A Comprehensive Study on Deep Learning-Based 3D Hand Pose Estimation Methods

 , ,
, ,  ,
,  and
and
Abstract
1. Introduction
- High articulation: A human hand has more than 20 degrees of freedom (DOF) [20], therefore, a lot of parameters are needed in order to properly model the complexity of hand, as well as finger movements.
- Occlusions: During the performance of a gesture, fingers of the same hand may be strongly occluded by each other, other body parts, or objects. This could potentially result in hidden hand parts or different fingers mistakenly inferred in the same location.
- Low resolution: The size of a hand, let alone a finger, occupy a small area in an RGB image or a depth map, if it is not the focus of attention or there is some distance between the camera and the hand. Additionally, limitations in camera technologies (e.g., lens resolution, depth sensing capabilities) may lead to inaccurate data, further hindering the results of hand pose estimation methods.
- Annotated data: The creation of annotated 3D data is a costly and time-consuming task. In order to capture accurate 3D data, an expensive marker-based motion capture system or a massive multi-view camera setting is required [21].
- Rapid hand and finger movements: Usually, hand motion is highly non-monotonic and consists of very fast movements, sudden stops, and joint rotations that are not met in other body parts. Currently, most conventional depth and RGB cameras can support 30 to 60 frames per second (fps) but still fall short to capture the speed of hand motions, resulting in blurry frames or uncorrelated consecutive frames.
- We provide a comprehensive overview of the modern deep learning methods on 3D hand pose estimation, along with a brief overview of earlier machine learning methods for context. For each presented work, we describe the proposed method and the network architecture.
- We propose a new taxonomy for a better categorization and presentation of deep-learning-based 3D hand pose estimation methods. More specifically, in this paper, the following three categories are used: RGB-based, depth-based, and multimodal approaches.
- We present the most significant datasets employed by the research community, along with state-of-the-art results on each one.
- We draw conclusions and suggest possible future directions in terms of datasets and model architectures.
2. Previous Categorizations and Early Machine Learning Methods
2.1. Previously Proposed Categorizations
2.2. Early Machine Learning Methods
3. Deep Learning Methods
3.1. Depth-Based Approaches
3.1.1. 2D Depth Map Utilization
3.1.2. 3D Representation Utilization
3.2. RGB-Based Approaches
3.2.1. Model-Free Approaches
3.2.2. Model-Based Approaches
3.3. Multimodal Approaches
3.3.1. Unimodal Inference
3.3.2. Multimodal Inference
4. Datasets & Metrics
4.1. Datasets
4.2. Metrics
5. Conclusions and Future Directions
Author Contributions
Funding
Conflicts of Interest
References
- Piumsomboon, T.; Clark, A.; Billinghurst, M.; Cockburn, A. User-defined gestures for augmented reality. In Proceedings of the 14th IFIP TC 13 International Conference on Human-Computer Interaction, Cape Town, South Africa, 2–6 September 2013; Springer: Berlin, Germany, 2013; pp. 282–299. [Google Scholar]
- Lee, T.; Hollerer, T. Multithreaded hybrid feature tracking for markerless augmented reality. IEEE Trans. Vis. Comput. Graph. 2009, 15, 355–368. [Google Scholar]
- Jang, Y.; Noh, S.T.; Chang, H.J.; Kim, T.K.; Woo, W. 3d finger cape: Clicking action and position estimation under self-occlusions in egocentric viewpoint. IEEE Trans. Vis. Comput. Graph. 2015, 21, 501–510. [Google Scholar]
- Kordelas, G.; Agapito, J.P.M.; Hernandez, J.V.; Daras, P. State-of-the-art algorithms for complete 3d model reconstruction. In Proceedings of the Summer School ENGAGE-Immersive and Engaging Interaction with VH on Internet, Zermatt, Switzerland, 13–15 September 2010; Volume 1315, p. 115. [Google Scholar]
- Alexiadis, D.S.; Daras, P. Quaternionic signal processing techniques for automatic evaluation of dance performances from MoCap data. IEEE Trans. Multimed. 2014, 16, 1391–1406. [Google Scholar]
- Alivizatou-Barakou, M.; Kitsikidis, A.; Tsalakanidou, F.; Dimitropoulos, K.; Giannis, C.; Nikolopoulos, S.; Al Kork, S.; Denby, B.; Buchman, L.; Adda-Decker, M.; et al. Intangible cultural heritage and new technologies: Challenges and opportunities for cultural preservation and development. In Mixed Reality and Gamification for Cultural Heritage; Springer: New York, NY, USA, 2017; pp. 129–158. [Google Scholar]
- Dimitropoulos, K.; Tsalakanidou, F.; Nikolopoulos, S.; Kompatsiaris, I.; Grammalidis, N.; Manitsaris, S.; Denby, B.; Crevier-Buchman, L.; Dupont, S.; Charisis, V.; et al. A multimodal approach for the safeguarding and transmission of intangible cultural heritage: The case of i-Treasures. IEEE Intell. Syst. 2018, 33, 3–16. [Google Scholar]
- Caggianese, G.; Capece, N.; Erra, U.; Gallo, L.; Rinaldi, M. Freehand-Steering Locomotion Techniques for Immersive Virtual Environments: A Comparative Evaluation. Int. J. Hum.–Comput. Interact. 2020, 36, 1734–1755. [Google Scholar]
- Kopuklu, O.; Kose, N.; Rigoll, G. Motion fused frames: Data level fusion strategy for hand gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2103–2111. [Google Scholar]
- Abavisani, M.; Joze, H.R.V.; Patel, V.M. Improving the performance of unimodal dynamic hand-gesture recognition with multimodal training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1165–1174. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Advances in Neural Information Processing Systems; MIT Press: Montreal, QC, Canada, 2014; pp. 568–576. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Baulig, G.; Gulde, T.; Curio, C. Adapting egocentric visual hand pose estimation towards a robot-controlled exoskeleton. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Papastratis, I.; Dimitropoulos, K.; Konstantinidis, D.; Daras, P. Continuous Sign Language Recognition Through Cross-Modal Alignment of Video and Text Embeddings in a Joint-Latent Space. IEEE Access 2020, 8, 91170–91180. [Google Scholar]
- Koller, O.; Camgoz, C.; Ney, H.; Bowden, R. Weakly Supervised Learning with Multi-Stream CNN-LSTM-HMMs to Discover Sequential Parallelism in Sign Language Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2306–2320. [Google Scholar]
- Adaloglou, N.; Chatzis, T.; Papastratis, I.; Stergioulas, A.; Papadopoulos, G.T.; Zacharopoulou, V.; Xydopoulos, G.J.; Atzakas, K.; Papazachariou, D.; Daras, P. A Comprehensive Study on Sign Language Recognition Methods. arXiv 2020, arXiv:2007.12530. [Google Scholar]
- Konstantinidis, D.; Dimitropoulos, K.; Daras, P. A deep learning approach for analyzing video and skeletal features in sign language recognition. In Proceedings of the 2018 IEEE International Conference on Imaging Systems and Techniques (IST), Krakow, Poland, 16–18 October 2018; IEEE: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Konstantinidis, D.; Dimitropoulos, K.; Daras, P. Sign language recognition based on hand and body skeletal data. In Proceedings of the 2018-3DTV-Conference: The True Vision-Capture, Transmission and Display of 3D Video (3DTV-CON), Helsinki, Finland, 3–5 June 2018; IEEE: New York, NY, USA, 2018; pp. 1–4. [Google Scholar]
- Stefanidis, K.; Konstantinidis, D.; Kalvourtzis, A.; Dimitropoulos, K.; Daras, P. 3D Technologies and Applications in Sign Language. In Recent Advances in 3D Imaging, Modeling, and Reconstruction; IGI Global: Hersey, PA, USA, 2020; pp. 50–78. [Google Scholar]
- Erol, A.; Bebis, G.; Nicolescu, M.; Boyle, R.D.; Twombly, X. Vision-based hand pose estimation: A review. Comput. Vis. Image Underst. 2007, 108, 52–73. [Google Scholar]
- Joo, H.; Simon, T.; Li, X.; Liu, H.; Tan, L.; Gui, L.; Banerjee, S.; Godisart, T.; Nabbe, B.; Matthews, I.; et al. Panoptic studio: A massively multiview system for social interaction capture. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 190–204. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Communications of the ACM: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; Communications of the ACM: New York, NY, USA, 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Cao, Z.; Simon, T.; Wei, S.; Sheikh, Y.A. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Xiang, D.; Joo, H.; Sheikh, Y. Monocular total capture: Posing face, body, and hands in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10965–10974. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1995; Volume 3361, p. 1995. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems, Proceedings of the 2001 Neural Information Processing Systems (NIPS) Conference, Vancouver, BC, Canada, 3–8 December 2001; A Bradford Book: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Hands deep in deep learning for hand pose estimation. arXiv 2015, arXiv:1502.06807. [Google Scholar]
- Ge, L.; Cai, Y.; Weng, J.; Yuan, J. Hand pointnet: 3d hand pose estimation using point sets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8417–8426. [Google Scholar]
- Wang, Y.; Peng, C.; Liu, Y. Mask-pose cascaded cnn for 2d hand pose estimation from single color image. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3258–3268. [Google Scholar] [CrossRef]
- Gao, Q.; Liu, J.; Ju, Z. Robust real-time hand detection and localization for space human–robot interaction based on deep learning. Neurocomputing 2019, 390, 198–206. [Google Scholar] [CrossRef]
- Yuan, S.; Garcia-Hernando, G.; Stenger, B.; Moon, G.; Yong Chang, J.; Mu Lee, K.; Molchanov, P.; Kautz, J.; Honari, S.; Ge, L.; et al. Depth-based 3d hand pose estimation: From current achievements to future goals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2636–2645. [Google Scholar]
- Supancic, J.S.; Rogez, G.; Yang, Y.; Shotton, J.; Ramanan, D. Depth-based hand pose estimation: Data, methods, and challenges. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1868–1876. [Google Scholar]
- Tang, D.; Jin Chang, H.; Tejani, A.; Kim, T.K. Latent regression forest: Structured estimation of 3d articulated hand posture. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3786–3793. [Google Scholar]
- Tompson, J.; Stein, M.; Lecun, Y.; Perlin, K. Real-time continuous pose recovery of human hands using convolutional networks. ACM Trans. Graph. (ToG) 2014, 33, 1–10. [Google Scholar] [CrossRef]
- Zimmermann, C.; Brox, T. Learning to estimate 3d hand pose from single rgb images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4903–4911. [Google Scholar]
- Zhang, J.; Jiao, J.; Chen, M.; Qu, L.; Xu, X.; Yang, Q. A hand pose tracking benchmark from stereo matching. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: New York, NY, USA, 2017; pp. 982–986. [Google Scholar]
- Yuan, S.; Ye, Q.; Garcia-Hernando, G.; Kim, T.K. The 2017 hands in the million challenge on 3d hand pose estimation. arXiv 2017, arXiv:1707.02237. [Google Scholar]
- Otberdout, N.; Ballihi, L.; Aboutajdine, D. Hand pose estimation based on deep learning depth map for hand gesture recognition. In Proceedings of the 2017 Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 17–19 April 2017; IEEE: New York, NY, USA, 2017; pp. 1–8. [Google Scholar]
- Liang, H.; Wang, J.; Sun, Q.; Liu, Y.J.; Yuan, J.; Luo, J.; He, Y. Barehanded music: Real-time hand interaction for virtual piano. In Proceedings of the 20th ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games, Redmond, WA, USA, 27 February 2016; pp. 87–94. [Google Scholar]
- Liang, H.; Yuan, J.; Lee, J.; Ge, L.; Thalmann, D. Hough forest with optimized leaves for global hand pose estimation with arbitrary postures. IEEE Trans. Cybern. 2017, 49, 527–541. [Google Scholar] [CrossRef]
- Spurr, A.; Song, J.; Park, S.; Hilliges, O. Cross-modal deep variational hand pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 89–98. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. Real-time 3D hand pose estimation with 3D convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 956–970. [Google Scholar] [CrossRef]
- Abdi, M.; Abbasnejad, E.; Lim, C.P.; Nahavandi, S. 3d hand pose estimation using simulation and partial-supervision with a shared latent space. arXiv 2018, arXiv:1807.05380. [Google Scholar]
- Baek, S.; In Kim, K.; Kim, T.K. Augmented skeleton space transfer for depth-based hand pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8330–8339. [Google Scholar]
- Liang, H.; Yuan, J.; Thalmann, D.; Zhang, Z. Model-based hand pose estimation via spatial-temporal hand parsing and 3D fingertip localization. Vis. Comput. 2013, 29, 837–848. [Google Scholar] [CrossRef]
- Taylor, J.; Stebbing, R.; Ramakrishna, V.; Keskin, C.; Shotton, J.; Izadi, S.; Hertzmann, A.; Fitzgibbon, A. User-specific hand modeling from monocular depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 644–651. [Google Scholar]
- Melax, S.; Keselman, L.; Orsten, S. Dynamics based 3D skeletal hand tracking. In Proceedings of the ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games, Orlando, FL, USA, 21 March 2013; p. 184. [Google Scholar]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A.A. Efficient model-based 3D tracking of hand articulations using Kinect. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; Volume 1, p. 3. [Google Scholar]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A.A. Tracking the articulated motion of two strongly interacting hands. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: New Yorky, NY, USA, 2012; pp. 1862–1869. [Google Scholar]
- Oikonomidis, I.; Lourakis, M.I.; Argyros, A.A. Evolutionary quasi-random search for hand articulations tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 3422–3429. [Google Scholar]
- Roditakis, K.; Makris, A.; Argyros, A.A. Generative 3D Hand Tracking with Spatially Constrained Pose Sampling. In Proceedings of the British Machine Vision Conference, London, UK, 7–10 September 2017; Volume 1, p. 2. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; IEEE: New York, NY, USA, 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Tagliasacchi, A.; Schröder, M.; Tkach, A.; Bouaziz, S.; Botsch, M.; Pauly, M. Robust articulated-ICP for real-time hand tracking. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2015; Volume 34, pp. 101–114. [Google Scholar]
- Sinha, A.; Choi, C.; Ramani, K. Deephand: Robust hand pose estimation by completing a matrix imputed with deep features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4150–4158. [Google Scholar]
- Sun, X.; Wei, Y.; Liang, S.; Tang, X.; Sun, J. Cascaded hand pose regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 824–832. [Google Scholar]
- Moon, G.; Yong Chang, J.; Mu Lee, K. V2v-posenet: Voxel-to-voxel prediction network for accurate 3d hand and human pose estimation from a single depth map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5079–5088. [Google Scholar]
- Wan, C.; Probst, T.; Van Gool, L.; Yao, A. Crossing nets: Combining gans and vaes with a shared latent space for hand pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 680–689. [Google Scholar]
- Yang, H.; Zhang, J. Hand pose regression via a classification-guided approach. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Cham, Switzerland, 2016; pp. 452–466. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. Robust 3d hand pose estimation in single depth images: From single-view cnn to multi-view cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3593–3601. [Google Scholar]
- Keskin, C.; Kıraç, F.; Kara, Y.E.; Akarun, L. Real time hand pose estimation using depth sensors. In Consumer Depth Cameras for Computer Vision; Springer: New York, NY, USA, 2013; pp. 119–137. [Google Scholar]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; IEEE: New York, NY, USA, 2011; pp. 1297–1304. [Google Scholar]
- Athitsos, V.; Sclaroff, S. Estimating 3D hand pose from a cluttered image. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; IEEE: New York, NY, USA, 2003; Volume 2, pp. II–432. [Google Scholar]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A.A. Markerless and efficient 26-dof hand pose recovery. In Proceedings of the 10th Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; Springer: Berlin, Germany, 2010; pp. 744–757. [Google Scholar]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A.A. Full dof tracking of a hand interacting with an object by modeling occlusions and physical constraints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: New York, NY, USA, 2011; pp. 2088–2095. [Google Scholar]
- Wang, R.Y.; Popović, J. Real-time hand-tracking with a color glove. ACM Trans. Graph. (TOG) 2009, 28, 1–8. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Keskin, C.; Kıraç, F.; Kara, Y.E.; Akarun, L. Hand pose estimation and hand shape classification using multi-layered randomized decision forests. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin, Germany, 2012; pp. 852–863. [Google Scholar]
- Tang, D.; Yu, T.H.; Kim, T.K. Real-time articulated hand pose estimation using semi-supervised transductive regression forests. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3224–3231. [Google Scholar]
- Liang, H.; Yuan, J.; Thalmann, D. Parsing the hand in depth images. IEEE Trans. Multimed. 2014, 16, 1241–1253. [Google Scholar] [CrossRef]
- Dollár, P.; Welinder, P.; Perona, P. Cascaded pose regression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: New York, NY, USA, 2010; pp. 1078–1085. [Google Scholar]
- Sridhar, S.; Oulasvirta, A.; Theobalt, C. Interactive markerless articulated hand motion tracking using RGB and depth data. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2456–2463. [Google Scholar]
- Tkach, A.; Pauly, M.; Tagliasacchi, A. Sphere-meshes for real-time hand modeling and tracking. ACM Trans. Graph. (ToG) 2016, 35, 1–11. [Google Scholar] [CrossRef]
- Tzionas, D.; Ballan, L.; Srikantha, A.; Aponte, P.; Pollefeys, M.; Gall, J. Capturing hands in action using discriminative salient points and physics simulation. Int. J. Comput. Vis. 2016, 118, 172–193. [Google Scholar] [CrossRef]
- Romero, J.; Tzionas, D.; Black, M.J. Embodied hands: Modeling and capturing hands and bodies together. ACM Trans. Graph. (ToG) 2017, 36, 245. [Google Scholar] [CrossRef]
- Oberweger, M.; Lepetit, V. Deepprior++: Improving fast and accurate 3d hand pose estimation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 585–594. [Google Scholar]
- Zhou, Y.; Lu, J.; Du, K.; Lin, X.; Sun, Y.; Ma, X. Hbe: Hand branch ensemble network for real-time 3d hand pose estimation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 501–516. [Google Scholar]
- Rad, M.; Oberweger, M.; Lepetit, V. Feature mapping for learning fast and accurate 3d pose inference from synthetic images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4663–4672. [Google Scholar]
- Du, K.; Lin, X.; Sun, Y.; Ma, X. Crossinfonet: Multi-task information sharing based hand pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9896–9905. [Google Scholar]
- Ren, P.; Sun, H.; Qi, Q.; Wang, J.; Huang, W. SRN: Stacked Regression Network for Real-time 3D Hand Pose Estimation. In Proceedings of the 30th British Machine Vision Conference 2019, BMVC 2019, Cardiff, UK, 9–12 September 2019; p. 112. [Google Scholar]
- Zhou, X.; Wan, Q.; Zhang, W.; Xue, X.; Wei, Y. Model-based Deep Hand Pose Estimation. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Šarić, M. LibHand: A Library for Hand Articulation. Version 0.9. Available online: http://www.libhand.org/ (accessed on 31 July 2020).
- Malik, J.; Elhayek, A.; Stricker, D. Simultaneous hand pose and skeleton bone-lengths estimation from a single depth image. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; IEEE: New York, NY, USA, 2017; pp. 557–565. [Google Scholar]
- Malik, J.; Elhayek, A.; Stricker, D. Structure-aware 3d hand pose regression from a single depth image. In Proceedings of the International Conference on Virtual Reality and Augmented Reality, London, UK, 22–23 October 2018; Springer: Cham, Switzerland, 2018; pp. 3–17. [Google Scholar]
- Malik, J.; Elhayek, A.; Nunnari, F.; Varanasi, K.; Tamaddon, K.; Heloir, A.; Stricker, D. Deephps: End-to-end estimation of 3d hand pose and shape by learning from synthetic depth. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; IEEE: New York, NY, USA, 2018; pp. 110–119. [Google Scholar]
- Malik, J.; Elhayek, A.; Stricker, D. WHSP-Net: A Weakly-Supervised Approach for 3D Hand Shape and Pose Recovery from a Single Depth Image. Sensors 2019, 19, 3784. [Google Scholar] [CrossRef]
- Wan, C.; Probst, T.; Gool, L.V.; Yao, A. Self-supervised 3d hand pose estimation through training by fitting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10853–10862. [Google Scholar]
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Training a feedback loop for hand pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3316–3324. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 700–708. [Google Scholar]
- Wan, C.; Probst, T.; Van Gool, L.; Yao, A. Dense 3d regression for hand pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5147–5156. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Ge, L.; Ren, Z.; Yuan, J. Point-to-point regression pointnet for 3d hand pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 475–491. [Google Scholar]
- Xiong, F.; Zhang, B.; Xiao, Y.; Cao, Z.; Yu, T.; Zhou, J.T.; Yuan, J. A2j: Anchor-to-joint regression network for 3d articulated pose estimation from a single depth image. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 793–802. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Chen, X.; Wang, G.; Zhang, C.; Kim, T.K.; Ji, X. Shpr-net: Deep semantic hand pose regression from point clouds. IEEE Access 2018, 6, 43425–43439. [Google Scholar] [CrossRef]
- Zhu, T.; Sun, Y.; Ma, X.; Lin, X. Hand Pose Ensemble Learning Based on Grouping Features of Hand Point Sets. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Li, S.; Lee, D. Point-to-pose voting based hand pose estimation using residual permutation equivariant layer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11927–11936. [Google Scholar]
- Ravanbakhsh, S.; Schneider, J.; Póczos, B. Deep Learning with Sets and Point Clouds. arXiv 2017, arXiv:1611.04500. [Google Scholar]
- Chen, Y.; Tu, Z.; Ge, L.; Zhang, D.; Chen, R.; Yuan, J. So-handnet: Self-organizing network for 3d hand pose estimation with semi-supervised learning. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 6961–6970. [Google Scholar]
- Li, J.; Chen, B.M.; Hee Lee, G. So-net: Self-organizing network for point cloud analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9397–9406. [Google Scholar]
- Kohonen, T.; Honkela, T. Kohonen network. Scholarpedia 2007, 2, 1568. [Google Scholar]
- Huang, F.; Zeng, A.; Liu, M.; Qin, J.; Xu, Q. Structure-aware 3d hourglass network for hand pose estimation from single depth image. arXiv 2018, arXiv:1812.10320. [Google Scholar]
- Wu, X.; Finnegan, D.; O’Neill, E.; Yang, Y.L. Handmap: Robust hand pose estimation via intermediate dense guidance map supervision. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 237–253. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. 3d convolutional neural networks for efficient and robust hand pose estimation from single depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1991–2000. [Google Scholar]
- Song, S.; Xiao, J. Deep sliding shapes for amodal 3d object detection in rgb-d images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 808–816. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Malik, J.; Abdelaziz, I.; Elhayek, A.; Shimada, S.; Ali, S.A.; Golyanik, V.; Theobalt, C.; Stricker, D. HandVoxNet: Deep Voxel-Based Network for 3D Hand Shape and Pose Estimation from a Single Depth Map. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 7113–7122. [Google Scholar]
- Iqbal, U.; Molchanov, P.; Breuel Juergen Gall, T.; Kautz, J. Hand pose estimation via latent 2.5 d heatmap regression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 118–134. [Google Scholar]
- Spurr, A.; Iqbal, U.; Molchanov, P.; Hilliges, O.; Kautz, J. Weakly Supervised 3D Hand Pose Estimation via Biomechanical Constraints. arXiv 2020, arXiv:2003.09282. [Google Scholar]
- Theodoridis, T.; Chatzis, T.; Solachidis, V.; Dimitropoulos, K.; Daras, P. Cross-Modal Variational Alignment of Latent Spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 960–961. [Google Scholar]
- Yang, L.; Yao, A. Disentangling latent hands for image synthesis and pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9877–9886. [Google Scholar]
- Gu, J.; Wang, Z.; Ouyang, W.; Zhang, W.; Li, J.; Zhuo, L. 3D Hand Pose Estimation with Disentangled Cross-Modal Latent Space. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 391–400. [Google Scholar]
- Panteleris, P.; Oikonomidis, I.; Argyros, A. Using a single rgb frame for real time 3d hand pose estimation in the wild. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: New York, NY, USA, 2018; pp. 436–445. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Mueller, F.; Bernard, F.; Sotnychenko, O.; Mehta, D.; Sridhar, S.; Casas, D.; Theobalt, C. Ganerated hands for real-time 3d hand tracking from monocular rgb. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 49–59. [Google Scholar]
- Zhang, X.; Li, Q.; Mo, H.; Zhang, W.; Zheng, W. End-to-end hand mesh recovery from a monocular rgb image. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2354–2364. [Google Scholar]
- Boukhayma, A.; Bem, R.D.; Torr, P.H. 3d hand shape and pose from images in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10843–10852. [Google Scholar]
- Baek, S.; Kim, K.I.; Kim, T.K. Pushing the envelope for rgb-based dense 3d hand pose estimation via neural rendering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1067–1076. [Google Scholar]
- He, Y.; Hu, W.; Yang, S.; Qu, X.; Wan, P.; Guo, Z. 3D Hand Pose Estimation in the Wild via Graph Refinement under Adversarial Learning. arXiv 2019, arXiv:1811.07376. [Google Scholar]
- Yuan, S.; Stenger, B.; Kim, T. 3D Hand Pose Estimation from RGB Using Privileged Learning with Depth Data. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 2866–2873. [Google Scholar]
- Cai, Y.; Ge, L.; Cai, J.; Yuan, J. Weakly-supervised 3d hand pose estimation from monocular rgb images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 666–682. [Google Scholar]
- Dibra, E.; Melchior, S.; Balkis, A.; Wolf, T.; Oztireli, C.; Gross, M. Monocular RGB hand pose inference from unsupervised refinable nets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1075–1085. [Google Scholar]
- Chen, L.; Lin, S.Y.; Xie, Y.; Lin, Y.Y.; Fan, W.; Xie, X. DGGAN: Depth-image Guided Generative Adversarial Networks forDisentangling RGB and Depth Images in 3D Hand Pose Estimation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 411–419. [Google Scholar]
- Zhao, L.; Peng, X.; Chen, Y.; Kapadia, M.; Metaxas, D.N. Knowledge as Priors: Cross-Modal Knowledge Generalization for Datasets without Superior Knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6528–6537. [Google Scholar]
- Yang, L.; Li, S.; Lee, D.; Yao, A. Aligning latent spaces for 3d hand pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2335–2343. [Google Scholar]
- Ge, L.; Ren, Z.; Li, Y.; Xue, Z.; Wang, Y.; Cai, J.; Yuan, J. 3d hand shape and pose estimation from a single rgb image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10833–10842. [Google Scholar]
- Zhou, Y.; Habermann, M.; Xu, W.; Habibie, I.; Theobalt, C.; Xu, F. Monocular Real-time Hand Shape and Motion Capture using Multi-modal Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 5346–5355. [Google Scholar]
- Mueller, F.; Mehta, D.; Sotnychenko, O.; Sridhar, S.; Casas, D.; Theobalt, C. Real-time hand tracking under occlusion from an egocentric rgb-d sensor. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1284–1293. [Google Scholar]
- Kazakos, E.; Nikou, C.; Kakadiaris, I.A. On the Fusion of RGB and Depth Information for Hand Pose Estimation. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: New York, NY, USA, 2018; pp. 868–872. [Google Scholar]
- Wetzler, A.; Slossberg, R.; Kimmel, R. Rule of thumb: Deep derotation for improved fingertip detection. arXiv 2015, arXiv:1507.05726. [Google Scholar]
- Yuan, S.; Ye, Q.; Stenger, B.; Jain, S.; Kim, T.K. Bighand2.2m benchmark: Hand pose dataset and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4866–4874. [Google Scholar]
- Zimmermann, C.; Ceylan, D.; Yang, J.; Russell, B.; Argus, M.; Brox, T. Freihand: A dataset for markerless capture of hand pose and shape from single rgb images. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 813–822. [Google Scholar]
- Sridhar, S.; Mueller, F.; Zollhöfer, M.; Casas, D.; Oulasvirta, A.; Theobalt, C. Real-time joint tracking of a hand manipulating an object from rgb-d input. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 294–310. [Google Scholar]
- Garcia-Hernando, G.; Yuan, S.; Baek, S.; Kim, T.K. First-person hand action benchmark with rgb-d videos and 3d hand pose annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 409–419. [Google Scholar]
- Simon, T.; Joo, H.; Matthews, I.; Sheikh, Y. Hand keypoint detection in single images using multiview bootstrapping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1145–1153. [Google Scholar]



{kind=link}
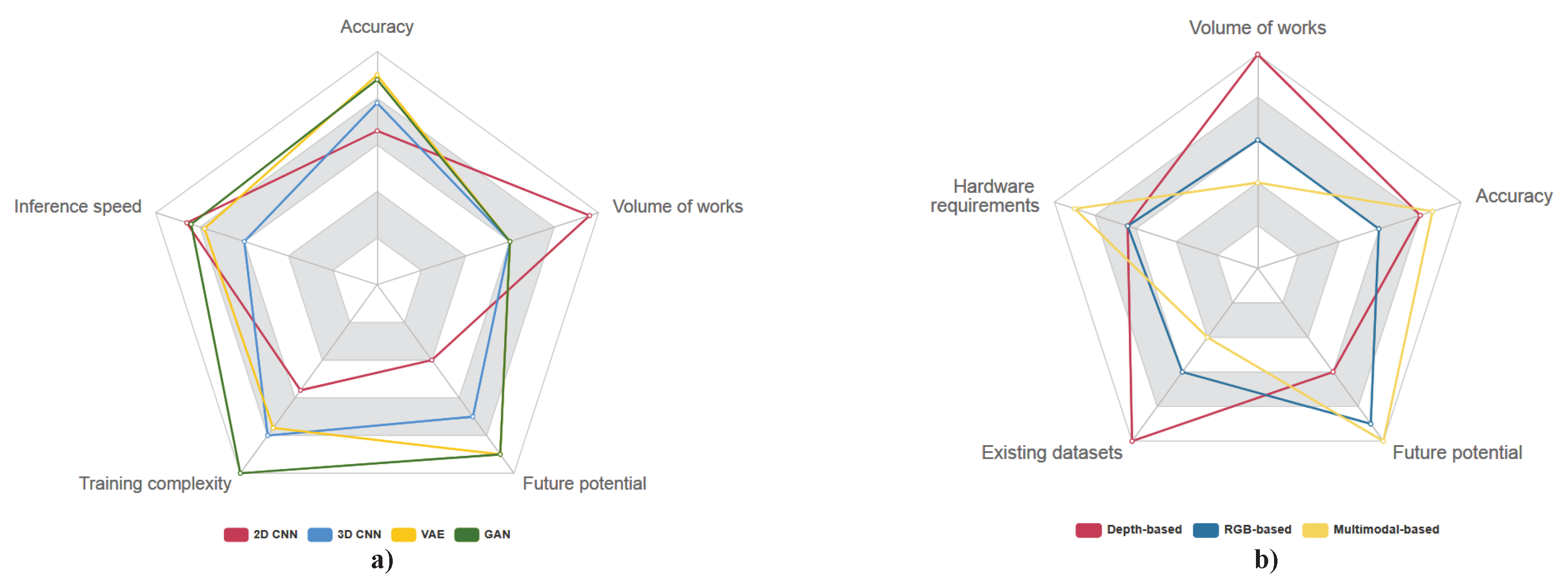{kind=link}
| Dataset | Modality | Year | View | Type | # of Subjects | # of Joints | # of Frames |
|---|---|---|---|---|---|---|---|
| ICVL [41] | D | 2014 | 3rd | Real | 10 | 16 | 332.5 K |
| NYU [42] | D | 2014 | 3rd | Real | 2 | 36 | 81 K |
| MSRA15 [63] | D | 2015 | 3rd | Real | 9 | 21 | 76.5 K |
| HandNet [138] | D | 2015 | 3rd | Real | 10 | 6 | 212 K |
| BigHand2.2M [139] | D | 2017 | ego/3rd | Real | 10 | 21 | 2.2 M |
| HANDS 2017 [45] | D | 2017 | ego/3rd | Real | 20 | 21 | 1.2 M |
| SynHand5M [92] | D | 2018 | 3rd | Synthetic | - | 22 | 5 M |
| FreiHAND [140] | RGB | 2019 | 3rd | Real | 32 | 21 | 134 K |
| Dexter1 [79] | RGB+D | 2013 | 3rd | Real | 1 | 6 | 2 K |
| Dexter+Object [141] | RGB+D | 2016 | 3rd | Real | 2 | 5 | 3 K |
| RHD [43] | RGB+D | 2017 | 3rd | Synthetic | 20 | 21 | 44 K |
| STB [44] | RGB+D | 2017 | 3rd | Real | 1 | 21 | 18 K |
| EgoDexter [136] | RGB+D | 2017 | ego | Real | 4 | 5 | 3190 |
| SynthHands [136] | RGB+D | 2017 | ego | Synthetic | 2 | 21 | 63.5 K |
| Datasets | Input Modality | Sub-Category | Method | Results |
|---|---|---|---|---|
| ICVL [41] | Depth-based | 2D depth map | Zhou et al. [103] | 6.24 mEPE |
| Ren et al. [87] | 6.26 mEPE | |||
| Xiong et al. [100] | 6.46 mEPE | |||
| 3D representations | Moon et al. [64] | 6.28 mEPE | ||
| Ge et al. [99] | 6.30 mEPE | |||
| Ge et al. [50] | 6.70 mEPE | |||
| NYU [42] | Depth-based | 2D depth map | Rad et al. [85] | 7.40 mEPE |
| Ren et al. [87] | 7.78 mEPE | |||
| Xiong et al. [100] | 8.61 mepe | |||
| 3D representations | Moon et al. [64] | 8.42mEPE | ||
| Malik et al. [115] | 8.72 mEPE | |||
| Huang et al. [110] | 8.9 mEPE | |||
| MSRA15 [63] | Depth-based | 2D depth map | Ren et al. [87] | 7.16 mEPE |
| Du et al. [86] | 7.20 mEPE | |||
| Wan et al. [97] | 7.20 mepe | |||
| 3D representations | Moon et al. [64] | 7.49 mEPE | ||
| Huang et al. [110] | 7.40 mEPE | |||
| Ge et al. [99] | 7.70 mEPE | |||
| HANDS 2017 [45] | Depth-based | 2D depth map | Zhou et al. [84] | 5.26 mEPE |
| Wu et al. [111] | 5.90 mEPE | |||
| Ren et al. [87] | 8.33 mEPE | |||
| 3D representations | Li et al. [105] | 9.82 mepe | ||
| Moon et al. [64] | 9.95mEPE | |||
| SynHand5M [92] | Depth-based | 2D depth map | Malik et al. [93] | 4.32 mEPE |
| Malik et al. [93] | 6.30 mEPE | |||
| 3D representations | Malik et al. [115] | 3.75 mEPE | ||
| Moon et al. [64] | 3.81 mEPE | |||
| Dexter+Object [141] | RGB-based | Model-based | Zhang et al. [124] | 0.825 AUC |
| Boukhayma et al. [125] | 25.53 mEPE/0.763 AUC | |||
| Baek et al. [126] | 0.610 AUC | |||
| Model-free | Spurr et al. [117] | 0.820 AUC | ||
| Iqbal [116] | 0.710 AUC | |||
| Multimodal | Unimodal Inference | Zhou et al. [135] | 0.948 AUC | |
| RHD [43] | RGB-based | Model-based | He et al. [127] | 12.40 mEPE |
| Baek et al. [126] | 0.926 AUC | |||
| Zhang et al. [124] | 0.901 AUC | |||
| Model-free | Iqbal et al. [116] | 13.41mEPE/0.940 AUC | ||
| Theodoridis et al. [118] | 15.61 mEPE/0.907 AUC | |||
| Spurr et al. [49] | 19.73 mEPE/0.849 AUC | |||
| Multimodal | Unimodal inference | Yang et al. [133] | 13.14 mEPE/0.943 AUC | |
| Ge et al. [134] | 0.920 AUC | |||
| Cai et al. [129] | 0.887 AUC | |||
| STB [44] | RGB-based | Multimodal | He et al. [127] | 3.96 mEPE |
| Baek et al. [126] | 0.995 AUC | |||
| Zhang et al. [124] | 0.995 AUC | |||
| Model-free | Theodoridis et al. [118] | 6.93 mEPE/0.997AUC | ||
| Iqbal et al. [116] | 0.994 AUC | |||
| Spurr et al. [49] | 8.56 mEPE/0.983 AUC | |||
| Multimodal | Unimodal Inference | Ge et al. [134] | 6.37 mEPE/0.998 AUC | |
| Yang et al. [133] | 7.05 mEPE/0.996 AUC | |||
| Cai et al. [129] | 0.994 AUC | |||
| EgoDexter [136] | RGB-based | Model-based | Boukhayma et al. [125] | 45.33mEPE/0.674AUC |
| Model-free | Iqbal et al. [116] | 0.580AUC | ||
| Multimodal | Unimodal Inference | Zhou et al. [135] | 0.811 AUC |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chatzis, T.; Stergioulas, A.; Konstantinidis, D.; Dimitropoulos, K.; Daras, P. A Comprehensive Study on Deep Learning-Based 3D Hand Pose Estimation Methods. Appl. Sci. 2020, 10, 6850. https://doi.org/10.3390/app10196850
Chatzis T, Stergioulas A, Konstantinidis D, Dimitropoulos K, Daras P. A Comprehensive Study on Deep Learning-Based 3D Hand Pose Estimation Methods. Applied Sciences. 2020; 10(19):6850. https://doi.org/10.3390/app10196850
Chicago/Turabian StyleChatzis, Theocharis, Andreas Stergioulas, Dimitrios Konstantinidis, Kosmas Dimitropoulos, and Petros Daras. 2020. "A Comprehensive Study on Deep Learning-Based 3D Hand Pose Estimation Methods" Applied Sciences 10, no. 19: 6850. https://doi.org/10.3390/app10196850
APA StyleChatzis, T., Stergioulas, A., Konstantinidis, D., Dimitropoulos, K., & Daras, P. (2020). A Comprehensive Study on Deep Learning-Based 3D Hand Pose Estimation Methods. Applied Sciences, 10(19), 6850. https://doi.org/10.3390/app10196850