The Efficiency of Social Network Services Management in Organizations. An In-Depth Analysis Applying Machine Learning Algorithms and Multiple Linear Regressions



Abstract
1. Introduction
1.1. Social Network Services in Organizations
1.2. The Efficiency of Social Network Services Management in Organizations
1.3. Objectives
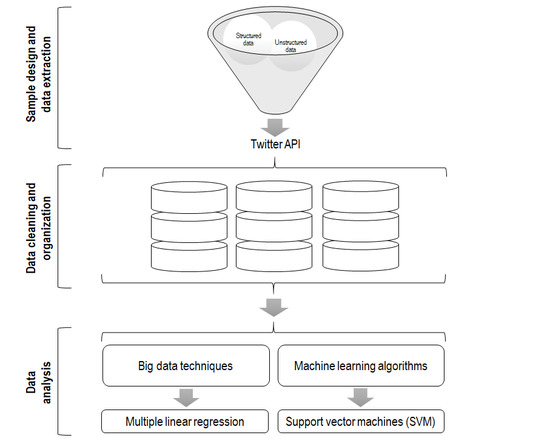
2. Materials and Methods
2.1. Sample Design and Data Extraction
2.2. Data Cleaning and Organization
2.3. Data Analysis
2.3.1. First Step: Machine Learning Algorithms
2.3.2. Second Step: Multiple Linear Regressions
3. Results
3.1. First Step: Machine Learning Algorithms
3.2. Second Step: Multiple Linear Regressions
4. Discussion
4.1. Volumes, Components, and Publication Moments That Increase Content Recognition (RQI)
4.2. Publication Topics That Increase Content Recognition (RQII)
5. Conclusions
6. Limitations and Further Research
Author Contributions
Funding
Conflicts of Interest
References
- Hootsuite & We Are Social; Kemp, S. Digital 2020: Global Digital Overview; Singapore. Available online: https://datareportal.com/reports/digital-2020-singapore?rq=singapore (accessed on 1 May 2020).
- Gómez-García, M.; Matosas-López, L.; Palmero-Ruiz, J. Social Networks Use Patterns among University Youth: The Validity and Reliability of an Updated Measurement Instrument. Sustainability 2020, 12, 3503. [Google Scholar] [CrossRef]
- Sandoval Romero, Y.; Aguaded Gómez, J.I. Nuevas audiencias, nuevas responsabilidades. La competencia mediática en la era de la convergencia digital. ICONO14 2012, 10, 8–22. [Google Scholar] [CrossRef]
- Sánchez Carrero, J.; Contreras Pulido, P. De cara al prosumidor: Producción y consumo empoderando a la ciudadanía 3.0. ICONO14 2012, 10, 62–84. [Google Scholar] [CrossRef]
- Katz, E.; Blumler, J.G.; Gurevitch, M. Uses and Gratifications Research. Public Opin. Q. 1974, 37, 509–523. [Google Scholar] [CrossRef]
- Ruggiero, T.E. Uses and Gratifications Theory in the 21st Century. Mass Commun. Soc. 2000, 3, 3–37. [Google Scholar] [CrossRef]
- Raacke, J.; Bonds-Raacke, J. MySpace and Facebook: Applying the Uses and Gratifications Theory to Exploring Friend-Networking Sites. Cyberpsychol. Behav. 2008, 11, 169–174. [Google Scholar] [CrossRef]
- Smock, A.D.; Ellison, N.B.; Lampe, C.; Wohn, D.Y. Facebook as a toolkit: A uses and gratification approach to unbundling feature use. Comput. Hum. Behav. 2011, 27, 2322–2329. [Google Scholar] [CrossRef]
- Chen, G.M. Tweet this: A uses and gratifications perspective on how active Twitter use gratifies a need to connect with others. Comput. Hum. Behav. 2011, 27, 755–762. [Google Scholar] [CrossRef]
- Tarullo, R. ¿Por qué los y las jóvenes están en las redes sociales? Un análisis de sus motivaciones a partir de la teoría de usos y gratificaciones. Prism. Soc. 2020, 29, 222–239. [Google Scholar]
- Cuevas-Molano, E.; Sánchez Cid, M.; Matosas-López, L. Análisis bibliométrico de estudios sobre la estrategia de contenidos de marca en los medios sociales. Comun. Soc. 2019, 2019, 1–25. [Google Scholar] [CrossRef]
- Casanoves Boix, J.; Küster Boluda, I.; Vila López, N. ¿Por qué las instituciones de educación superior deben apostar por la marca? Rev. Investig. Educ. 2018, 37, 111–127. [Google Scholar] [CrossRef]
- Oviedo-García, M.A.; Muñoz-Expósito, M.; Castellanos-Verdugo, M.; Sancho-Mejías, M. Metric proposal for customer engagement in Facebook. J. Res. Interact. Mark. 2014, 8, 327–344. [Google Scholar] [CrossRef]
- Matosas-López, L. Cómo distintos tipos de organización gestionan su presencia en plataformas sociales. In Proceedings of the XX International Conference on Knowledge, Culture, and Change in Organizations, Chicago, IL, USA, 20–21 October 2020. [Google Scholar]
- Balan, C. Nike on Instagram: Themes of branded content and their engagement power. In Proceedings of the CBU International Conference, Prague, Czech Republic, 22–24 March 2017; Volume 5, pp. 13–18. [Google Scholar]
- Matosas López, L.M. Variables of twitter´s brand activity that influence audience spreading behavior of branded content. ESIC Mark. Econ. Bus. J. 2018, 44, 525–546. [Google Scholar] [CrossRef]
- Carlson, J.; Rahman, M.; Voola, R.; De Vries, N. Customer engagement behaviours in social media: Capturing innovation opportunities. J. Serv. Mark. 2018, 32, 83–94. [Google Scholar] [CrossRef]
- Mukherjee, K.; Banerjee, N. Social networking sites and customers’ attitude towards advertisements. J. Res. Interact. Mark. 2019, 13, 477–491. [Google Scholar] [CrossRef]
- Giakoumaki, C.; Krepapa, A. Brand engagement in self-concept and consumer engagement in social media: The role of the source. Psychol. Mark. 2019, 37, 457–465. [Google Scholar] [CrossRef]
- Majumdar, A.; Bose, I. Do tweets create value? A multi-period analysis of Twitter use and content of tweets for manufacturing firms. Int. J. Prod. Econ. 2019, 216, 1–11. [Google Scholar] [CrossRef]
- Laudano, C.N.; Planas, J.; Kessler, M.I. Aproximacones a los usos de twitter en bibliotecas universitarias de Argentina. An. Doc. 2016, 19. [Google Scholar] [CrossRef][Green Version]
- Cabrera Espín, S.I.; Camarero, E. Comunicación de la ciencia y la tecnología en las universidades ecuatorianas: Estudio preliminar del impacto y percepción entre la población universitaria. Rev. Comun. SEECI 2016, 40, 27. [Google Scholar] [CrossRef][Green Version]
- Quitana Pujalte, L.; Sosa Valcarcel, A.; Castillo Esparcia, A. Acciones y estrategias de comunicación en plataformas digitales. El caso Cifuentes. Prism. Soc. 2018, 22, 247–270. [Google Scholar]
- López-Pérez, L.; Olvera-Lobo, M.-D. Comunicación pública de la ciencia a través de la web 2.0. El caso de los centros de investigación y universidades públicas de España. El profesional de la información 2016, 25, 441. [Google Scholar] [CrossRef]
- Wu, J.; Chen, J.; Chen, H.; Dou, W.; Shao, D. What to say on social media and how: Effects of communication style and function on online customer engagement in China. J. Serv. Theory Pract. 2019, 29, 691–707. [Google Scholar] [CrossRef]
- Kimmons, R.; Veletsianos, G.; Woodward, S. Institutional Uses of Twitter in U.S. Higher Education. Innov. High. Educ. 2017, 42, 97–111. [Google Scholar] [CrossRef]
- Laaser, W.; Brito, J.G.; Toloza, E.A. El uso de redes sociales por parte de las universidades a nivel institucional. Un estudio comparativo. Red Rev. Educ. A Distancia 2012, 32, 231–239. [Google Scholar]
- Pletikosa Cvijikj, I.; Michahelles, F. Online engagement factors on Facebook brand pages. Soc. Netw. Anal. Min. 2013, 3, 843–861. [Google Scholar] [CrossRef]
- Golchha, N. Big Data—The information revolution. Int. J. Appl. Res. 2015, 1, 791–794. [Google Scholar]
- García-González, J.D.; Skrita, A. Predicting academic performance based on students’ family environment: Evidence for Colombia using classification trees. Psychol. Soc. Educ. 2019, 11, 299–311. [Google Scholar] [CrossRef]
- Matosas-López, L. Divergencias en el uso de redes sociales en universitarios de los grados de Economía y Marketing. In Aproximación Periodística y Educomunicativa al Fenómeno de las Redes Sociales; Sanchez, A.M.d.V.D.J.S., Ed.; McGraw Hill: Madrid, Spain, 2019; pp. 697–708. [Google Scholar]
- Saura, J.R.; Herraez, B.R.; Reyes-Menendez, A. Comparing a traditional approach for financial brand communication analysis with a big data analytics technique. IEEE Access 2019, 7, 37100–37108. [Google Scholar] [CrossRef]
- Marciniak, R. Propuesta metodológica para la aplicación del benchmarking internacional en la evaluación de la calidad de la educación superior virtual. Rev. Univ. Soc. Del Conoc. 2013, 12, 46–61. [Google Scholar] [CrossRef]
- Túñez López, M.; Valdiviezo Abad, C.; Martínez Solana, Y. Las redes sociales en la gestión de la comunicación universitaria. Opción 2015, 6, 852–874. [Google Scholar]
- Alkadri, M.F.; Istiani, N.F.F.; Yatmo, Y.A. Mapping Social Media Texts as the Basis of Place-Making Process. Procedia Soc. Behav. Sci. 2015, 184, 46–55. [Google Scholar] [CrossRef][Green Version]
- Bruns, A.; Stieglitz, S. Towards more systematic Twitter analysis: Metrics for tweeting activities. Int. J. Soc. Res. Methodol. 2013, 16, 91–108. [Google Scholar] [CrossRef]
- De Vries, L.; Gensler, S.; Leeflang, P.S.H. Popularity of Brand Posts on Brand Fan Pages: An Investigation of the Effects of Social Media Marketing. J. Interact. Mark. 2012, 26, 83–91. [Google Scholar] [CrossRef]
- Valerio Ureña, G.; Herrera-Murillo, D.J.; Rodríguez-Martínez, M.D.C. Asociación entre el momento de publicación en las redes sociales y el engagement: Estudio de las universidades Mexicanas. Palabra Clave 2014, 17, 749–772. [Google Scholar] [CrossRef]
- García García, M. Universidad y medios sociales. Gestión de la comunicación en la universidad española. Prism. Soc. 2018, 22, 21–36. [Google Scholar]
- Thai, M.T.; Wu, W.; Xiong, H. Big Data in Complex and Social Networks; Chapman & Hall/CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Goonetilleke, O.; Sellis, T.; Zhang, X.; Sathe, S. Twitter analytics: A big data management perspective. ACM Sigkdd Explor. Newsl. 2014, 16, 11–20. [Google Scholar] [CrossRef]
- Kumar, S.; Morstatter, F.; Liu, H. Twitter Data Analytics; Springer: New York, NY, USA, 2013. [Google Scholar]
- Lin, J.; Ryaboy, D. Scaling Big Data Mining Infrastructure: The Twitter Experience. Sigkdd Explor. 2012, 14, 6–19. [Google Scholar] [CrossRef]
- Hoeber, O.; Hoeber, L.; El Meseery, M.; Odoh, K.; Gopi, R. Visual Twitter Analytics (Vista): Temporally changing sentiment and the discovery of emergent themes within sport event tweets. Online Inf. Rev. 2016, 40, 25–41. [Google Scholar] [CrossRef]
- Lakhiwal, A.; Kar, A.K. Insights from twitter analytics: Modeling social media personality dimensions and impact of breakthrough events. In Proceedings of the 15th Conference on e-Business, e-Services and e-Society (I3E), Swansea, UK, 13–15 September 2016; Volume 9844, pp. 533–544. [Google Scholar]
- De Maio, C.; Fenza, G.; Loia, V.; Parente, M.; Cuzzocrea, A. Towards OLAP Analysis of Multidimensional Tweet Streams. In Proceedings of the DOLAP ’15: ACM Eighteenth International Workshop on Data Warehousing and OLAP, Melbourne, Australia, 19–23 October 2015; pp. 69–73. [Google Scholar]
- Blachnik, M.; Kordos, M. Comparison of Instance Selection and Construction Methods with Various Classifiers. Appl. Sci. 2020, 10, 3933. [Google Scholar] [CrossRef]
- Kowsari, K.; Meimandi, K.J.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text Classification Algorithms: A Survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Salas-Rueda, R.-A. Percepciones de los estudiantes sobre el uso de Facebook y Twitter en el contexto educativo por medio de la ciencia de datos y el aprendizaje automático. Pixel-Bit. Rev. Medios Educ. 2020, 58, 91–115. [Google Scholar] [CrossRef]
- Simeone, O. A Very Brief Introduction to Machine Learning with Applications to Communication Systems. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 648–664. [Google Scholar] [CrossRef]
- Wang, Z.; Bai, G.; Chowdhury, S.; Xu, Q.; Seow, Z.L. TwiInsight: Discovering Topics and Sentiments from Social Media Datasets. Comput. Res. Repos. 2017, 2017, 1–14. [Google Scholar]
- Saura, J.R.; Reyes-Menendez, A.; Alvarez-Alonso, C. Do online comments affect environmental management? Identifying factors related to environmental management and sustainability of hotels. Sustainability 2018, 10, 3016. [Google Scholar] [CrossRef]
- Valerio Ureña, G.; Serna Valdivia, R. Redes sociales y bienestar psicológico del estudiante universitario. Rev. Electrónica Investig. Educ. 2018, 20, 19. [Google Scholar] [CrossRef]
- Alonso, M. Las redes sociales como canal de comunicación de las marcas de moda españolas. El caso de Zara, Mango y el Corte Inglés. Index Comun. 2015, 5, 77–105. [Google Scholar]
- Razali, N.M.; Wah, Y.B. Power comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests. J. Stat. Model. Anal. 2011, 2, 21–33. [Google Scholar]
- Gujarati, D.N.; Porter, D.C. Essentials of Econometrics, 4th ed.; McGraw-Hill: New York, NY, USA, 2010. [Google Scholar]
- Gureeva, A.N. Social Networks as a Media Communication Resource for Managing the Image of a Russian Higher Education Institution. Mediascope 2018, 2. [Google Scholar] [CrossRef]
- Guzmán Duque, A.P.; del Moral Pérez, M.E.; González Ladrón de Guevara, F.; Gil Gómez, H. Impacto de twitter en la comunicación y promoción institucional de las universidades Impact of twitter on communication and institutional promotion of universities. Pixel Bit. Rev. Medios Educ. 2013, 43, 139–153. [Google Scholar] [CrossRef][Green Version]
- Hanifawati, T.; Ritonga, U.S.; Puspitasari, E.E. Managing brands’ popularity on Facebook: Post time, content, and brand communication strategies. J. Indones. Econ. Bus. 2019, 34, 185. [Google Scholar] [CrossRef]
- Wang, Y.; Youn, H. Feature weighting based on inter-category and intra-category strength for Twitter sentiment analysis. Appl. Sci. 2019, 9, 92. [Google Scholar] [CrossRef]
- Andéhn, M.; Kazeminia, A.; Lucarelli, A.; Sevin, E. User-generated place brand equity on Twitter: The dynamics of brand associations in social media. Place Brand. Public Dipl. 2014, 10, 132–144. [Google Scholar] [CrossRef]
- Morales, A.J.; Borondo, J.; Losada, J.C.; Benito, R.M. Efficiency of human activity on information spreading on Twitter. Soc. Netw. 2014, 39, 1–11. [Google Scholar] [CrossRef]
- Saif, H.; He, Y.; Fernandez, M.; Alani, H. Contextual semantics for sentiment analysis of Twitter. Inf. Process. Manag. 2016, 52, 5–19. [Google Scholar] [CrossRef]
- Kraiem, M.B.; Feki, J.; Khrouf, K.; Ravat, F.; Teste, O. Modeling and OLAPing social media: The case of Twitter. Soc. Netw. Anal. Min. 2015, 5, 1–15. [Google Scholar] [CrossRef]
- Kraiem, M.B.; Feki, J.; Khrouf, K.; Ravat, F.; Teste, O. OLAP4Tweets: Multidimensional Modeling of tweets. In Proceedings of the 19th East-European Conference on Advances in Databases and Information Systems (ADBIS 2015), Poitiers, France, 8–11 September 2015. [Google Scholar]


{kind=link}
{kind=link}
| Author/s | Year | Platforms Considered | Type of Organization | Purpose of the Study |
|---|---|---|---|---|
| Laudano et al. | 2016 | University | Dissemination of information about libraries collections and services | |
| López-Pérez and Olvera-Lobo | 2016 | Facebook and Twitter | University | Distribution of research results |
| Cabrera Espín and Camarero | 2016 | University | Analysis and comparison of digital communication channels | |
| Kimmons et al. | 2017 | University | Dialogic functionality of the platform | |
| Balan | 2017 | Business | Recognition received by the message depending on the publication topic | |
| Matosas López | 2018 | Business | Content sharing and propagation | |
| Carlson et al. | 2018 | Business | Client perception of the organization | |
| Quitana Pujalte et al. | 2018 | University | Use of corporate accounts in situations of reputational crisis | |
| Wu et al. | 2019 | University | Recognition obtained depending on the publication source | |
| Mukherjee and Banerjee | 2019 | Business | Impact that advertising insertions have on the user | |
| Giakoumaki and Krepapa | 2019 | Business | Influence of publication’s tone on the volume of comments | |
| Majumdar and Bose | 2019 | Business | Associations between platform’s activity and company market value |
| Category | No. of Variables | Name of the Variables |
|---|---|---|
| (a) Publication volumes | 3 | Original Tweets, Retweets, and Replies |
| (b) Publication components | 3 | Links, Mentions, and Hashtags |
| (c) Publication day of the week | 7 | Pub. On Mon., Pub. On Tue., Pub. On Wed., Pub. On Thu, Pub. On Fri., Pub. On Sat., Pub. On Sun. |
| (d) Publication time slot | 8 | Pub. 8:00 to 10:00, Pub. 11:00 to 13:00, Pub. 14:00 to 16:00, Pub. 17:00 to 19:00, Pub. 20:00 to 22:00, Pub. 23:00 to 1:00, Pub. 2:00 to 4:00, Pub. 5:00 to 7:00 |
| (e) Publication topic | 16 | Central topic discussed in the pub. |
| (f)Recognition obtained by the publication | 2 | Retweeted Pubs. and Favorite Pubs. |
| Total | 39 |
| Publication Topic | Number of Tweets | % of Total Tweets | Average Number of Retweets Obtained Per Pub. | Average Number of Favorites Obtained Per Pub. |
|---|---|---|---|---|
| General news | 2458 | 11.29% | 18.87 | 9.21 |
| Scholarships | 429 | 1.97% | 11.21 | 11.16 |
| Science and technology | 1960 | 9.00% | 13.68 | 8.37 |
| Contests | 267 | 1.23% | 9.06 | 6.41 |
| Culture and exhibitions | 1437 | 6.60% | 10.99 | 6.23 |
| Sports | 814 | 3.74% | 11.87 | 5.01 |
| Entrepreneurship | 308 | 1.41% | 7.97 | 5.25 |
| Complementary training | 1228 | 5.64% | 8.01 | 4.18 |
| Gender equality | 700 | 3.22% | 50.98 | 26.14 |
| Institutional information | 4382 | 20.13% | 13.87 | 7.21 |
| Employability | 685 | 3.15% | 8.12 | 4.18 |
| Research | 1796 | 8.25% | 13.08 | 7.38 |
| Seminars and conferences | 1968 | 9.04% | 7.98 | 4.07 |
| Awards and recognitions | 1907 | 8.76% | 11.94 | 3.98 |
| Health and green environment | 1177 | 5.41% | 18.54 | 11.99 |
| Volunteering | 255 | 1.17% | 13.87 | 5.29 |
| Total | 21,771 | 100.00% | 45.84 | 24.98 |
| (f) Recognition Obtained by the Publication | ||||
|---|---|---|---|---|
| Retweeted Pubs. | Favorite Pubs. | |||
| Category/Variable | Β | p-Value | Β | p-Value |
| (a) Publication volumes | ||||
| Original Tweets | −0.164 | 0.281 | 0.198 | 0.003 * |
| Retweets | −0.098 | 0.326 | 0.014 | 0.624 |
| Responses | 0.011 | 0.908 | 0.077 | 0.346 |
| (b) Publication components | ||||
| Links | 0.560 | 0.000 ** | −0.017 | 0.899 |
| Mentions | −0.048 | 0.680 | 0.112 | 0.016 |
| Hashtags | 0.455 | 0.001 * | 0.090 | 0.097 |
| (c) Publication day of the week | ||||
| Pub. On Monday | −0.111 | 0.538 | −0.421 | 0.074 |
| Pub. On Tuesday | −0.121 | 0.435 | −0.094 | 0.698 |
| Pub. On Wednesday | −0.107 | 0.441 | −0.127 | 0.518 |
| Pub. On Thursday | −0.091 | 0.437 | 0.228 | 0.374 |
| Pub. On Friday | −0.157 | 0.381 | 0.124 | 0.493 |
| Pub. On Saturday | −0.153 | 0.207 | 0.049 | 0.409 |
| Pub. On Sunday | −0.006 | 0.981 | −0.054 | 0.364 |
| (d) Publication time slot | ||||
| Pub. 8:00 to 10:00 | −0.071 | 0.781 | 0.237 | 0.004 * |
| Pub. 11:00 to 13:00 | −0.088 | 0.601 | 0.184 | 0.081 |
| Pub. 14:00 to 16:00 | −0.009 | 0.971 | 0.091 | 0.172 |
| Pub. 17:00 to 19:00 | −0.016 | 0.902 | −0.017 | 0.791 |
| Pub. 20:00 to 22:00 | 0.131 | 0.547 | −0.039 | 0.514 |
| Pub. 23:00 to 1:00 | 0.059 | 0.611 | 0.009 | 0.843 |
| Pub. 2:00 to 4:00 | 0.069 | 0.654 | −0.062 | 0.185 |
| Pub. 5:00 to 7:00 | −0.157 | 0.135 | −0.124 | 0.018 |
| (e) Publication topic | ||||
| General news | 0.185 | 0.420 | 0.021 | 0.734 |
| Scholarships | −0.014 | 0.750 | 0.180 | 0.121 |
| Science and technology | −0.039 | 0.537 | 0.074 | 0.117 |
| Contests | 0.517 | 0.427 | 0.092 | 0.092 |
| Culture and exhibitions | 0.066 | 0.905 | 0.071 | 0.151 |
| Sports | −0.087 | 0.547 | 0.263 | 0.341 |
| Entrepreneurship | −0.124 | 0.411 | 0.181 | 0.512 |
| Complementary training | −0.159 | 0.195 | 0.025 | 0.663 |
| Gender equality | 0.447 | 0.000 ** | 0.531 | 0.001 * |
| Institutional information | 0.039 | 0.732 | 0.018 | 0.903 |
| Employability | −0.058 | 0.701 | 0.209 | 0.214 |
| Research | −0.109 | 0.381 | −25.852 | 0.468 |
| Seminars and conferences | 0.091 | 0.514 | 0.034 | 0.584 |
| Awards and recognitions | −0.113 | 0.145 | 0.019 | 0.607 |
| Health and green environment | 0.127 | 0.584 | −0.037 | 0.484 |
| Volunteering | 0.052 | 0.552 | 0.017 | 0.803 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matosas-López, L.; Romero-Ania, A. The Efficiency of Social Network Services Management in Organizations. An In-Depth Analysis Applying Machine Learning Algorithms and Multiple Linear Regressions. Appl. Sci. 2020, 10, 5167. https://doi.org/10.3390/app10155167
Matosas-López L, Romero-Ania A. The Efficiency of Social Network Services Management in Organizations. An In-Depth Analysis Applying Machine Learning Algorithms and Multiple Linear Regressions. Applied Sciences. 2020; 10(15):5167. https://doi.org/10.3390/app10155167
Chicago/Turabian StyleMatosas-López, Luis, and Alberto Romero-Ania. 2020. "The Efficiency of Social Network Services Management in Organizations. An In-Depth Analysis Applying Machine Learning Algorithms and Multiple Linear Regressions" Applied Sciences 10, no. 15: 5167. https://doi.org/10.3390/app10155167
APA StyleMatosas-López, L., & Romero-Ania, A. (2020). The Efficiency of Social Network Services Management in Organizations. An In-Depth Analysis Applying Machine Learning Algorithms and Multiple Linear Regressions. Applied Sciences, 10(15), 5167. https://doi.org/10.3390/app10155167