1. Introduction
Sentiment analysis is the task of recognizing positive and negative opinions of users regarding different purposes, e.g., users’ opinions about movies, products, music albums, and many other fields. To provide a better definition, the sentiment is referred to as a judgement, opinion, attitude, or emotional state prompted by feeling. Sentiment analysis is an automated process in which, by using the natural language processing (NLP), the subjective information is computationally identified, analyzed, and classified into positive, negative, or neutral to specify the sentiment of that text which is the result of its author’s attitude [
1]. There are different types of sentiment analysis, the most popular types are classified and described in the following:
Grained Sentiment Analysis: The results in this type are more than binary classification results where two labels (positive, negative) are presented. It is achieved in fine-grained granularity varying from strong negative, weakly negative, neutral, weakly positive to strong positive based on the determined polarity, mainly used when the polarity precision is highly important and binary results like negative or positive could not be useful and may provide incorrect classifications [
2].
Emotion detection: It classifies different emotions in the text such as fear, anger, sadness, joy, disgust, etc. Sophisticated machine learning algorithms [
3] are used to detect emotions for different goals.
Aspect-based Sentiment Analysis: The results in this type are achieved after splitting the text into different aspects and then assign each aspect a corresponding sentiment. For instance, the result of aspect-based sentiment analysis on a special product’s review “It is so easy to use but Insanely Expensive” would be (a) Ease of use: positive and (b) Price: negative due to the nature of this type, it is mostly utilized in customer-centric businesses to have a deeper understanding of customer’s requirements [
4].
The sentiment analysis field has many applications. For example, in businesses and organizations, they need to find consumer or public opinions regarding their products and services. Individual consumers may also need to know the evaluation of other users of a product before purchasing it. Moreover, they might be interested in others’ opinions concerning political candidates before making a voting decision in a political election. Furthermore, nowadays data are published enormously and freely on the Web, but with no data quality assurance, it is left to the readers to decide whether they believe it or not. This results in high demand for advanced fact checking techniques and applications that contribute to the assurance of data quality. In particular, users surfing the Web are more often inflicted with harm/damage by inconsistent information. In addition, designing and developing such fact checking systems need robust models of sentiment analysis. This task for fact checking detection can be fulfilled when fact checking systems are provided by a general or universal model that can be trained once and then applied to other reviews. Surely, this model should show high performance to increase the accuracy of such fact checking systems.
Hussein in [
5] discussed the importance and effects of the challenges in sentiment analysis is the domain-dependence. Moreover, the author concluded that the nature of the topic and the review structure determine the suitable challenges for the evaluation of sentiment reviews. Hence, building a generalized model is a challenge that should be considered by researchers in this research field.
This work focuses on providing a generalized model for sentiment analysis. It has two main contributions: (a) it shows that convolutional neural networks (CNN) combined with our review to vector algorithm can lead to design models that can be trained once and work well using other types of data that might even be related to a different domain and (b) it shows high performance using different precision metrics compared to other approaches from the state of the art that use same datasets for evaluation. We believe that this is one of the few works that address the generalization capabilities of deep models w.r.t. domain-Independence.
The remainder of this paper is organized as follows:
Section 2 outlines a set of related works. In
Section 3, we present the proposed approach.
Section 4 lists datasets that are used for evaluation purposes. In
Section 5, we cover experimental results.
Section 6 illustrates a detailed discussion containing the major contribution of the paper.
Section 7 concludes the paper and gives an overview of future work.
2. Related Works
Although linguistics and natural language processing (NLP) have a long history of research, few works were published concerning sentiments before the year 2000 [
6]. After 2000, the field has attracted the attention of researchers and many research groups to work on.
To provide an example, [
7] studies the prediction of every review for being negative or positive in the aspect-oriented opinion in the opinion mining domain at the sentence level. The authors of this work propose groups of selected models based on conditional random fields (CRFs) with an added multi-label presentation that not only models the opinion in a review, but also models set of opinions in a single review. In [
8], authors suggest a sentiment analysis system that is able to identify and relate the sentiment to every rated product or item in the reviews. They present a probabilistic model to investigate the structure of each review and to which cluster each of them is related to, where it represents a specific sentiment.
In [
9], the researchers offer a flexible automated classification system that uses supervised machine learning techniques using Markov Logic for sentiment classification on a sub sentence level and incorporates polarity differentiations from different origins.
Furthermore, in [
10], enhanced latent aspect rating analysis model is presented. This model does not require predefined keywords that are associated with specific aspects. This work investigates the reviews in order to define the topical aspects, the ratings of the individual aspect and assigning weights that differentiate depending on the aspects from a reviewer point of view. [
11] proposes a simple hierarchical clustering approach (unsupervised model) for product aspects extraction, clustering, and also defining the relations between aspects (relevant and irrelevant). In [
12], the authors introduce a novel supervised approach for joint topic aspects for choosing specific reviews that are considered to be helpful among a set of reviews.
Moreover, in [
13], an employee dataset is created and a novel ensemble model for sentiment analysis is proposed on aspects level. In [
14], a sentiment analysis is conducted on movie reviews. New features are extracted that have influence on determining the polarity scores of the opinion more accurately. Natural language processing approaches are applied using the impact of the unique extracted features. In [
15], supervised and semi-supervised approaches are investigated for text classification.
Additionally, deep learning is also used for sentiment analysis. Authors of convolutional neural networks for sentence classification use CNN to classify users’ reviews for movies. Others, as in [
15], use bidirectional long-short term memory models which is applied to the IMDb dataset.
Table 1 shows a summary of the state-of-the-art approaches for sentiment analysis. More information regarding the performance of different approaches can be found in
Section 6.
Based on the previous works, this research has started to be one of the highlights for scientific contributions because: (a) it has different applications for recommender systems and fact checking systems, and (b) it contains several challenging research problems that motivate researchers to work and improve their works on them.
3. Approach
In this section, we present the preprocessing, the review to vector algorithm and the design details of the proposed neural models for sentiment analysis, and then the evaluation metrics and the overall evaluation. We aim at training a neural model once using a batch of IMDb dataset and test it on other reviews’ datasets to see how far the generalization is possible.
3.1. Review to Vector
Before features extraction, we removed the stop words from the given dataset, e.g., “the”, “a”, “an”, and “in”. Then, the next step includes removing punctuation. In this step, we extracted feature elements from a batch of IMDb dataset for positive and negative reviews. The batch size has been determined using grid search (see
Section 5). We formulated a function which works like a dictionary where the keys are the words in the text and the values are the count associated with that word. The output is saved in
word_ f eatures.
Algorithm 1 illustrates the procedure of converting reviews to vectors. It takes two inputs and returns the input vectors for all reviews saved in all_ f eatures. The output vectors will be fed later into our proposed neural models The input parameters are word_ f eatures which is the first 4900 words after calculating the frequency distribution of each word from both training data, mainly the positive and negative reviews. The number 4900 words have been selected after applying grid search using different lengths which give the highest performance. The second input parameter is the reviews. The summary of the algorithm is as follows: for each review in the reviews, the function word_tokenize splits the current review into sub-strings (words). After that, for each word in word_ f eatures, it should be checked whether that word is a word in the current review. If yes, 1 is added to the features list or 0 is added if it is not. Finally, the function returns all_ f eatures, which is a matrix.
The vectors of the review to vector algorithm (see Algorithm 1) are used for training different classification models (see
Section 3.2).
3.2. Classification
3.2.1. Convolutional Neural Network (CNN)
To perform the sentiment classification task, we propose a neurocomputing-based approach. A CNN is a kind of feed-forward network structure that consists of multiple layers of convolutional filters followed by subsampling filters and ends with a fully connected classification layer. The classical LeNet-5CNN was first proposed by LeCun et al. [
22], which is the basic model of different CNN applications for object detection, localization, and prediction. First, the output vectors of the review to vector Algorithm 1 are converted to matrices where the goal is to make the application of CNN model possible. As illustrated in
Figure 1, the proposed CNN model has one convolutional layer, one subsampling layer, and an output layer.
The convolutional layers generate feature maps using five (2 × 2) filters followed by a Scaled Exponential Linear Units (SELU) [
23] as an activation function. Additionally, in the subsampling layers, the generated feature maps are spatially dissembled. In our proposed model, the feature maps in layers are subsampled to a corresponding feature map of size 2 × 2 in the subsequent layer.
The final layer, which is a fully CNN model that performs the classification process, consists of three layers. The first layer is the input layer which has 6125 nodes and the second that has five nodes. Each SELU activation function.
The final layer is the softmax output layer. The result of the mentioned layers is a 2D representation of extracted features from input feature map(s) based on the input features for the reviews.
| Algorithm 1 |
| 1: Input: word_ f eatures, Reviews |
| 2: |
| 3: function REVIEW_TO_VECTOR(Reviews) |
| 4: |
| 5: all_ f eatures = [ ] |
| 6: |
| 7: for review in reviews do |
| 8: |
| 9: words = word_tokenize(review) |
| 10: |
| 11: features =[ ] |
| 12: |
| 13: for w in word_features do |
| 14: |
| 15: if (w in words) then |
| 16: |
| 17: Features[w] = 1 |
| 18: |
| 19: else |
| 20: |
| 21: Features[w] = 0 |
| 22: |
| 23: end if |
| 24: |
| 25: end for |
| 27: all_features+=[Features] |
| 28: |
| 29: end for |
| 30: return all_ f eatures |
| 31: end function |
| 32: |
The proposed CNN consists of one convolutional layer and a max-pooling layer is because the small size of our input dimension does not require additional layers to extract features/patterns. The reason for using SELU is due to the fact that (a) SELUs performed better than Rectified Linear Units (RELUs), (b) SELUs offer self-normalization [
23], and (c) they never lead to vanishing gradients problem. Since the dropout is a regularization technique to avoid over-fitting in neural networks based on preventing complex co-adaptations on training data [
24], our dropout for each layer was 0.75, which is related to the fraction of the input units to drop.
The proposed CNN model has been trained on IMDb. Then, the model has been saved to be tested on other datasets. The length of the considered feature vectors is 4900 words that are converted to matrices of size (70 × 70).
The parameters of CNN are selected by using grid search from a scikit-learn library considering different settings.
Table 2 shows parameters used for all the layers of the proposed CNN model.
3.2.2. Shallow Neural Network (SNN)
To perform the sentiment classification task, we use a neural model [
25,
26]. First, the output vectors of the review to vector algorithm are fed into the neural model to the hidden layer which consists of three neurons and a hyperbolic activation function; then, the final layer is the output layer which consists of a softmax activation function, Adam optimizer [
27], and a cross entropy loss function. The parameters are selected by using a grid search from scikit-learn library (
https://scikit-learn.org, see
Figure 2), where the optimizer is Adam and the loss function is the binary cross entropy.
The proposed neural network model has been trained on a batch of IMDb datasets. Then, the model has been saved to be tested on other datasets.
Table 3 shows parameters used for all the layers of the proposed CNN model.
3.2.3. Other Classifiers
Additionally, we examine several classifiers to compare the performance of the existing models and the proposed ones, particularly Support Vector Machines (SVM) [
28], K–Nearest Neighbor (KNN) [
29], Naive Bayes [
30], and Random Forest [
31]. In addition, selecting the previous classifiers has different advantages such as the objective of random forests that they consider a set of high-variance, low-bias decision trees, and the ability to convert them into a model that has both low variance and low bias. On the other hand, K-nearest neighbors is an algorithm which stores all the available cases and classifies new cases based on a similarity measure (e.g., distance functions). Therefore, KNN has been applied in statistical estimation and pattern recognition from the beginning of 1970
s on as a non-parametric technique [
29]. SVM are well-known in handling non linearly separable data based on their nonlinear kernel; e.g., SVM with a polynomial kernel (SVM (poly)) and the SVM with a radial basis kernel (SVM (rbf)). Therefore, we classify the reviews data using three types of SVMs; the standard linear SVM (SVM (linear)), SVM (poly), and SVM (rbf). Finally, we used a simple probabilistic model which is the Naive Bayes. The purpose of using such a probabilistic model is to show how it behaves w.r.t. different contexts.
Table 4 shows values of parameters for the proposed SNN, CNN, and all other classifiers.
3.3. Evaluation Metrics and Validation Concept
To evaluate the overall performance of the classifiers, we consider several performance metrics. In particular, we use precision, recall, f-measure, and accuracy, as in [
32].
Equations (
1)–(
4) show mathematical expressions of the metrics accuracy, precision, recall, and f-measure, respectively, where TP, TN, FP, and FN refer respectively to “True Positives”, “True Negatives”, “False Positives”, and “False Negatives”, respectively:
Regarding the evaluation scenarios, we consider two cases: the domain-dependent and domain–independent cases. Domain-dependent means training and testing have been performed for each dataset. Domain–independent means the training has been performed on a IMDb datasets of subjects and testing has been performed on a totally new datasets. The reason for training on IMDb is due to its large size and thus can support a better generalized model if the training has been preformed and regularized properly.
4. Datasets
4.1. IMDb Dataset
ACL-IMDb [
33] dataset is a collection of reviews that are taken from Internet Movie Database (IMDb). The dataset size is 50 K and contains highly polar movie reviews annotated as positive or negative review, which makes it widely used for a binary classification tasks. The average length of a document in the training set is 25 k for training and 25 k for testing. The dataset also contains an additional bag of words formats and raw texts (
http://ai.stanford.edu/~amaas/data/sentiment/).
4.2. Movie Reviews (MR)
Movie Reviews (MR) is a small sized dataset (
https://www.cs.cornell.edu/people/pabo/movie-review-data/) [
34] (5 k positive and 5 k negative reviews) that contains reviews in the form of labeled sentences, which can be specified as objective or subjective. Furthermore, the selected sentences have been gathered from IMDb and Rotten Tomatoes websites (
https://www.rottentomatoes.com/), each selected sentence contains at least 10 words. The sentiments of these sentences have been classified as positive or negative.
4.3. Amazon Dataset (Amazon)
Reviews data from iPhone wireless earphones on Amazon were collected. Overall, we collected 480 negative reviews and 480 positive ones in order to use the data to check the overall performance of the proposed model. We annotated the data with 0 or 1 where every positive review is annotated or labeled by 1 and the negative reviews were annotated by 0.
5. Results
In this section, we want to demonstrate the performance of the proposed approach. The prototype is implemented in Python. In order to gain sufficient information and prove the applicability of our approach, the following libraries have been used: NLTK (
https://www.nltk.org/) library for natural language processing, Keras (
https://keras.io/) (Deep learning) and scikit-learn (
https://scikit-learn.org/stable/) (machine learning), which is mainly used for testing the performance of the other classifiers. We applied 10-fold cross-validation for performance evaluation. The neural models have been trained on a GeForce GTX 1080-NVIDIA (
https://www.nvidia.com/de-de/geforce/products/10series/geforce-gtx-1080/).
In order to conduct experimental results and check the performance of the proposed approach, we tested the algorithm using the extracted features based on three datasets, namely IMDb, Movie Reviews, and Amazon reviews.
To evaluate the overall performance of the classifiers, we consider several performance metrics. In particular, we use precision, recall, f1, and accuracy, as in [
32].
Regarding the evaluation scenarios, we used the trained model in
Section 3.2.
Table 5,
Table 6 and
Table 7 present the precision, the recall, and the f-measure using IMDb, Movie Reviews, and Amazon datasets, respectively.
In all tables, the proposed neural models show the highest performance compared to random forest which is hereby the next best classifier. However, the support vector machine using a radial basis function kernel also performs well for the IMDb dataset, but the Naive Bayes classifier performs much better using our own Amazon dataset.
Additionally, it is remarkable to realize that the proposed shallow neural network performs better than the proposed convolutional neural network model. However, random forest and our proposed neural models show a robust behavior regarding sentiment classification.
Moreover, it should be realized that some classifiers show high precision and low recall or vice versa where high precision relates to a low false positive rate, and high recall relates to a low false negative rate. This reflects the complexity of this classification task and shows the robust performance of the proposed neural models.
Furthermore, the trained neural models are applied on different datasets that are not related to each other (see
Table 8). Despite of this fact, it still behaves well and, consequently, it can be extended for different applications in the research field of sentiment analysis.
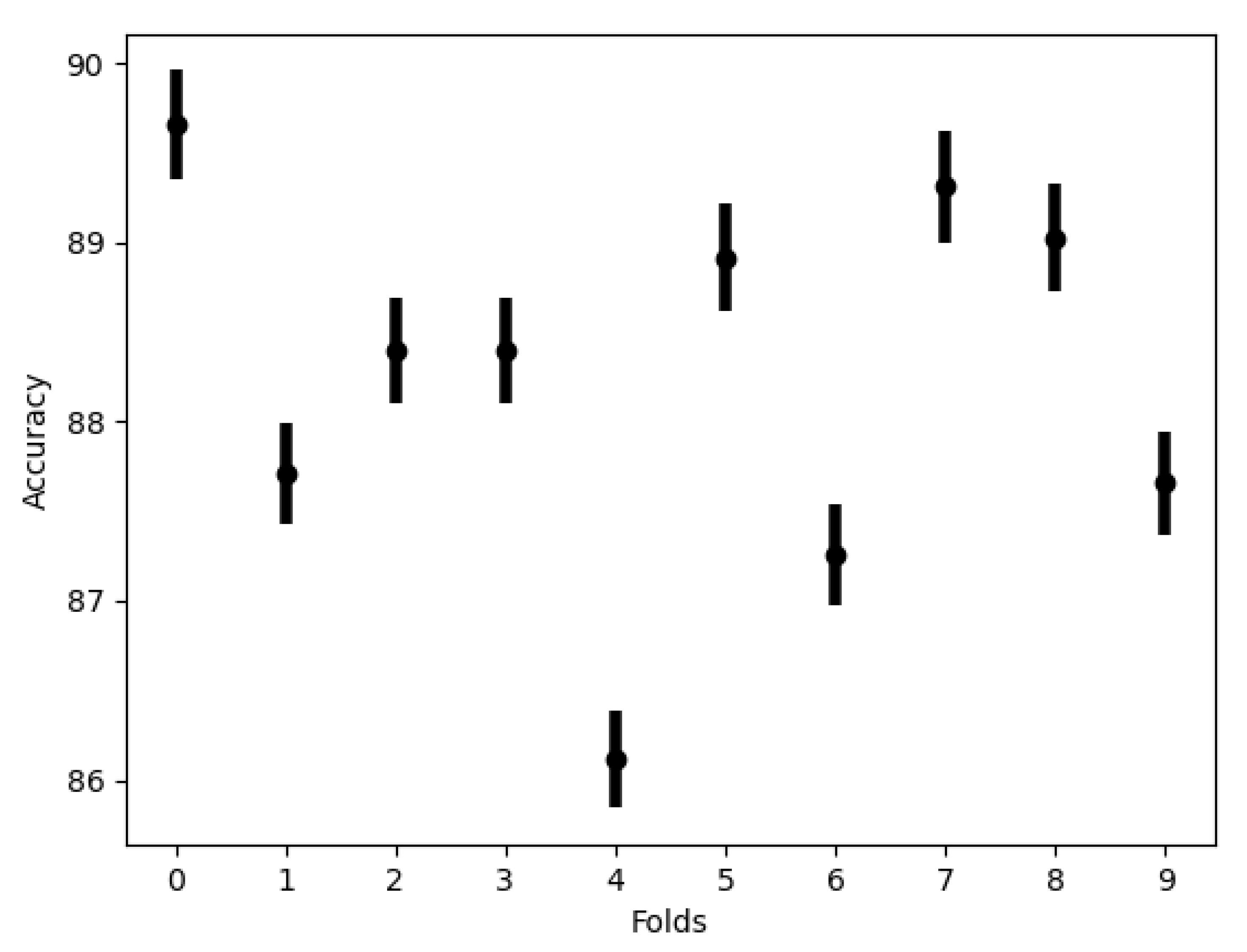
Figure 3 and
Figure 4 show the 10-folds cross-validation results for the trained CNN and SNN models, respectively. In addition, they show the mean accuracy and the standard deviation for each fold. We can observe a reasonable symmetric distribution and that the mean captures the central tendency well. The cross-validation results belong to the pre-trained model which has been applied to calculate the results in
Table 8.
6. Discussion
Based on our results, we could demonstrate the following points:
Summarizing the final opinion in some words might lead to the problem that the extracted features did not take that sentence as a feature of interest. For example, a reviewer might have a positive opinion about acting and the overall story of a movie, but he was not satisfied by the music in certain scenes.
Sentiments can be expressed in different forms that might be even indirect expressions. Therefore, they require common sense reasoning techniques to be classified. In addition, it is challenging to analyze sentiments with complex structures of sentences, especially when negations do exist.
Some reviewers may use expressions that have negative connotations, but at the end of the review, they summarize their overall opinion clearly. Consequently, this makes the classification a tough task.
Feature engineering suffers from overcoming the previous problems.
Sentiment analysis requires analyzing large units of individual words to capture the context in which those words appear.
Table 8 shows that SNN shows a better generalization performance using the MR dataset compared to CNN. The results of other approaches are listed in
Table 9 and
Table 10 for movie review data and IMDb, respectively. Some of the proposed approaches perform better; however, they do not consider the domain-independent sentiment classification. It means that the results are obtained for training and testing on the same dataset.
We can observe that this work is:
Able to classify binary reviews very well, especially, domain-independent reviews.
The first building block toward the generalization of sentiment classification where a model can be trained once and tested on totally new datasets that even may come from different contexts.
It inherits the advantages of neural models which is nowadays able to classify hundreds of objects using a pre-trained model.
This is due to the fact that CNN can overcome many challenges of sentiment analysis that have been highlighted previously. For example, words in a specific region are more likely to be related than words far away. Thus, CNN can automatically and adaptively extract spatial hierarchies of features out of written reviews that may capture different writing styles of users.
7. Conclusions
In this work, we proposed a sentiment analysis generalized approach that is able to classify the sentiments of different datasets robustly. Additionally, the proposed approach showed promising results in the context of domain-independent sentiment analysis. This is due to the fact that neural models can extract robust features when reviews are converted to proper input vectors using our proposed review for vector algorithms. Furthermore, it shows a high performance regarding generalization. The proposed model has been trained once and tested on three different datasets from different domains. The model could perform very well compared to other works that used the same datasets and showed a generalization capability for sentiment classification w.r.t. different domains. Furthermore, the paper covered a wide range of sentiment analysis approaches from the state of the art and compared the results obtained to the performance of the proposed neural models.
Additionally, in our future work, we will integrate the implemented version of the algorithm into different browsers and platforms aiming at using the power of this approach for fact checking purposes.








{kind=link}
{kind=link}
{kind=link}
{kind=link}