Memory-Based Deep Neural Attention (mDNA) for Cognitive Multi-Turn Response Retrieval in Task-Oriented Chatbots




Abstract
1. Introduction
- logical inconsistency error: where retrieved response candidates are wrong due to logical mismatch
- vague or fuzzy response candidate error: where selected responses contains improper details
2. Related Works
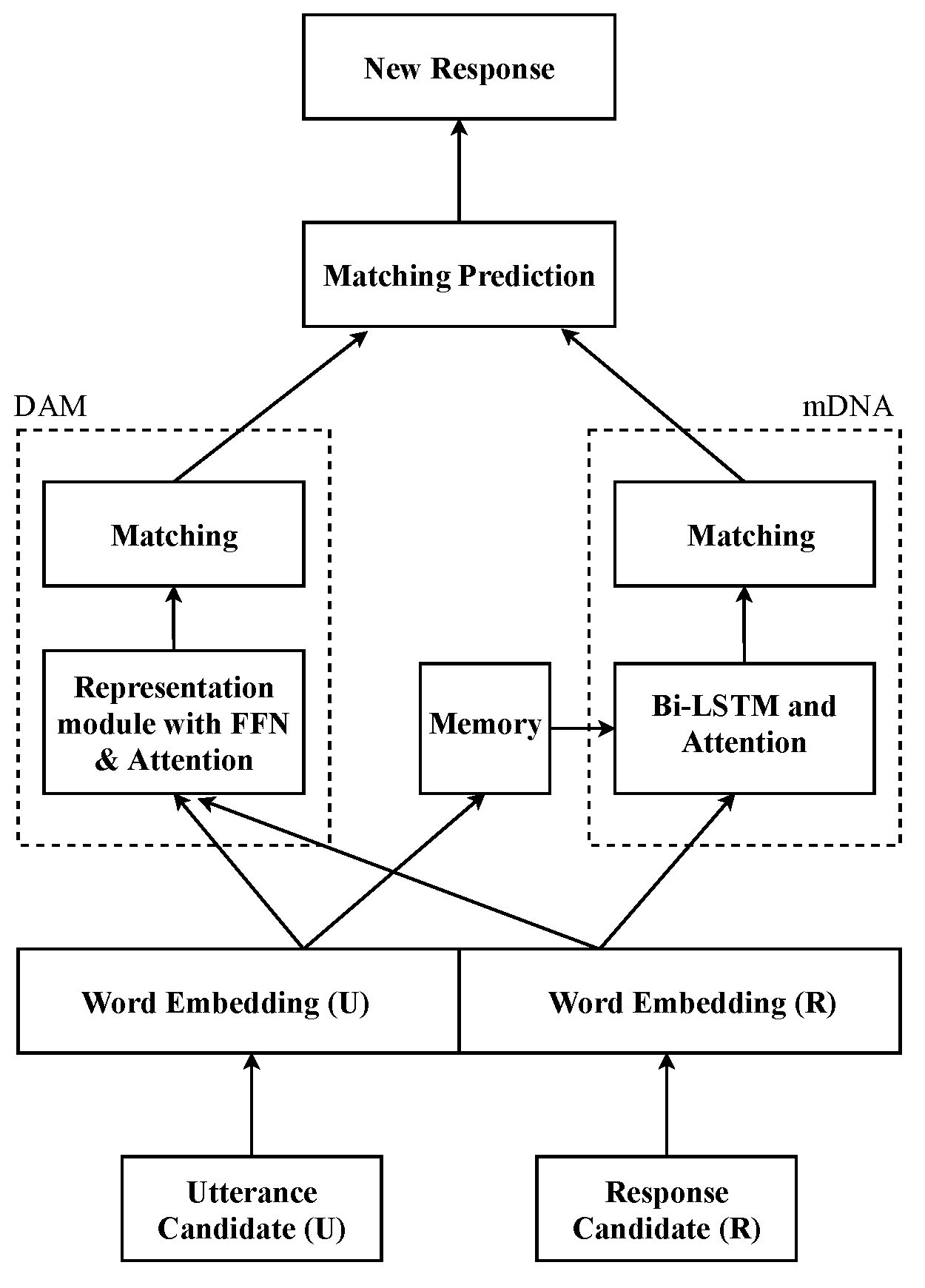
3. Model Description
3.1. Memory Utterance Embedding
3.2. Bi-LSTM Encoding with Attention
3.3. Matching Composition and Prediction
4. Experiments
4.1. Dataset
4.2. Hyperparameter Settings
5. Results and Evaluation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhou, X.; Li, L.; Dong, D.; Liu, Y.; Chen, Y.; Zhao, W.X.; Yu, D.; Wu, H. Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 1118–1127. [Google Scholar]
- Wu, Y.; Wu, W.; Xing, C.; Li, Z.; Zhou, M. Sequential Matching Network: A New Architecture for Multi-turn Response Selection in Retrieval-based Chatbots. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 496–505. [Google Scholar]
- Leuski, A.; Traum, D. NPCEditor: Creating Virtual Human Dialogue Using Information Retrieval Techniques. AAAI AI Mag. 2011, 32, 42–56. [Google Scholar] [CrossRef]
- Wang, H.; Lu, Z.; Li, H.; Chen, E. A Dataset for Research on Short-Text Conversation. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 935–945. [Google Scholar]
- Hu, B.; Lu, Z.; Li, H.; Chen, Q. Convolutional neural network architectures for matching natural language sentences. In Proceedings of the 27th Conference Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2042–2050. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Medina, J.R.; Kalita, J. Parallel Attention Mechanisms in Neural Machine Translation. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, Orlando, FL, USA, 17–20 December 2018; pp. 547–552. [Google Scholar]
- Zhang, Z.; Li, J.; Zhu, P.; Zhao, H.; Liu, G. Modeling Multi-turn Conversation with Deep Utterance Aggregation. In Proceedings of the 27th International Conference Computational Linguistics, Santa Fe, NM, USA, 21–25 November 2018; pp. 3740–3752. [Google Scholar]
- Liu, K.; Li, Y.; Xu, N.; Natarajan, P. Learn to combine modalities in multimodal deep learning. arXiv 2018, arXiv:1805.11730. [Google Scholar]
- Henderson, M.; Vulic, I.; Gerz, D.; Casanueva, I.; Budzianowski, P.; Coope, S.; Spithourakis, G.; Wen, T.; Mrkšic, N.; Su, P. Training Neural Response Selection for Task-Oriented Dialogue Systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5392–5406. [Google Scholar]
- Zhao, X.; Tao, C.; Wu, W.; Xu, C.; Zhao, D.; Yan, R. A Document-grounded Matching Network for Response Selection in Retrieval-based Chatbots. In Proceedings of the 28th IJCAI Conference on AI, Macao, China, 10–16 August 2019; pp. 5443–5449. [Google Scholar]
- Yang, L.; Ai, Q.; Guo, J.; Croft, W.B. aNMM: Ranking Short Answer Texts with Attention-Based Neural Matching Model. In Proceedings of the 25th ACM International Conference Information and Knowledge, Indianapolis, IN, USA, 24–28 October 2016; Volume 8, pp. 287–296. [Google Scholar]
- Lakew, S.M.; Cettolo, M.; Federico, M. A Comparison of Transformer and Recurrent Neural Networks on Multilingual Neural Machine Translation. In Proceedings of the of 27th International Conference Computational Linguistics, Santa Fe, NM, USA, 20–25 August 2018; pp. 641–652. [Google Scholar]
- Wang, Z.; Ma, Y.; Liu, Z.; Tang, J. R-transformer: Recurrent Neural Network Enhanced Transformer. arXiv 2019, arXiv:1907.05572. [Google Scholar]
- Sukhbaatar, S.; Szlam, A.; Weston, J.; Fergus, R. End-to-end Memory Networks. In Proceedings of the Conference on Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 1, pp. 2440–2448. [Google Scholar]
- Kaiser, Ł.; Bengio, S. Can Active Memory Replace Attention? In Proceedings of the 30th Conference Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 3781–3789. [Google Scholar]
- Wulamu, A.; Sun, Z.; Xie, Y.; Xu, C.; Yang, A. An Improved End-to-End Memory Network for QA Tasks. Cmc Comput. Mater. Contin. 2019, 60, 1283–1295. [Google Scholar] [CrossRef]
- Domhan, T. How Much Attention Do You Need? A Granular Analysis of Neural Machine Translation Architectures. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1799–1808. [Google Scholar]
- Zhou, Q.; Wu, H. NLP at IEST 2018: BiLSTM-Attention and LSTM-Attention via Soft Voting in Emotion Classification. In Proceedings of the 9th ACM Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Brussels, Belgium, 31 October 2018; pp. 189–194. [Google Scholar]
- Vakili, A.; Shakery, A. Enriching Conversation Context in Retrieval-based Chatbots. arXiv 2019, arXiv:1911.02290v1. [Google Scholar]
- Chen, J.; Abdul, A. A Session-based Customer Preference Learning Method by Using the Gated Recurrent Units with Attention Function. IEEE Access 2019, 7, 17750–17759. [Google Scholar] [CrossRef]
- Gruber, N.; Jockisch, A. Are GRU Cells More Specific and LSTM Cells More Sensitive in Motive Classification of Text? J. Front. Artif. Intell. 2020, 3, 1–6. [Google Scholar] [CrossRef]
- Lowe, R.; Pow, N.; Serban, I.; Pineau, J. The ubuntu dialogue corpus: A large dataset for research in unstructured multi-turn dialogue systems. In Proceedings of the of 16th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Prague, Czech Republic, 2–4 September 2015; pp. 285–294. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 27th Annual Conference Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference Learning Representations, San Diego, CA, USA, 7–9 May 2015; Volume 1412. [Google Scholar]
- Pang, L.; Lan, Y.; Guo, J.; Xu, J.; Wan, S.; Cheng, X. Text matching as image recognition. In Proceedings of the 30th AAAI Conference Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2793–2799. [Google Scholar]
- Wang, S.; Jiang, J. Machine Comprehension using Match-LSTM and Answer Pointer. In Proceedings of the International Conference Learning Representations, Palais des Congrès Neptune, Toulon, France, 24–26 April 2017; pp. 2793–2799. [Google Scholar]
- Zhou, X.; Dong, D.; Wu, H.; Zhao, S.; Yu, D.; Tian, H.; Liu, X.; Yan, R. Multi-view response selection for human-computer conversation. In Proceedings of the EMNLP 2016, Austin, TX, USA, 1–5 November 2016; pp. 372–381. [Google Scholar]
- Yan, R.; Song, Y.; Wu, H. Learning to respond with deep neural networks for retrievalbased human-computer conversation system. In Proceedings of the SIGIR 2016, Pisa, Italy, 17–21 July 2016; pp. 55–64. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Matching Score | ||
|---|---|---|---|
| Context | A: Hi, I am looking to see what packages are installed on my system, I don’t see a path in the list being held somewhere else. | ||
| B: try dpkg – get-selections. | |||
| A: Is that like a database for packages instead of a flat file structure? | |||
| B: dpkg is the debian package manager-get-selections that simply shows you what packages are handled by it. | |||
| Response | No clue what do you need it for, its just reassurance as I don’t know the debian package manager | 1 | 0.995 |
| Then why not +q good point thanks. | 0 | 0.231 | |
| I mean real media … not the command lol exactly. | 0 | 0.035 | |
| Hmm: should i force version to hoary. | 0 | 0.299 | |
| I will also run on core2 intels i installed ubuntu on a usb … | 0 | 0.016 | |
| And what’s your system specs the live cd does not use the hard drive at all | 0 | 0.019 | |
| Thanks i will see if i can find another option and use that as a last resort the steps … | 0 | 0.911 | |
| Number is long term support also and not that much difference between number and number with the next ubuntu kubuntu and xubuntu at the end of april. | 0 | 0.02 | |
| These days backup to usb probably is more relevant … | 0 | 0.004 | |
| It explains the same stuff a bit more in depth:) … | 0 | 0.963 | |
| Training | Validation | Testing | |
|---|---|---|---|
| # context response pairs | 1 M | 500 K | 500 K |
| # candidates per context | 2 | 10 | 10 |
| Avg. # turns per dialogue | 7.71 | 7.33 | 7.54 |
| Avg. # words per utterance | 10.34 | 10.22 | 10.33 |
| Model | R | R | R |
|---|---|---|---|
| DualEncoder [23] | 0.638 | 0.784 | 0.949 |
| MV-LSTM [26] | 0.653 | 0.804 | 0.946 |
| Match-LSTM [27] | 0.653 | 0.799 | 0.944 |
| Multiview [28] | 0.662 | 0.801 | 0.951 |
| DL2R [29] | 0.626 | 0.783 | 0.944 |
| SMN [2] | 0.726 | 0.847 | 0.961 |
| DAM [1] | 0.767 | 0.874 | 0.969 |
| BERT Bi-Encoder + CE [20] | 0.793 | 0.893 | 0.975 |
| mDNA | 0.797 | 0.891 | 0.975 |
| mDNA | 0.788 | 0.885 | 0.971 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Agbodike, O.; Wang, L. Memory-Based Deep Neural Attention (mDNA) for Cognitive Multi-Turn Response Retrieval in Task-Oriented Chatbots. Appl. Sci. 2020, 10, 5819. https://doi.org/10.3390/app10175819
Chen J, Agbodike O, Wang L. Memory-Based Deep Neural Attention (mDNA) for Cognitive Multi-Turn Response Retrieval in Task-Oriented Chatbots. Applied Sciences. 2020; 10(17):5819. https://doi.org/10.3390/app10175819
Chicago/Turabian StyleChen, Jenhui, Obinna Agbodike, and Lei Wang. 2020. "Memory-Based Deep Neural Attention (mDNA) for Cognitive Multi-Turn Response Retrieval in Task-Oriented Chatbots" Applied Sciences 10, no. 17: 5819. https://doi.org/10.3390/app10175819
APA StyleChen, J., Agbodike, O., & Wang, L. (2020). Memory-Based Deep Neural Attention (mDNA) for Cognitive Multi-Turn Response Retrieval in Task-Oriented Chatbots. Applied Sciences, 10(17), 5819. https://doi.org/10.3390/app10175819