Training Set Enlargement Using Binary Weighted Interpolation Maps for the Single Sample per Person Problem in Face Recognition


Abstract
1. Introduction
2. Proposed Method
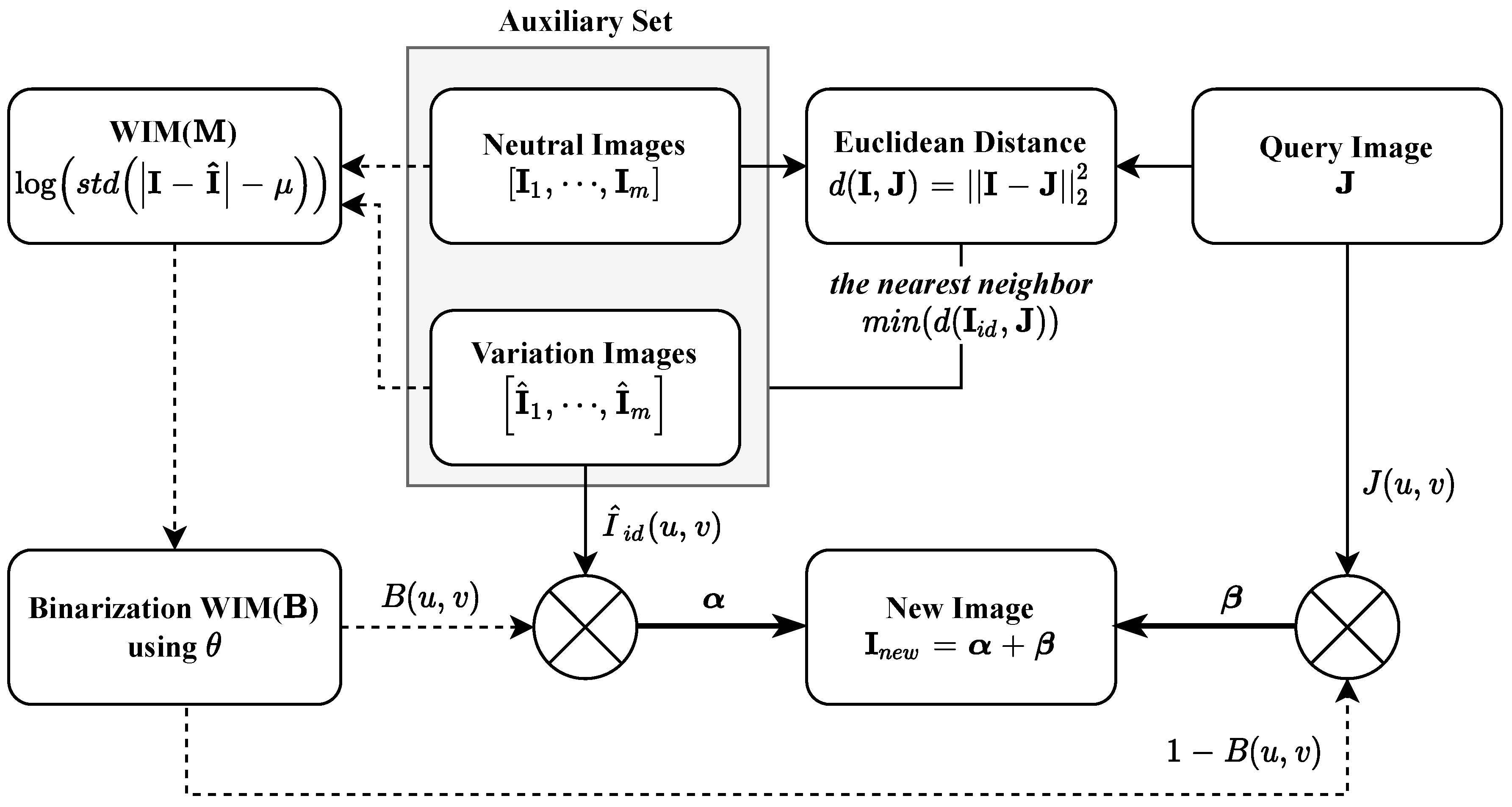
2.1. Binary Weighted Interpolation Maps (B-WIM)
2.2. Generation of New Images from a Query Image
- Step 1: Extraction of the normalized WIM using log-scaled standard deviation of the absolute difference between and in the auxiliary set;
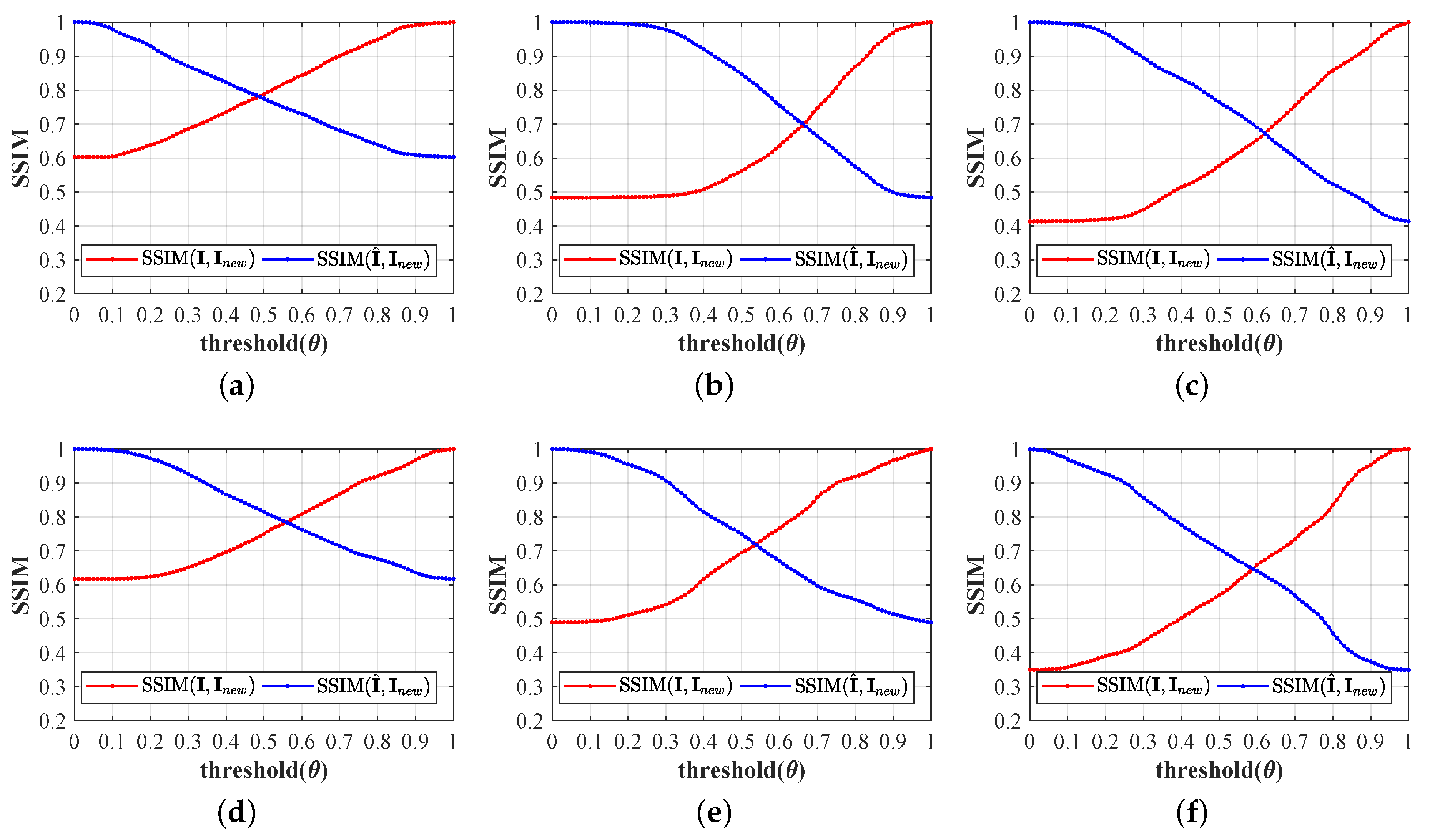
- Step 2: Binarization of WIM from threshold ();
- Step 3: Selection of the index () of the nearest neighbor in the auxiliary set based on Euclidean distance with the query image; ()
- Step 4: Replacement of with , derived from ;
- Step 5: Generation of the new image ().
3. Experiments
3.1. Database
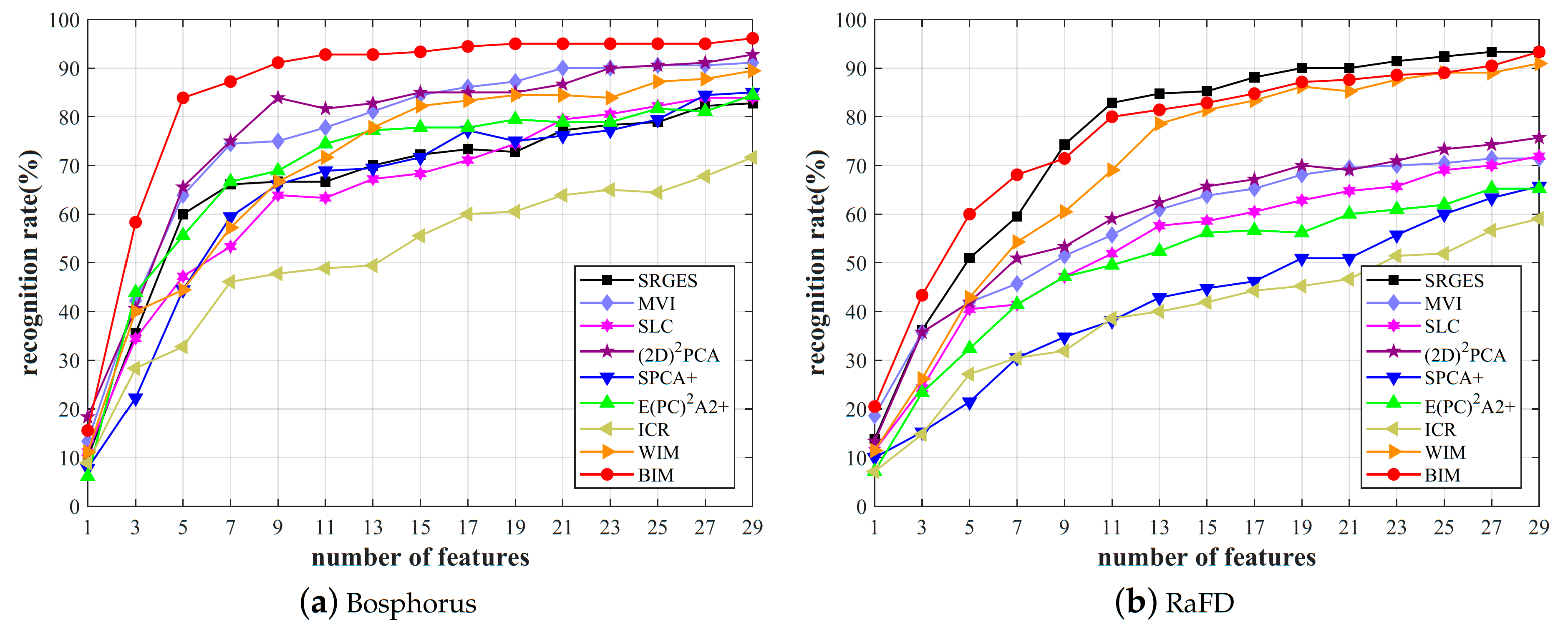
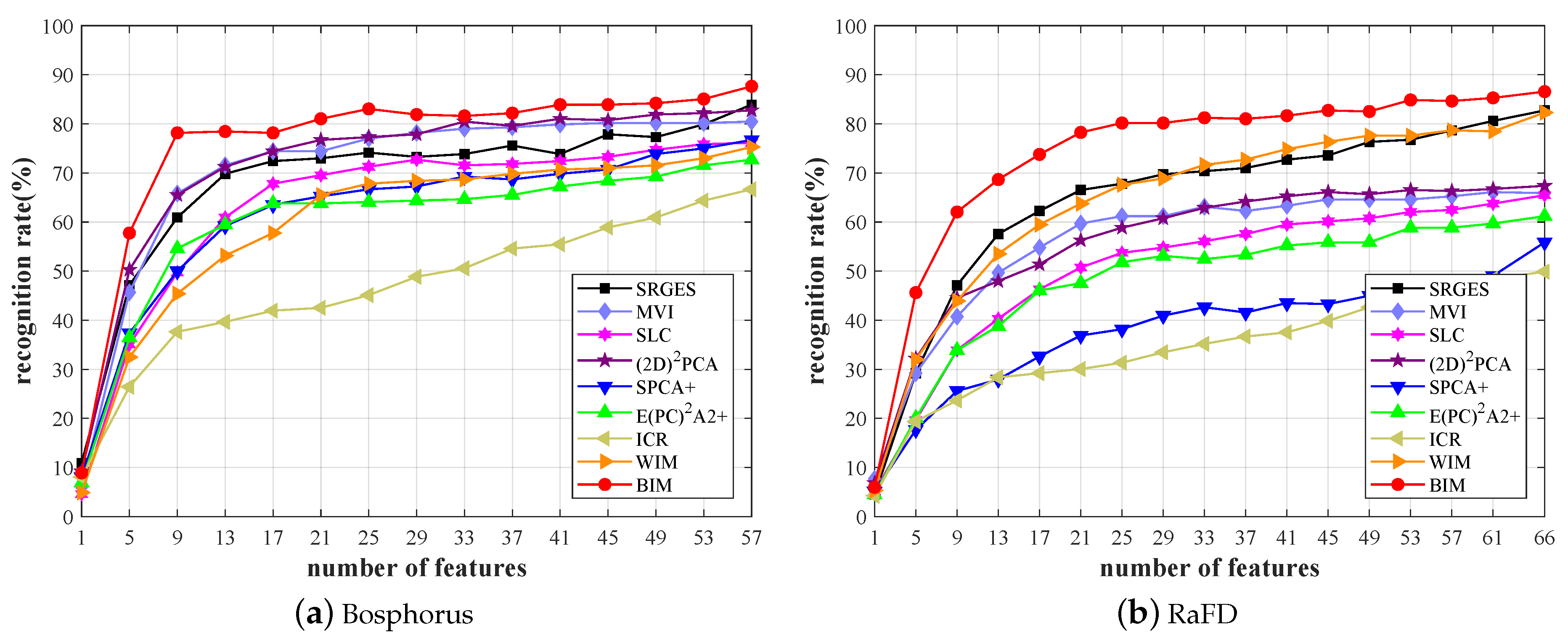
3.2. Face Recognition Results
- : In this case, all images were collected under similar conditions. Thus, all images belonged to the same database. In the experiment, the database was divided into a face recognition set and an auxiliary set. The face recognition set consisted of training and test sets. Neutral images for each class used to generate images were included in the training set, and the remaining images containing only variations were used as the test set. This method had the same variations (“expression”) in both face recognition and auxiliary sets;
- : This case used a separate auxiliary set from a given database to demonstrate the superiority of the proposed method. The training and test sets were collected under similar conditions. However, the auxiliary set was taken in environments different from those. The face recognition set was constructed in the same way as in the “” case, and neutral images were used to enlarge the others. Both face recognition and auxiliary sets included “expression” variations. However, the types of detailed variations could be different.
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AUs | action units |
| B-WIM | binary weighted interpolation maps |
| DCV | discriminant common vector |
| FACS | facial action coding system |
| ICR | interclass relationship |
| PCA | principal component analysis |
| SSIM | structural similarity |
| SSPP | single sample per person |
| WIM | weighted interpolation maps |
References
- Kortli, Y.; Jridi, M.; Al Falou, A.; Atri, M. Face recognition systems: A Survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef]
- Choi, S.I.; Lee, Y.; Lee, M. Face Recognition in SSPP Problem Using Face Relighting Based on Coupled Bilinear Model. Sensors 2019, 19, 43. [Google Scholar] [CrossRef]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Panetta, K.; Wan, Q.; Agaian, S.; Rajeev, S.; Kamath, S.; Rajendran, R.; Rao, S.; Kaszowska, A.; Taylor, H.; Samani, A.; et al. A comprehensive database for benchmarking imaging systems. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 509–520. [Google Scholar] [CrossRef]
- Bansal, A.; Nanduri, A.; Castillo, C.D.; Ranjan, R.; Chellappa, R. Umdfaces: An annotated face dataset for training deep networks. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 464–473. [Google Scholar]
- Kemelmacher-Shlizerman, I.; Seitz, S.M.; Miller, D.; Brossard, E. The megaface benchmark: 1 million faces for recognition at scale. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4873–4882. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. 2008. Available online: http://vis-www.cs.umass.edu/lfw (accessed on 1 September 2020).
- Huang, G.B.; Learned-Miller, E. Labeled Faces in the Wild: Updates and New Reporting Procedures; Technical Report UM-CS-2014-003; Department of Computer Science, University of Massachusetts Amherst: Amherst, MA, USA, 2014. [Google Scholar]
- Tan, X.; Chen, S.; Zhou, Z.H.; Zhang, F. Face recognition from a single image per person: A survey. Pattern Recognit. 2006, 39, 1725–1745. [Google Scholar] [CrossRef]
- Ríos-Sánchez, B.; Costa-da Silva, D.; Martín-Yuste, N.; Sánchez-Ávila, C. Deep Learning for Facial Recognition on Single Sample per Person Scenarios with Varied Capturing Conditions. Appl. Sci. 2019, 9, 5474. [Google Scholar] [CrossRef]
- Noyes, E.; Jenkins, R. Deliberate disguise in face identification. J. Exp. Psychol. Appl. 2019, 25, 280. [Google Scholar] [CrossRef]
- Demleitner, N.V. Witness Protection in Criminal Cases: Anonymity, Disguise or Other Options? Am. J. Comp. Law 1998, 46, 641–664. [Google Scholar] [CrossRef]
- Wang, F.; Cheng, J.; Liu, W.; Liu, H. Additive margin softmax for face verification. IEEE Signal Process. Lett. 2018, 25, 926–930. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5265–5274. [Google Scholar]
- Zheng, Y.; Pal, D.K.; Savvides, M. Ring loss: Convex feature normalization for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5089–5097. [Google Scholar]
- Coccia, M.; Watts, J. A theory of the evolution of technology: Technological parasitism and the implications for innovation magement. J. Eng. Technol. Manag. 2020, 55, 101552. [Google Scholar] [CrossRef]
- Coccia, M. Sources of technological innovation: Radical and incremental innovation problem-driven to support competitive advantage of firms. Technol. Anal. Strateg. Manag. 2017, 29, 1048–1061. [Google Scholar] [CrossRef]
- Arthur, W.B. The Nature of Technology: What It Is and How It Evolves; Simon and Schuster: New York City, NY, USA, 2009. [Google Scholar]
- Arthur, W.B.; Polak, W. The evolution of technology within a simple computer model. Complexity 2006, 11, 23–31. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, D.; Zhou, Z.H. Enhanced (PC)2A for face recognition with one training image per person. Pattern Recognit. Lett. 2004, 25, 1173–1181. [Google Scholar] [CrossRef]
- Wu, J.; Zhou, Z.H. Face recognition with one training image per person. Pattern Recognit. Lett. 2002, 23, 1711–1719. [Google Scholar] [CrossRef]
- Zhang, D.; Zhou, Z.H. (2D)2PCA: Two-directional two-dimensional PCA for efficient face representation and recognition. Neurocomputing 2005, 69, 224–231. [Google Scholar] [CrossRef]
- Turk, M.; Pentland, A. Eigenfaces for recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef]
- Zhang, D.; Chen, S.; Zhou, Z.H. A new face recognition method based on SVD perturbation for single example image per person. Appl. Math. Comput. 2005, 163, 895–907. [Google Scholar] [CrossRef]
- Xu, Y.; Zhu, X.; Li, Z.; Liu, G.; Lu, Y.; Liu, H. Using the original and ‘symmetrical face’ training samples to perform representation based two-step face recognition. Pattern Recognit. 2013, 46, 1151–1158. [Google Scholar] [CrossRef]
- Zhang, T.; Li, X.; Guo, R.Z. Producing virtual face images for single sample face recognition. Opt.-Int. J. Light Electron Opt. 2014, 125, 5017–5024. [Google Scholar] [CrossRef]
- Li, Q.; Wang, H.J.; You, J.; Li, Z.M.; Li, J.X. Enlarge the training set based on inter-class relationship for face recognition from one image per person. PLoS ONE 2013, 8, e68539. [Google Scholar] [CrossRef]
- Moon, H.M.; Kim, M.G.; Shin, J.H.; Pan, S.B. Multiresolution face recognition through virtual faces generation using a single image for one person. Wirel. Commun. Mob. Comput. 2018, 2018. [Google Scholar] [CrossRef]
- Ding, Y.; Qi, L.; Tie, Y.; Liang, C.; Wang, Z. Single sample per person face recognition based on sparse representation with extended generic set. In Proceedings of the 2018 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Zhengzhou, China, 18–20 October 2018; pp. 37–375. [Google Scholar]
- Lee, Y.; Kang, J. Occlusion Images Generation from Occlusion-Free Images for Criminals Identification based on Artificial Intelligence Using Image. Int. J. Eng. Technol. 2018, 7, 161–164. [Google Scholar]
- Savran, A.; Alyüz, N.; Dibeklioğlu, H.; Çeliktutan, O.; Gökberk, B.; Sankur, B.; Akarun, L. Bosphorus database for 3D face analysis. In European Workshop on Biometrics and Identity Management; Springer: Berlin/Heidelberg, Germany, 2008; pp. 47–56. [Google Scholar]
- Friesen, E.; Ekman, P. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologists Press: City of Palo Alto, CA, USA, 1978. [Google Scholar]
- Scheve, T. How Many Muscles Does It Take to Smile? How Stuff Works Science. June 2009, Volume 2. Available online: https://science.howstuffworks.com/life/inside-the-mind/emotions/muscles-smile.htm (accessed on 1 September 2020).
- Waller, B.M.; Cray, J.J., Jr.; Burrows, A.M. Selection for universal facial emotion. Emotion 2008, 8, 435. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Renieblas, G.P.; Nogués, A.T.; González, A.M.; León, N.G.; Del Castillo, E.G. Structural similarity index family for image quality assessment in radiological images. J. Med. Imaging 2017, 4, 035501. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing; Prentice Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Langner, O.; Dotsch, R.; Bijlstra, G.; Wigboldus, D.H.; Hawk, S.T.; Van Knippenberg, A. Presentation and validation of the Radboud Faces Database. Cogn. Emot. 2010, 24, 1377–1388. [Google Scholar] [CrossRef]
- Cevikalp, H.; Neamtu, M.; Wilkes, M.; Barkana, A. Discriminative common vectors for face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 4–13. [Google Scholar] [CrossRef]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 1. [Google Scholar]
- Du, S.; Tao, Y.; Martinez, A.M. Compound facial expressions of emotion. Proc. Natl. Acad. Sci. USA 2014, 111, E1454–E1462. [Google Scholar]
- Martınez, A.; Benavente, R. The AR face database. Rapp. Tech. 1998, 24. Available online: http://www2.ece.ohio-state.edu/~aleix/ARdatabase (accessed on 1 September 2020).
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with gabor wavelets. In Proceedings of the 1998 Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 200–205. [Google Scholar]
- Lee, H.S.; Park, S.; Kang, B.N.; Shin, J.; Lee, J.Y.; Je, H.; Jun, B.; Kim, D. The POSTECH face database (PF07) and performance evaluation. In Proceedings of the 8th IEEE International Conference on Automatic Face & Gesture Recognition (2008 FG’08), Amsterdam, The Netherlands, 17–19 September 2008; pp. 1–6. [Google Scholar]
- Georghiades, A. Yale Face Database. Center for Computational Vision and Control at Yale University, 1997. Available online: http://cvc.cs.yale.edu/cvc/projects/yalefaces/yalefaces.html (accessed on 1 September 2020).
- Shamir, L. Evaluation of face datasets as tools for assessing the performance of face recognition methods. Int. J. Comput. Vis. 2008, 79, 225. [Google Scholar]
- Dang, L.M.; Hassan, S.I.; Im, S.; Moon, H. Face image manipulation detection based on a convolutional neural network. Expert Syst. Appl. 2019, 129, 156–168. [Google Scholar] [CrossRef]
- He, M. Distinguish computer generated and digital images: A CNN solution. Concurr. Comput. Pract. Exp. 2019, 31, e4788. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Expression | Bosphorus | RaFD |
|---|---|---|
| Neutral | ◯ | ◯ |
| Afraid | ◯ | ◯ |
| Angry | ◯ | ◯ |
| Disgusted | ◯ | ◯ |
| Sad | ◯ | ◯ |
| Smiling (smiling) | ◯ | ◯ |
| Surprise (scream) | ◯ | ◯ |
| Contemptuous | ◯ | |
| No. of subjects | 58 | 67 |
| No. of images per subject | 7 | 8 |
| Index of neutral face images | 5 | 6 |
| No. of testing images | 348 | 469 |
| Method | Bosphorus | RaFD | ||
|---|---|---|---|---|
| PCA | DCV | PCA | DCV | |
| B-WIM | 95.56% | 96.11% | 90.48% | 93.33% |
| WIM [31] | 91.11% | 89.44% | 84.29% | 90.95% |
| ICR [28] | 93.89% | 71.67% | 76.67% | 59.05% |
| E(PC)A2+ [21] | 92.78% | 84.44% | 65.71% | 65.24% |
| SPCA+ [25] | 88.89% | 85.00% | 55.71% | 65.71% |
| (2D)PCA [26] | 91.11% | 92.78% | 76.19% | 75.71% |
| SLC [27] | 91.11% | 83.89% | 75.24% | 71.90% |
| MVI [29] | 92.78% | 90.56% | 74.76% | 75.24% |
| SRGES [30] | 92.22% | 82.78% | 77.62% | 93.33% |
| Expressions | AR | CK+ | Jaffe | PF07 | Yale |
|---|---|---|---|---|---|
| Neutral | ◯ | ◯ | ◯ | ◯ | ◯ |
| Afraid | ◯ | ◯ | |||
| Angry | ◯ | ◯ | ◯ | ◯ | |
| Disgusted | ◯ | ◯ | |||
| Sad | ◯ | ◯ | ◯ | ||
| Smiling (smiling) | ◯ | ◯ | ◯ | ◯ | ◯ |
| Surprised (screaming) | ◯ | ◯ | ◯ | ◯ | ◯ |
| Method | Bosphorus | RaFD | ||
|---|---|---|---|---|
| PCA | DCV | PCA | DCV | |
| B-WIM | 87.64% | 88.51% | 81.88% | 87.21% |
| WIM [31] | 86.49% | 75.29% | 76.12% | 82.30% |
| ICR [28] | 83.91% | 66.67% | 66.52% | 49.89% |
| E(PC)A2+ [21] | 83.62% | 72.70% | 58.85% | 61.19% |
| SPCA+ [25] | 78.16% | 76.72% | 47.33% | 55.86% |
| (2D)PCA [26] | 81.32% | 82.76% | 67.59% | 67.38% |
| SLC [27] | 82.18% | 76.15% | 71.86% | 65.46% |
| MVI [29] | 82.76% | 83.05% | 65.88% | 69.08% |
| SRGES [30] | 81.90% | 83.91% | 73.13% | 82.73% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.; Choi, S.-I. Training Set Enlargement Using Binary Weighted Interpolation Maps for the Single Sample per Person Problem in Face Recognition. Appl. Sci. 2020, 10, 6659. https://doi.org/10.3390/app10196659
Lee Y, Choi S-I. Training Set Enlargement Using Binary Weighted Interpolation Maps for the Single Sample per Person Problem in Face Recognition. Applied Sciences. 2020; 10(19):6659. https://doi.org/10.3390/app10196659
Chicago/Turabian StyleLee, Yonggeol, and Sang-Il Choi. 2020. "Training Set Enlargement Using Binary Weighted Interpolation Maps for the Single Sample per Person Problem in Face Recognition" Applied Sciences 10, no. 19: 6659. https://doi.org/10.3390/app10196659
APA StyleLee, Y., & Choi, S.-I. (2020). Training Set Enlargement Using Binary Weighted Interpolation Maps for the Single Sample per Person Problem in Face Recognition. Applied Sciences, 10(19), 6659. https://doi.org/10.3390/app10196659