Automatic Detection of Airway Invasion from Videofluoroscopy via Deep Learning Technology


Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. VFSS Protocol
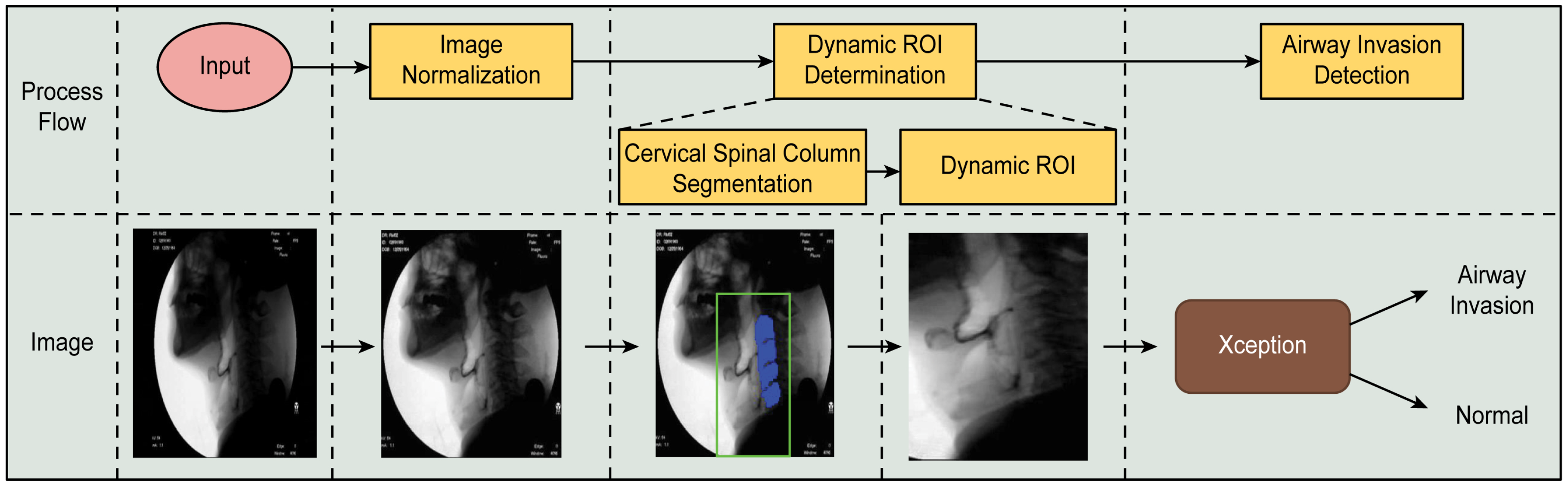
2.3. Proposed Model for the Detection of Airway Invasion
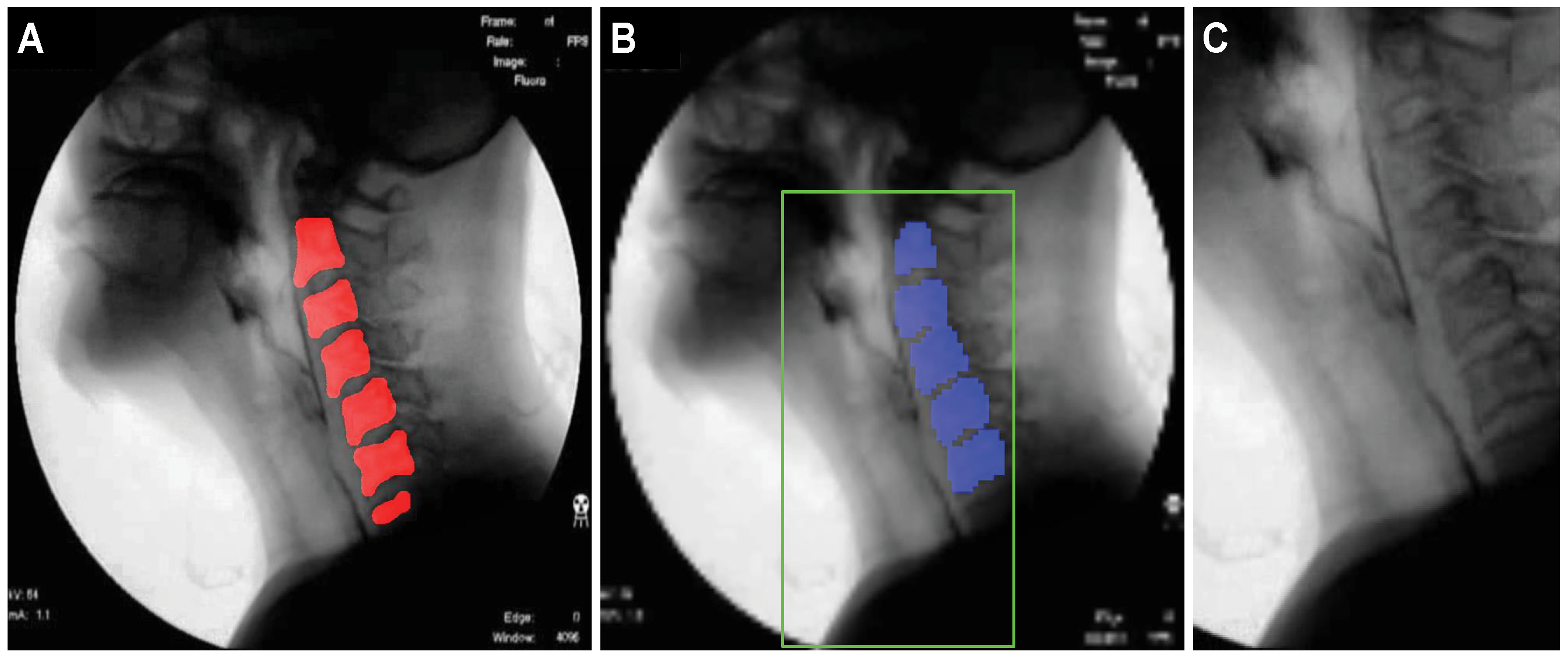
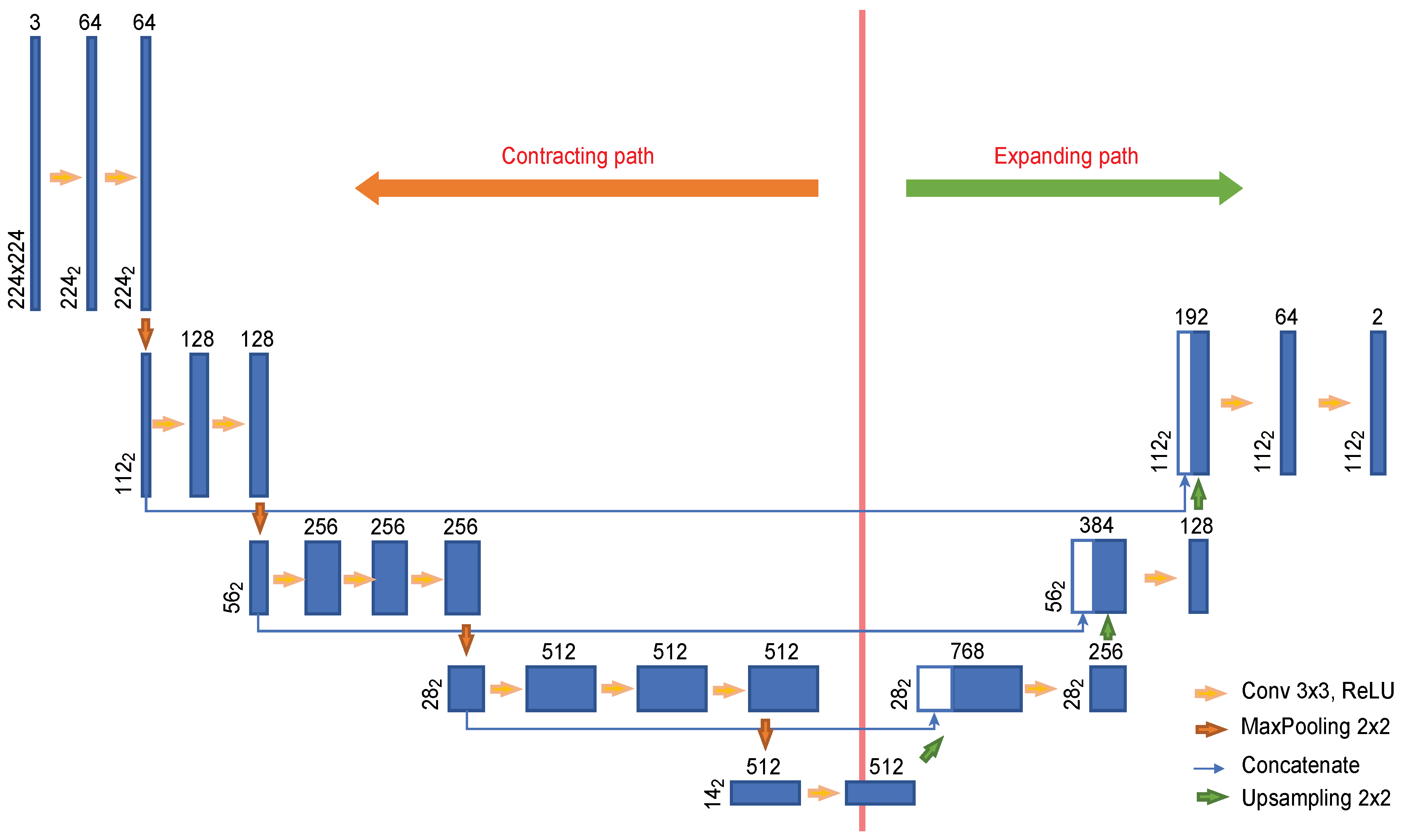
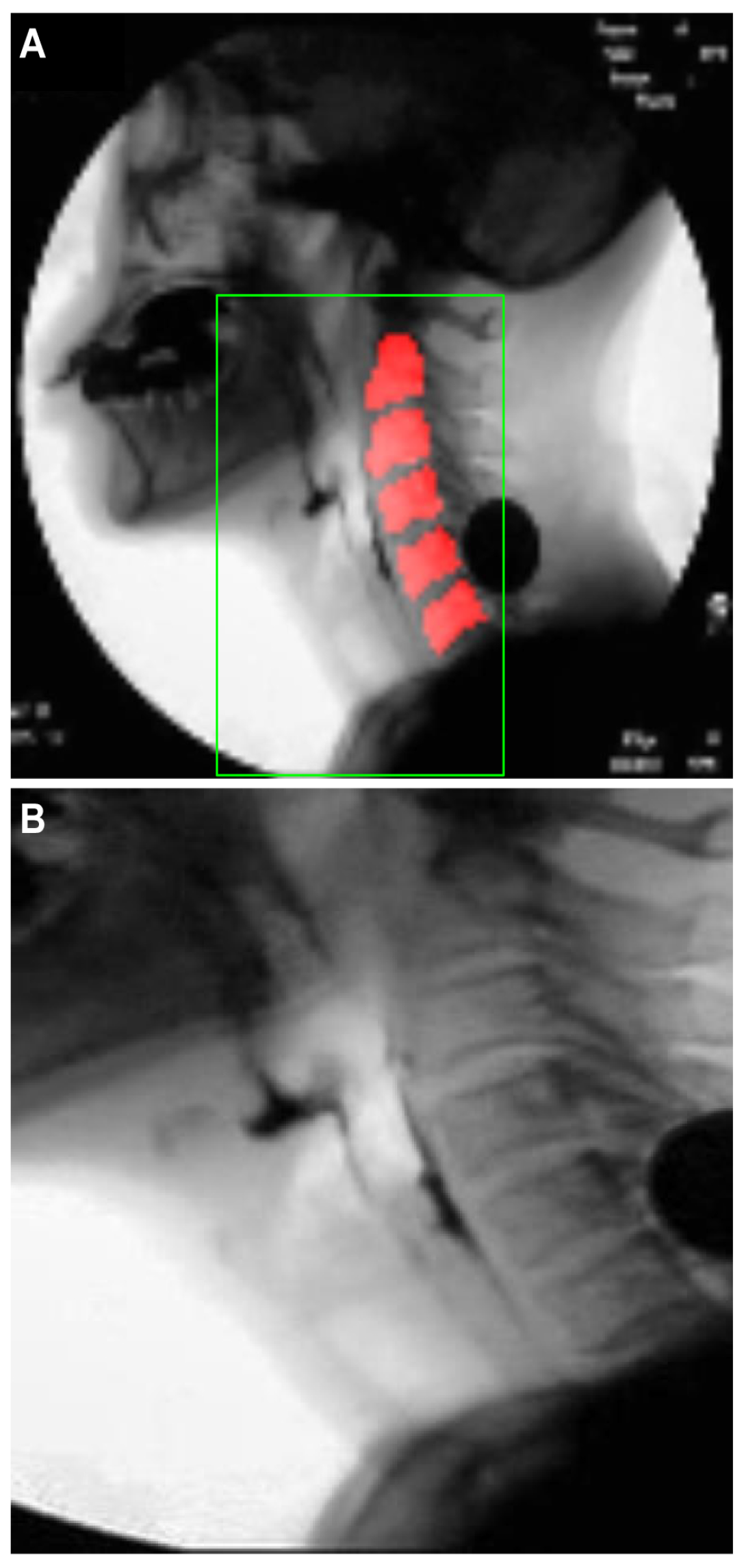
2.3.1. Creation of a Dynamic ROI Using Global Localization of the Cervical Spinal Column
2.3.2. Design of the Airway Invasion Detector
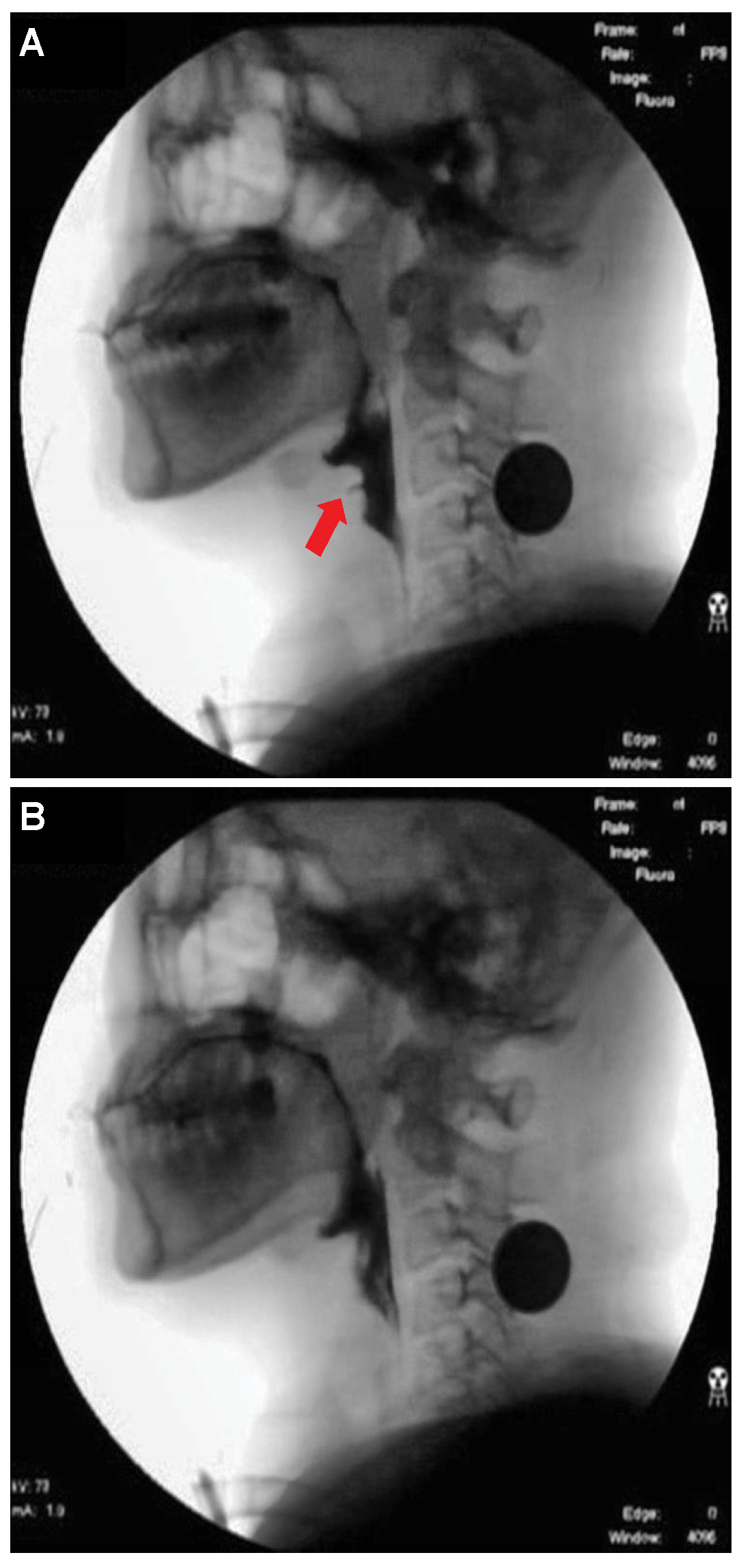
- Deep neural network for the detection of airway invasion:As described in Section 2.3.1, the ROI image (Figure 2C) specified using U-Net is used as the input image for airway invasion detection. To identify the occurrence of airway invasion in individual image frames, we designed a DCNN (deep convolutional neural network)-based classifier. Based on the position and shape of the bolus in the image, the classifier distinguishes whether the bolus is passing normally through the esophagus (normal swallowing action) or whether airway invasion has occurred.A deep neural network contains numerous connections between neurons, and a weight is assigned to each connection. The deeper the network is, the greater the number of weights to be learned, where this increase scales exponentially; consequently, sufficient data are needed to prevent overfitting. Therefore, among the models that can be effectively trained on limited data, in this paper, we choose a CNN based on an Xception module [27]. The Xception architecture not only reduces the number of parameters to be learned by performing convolution on each channel of the image, but also has the advantage of efficiently utilizing spatial and cross-channel correlations in the image (Figure 4). Additionally, by means of residual connections, the degradation problems that can occur as the network deepens can be avoided. In the Xception architecture, data are processed through three flows, namely (1) the entry flow, (2) the middle flow, and (3) the exit flow, and this architecture consists of convolutional layers with a total of 36 3 × 3 filters. All common convolutional and separable convolutional layers are followed by batch normalization [28].For airway invasion detection, we defined the image frames corresponding to instances of airway invasion as the positive class (Figure 5A) and the remaining image frames as the negative class (Figure 5B) and designed a CNN classifier using the Xception architecture with a binary output. Among the 15,335 positive image frames and 252,413 negative image frames included among all 319 video files, seventy percent of the videos in each class were used as training data, and ten percent were used for the validation of the trained network. The remaining 20% of the videos were used as test data to evaluate the final performance of the proposed classifier. Table 1 shows the total number of image frames used in the experiment and the numbers of frames in each class used for training, validation, and testing.In this study, we used an Xception module [27] pretrained on ImageNet and fine-tuned through transfer learning [25] on videofluoroscopic image data (Figure 4). The pretrained Xception module takes an image with 3 channels and dimensions of as the input, whereas a video fluoroscopic image is a grayscale image with a single channel. Therefore, we used the same grayscale ROI image resized to as the input to each of the three channels. The transfer learning procedure increased the validation accuracy by approximately 5% compared to training from scratch.
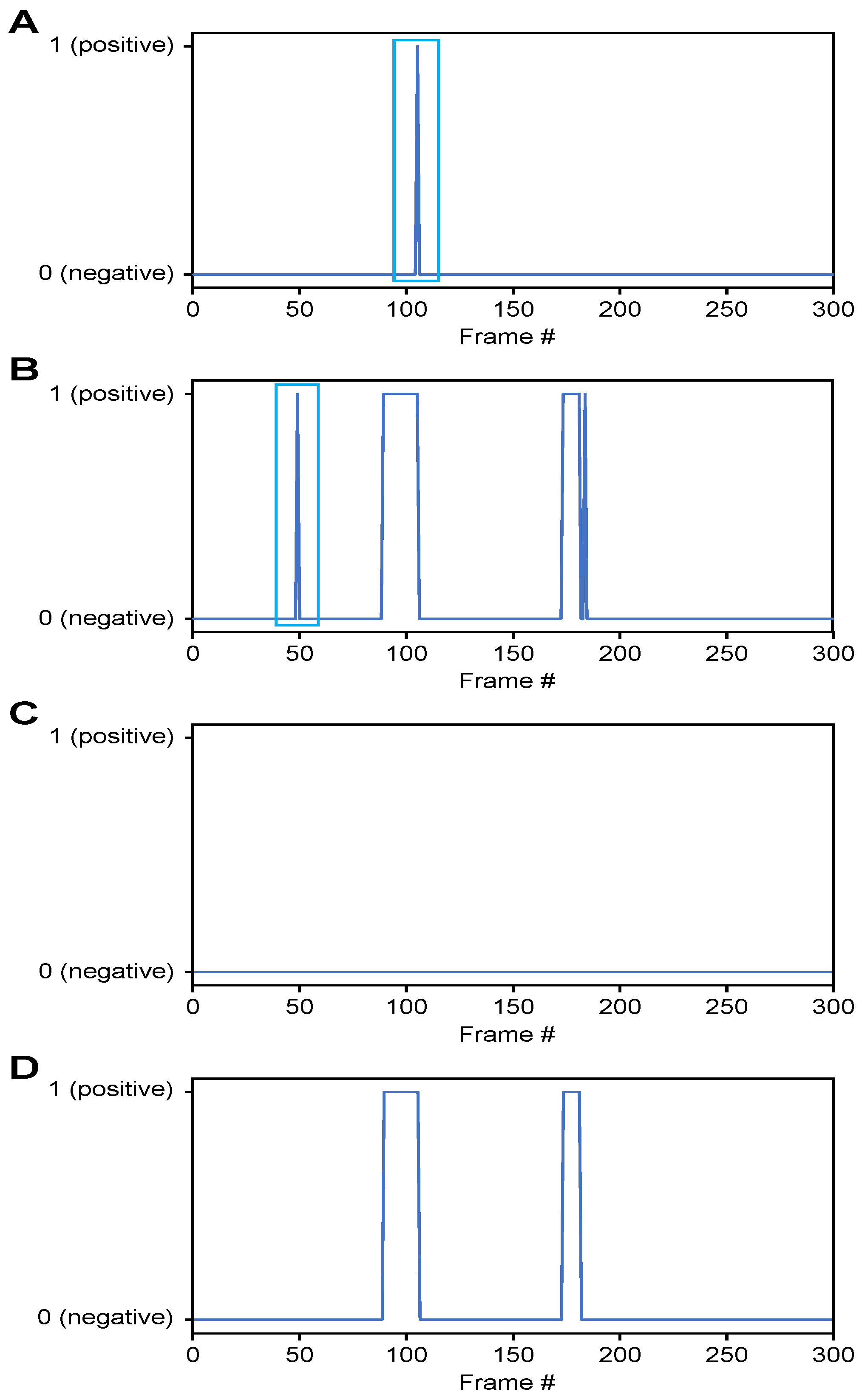
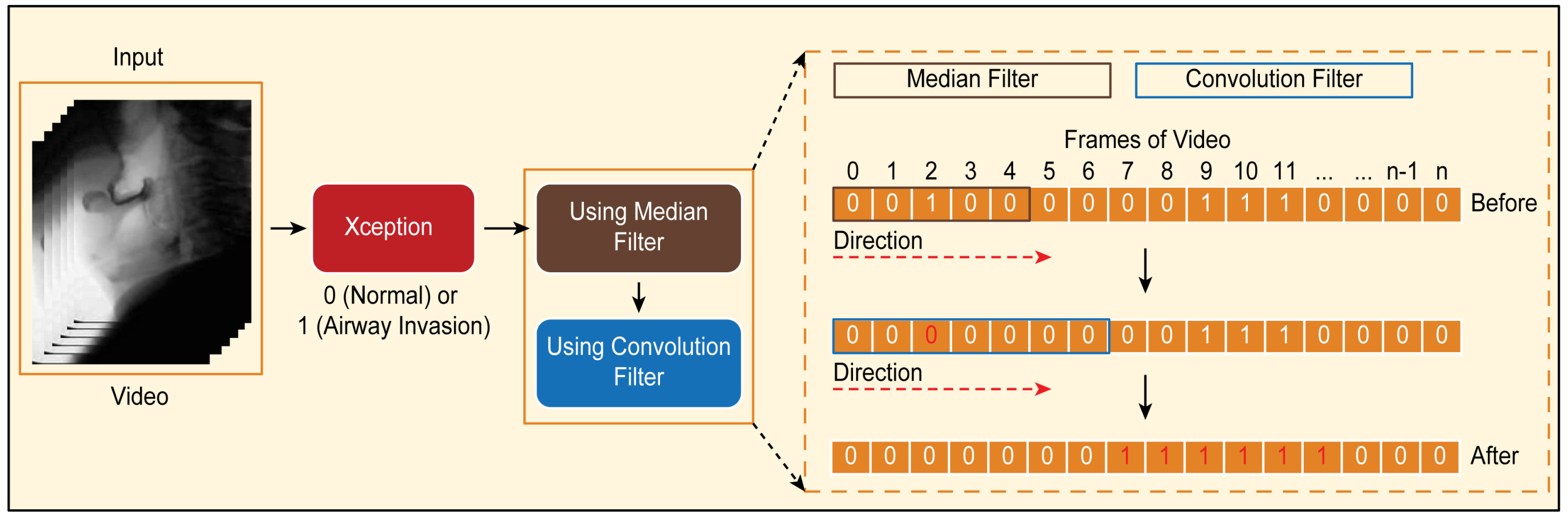
- Classification of airway invasion for a whole video:Figure 6 shows the classification results of the Xception module-based CNN for each image frame included in the videos from two subjects participating in the VFSS procedure (Figure 6A: results for a person with normal swallowing; Figure 6B: results for a patient). In Figure 6, the horizontal axis shows the acquisition time index of the image frames, and the vertical axis shows the classification result for each image frame. A value of 1 appears for a frame that is classified as positive, and a value of 0 indicates a negative classification.Based on the classification results for the individual image frames as shown in Figure 6, we can finally determine whether airway invasion occurred in a particular video of a subject participating in the VFSS. Since the bolus-swallowing motion is a continuous motion, the images acquired during a true instance of airway invasion should be classified as positive samples continuously along the time axis. To capture the temporal context of each video in the final decision on whether airway invasion has occurred, we applied two types of filters, namely a median filter [29] and a convolution filter, to the classification results for the individual images, as shown in Figure 6.First, since the video files we used were recorded at 24 fps, it is reasonable to regard positive samples generated in the form of intermittent impulses, as indicated by the blue boxes in Figure 6A,B, as false positives. Therefore, we chose to correct the classification results for such samples to negative results using a median filter with a length of 5. From a similar perspective, we determined that airway invasion can be considered to have occurred only when two or more of the classification results for seven consecutive image frames are classified as positive samples. Formally, let the vector contain the classification results (Figure 6) for all image frames of a video composed of l frames. We consider that airway invasion has occurred only when the following is two or more:Here, is a convolution filter of length 7 with a value of 1 for all components (Figure 7).
3. Results
3.1. Network Training
3.2. Evaluation Metrics
3.3. Performance Evaluation for the Global Localization of the Cervical Spinal Column
3.4. Performance Evaluation for Airway Invasion Detection
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Logemann, J.A. Evaluation and treatment of swallowing disorders. Am. J. Speech-Lang. Pathol. 1994, 3, 41–44. [Google Scholar] [CrossRef]
- Sura, L.; Madhavan, A.; Carnaby, G.; Crary, M. Dysphagia in the elderly: Management and nutritional considerations. Clin. Interv. Aging 2012, 7, 287–298. [Google Scholar] [CrossRef] [PubMed]
- Martin-Harris, B.; Jones, B. The videofluorographic swallowing study. Phys. Med. Rehabil. Clin. N. Am. 2008, 19, 769–785. [Google Scholar] [CrossRef] [PubMed]
- Scott, A.; Perry, A.; Bench, J. A study of inter-rater reliability when using videofluoroscopy as an assessment of swallowing. Dysphagia 1998, 13, 223–227. [Google Scholar] [CrossRef] [PubMed]
- Kuhlemeier, K.; Yates, P.; Palmer, J. Intra- and inter-rater variation in the evaluation of videofluorographic swallowing studies. Dysphagia 1998, 13, 142–147. [Google Scholar] [CrossRef] [PubMed]
- McCullough, G.H.; Wertz, R.T.; Rosenbek, J.C.; Mills, R.H.; Webb, W.G.; Ross, K.B. Inter-and intrajudge reliability for videofluoroscopic swallowing evaluation measures. Dysphagia 2001, 16, 110–118. [Google Scholar] [CrossRef]
- Stoeckli, S.J.; Huisman, T.A.; Seifert, B.A.; Martin-Harris, B.J. Interrater reliability of videofluoroscopic swallow evaluation. Dysphagia 2003, 18, 53–57. [Google Scholar] [CrossRef]
- Kim, D.; Choi, K.; Kim, H.; Koo, J.; Kim, B.; Kim, T.; Ryu, J.; Im, S.; Choi, I.; Pyun, S.B.; et al. Inter-rater reliability of videofluoroscopic dysphagia scale. Ann. Rehabil. Med. 2012, 36, 791–796. [Google Scholar] [CrossRef]
- Baijens, L.; Barikroo, A.; Pilz, W. Intrarater and inter-rater reliability for measurements in videofluoroscopy of swallowing. Eur. J. Radiol. 2013, 82, 1683–1695. [Google Scholar] [CrossRef]
- Aung, M.; Goulermas, J.; Stanschus, S.; Hamdy, S.; Power, M. Automated anatomical demarcation using an active shape model for videofluoroscopic analysis in swallowing. Med. Eng. Phys. 2010, 32, 1170–1179. [Google Scholar] [CrossRef]
- Chang, M.W.; Lin, E.; Hwang, J.N. Contour tracking using a knowledge-based snake algorithm to construct three-dimensional pharyngeal bolus movement. Dysphagia 1999, 14, 219–227. [Google Scholar] [CrossRef]
- Aung, M.S.; Goulermas, J.Y.; Hamdy, S.; Power, M. Spatiotemporal visualizations for the measurement of oropharyngeal transit time from videofluoroscopy. IEEE Trans. Biomed. Eng. 2009, 57, 432–441. [Google Scholar] [CrossRef] [PubMed]
- Hossain, I.; Roberts-South, A.; Jog, M.; El-Sakka, M.R. Semi-automatic assessment of hyoid bone motion in digital videofluoroscopic images. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2014, 2, 25–37. [Google Scholar] [CrossRef]
- Lee, W.H.; Chun, C.; Seo, H.G.; Lee, S.H.; Oh, B.M. STAMPS: Development and verification of swallowing kinematic analysis software. Biomed. Eng. Online 2017, 16, 120. [Google Scholar] [CrossRef]
- Natarajan, R.; Stavness, I., Jr.; William, P. Semi-automatic tracking of hyolaryngeal coordinates in videofluoroscopic swallowing studies. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2017, 5, 379–389. [Google Scholar] [CrossRef]
- Zhang, Z.; Coyle, J.L.; Sejdić, E. Automatic hyoid bone detection in fluoroscopic images using deep learning. Sci. Rep. 2018, 8, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Lundervold, A.S.; Lundervold, A. An overview of deep learning in medical imaging focusing on MRI. Z. Med. Phys. 2019, 29, 102–127. [Google Scholar] [CrossRef]
- Le, M.H.; Chen, J.; Wang, L.; Wang, Z.; Liu, W.; Cheng, K.T.T.; Yang, X. Automated diagnosis of prostate cancer in multi-parametric MRI based on multimodal convolutional neural networks. Phys. Med. Biol. 2017, 62, 6497. [Google Scholar] [CrossRef]
- Dong, Y.; Pan, Y.; Zhang, J.; Xu, W. Learning to read chest X-ray images from 16000+ examples using CNN. In Proceedings of the 2017 IEEE/ACM International Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), Philadelphia, PA, USA, 17–19 July 2017; pp. 51–57. [Google Scholar]
- Song, Q.; Zhao, L.; Luo, X.; Dou, X. Using deep learning for classification of lung nodules on computed tomography images. J. Healthc. Eng. 2017, 2017, 8314740. [Google Scholar] [CrossRef]
- Lee, J.T.; Park, E.; Jung, T.D. Automatic detection of the pharyngeal phase in raw videos for the videofluoroscopic swallowing study using efficient data collection and 3D convolutional networks. Sensors 2019, 19, 3873. [Google Scholar] [CrossRef]
- Zuiderveld, K. Contrast limited adaptive histogram equalization. In Graphics Gems IV; Academic Press Professional, Inc.: Cambridge, MA, USA, 1994; pp. 474–485. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Arce, G.R. Nonlinear Signal Processing: A Statistical Approach; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 558–567. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Hartwig Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zoph, B.; Ghiasi, G.; Lin, T.Y.; Cui, Y.; Liu, H.; Cubuk, E.D.; Le, Q.V. Rethinking pre-training and self-training. arXiv 2020, arXiv:2006.06882. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Rosenbek, J.; Robbins, J.; Roecker, E.; Coyle, J.; Wood, J. A penetration-aspiration scale. Dysphagia 1996, 11, 93–98. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Validation | Test | Total | |
|---|---|---|---|---|
| No-Invasion Images | 137,095 | 41,322 | 73,996 | 252,413 |
| Invasion Images | 10,524 | 2010 | 2801 | 15,335 |
| Total | 147,619 | 43,322 | 76,797 | 267,748 |
| Deep Learning Algorithm | Accuracy | Recall | Precision | Specificity | NPV | Average Precision |
|---|---|---|---|---|---|---|
| U-Net | 99.0% | 75.6% | 88.7% | 99.7% | 99.3% | 94.8% |
| Accuracy | Recall | Precision | Specificity | NPV | F1-Score |
|---|---|---|---|---|---|
| 97.2% | 74.2% | 59.1% | 98.0% | 99.0% | 0.658 |
| Accuracy | Recall | Precision | Specificity | NPV |
|---|---|---|---|---|
| 93.2% (167/179) | 91.2% (52/57) | 88.1% (52/59) | 94.2% (115/122) | 95.8% (115/120) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.J.; Ko, J.Y.; Kim, H.I.; Choi, S.-I. Automatic Detection of Airway Invasion from Videofluoroscopy via Deep Learning Technology. Appl. Sci. 2020, 10, 6179. https://doi.org/10.3390/app10186179
Lee SJ, Ko JY, Kim HI, Choi S-I. Automatic Detection of Airway Invasion from Videofluoroscopy via Deep Learning Technology. Applied Sciences. 2020; 10(18):6179. https://doi.org/10.3390/app10186179
Chicago/Turabian StyleLee, Seong Jae, Joo Young Ko, Hyun Il Kim, and Sang-Il Choi. 2020. "Automatic Detection of Airway Invasion from Videofluoroscopy via Deep Learning Technology" Applied Sciences 10, no. 18: 6179. https://doi.org/10.3390/app10186179
APA StyleLee, S. J., Ko, J. Y., Kim, H. I., & Choi, S.-I. (2020). Automatic Detection of Airway Invasion from Videofluoroscopy via Deep Learning Technology. Applied Sciences, 10(18), 6179. https://doi.org/10.3390/app10186179