Human Height Estimation by Color Deep Learning and Depth 3D Conversion



Abstract
1. Introduction
2. Related Works
2.1. Object Detection from Color Information by Convolutional Neural Network
2.2. Object Length Measurement from Color or Depth Information
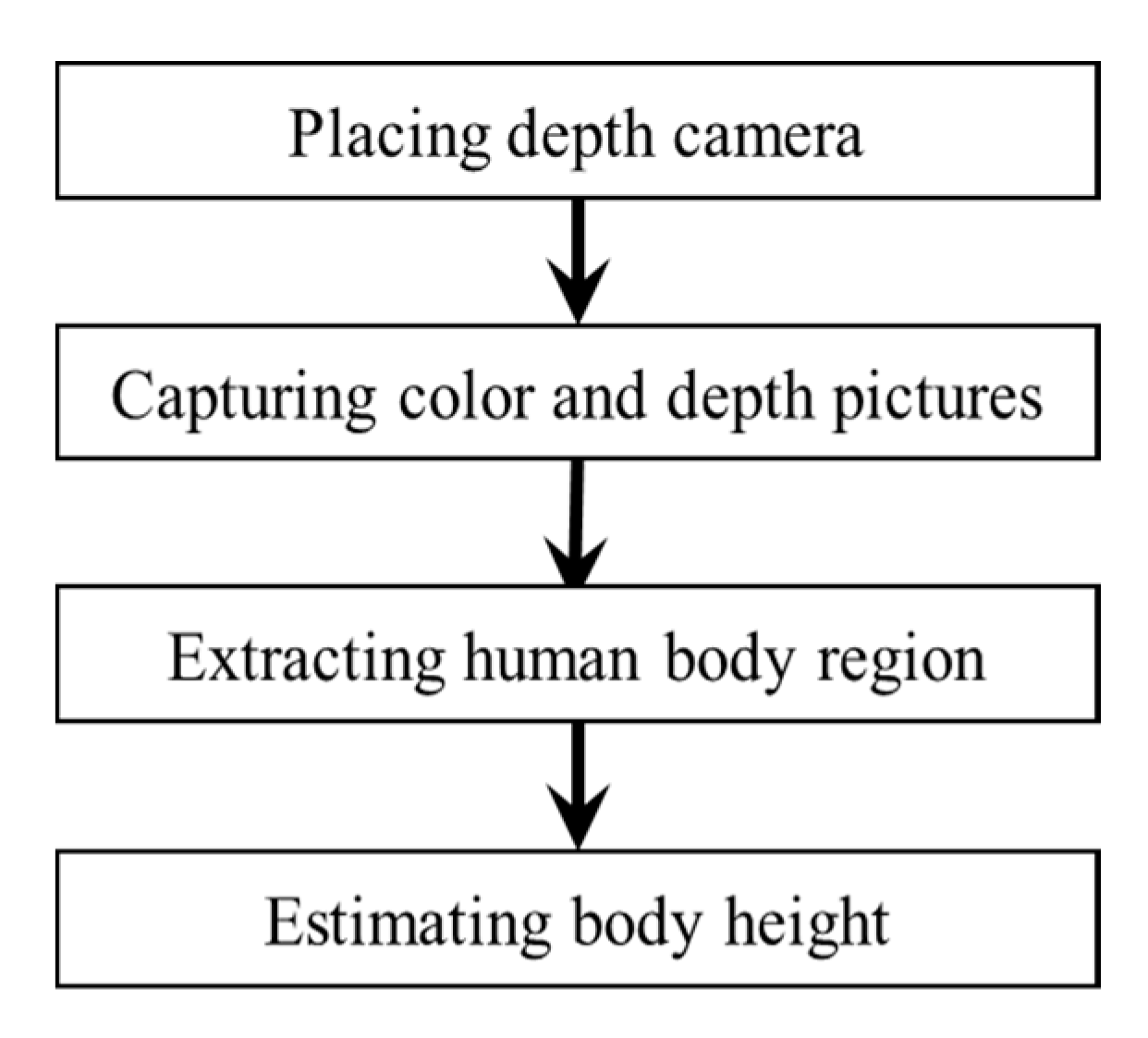
3. Proposed Method
3.1. Human Body Region Extraction
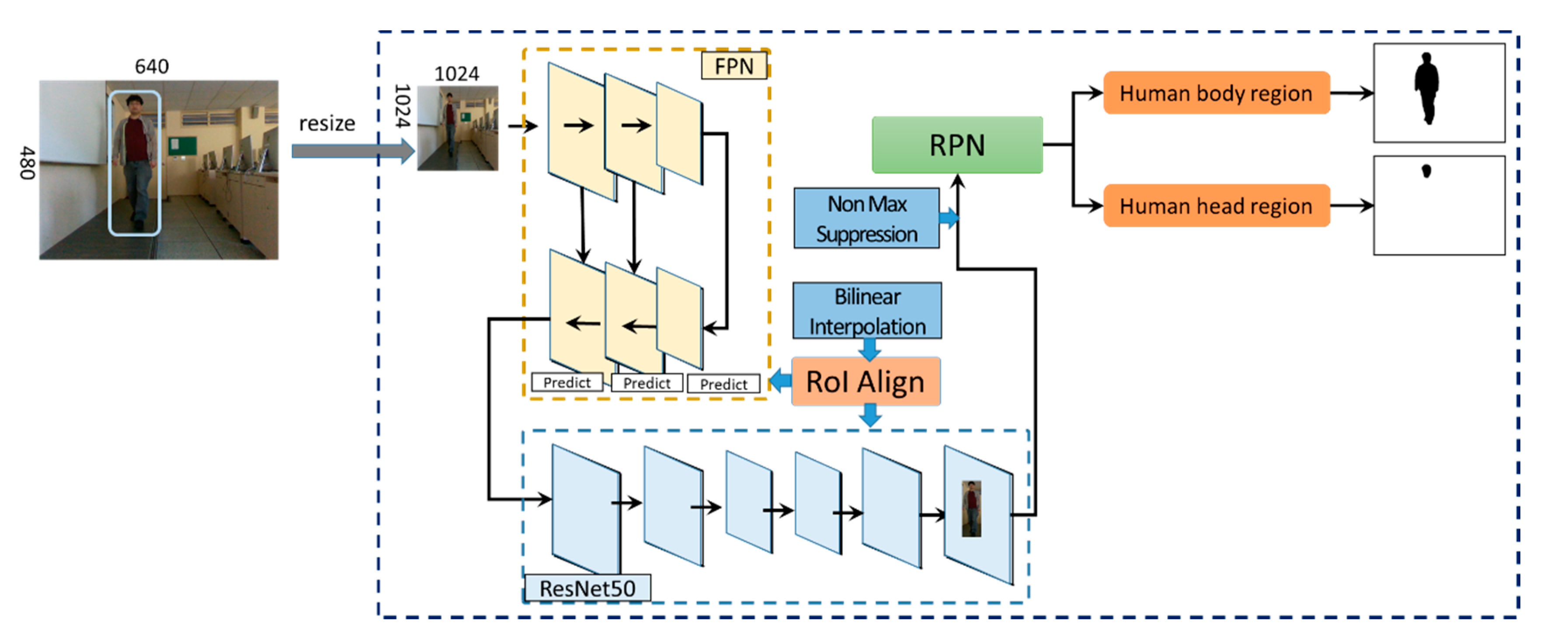
3.1.1. Human Body Region Extraction Using Color Frames
- Resizing a color image to a certain size
- Extracting a feature map through FPN and ResNet50
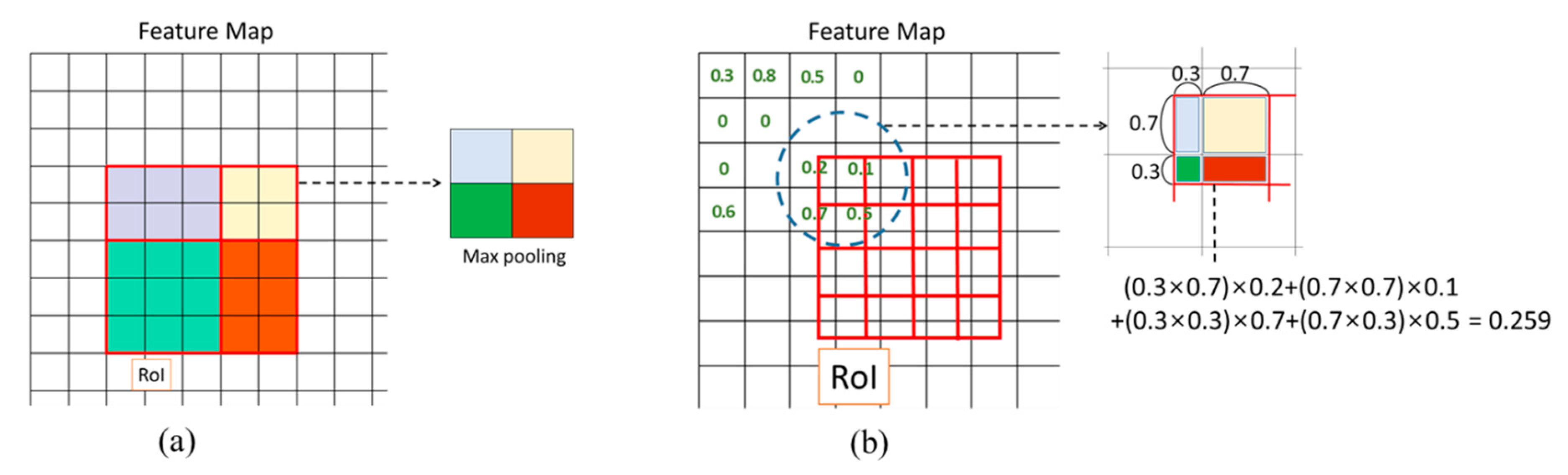
- Extracting RoI boundary boxes from feature map by RoIAlign
- Boundary box regression and classification for boundary boxes through RPN
- Generating boundary box candidates by projecting the boundary box regression results onto the color frame
- Detecting a boundary box for each object by non-max-suppression
- Adjusting the boundary box area through RoIAlign
- Finding pixels in boundary boxes to obtain a mask for each boundary box
3.1.2. Human Body Region Extraction Using Depth Frames
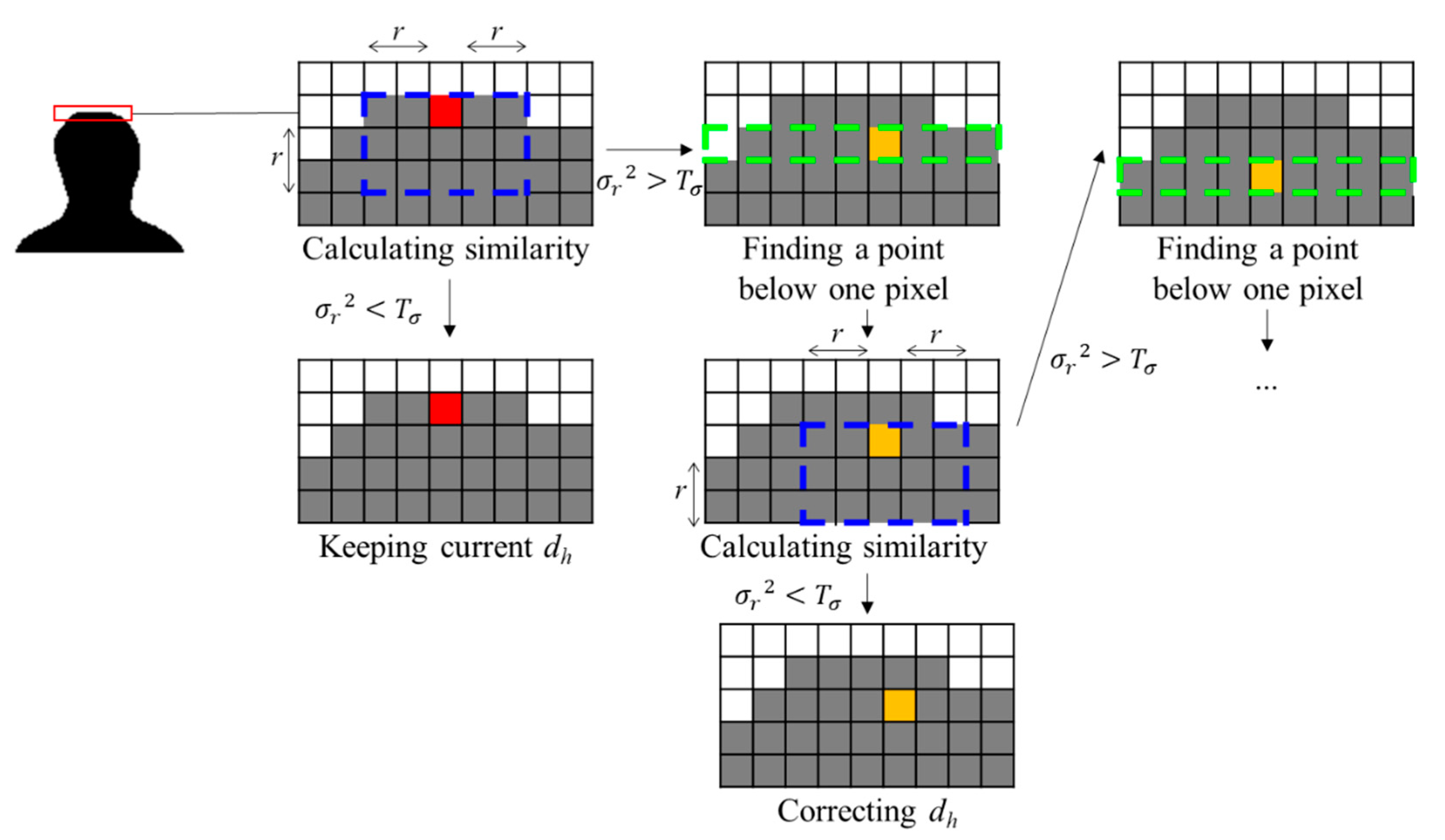
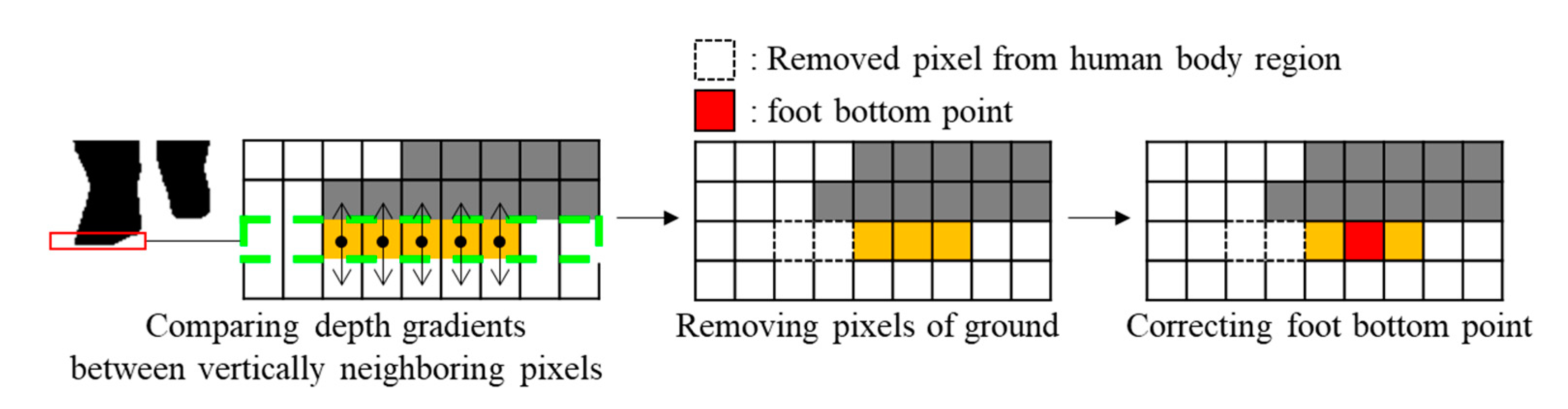
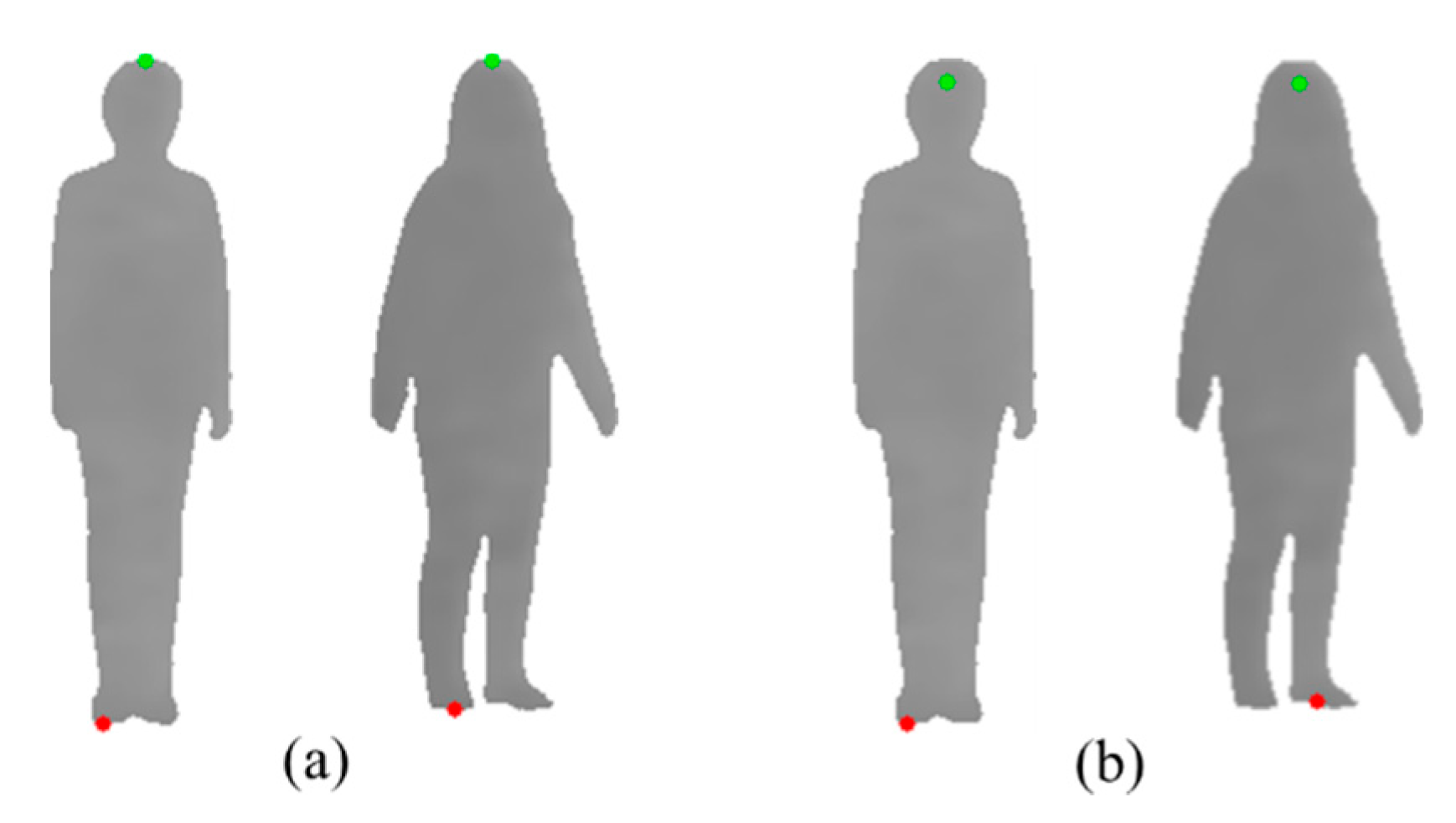
3.2. Extraction of Head Top and Foot Bottom Points
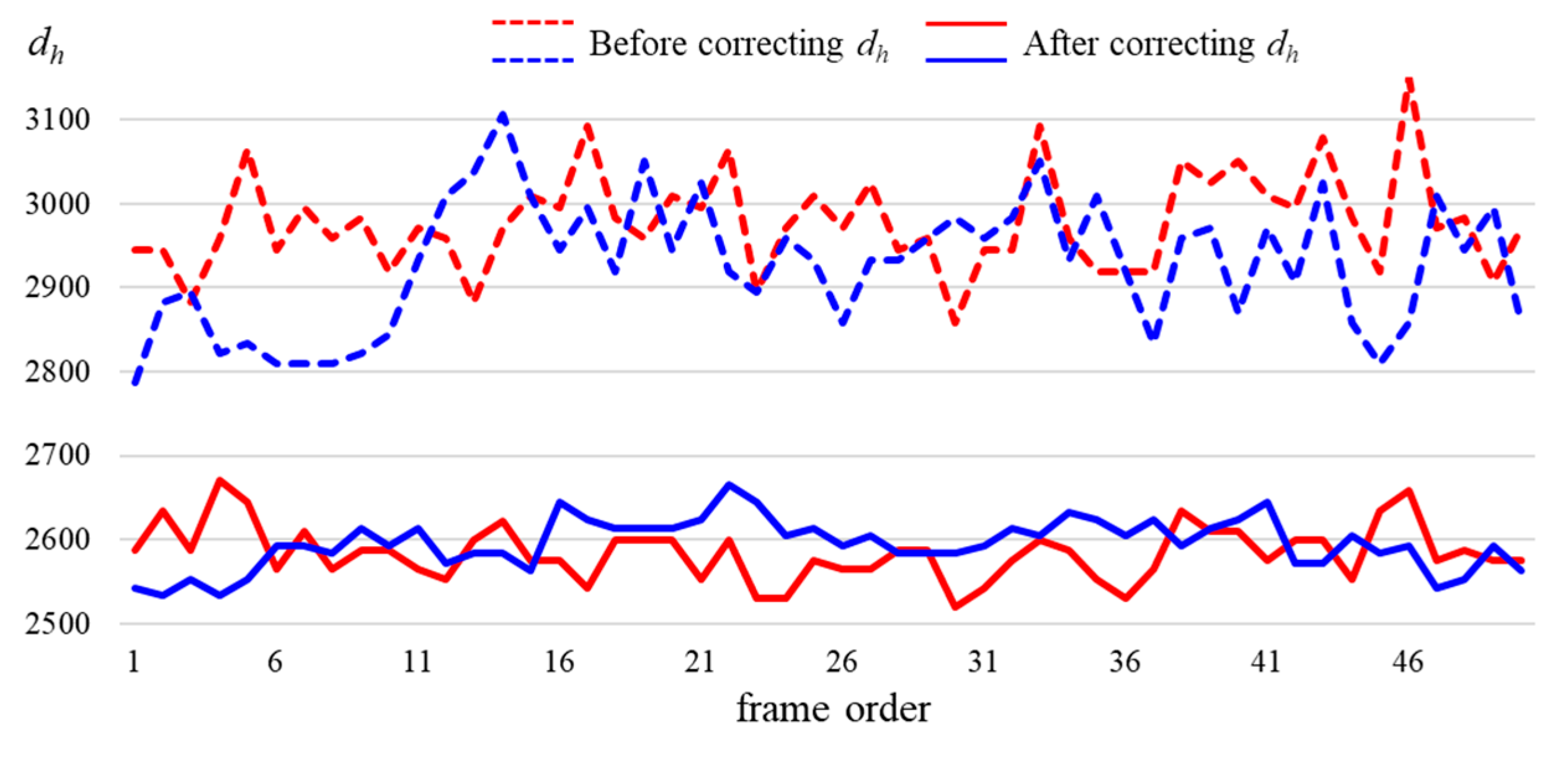
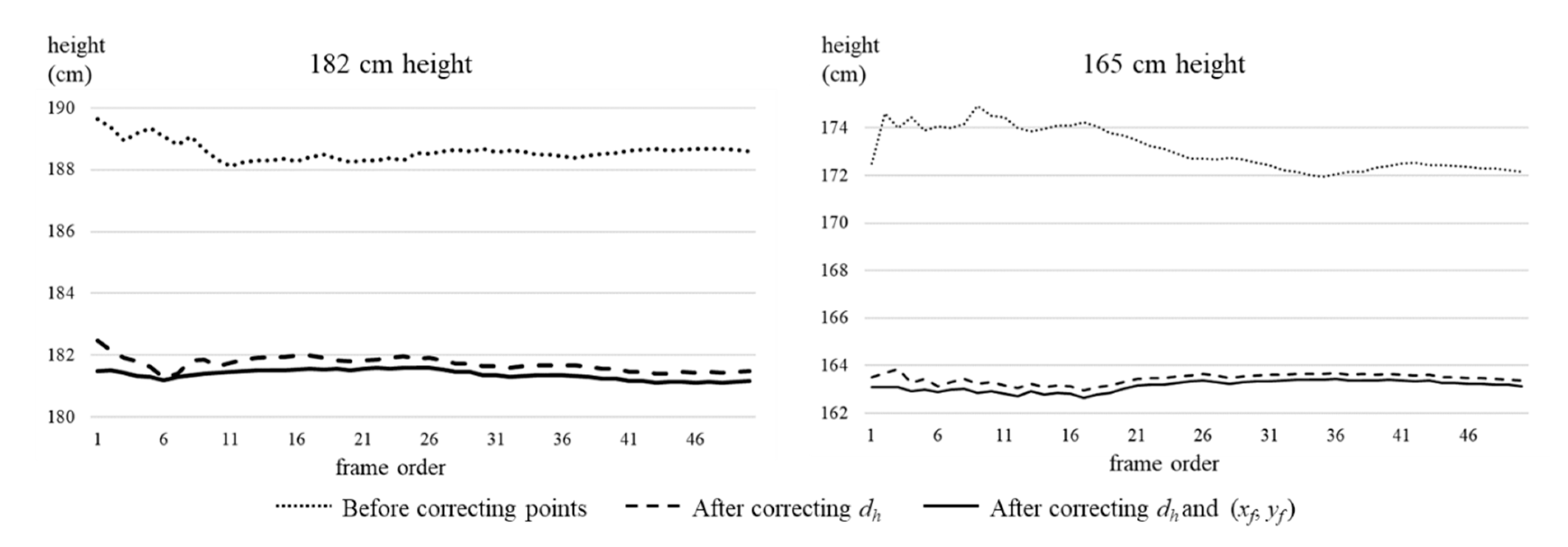
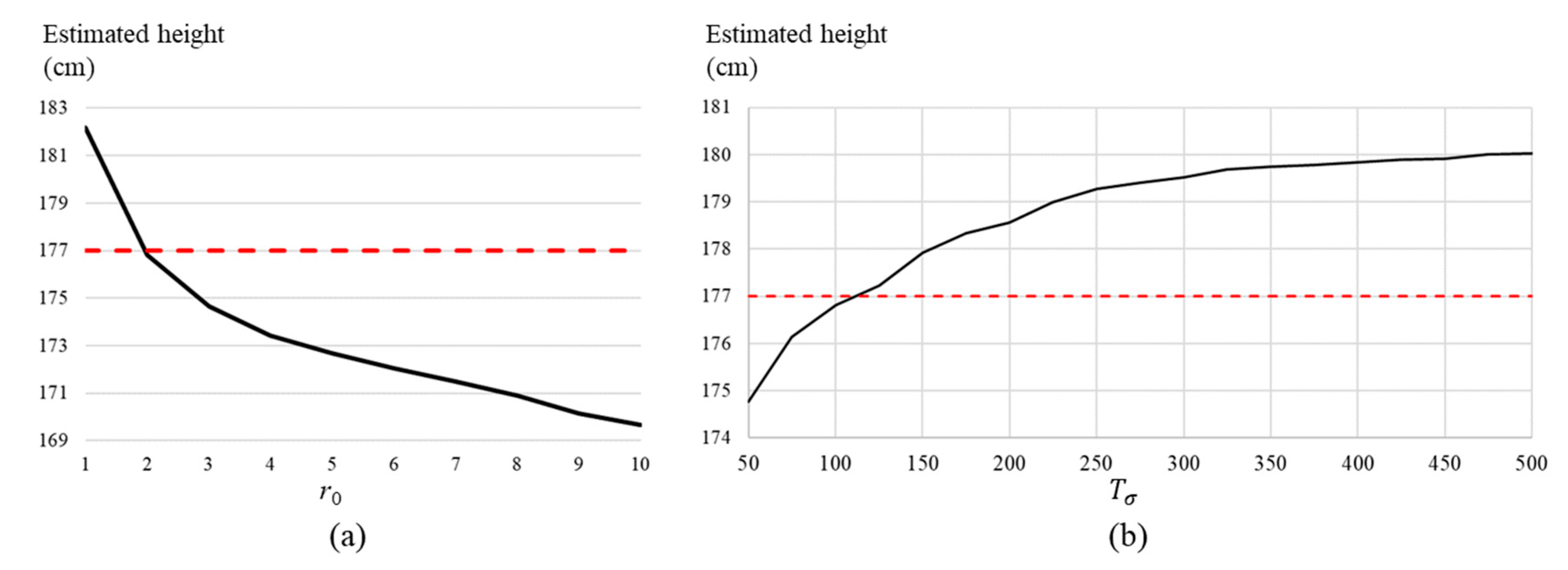
3.3. Human Height Estimation
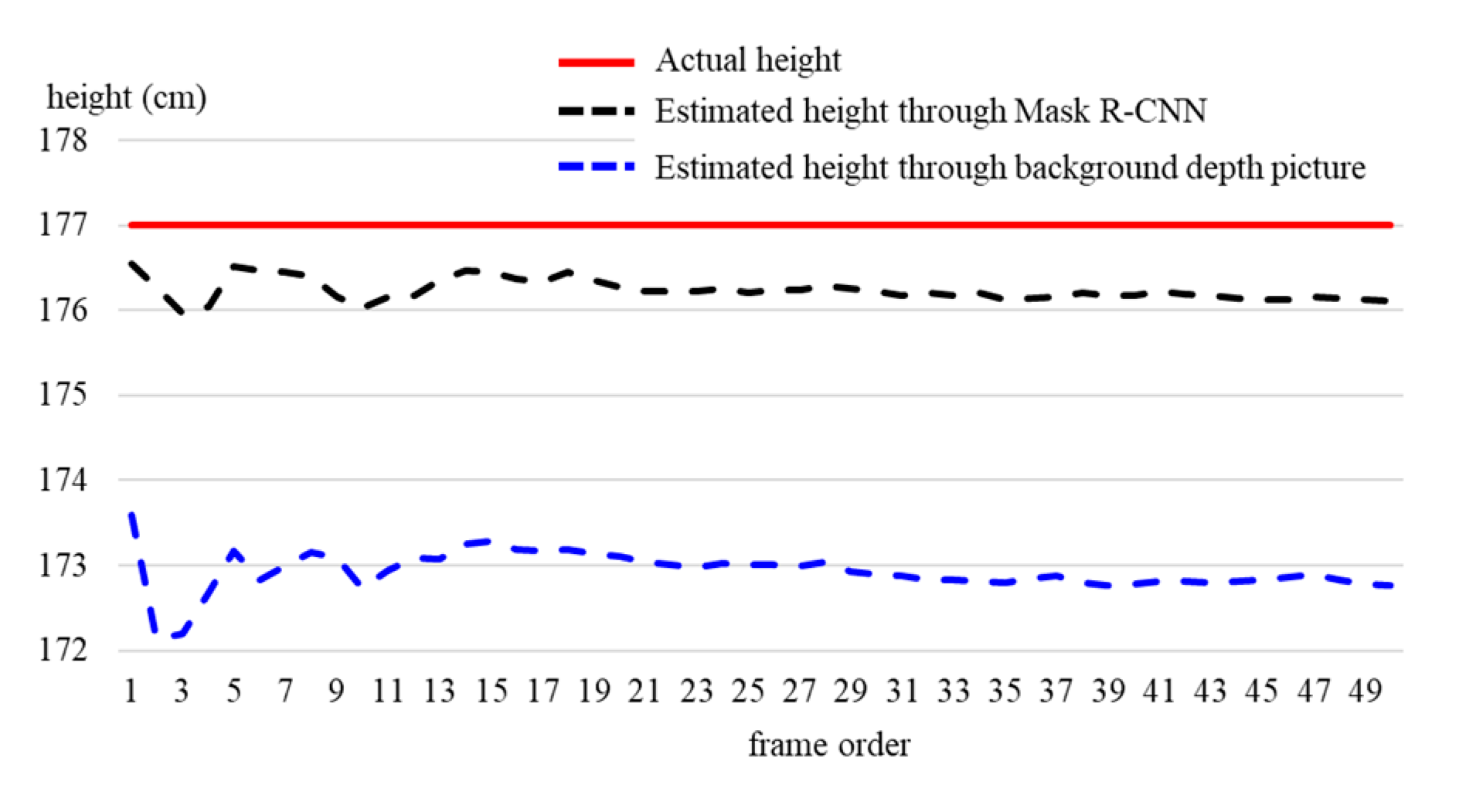
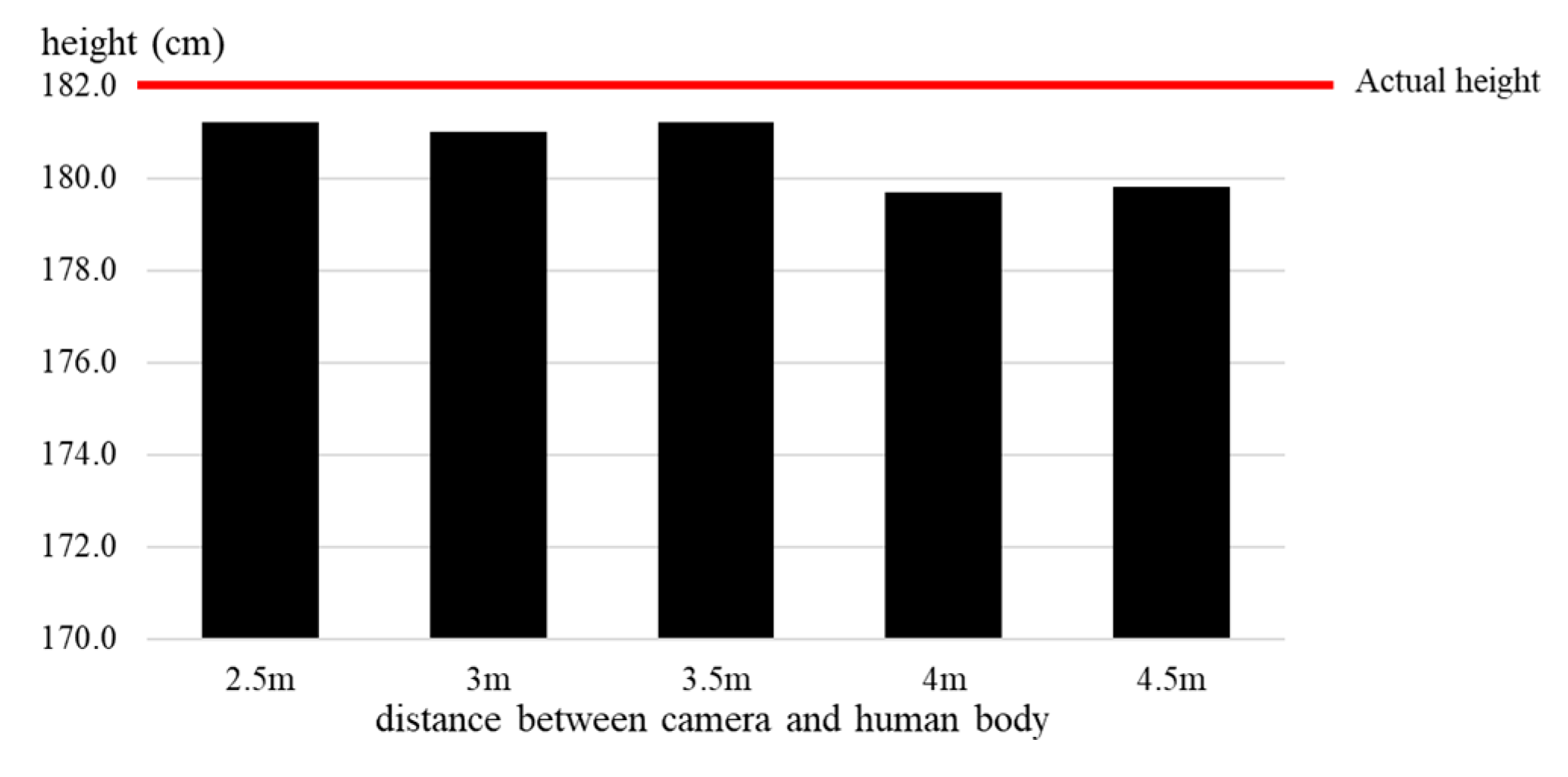
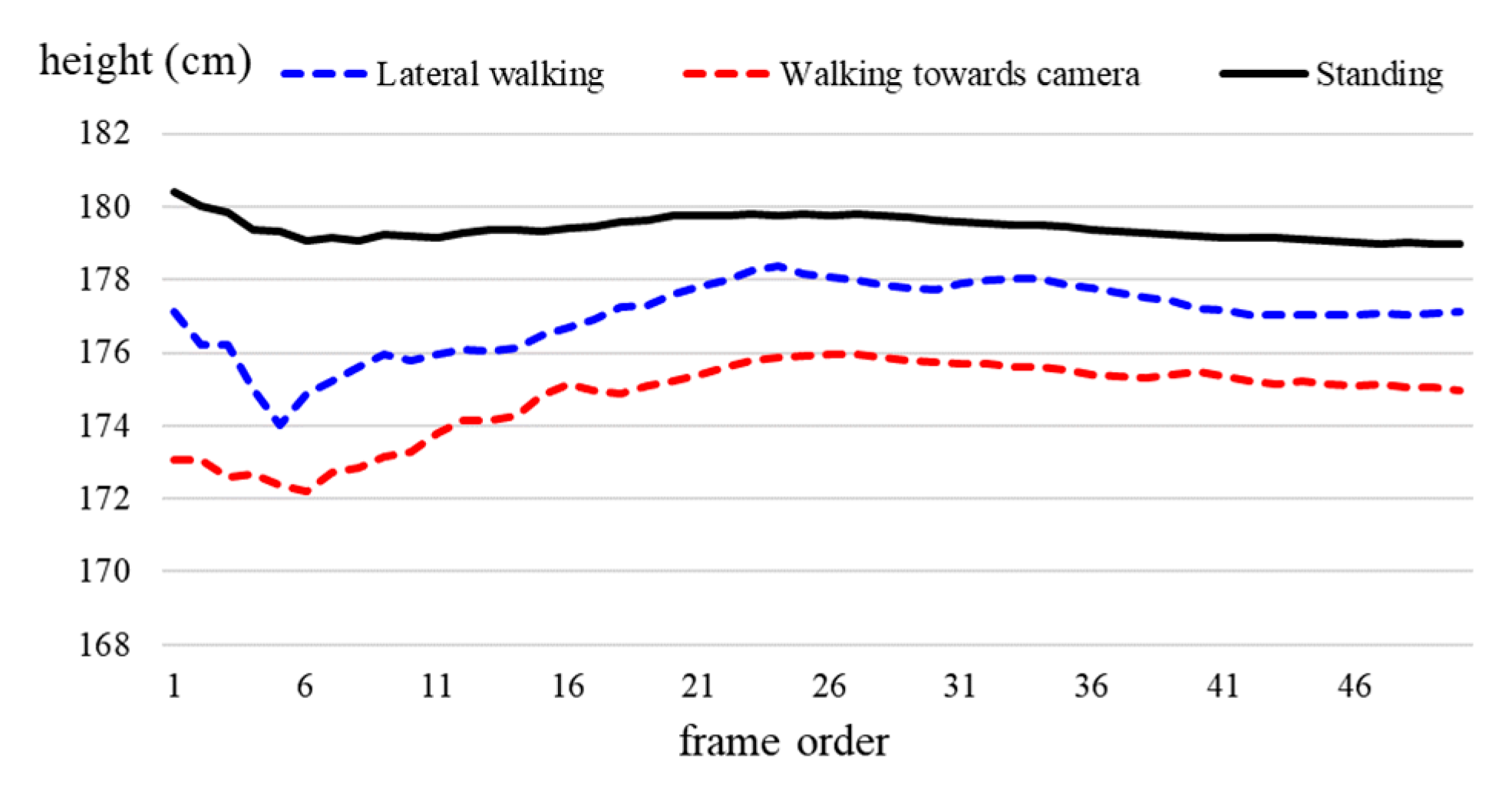
4. Experiment Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tsakanikas, V.; Dagiuklas, T. Video surveillance systems-current status and future trends. Comput. Electr. Eng. 2018, 70, 736–753. [Google Scholar] [CrossRef]
- Momeni, M.; Diamantas, S.; Ruggiero, F.; Siciliano, B. Height estimation from a single camera view. In Proceedings of the International Conference on Computer Vision Theory and Applications, Rome, Italy, 24–26 February 2012; pp. 358–364. [Google Scholar]
- Gallagher, A.C.; Blose, A.C.; Chen, T. Jointly estimating demographics and height with a calibrated camera. In Proceedings of the International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1187–1194. [Google Scholar]
- Zhou, X.; Jiang, P.; Zhang, X.; Zhang, B.; Wang, F. The measurement of human height based on coordinate transformation. In Proceedings of the International Conference on Intelligent Computing, Lanzhou, China, 2–5 August 2016; pp. 717–725. [Google Scholar]
- Liu, J.; Collins, R.; Liu, Y. Surveillance camera auto calibration based on pedestrian height distributions. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; pp. 1–11. [Google Scholar]
- Cho, W.; Shin, M.; Jang, J.; Paik, J. Robust pedestrian height estimation using principal component analysis and its application to automatic camera calibration. In Proceedings of the International Conference on Electronics, Information, and Communication, Honolulu, HI, USA, 24–27 January 2018; pp. 1–2. [Google Scholar]
- Criminisi, A.; Reid, I.; Zisserman, A. Single view metrology. Int. J. Comput. Vis. 2000, 40, 123–148. [Google Scholar] [CrossRef]
- Andaló, F.A.; Taubin, G.; Goldenstein, G. Efficient height measurements in single images based on the detection of vanishing points. Comput. Vis. Image Underst. 2015, 138, 51–60. [Google Scholar] [CrossRef]
- Jung, J.; Kim, H.; Yoon, I.; Paik, J. Human height analysis using multiple uncalibrated cameras. In Proceedings of the International Conference on Consumer Electronics, Las Vegas, NV, USA, 7–11 January 2016; pp. 213–214. [Google Scholar]
- Viswanath, P.; Kakadiaris, I.A.; Shah, S.K. A simplified error model for height estimation using a single camera. In Proceedings of the International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1259–1266. [Google Scholar]
- Rother, D.; Patwardhan, K.A.; Sapiro, G. What can casual walkers tell us about a 3d scene? In Proceedings of the International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Pribyl, B.; Zemcik, P. Simple single view scene calibration. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6915, pp. 748–759. [Google Scholar]
- Zhao, Y.; Carraro, M.; Munaro, M.; Menegatti, E. Robust multiple object tracking in rgb-d camera networks. In Proceedings of the International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; pp. 6625–6632. [Google Scholar]
- Ren, C.Y.; Prisacariu, V.A.; Kahler, O.; Reid, I.D.; Murray, D.W. Real-time tracking of single and multiple objects from depth-colour imagery using 3d signed distance functions. Int. J. Comput. Vis. 2017, 124, 80–95. [Google Scholar] [CrossRef] [PubMed]
- Jiang, M.X.; Luo, X.X.; Hai, T.; Wang, H.Y.; Yang, S.; Abdalla, A.N. Visual Object Tracking in RGB-D Data via Genetic Feature Learning. Complexity 2019, 2019, 1–8. [Google Scholar] [CrossRef]
- Ren, Z.; Yuan, J.; Meng, J.; Zhang, Z. Robust part-based hand gesture recognition using kinect sensor. IEEE Trans. Multimed. 2013, 15, 1110–1120. [Google Scholar] [CrossRef]
- Li, Y.; Miao, Q.; Tian, K.; Fan, Y.; Xu, X.; Li, R.; Song, J. Large-scale gesture recognition with a fusion of rgb-d data based on the c3d model. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 25–30. [Google Scholar]
- Li, Y. Hand gesture recognition using Kinect. In Proceedings of the 2012 IEEE International Conference on Computer Science and Automation Engineering, Beijing, China, 22–24 June 2012; pp. 196–199. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Shaoqing, R.; Kaiming, H.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Soviany, P.; Ionescu, R.T. Optimizing the trade-off between single-stage and two-stage deep object detectors using image difficulty prediction. In Proceedings of the International Symposium on Symbolic and Numeric Algorithms for Scientific Computing, Timisoara, Romania, 20–23 September 2018; pp. 209–214. [Google Scholar]
- BenAbdelkader, C.; Yacoob, Y. Statistical body height estimation from a single image. In Proceedings of the International Conference on Automatic Face & Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008; pp. 1–7. [Google Scholar]
- Guan, Y. Unsupervised human height estimation from a single image. J. Biomed. Eng. 2009, 2, 425–430. [Google Scholar] [CrossRef]
- BenAbdelkader, C.; Cutler, R.; Davis, L. Stride and cadence as a biometric in automatic person identification and verification. In Proceedings of the International Conference on Automatic Face Gesture Recognition, Washington, DC, USA, 21 May 2002; pp. 372–377. [Google Scholar]
- Koide, K.; Miura, J. Identification of a specific person using color, height, and gait features for a person following robot. Robot. Auton. Syst. 2016, 84, 76–87. [Google Scholar] [CrossRef]
- Günel, S.; Rhodin, H.; Fua, P. What face and body shapes can tell us about height. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1819–1827. [Google Scholar]
- Sayed, M.R.; Sim, T.; Lim, J.; Ma, K.T. Which Body Is Mine? In Proceedings of the Winter Conference on Applications of Computer Vision, Waikoloa Village, HI, USA, 8–10 January 2019; pp. 829–838. [Google Scholar]
- Contreras, A.E.; Caiman, P.S.; Quevedo, A.U. Development of a kinect-based anthropometric measurement application. In Proceedings of the IEEE Virtual Reality, Minneapolis, MN, USA, 29 March–2 April 2014; pp. 71–72. [Google Scholar]
- Robinson, M.; Parkinson, M. Estimating anthropometry with microsoft Kinect. In Proceedings of the International Digital Human Modeling Symposium, Ann Arbor, MI, USA, 11–13 June 2013; pp. 1–7. [Google Scholar]
- Samejima, I.; Maki, K.; Kagami, S.; Kouchi, M.; Mizoguchi, H. A body dimensions estimation method of subject from a few measurement items using KINECT. In Proceedings of the International Conference on Systems, Man, and Cybernetics, Seoul, Korea, 14–17 October 2012; pp. 3384–3389. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 630–645. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Hartley, R.; Zisserman, A. Camera Models, in Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: New York, NY, USA, 2000; pp. 153–177. [Google Scholar]
- Kwon, S.K.; Lee, D.S. Zoom motion estimation for color and depth videos using depth information. EURASIP J. Image Video Process. 2020, 2020, 1–13. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | Learn Rate Schedules | Train Time (s/iter) | Inference Time (s/im) | Box AP (%) |
|---|---|---|---|---|
| R50-C4 | 1x | 0.584 | 0.110 | 35.7 |
| R50-DC5 | 1x | 0.471 | 0.076 | 37.3 |
| ResNet-50 FPN | 1x | 0.261 | 0.043 | 37.9 |
| R50-C4 | 3x | 0.575 | 0.111 | 38.4 |
| R50-DC5 | 3x | 0.470 | 0.076 | 39.0 |
| ResNet-50 FPN | 3x | 0.261 | 0.043 | 40.2 |
| R101-C4 | 3x | 0.652 | 0.145 | 41.1 |
| R101-DC5 | 3x | 0.545 | 0.092 | 40.6 |
| ResNet-101 FPN | 3x | 0.340 | 0.056 | 42.0 |
| X-101-FPN | 3x | 0.690 | 0.103 | 43.0 |
| Person No. | Actual Height (cm) | Extracting Human Body by Mask R-CNN | Extracting Human Body by Background Depth Image | ||
|---|---|---|---|---|---|
| Estimated Height (cm) | Estimation Error (%) | Estimated Height (cm) | Estimation Error (%) | ||
| 1 | 177 | 179.6 | 1.5 | 172.1 | 2.8 |
| 2 | 183 | 182.1 | 0.5 | 176.5 | 3.6 |
| 3 | 165 | 164.2 | 0.5 | 161.3 | 2.2 |
| 4 | 178 | 176.5 | 0.8 | 173.9 | 2.3 |
| 5 | 182 | 180.9 | 0.6 | 177.7 | 2.4 |
| 6 | 173 | 174.6 | 0.9 | 175.2 | 1.3 |
| 7 | 175 | 174.4 | 0.3 | 171.3 | 2.1 |
| 8 | 170 | 169.2 | 0.5 | 167.1 | 1.7 |
| 9 | 168 | 167.3 | 0.4 | 165.6 | 1.4 |
| 10 | 181 | 178.9 | 0.6 | 177.4 | 1.4 |
| Average error (%) | 0.7 | 2.2 | |||
| Person No. | Actual Height (cm) | Extracting Human Body by Mask R-CNN | Extracting Human Body by Background Depth Image | ||
|---|---|---|---|---|---|
| Estimated Height (cm) | Estimation Error (%) | Estimated Height (cm) | Estimation Error (%) | ||
| 1 | 177 | 176.1 | 0.5 | 171.5 | 3.1 |
| 2 | 183 | 180.7 | 1.3 | 175.9 | 3.9 |
| 3 | 165 | 163.0 | 1.2 | 160.1 | 3.0 |
| 4 | 178 | 175.2 | 1.6 | 174.1 | 2.2 |
| 5 | 182 | 179.6 | 1.3 | 176.6 | 3.0 |
| 6 | 173 | 170.7 | 1.3 | 168.1 | 2.8 |
| 7 | 175 | 172.6 | 1.4 | 170.7 | 2.5 |
| 8 | 170 | 167.5 | 1.5 | 166.1 | 2.3 |
| 9 | 168 | 166.2 | 1.1 | 162.8 | 3.1 |
| 10 | 181 | 177.1 | 1.6 | 174.8 | 2.9 |
| Average error (%) | 1.3 | 2.9 | |||
| Person No. | Actual Height (cm) | Extracting Human Body by Mask R-CNN | Extracting Human Body by Background Depth Image | ||
|---|---|---|---|---|---|
| Estimated Height (cm) | Estimation Error (%) | Estimated Height (cm) | Estimation Error (%) | ||
| 1 | 177 | 174.1 | 1.6 | 167.5 | 5.4 |
| 2 | 183 | 178.7 | 2.3 | 172.9 | 5.5 |
| 3 | 165 | 161.0 | 2.4 | 157.1 | 4.8 |
| 4 | 178 | 173.8 | 2.4 | 172.1 | 3.3 |
| 5 | 182 | 178.4 | 2.0 | 173.6 | 4.6 |
| 6 | 173 | 169.7 | 1.9 | 164.1 | 5.1 |
| 7 | 175 | 171.2 | 2.2 | 168.7 | 3.6 |
| 8 | 170 | 166.4 | 2.1 | 163.1 | 4.1 |
| 9 | 168 | 165.2 | 1.7 | 158.8 | 5.5 |
| 10 | 181 | 174.9 | 2.8 | 171.8 | 4.6 |
| Average error (%) | 2.1 | 4.6 | |||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, D.-s.; Kim, J.-s.; Jeong, S.C.; Kwon, S.-k. Human Height Estimation by Color Deep Learning and Depth 3D Conversion. Appl. Sci. 2020, 10, 5531. https://doi.org/10.3390/app10165531
Lee D-s, Kim J-s, Jeong SC, Kwon S-k. Human Height Estimation by Color Deep Learning and Depth 3D Conversion. Applied Sciences. 2020; 10(16):5531. https://doi.org/10.3390/app10165531
Chicago/Turabian StyleLee, Dong-seok, Jong-soo Kim, Seok Chan Jeong, and Soon-kak Kwon. 2020. "Human Height Estimation by Color Deep Learning and Depth 3D Conversion" Applied Sciences 10, no. 16: 5531. https://doi.org/10.3390/app10165531
APA StyleLee, D.-s., Kim, J.-s., Jeong, S. C., & Kwon, S.-k. (2020). Human Height Estimation by Color Deep Learning and Depth 3D Conversion. Applied Sciences, 10(16), 5531. https://doi.org/10.3390/app10165531