Non-Local Spatial and Temporal Attention Network for Video-Based Person Re-Identification




Abstract
:1. Introduction
- Extraction of dynamic features from other CNN inputs, e.g., by optical flux [8].
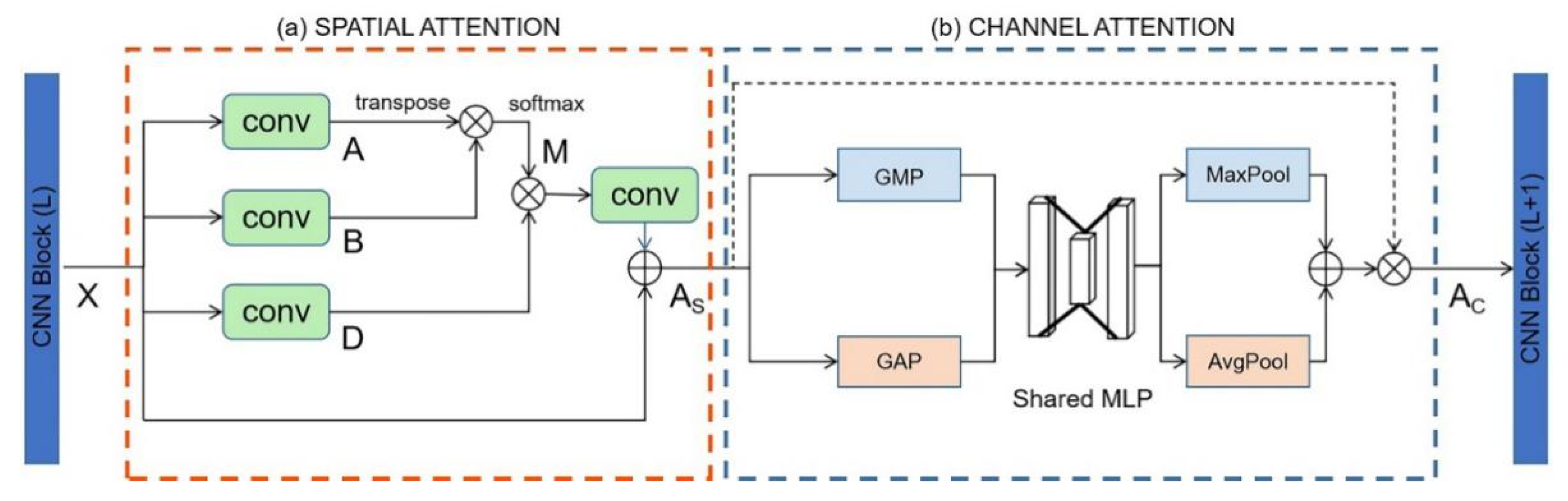
- We propose a plug-and-play non-local attention module (NLAM). It can be inserted into CNN networks for frame-level feature extraction. In the video-based person Re-ID task, the spatial position of the target person in the image can be determined more accurately.
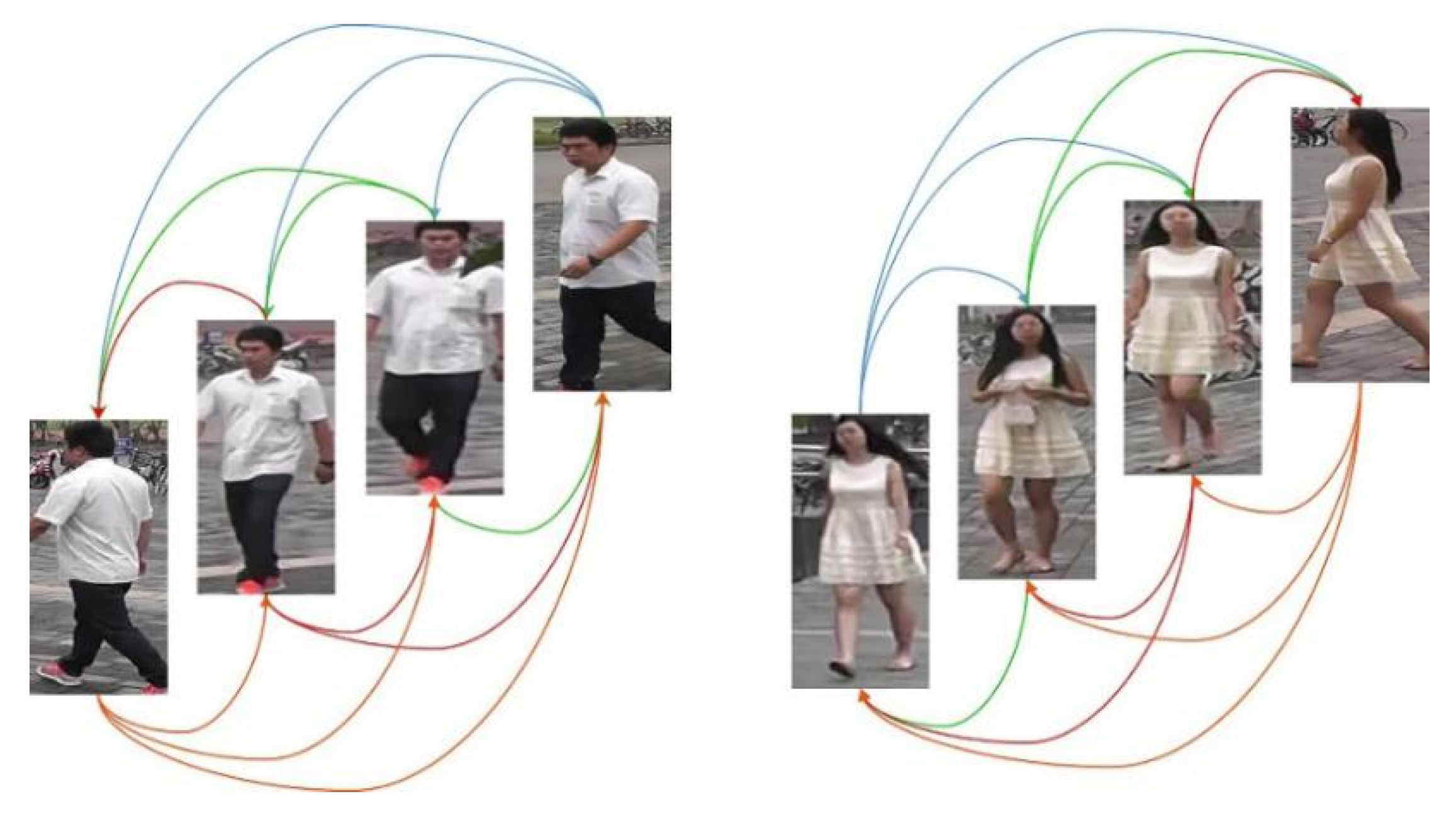
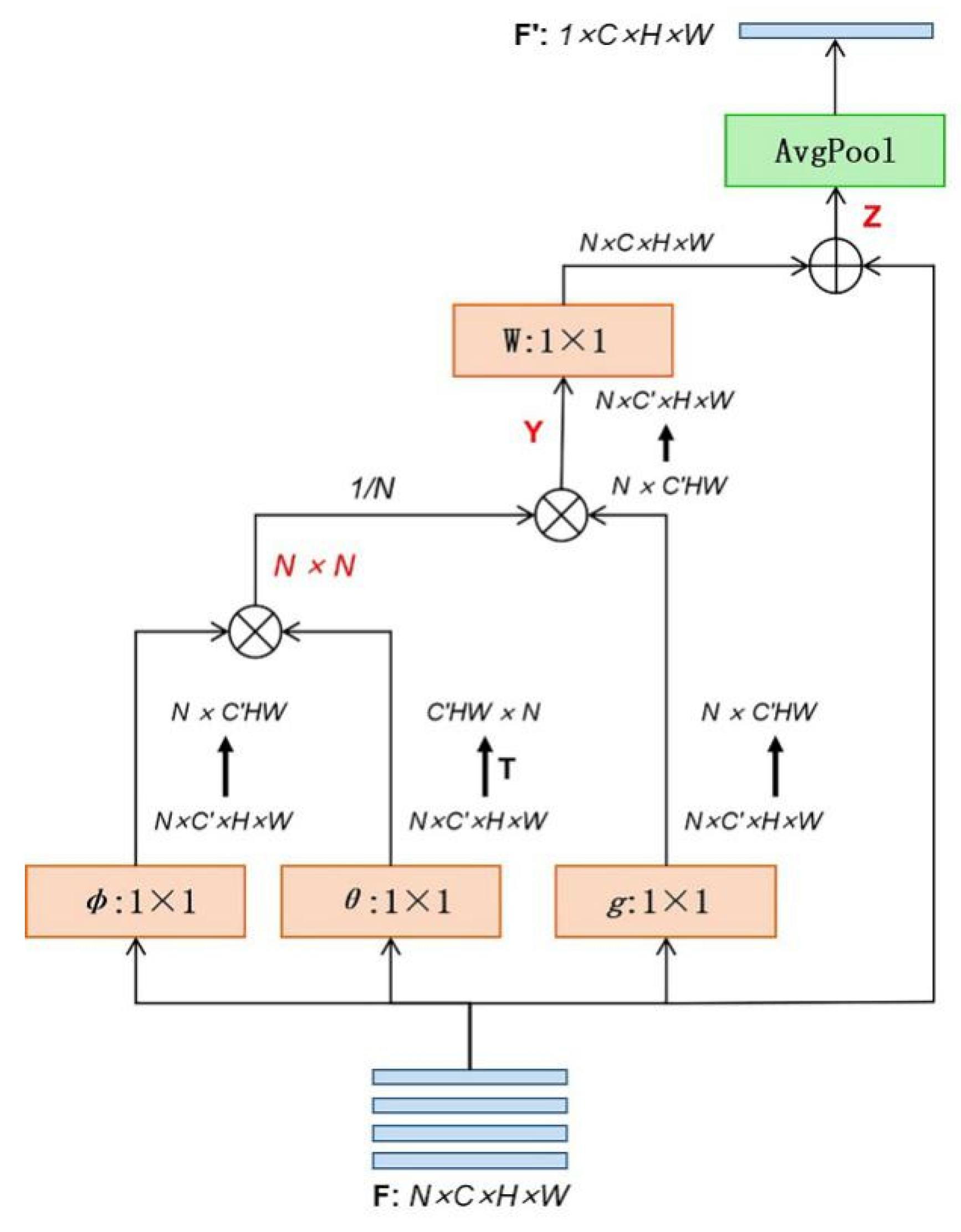
- We propose a non-local temporal pooling (NLTP) method for temporal feature aggregation. We use it to replace the single average or maximum pooling, which could not order the video frames.
- We verified the effectiveness of our two methods on different datasets.
2. Related Works
2.1. Image-Based Person Re-ID
2.2. Video-Based Person Re-ID
2.3. A Video-Based Person Re-ID Pipeline
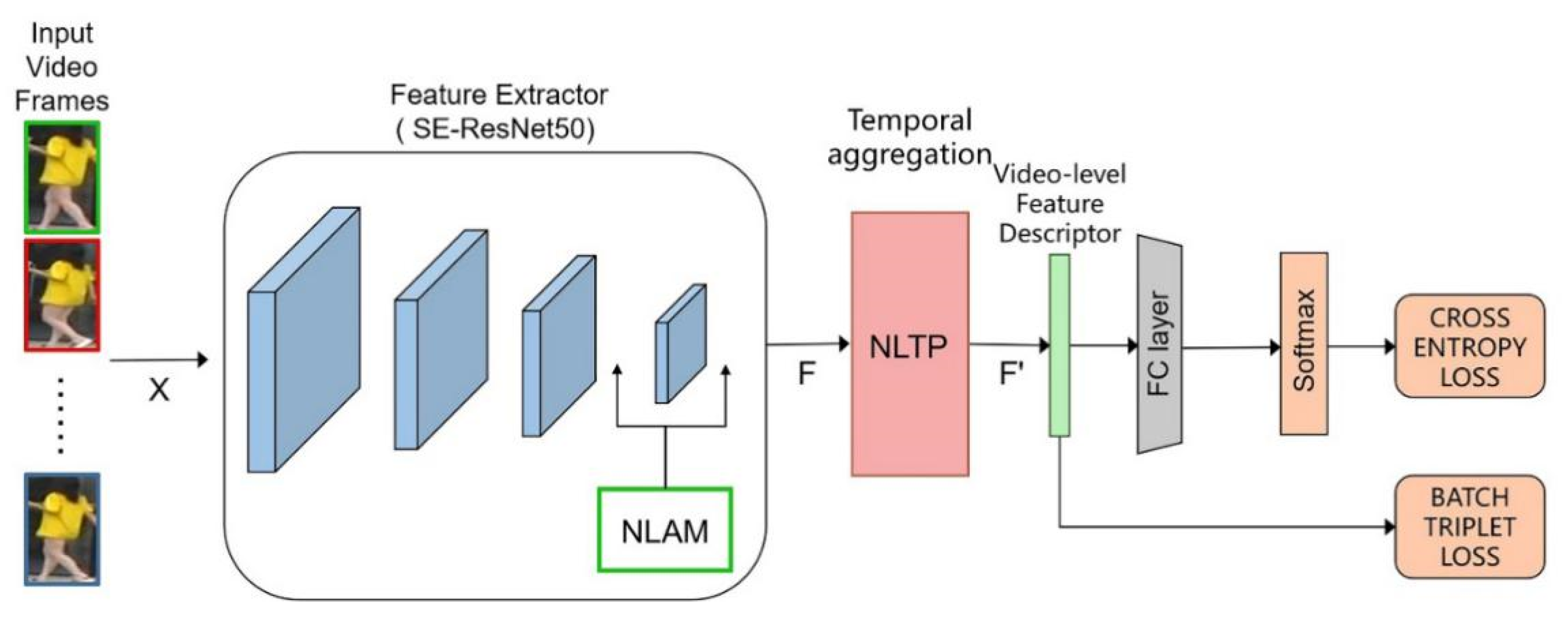
3. Our Approach
3.1. Frame-Level Feature Extraction
3.2. Temporal Aggregation
3.3. Loss Function
4. Experiment
4.1. Datasets and Evaluation
- The total number of people included;
- The number of people used for training;
- The number of people used for testing;
- The number of people used as distractors;
- The total number of videos contained in the dataset; and
- The number of cameras used in data collection.
4.2. Implementation Details
4.3. Result
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chi, S.; Li, J.; Zhang, S.; Xing, J.; Qi, T. Pose-Driven Deep Convolutional Model for Person Re-identification. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, J.; Zhang, S.; Tian, Q.; Wang, M.; Gao, W. Pose-Guided Representation Learning for Person Re-Identification. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 99, 1. [Google Scholar] [CrossRef] [PubMed]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–14 December 2015. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person Transfer GAN to Bridge Domain Gap for Person Re-Identification. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Mclaughlin, N.; Rincon, J.M.D.; Miller, P. Recurrent Convolutional Network for Video-based Person Re-Identification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Zhen, Z.; Yan, H.; Wei, W.; Liang, W.; Tan, T. See the Forest for the Trees: Joint Spatial and Temporal Recurrent Neural Networks for Video-Based Person Re-identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xu, S.; Cheng, Y.; Gu, K.; Yang, Y.; Chang, S.; Zhou, P. Jointly Attentive Spatial-Temporal Pooling Networks for Video-Based Person Re-identification. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4743–4752. [Google Scholar]
- Chung, D.; Tahboub, K.; Delp, E.J. A Two Stream Siamese Convolutional Neural Network for Person Re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Strnadl, C.F. Dense 3D-convolutional neural network for person re-identification in videos. Comput. Rev. 2019, 60, 298. [Google Scholar]
- Li, J.; Zhang, S.; Huang, T. Multi-Scale 3D Convolution Network for Video Based Person Re-Identification. Proc. AAAI Conf. Artif. Intell. 2019, 33, 8618–8625. [Google Scholar] [CrossRef]
- Yan, Y.; Ni, B.; Song, Z.; Ma, C.; Yan, Y.; Yang, X. Person Re-Identification via Recurrent Feature Aggregation. In Proceedings of the European Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liu, H.; Jie, Z.; Jayashree, K.; Qi, M.; Jiang, J.; Yan, S.; Feng, J. Video-based Person Re-identification with Accumulative Motion Context. IEEE Trans. Circuits Syst. Video Technol. 2017, 1. [Google Scholar] [CrossRef]
- Li, S.; Bak, S.; Carr, P.; Wang, X. Diversity Regularized Spatiotemporal Attention for Video-Based Person Re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 369–378. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 7794–7803. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In Defense of the Triplet Loss for Person Re-Identification. arXiv preprint 2017, arXiv:1703.07737. Available online: http://arxiv.org/abs/1703.07737 (accessed on 21 November 2017).
- Li, W.; Zhu, X.; Gong, S. Harmonious Attention Network for Person Re-Identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Sun, Y.; Zheng, L.; Deng, W.; Wang, S. SVDNet for Pedestrian Retrieval. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Xiao, T.; Li, H.; Ouyang, W.; Wang, X. Learning Deep Feature Representations with Domain Guided Dropout for Person Re-identification. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Zheng, L.; Zhang, H.; Sun, S.; Chandraker, M.; Tian, Q. Person Re-identification in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 384–393. [Google Scholar]
- Dong, S.C.; Cristani, M.; Stoppa, M.; Bazzani, L.; Murino, V. Custom Pictorial Structures for Re-identification. Br. Mach. Vis. Conf. (BMVC) 2011, 1, 6. [Google Scholar]
- Gray, D.; Hai, T. Viewpoint Invariant Pedestrian Recognition with an Ensemble of Localized Features. In Proceedings of the Computer Vision—ECCV 2008, 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008. [Google Scholar]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person Re-identification by Local Maximal Occurrence Representation and Metric Learning. arXiv 2015, arXiv:1406.4216. Available online: http://arxiv.org/abs/1406.4216 (accessed on 6 May 2015).
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person Re-identification: Past, Present and Future. arXiv preprint 2016, arXiv:1610.02984. Available online: http://arxiv.org/abs/1610.02984 (accessed on 10 October 2016).
- Karaman, S.; Bagdanov, A.D. Identity Inference: Generalizing Person Re-identification Scenarios. In Proceedings of the International Conference on Computer Vision-volume Part I, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Simonnet, D.; Lewandowski, M.; Velastin, S.A.; Orwell, J.; Turkbeyler, E. Re-identification of Pedestrians in Crowds Using Dynamic Time Warping. In Proceedings of the International Conference on Computer Vision-volume Part I, Florence, Italy, 7–13 October 2012. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Gao, J.; Nevatia, R. Revisiting Temporal Modeling for Video-based Person ReID. arXiv 2018, arXiv:1805.02104. [Google Scholar]
- Arulkumar, S.; Athira, N. Anurag Mittal Co-Segmentation Inspired Attention Networks for Video-Based Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Zheng, L.; Bie, Z.; Sun, Y.; Wang, J.; Su, C.; Wang, S.; Tian, Q. MARS: A Video Benchmark for Large-Scale Person Re-Identification. In Proceedings of the European Conference on Computer Vision, Durham, NC, USA, 11–14 October 2016; pp. 868–884. [Google Scholar]
- Wu, Y.; Lin, Y.; Dong, X.; Yan, Y.; Yang, Y. Exploit the Unknown Gradually: One-Shot Video-Based Person Re-identification by Stepwise Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.S. Performance Measures and a Data Set for Multi-Target, Multi-Camera Tracking. In Proceedings of the European Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 17–35. [Google Scholar]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Lee, K.M. Part-Aligned Bilinear Representations for Person Re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Venice, Italy, 22–29 October 2017; pp. 402–419. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the 31st Conference on Neural Information Processing System, Long Beach, CA, USA, 28 October 2017. [Google Scholar]
- Liu, Y.; Yan, J.; Ouyang, W. Quality Aware Network for Set to Set Recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Learning Deep Context-aware Features over Body and Latent Parts for Person Re-identification. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 384–393. [Google Scholar]
- Song, G.; Leng, B.; Liu, Y.; Hetang, C.; Cai, S. Region-based Quality Estimation Network for Large-scale Person Re-identification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Chen, D.; Li, H.; Tong, X.; Shuai, Y.; Wang, X. Video Person Re-identification with Competitive Snippet-Similarity Aggregation and Co-attentive Snippet Embedding. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Temporal Aggregation | MARS | DukeMTMC-VideoReID | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Extractor | mAP | R1 | R5 | R20 | mAP | R1 | R5 | R20 | |
| ResNet50 | TPavg | 75.8 | 83.1 | 92.8 | 96.8 | 92.9 | 93.6 | 99.0 | 99.7 |
| ResNet50 | TA | 76.7 | 83.3 | 93.8 | 97.4 | 93.2 | 93.9 | 98.9 | 99.5 |
| ResNet50 | RNN | 73.8 | 81.6 | 92.8 | 96.7 | 88.1 | 88.7 | 97.6 | 99.3 |
| SE-ResNet50 | TPavg | 78.1 | 84.0 | 95.2 | 97.1 | 93.5 | 93.7 | 99.0 | 99.7 |
| SE-ResNet50 | TA | 77.7 | 84.2 | 94.7 | 97.4 | 93.1 | 94.2 | 99.0 | 99.7 |
| SE-ResNet50 | RNN | 75.7 | 83.1 | 93.6 | 96.0 | 92.4 | 94.0 | 98.4 | 99.1 |
| Dataset | Identity | Train | Test | Distractor | Video | Camera |
|---|---|---|---|---|---|---|
| MARS [30] | 1261 | 625 | 636 | 3248 | 20478 | 6 |
| Duke [31] | 1404 | 702 | 702 | 408 | 4832 | 8 |
| Location | MARS | Duke | ||||||
|---|---|---|---|---|---|---|---|---|
| mAP | R1 | R5 | R20 | mAP | R1 | R5 | R20 | |
| 2 | 70.6 | 80.6 | 92.3 | 96.3 | 92.7 | 94.0 | 98.8 | 99.6 |
| 3 | 79.5 | 85.7 | 94.8 | 97.5 | 93.8 | 94.7 | 98.9 | 99.8 |
| 4 | 79.4 | 85.8 | 95.2 | 97.6 | 94.0 | 94.9 | 99.1 | 99.9 |
| 5 | 79.5 | 85.5 | 95.3 | 97.5 | 94.1 | 95.0 | 99.0 | 99.9 |
| Location | MARS | Duke | ||||||
|---|---|---|---|---|---|---|---|---|
| mAP | R1 | R5 | R20 | mAP | R1 | R5 | R20 | |
| 3,4 | 79.3 | 86.1 | 94.9 | 97.6 | 94.0 | 94.2 | 98.9 | 99.8 |
| 3,5 | 79.5 | 85.3 | 95.7 | 97.7 | 94.0 | 94.8 | 99.1 | 99.9 |
| 4,5 | 79.8 | 86.3 | 95.8 | 97.8 | 94.5 | 95.0 | 99.3 | 99.9 |
| 3,4,5 | 80.1 | 86.0 | 95.5 | 97.4 | 94.4 | 95.1 | 99.0 | 99.9 |
| Temporal Aggregation | MARS | Duke | ||||
|---|---|---|---|---|---|---|
| mAP | R1 | R5 | mAP | R1 | R5 | |
| TP | 79.6 | 85.8 | 95.7 | 94.1 | 94.9 | 99.1 |
| NLTP (ours) | 79.8 | 86.3 | 95.8 | 94.5 | 95.0 | 99.3 |
| Sequence Length | MARS | ||
|---|---|---|---|
| mAP | R1 | R5 | |
| N = 2 | 77.1 | 83.6 | 94.2 |
| N = 4 | 78.9 | 85.5 | 95.3 |
| N = 8 | 79.8 | 86.3 | 95.8 |
| Network | MARS | ||
| mAP | R1 | R5 | |
| JST-RNN [6] Context Aware Parts [36] | 50.7 56.1 | 70.6 71.8 | 90.0 86.6 |
| Region QEN [37] | 71.1 | 77.8 | 88.8 |
| TriNet [15] | 67.7 | 79.8 | 91.4 |
| Comp. Snippet Sim. [38] | 69.4 | 81.2 | 92.1 |
| Part-Aligned [33] | 72.2 | 83.0 | 92.8 |
| RevisitTempPool [28] | 76.7 | 83.3 | 93.8 |
| [28] + SE-ResNet50 + TPavg (Baseline) | 78.1 | 84.0 | 95.2 |
| SE-ResNet50 + COSAM + TPavg [29] | 79.9 | 84.9 | 95.5 |
| SE-ResNet50 + NLAM (4,5) + NLTP (ours) | 79.8 | 86.3 | 95.8 |
| Network | Duke | ||
| mAP | R1 | R5 | |
| ETAP-Net [31] RevisitTempPool [28] | 78.3 93.2 | 83.6 93.9 | 94.6 98.9 |
| [28] + SE-ResNet50 + TPavg (Baseline) | 93.5 | 93.7 | 99.0 |
| SE-ResNet50 + COSAM + TPavg [29] | 94.1 | 95.4 | 99.3 |
| SE-ResNet50 + NLAM (4,5) + NLTP (ours) | 94.5 | 95.0 | 99.3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Du, F.; Li, W.; Liu, X.; Zou, Q. Non-Local Spatial and Temporal Attention Network for Video-Based Person Re-Identification. Appl. Sci. 2020, 10, 5385. https://doi.org/10.3390/app10155385
Liu Z, Du F, Li W, Liu X, Zou Q. Non-Local Spatial and Temporal Attention Network for Video-Based Person Re-Identification. Applied Sciences. 2020; 10(15):5385. https://doi.org/10.3390/app10155385
Chicago/Turabian StyleLiu, Zheng, Feixiang Du, Wang Li, Xu Liu, and Qiang Zou. 2020. "Non-Local Spatial and Temporal Attention Network for Video-Based Person Re-Identification" Applied Sciences 10, no. 15: 5385. https://doi.org/10.3390/app10155385
APA StyleLiu, Z., Du, F., Li, W., Liu, X., & Zou, Q. (2020). Non-Local Spatial and Temporal Attention Network for Video-Based Person Re-Identification. Applied Sciences, 10(15), 5385. https://doi.org/10.3390/app10155385