Training and Testing of a Single-Layer LSTM Network for Near-Future Solar Forecasting

 and
and
Abstract
1. Introduction
1.1. Background
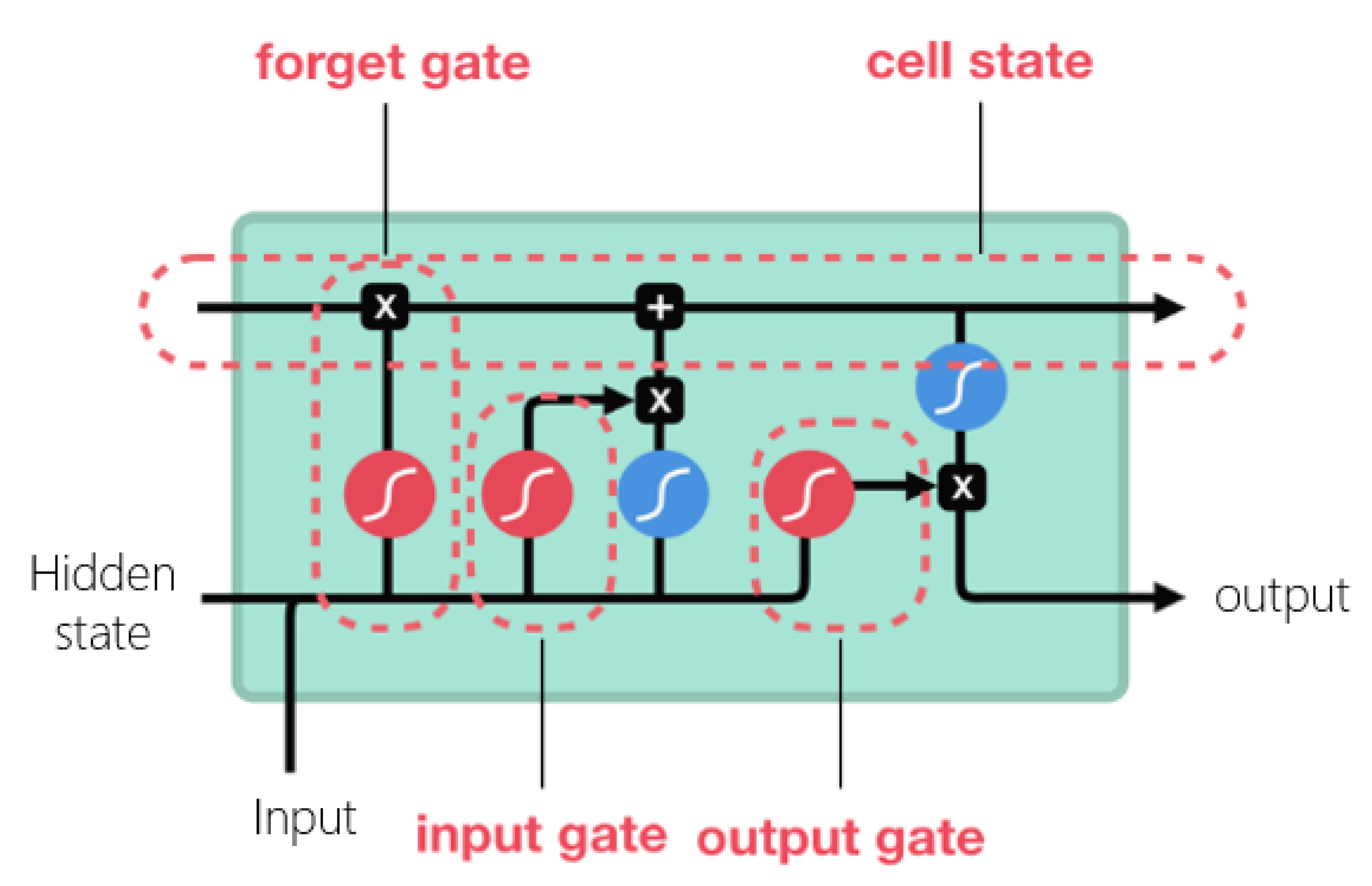
1.1.1. Theory of LSTM Networks
1.1.2. Related Studies from Literature
2. Data and Methods
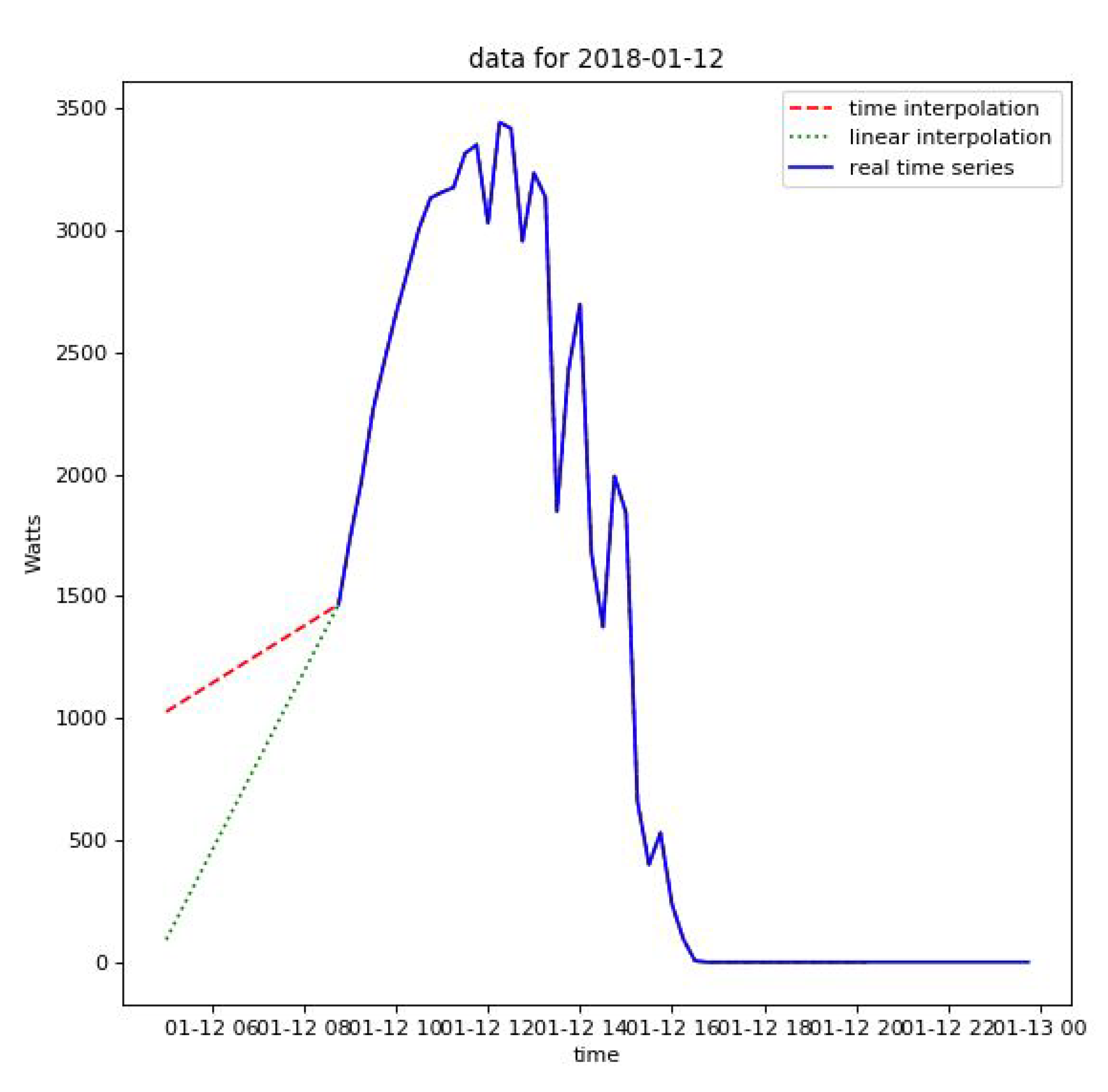
2.1. Data Preprocessing Methods
2.2. Data Quality and Preprocessing
2.3. LSTM Building, Training, and Evaluation
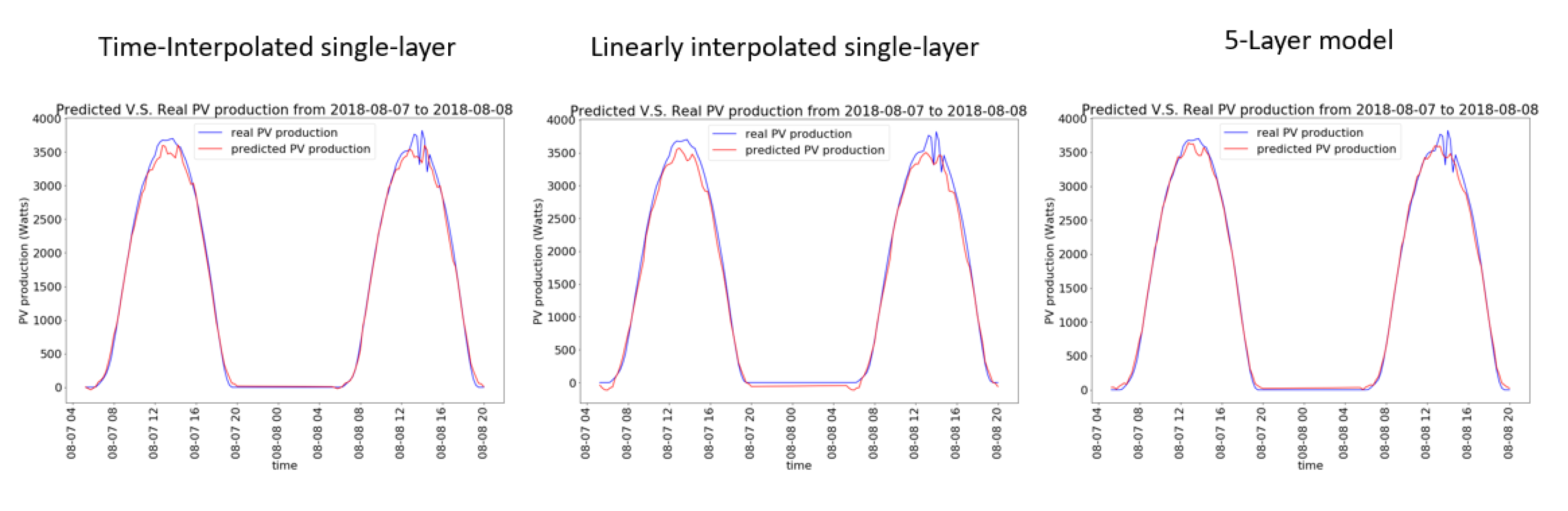
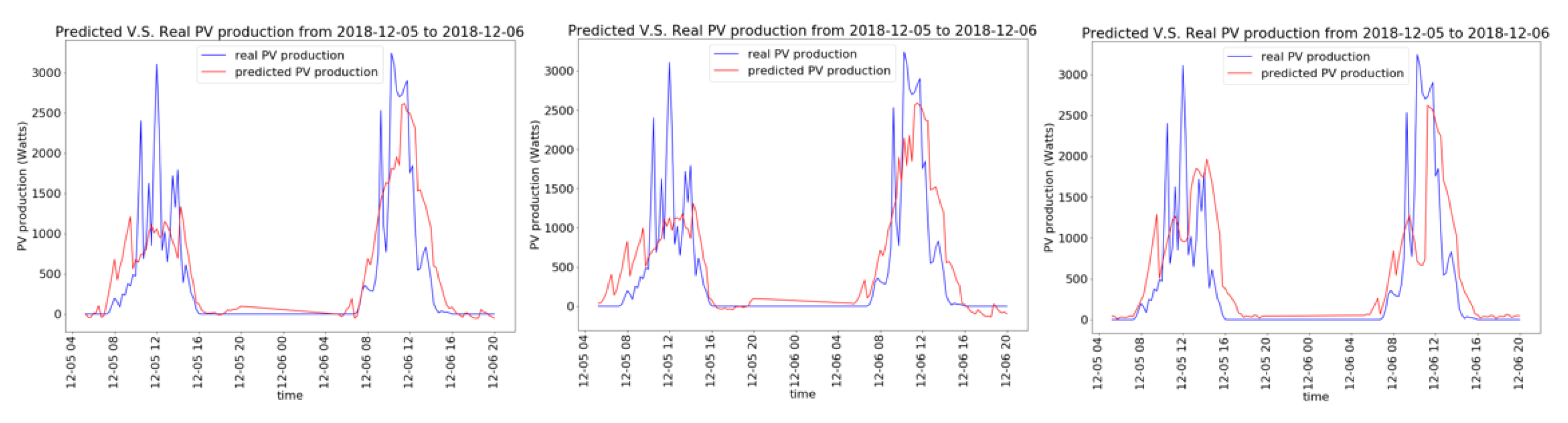
3. Results
4. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| BRT | bagged regression trees |
| IDE | Integrated Development Environment |
| ISO | Independent System Operator |
| kW | kilowatt |
| LSTM | long-short-term memory network |
| MLR | multiple-linear regression |
| MSE | mean squared error |
| nan | not-a-number value |
| nRMSE | normalized root mean squared error |
| PV | photovoltaic |
| RMSE | Root mean squared error |
| RNN | recurrent neural network |
| SVM | support vector machine |
| W | Watts |
References
- “PROGNOSIS”, Sustainable Energy Laboratory. Available online: https://www.energylab.ac.cy/projects/prognosis/en/ (accessed on 21 June 2020).
- Dacombe, J. An Introduction to Artificial Neural Networks (with Example); Medium: San Francisco, CA, USA, 2017; Available online: https://medium.com/@jamesdacombe/an-introduction-to-artificial-neural-networks-with-example-ad459bb6941b (accessed on 21 June 2020).
- A Beginner’s Guide to LSTMs and Recurrent Neural Networks. Pathmind. Available online: http://pathmind.com/wiki/lstm (accessed on 13 December 2019).
- Nguyen, M. Illustrated Guide to LSTM’s and GRU’s: A Step by Step Explanation; Medium: San Francisco, CA, USA, 2019; Available online: https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-sa-step-by-step-explanation-44e9eb85bf21 (accessed on 13 December 2019).
- Zaouali, K.; Rekik, R.; Bouallegue, R. Deep Learning Forecasting Based on Auto-LSTM Model for Home Solar Power Systems. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Exeter, UK, 28–30 June 2018; pp. 235–242. [Google Scholar] [CrossRef]
- Brownlee, J. How to Use Data Scaling Improve Deep Learning Model Stability and Performance; Machine Learning Mastery: Vermont, Australia, 2019; Available online: https://machinelearningmastery.com/howto-improve-neural-network-stability-and-modeling-performance-with-data-scaling/ (accessed on 22 June 2020).
- Brownlee, J. How to Configure the Number of Layers and Nodes in a Neural Network; Machine Learning Mastery: Vermont, Australia, 2018; Available online: https://machinelearningmastery.com/how-to-configure-the-number-of-layers-and-nodes-in-a-neural-network/ (accessed on 23 June 2020).
- Lee, D.; Kim, K. Recurrent Neural Network-Based Hourly Prediction of Photovoltaic Power Output Using Meteorological Information. Energies 2019, 12, 215. [Google Scholar] [CrossRef]
- Abdel-Nasser, M.; Mahmoud, K. Accurate photovoltaic power forecasting models using deep LSTM-RNN. Neural Comput. Appl. 2017. [Google Scholar] [CrossRef]
- RMSE: Root Mean Square Error—Statistics How To. Available online: https://www.statisticshowto.datasciencecentral.com/rmse/ (accessed on 13 December 2019).
- rrmse: Relative Root Mean Square Error in Fgmutils: Forest Growth Model Utilities. Available online: https://rdrr.io/cran/Fgmutils/man/rrmse.html (accessed on 13 December 2019).
- Mean Bias Error—An overview | ScienceDirect Topics. Available online: https://www.sciencedirect.com/topics/engineering/mean-bias-error (accessed on 13 July 2020).
- Stephanie. Absolute Error & Mean Absolute Error (MAE). Statistics How to. 25 October 2016. Available online: https://www.statisticshowto.com/absolute-error/ (accessed on 13 July 2020).
- Blaga, R.; Sabadus, A.; Stefu, N.; Dughir, C.; Paulescu, M.; Badescu, V. A current perspective on the accuracy of incoming solar energy forecasting. Prog. Energy Combust. Sci. 2019, 70, 119–144. [Google Scholar] [CrossRef]
- Kardakos, E.G.; Alexiadis, M.C.; Vagropoulos, S.I.; Simoglou, C.K.; Biskas, P.N.; Bakirtzis, A.G. Application of time series and artificial neural network models in short-term forecasting of PV power generation. In Proceedings of the 2013 48th International Universities’ Power Engineering Conference (UPEC), Dublin, Ireland, 2–5 September 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Paoli, C.; Voyant, C.; Muselli, M.; Nivet, M.-L. Forecasting of preprocessed daily solar radiation time series using neural networks. Sol. Energy 2010, 84, 2146–2160. [Google Scholar] [CrossRef]
- Nkounga, W.M.; Ndiaye, M.F.; Ndiaye, M.L.; Cisse, O.; Bop, M.; Sioutas, A. Short-term forecasting for solar irradiation based on the multi-layer neural network with the Levenberg-Marquardt algorithm and meteorological data: Application to the Gandon site in Senegal. In Proceedings of the 2018 7th International Conference on Renewable Energy Research and Applications (ICRERA), Paris, France, 14–17 October 2018; pp. 869–874. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RMSE (W) | nRMSE | MBE (W) | MAE (W) | ||
|---|---|---|---|---|---|
| time-interpolated single-layer model | 450.90 | 10.7% | 26.56 | 235.10 | 0.882 |
| linearly interpolated single-layer model | 455.35 | 10.8% | 1.30 | 259.39 | 0.879 |
| 5-layer (time interpolated) model | 478.25 | 11.4% | 76.2 | 240.65 | 0.868 |
| Mean Squared Error (W) | Variance (W) | |
|---|---|---|
| time-interpolated single-layer model | 0.0097 | 0.0069 |
| linearly interpolated single-layer model | 0.0010 | 0.0075 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Halpern-Wight, N.; Konstantinou, M.; Charalambides, A.G.; Reinders, A. Training and Testing of a Single-Layer LSTM Network for Near-Future Solar Forecasting. Appl. Sci. 2020, 10, 5873. https://doi.org/10.3390/app10175873
Halpern-Wight N, Konstantinou M, Charalambides AG, Reinders A. Training and Testing of a Single-Layer LSTM Network for Near-Future Solar Forecasting. Applied Sciences. 2020; 10(17):5873. https://doi.org/10.3390/app10175873
Chicago/Turabian StyleHalpern-Wight, Naylani, Maria Konstantinou, Alexandros G. Charalambides, and Angèle Reinders. 2020. "Training and Testing of a Single-Layer LSTM Network for Near-Future Solar Forecasting" Applied Sciences 10, no. 17: 5873. https://doi.org/10.3390/app10175873
APA StyleHalpern-Wight, N., Konstantinou, M., Charalambides, A. G., & Reinders, A. (2020). Training and Testing of a Single-Layer LSTM Network for Near-Future Solar Forecasting. Applied Sciences, 10(17), 5873. https://doi.org/10.3390/app10175873