1. Introduction
Industrial Internet of Things (IIoT) has emerged as an enabler of the rapid integration of advanced technologies in the industrial world [
1]. Factories are becoming fully connected and smart, thereby allowing manufacturers to improve process efficiency, sustainability, and safety while decreasing costs. Many industries are making heavy investments in smart manufacturing and production systems. In return, they expect optimal and sustainable production with minimum maintenance efforts. This makes maintenance one of the most important aspects of industrial process activities. Formerly considered as part of general enterprise costs, it has become a real source of data and critical for business continuity and performance [
2].
Systems such as Computerized Maintenance Management System (CMMS), Manufacturing Execution System (MES) and Enterprise Resource Planning (ERP) are used to perform maintenance activities in several industries [
3]. These systems provide features such as predictive and preventive maintenance, maintenance planning, scheduling, execution, monitoring and traceability. However, these systems have two inherent drawbacks. First, they are intended to optimize the maintenance process at given location (a factory or a site). This means that two different factories (or sites) cannot share the details of a specific machine’s maintenance operations without a human expert in the loop. Such sharing is useful when machines share the same characteristics and perform the same operations regardless of their locations. While cloud-based offers are a potential remedy, several customers still do not want to have their data on multiple vendor cloud platforms.
The second drawback of these systems is that they are not interoperable at the semantic level. Schneider Electric works with several Original Equipment Manufacturers (OEMs) who design, build and ship machines for their customers around the world. In our experience, there is no easy way to align the data coming out of these maintenance systems and to thereby get a uniform understanding. This issue is complicated by the heterogeneity of these systems and the associated silos since each business segment and customer is unique and operates under different regulatory and geographic constraints. Despite these challenges, our customers are increasingly demanding better visibility about the performance of their assets, reductions in maintenance costs and downtime, improved productivity and more agility in their end-to-end processes.
In this paper, we present the early outcomes of our work, SemKoRe: how we use it to construct knowledge graphs of machine failures and exploit it to address various issues. SemKoRe is a vendor agnostic solution that uses formal, shared and explicit models to capture the details of machine domains, the failures of these machines and the applied repairing procedures. SemKoRe is designed to speed-up the maintenance process and to allow for quick recovery from failures. When a new machine is installed in a factory today, there is no existing knowledge of its failures. In any given factory, each failure is only discovered at its first occurrence. The maintenance process includes diagnostics to determine the reasons for a failure, its impact, and to define and apply the correct repair procedures. This process is repeated at different locations for the same machines having the same failures. In reality, failure details are usually captured manually, e.g., using spreadsheets (e.g., Excel). This approach is not fault proof as each person filling out the sheet cannot be expected to provide all the required information and even if that information is given, there will be semantic mismatch, e.g., one person describes issue as "abnormal rotation speed" while another person describes the same issue as "irregular spinning rate". Both mean the same but use different semantics (we provide more details on it based on interactions with our actual customers in
Section 2).
SemKoRe helps to avoid this semantic mismatch, and captures all the machine, failure and maintenance data as a knowledge graph, allowing several actors to benefit (
Section 4 and
Section 5). For example, Operators and Technicians can benefit from the knowledge provided by other operators at different sites to address their issues. This will also reduce the risk of mismanipulation of machines by incompetent operators, which is a considerable industrial threat in reality [
4]. OEM Machine Builders can improve the next generations of the machines they build, thanks to the knowledge captured in SemKoRe that helps them to know why certain machines have higher failure rates. Analytic teams can improve their work, as SemKoRe will provide a global view of machine failures and the background of a variety of contexts.
We implement our SemKoRe system using a triplestore called "GraphDB by Ontotext" (as cloud/gateway triplestore), IBM Node-Red (flow-based development tool), Microsoft Azure (for cloud service), Azure IoT Hub (for IoT connectivity), and Docker (to package SemKoRe services) (
Section 6). To support the needs of different actors, SemKoRe is developed using the semantic web and ontologies [
5]. This approach helps to accommodate future requirements and to provide a clear separation of concerns between the application needs and the domain knowledge which in this case is machine domain and failure domain knowledge. We adopted a distributed architecture in which knowledge collection is performed on the edge layer. The collected knowledge is shared with other actors and machines through a cloud-based instance.
2. Motivating Scenario and Requirements
In this section, we talk about some key motivating scenarios, with practical examples, that would help to envision the core idea of the problem domain. Then we present the set of customers requirements that guided us during the elaboration of our solution.
2.1. Motivating Scenario
The following scenario is based on our interactions with real customers who want to improve their existing maintenance process. Let us consider three actors: Bob the machine operator, Alice the maintenance technician and Joe the OEM machine builder. On a given day, Bob is working on factory floor operating several machines when suddenly one machine stops working. Bob spends some time to fix the issue himself but is unable to do so, since Bob’s main job is to operate the machine. He might be able to fix small issues due to his experience but he is supposed to call a qualified technician for anything major. He then calls Alice to come to factory floor to check on the machine. When Alice checks the machine she finds that she is also not able to solve the issue so she calls the OEM or Schneider Electric service bureau, where a machine expert guides her through the repair process. Finally, Alice is able to fix the issue and the machine starts working.
The whole process took a long time and while Bob is now able to operate his machine, if the same issue occurs in a similar type of machine located in a different city the same process would likely be repeated because only Alice knows how to quickly solve this particular issue. However, if Alice can describe what she learned from the service bureau and share her experience with the technicians in other sites by using some appropriate mechanism, they could all benefit from this common knowledge.
Another beneficiary of this common knowledge is Joe. Today, when Joe gets reports about the issues with his machines from different customers, he has no easy way to get the finer details that can only come from the technicians like Alice. These details could be useful and help him to understand why some of his machines are facing particular issues. This can help him to improve the design and engineering process of his machines, especially in the case of hundreds or thousands of machines being used worldwide, the scale of problem and timely action in resolving the issue becomes hugely difficult. Another benefit is that using the insights from customer A, Joe can help customer B to quickly respond to machine issues while respecting of privacy and sensitive nature of the information, if both customers have the same type of machines. The importance of the quick resilience after failure aspect is discussed in details by Alcaraz et al. in [
6].
2.2. Requirements
Based on the motivating scenario described above, we now present the following set of requirements. The first requirement is that the proposed solution should make it easy to capture and share knowledge among various actors. The second requirement is that the proposed solution should be usable both on cloud (public or private) and on-premise systems. Indeed many customers are willing to connect their machines and factories to the cloud, while others choose to fully isolate their factories in order to protect their industrial property and to keep their private data locally. The third requirement is that the solution should have built-in mechanism to protect the sensitive information about the processes and the business. During our interactions with customers, this requirement came up as the make or break point for them. The fourth requirement is that the solution should support root cause analysis and make it easy to identify the component(s) that cause the failures. The fifth requirement is that the solution should be platform-independent and thus should not depend on any particular hardware or software platform. The sixth and last requirement is that the proposed solution should be open and extensible to cover the current as well as future needs. These requirements are also thought to avoid introducing security issues or affecting the machines’ performances in the customers sites [
7].
3. Related Works
E. Kharlamov et al. present one of the earlier works, from a major industrial company on capturing industrial information models using W3C standards [
8]. This work proposes an application front-end to allow non-semantic experts to develop ontologies. The front-end is a modified Web-Protegé [
9], that hides the complexity associated with the desktop Protegé version. The work highlights the benefits of involving domain experts to capture the domain knowledge and to create different services using it. However, the solution does not cover our main requirements.
N. Zaini et al. [
10] propose a generic online tool for building collaborative ontology without prior deep knowledge of the domain. An initial ontology is built, populated and enriched by multiple participants in a collaborated manner. The goal is to simplify the ontology based modeling of domain knowledge for the users without ontology expertise. However, the ontology concepts are not sufficiently abstracted, as these concepts are simply renamed. This means that despite simplification, substantial semantic expertise is needed to make the necessary modifications to the ontology. Another important missing element is that there are no checks to ensure consistency which can be an issue in a multiple user environment.
There is a large pool of work on industrial maintenance. D. L. Nunez et al. [
11] created a taxonomy of the Prognostics and Health Management in manufacturing. They propose a formal ontology for failure prognostics based on industrial ISO standards for failure mode analysis, failure diagnostics and prognostics (e.g., ISO 13372, ISO 13379, ISO 13381 and others). Failure knowledge is described in ontologies from ISO standards. Semantic Web Rule Language (SWRL) [
12] is used to define rules in order to generate warning messages in case of abnormal states. However no approach is described to share the acquired failure knowledge among different users.
In [
13], M. Melik-Merkumians et al. used ontologies for fault diagnosis for industrial control applications. They utilized reasoning capability to check the model consistency over the time and to raise early-alarms for critical failures.
L. Palacios et al. [
14] propose an ontology based support for fault diagnosis for aircraft maintenance operations. An aircraft maintenance ontology is modeled and fed by the (manual) alignment of several existing ontologies related to the avionics domain to discover the relations between the causes and failure symptoms, explain the failures and any unscheduled maintenance requirements as well as the possible procedures that can be applied to each situation.
An ontology-based approach is adopted by H. Peng et al. [
15] for the fault diagnostics of conveyors. The knowledge about fault symptoms, fault causes and fault solutions was modeled with multiple ontologies. The resulted ontologies were mapped together based on a mathematical formulation of conveyor fault diagnostics. Some reasoning rules were defined in order to infer additional relations between faults, symptoms and potential causes.
In [
16], R. Chen et al. used ontologies to model the knowledge of fault diagnosis for rotating machines. Their proposed ontology model describes fault diagnosis knowledge considering the vibration characteristics as main fault factor. The model’s reasoning capability is considered by defining some SWRL rules for fault diagnostics.
F. Xur et al. [
17] also relied on ontologies to design a loader fault diagnosis system. It aims to help users find the fault causes, locations and fault maintenance measures of loaders in a reasonable amount of time. Ontology is used to model the loader information and describe the relative failures. This work uses the Condition Based Reasoning (CBR) method to diagnose loader faults by finding similar corresponding situations in the past. When no corresponding case is found, CBR fails and the (SWRL-based) Rule Based Reasoning (RBR) approach is proposed for fault diagnosis.
In [
18], S. Wan et al. developed a Collaborative Maintenance System Planning that allows many stakeholders to collaborate to ensure maintenance process quality. An ontology-based approach is adopted to model a large field of knowledge: the machine domain model, failure knowledge and stakeholders knowledge are modeled together to ensure the interoperability between their systems, the maintenance planning and Resources and Constraints knowledge. However, this centralized solution focuses mainly on preventive maintenance planning. In addition, the managed failure knowledge is relatively basic and does not consider root causes or symptoms.
All the works mentioned above use ontologies to model machine data models and failure knowledge. However, none of these works satisfy all of the requirements that we identified from our motivating scenario. These works developed various ontology models and some exhaustively described potential failures and their characteristics. However, to the best of our knowledge no machine failure ontology is available for reuse or for extension. Furthermore, neither of our two major requirements, i.e., knowledge sharing and data confidentiality have been considered.
Furthermore, many cloud-based solutions are proposed to enhance the maintenance process for different domains like smart grids, shop-floors, etc. Different aspects were analyzed: such as remote maintenance [
19], fault detection [
20], machines monitoring [
19,
21], preventive maintenance scheduling [
22], predictive maintenance [
23], or data confidentiality [
24]. However, none of these studies considered sharing experiences or knowledge between different actors for maintenance purpose.
4. Architecture and Ontology Models
In this section, we discuss our contributions and our proposed architectures, along with the developed ontology models.
4.1. High-Level Architecture
As mentioned before, our customers require different deployment options, and so we divided them into three categories and developed three architectures. In the first category, customers prefer to not connect their machines to the cloud and some even do not want to connect to the Internet due to the sensitive nature of their business, and to protect their data. The architecture proposed for this category is shown in
Figure 1a. The second category of customers opted for an entirely connected architecture, in which the machines/gateways in their factories are directly connected to the cloud. For this category, we proposed the architecture shown in
Figure 1b. The third architecture targets the customers who refuse to connect their machines to the cloud, but are ready to deploy a local on-premise server between the cloud and their machines. For this use case, we proposed a hybrid architecture
Figure 1c, where most of the collected data stays in the local server, and only an anonymized part of the data are transmitted to the cloud.
In all these cases, each machine is connected to an industrial IoT gateway, e.g., Modicon M262 (
https://www.se.com/ww/en/product-range/65771-modicon-m262/) to collect the run-time data of the machine and the information provided by maintenance personnel and/or operators. Each gateway is connected to a central entity (either a Local SemKoRe or a SemKoRe Server) which collects the data from all the gateways and then aggregates and shares with the gateways connected to the same type of machine.
Though, the Achilles heel of our proposal remains the case of the first category of customers, i.e., who do not want to connect their factories to the cloud. The unique technical solution to share the maintenance knowledge consists of using physical supports (e.g., USB keys, CDs, ...) with human intervention. However, the internal business case analysis is still in progress. We believe that once the business case is finalized, the technical adaptation of the SemKoRe services will be trivial and will not require lot of efforts.
In this paper, we focus on the cloud-based architecture because it covers all the constraints and features of the other architectures. This architecture is also implemented in a proof-of-concept to demonstrate the feasibility (see
Section 6).
4.2. Detailed Architecture
Figure 2 shows the detailed architecture of the SemKoRe.
The SemKoRe consists of three entities:
A SemKoRe Agent: Runs on industrial IoT gateways connected to the machines. It collects data when failures occur in the connected machines. According to the chosen architecture, the collected data are then shared with either the SemKoRe Server or Local SemKoRe. The SemKoRe Agent is designed to fit in all architectures (see
Figure 1).
A SemKoRe Server: Running on the cloud, it manages several failure data producers, i.e., Local SemKoRes or SemKoRe Agents. The collected failure data are validated by an expert and aggregated and afterwards shared with the SemKoRe Agents and/or Local SemKoRes.
Local SemKoRe: Lightweight instance of the SemKoRe Server deployed on a local server to manage the machines located in a site or factory. It collects data produced by the SemKoRe Server (if available) and the SemKoRe Agents on local gateways. The data aggregation is done locally, and only aggregated data are shared with the SemKoRe Server. The cloud then merges its aggregations with the Local SemKoRe aggregation, and pushes back the updates to the corresponding entities.
We use in the cloud a message broker to connect the machine gateways to the SemKoRe Server for bi-directional data sharing. We also developed a REST (Representational State Transfer) interface on the SemKoRe Server side to directly call remote services, e.g., commissioning service.
4.3. Machine Failure Ontology Model
The first part of our work is collecting information on machine failures to be able to answer the following questions:
What are the failure symptoms? Symptoms reflect the perceptible aspects of failures whether they are visual, sonic, odor or heat related.
What is the impact of the failure? This may or may not be detected easily. Each failure impact is relative to a machine or to one of its components.
What are the root causes of a particular failure? This question is difficult to answer, since it assumes prior knowledge about the cause-effect relations specific to each machine type. Answering this question requires the knowledge of a machine domain expert.
After knowing the failure type and impact, how can we repair the machine?
After knowing the root causes of a specific failure, is there a preventive maintenance procedure that can help us to avoid that failure?
To answer all of these questions, we defined the data model of the machine failures using Semantic Web standards because of the schema-less nature of RDF (Resource Description Framework), RDFS (RDF Schema), OWL (Web Ontology Language) and the explicit formalism supported by these languages. The failure ontology is created by interacting with the machine builders and by using the initial set of requirements described in
Section 2.2. It acts as a common data model and will be enriched with new concepts by domain experts over time. Progressively, our design, engineering, configuration and maintenance tools will use this ontology to create the knowledge about the failures and allow us to develop different services over it. SemKoRe targets the industry automation business, in which the failure knowledge can be significantly different from one customer to another. The concept uses a flat ontology model, containing only the most common general concepts required for current needs. The subsequent specialization concepts will be easily and naturally added by domain experts as the knowledge collection progresses.
To develop the machine failure ontology presented in
Figure 3, we adopted the Seven-step method, developed by the Medical Information Center of Stanford University [
25]. Its seven steps are as follows:
Determine domain and scope: This work focuses on industrial machine failures.
Consider reusing existing ontologies: No existing machine domain or machine failure ontology was found for reuse, therefore we developed both for this work. Regarding upper-level ontologies, there are several candidates like Basic Formal Ontology (BFO), ISO-15926, Gist, and Suggested Upper Merged Ontology (SUMO) but we still need to finalize one.
List important terms in the ontology: After interactions with the machine domain experts, the following important terms were identified Failure, Symptom, Impact, Root cause, Solving Procedure, among others.
Define classes and class hierarchy: Several classes were created including the important terms listed above. However, since no specialization concept will be introduced, the ontology is flat. Only the classes relative to types (e.g., Failure Type, Symptom Type) are grouped as sub-classes of the Types class.
Define object properties of classes: We defined a set of object properties that link all the defined classes together. For example, the property
hasSymptoms links a Symptom to a specific Failure. The complete list is illustrated in
Figure 4b
Define data properties of classes: We also defined several of the data properties of classes, with cardinality and type constraints, as shown in
Figure 4c.
Create instances and check exceptions: Instances of SemKoRe ontology are divided into two parts. The first part, defined by experts during the design time, concerns the generic concepts that will be used for most industrial use cases, such as Severity level (Catastrophic, Critical, Moderate, Low). The second type of instances concern the data provided by the users during the runtime of the SemKoRe. Users instances include details about the failures and symptoms. To check for exceptions, we used Pellet reasoner [
26] to verify the correctness of our ontology model.
In addition to the failure ontology, we also created a machine domain ontology (
Figure 4a) to describe the machine components to satisfy our requirement to link failures to specific machine components when and where they occur, as simply knowing about a failure is not useful on its own. We also need to identify the components that caused a failure or that show failure symptoms, so that they can be identified as candidates for repair or inspections. For simplification, we only described two types of machines in our machine domain ontology, a Tray Sealers Machine and a Packaging Machine. Each machine type is composed of many components (PLC, Drive, Actuator, Sensor, and others), connected through different communication buses. To integrate both ontologies, we created OWL Class
FailureAsset, to associate failures to the corresponding components in the machine domain ontology.
However, we faced another issue to identify the exact component of a machine that has failed or is impacted by the failure. For example, consider that a machine has two Servo Drives of the same type. These Servo Drives are described in the machine domain ontology as two instances (SDA and SDB) of the "ServoDrive" class and are associated with the instance of a machine. When a failure occurs in SDA, we should be able to identify it through ontology. Such detailed identification is especially useful when the failure knowledge is shared with the other sites using the same machine type, as it will help them to recognize the exact component responsible or impacted by the failure.
To address this issue, each component in the machine domain ontology has a unique number "FunctionID", to distinguish its role in the machine compared to other components of the same type.
We used both desktop Protégé [
27] and Web-Protégé [
9] to create our ontologies. The latter allowed us to include machine domain experts in the ontology development process and to gather and organize their feedback.
It is important to mention that our main focus in this work has been on the validation of the idea to the OEMs, that formalized knowledge about machines and their failures can be useful for quick resolution of failures and to improve Overall Equipment Effectiveness (OEE). The ontology, in its current form, will be extended to cover the needs of the OEMs. To guarantee the ontology generality, a potential extension basis could be the adoption of taxonomy of ISO standards for failure mode analysis (similarly to [
11]). Relevant actors can be involved to extend these ontologies with new concepts and relationships by using appropriate tools like the ones mentioned in
Section 7.1.
5. SemKoRe Process
Figure 5 shows the SemKoRe process of failure data collection and sharing. The process is distributed on two layers: on the edge with the SemKoRe Agent, and on the cloud with the SemKoRe Server.
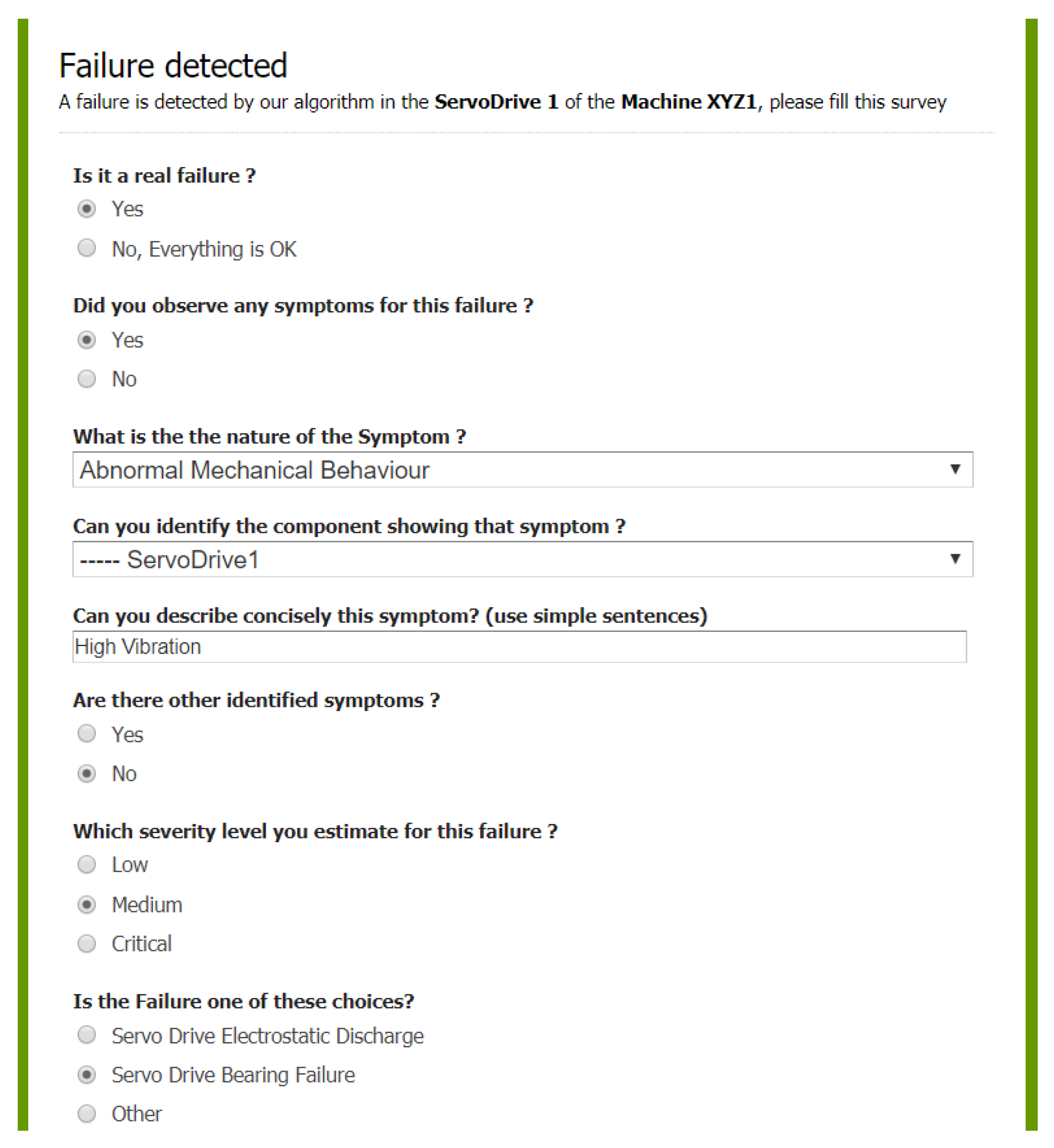
The failure data collection starts when a machine failure occurs. The failure information collection service generates the Human Machine Interface (HMI) for the user (Bob or Alice) to offer the details of the failure
Figure 6. Through the survey, we first try to know if the failure has really occurred or it was only a false positive case triggered by some failure detection service. Then the user is asked to provide details about the symptoms of the failure by selecting known symptoms or by creating new ones, when necessary.
The user checks if the identified failure is already known by the SemKoRe before providing additional details. If the failure already exists, the user follows the instructions to repair the machine. Otherwise, the failure will be documented by Alice or by machine domain experts as shown in
Figure 5. Sometimes, the impacts of a failure may differ from one machine to another. So, existing repair procedures might be adapted or new procedures might be created to repair the machine. This process ends, in the edge level, by sharing the collected data with the SemKoRe Server in the cloud.
When the SemKoRe Server receives failure data from a SemKoRe Agent instance, the data must be validated by a machine domain expert before it is integrated into the SemKoRe Knowledge Graph. After the validation process, data are anonymized to protect the data and customer privacy and business sensitive information of the customers (see
Section 6.3). The anonymized data are then aggregated (see
Section 6.4) in order to get insights about the occurrence frequency of failures, their impacts and the most adapted/used repairing procedures.
The aggregated data are then shared with the SemKoRe Agents instances connected to the same machine type. On the other side, each SemKoRe Agent instance integrates the data it receives from the cloud into the local triplestores (Graph databases).
6. SemKoRe Implementation
In this section, we describe the services implemented for the SemKoRe. It must be noted that the services deployed on Local SemKoRes are the same as the ones deployed on a SemKoRe Server. As stated previously, we only focus on the architecture where gateways are directly connected to the cloud (since its an overarching architecture and covers all the scenarios we described in
Figure 1).
6.1. Startup Commissioning
Knowing that our Failure ontology will evolve, it is only deployed on the SemKoRe Server. On-premises, the gateways must run the commissioning service in order to get the latest failure model corresponding to the type of the connected machine. The startup commissioning service retrieves two types of information from the SemKoRe Server:
The machine failure T-Box, containing the concepts defined in the failure ontology; and,
A-Box data, containing the instances of the T-Box concepts. Knowing that the SemKoRe Server manages data relative to several types of machines, the A-Box retrieved by a gateway contains only the information relative to the machines connected to it.
The startup commissioning service sends a request to the SemKoRe Server with the identity and the type of the connected machines. The SemKoRe Server runs then a Construct SPARQL query to create a sub-graph containing all the data (T-Box and the A-Box) related to the provided machine type. The resulting sub-graph is sent back to the gateway.
6.2. Failure Data Collection
This service runs exclusively in the SemKoRe Agent and is used during or after the maintenance phase. It consists of the following two parts:
6.2.1. Failure Survey
This part collects the failure information using an ordered set of predefined questions. It facilitates the collection of perceptible symptoms of the failures as well as the reporting of new symptoms and failures. During our interactions with machine domain experts, we found that the content of the survey is strongly correlated with the machine types and the kinds of failures they encounter. Our on-field interactions with the operators, technicians and experts highlighted the importance of an intuitive user interface.
6.2.2. Failure Ontology Instantiation
We use the Model Driven Interfaces (MDI) to dynamically generate the user interfaces using the Failure ontology. This procedure has two advantages: One, the UIs allow instantiation of the Failure ontology by non-technical users without any knowledge about the Semantic Web or ontologies; and Two, the UIs enforce the constraints defined in the ontology model and ensure that all the inputs are valid. These UIs rely on the annotations defined in the ontology such as, @rdfs:label and @rdfs:comment. The former is used as a human readable label of the input fields shown to the user, while the latter is displayed to explain the nature of the field and the expected input. We defined an additional annotation @semkore:hidden to hide a field on the UI in case it should be defined automatically or exclusively by an expert.
The ontology model incorporates two types of constraints: value and cardinality constraints, as described below.
Value Constraints
In the W3C OWL reference [
28], a value constraint is used to enforce restrictions on the range of a property when applied to a particular class description. Value constraints can be applied to data properties, for which the value is a data literal, and object properties, for which the value is an individual. We handle each type of property differently:
Data properties: Users can input a value in the text box which will be validated to make sure that the data type is correct as per the defined constraints; and
Object properties: A select box is provided with the list of all possible values. For example, for the object property Machine hasComponent AllValuesFrom Component, will lead to a select box with the list of all available Component instances. With this approach, the probability of getting an invalid input is eliminated altogether.
Only the
owl:someValuesFrom constraint was managed differently from the W3C standard [
28] definition, as it defines a constraint that is applied to at least one value, which means that the property could have other values without any restrictions. Since our UIs are targeting non-expert users, and to guarantee the consistency of our model, we considered
owl:someValuesFrom as being similar to the
owl:allValuesFrom constraint in our implementation.
Cardinality Constraints
In the W3C OWL reference [
28], a cardinality constraint restricts the (min, max, or extact) number of values a data or object property can have. To satisfy the cardinality, single/multiple input fields are generated for each property, allowing to the user to provide the correct number of values for each property.
6.3. Anonymization Service
Privacy protection is a very important concern for our customers. They do not want to share any machine and process-related data in a way that could potentially expose sensitive business information. To address this concern, we implemented a simple service (described below), in the SemKoRe Server in the cloud, to anonymize the collected data before sharing it with other sites or locations.
When a failure occurs, the gateway creates an instance of “Failure Occurrence Class”, containing information about the failure, e.g., symptoms, impact, root causes if known, and the failure context, which includes the machine ID, its location, timestamp when failure occurred, and a snapshot of the current parameters. The whole process consists of three steps:
The SemKoRe Server removes the machine ID, location, and owner-related information and does not share this information.
A human expert reviews and validates all of the failure information before integrating it into the SemKoRe Knowledge Graph. This additional check helps to protect sensitive business information.
Finally, all the validated failure information is aggregated and then shared with the connected gateways. This process ensures that no one can deduce the origin of the data, the failure location or the ownership details.
This service is a subject for future SemKoRe versions. The goal is to automate this process so that little to no human involvement is required.
6.4. Failure Data Aggregation
Hosted in SemKoRe Server, this service and aggregates failure data collected from different gateways in order to produce deep insights on the machine failures and their characteristics including symptoms, impacts, and root causes. Once the aggregation is done, the data are shared by the SemKoRe Server with the connected gateways that need it. We have defined a list of simple aggregations that are applied to the failure data:
For each machine type, get the list of all failures and their frequency;
For each failure, compute the list of all possible symptoms with the frequency of each symptom;
For each failure, compute the list of all possible impacts with the frequency of each impact;
For each failure, compute the list of all possible root causes with the frequency of each root cause; and
For each failure, get the list of solutions with the number of times each solution was successfully used to repair that failure.
For each of these aggregations, a dedicated SPARQL query is executed and the results are injected into the Knowledge Graph. The aggregation service executes after every new data collection to keep the Knowledge Graph up-to-date.
6.5. Failure Data Sharing
The failure data sharing is done through the SemKoRe Server’s message broker. Each gateway subscribes to the topic ".../failure_updates/{machine_type}", where {machine_type} is the type of machine to which the gateway is connected. When failure data are sent to the SemKoRe server (through the REST interface), it is validated, anonymized, aggregated and then published on the message topic corresponding to the right machine type. The gateways receiving these data will simply update the locally stored graph data.
6.6. Implementation Details
To demonstrate the feasibility of the SemKoRe approach, we developed a proof-of-concept (
Figure 7) using the following technologies:
GraphDB: We used GraphDB [
29] as triplestore in the cloud and in the gateway. It provides high performance and scalability in addition to the reasoning capabilities.
Node-Red: Node-Red was used to develop all above-mentioned services for the SemKoRe Server and the SemKoRe Agent. Node-Red is a flow-based development tool for visual programming originally developed by IBM for wiring together hardware devices, APIs (Application Programming Interfaces) and online services as part of the Internet of Things [
30]. Node-Red is gaining popularity for rapid application development in Schneider’s Industrial Automation business.
Microsoft Azure: The SemKoRe Server services are hosted on Microsoft Azure, which provides high-performance cloud services. The server uses Azure IoT Hub [
31] to connect the IoT devices to the cloud using several communication protocols, including the MQTT (Message Queuing Telemetry Transport) messaging protocol [
32], which we used to simplify the data flow transmission between our SemKoRe agent and server services. For the edge, the Azure IoT Edge service was used to easily connect the edge gateways to the cloud via Azure IoT Hub as shown in
Figure 7.
Docker: This is a popular container-based virtualization [
33] tool. Docker supports many operating systems and hardware architectures, and allows self contained applications to be packaged and executed with a high level of portability and reproducible results [
34]. We used Docker to package all of the services of SemKoRe Server and SemKoRe Agent. In reality SemaKoRe agent will reside with many other components. Docker allows us to have the flexibility of deploying different components easily and manage/extend them without impacting others.
As we are still in early stage, we were not able to implement the SemKoRe in real conditions with SemKoRe Agent running on Industrial Gateways connected to real machines. The main obstacle was that the current hardware available for this work had ARM architecture and so it would require a significant effort to port the triplestore and other software components. That effort was beyond the scope of our work. However, after the successful PoC, the business team decided to use an industrial PC as a gateway with enough RAM (8GB), processing (Intel Atom) and storage (64GB) capability. The next iteration of this work will use this industrial PC when it is ready for commercialization. In the meantime, we evaluated our implementation by simulating many virtual SemKoRe Agent instances on a PC equipped with an Intel(R) Core(TM) i7-7820HQ processor, and 16Gb of RAM. We used a single GraphDB server to manage separate triplestores for all the SemKoRe Agent instances. We randomly defined a set of three machine types {Packaging Machine, Palletizing Machine, Pasteurization Machine} that we associated to the active SemKoRe Agents. Each machine type was associated with at least two SemKoRe Agent instances which were then connected to the cloud SemKoRe Server. Our current implementation choices will facilitate an easy transition to industrial PCs in future.
We generated random machine failure data by defining a set of potential failures for each machine type. Each failure was then associated to a set of potential characteristics: symptoms, impacts, root causes and solving procedures. For each machine failure occurrence, we randomly picked one of the potential failures of the machine, and then picked a random number of the failure characteristics from the predefined sets.
We were able to demonstrate that the failure data were collected by each SemKoRe Agent and successfully shared with the SemKoRe Server. The data were aggregated and shared back with the SemKoRe Agent instances connected to the same machine type.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 IoT gateway connected to a real machine:
IoT gateway connected to a real machine:  Local server.
Local server.





