Speech Enhancement for Hearing Aids with Deep Learning on Environmental Noises


Abstract
1. Introduction
2. Materials and Methods
2.1. Deep Neural Networks
2.2. Classification of Environmental Noise
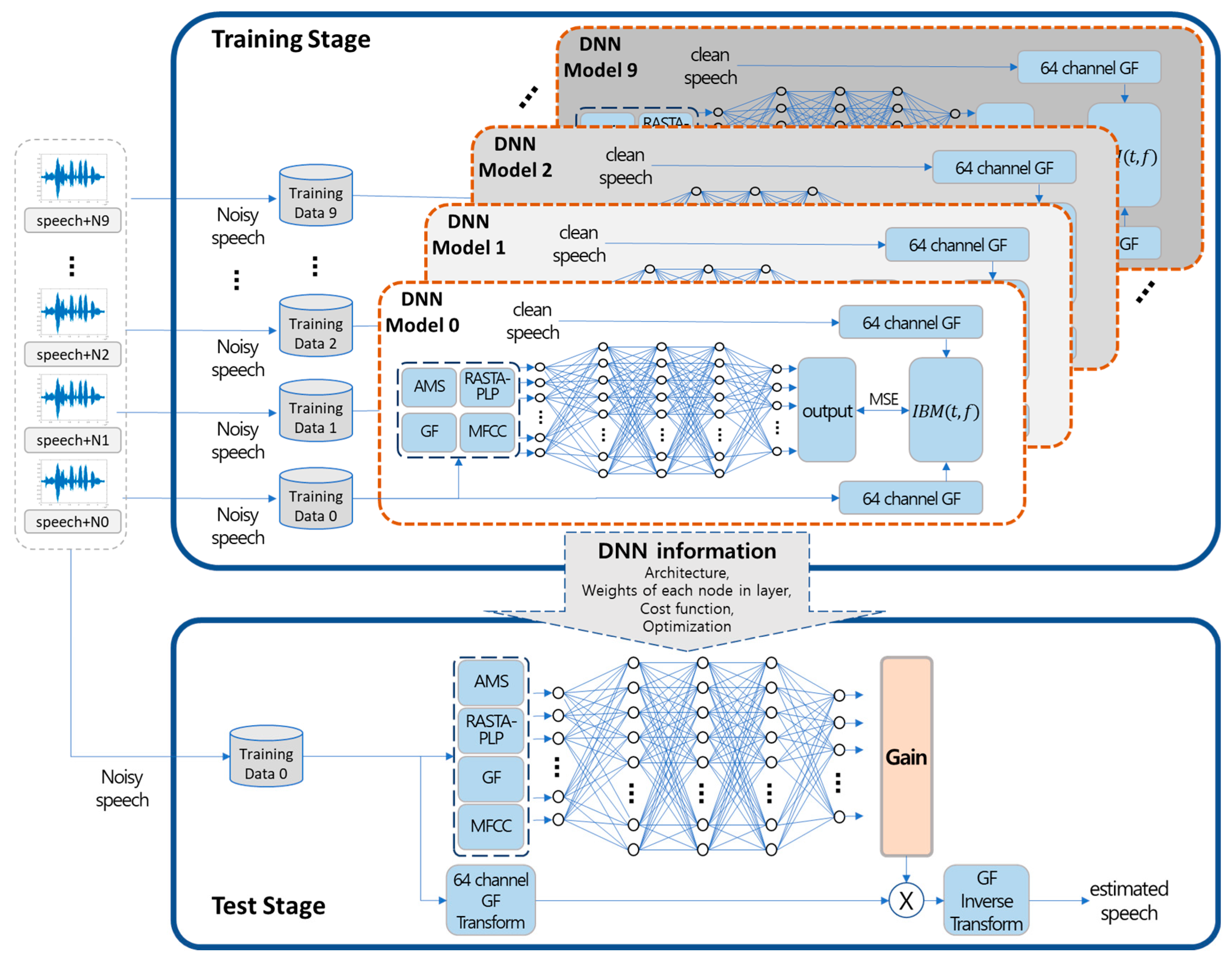
2.3. Proposed Algorithm
2.4. Experimental Setting
2.5. Performance Evaluation
3. Results
3.1. Speech Enhancement
3.2. Comparison Algorithms
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Festen, J.M.; Plomp, R. Effects of fluctuating noise and interfering speech on the speech-reception threshold for impaired and normal hearing. J. Acoust. Soc. Am. 1990, 88, 1725–1736. [Google Scholar] [CrossRef] [PubMed]
- Hygge, S.; Ronnberg, J.; Larsby, B.; Arlinger, S. Normal-hearing and hearing-impaired subjects’ ability to just follow conversation in competing speech, reversed speech, and noise backgrounds. J. Speech Lang. Hear. Res. 1992, 35, 208–215. [Google Scholar] [CrossRef] [PubMed]
- Plomp, R. Auditory handicap of hearing impairment and the limited benefit of hearing aids. J. Acoust. Soc. Am. 1978, 63, 533–549. [Google Scholar] [CrossRef] [PubMed]
- Duquesnoy, A. Effect of a single interfering noise or speech source upon the binaural sentence intelligibility of aged persons. J. Acoust. Soc. Am. 1983, 74, 739–743. [Google Scholar] [CrossRef]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Kim, G.; Lu, Y.; Hu, Y.; Loizou, P.C. An algorithm that improves speech intelligibility in noise for normal-hearing listeners. J. Acoust. Soc. Am. 2009, 126, 1486–1494. [Google Scholar] [CrossRef]
- Martin, R. Noise power spectral density estimation based on optimal smoothing and minimum statistics. IEEE Trans. Speech Audio Process. 2001, 9, 504–512. [Google Scholar] [CrossRef]
- Cohen, I.; Berdugo, B. Noise estimation by minima controlled recursive averaging for robust speech enhancement. IEEE Signal Process. Lett. 2002, 9, 12–15. [Google Scholar] [CrossRef]
- Cohen, I. Noise spectrum estimation in adverse environments: Improved minima controlled recursive averaging. IEEE Trans. Speech Audio Process. 2003, 11, 466–475. [Google Scholar] [CrossRef]
- Loizou, P.C. Speech Enhancement: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Van den Bogaert, T.; Doclo, S.; Wouters, J.; Moonen, M. Speech enhancement with multichannel Wiener filter techniques in multimicrophone binaural hearing aids. J. Acoust. Soc. Am. 2009, 125, 360–371. [Google Scholar] [CrossRef]
- Eddins, D.A. Sandlin’s Textbook of Hearing Aid Amplification; Taylor & Francis: Abingdon, UK, 2014. [Google Scholar]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1985, 33, 443–445. [Google Scholar] [CrossRef]
- Rao, Y.; Hao, Y.; Panahi, I.M.; Kehtarnavaz, N. Smartphone-based real-time speech enhancement for improving hearing aids speech perception. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 5885–5888. [Google Scholar]
- Modhave, N.; Karuna, Y.; Tonde, S. Design of multichannel wiener filter for speech enhancement in hearing aids and noise reduction technique. In Proceedings of the 2016 Online International Conference on Green Engineering and Technologies (IC-GET), Coimbatore, India, 19 November 2016; pp. 1–4. [Google Scholar]
- Reddy, C.K.; Hao, Y.; Panahi, I. Two microphones spectral-coherence based speech enhancement for hearing aids using smartphone as an assistive device. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 3670–3673. [Google Scholar]
- Jeon, Y.; Lee, S. Low-Complexity Speech Enhancement Algorithm Based on IMCRA Algorithm for Hearing Aids. J. Rehabil. Welf. Eng. Assist. Technol. 2017, 11, 363–370. [Google Scholar]
- Jeon, Y. A Study on Low-Complexity Speech Enhancement with Optimal Parameters Based on Noise Classification. Ph.D. Thesis, Inha-University, Incheon, Korea, February 2018. [Google Scholar]
- Varga, A.; Steeneken, H.J. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. Subjective comparison and evaluation of speech enhancement algorithms. Speech Commun. 2007, 49, 588–601. [Google Scholar] [CrossRef]
- Barker, J.; Vincent, E.; Ma, N.; Christensen, H.; Green, P. The PASCAL CHiME speech separation and recognition challenge. Comput. Speech Lang. 2013, 27, 621–633. [Google Scholar] [CrossRef]
- Hirsch, H.-G.; Pearce, D. The Aurora experimental framework for the performance evaluation of speech recognition systems under noisy conditions. In ASR2000-Automatic Speech Recognition: Challenges for the New Millenium; ISCA tutorial and research workshop (ITRW): Paris, France, 2000. [Google Scholar]
- Park, G.; Lee, S. Environmental Noise Classification Using Convolutional Neural Networks with Input Transform for Hearing Aids. Int. J. Environ. Res. Public Health 2020, 17, 2270. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- McClelland, J.L.; Rumelhart, D.E.; Group, P.R. Parallel distributed processing. Explor. Microstruct. Cognit. 1986, 2, 216–271. [Google Scholar]
- Fukushima, K.; Miyake, S. Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition. In Competition and Cooperation in Neural Nets; Springer: Berlin/Heidelberg, Germany, 1982; pp. 267–285. [Google Scholar]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, Proceedings of the Neural Information Processing Systems Conference, Lake Tahoe, NV, USA, 3–6 December 2012; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; NIPS: San Diego, CA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Yang, C.-C. Improving the overshooting of a sharpened image by employing nonlinear transfer functions in the mask-filtering approach. Optik 2013, 124, 2784–2786. [Google Scholar] [CrossRef]
- Hong, S.-W.; Kim, N.-H. A study on median filter using directional mask in salt & pepper noise environments. J. Korea Inst. Inf. Commun. Eng. 2015, 19, 230–236. [Google Scholar]
- Wang, Y.; Narayanan, A.; Wang, D. On training targets for supervised speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1849–1858. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Han, K.; Wang, D. Exploring monaural features for classification-based speech segregation. IEEE Trans. Audio Speech Lang. Process. 2012, 21, 270–279. [Google Scholar] [CrossRef]
- Wang, D. On ideal binary mask as the computational goal of auditory scene analysis. In Speech Separation by Humans and Machines; Springer: Berlin/Heidelberg, Germany, 2005; pp. 181–197. [Google Scholar]
- Han, K.; Wang, D. A classification based approach to speech segregation. J. Acoust. Soc. Am. 2012, 132, 3475–3483. [Google Scholar] [CrossRef]
- Coelho, R.F.; Nascimento, V.H.; de Queiroz, R.L.; Romano, J.M.T.; Cavalcante, C.C. Signals and Images: Advances and Results in Speech, Estimation, Compression, Recognition, Filtering, and Processing; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]


{kind=link}
| Noise | SNR (dB) | PESQ Score | STOI Score | OQCM Score | LLR Score | ||||
|---|---|---|---|---|---|---|---|---|---|
| Before | After | Before | After | Before | After | Before | After | ||
| Café | 0 | 1.086 | 1.315 | 0.642 | 0.759 | 1.415 | 1.850 | 0.956 | 0.624 |
| 5 | 1.195 | 1.578 | 0.750 | 0.832 | 1.731 | 2.255 | 0.729 | 0.450 | |
| 10 | 1.419 | 1.966 | 0.837 | 0.889 | 2.117 | 2.727 | 0.530 | 0.317 | |
| 15 | 1.802 | 2.460 | 0.907 | 0.934 | 2.608 | 3.251 | 0.359 | 0.214 | |
| Car interior | 0 | 1.071 | 1.472 | 0.712 | 0.820 | 1.533 | 2.257 | 0.690 | 0.225 |
| 5 | 1.165 | 1.788 | 0.780 | 0.862 | 1.812 | 2.629 | 0.507 | 0.164 | |
| 10 | 1.369 | 2.162 | 0.845 | 0.901 | 2.162 | 3.025 | 0.357 | 0.122 | |
| 15 | 1.710 | 2.586 | 0.901 | 0.936 | 2.591 | 3.442 | 0.241 | 0.091 | |
| Fan | 0 | 1.075 | 1.456 | 0.685 | 0.808 | 1.400 | 2.107 | 1.002 | 0.469 |
| 5 | 1.179 | 1.758 | 0.768 | 0.856 | 1.705 | 2.503 | 0.765 | 0.338 | |
| 10 | 1.396 | 2.128 | 0.839 | 0.898 | 2.094 | 2.930 | 0.547 | 0.235 | |
| 15 | 1.758 | 2.624 | 0.901 | 0.934 | 2.571 | 3.435 | 0.364 | 0.163 | |
| Laundry | 0 | 1.066 | 1.455 | 0.644 | 0.808 | 1.336 | 2.034 | 1.011 | 0.577 |
| 5 | 1.149 | 1.756 | 0.753 | 0.869 | 1.631 | 2.448 | 0.787 | 0.421 | |
| 10 | 1.352 | 2.159 | 0.840 | 0.915 | 2.013 | 2.914 | 0.578 | 0.303 | |
| 15 | 1.711 | 2.635 | 0.903 | 0.947 | 2.491 | 3.411 | 0.396 | 0.210 | |
| Library | 0 | 1.080 | 1.460 | 0.671 | 0.793 | 1.484 | 2.054 | 1.056 | 0.686 |
| 5 | 1.167 | 1.694 | 0.758 | 0.849 | 1.725 | 2.377 | 0.875 | 0.555 | |
| 10 | 1.458 | 2.134 | 0.854 | 0.905 | 2.193 | 2.895 | 0.614 | 0.391 | |
| 15 | 1.780 | 2.514 | 0.908 | 0.938 | 2.596 | 3.299 | 0.450 | 0.294 | |
| Office | 0 | 1.059 | 1.349 | 0.629 | 0.770 | 1.355 | 1.893 | 1.083 | 0.678 |
| 5 | 1.136 | 1.609 | 0.729 | 0.834 | 1.633 | 2.278 | 0.863 | 0.520 | |
| 10 | 1.316 | 1.962 | 0.822 | 0.888 | 1.992 | 2.714 | 0.642 | 0.382 | |
| 15 | 1.649 | 2.404 | 0.896 | 0.931 | 2.448 | 3.194 | 0.447 | 0.270 | |
| Restaurant | 0 | 1.070 | 1.322 | 0.614 | 0.755 | 1.245 | 1.814 | 1.347 | 0.784 |
| 5 | 1.143 | 1.610 | 0.739 | 0.842 | 1.528 | 2.237 | 1.126 | 0.599 | |
| 10 | 1.310 | 1.987 | 0.847 | 0.905 | 1.888 | 2.697 | 0.878 | 0.448 | |
| 15 | 1.632 | 2.474 | 0.922 | 0.948 | 2.354 | 3.221 | 0.635 | 0.319 | |
| Subway | 0 | 1.094 | 1.486 | 0.715 | 0.814 | 1.554 | 2.215 | 0.774 | 0.331 |
| 5 | 1.215 | 1.811 | 0.780 | 0.858 | 1.847 | 2.611 | 0.578 | 0.241 | |
| 10 | 1.453 | 2.189 | 0.843 | 0.898 | 2.228 | 3.029 | 0.406 | 0.168 | |
| 15 | 1.825 | 2.637 | 0.900 | 0.933 | 2.690 | 3.479 | 0.266 | 0.117 | |
| Traffic | 0 | 1.076 | 1.367 | 0.668 | 0.783 | 1.417 | 1.953 | 1.075 | 0.623 |
| 5 | 1.171 | 1.666 | 0.775 | 0.854 | 1.721 | 2.371 | 0.834 | 0.454 | |
| 10 | 1.380 | 2.074 | 0.859 | 0.907 | 2.090 | 2.845 | 0.618 | 0.320 | |
| 15 | 1.754 | 2.559 | 0.920 | 0.944 | 2.566 | 3.348 | 0.428 | 0.225 | |
| White | 0 | 1.034 | 1.526 | 0.701 | 0.827 | 1.224 | 2.062 | 1.577 | 0.854 |
| 5 | 1.058 | 1.880 | 0.811 | 0.894 | 1.378 | 2.479 | 1.491 | 0.729 | |
| 10 | 1.143 | 2.307 | 0.898 | 0.942 | 1.598 | 2.946 | 1.343 | 0.598 | |
| 15 | 1.351 | 2.769 | 0.953 | 0.971 | 1.933 | 3.430 | 1.133 | 0.472 | |
| Average 1 | 0 | 1.071 | 1.421 | 0.668 | 0.794 | 1.396 | 2.024 | 1.057 | 0.585 |
| 5 | 1.158 | 1.715 | 0.764 | 0.855 | 1.671 | 2.419 | 0.856 | 0.447 | |
| 10 | 1.360 | 2.107 | 0.848 | 0.905 | 2.038 | 2.872 | 0.651 | 0.328 | |
| 15 | 1.697 | 2.566 | 0.911 | 0.938 | 2.485 | 3.351 | 0.472 | 0.238 | |
| Evaluation Measure | SNR (dB) | IMCRA + logMMSE with Classification | Proposed DNNs without Classification | Proposed DNNs with Classification |
|---|---|---|---|---|
| PESQ score | 0 | 1.320 | 1.324 | 1.421 |
| 5 | 1.593 | 1.554 | 1.715 | |
| 10 | 1.978 | 1.921 | 2.107 | |
| 15 | 2.451 | 2.440 | 2.566 | |
| STOI score | 0 | 0.719 | 0.765 | 0.794 |
| 5 | 0.807 | 0.839 | 0.855 | |
| 10 | 0.879 | 0.897 | 0.905 | |
| 15 | 0.931 | 0.939 | 0.942 | |
| OQCM score | 0 | 1.382 | 1.872 | 2.024 |
| 5 | 1.734 | 2.230 | 2.419 | |
| 10 | 2.145 | 2.679 | 2.872 | |
| 15 | 2.720 | 3.223 | 3.351 | |
| LLR score | 0 | 0.726 | 0.684 | 0.585 |
| 5 | 0.510 | 0.537 | 0.447 | |
| 10 | 0.359 | 0.395 | 0.328 | |
| 15 | 0.226 | 0.281 | 0.238 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, G.; Cho, W.; Kim, K.-S.; Lee, S. Speech Enhancement for Hearing Aids with Deep Learning on Environmental Noises. Appl. Sci. 2020, 10, 6077. https://doi.org/10.3390/app10176077
Park G, Cho W, Kim K-S, Lee S. Speech Enhancement for Hearing Aids with Deep Learning on Environmental Noises. Applied Sciences. 2020; 10(17):6077. https://doi.org/10.3390/app10176077
Chicago/Turabian StylePark, Gyuseok, Woohyeong Cho, Kyu-Sung Kim, and Sangmin Lee. 2020. "Speech Enhancement for Hearing Aids with Deep Learning on Environmental Noises" Applied Sciences 10, no. 17: 6077. https://doi.org/10.3390/app10176077
APA StylePark, G., Cho, W., Kim, K.-S., & Lee, S. (2020). Speech Enhancement for Hearing Aids with Deep Learning on Environmental Noises. Applied Sciences, 10(17), 6077. https://doi.org/10.3390/app10176077