3.2. Model Overview
To solve the style transfer problem defined above, our goal is to learn a model with as the input, where is the sentence with the original style attribute, is the target style, and the output of the model is sentence with style .
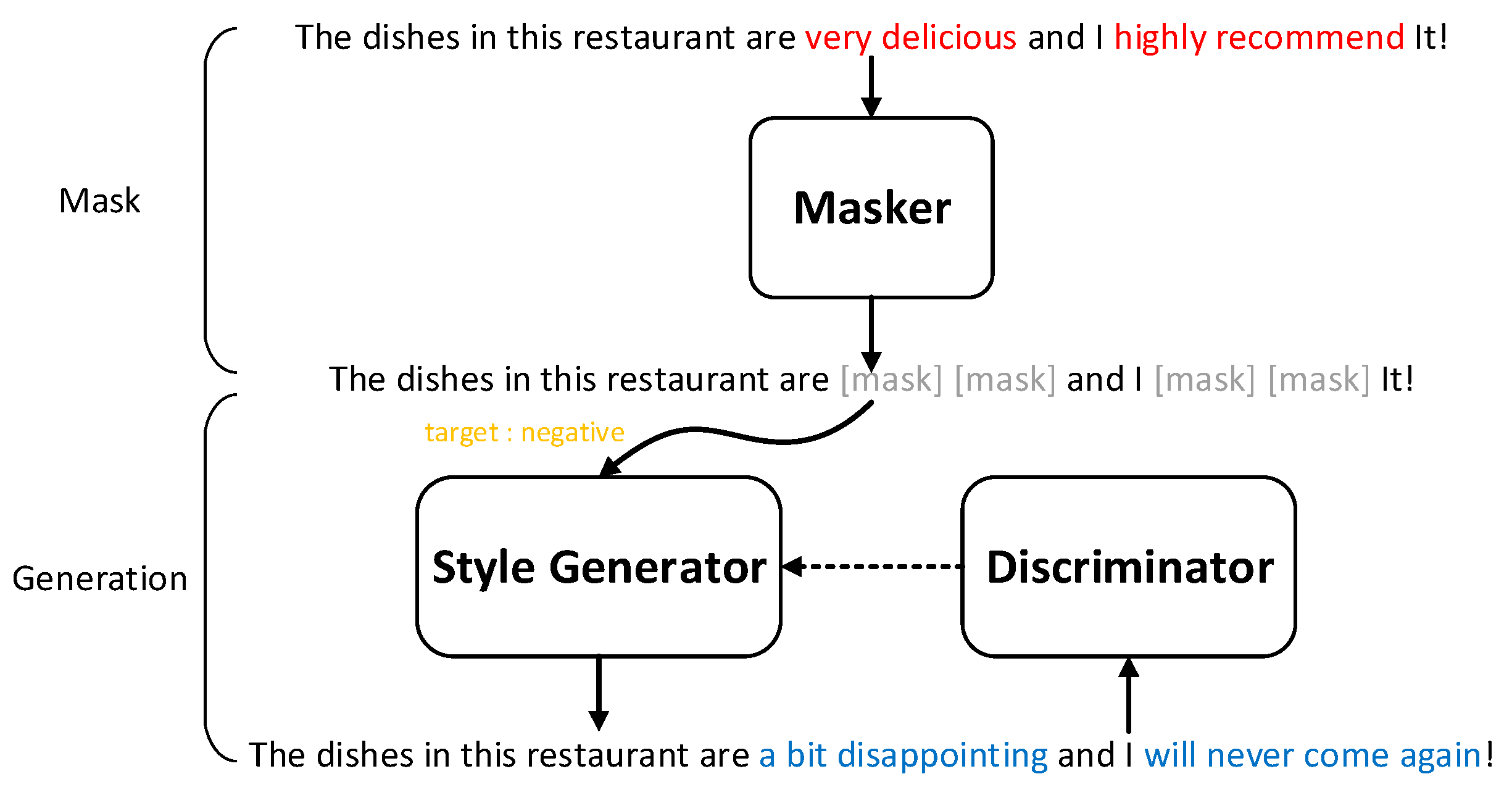
Our method consists of three parts: a Masker module, a Style Generator module, and a discriminator module, as shown in
Figure 2. In
Section 3.3, the Masker module combines the advantages of the two methods by using the self-attention classification model and the auxiliary style dictionary to find the words with strong style attributes in the sentence. After that, it will perform the mask operation to obtain the masked sentence. In
Section 3.4, we take the masked sentence and the specified target style as the input, and the Style Generator will regenerate a sentence with the target style. Unlike the method of filling the mask position, our method will regenerate a complete sentence based on the masked sentence, so that the generated sentence is more flexible in terms of structure and semantics. In addition, a major problem in text style transfer is that there are not enough parallel corpora. Therefore, we cannot directly train our style conversion model in a supervised manner. In
Section 3.5, we will introduce a discriminator-based approach [
21,
22] to conducting supervised training using nonparallel corpora. Finally, we will combine these three parts to train our style transfer model through the learning algorithm in
Section 3.6.
3.4. Style Generator
In the Style Generator, we chose the standard Transformer model, following the classic encoder-decoder structure. For example, for the input
, the transformer encoder
maps it to a latent continuous representation vector
. Then, the transformer decoder
generates the conditional probability of output
through an autoregressive calculation as follows:
For each time
, in the decoder, the probability of generating a word is calculated by a Softmax layer:
where
is the logit vector output by the decoder.
To apply the target style control to the generation, we additionally add a mark of the target style before the input, similar to the <cls> mark for BERT. That is,
. Therefore, the model can calculate the output probability under the conditions of input
and target style s:
We denote the Style Generator model as , where represents the model parameters. Then, the predicted sentence calculated above is denoted by .
3.5. Discriminator
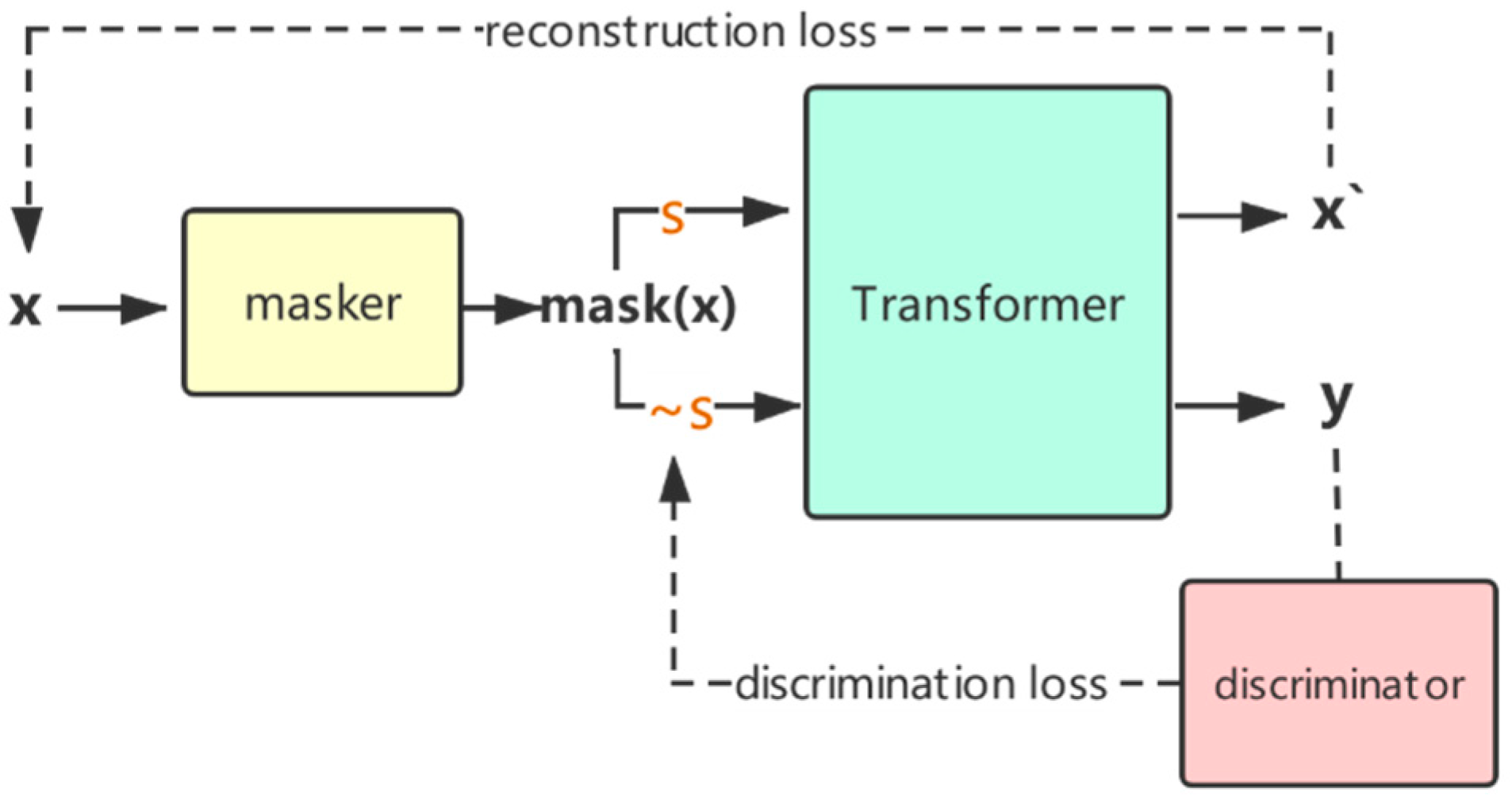
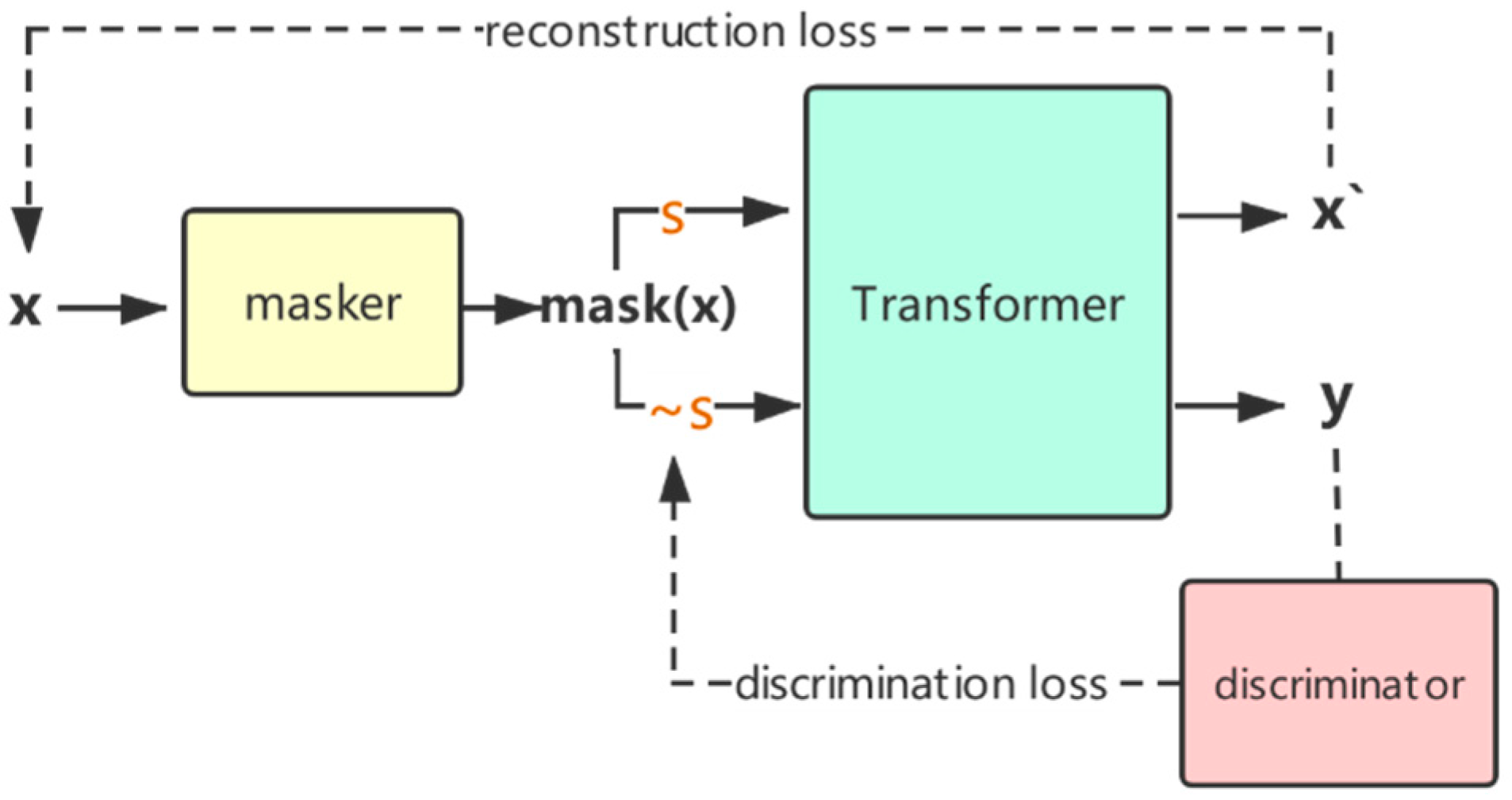
The purpose of introducing the discriminator module is to solve the problem of nonparallel corpus training. When we take samples from the dataset and obtain through the masker module, but due to the lack of a parallel corpus, we cannot obtain the corresponding reference to sentence , while target style . Therefore, we introduce a discriminator module to learn via supervised training from nonparallel corpora.
For the data , we can intuitively restore to sentence according to its original style . Furthermore, we use its own supervised training to make the model have a certain style transfer ability. For the target style , we train a discriminator network to constrain the optimization direction of the generation module in order to better generate target style sentences.
The discriminator network we use includes a Transformer encoder, which is used to distinguish the styles of sentences. The style control information of the discriminator network will be passed to the generation module. Different from the traditional discriminator, in order to better guide the generation module during training, we refer to the discriminator training method of [
18] and use two different discriminator structures. We denote the discriminant model as
, where
is the model parameter.
Similar to the discriminator in conditional GANs (Generative Adversarial Networks), the conditional discriminator makes decisions based on the input sentence and style. Specifically, the conditional discriminator needs to complete a binary classification task, and its inputs are the sentence x and the matching style . The output of the discriminator determines whether the style of the input sentence is .
In the discriminator training process, for the style , the positive sample is the real sentence and the reconstructed sentence , and the negative sample is the transfer sentence while the target style . In the training process of the Style Generator, the goal of the generator is to maximize the probability that the discriminator determines that is true.
- 2.
Multi-Class Discriminator
Compared to the former, the multiclass discriminator only uses one sentence as its input, and its goal is to judge the style of the sentence. Unlike traditional discriminators, for K-style tasks, multiclass discriminators need to perform K + 1 classification tasks. The first K categories are K styles, and the last category is the transfer sentence of the target style . The purpose of this design is to help the generation module learn more accurate knowledge from the discriminator. As the transfer sentence is usually poor at the beginning of training, setting these sentences as another class can make the generator closer to the distribution of real sentences during the iterative training process.
In the discriminator training process, the real sentence and the reconstructed sentence will be labeled as style s, and the transfer sentence will be labeled as class 0. In the training process of the Style Generator, the goal of is to maximize the probability that the discriminator determines that has style .
3.6. Training Algorithm
This section will mainly introduce the training algorithm of each module.
The training algorithm of the masker module mainly trains a classification model based on self-attention. Its goal is to determine the style category of each sentence to obtain the attention weight as the subsidiary product. This is the basis for analyzing and masking the sentence. The loss function for the Masker is the cross-entropy loss of the classification problem; that is,
where dataset
is the original training set.
The learning algorithm of the discriminator mainly trains a classification model based on the Transformer encoder. Its goal is to distinguish between the original sentence , the reconstructed sentence and the transfer sentence . The loss function for the discriminator is the cross-entropy loss of the classification problem.
For the conditional discriminator,
and for multiclass discriminator,
where dataset
consists of
,
and
. The details are given in Algorithm 1.
| Algorithm 1: The Training of the Discriminator |
| | Input: dataset , discriminator , style generator |
| 1 | for each sentence in dataset do |
| 2 | Select a style where ; |
| 3 | ; |
| 4 | ; |
| 5 | Append to dataset |
| 6 | end for |
| 7 | for each iteration i = 1, 2, …, m do |
| 8 | Sample a minibatch of cases from ; |
| 9 | for each case in a batch do |
| 10 | if discriminator is multi-class then |
| 11 | Set {} as class s + 1; |
| 12 | Set {} as class 0; |
| 13 | Compute (10); |
| 14 | else |
| 15 | Set {, } as True; |
| 16 | Set {, } as False; |
| 17 | Compute (9); |
| 18 | end if |
| 19 | end for |
| 20 | Update the model parameters ; |
| 21 | end for |
- 2.
Style Generator Training Algorithm
The training of the style generator is divided into two parts. One part is the case where the target style , and the other part is the case where the target style .
Sentence reconstruction: For the case when the target style
, we can directly apply a training method that reconstructs the mask sentence
into the original sentence
by using its own supervision information. Specifically, when using the style
and the masked sentence
as input, the model output is as
close as possible to the original sentence
. The training goal is to minimize the negative log-likelihood:
where the dataset
is obtained by masking the sentences in the original training set
.
Style generation: For the case when the target style , we introduce a loss function to control the generation of the style, so that the transformed sentences are closer to the distribution of the real sentences and the reconstructed sentences.
Using the conditional discriminator, we can obtain the probability that
is true. The goal of the generator is to minimize the negative log-likelihood:
Using the multiclass discriminator, we can calculate the probability that
has the style
. The goal of the generator is to minimize the negative log-likelihood of the class probability:
Combining the loss functions described above, we can conduct training for the generator. Algorithm 2 shows the details of the training process.
| Algorithm 2: The Training of the Style Generator |
| | Input: dataset , discriminator , style generator |
| 1 | for each iteration i = 1, 2, …, m do |
| 2 | Sample a minibatch of cases from ; |
| 3 | for each case in a batch do |
| 4 | Select a style where ; |
| 5 | Reconstruct the sentence ; |
| 6 | Generate a sentence ; |
| 7 | Judge by discriminator ; |
| 8 | Compute (11); |
| 9 | Compute (12 or 13); |
| 10 | end for |
| 11 | Update the model parameters ; |
| 12 | end for |
By combining the training algorithms of the above modules, we can obtain the whole training process of the model. In the mask part, first, the self-attention model of the Masker is trained. After the model convergence is stable, the Masker masks the sentences in the original dataset
and obtains the dataset
. In the style generation part, using the alternate training method of the generator and discriminator in GANs [
14], we also alternately train the Style Generator and Discriminator. In each iterative round, we first train the Discriminator
steps to obtain an optimized discrimination module. Under the updated Discriminator, the Style Generator will be trained
steps to optimize the results of the generation. The iterative training continues until the model converges and stabilizes. The specific algorithm is given in Algorithm 3.
| Algorithm 3: The Whole Training Algorithm |
| | Input: dataset , attention-based classifier |
| 1 | for each iteration do |
| 2 | Sample a minibatch of sentences from ; |
| 3 | Compute (8) for the batch; |
| 4 | Update the model parameters ; |
| 5 | end for |
| 6 | Build the style dictionary by (5) |
| 7 | for each sentence in dataset do |
| 8 | Mask the sentence using the style dictionary; |
| 9 | if (mask words/length of sentence) < masking percentage then |
| 10 | Mask again according to the attention weight from clsρ; |
| 11 | end if |
| 12 | Append the case into ; |
| 13 | end for |
| 14 | Initialize Style Generator network and Discriminator network ; |
| 15 | for each iteration i = 1, 2, …, m do |
| 16 | for steps do |
| 17 | Algorithm 2; |
| 18 | end for |
| 19 | for steps do |
| 20 | Algorithm 3; |
| 21 | end for |
| 22 | end for |
The learning algorithm of the discriminator mainly trains a classification model based on the Transformer encoder. Its goal is to distinguish between the original sentence , the reconstructed sentence and the transfer sentence . The loss function for the discriminator is the cross-entropy loss of the classification problem.
In addition, there is a problem in training that needs to be briefly explained. Due to the discrete nature of natural language, when we obtain the transfer sentence and input it into the discrimination module, the gradient calculated by the discrimination module cannot be propagated back to the generation module. To solve this problem, it is common to use the Gumbel–Softmax strategy or the reinforcement learning method to evaluate the gradient from the discriminator. However, both methods have the problem of high variance, which makes it difficult for the model to converge and stabilize. Therefore, we use the way that [
18] deal with discrete sample problems. Instead of directly using the generated words as the input, we use the Softmax distribution generated by
as the input. Similarly, for the decoder of the generator, the decoding method is also changed from greedy decoding to continuous decoding. Specifically, at each calculation time, instead of using the word with the highest probability predicted in the previous step, we use the probability distribution as the input. Regarding the input in the form of a probability distribution, the decoder will calculate the weighted average representation of the probability distribution through the embedding matrix.




{kind=link}
{kind=link}