef]
- Yang, Z.; Yu, C.; Xiao, J.; Zhang, B. Deep residual detection of radio frequency interference for FAST. Mon. Not. R. Astron. Soc. 2020, 492, 1421–1431. [Google Scholar] [CrossRef]
- Gecgel, S.; Goztepe, C.; Kurt, G.K. Jammer detection based on artificial neural networks: A measurement study. In Proceedings of the ACM Workshop on Wireless Security and Machine Learning, Miami, FL, USA, 15–17 May 2019; pp. 43–48. [Google Scholar]
- Ramjee, S.; Ju, S.; Yang, D.; Liu, X.; Gamal, A.E.; Eldar, Y.C. Fast deep learning for automatic modulation classification. arXiv 2019, arXiv:1901.05850. [Google Scholar]
- Jiang, K.; Zhang, J.; Wu, H.; Wang, A.; Iwahori, Y. A Novel Digital Modulation Recognition Algorithm Based on Deep Convolutional Neural Network. Appl. Sci. 2020, 10, 1166. [Google Scholar] [CrossRef]
- Karra, K.; Kuzdeba, S.; Petersen, J. Modulation recognition using hierarchical deep neural networks. In Proceedings of the 2017 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Piscataway, NJ, USA, 6–9 March 2017; pp. 1–3. [Google Scholar]
- Yang, C.; He, Z.; Peng, Y.; Wang, Y.; Yang, J. Deep Learning Aided Method for Automatic Modulation Recognition. IEEE Access 2019, 7, 109063–109068. [Google Scholar] [CrossRef]
- Shi, J.; Hong, S.; Cai, C.; Wang, Y.; Huang, H.; Gui, G. Deep Learning-Based Automatic Modulation Recognition Method in the Presence of Phase Offset. IEEE Access 2020, 8, 42841–42847. [Google Scholar] [CrossRef]
- Zhang, D.; Ding, W.; Zhang, B.; Xie, C.; Li, H.; Liu, C.; Han, J. Automatic modulation classification based on deep learning for unmanned aerial vehicles. Sensors 2018, 18, 924. [Google Scholar] [CrossRef] [PubMed]
- National Instruments. USRP N210 Kit. Available online: http://www.ettus.com/all-products/un210-kit/ (accessed on 15 January 2020).
- Solutions, K.D.S. T400CS Channel Simulator. Available online: http://www.rtlogic.com/products/rf-link-monitoring-and-protection-products/t400cs-channel-simulator (accessed on 28 August 2019).
- Smyth, T. CMPT 468:Frequency Modulation (FM) Synthesis; School of Computing Science, Simon Fraser University: Burnaby, BC, Canada, 2013. [Google Scholar]
- Yuan, Y.; Xun, G.; Jia, K.; Zhang, A. A multi-context learning approach for EEG epileptic seizure detection. BMC Syst. Biol. 2018, 12, 107. [Google Scholar] [CrossRef] [PubMed]
- Lenoir, G.; Crucifix, M. A general theory on frequency and time–frequency analysis of irregularly sampled time series based on projection methods–Part 1: Frequency analysis. Nonlinear Process. Geophys. 2018, 25, 145. [Google Scholar] [CrossRef]
- Lilly, J.M.; Olhede, S.C. Generalized Morse wavelets as a superfamily of analytic wavelets. IEEE Trans. Signal Process. 2012, 60, 6036–6041. [Google Scholar] [CrossRef]
- Pan, J.; Yang, Q. Feature-Based Transfer Learning with Real-World Applications; Hong Kong University of Science and Technology: Hong Kong, China, 2010. [Google Scholar]
- Raykar, V.C.; Krishnapuram, B.; Bi, J.; Dundar, M.; Rao, R.B. Bayesian multiple instance learning: Automatic feature selection and inductive transfer. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 808–815. [Google Scholar]
- MathWorks. Image Category Classification Using Deep Learning. Available online: https://www.mathworks.com/help/vision/examples/image-category-classification-using-deep-learning.html (accessed on 25 March 2020).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- MathWorks. Convolution2dLayer. Available online: https://www.mathworks.com/help/deeplearning/ref/nnet.cnn.layer.convolution2dlayer.html (accessed on 15 January 2020).
- Pokharna, H. The Best Explanation of Convolutional Neural Networks on the Internet! Available online: https://medium.com/technologymadeeasy/the-best-explanation-of-convolutional-neural-networks-on-the-internet-fbb8b1ad5df8 (accessed on 15 January 2020).
- Reddy, S.; Reddy, K.T.; ValliKumari, V. Optimization of Deep Learning Using Various Optimizers, Loss Functions and Dropout. Int. J. Recent Technol. Eng. 2018, 7, 448–455. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Value |
|---|---|
| Total number of observations | 4800 |
| Length of each generated signal | 32,448 (8 ms) |
| Sampling frequency | 40 × 10 Hz |
| Modulation types | QPSK, 8APSK, 16APSK, and 32APSK |
| AWGN power | 140 dBm ( 9 dB) |
| No. of each class of signals per modulation type | 300 |
| AWGN Power (dBm) | −140 | −135 | −130 | −125 |
|---|---|---|---|---|
| AlexNet | 89.80% | 79.13% | 76.44% | 74.55% |
| VGG16 | 95.51% | 80.90% | 78.77% | 77% |
| GoogleNet | 90% | 78.80% | 74.53% | 72.80% |
| ResNet18 | 91.90% | 80.88% | 76% | 74.32% |
| AWGN Power (dBm) | −140 | −135 | −130 | −125 |
|---|---|---|---|---|
| AlexNet | 94% | 84% | 52% | 45.50% |
| VGG16 | 85.50% | 53% | 48.70% | 42.25% |
| GoogleNet | 87% | 56.25% | 38.25% | 36.50% |
| ResNet18 | 92.41% | 56.25% | 42.25% | 40.70% |
| AWGN Power (dBm) | −140 | −135 | −130 | −125 |
|---|---|---|---|---|
| AlexNet | 90.03% | 58.50% | 40% | 37.50% |
| VGG16 | 85.83% | 52% | 41% | 31.50% |
| GoogleNet | 87.88% | 55.60% | 44.13% | 39.50% |
| ResNet18 | 91.03% | 69% | 50% | 40.50% |
| AWGN Power (dBm) | −140 | −135 | −130 | −125 |
|---|---|---|---|---|
| AlexNet | 70.25% | 58.50% | 31.50% | 24.90% |
| VGG16 | 71.91% | 69.50% | 50.50% | 40% |
| GoogleNet | 67.50% | 62% | 41% | 31% |
| ResNet18 | 70.91% | 64% | 45% | 37% |
| AWGN Power (dBm) | −140 | −135 | −130 | −125 |
|---|---|---|---|---|
| AlexNet | 78.60% | 55% | 52% | 45% |
| VGG16 | 77% | 56% | 53% | 44% |
| GoogleNet | 76.70% | 56.50% | 50.50% | 43% |
| ResNet18 | 80% | 59.50% | 58% | 47% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ujan, S.; Navidi, N.; Jr Landry, R. An Efficient Radio Frequency Interference (RFI) Recognition and Characterization Using End-to-End Transfer Learning. Appl. Sci. 2020, 10, 6885. https://doi.org/10.3390/app10196885
Ujan S, Navidi N, Jr Landry R. An Efficient Radio Frequency Interference (RFI) Recognition and Characterization Using End-to-End Transfer Learning. Applied Sciences. 2020; 10(19):6885. https://doi.org/10.3390/app10196885
Chicago/Turabian StyleUjan, Sahar, Neda Navidi, and Rene Jr Landry. 2020. "An Efficient Radio Frequency Interference (RFI) Recognition and Characterization Using End-to-End Transfer Learning" Applied Sciences 10, no. 19: 6885. https://doi.org/10.3390/app10196885
APA StyleUjan, S., Navidi, N., & Jr Landry, R. (2020). An Efficient Radio Frequency Interference (RFI) Recognition and Characterization Using End-to-End Transfer Learning. Applied Sciences, 10(19), 6885. https://doi.org/10.3390/app10196885