1. Introduction
Transportation is an essential factor in human lives, as it plays an important role in developing civilization. Therefore, recent work on both scientific and industrial sides has focused on constructing an intelligent transport system (ITS), in which autonomous vehicles are arguably the most attractive part [
1,
2,
3]. It is partly due to the rapid development of artificial intelligent approaches that their contributions have been shown in several fields in recent years [
4,
5,
6]. However, since the final target is completely replacing the traditional vehicles with the autonomous ones, there are still many challenges ahead that need to be resolved. For example, the on-road autonomous vehicles may need to estimate each other’s positions to maintain safe distances and make urgent decisions when necessary. Thanks to that, we can avoid traffic accidents and congestion. Therefore, there is an increasing demand for an efficient vehicle-to-vehicle (V2V) positioning solution.
Referring to previous studies, many drawbacks that affect the performances of the existing V2V positioning technologies, such as time difference of arrival (TDOA) and light detection and ranging (LiDAR), have been observed [
7,
8]. In particular, with TDOA, an estimation result greatly depends on the time measurement, which causes difficulty in obtaining high accuracy in practice. Besides, LiDAR has to face some major limitations such as high cost, complicated installation, high sensitivity to signal interference, and jamming. Compared to these methods, the stereo vision system has some strong points as follows. First, the stereo vision system has an affordable price. Second, it is easily installed and maintained on the vehicle. Third, the stereo vision system can observe the appearance of the objects. Therefore, the stereo vision system can be considered as an alternative for the V2V positioning application.
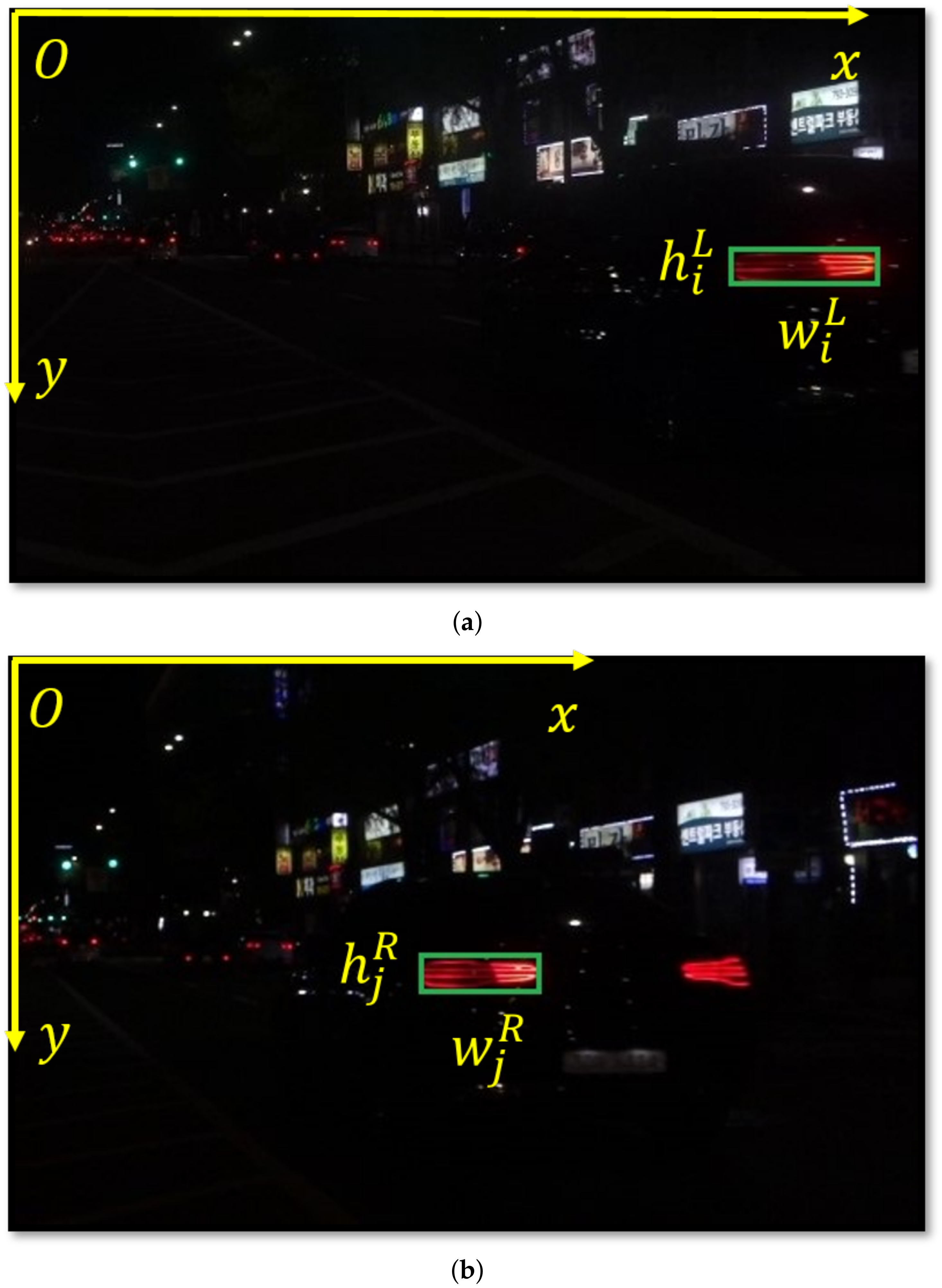
To estimate the world coordinates of the object relative to the camera using the stereo-vision-based approach, initially, this object has to be detected from the captured image. However, it is extremely difficult to directly detect a vehicle at nighttime, since the appearance of the vehicle may become hardly observable due to the inadequate lighting conditions. Instead, most papers focus on detecting the most prominent part of the vehicle at nighttime (vehicle lighting), which is often a taillight [
8,
9,
10,
11]. In these papers, they use the stereo vision system, which includes two cameras, on the host vehicle to capture a real scene from two different views. Next, the world coordinates of the front vehicle’s taillights can be determined based on the relation between their corresponding pixel coordinates on the two captured images. This helps in estimating the position of the corresponding front vehicle. However, as all of them were based on simulation experiments with a single in-front vehicle, they have not dealt with three serious problems that need to be addressed to locate multiple front vehicles in practice. First, in the urban traffic environment, the cameras would presumably capture several light sources in the front, which may lead to difficulties in identifying the real taillight. Second, with many taillights detected from each image, how can we determine which one in the left image corresponds to a certain one in the right image. The third problem is how to pair every two taillights that belong to the same vehicle so that the vehicle’s presence can be confirmed. These three issues, which are respectively termed the detection problem, the stereo matching problem, and the pairing problem, are what we want to address in this paper.
Initially, we briefly review what has been done in previous works to deal with each of the above problems as follows:
(1) Detection problem: Due to the arbitrary shape and size of a vehicle’s taillights, it is challenging based on these characteristics to detect the taillight regions from an image, especially in nighttime situations. The most popular approach is relying on color and brightness, given the assumption that the vehicle’s taillights dominantly contain red points and their brightness is relatively higher than the other parts of the image. Specifically, they consider the threshold based on different color spaces, such as HSV [
12,
13,
14,
15], Lab [
16], Y’UV [
17], grayscale [
18], or RGB [
19], and use some conventional techniques [
12,
13,
15,
16,
17,
18,
19] or machine-learning-based techniques [
14] to detect the taillights from the image. However, the previous works often lacked a step to verify whether the detected region is a taillight or just a bright object. Furthermore, most of them have not mentioned labeling and determining the pixel coordinates of each detected taillight region, which is mandatory for V2V positioning.
(2) Stereo matching problem: Stereo matching [
20] is a well-known problem that has appeared in many computer vision studies. In particular, it involves the task of determining which part of one image corresponds to a particular part of another image. These two images are taken of the same real scene but from different viewpoints. Previous studies mostly resolved the stereo correspondence problem by proposing a dense matcher to compare each small patch between two images for depth estimation or 3D reconstruction [
21,
22,
23,
24,
25]. These approaches have two major drawbacks. First, the stereo matching that operates on the full image may generate bad results on low textured or non-Lambertian surfaces. Second, since the regions of interest often just fill in a small part of the image, the dense stereo matching task will possibly lead to high computational complexity, which may affect the performance in a real-time application like V2V positioning.
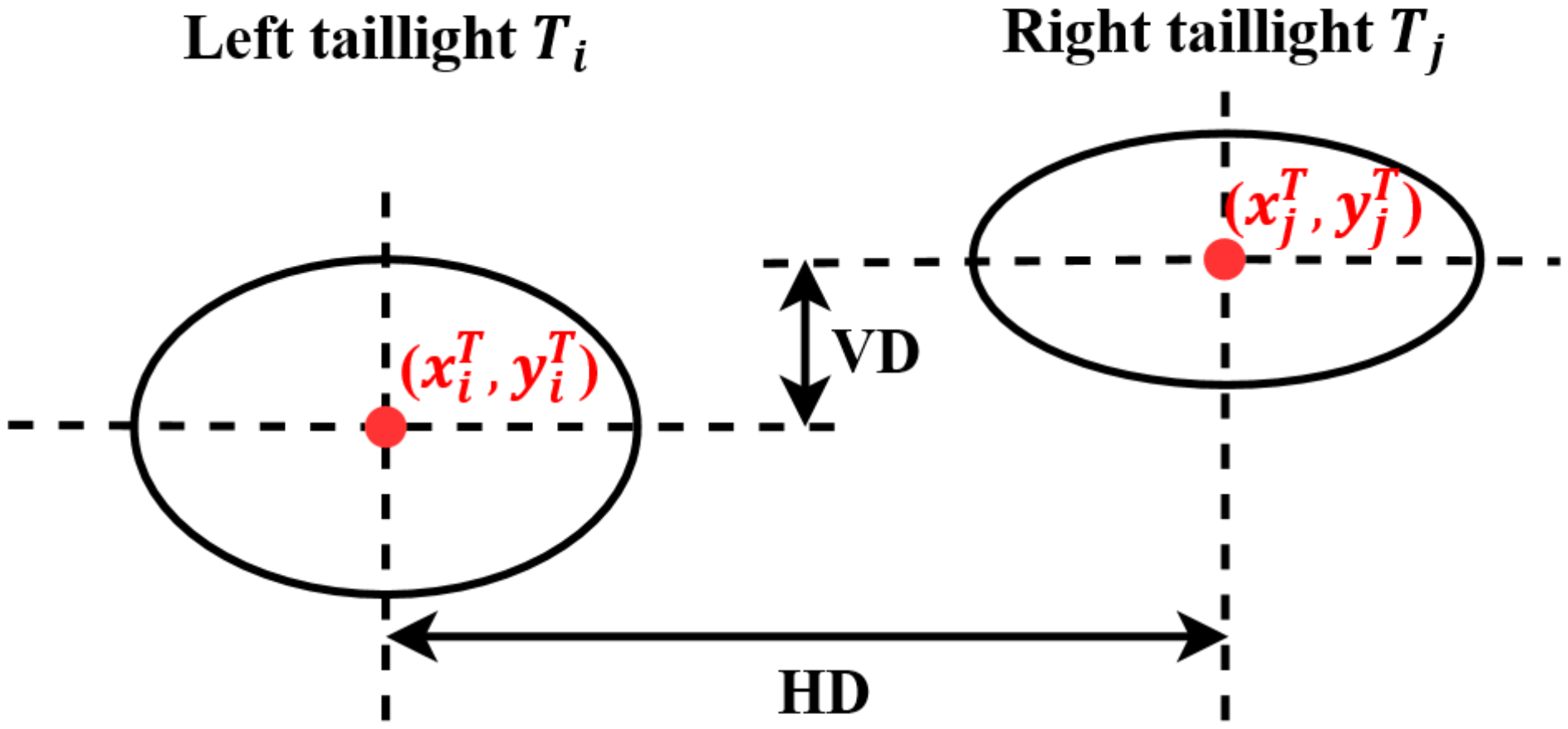
(3) Pairing problem: Regularly, to decide whether the two taillights belong to the same vehicle, the common approach is comparing some relations relevant to their size, color, and position with some particular thresholds [
12,
13,
14,
15,
16,
17,
18,
19,
26]. The threshold values are usually chosen empirically but must be reasonable to distinguish between the two taillights. Therefore, these methods lack the flexibility to handle different cases in real situations. Furthermore, many of them are applied for the surveillance camera [
13,
16,
17,
19,
26], which has a different perspective from the vehicle-mounted camera used in our positioning system.
To solve the aforementioned problems, we propose three methods, which are summarized as a three-fold contribution below:
A detection method in which we derive a connected-component analysis algorithm to determine the region and estimate the pixel coordinates of each candidate taillight in the image. In this method, we also provide a rule-based verification phase to reduce the number of outliers in detection results as much as possible.
A stereo matching method that uses a gradient boosted tree classifier for ascertaining which taillight in the left image is the same as that in the right image, while the other part of the image, which is not the target for V2V positioning, is ignored. Thanks to that, we reduce the computational complexity when compared with the conventional stereo matching approaches.
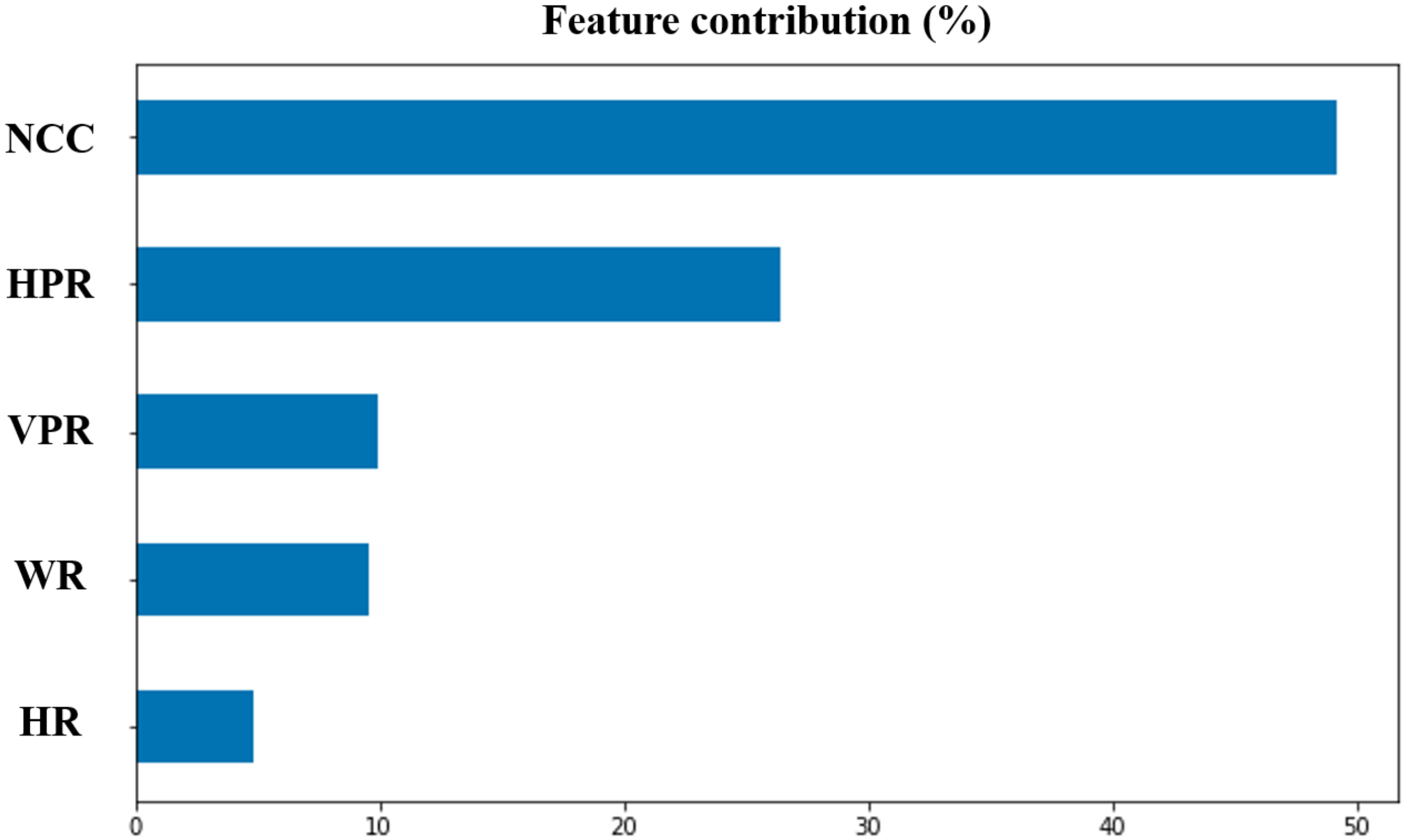
A neural-network-based pairing algorithm that adaptively determines the threshold of the horizontal distance, that of the vertical distance, and the correlation between two arbitrary taillights to decide whether they belong to the same vehicle. It is different from the existing works that set the threshold empirically.
Furthermore, an outdoor experiment was conducted to capture the images in a nighttime traffic environment. The obtained images were then processed using our proposed methods, to reveal the performances of these methods in real situations.
The remainder of this paper is structured as follows. First, in
Section 2, we explain the stereo-vision-based nighttime V2V positioning process, which utilizes the stereo triangulation approach for estimating the world coordinates of the front vehicle using the pixel coordinates of its taillights. Second, three proposed methods for taillight detection, stereo taillight matching, and taillight pairing are respectively described in
Section 3.
Section 4 demonstrates our experiments in the real traffic scenario and evaluates the performances of the proposed methods on the captured images. Finally, we present the conclusions in
Section 5.
2. Stereo-Vision-Based Nighttime V2V Positioning
A stereo-vision-based V2V positioning process in nighttime scenarios includes five stages. In stage (
1), the proposed taillight detection method is applied to locate the region and pixel coordinates of each taillight in each image. In stage (
2), a stereo matching method is applied to determine which taillight detected from the left image corresponds to which taillight detected from the right image; and a pairing method in stage (
3) is to associate every pair of taillights that belong to the same vehicle on each image. When the pixel coordinates of each taillight in the left and right images have been determined, the world coordinates of this taillight can be calculated in stage (
4). Finally, given the world coordinates of each pair of taillights, the world coordinates of the corresponding vehicle are estimated in stage (
5). An overview of this process is presented in
Figure 1.
In this study, our contribution includes three proposed methods for the first three stages from (1) to (3). Therefore, they will be described in detail in the next section. Besides, the intuition behind stages (4) and (5) is explained as follows:
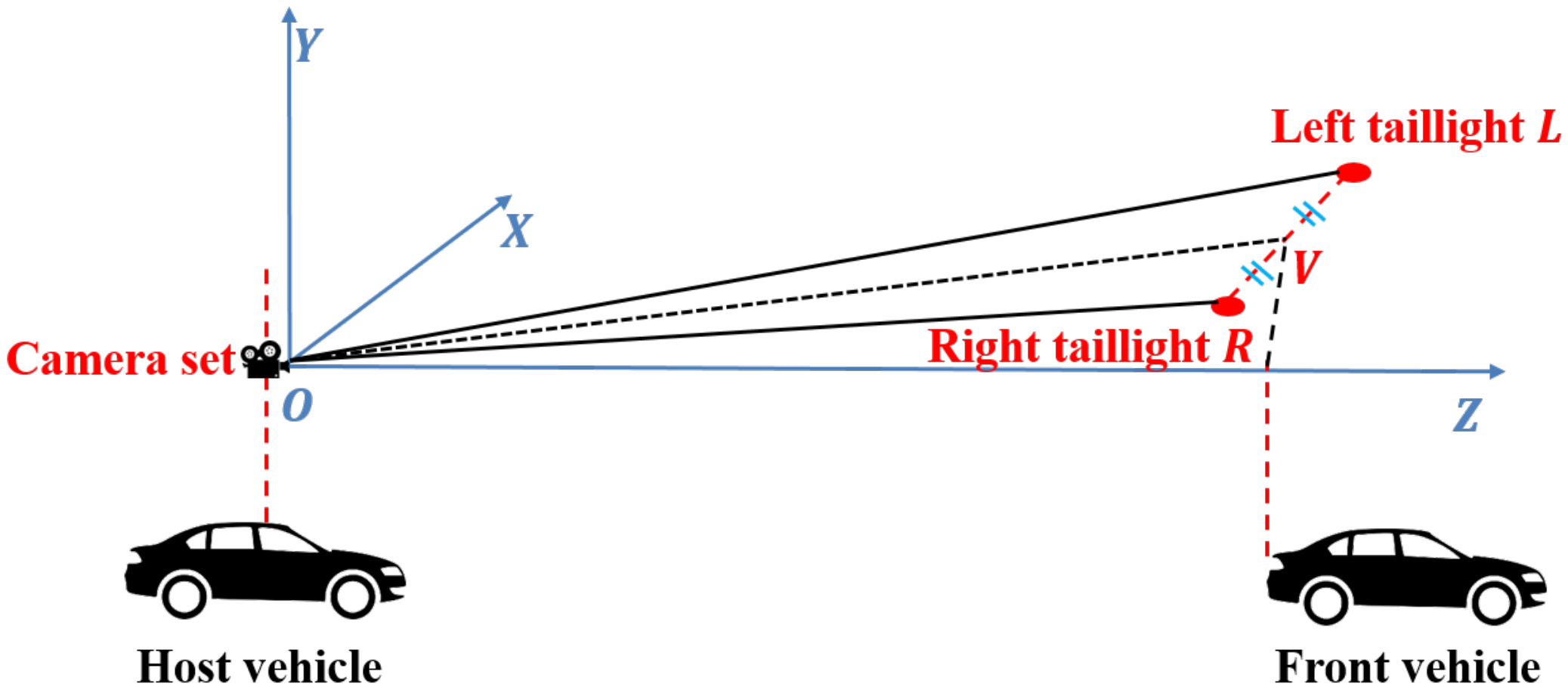
In stage (
4), the stereo triangulation approach [
27] is utilized to determine the world coordinates of each detected taillight, given an assumption that the two cameras capture the images simultaneously. We denote
as the world coordinates of the taillight
P;
and
, respectively, as the pixel coordinates of the left and right cameras’ optical centers; and
and
as the pixel coordinates of
P in the left and right images. Additionally, two cameras have the same horizontal focal length
and vertical focal length
, and the camera baseline is
b. The stereo triangulation approach for taillight positioning is illustrated in
Figure 2.
When considering two similar triangles,
and
, the Oz-axis value
Z of the taillight
P can be calculated using the following equations, given that all the mentioned coordinates are already known:
After calculating
Z, the two remaining values,
X and
Y, of the world coordinates of
P can be identified:
In stage (
5), we suppose that
V is the midpoint of the line segment that connects the left taillight
L and right taillight
R of the vehicle. The world coordinates of
V can be considered as the position of the vehicle, as illustrated in
Figure 3.
Once the world coordinates of the left taillight
L and right taillight
R have been determined as
and
, respectively, the world coordinates
of the front vehicle are given by:
5. Conclusions
V2V positioning is a fundamental part of any intelligent transport system, such as an autonomous vehicle, because it helps to prevent traffic accidents and congestion, especially in nighttime situations. The stereo vision system is promising as a potential solution, owing to its existing advantages compared to other existing technologies. This paper considers a stereo-vision-based nighttime V2V positioning process which is based on detecting the vehicle taillights and using the stereo triangulation approach. However, in the urban traffic environment, each camera in the system often captures multiple light sources in a single image, which leads to three problems for the V2V positioning task: the detection problem, the stereo matching problem, and the pairing problem. To address these problems, in this study, a threefold contribution is proposed. The first contribution is a detection method for labeling and determining the pixel coordinates of each taillight region in the image. Second, we propose a stereo taillight matching method using a gradient boosted tree classifier, which helps in determining which taillight detected in the left image corresponds to a taillight detected in the right image while ignoring the remaining parts of the images, which are redundant for the V2V positioning task. Third, a neural-network-based pairing method is provided to associate every two taillights that belong to the same vehicle. We also conducted an outdoor experiment to evaluate the performance of each proposed method in urban traffic at nighttime. In future work, it is necessary to quantitatively compare the performance of each proposed method with the existing alternatives in different aspects to show their potential to be utilized in autonomous vehicles.
There are two main directions to develop this study for future research. The first direction is to improve the explainability and performance of each proposed method, especially the taillight detection method, as the two remaining ones greatly depend on the detection result. To fulfill this target, some advanced deep learning approaches, such as faster-RCNN, can be considered to provide a better solution. The second direction is to expand the research scope into detecting vehicle headlights, daytime positioning, or dealing with several weather conditions. All these directions aim to provide a robust V2V positioning system that can work efficiently in different circumstances of urban traffic.






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}